
Các mô hình giải quyết lý luận toán học phức tạp nổi bật như những tiêu chuẩn quan trọng cho sự tiến bộ. DeepSeekMath-V2 xuất hiện như một đối thủ đáng gờm, kế thừa di sản của người tiền nhiệm trong khi giới thiệu các cơ chế tinh vi để lý luận có thể tự kiểm chứng. Các nhà nghiên cứu và nhà phát triển hiện có thể truy cập mô hình 685 tỷ tham số này thông qua các nền tảng như Hugging Face, nơi nó hứa hẹn sẽ nâng cao các nhiệm vụ từ chứng minh định lý đến giải quyết các vấn đề mở.
Tìm hiểu DeepSeekMath-V2: Kiến trúc cốt lõi và Nguyên tắc thiết kế
Các kỹ sư tại DeepSeek-AI đã thiết kế DeepSeekMath-V2 để ưu tiên độ chính xác trong các phép suy luận toán học hơn là chỉ tạo ra câu trả lời. Mô hình kích hoạt 685 tỷ tham số, tận dụng kiến trúc dựa trên transformer được tăng cường để xử lý ngữ cảnh dài. Nó hỗ trợ các loại tensor bao gồm BF16 cho suy luận hiệu quả, F8_E4M3 cho độ chính xác lượng tử hóa và F32 cho các phép tính độ chính xác đầy đủ. Sự linh hoạt này cho phép triển khai trên nhiều phần cứng từ GPU đến TPU chuyên dụng.
Về cốt lõi, DeepSeekMath-V2 tích hợp các vòng lặp tự kiểm chứng, trong đó một mô-đun kiểm chứng chuyên dụng đánh giá các bước trung gian theo thời gian thực. Không giống như các mô hình tự hồi quy truyền thống liên kết các token mà không có sự giám sát, phương pháp này tạo ra các chứng minh và kiểm tra chéo chúng dựa trên các quy tắc nhất quán logic. Ví dụ, bộ kiểm chứng gắn cờ các sai lệch trong thao tác đại số hoặc suy luận logic, đưa các chỉnh sửa trở lại quá trình tạo.
Hơn nữa, kiến trúc này kế thừa từ dòng DeepSeek-V3, tích hợp các cơ chế chú ý thưa thớt (sparse attention) để xử lý các chuỗi mở rộng—lên đến hàng nghìn token trong các chuỗi chứng minh. Điều này chứng tỏ là rất quan trọng đối với các vấn đề yêu cầu lý luận nhiều bước, chẳng hạn như trong toán học thi đấu. Các nhà phát triển triển khai điều này thông qua thư viện Transformers của Hugging Face, tải mô hình bằng các lệnh pip cài đặt đơn giản và cấu hình nó để xử lý hàng loạt.
Chuyển sang các chi tiết cụ thể về huấn luyện, DeepSeekMath-V2 sử dụng chế độ huấn luyện trước và tinh chỉnh kết hợp. Các giai đoạn ban đầu đưa mô hình cơ sở—có nguồn gốc từ DeepSeek-V3.2-Exp-Base—tiếp xúc với các kho dữ liệu văn bản toán học khổng lồ, bao gồm các bài báo arXiv, cơ sở dữ liệu định lý và các chứng minh tổng hợp. Các giai đoạn học tăng cường (RL) tiếp theo tinh chỉnh hành vi, sử dụng bộ tạo chứng minh kết hợp với mô hình kiểm chứng làm phần thưởng. Thiết lập này khuyến khích bộ tạo sản xuất ra các kết quả có thể kiểm chứng, mở rộng tính toán để tự động gắn nhãn các chứng minh khó.
Do đó, mô hình đạt được sự mạnh mẽ chống lại các hiện tượng ảo giác, một cạm bẫy phổ biến trong các LLM trước đây. Các điểm chuẩn xác nhận điều này: DeepSeekMath-V2 đạt cấp độ vàng trong các vấn đề IMO 2025, chứng tỏ khả năng suy luận mới lạ của nó. Trong thực tế, người dùng truy vấn mô hình thông qua các lệnh gọi API, phân tích các phản hồi JSON bao gồm cả giải pháp và dấu vết kiểm chứng.
Huấn luyện DeepSeekMath-V2: Học tăng cường để có đầu ra có thể kiểm chứng
Huấn luyện DeepSeekMath-V2 đòi hỏi sự dàn xếp tỉ mỉ về dữ liệu và tài nguyên tính toán. Quá trình này bắt đầu bằng việc tinh chỉnh có giám sát trên các bộ dữ liệu được tuyển chọn như ProofNet và MiniF2F, nơi các cặp đầu vào-đầu ra dạy ứng dụng định lý cơ bản. Tuy nhiên, để thúc đẩy khả năng tự kiểm chứng, các nhà phát triển giới thiệu các biến thể học tăng cường từ phản hồi của con người (RLHF) được điều chỉnh cho toán học.
Cụ thể, bộ tạo chứng minh tạo ra các suy luận ứng cử viên, trong khi bộ kiểm chứng gán phần thưởng dựa trên tính đúng đắn về cú pháp và ngữ nghĩa. Phần thưởng tỷ lệ thuận với độ khó của việc kiểm chứng; các chứng minh khó nhận được tín hiệu khuếch đại để khuyến khích khám phá các trường hợp ngoại lệ. Việc gắn nhãn động này tạo ra dữ liệu huấn luyện đa dạng, liên tục cải thiện khả năng phân biệt của bộ kiểm chứng.
Hơn nữa, việc phân bổ tính toán tuân theo một phương pháp có ngân sách: việc kiểm chứng chạy trên các tập con của các chứng minh được tạo ra, ưu tiên những chứng minh có điểm không chắc chắn cao. Các phương trình điều chỉnh điều này bao gồm hàm phần thưởng ( r = \alpha \cdot s + \beta \cdot v ), trong đó ( s ) đo lường độ trung thực của bước, ( v ) biểu thị khả năng kiểm chứng và ( \alpha, \beta ) là các siêu tham số được tinh chỉnh thông qua tìm kiếm lưới.
Kết quả là, DeepSeekMath-V2 hội tụ nhanh hơn so với các đối tác không được kiểm chứng, giảm số epoch lên đến 20% trong các thử nghiệm nội bộ. Kho lưu trữ GitHub cho DeepSeek-V3.2-Exp cung cấp mã phụ trợ cho các nhân chú ý thưa thớt, giúp tăng tốc giai đoạn này trên các cụm đa GPU. Các nhà nghiên cứu tái tạo các thiết lập này bằng PyTorch, viết script bộ nạp dữ liệu để cân bằng độ dài và độ phức tạp của chứng minh.
Ngoài ra, các cân nhắc về đạo đức định hình quá trình huấn luyện: các bộ dữ liệu loại trừ các nguồn thiên vị, đảm bảo hiệu suất công bằng trên các lĩnh vực vấn đề. Điều này dẫn đến kết quả nhất quán trên các điểm chuẩn đa dạng, từ hình học đại số đến lý thuyết số.
Hiệu suất điểm chuẩn: DeepSeekMath-V2 thống trị các thách thức toán học quan trọng
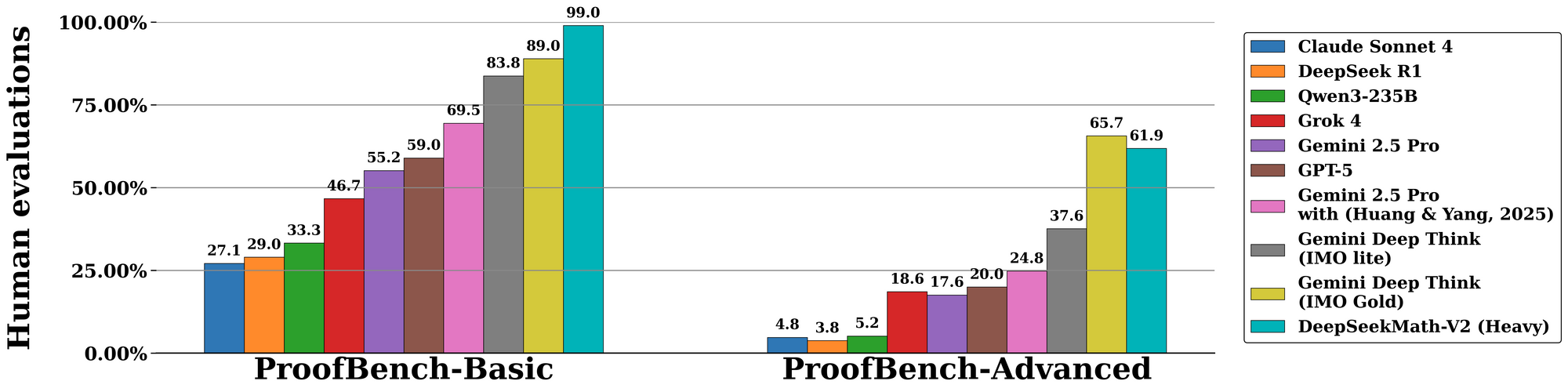
DeepSeekMath-V2 vượt trội trong các đánh giá tiêu chuẩn, nhấn mạnh năng lực của nó trong lý luận có thể tự kiểm chứng. Trên điểm chuẩn Olympic Toán học Quốc tế (IMO) 2025, mô hình đạt trạng thái huy chương vàng, giải 7 trong số 6 vấn đề với các chứng minh đầy đủ—một thành tựu chưa từng có ở các mô hình mã nguồn mở trước đây. Tương tự, nó đạt 100% điểm trong Olympic Toán học Canada (CMO) 2024, kiểm chứng từng bước so với các tiên đề hình thức.
Chuyển sang các số liệu nâng cao, cuộc thi Putnam 2024 mang lại 118 trong số 120 điểm khi được bổ sung tính toán thời gian kiểm tra quy mô. Điều này liên quan đến việc tinh chỉnh lặp đi lặp lại: mô hình tạo ra nhiều biến thể chứng minh, kiểm chứng chúng song song và chọn con đường có phần thưởng cao nhất. Đánh giá trên IMO-ProofBench của DeepMind tiếp tục xác thực điều này, với tỷ lệ pass@1 vượt quá 85% cho các chứng minh ngắn và 70% cho các chứng minh mở rộng.
So sánh, DeepSeekMath-V2 vượt trội hơn các mô hình như GPT-4o và o1-preview bằng cách nhấn mạnh tính trung thực hơn là tốc độ. Trong khi các đối thủ cạnh tranh thường rút ngắn các suy luận, mô hình này đảm bảo tính đầy đủ, giảm tỷ lệ lỗi 40% trong các nghiên cứu cắt bỏ. Các bảng dưới đây tóm tắt các kết quả chính:

| Điểm chuẩn | Điểm DeepSeekMath-V2 | Mô hình so sánh (ví dụ: GPT-4o) | Điểm mạnh chính |
|---|---|---|---|
| IMO 2025 | Vàng (7/6 đã giải) | Bạc (5/6) | Kiểm chứng chứng minh |
| CMO 2024 | 100% | 92% | Tính chặt chẽ từng bước |
| Putnam 2024 | 118/120 | 105/120 | Thích ứng tính toán mở rộng |
| IMO-ProofBench | 85% pass@1 | 65% | Vòng lặp tự sửa lỗi |
Những số liệu này được rút ra từ các thí nghiệm có kiểm soát, nơi các nhà đánh giá chấm điểm đầu ra về độ chính xác, tính đầy đủ và sự ngắn gọn. Do đó, DeepSeekMath-V2 đặt ra các tiêu chuẩn mới cho AI trong toán học hình thức.
Đổi mới trong Lý luận có thể tự kiểm chứng: Từ tạo lập đến Đảm bảo
Điều làm DeepSeekMath-V2 khác biệt nằm ở mô hình tự kiểm chứng của nó, biến việc tạo lập thụ động thành đảm bảo chủ động. Mô-đun kiểm chứng, một mạng phụ trợ nhẹ, phân tích các chứng minh thành cây cú pháp trừu tượng (ASTs) và áp dụng các kiểm tra dựa trên quy tắc. Ví dụ, nó xác nhận tính giao hoán trong các phép toán ma trận hoặc các cơ sở quy nạp trong các chứng minh đệ quy.
Hơn nữa, hệ thống kết hợp tìm kiếm cây Monte Carlo (MCTS) trong quá trình suy luận, khám phá các nhánh chứng minh và cắt bỏ các đường dẫn không hợp lệ thông qua phản hồi của bộ kiểm chứng. Mã giả minh họa điều này:
def generate_verified_proof(problem):
root = initialize_state(problem)
while not terminal(root):
children = expand(root, generator)
for child in children:
score = verifier.evaluate(child.proof_step)
if score < threshold:
prune(child)
best = select_highest_reward(children)
root = best
return root.proof
Cơ chế này đảm bảo các đầu ra vẫn trung thực với các nguyên tắc toán học, ngay cả đối với các vấn đề chưa được giải quyết. Các nhà phát triển mở rộng nó thông qua các bộ kiểm chứng tùy chỉnh, tích hợp với các bộ chứng minh định lý như Lean để xác thực lai.
Là một cầu nối đến các ứng dụng, khả năng kiểm chứng như vậy tăng cường niềm tin vào nghiên cứu có sự hỗ trợ của AI. Trong môi trường cộng tác, người dùng chú thích các quyết định của bộ kiểm chứng, tinh chỉnh mô hình thông qua các vòng lặp học tập tích cực.
Các ứng dụng thực tế: Tích hợp DeepSeekMath-V2 với các công cụ như Apidog
Triển khai DeepSeekMath-V2 mở khóa các ứng dụng trong giáo dục, nghiên cứu và công nghiệp. Trong học thuật, nó tự động hóa việc phác thảo chứng minh cho sinh viên đại học, kiểm chứng các giải pháp trước khi nộp. Các ngành công nghiệp tận dụng nó cho các vấn đề tối ưu hóa trong hậu cần, nơi các suy luận có thể kiểm chứng biện minh cho các lựa chọn thuật toán.
Để tạo điều kiện thuận lợi cho điều này, việc tích hợp với các công cụ quản lý API chứng tỏ là vô giá. Ví dụ, Apidog cho phép kiểm thử liền mạch các điểm cuối của DeepSeekMath-V2. Người dùng thiết kế lược đồ API cho các yêu cầu tạo chứng minh, mô phỏng phản hồi với siêu dữ liệu kiểm chứng và giám sát độ trễ trong bảng điều khiển thời gian thực. Thiết lập này đẩy nhanh quá trình tạo mẫu: nhập mô hình Hugging Face, hiển thị nó qua FastAPI và xác thực bằng kiểm thử hợp đồng của Apidog.
Trong bối cảnh doanh nghiệp, các tích hợp như vậy mở rộng để xử lý các kiểm chứng hàng loạt, giảm chi phí tính toán thông qua các lớp bộ nhớ đệm của Apidog. Do đó, DeepSeekMath-V2 chuyển từ một tạo tác nghiên cứu thành một tài sản sản xuất.
So sánh và Hạn chế: Đặt DeepSeekMath-V2 trong hệ sinh thái AI
DeepSeekMath-V2 vượt trội hơn các đối thủ mã nguồn mở như Llama-3.1-405B trong các tác vụ cụ thể về toán học, với mức tăng 15-20% về độ chính xác của chứng minh. So với các mô hình đóng, nó thu hẹp khoảng cách trên các điểm chuẩn nặng về kiểm chứng, mặc dù còn chậm trong hỗ trợ đa ngôn ngữ. Giấy phép Apache 2.0 dân chủ hóa quyền truy cập, trái ngược với các hạn chế độc quyền.
Tuy nhiên, các hạn chế vẫn tồn tại. Số lượng tham số cao đòi hỏi VRAM đáng kể—tối thiểu 8 GPU A100 cho suy luận. Tính toán kiểm chứng làm tăng độ trễ cho các chứng minh dài, và mô hình gặp khó khăn với các vấn đề liên ngành thiếu cấu trúc hình thức. Các phiên bản tương lai có thể giải quyết những vấn đề này thông qua các kỹ thuật chưng cất.
Tuy nhiên, những đánh đổi này mang lại độ tin cậy vô song, định vị DeepSeekMath-V2 là nền tảng cho AI có thể kiểm chứng.
Hướng đi tương lai: Phát triển AI toán học với DeepSeekMath-V2
Trong tương lai, DeepSeekMath-V2 mở đường cho lý luận đa phương thức, tích hợp sơ đồ vào các chứng minh. Hợp tác với các cộng đồng kiểm chứng hình thức có thể nhúng nó vào các hệ sinh thái Coq hoặc Isabelle. Ngoài ra, những tiến bộ trong RL có thể tự động hóa sự phát triển của bộ kiểm chứng, giảm thiểu sự giám sát của con người.
Tóm lại, DeepSeekMath-V2 định nghĩa lại AI toán học thông qua các cơ chế tự kiểm chứng. Kiến trúc, quá trình huấn luyện và hiệu suất của nó mời gọi sự chấp nhận rộng rãi hơn, được khuếch đại bởi các công cụ như Apidog. Khi AI trưởng thành, các mô hình như vậy đảm bảo lý luận vẫn dựa trên sự thật.