
Lĩnh vực trí tuệ nhân tạo tiếp tục mở rộng nhanh chóng, với các Mô hình Ngôn ngữ Lớn (LLM) ngày càng thể hiện khả năng nhận thức tinh vi. Trong số đó, FractalAIResearch/Fathom-R1-14B nổi lên như một mô hình đáng chú ý, chứa khoảng 14,8 tỷ tham số. Mô hình này đã được Fractal AI Research thiết kế đặc biệt để vượt trội trong các tác vụ suy luận toán học phức tạp và suy luận tổng quát. Điều làm cho Fathom-R1-14B khác biệt là khả năng đạt được hiệu suất cao này với hiệu quả chi phí đáng kể và trong cửa sổ ngữ cảnh **16.384 (16K) token** thực tế. Bài viết này cung cấp cái nhìn tổng quan kỹ thuật về Fathom-R1-14B, trình bày chi tiết quá trình phát triển, kiến trúc, quy trình đào tạo, hiệu suất được đo điểm chuẩn và cung cấp hướng dẫn tập trung vào việc triển khai thực tế dựa trên các phương pháp đã được thiết lập.
Fractal AI: Những Nhà Đổi Mới Đứng Sau Mô Hình

Fathom-R1-14B là sản phẩm của Fractal AI Research, bộ phận nghiên cứu của Fractal, một công ty phân tích và AI nổi tiếng có trụ sở chính tại **Mumbai, Ấn Độ**. Fractal đã tạo dựng được danh tiếng toàn cầu trong việc cung cấp các giải pháp trí tuệ nhân tạo và phân tích nâng cao cho các công ty trong danh sách Fortune 500. Việc tạo ra Fathom-R1-14B gắn liền với tham vọng ngày càng tăng của Ấn Độ trong lĩnh vực trí tuệ nhân tạo.
Tham Vọng AI Của Ấn Độ
Sự phát triển của mô hình này đặc biệt quan trọng trong bối cảnh **Nhiệm vụ IndiaAI**. Ông Srikanth Velamakanni, Đồng sáng lập, Giám đốc điều hành Tập đoàn & Phó Chủ tịch của Fractal, cho biết Fathom-R1-14B là một minh chứng ban đầu cho một sáng kiến lớn hơn. Ông ấy đã đề cập, "Chúng tôi đề xuất xây dựng mô hình suy luận lớn (LRM) đầu tiên của Ấn Độ như một phần của nhiệm vụ IndiaAI... Đây [Fathom-R1-14B] chỉ là một minh chứng nhỏ cho những gì có thể thực hiện," ám chỉ kế hoạch cho một loạt các mô hình, bao gồm cả phiên bản 70 tỷ tham số lớn hơn nhiều. Hướng đi chiến lược này nhấn mạnh cam kết quốc gia về sự tự chủ AI và việc tạo ra các mô hình nền tảng bản địa. Những đóng góp rộng lớn hơn của Fractal cho AI bao gồm các dự án có tác động khác, chẳng hạn như **Vaidya.ai**, một nền tảng AI đa phương thức để hỗ trợ chăm sóc sức khỏe. Do đó, việc phát hành Fathom-R1-14B dưới dạng công cụ mã nguồn mở không chỉ mang lại lợi ích cho cộng đồng AI toàn cầu mà còn đánh dấu một thành tựu quan trọng trong bối cảnh AI đang phát triển của Ấn Độ.
Thiết Kế Nền Tảng và Bản Thiết Kế Kiến Trúc của Fathom-R1-14B
Những khả năng ấn tượng của Fathom-R1-14B được xây dựng dựa trên nền tảng được lựa chọn cẩn thận và thiết kế kiến trúc mạnh mẽ, được tối ưu hóa cho các tác vụ suy luận.
Hành trình của Fathom-R1-14B bắt đầu với việc lựa chọn Deepseek-R1-Distilled-Qwen-14B làm mô hình cơ sở. Bản chất "chưng cất" (distilled) của mô hình này có nghĩa là nó là một phiên bản phái sinh nhỏ gọn và hiệu quả hơn về mặt tính toán từ một mô hình gốc lớn hơn, được thiết kế đặc biệt để giữ lại một phần đáng kể khả năng của bản gốc, đặc biệt là những khả năng từ dòng Qwen được đánh giá cao. Điều này cung cấp một điểm khởi đầu mạnh mẽ, sau đó Fractal AI Research đã tỉ mỉ nâng cao thông qua các kỹ thuật hậu đào tạo chuyên biệt. Đối với hoạt động của mình, mô hình thường sử dụng độ chính xác **bfloat16 (Định dạng Dấu chấm động Brain)**, tạo ra sự cân bằng hiệu quả giữa tốc độ tính toán và độ chính xác số học cần thiết cho các phép tính phức tạp.
Fathom-R1-14B được xây dựng dựa trên **kiến trúc Qwen2**, một phiên bản mạnh mẽ trong họ mô hình Transformer. Các mô hình Transformer là tiêu chuẩn hiện tại cho các LLM hiệu suất cao, phần lớn nhờ vào **cơ chế tự chú ý** (self-attention) đổi mới của chúng. Các cơ chế này cho phép mô hình động điều chỉnh trọng lượng tầm quan trọng của các token khác nhau—dù là từ, từ con hay ký hiệu toán học—trong một chuỗi đầu vào khi tạo ra đầu ra. Khả năng này rất quan trọng để hiểu được các phụ thuộc phức tạp có trong các bài toán toán học phức tạp và các lập luận logic tinh tế.
Quy mô của mô hình, đặc trưng bởi khoảng **14,8 tỷ tham số**, là yếu tố chính quyết định hiệu suất của nó. Các tham số này, về cơ bản là các giá trị số học được học trong các lớp của mạng nơ-ron, mã hóa kiến thức và khả năng suy luận của mô hình. Một mô hình có kích thước này cung cấp dung lượng đáng kể để nắm bắt và biểu diễn các mẫu phức tạp từ dữ liệu đào tạo của nó.
Ý Nghĩa của Cửa Sổ Ngữ Cảnh 16K
Một đặc tả kiến trúc quan trọng là **cửa sổ ngữ cảnh 16.384 token**. Điều này xác định độ dài tối đa của sự kết hợp giữa lời nhắc đầu vào và đầu ra do mô hình tạo ra có thể được xử lý trong một lần hoạt động. Mặc dù một số mô hình tự hào có cửa sổ ngữ cảnh lớn hơn nhiều, dung lượng 16K của Fathom-R1-14B là một lựa chọn thiết kế có chủ ý và thực dụng. Nó đủ lớn để chứa các phát biểu bài toán chi tiết, các chuỗi suy luận từng bước mở rộng (như thường yêu cầu trong toán học cấp độ Olympic) và các câu trả lời toàn diện. Quan trọng là, điều này đạt được mà không phải chịu chi phí tính toán tăng theo cấp số nhân có thể liên quan đến các cơ chế chú ý trong các chuỗi cực dài, giúp Fathom-R1-14B linh hoạt hơn và ít tốn tài nguyên hơn trong quá trình suy luận (inference).
Fathom-R1-14B Thực Sự, Thực Sự Hiệu Quả Về Chi Phí
Một trong những khía cạnh nổi bật nhất của Fathom-R1-14B là hiệu quả của quy trình hậu đào tạo. Phiên bản chính của mô hình đã được tinh chỉnh với chi phí được báo cáo là khoảng **499 USD**. Khả năng kinh tế đáng chú ý này đạt được thông qua một chiến lược đào tạo phức tạp, đa diện, tập trung vào việc tối đa hóa kỹ năng suy luận mà không tốn quá nhiều chi phí tính toán.
Các kỹ thuật cốt lõi hỗ trợ cho sự chuyên môn hóa hiệu quả này bao gồm:
- Tinh chỉnh có Giám sát (SFT): Giai đoạn nền tảng này bao gồm việc đào tạo mô hình cơ sở trên một tập dữ liệu chất lượng cao, được tuyển chọn gồm các cặp bài toán-lời giải được điều chỉnh đặc biệt cho suy luận toán học nâng cao. Thông qua SFT, mô hình đã học cách mô phỏng các con đường giải quyết vấn đề chính xác và suy luận logic.
- Học theo Chương trình Lặp (Iterative Curriculum Learning): Thay vì cho mô hình tiếp xúc với toàn bộ phạm vi độ khó của bài toán cùng một lúc, chiến lược này giới thiệu các thử thách một cách dần dần. Mô hình bắt đầu với các bài toán toán học đơn giản hơn và dần dần chuyển sang các bài toán phức tạp hơn, chẳng hạn như các bài từ AIME và HMMT. Cách tiếp cận có cấu trúc này tạo điều kiện cho việc học ổn định và hiệu quả hơn, cho phép mô hình xây dựng nền tảng vững chắc trước khi giải quyết các tác vụ cực kỳ khó khăn. Kỹ thuật này là trọng tâm trong việc phát triển một mô hình tiền thân quan trọng,
Fathom-R1-14B-V0.6. - Ghép Mô Hình (Model Merging): Mô hình Fathom-R1-14B cuối cùng là sự kết hợp của hai mô hình tiền nhiệm đã được tinh chỉnh cụ thể:
Fathom-R1-14B-V0.6(đã trải qua Iterative Curriculum SFT) vàFathom-R1-14B-V0.4(tập trung vào SFT với "Shortest-Chains," có thể nhấn mạnh sự súc tích trong các giải pháp). Bằng cách ghép các mô hình được đào tạo với các trọng tâm hơi khác nhau, mô hình kết quả kế thừa một tập hợp các điểm mạnh rộng hơn.
Mục tiêu bao trùm của quy trình đào tạo tỉ mỉ này là thấm nhuần "suy luận toán học súc tích nhưng chính xác".
Fractal AI Research cũng đã khám phá một con đường đào tạo thay thế với một biến thể có tên Fathom-R1-14B-RS. Phiên bản này kết hợp **Học Tăng cường (RL)**, cụ thể là sử dụng một thuật toán được gọi là GRPO (Generalized Reward Pushing Optimization), cùng với SFT. Mặc dù cách tiếp cận này mang lại hiệu suất cao tương đương, chi phí hậu đào tạo của nó hơi cao hơn, ở mức **967 USD**. Sự phát triển của cả hai phiên bản nhấn mạnh cam kết khám phá các phương pháp đa dạng để đạt được hiệu suất suy luận tối ưu một cách hiệu quả. Như một phần trong cam kết về tính minh bạch, Fractal AI Research đã công khai mã nguồn (open-source) các công thức đào tạo và tập dữ liệu.
Các Điểm Chuẩn Hiệu Suất: Định Lượng Sự Xuất Sắc Trong Suy Luận
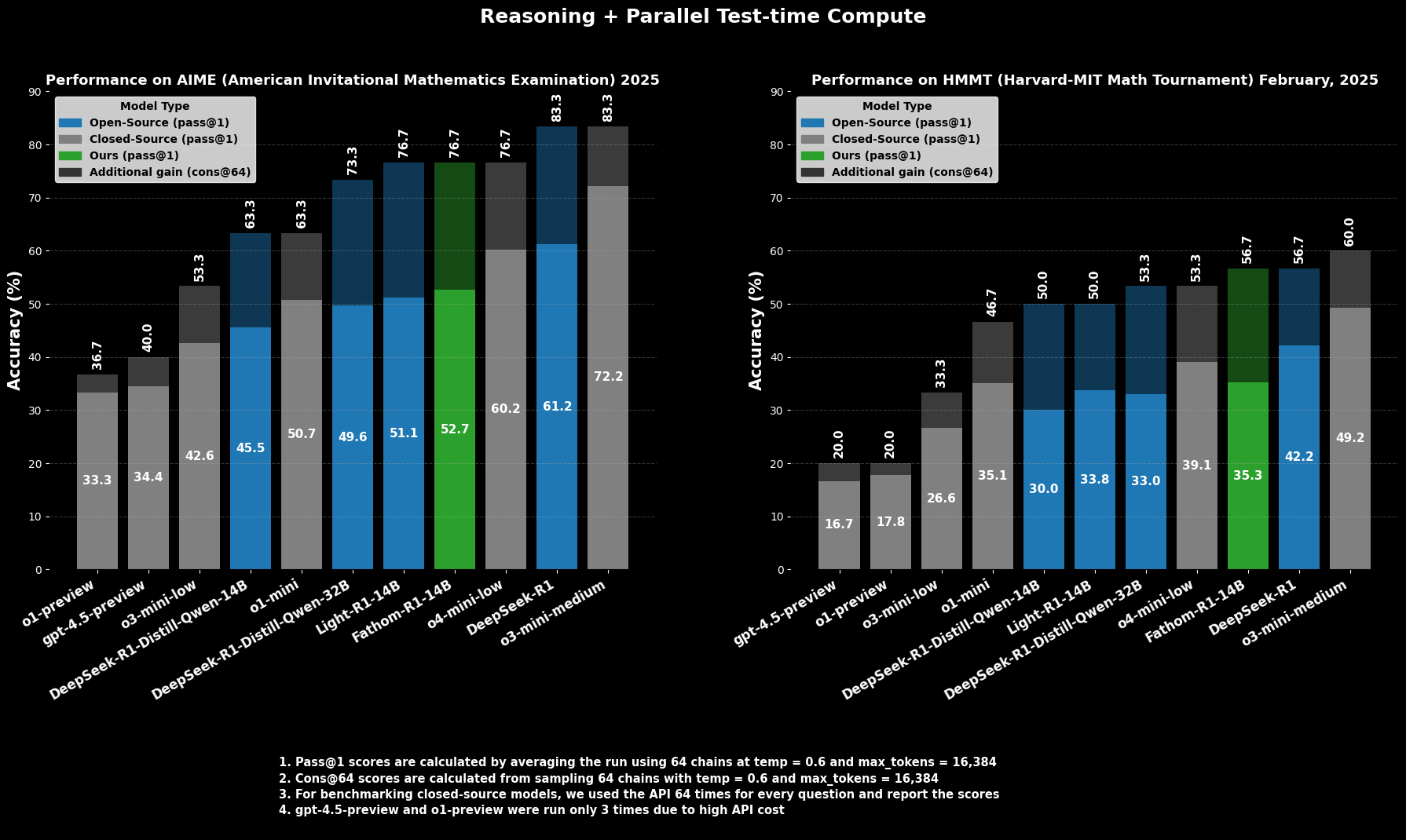
Sự thành thạo của Fathom-R1-14B không chỉ là lý thuyết; nó được chứng minh bằng hiệu suất ấn tượng trên các điểm chuẩn suy luận toán học nghiêm ngặt, được quốc tế công nhận.
Thành Công trên AIME và HMMT
Tại **AIME2025 (American Invitational Mathematics Examination)**, một cuộc thi toán học tiền đại học đầy thử thách, Fathom-R1-14B đạt được độ chính xác **Pass@1 là 52,71%**. Chỉ số `Pass@1` cho biết tỷ lệ phần trăm các bài toán mà mô hình tạo ra lời giải đúng chỉ trong một lần thử. Khi được cấp thêm ngân sách tính toán tại thời điểm kiểm tra, được đánh giá bằng **cons@64** (sự nhất quán giữa 64 lời giải được lấy mẫu), độ chính xác của nó trên AIME2025 tăng lên mức ấn tượng **76,7%**.
Tương tự, tại **HMMT25 (Harvard-MIT Mathematics Tournament)**, một cuộc thi cấp cao khác, mô hình đạt điểm **35,26% Pass@1**, tăng lên **56,7% cons@64**. Những điểm số này đặc biệt đáng chú ý vì chúng đạt được trong giới hạn ngân sách đầu ra 16K token của mô hình, phản ánh các cân nhắc triển khai thực tế.
Hiệu Suất So Sánh
Trong các đánh giá so sánh, Fathom-R1-14B vượt trội đáng kể so với các mô hình mã nguồn mở khác có kích thước tương đương hoặc thậm chí lớn hơn trên các điểm chuẩn toán học cụ thể này ở `Pass@1`. Đáng chú ý hơn, hiệu suất của nó, đặc biệt khi xem xét chỉ số `cons@64`, đặt nó vào vị thế cạnh tranh với một số mô hình mã nguồn đóng có khả năng, vốn thường được cho là có quyền truy cập vào các nguồn tài nguyên lớn hơn rất nhiều. Điều này làm nổi bật hiệu quả của Fathom-R1-14B trong việc chuyển đổi các tham số và quá trình đào tạo của nó thành khả năng suy luận có độ chính xác cao.
Hãy Thử Chạy Fathom-R1-14B
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
Phần này cung cấp hướng dẫn tập trung về cách chạy Fathom-R1-14B bằng thư viện transformers của Hugging Face trong môi trường Python. Cách tiếp cận này rất phù hợp cho người dùng có quyền truy cập vào phần cứng GPU mạnh mẽ, dù là cục bộ hay thông qua các nhà cung cấp dịch vụ đám mây. Các bước được phác thảo ở đây tuân thủ chặt chẽ các phương pháp đã được thiết lập để triển khai các mô hình như vậy.
Cấu Hình Môi Trường
Thiết lập một môi trường Python phù hợp là rất quan trọng. Các bước sau đây trình bày chi tiết một thiết lập phổ biến sử dụng Conda trên hệ thống dựa trên Linux (hoặc Windows Subsystem for Linux):
Truy Cập Máy Của Bạn: Nếu sử dụng một phiên bản GPU đám mây từ xa, hãy kết nối với nó qua SSH.Bash
# Example: ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key
Xác Minh Nhận Diện GPU: Đảm bảo hệ thống nhận diện GPU NVIDIA và các trình điều khiển đã được cài đặt đúng.Bash
nvidia-smi
Tạo và Kích Hoạt Môi Trường Conda: Đây là cách làm tốt để cô lập các phụ thuộc của dự án.Bash
conda create -n fathom python=3.11 -y
conda activate fathom
Cài Đặt Các Thư Viện Cần Thiết: Cài đặt PyTorch (tương thích với phiên bản CUDA của bạn), `transformers` của Hugging Face, `accelerate` (để tải và phân phối mô hình hiệu quả), `notebook` (cho Jupyter), và `ipywidgets` (cho khả năng tương tác của notebook).Bash
# Ensure you install a PyTorch version compatible with your GPU's CUDA toolkit
# Example for CUDA 11.8:
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Or for CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install -c conda-forge --override-channels notebook -y
pip install ipywidgets transformers accelerate
Suy Luận Dựa Trên Python Trong Jupyter Notebook
Sau khi môi trường đã sẵn sàng, bạn có thể sử dụng Jupyter Notebook để tải và tương tác với Fathom-R1-14B.
Khởi Động Máy Chủ Jupyter Notebook: Nếu đang ở trên máy chủ từ xa, hãy khởi động Jupyter Notebook cho phép truy cập từ xa và chỉ định một cổng.Bash
jupyter notebook --no-browser --port=8888 --allow-root
Nếu chạy từ xa, bạn có thể sẽ cần thiết lập chuyển tiếp cổng SSH từ máy cục bộ của mình để truy cập giao diện Jupyter:Bash
# Example: ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip
Sau đó, mở http://localhost:8889 (hoặc cổng cục bộ bạn đã chọn) trong trình duyệt web của bạn.
Mã Python để Tương Tác với Mô Hình: Tạo một Jupyter Notebook mới và sử dụng mã Python sau:Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Define the model ID from Hugging Face
model_id = "FractalAIResearch/Fathom-R1-14B"
print(f"Loading tokenizer for {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(f"Loading model {model_id} (this may take a while)...")
# Load the model with bfloat16 precision for efficiency and device_map for auto distribution
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Use bfloat16 if your GPU supports it
device_map="auto", # Automatically distributes model layers across available hardware
trust_remote_code=True # Some models may require this
)
print("Model and tokenizer loaded successfully.")
# Define a sample mathematical prompt
prompt = """Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. In June, she sold 4 more clips than in May. How many clips did Natalia sell altogether in April, May, and June? Provide a step-by-step solution.
Solution:"""
print(f"\nPrompt:\n{prompt}")
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Ensure inputs are on the model's device
print("\nGenerating solution...")
# Generate the output from the model
# Adjust generation parameters as needed for different types of problems
outputs = model.generate(
**inputs,
max_new_tokens=768, # Maximum number of new tokens to generate for the solution
num_return_sequences=1, # Number of independent sequences to generate
temperature=0.1, # Lower temperature for more deterministic, factual outputs
top_p=0.7, # Use nucleus sampling with top_p
do_sample=True # Enable sampling for temperature and top_p to have an effect
)
# Decode the generated tokens into a string
solution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nGenerated Solution:\n")
print(solution_text)
Kết Luận: Tác Động của Fathom-R1-14B đối với AI Dễ Tiếp Cận
FractalAIResearch/Fathom-R1-14B là một minh chứng thuyết phục về sự khéo léo kỹ thuật trong lĩnh vực AI đương đại. Thiết kế đặc trưng của nó, với khoảng **14,8 tỷ tham số**, **kiến trúc Qwen2**, và **cửa sổ ngữ cảnh 16K token**, khi kết hợp với quy trình đào tạo đột phá và hiệu quả về chi phí (khoảng **499 USD** cho phiên bản chính), đã tạo ra một LLM mang lại hiệu suất hàng đầu. Điều này được chứng minh bằng điểm số của nó trên các điểm chuẩn suy luận toán học khắt khe như AIME và HMMT.
Fathom-R1-14B minh họa một cách thuyết phục rằng ranh giới của suy luận AI có thể được nâng cao thông qua thiết kế thông minh và các phương pháp hiệu quả, thúc đẩy một tương lai nơi AI hiệu suất cao trở nên dân chủ hơn và mang lại lợi ích rộng rãi.
Bạn muốn một nền tảng Tích hợp, Tất cả trong Một cho Đội ngũ Phát triển của mình làm việc cùng nhau với năng suất tối đa?
Apidog đáp ứng mọi nhu cầu của bạn, và thay thế Postman với mức giá phải chăng hơn nhiều!