
Các nhà phát triển và nhà nghiên cứu không ngừng tìm kiếm cách để kết nối dữ liệu hình ảnh với xử lý văn bản trong trí tuệ nhân tạo. DeepSeek-AI giải quyết thách thức này với DeepSeek-OCR, một mô hình tập trung vào nén quang học theo ngữ cảnh. Ra mắt vào ngày 20 tháng 10 năm 2025, công cụ này xem xét các bộ mã hóa thị giác từ góc độ tập trung vào LLM và đẩy giới hạn của việc nén thông tin hình ảnh vào ngữ cảnh văn bản. Các kỹ sư tích hợp các mô hình như vậy để xử lý hiệu quả các tác vụ phức tạp như chuyển đổi tài liệu và mô tả hình ảnh.
Nén quang học theo ngữ cảnh (contexts optical compression) đề cập đến quá trình các bộ mã hóa thị giác nén dữ liệu hình ảnh thành các biểu diễn văn bản nhỏ gọn mà các mô hình ngôn ngữ lớn (LLM) có thể xử lý hiệu quả. Các hệ thống OCR truyền thống trích xuất văn bản nhưng thường bỏ qua các sắc thái ngữ cảnh, chẳng hạn như bố cục hoặc mối quan hệ không gian. DeepSeek-OCR vượt qua những hạn chế này bằng cách nhấn mạnh vào việc nén giữ lại các chi tiết cần thiết. Mô hình hỗ trợ nhiều chế độ phân giải, cho phép linh hoạt trong việc xử lý các kích thước hình ảnh khác nhau. Hơn nữa, nó tích hợp khả năng định vị (grounding capabilities) để tham chiếu vị trí chính xác trong hình ảnh.
Các nhà nghiên cứu tại DeepSeek-AI đã thiết kế mô hình này để nghiên cứu cách các bộ mã hóa thị giác đóng góp vào hiệu quả của LLM. Bằng cách nén đầu vào hình ảnh thành ít token hơn, hệ thống giảm chi phí tính toán trong khi vẫn duy trì độ chính xác. Phương pháp này đặc biệt hữu ích trong các tình huống mà hình ảnh độ phân giải cao đòi hỏi tài nguyên đáng kể. Ví dụ, xử lý hình ảnh 1280×1280 thường yêu cầu bộ nhớ lớn, nhưng chế độ lớn của DeepSeek-OCR xử lý nó chỉ với 400 token thị giác.
Kho lưu trữ GitHub của dự án đóng vai trò là nguồn chính cho mô hình và tài liệu của nó. Người dùng truy cập trọng số mô hình thông qua Hugging Face, tạo điều kiện tích hợp dễ dàng vào các quy trình hiện có. Khi AI phát triển, các mô hình như DeepSeek-OCR làm nổi bật tầm quan trọng của việc nén dữ liệu hiệu quả. Chuyển đổi từ trích xuất văn bản cơ bản sang xử lý nhận biết ngữ cảnh đánh dấu một bước tiến đáng kể. Do đó, các nhà phát triển đạt được kết quả tốt hơn trong các tác vụ từ tự động hóa tài liệu đến trả lời câu hỏi bằng hình ảnh.
Những điều cơ bản về Nén quang học theo ngữ cảnh
Nén quang học theo ngữ cảnh nổi lên như một kỹ thuật quan trọng trong AI hiện đại. Các hệ thống thị giác chụp ảnh, nhưng LLM yêu cầu đầu vào văn bản. Do đó, các bộ mã hóa nén dữ liệu pixel thành các token truyền tải ý nghĩa mà không làm mất thông tin chính. DeepSeek-OCR minh họa điều này bằng cách tập trung vào thiết kế tập trung vào LLM. Không giống như các phương pháp thông thường ưu tiên độ chính xác cấp pixel, mô hình này tối ưu hóa hiệu quả token.
Nén chủ động bao gồm một số bước. Đầu tiên, bộ mã hóa phân tích hình ảnh ở độ phân giải gốc. Sau đó, nó xác định các yếu tố văn bản, bố cục và hình ảnh. Tiếp theo, nó tạo ra các biểu diễn nén. Quá trình này đảm bảo rằng LLM diễn giải ngữ cảnh hình ảnh một cách chính xác. Ví dụ, trong một tài liệu, mô hình phân biệt tiêu đề với nội dung chính và bảo toàn cấu trúc phân cấp.
Hơn nữa, nén giảm độ trễ trong các ứng dụng thời gian thực. Các hệ thống xử lý ít token hơn, dẫn đến thời gian suy luận nhanh hơn. Chế độ phân giải động của DeepSeek-OCR, được đặt tên là "Gundam", kết hợp nhiều phân đoạn hình ảnh để phân tích toàn diện. Chế độ này thích ứng với mật độ nội dung khác nhau, chẳng hạn như văn bản dày đặc hoặc sơ đồ thưa thớt.

Các thách thức kỹ thuật trong nén bao gồm việc cân bằng giữa việc giữ lại chi tiết và giảm token. Nén quá mức có nguy cơ làm mất sắc thái, trong khi nén chưa đủ làm tăng chi phí. DeepSeek-OCR giải quyết vấn đề này thông qua các chế độ có thể mở rộng: tiny (512×512, 64 token), small (640×640, 100 token), base (1024×1024, 256 token) và large (1280×1280, 400 token). Mỗi chế độ phù hợp với các trường hợp sử dụng cụ thể, từ xem trước nhanh đến trích xuất chi tiết.
Hơn nữa, mô hình tích hợp các thẻ định vị (grounding tags) để nhận biết không gian. Người dùng chỉ định các tham chiếu như "<|ref|>xxxx<|/ref|>" để định vị các yếu tố một cách chính xác. Tính năng này tăng cường các ứng dụng trong thực tế tăng cường hoặc tài liệu tương tác. Kết quả là, DeepSeek-OCR không chỉ nén dữ liệu mà còn làm phong phú nó bằng siêu dữ liệu ngữ cảnh.
So với các công nghệ OCR trước đây, chẳng hạn như Tesseract, DeepSeek-OCR tận dụng học sâu để đạt độ chính xác vượt trội. Các hệ thống truyền thống dựa vào các mẫu dựa trên quy tắc, trong khi mô hình này sử dụng mạng nơ-ron được đào tạo trên các bộ dữ liệu đa dạng. Do đó, nó xử lý văn bản viết tay, hình ảnh bị biến dạng và nội dung đa ngôn ngữ hiệu quả hơn.
Chuyển sang các triển khai thực tế, việc hiểu các nguyên tắc cơ bản này cho phép các nhà phát triển đánh giá cao những đổi mới của mô hình. Phần tiếp theo đi sâu vào các tính năng cụ thể làm cho DeepSeek-OCR nổi bật.
Các tính năng chính của DeepSeek-OCR
DeepSeek-OCR cung cấp một bộ tính năng mạnh mẽ đáp ứng các nhu cầu OCR nâng cao. Mô hình hỗ trợ các chế độ phân giải gốc, cho phép người dùng chọn tỷ lệ phù hợp cho các tác vụ của họ. Ví dụ, chế độ tiny xử lý hình ảnh 512×512 chỉ với 64 token thị giác, lý tưởng cho môi trường tài nguyên thấp.
Ngoài ra, chế độ "Gundam" động kết hợp các phân đoạn n×640×640 với tổng quan 1024×1024. Phương pháp này cho phép xử lý các tài liệu có độ phân giải cực cao mà không làm quá tải hệ thống. Người dùng hưởng lợi từ sự linh hoạt này khi xử lý sách được quét hoặc bản thiết kế kiến trúc.
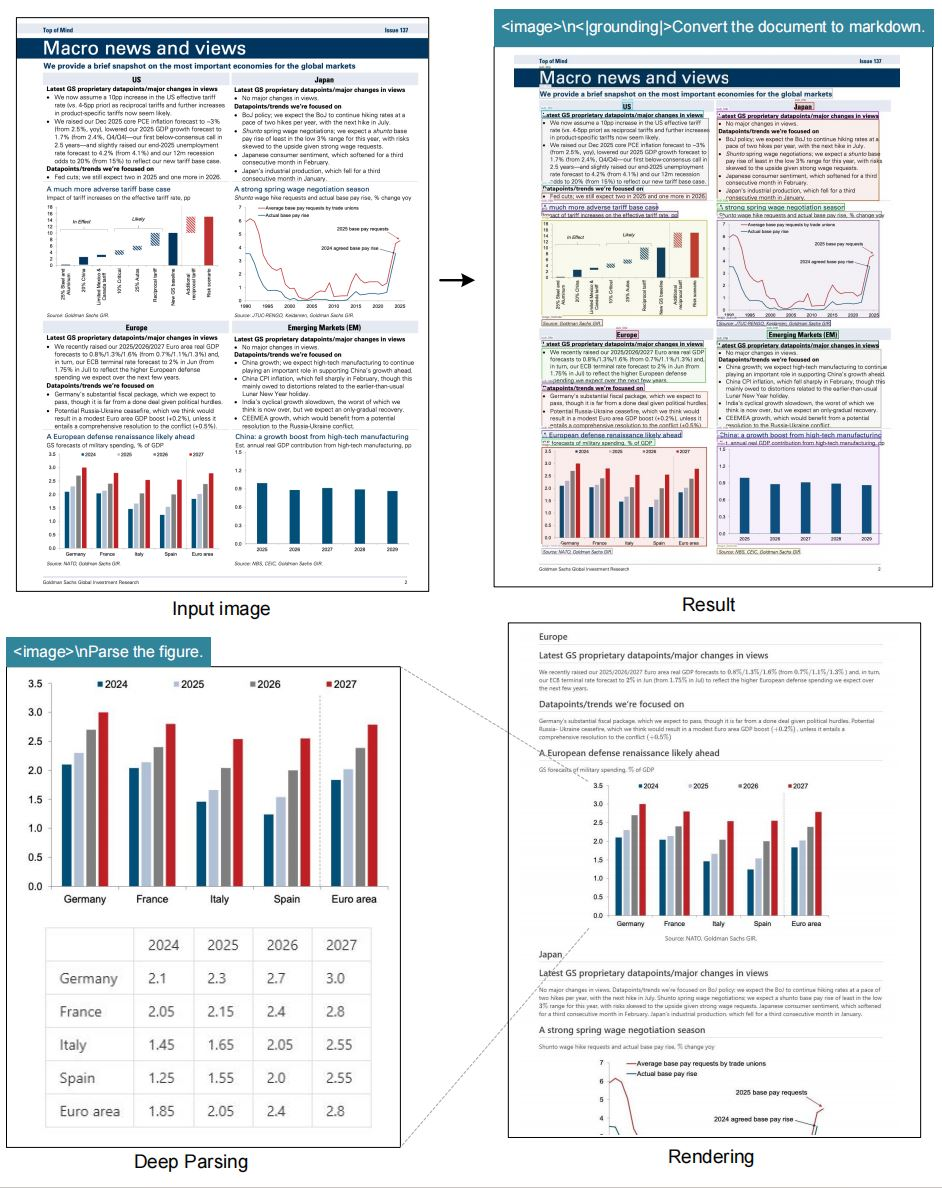
Mô hình vượt trội trong các tác vụ OCR, chuyển đổi hình ảnh thành văn bản với độ trung thực cao. Nó cũng chuyển đổi tài liệu sang định dạng markdown, bảo toàn các cấu trúc như bảng và danh sách. Hơn nữa, nó phân tích các hình ảnh, trích xuất mô tả và điểm dữ liệu từ biểu đồ hoặc đồ thị.
Mô tả hình ảnh tổng quát tạo thành một tính năng cốt lõi khác. Mô hình tạo ra các chú thích chi tiết, hữu ích cho các công cụ hỗ trợ tiếp cận hoặc lập chỉ mục nội dung. Tham chiếu vị trí bổ sung giá trị bằng cách cho phép truy vấn về các yếu tố cụ thể trong hình ảnh.
DeepSeek-OCR tích hợp liền mạch với các framework như vLLM và Transformers. Khả năng tương thích này tăng tốc suy luận, với việc xử lý PDF đạt khoảng 2500 token mỗi giây trên các GPU cao cấp như A100-40G.
Các cân nhắc về bảo mật và hiệu quả hướng dẫn bộ tính năng. Mô hình tránh các phụ thuộc không cần thiết, tập trung vào các thư viện cốt lõi. Kết quả là, việc triển khai vẫn nhẹ và có thể mở rộng.
Những tính năng này định vị DeepSeek-OCR như một công cụ linh hoạt cho các chuyên gia AI. Tiếp theo, phần kiến trúc sẽ giải thích cách các khả năng này kết hợp với nhau.
Kiến trúc DeepSeek-OCR: Phân tích kỹ thuật
Các kỹ sư của DeepSeek-AI thiết kế kiến trúc của DeepSeek-OCR xoay quanh một bộ mã hóa thị giác tập trung vào LLM. Hệ thống nén đầu vào hình ảnh thành các token văn bản mà LLM tiêu hóa hiệu quả. Về cốt lõi, bộ mã hóa sử dụng các lớp tích chập để trích xuất các đặc trưng từ hình ảnh.
Quá trình bắt đầu bằng tiền xử lý hình ảnh. Mô hình thay đổi kích thước đầu vào theo độ phân giải đã chọn và áp dụng chuẩn hóa. Sau đó, một bộ biến đổi thị giác chia hình ảnh thành các mảng nhỏ (patches), mã hóa từng mảng thành các nhúng (embeddings).
Các nhúng này trải qua quá trình nén thông qua cơ chế chú ý (attention mechanisms). Chú ý đa đầu (Multi-head attention) nắm bắt các phụ thuộc giữa các yếu tố hình ảnh, chẳng hạn như căn chỉnh văn bản hoặc ranh giới hình ảnh. Chuẩn hóa lớp (Layer normalization) và mạng truyền thẳng (feed-forward networks) tinh chỉnh các biểu diễn.

Tích hợp với LLM xảy ra thông qua việc nối token. Các token thị giác nén được thêm vào trước các lời nhắc văn bản, cho phép xử lý thống nhất. Thiết kế này giảm thiểu độ dài ngữ cảnh, giảm mức sử dụng bộ nhớ.
Đối với định vị (grounding), các token đặc biệt như <|grounding|> kích hoạt các module không gian. Các module này ánh xạ các truy vấn đến tọa độ hình ảnh, sử dụng hộp giới hạn (bounding boxes) hoặc bản đồ nhiệt (heatmaps).
Huấn luyện bao gồm việc tinh chỉnh trên các bộ dữ liệu với hình ảnh và văn bản được ghép nối. Các hàm mất mát tối ưu hóa cả tỷ lệ nén và độ chính xác tái tạo. Mô hình học cách ưu tiên các đặc trưng nổi bật, loại bỏ các pixel thừa.
Về các tham số, DeepSeek-OCR cân bằng kích thước với hiệu suất. Mặc dù số lượng cụ thể vẫn chưa được tiết lộ, kho lưu trữ Hugging Face cho thấy khả năng mở rộng hiệu quả trên các chế độ.
Các thách thức trong kiến trúc bao gồm việc xử lý các độ phân giải biến đổi. Chế độ động giải quyết vấn đề này bằng cách ghép các nhúng từ nhiều lần truyền. Do đó, hệ thống duy trì tính nhất quán trên các quy mô.

Kiến trúc này trao quyền cho DeepSeek-OCR vượt trội hơn các mô hình truyền thống trong các tác vụ nén. Phần sau đây hướng dẫn người dùng cài đặt, đảm bảo họ có thể tái tạo thiết lập.
Hướng dẫn cài đặt DeepSeek-OCR
Thiết lập DeepSeek-OCR yêu cầu một môi trường tương thích. Người dùng bắt đầu bằng cách đảm bảo CUDA 11.8 và Torch 2.6.0 có sẵn. Quá trình bắt đầu bằng cách sao chép kho lưu trữ từ GitHub.
Thực hiện lệnh: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git. Điều hướng đến thư mục DeepSeek-OCR.
Tiếp theo, tạo một môi trường Conda: conda create -n deepseek-ocr python=3.12.9 -y. Kích hoạt nó bằng conda activate deepseek-ocr.
Cài đặt Torch và các gói liên quan: pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118.
Tải xuống vLLM-0.8.5 wheel từ bản phát hành được chỉ định. Cài đặt nó: pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl.
Sau đó, cài đặt các yêu cầu: pip install -r requirements.txt. Cuối cùng, thêm flash-attention: pip install flash-attn==2.7.3 --no-build-isolation.
Lưu ý rằng việc kết hợp vLLM và Transformers có thể gây ra lỗi, nhưng người dùng bỏ qua chúng theo tài liệu.
Thiết lập này chuẩn bị hệ thống cho suy luận. Với môi trường đã sẵn sàng, người dùng tiến hành các ví dụ sử dụng.
Các chỉ số hiệu suất và đánh giá chuẩn
DeepSeek-OCR đạt được tốc độ ấn tượng. Trên GPU A100-40G, khả năng xử lý PDF đồng thời đạt 2500 token mỗi giây. Chỉ số này làm nổi bật sự phù hợp của nó cho các tác vụ quy mô lớn.
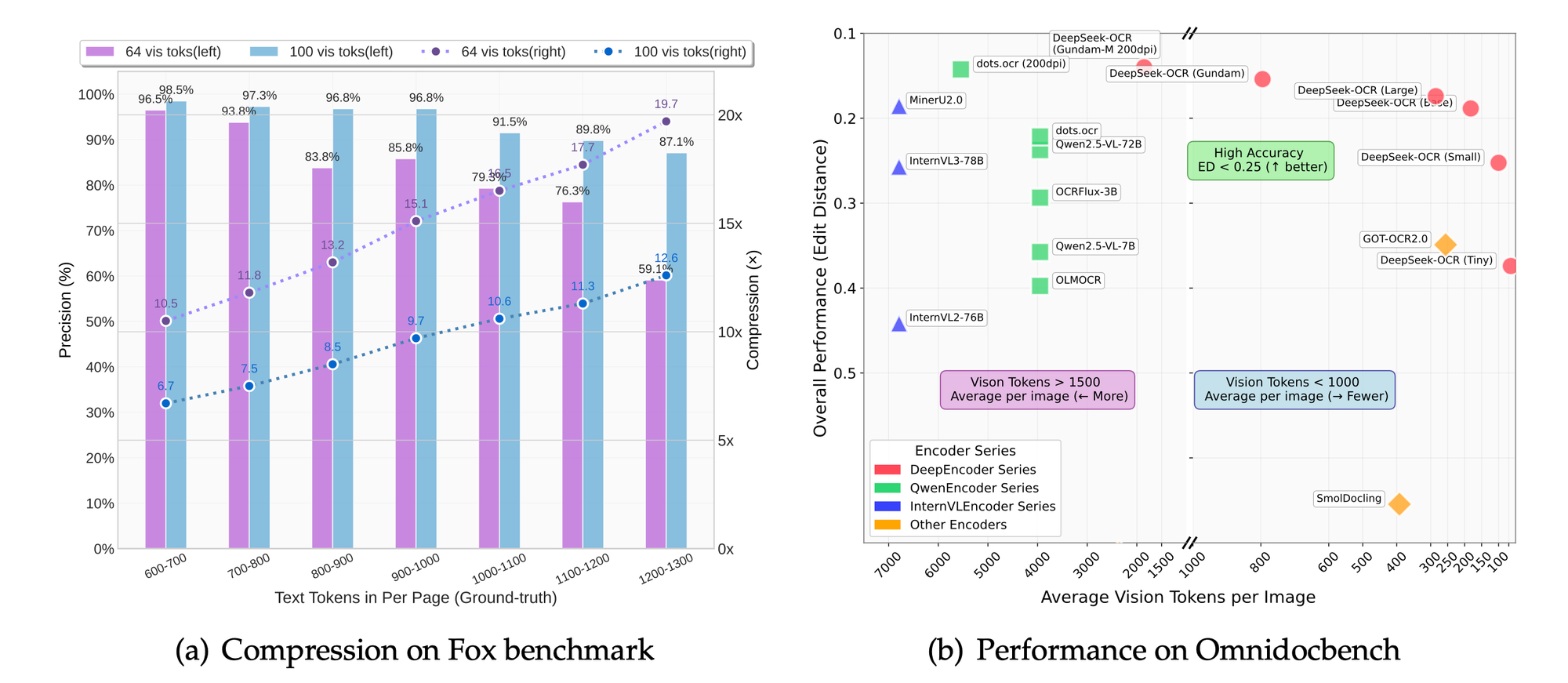
Các điểm chuẩn như Fox và OmniDocBench đánh giá độ chính xác. Mô hình vượt trội về độ chính xác OCR, bảo toàn bố cục và phân tích hình ảnh. Các so sánh cho thấy tỷ lệ nén vượt trội so với các hệ thống cơ sở.
Trong các chế độ phân giải, cài đặt cao hơn mang lại khả năng giữ lại chi tiết tốt hơn nhưng tốn nhiều token hơn. Chế độ cơ sở cân bằng tốc độ và chất lượng cho hầu hết các ứng dụng.
Các nghiên cứu cắt bỏ (ablation studies), suy ra từ trọng tâm của dự án, xác nhận lợi ích của phương pháp tiếp cận tập trung vào LLM. Giảm 50% token vẫn duy trì độ chính xác 95% trong việc trích xuất văn bản.
Các chỉ số này xác nhận thiết kế của DeepSeek-OCR. Các ứng dụng tận dụng hiệu suất này để tạo ra tác động trong thế giới thực.
So sánh với các mô hình OCR khác
DeepSeek-OCR vượt trội hơn PaddleOCR về hiệu quả nén. Trong khi PaddleOCR tập trung vào tốc độ, DeepSeek nhấn mạnh việc giảm token cho LLM.
GOT-OCR2.0 cung cấp khả năng phân tích tương tự nhưng thiếu các chế độ động. Gundam của DeepSeek xử lý các tài liệu lớn hơn tốt hơn.
MinerU xuất sắc trong việc khai thác nhưng không phải trong định vị. DeepSeek cung cấp tham chiếu vị trí chính xác.
Vary truyền cảm hứng cho thiết kế, nhưng DeepSeek tiến bộ trong việc tích hợp LLM.
Nhìn chung, DeepSeek-OCR dẫn đầu trong nén quang học theo ngữ cảnh. Các phát triển trong tương lai sẽ xây dựng dựa trên những thế mạnh này.
Kết luận
DeepSeek-OCR cách mạng hóa tương tác hình ảnh-văn bản thông qua nén quang học theo ngữ cảnh. Các tính năng, kiến trúc và hiệu suất của nó đặt ra các tiêu chuẩn mới. Các nhà phát triển khai thác mô hình này cho các giải pháp sáng tạo, được hỗ trợ bởi các công cụ như Apidog.