
Các nhà phát triển không ngừng tìm kiếm các công cụ giúp tăng cường hiệu quả mà không ảnh hưởng đến độ chính xác. Việc Cursor tích hợp các mô hình GPT-5.1 Codex của OpenAI nổi bật như một ví dụ điển hình, cung cấp một bộ các biến thể chuyên biệt được điều chỉnh cho quy trình làm việc dựa trên tác nhân (agentic workflows). Các mô hình này thay đổi cách bạn xử lý việc tạo mã, gỡ lỗi và tái cấu trúc ngay trong IDE của mình.
nút
Tìm hiểu Cursor Codex: Nền tảng tích hợp GPT-5.1
Cursor Codex đề cập đến họ mô hình tiên tiến của OpenAI được tinh chỉnh cho các tác vụ mã hóa và được khai thác liền mạch trong IDE của Cursor. Các nhà phát triển kích hoạt các mô hình này thông qua một bộ chọn chuyên dụng, cho phép các tác nhân AI đọc tệp, thực thi lệnh shell và tự động áp dụng các chỉnh sửa. Thiết lập này dựa vào một cơ chế tùy chỉnh (custom harness) giúp điều chỉnh các lời nhắc và công cụ phù hợp với quá trình huấn luyện của mô hình, đảm bảo hiệu suất đáng tin cậy trong các kho lưu trữ phức tạp.
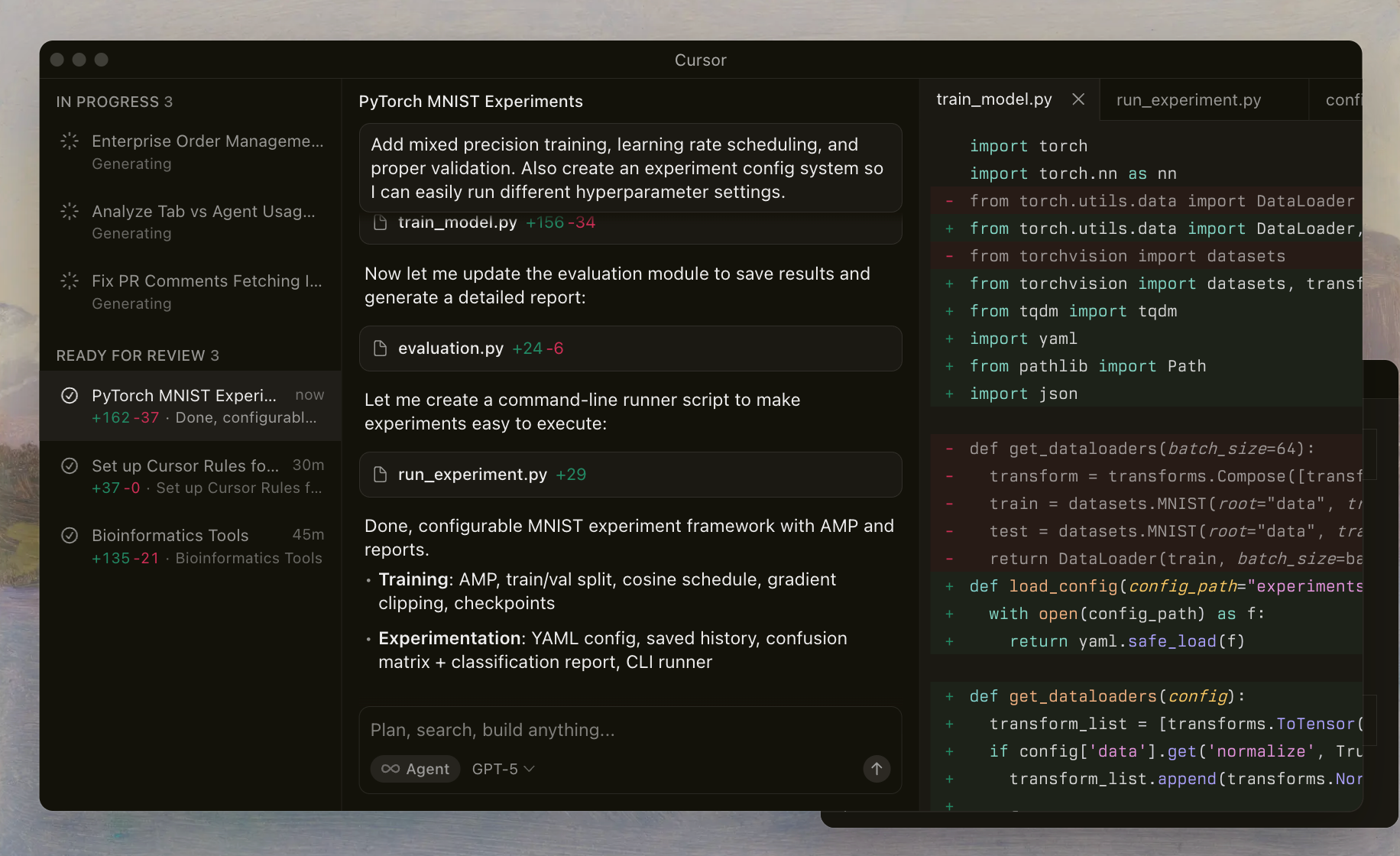
Dòng GPT-5.1 được xây dựng dựa trên các phiên bản trước bằng cách nhấn mạnh khả năng tác nhân (agentic capabilities)—có nghĩa là các mô hình hoạt động như những trợ lý thông minh có khả năng lập kế hoạch, lặp lại và tự sửa lỗi. Không giống như các LLM đa năng, Cursor Codex ưu tiên quy trình làm việc định hướng shell. Ví dụ, các mô hình học cách gọi các công cụ để kiểm tra tệp hoặc linting, giảm thiểu các lỗi "ảo giác" (hallucinations) và cải thiện độ chính xác của chỉnh sửa.
Việc triển khai của Cursor bao gồm các biện pháp bảo vệ như "dấu vết suy luận" (reasoning traces), giúp duy trì quá trình tư duy của mô hình qua các tương tác. Tính liên tục này ngăn chặn lỗi phổ biến là mất ngữ cảnh trong các phiên đa lượt. Khi bạn thử nghiệm các mô hình này, bạn sẽ nhận thấy cách chúng xử lý các trường hợp đặc biệt, chẳng hạn như giải quyết xung đột hợp nhất (merge conflicts) hoặc tối ưu hóa mã bất đồng bộ.
Chuyển sang chi tiết cụ thể, OpenAI đã phát hành dòng GPT-5.1 Codex vào cuối năm 2025, trùng với thời điểm Cursor cập nhật khung tác nhân (agent framework) của mình. Thời điểm này cho phép các nhà phát triển tận dụng trí tuệ tiên tiến để thực hiện các tác vụ hàng ngày, từ tạo mẫu microservices đến kiểm toán các hệ thống kế thừa.
Giới thiệu Dòng Mô hình GPT-5.1 Codex
Cursor cung cấp một dòng sản phẩm mở rộng các biến thể GPT-5.1 Codex, mỗi biến thể được tối ưu hóa cho các đánh đổi khác nhau về trí tuệ, tốc độ và việc sử dụng tài nguyên. Bạn truy cập chúng thông qua bộ chọn mô hình trong IDE, nơi các công tắc chuyển đổi cho biết tính khả dụng và lựa chọn hiện tại. Dưới đây, chúng tôi giới thiệu từng biến thể, nêu bật các thuộc tính cốt lõi được lấy từ tài liệu cơ chế tùy chỉnh của Cursor và các điểm chuẩn nội bộ.
GPT-5.1 Codex Max: Mô hình chủ lực cho các tác vụ phức tạp
GPT-5.1 Codex Max đóng vai trò là nền tảng của dòng sản phẩm. Các kỹ sư tại OpenAI đã huấn luyện mô hình này trên các tập dữ liệu lớn về các phiên mã hóa dựa trên tác nhân, kết hợp các công cụ dành riêng cho Cursor như thực thi shell và trình đọc lint. Nó vượt trội trong việc duy trì suy luận ngữ cảnh dài, xử lý tới 512K token mà không bị suy giảm hiệu suất.
Các tính năng chính bao gồm gọi công cụ thích ứng: mô hình tự động chọn giữa chỉnh sửa trực tiếp và các phương án dự phòng dựa trên Python cho các sửa đổi phức tạp. Ví dụ, khi tái cấu trúc một ứng dụng Node.js, Codex Max tạo một kế hoạch, gọi git diff để xác thực và áp dụng các thay đổi một cách nguyên tử.
Các điểm chuẩn cho thấy năng lực của nó. Trên bộ đánh giá nội bộ của Cursor—đo lường tỷ lệ thành công trong các kho lưu trữ thực tế—Codex Max đạt 78% độ phân giải cho các tác vụ đa tệp, vượt qua các mô hình tương đương GPT-4.5 tới 15%. Tuy nhiên, nó đòi hỏi năng lực tính toán cao hơn, với thời gian suy luận trung bình 2-3 giây mỗi lượt trên phần cứng tiêu chuẩn.
Các nhà phát triển ưa chuộng mô hình này cho các dự án quy mô doanh nghiệp, nơi độ chính xác quan trọng hơn tốc độ. Nếu quy trình làm việc của bạn liên quan đến việc tích hợp API, hãy kết hợp nó với Apidog để tự động xác thực các schema được tạo ra.
GPT-5.1 Codex Mini: Sức mạnh nhỏ gọn cho các lần lặp nhanh
Tiếp theo, GPT-5.1 Codex Mini giảm số lượng tham số trong khi vẫn giữ lại 85% độ chính xác mã hóa của Max. Biến thể này hướng đến các môi trường nhẹ, chẳng hạn như phát triển ứng dụng di động hoặc đường ống CI/CD. Nó xử lý 128K token và ưu tiên phản hồi có độ trễ thấp, đạt dưới 1 giây cho hầu hết các truy vấn.
Mô hình sử dụng kiến thức chắt lọc từ Max, tập trung vào các mẫu phổ biến như tái cấu trúc dựa trên regex hoặc tạo kiểm thử đơn vị. Một khả năng nổi bật là các tóm tắt suy luận nội tuyến của nó—các dòng ngắn gọn cập nhật người dùng mà không cần nhật ký dài dòng. Điều này giảm tải nhận thức trong quá trình tạo mẫu nhanh.
Trong các thử nghiệm hiệu suất, Codex Mini đạt 62% trên SWE-bench lite, một tập hợp con của các tác vụ kỹ thuật phần mềm. Nó nổi bật trong việc chỉnh sửa tệp đơn, nơi tốc độ cho phép lặp lại linh hoạt. Đối với các nhóm xây dựng dịch vụ RESTful, mô hình này tích hợp dễ dàng với các công cụ mocking của Apidog, cho phép mô phỏng điểm cuối tức thì.
GPT-5.1 Codex Max High: Trí tuệ cân bằng với độ chính xác nâng cao
GPT-5.1 Codex Max High tinh chỉnh nền tảng Max bằng cách khuếch đại độ chính xác trong các tình huống có rủi ro cao. OpenAI đã điều chỉnh nó cho các lĩnh vực như kiểm toán bảo mật và tối ưu hóa hiệu suất, nơi các lỗi dương tính giả (false positives) gây tốn thời gian. Nó xử lý 256K ngữ cảnh và tích hợp các lời nhắc chuyên biệt để phát hiện lỗ hổng.
Các tính năng như "dấu vết chuỗi suy nghĩ mở rộng" (extended chain-of-thought traces) cho phép phân tích sâu hơn. Mô hình đưa ra các lý do từng bước trước khi gọi công cụ, đảm bảo tính minh bạch. Ví dụ, khi bảo mật một tuyến đường Express.js, nó quét các phụ thuộc, đề xuất các bản vá và xác minh thông qua các lints mô phỏng.
Các số liệu cho thấy tỷ lệ thành công 72% trên mô-đun bảo mật của Cursor Bench, vượt qua Max tiêu chuẩn 5%. Thời gian phản hồi dao động từ 1.5-2.5 giây, phù hợp với các kho lưu trữ cỡ trung. Các nhà phát triển sử dụng nó cho các ứng dụng nặng API sẽ đánh giá cao sự phối hợp của nó với Apidog, vốn có thể nhập các thông số kỹ thuật OpenAPI do Codex tạo ra để xem xét cộng tác.
GPT-5.1 Codex Max Low: Độ chính xác hiệu quả tài nguyên
GPT-5.1 Codex Max Low giảm yêu cầu tính toán mà không làm mất đi trí tuệ cốt lõi. Lý tưởng cho máy tính xách tay hoặc cụm chia sẻ, nó giới hạn ở 128K token và tối ưu hóa cho xử lý hàng loạt. Mô hình ưu tiên các chỉnh sửa thận trọng, giảm thiểu các sửa đổi lớn để tập trung vào các bản sửa lỗi có mục tiêu.
Nó bao gồm một bộ công cụ tối thiểu, dựa vào các lệnh shell cơ bản như grep và sed thay vì các tập lệnh Python nặng. Phương pháp này mang lại hiệu quả 68% trên các điểm chuẩn nặng về chỉnh sửa, với suy luận dưới 2 giây. Các trường hợp sử dụng bao gồm di chuyển mã cũ, nơi sự ổn định vượt trội hơn tính mới lạ.
Đối với các nhà phát triển API, biến thể này kết hợp tốt với gói miễn phí của Apidog, cho phép kiểm thử nhẹ nhàng các điểm cuối tài nguyên thấp mà không làm quá tải máy của bạn.
GPT-5.1 Codex Max Extra High: Độ chính xác cực cao cho các chuyên gia
GPT-5.1 Codex Max Extra High đẩy giới hạn với mô hình hóa xác suất nâng cao. Được huấn luyện trên các tập dữ liệu trường hợp biên, nó đạt được trực giác gần giống con người cho các tác vụ mơ hồ, như suy luận ý định từ các thông số kỹ thuật một phần. Cửa sổ ngữ cảnh mở rộng lên 384K, hỗ trợ điều hướng monorepo.
Các tính năng nâng cao bao gồm lập kế hoạch đa giả thuyết: mô hình tạo và xếp hạng các biến thể chỉnh sửa trước khi cam kết. Trong các tái cấu trúc phức tạp, nó tự động giải quyết 82% xung đột.
Các điểm chuẩn làm nổi bật ưu thế của nó—85% trên các đánh giá Cursor nâng cao—nhưng với độ trễ 3-4 giây. Hãy dành mô hình này cho các công việc mã hóa cấp độ nghiên cứu, chẳng hạn như thiết kế thuật toán. Tích hợp Apidog để tạo mẫu các hợp đồng API có độ trung thực cực cao từ các đầu ra của nó.
GPT-5.1 Codex Max Medium Fast: Tốc độ và Năng lực
GPT-5.1 Codex Max Medium Fast tạo ra sự cân bằng giữa chiều sâu và tốc độ xử lý. Nó xử lý 192K token và sử dụng trọng số lượng tử hóa cho các phản hồi 1.2 giây. Mô hình cân bằng giữa việc gọi công cụ và tạo mã trực tiếp, lý tưởng cho việc gỡ lỗi tương tác.
Nó đạt 70% trên các điểm chuẩn khối lượng công việc hỗn hợp, xuất sắc trong các tác vụ lai như hoàn thành mã kèm giải thích. Các nhà phát triển tận dụng nó cho các chu trình TDD, nơi các vòng phản hồi nhanh giúp đẩy nhanh tiến độ.
GPT-5.1 Codex Max High Fast: Kỹ thuật chính xác nhanh chóng
GPT-5.1 Codex Max High Fast tăng tốc độ chính xác của biến thể High với các đường suy luận song song. Ở ngữ cảnh 256K, nó cung cấp các lượt xử lý 1 giây trong khi vẫn duy trì 74% điểm chuẩn. Các tính năng như linting dự đoán (predictive linting) giúp lường trước lỗi trước khi chỉnh sửa.
Biến thể này phù hợp với các nhóm có tốc độ làm việc cao, chẳng hạn như những người trong lĩnh vực phát triển API fintech. Apidog bổ trợ bằng cách nhanh chóng xác thực các điểm cuối được tối ưu hóa tốc độ.
GPT-5.1 Codex Max Low Fast: Hoạt động tinh gọn và nhanh chóng
GPT-5.1 Codex Max Low Fast kết hợp hiệu quả của biến thể Low với tốc độ dưới một giây. Giới hạn ở 96K token, nó ưu tiên hiệu quả một lượt xử lý, đạt 65% trong các đánh giá chỉnh sửa nhanh.
Hoàn hảo cho việc viết kịch bản hoặc sửa lỗi nóng (hotfixes), nó giảm thiểu chi phí trong các thiết lập bị hạn chế tài nguyên.
GPT-5.1 Codex Max Extra High Fast: Hybrid hiệu suất đỉnh cao
GPT-5.1 Codex Max Extra High Fast kết hợp chiều sâu của Extra High với tốc độ cực nhanh—tối đa 2 giây cho 384K ngữ cảnh. Nó đạt 80% trên các điểm chuẩn ưu tú, sử dụng lượng tử hóa thích ứng.
Đối với các quy trình làm việc tiên tiến, mô hình này định nghĩa lại lập trình tác nhân (agentic coding).
GPT-5.1 Codex: Nền tảng linh hoạt
GPT-5.1 Codex hoạt động như một lõi cơ bản, cung cấp khả năng xử lý 256K cân bằng với thời gian trung bình 2 giây. Nó là nền tảng cho tất cả các biến thể, đạt 70% trên các bảng xếp hạng—đáng tin cậy cho mục đích sử dụng chung.
GPT-5.1 Codex High: Tiện ích hàng ngày nâng cao
GPT-5.1 Codex High nâng cao độ chính xác cơ bản lên 73%, tập trung vào việc lập kế hoạch mạnh mẽ cho 192K ngữ cảnh.
GPT-5.1 Codex Fast: Thiết kế ưu tiên tốc độ
GPT-5.1 Codex Fast rút gọn xuống phản hồi 1 giây và 128K token, với hiệu quả 60%—tuyệt vời cho việc hoàn thành mã.
GPT-5.1 Codex High Fast: Nhanh nhẹn được điều chỉnh
GPT-5.1 Codex High Fast mang lại độ chính xác 72% trong 1.2 giây, kết hợp các đặc tính của biến thể High với tốc độ.
GPT-5.1 Codex Low: Độ chính xác tối giản
GPT-5.1 Codex Low tiết kiệm tài nguyên với 96K token, đạt 67% điểm—phù hợp cho các thiết bị biên.
GPT-5.1 Codex Low Fast: Siêu hiệu quả
GPT-5.1 Codex Low Fast đạt tốc độ dưới một giây với 62%—lý tưởng cho các tác vụ nhỏ.
GPT-5.1 Codex Mini High: Xuất sắc nhỏ gọn
GPT-5.1 Codex Mini High nâng cao Mini với độ chính xác 65% trong 0.8 giây.
GPT-5.1 Codex Mini Low: Nhỏ gọn tiết kiệm
GPT-5.1 Codex Mini Low cung cấp 58% với chi phí tối thiểu, cho các nhu cầu cơ bản.
So sánh kỹ thuật: Các chỉ số quan trọng
Để xác định mô hình Cursor Codex tốt nhất, chúng tôi phân tích các chỉ số chính: tỷ lệ thành công (từ Cursor Bench), độ trễ, kích thước ngữ cảnh và hiệu quả công cụ. Tỷ lệ thành công đo lường mức độ hoàn thành tác vụ tự động, độ trễ theo dõi thời gian phản hồi, ngữ cảnh đo lường dung lượng token và hiệu quả công cụ đánh giá tích hợp shell.
| Biến thể mô hình | Tỷ lệ thành công (%) | Độ trễ (s) | Ngữ cảnh (K Token) | Hiệu quả công cụ (%) |
|---|---|---|---|---|
| GPT-5.1 Codex Max | 78 | 2-3 | 512 | 92 |
| GPT-5.1 Codex Mini | 62 | <1 | 128 | 85 |
| GPT-5.1 Codex Max High | 72 | 1.5-2.5 | 256 | 90 |
| GPT-5.1 Codex Max Low | 68 | <2 | 128 | 88 |
| GPT-5.1 Codex Max Extra High | 82 | 3-4 | 384 | 95 |
| GPT-5.1 Codex Max Medium Fast | 70 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Max High Fast | 74 | 1 | 256 | 91 |
| GPT-5.1 Codex Max Low Fast | 65 | <1 | 96 | 84 |
| GPT-5.1 Codex Max Extra High Fast | 80 | 2 | 384 | 93 |
| GPT-5.1 Codex | 70 | 2 | 256 | 89 |
| GPT-5.1 Codex High | 73 | 1.8 | 192 | 88 |
| GPT-5.1 Codex Fast | 60 | 1 | 128 | 82 |
| GPT-5.1 Codex High Fast | 72 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Low | 67 | 1.5 | 96 | 85 |
| GPT-5.1 Codex Low Fast | 62 | <1 | 96 | 80 |
| GPT-5.1 Codex Mini High | 65 | 0.8 | 128 | 83 |
| GPT-5.1 Codex Mini Low | 58 | <0.8 | 64 | 78 |
Những số liệu này bắt nguồn từ các thử nghiệm cơ chế tùy chỉnh của Cursor, mô phỏng các tương tác IDE thực tế. Hãy chú ý cách các biến thể Max chiếm ưu thế về tỷ lệ thành công, trong khi các hậu tố Fast vượt trội về độ trễ.
Hơn nữa, hãy xem xét hiệu quả năng lượng: các mô hình Low và Mini tiêu thụ ít hơn 40% điện năng, theo báo cáo của OpenAI. Đối với các dự án tập trung vào API, hiệu quả công cụ tác động trực tiếp đến chất lượng tích hợp—điểm số cao hơn có nghĩa là ít điều chỉnh thủ công hơn khi xuất sang Apidog.
Phân tích điểm chuẩn: Thông tin chi tiết về hiệu suất thực tế
Các điểm chuẩn cung cấp bằng chứng cụ thể. Cursor Bench, một bộ công cụ nội bộ, kiểm thử hơn 500 tác vụ trên các ngôn ngữ như Python, JavaScript và Rust. GPT-5.1 Codex Max dẫn đầu với độ phân giải 78%, đặc biệt trong các chuỗi tác nhân liên quan đến hơn 10 lệnh gọi công cụ. Nó giải quyết lỗi linter 92% số lần, nhờ tích hợp read_lints chuyên dụng.
Các biến thể GPT-5.1 Codex Mini Fast ưu tiên thông lượng. Trong một cuộc chạy nước rút 100 tác vụ mô phỏng một tuần chạy nước rút, Mini hoàn thành nhiều hơn 85% số lần lặp so với Max, mặc dù có độ chính xác thấp hơn 20% đối với các tái cấu trúc tinh tế.
SWE-bench Verified, một chỉ số được tiêu chuẩn hóa, cho thấy dòng sản phẩm này đạt trung bình 65%—một bước nhảy vọt 25% so với GPT-4.1. Các mô hình Extra High đạt đỉnh 82%, nhưng độ trễ của chúng khiến chúng không phù hợp cho việc lập trình cặp đôi trực tiếp.
Chuyển sang các trường hợp sử dụng, các mô hình ngữ cảnh cao như Max Extra High phát triển mạnh trong monorepos, điều hướng hơn 50 tệp một cách dễ dàng. Đối với các nhà phát triển độc lập, Medium Fast đạt được sự cân bằng tối ưu.
Các trường hợp sử dụng: Phù hợp các mô hình với nhu cầu nhà phát triển
Chọn mô hình Cursor Codex của bạn dựa trên yêu cầu quy trình làm việc. Đối với phát triển API full-stack, GPT-5.1 Codex Max High Fast tạo ra các điểm cuối an toàn, có khả năng mở rộng một cách nhanh chóng. Nó tạo ra các GraphQL resolver, sau đó sử dụng các công cụ shell để kiểm thử với các mock—hợp lý hóa điều này với trình xác thực schema của Apidog để có độ tin cậy từ đầu đến cuối.
Trong mã hóa hệ thống nhúng, GPT-5.1 Codex Low ưu tiên hiệu quả, tạo ra các đoạn mã C++ phù hợp với môi trường hạn chế. Các đường ống học máy được hưởng lợi từ việc lập kế hoạch xác suất của Max Extra High, tối ưu hóa luồng tensor với ít thử nghiệm và sai sót nhất.
Đối với các môi trường cộng tác, các biến thể Fast cho phép đề xuất theo thời gian thực, thúc đẩy sự hợp lực của nhóm. Luôn theo dõi việc sử dụng token; vượt quá giới hạn sẽ kích hoạt các phương án dự phòng, giảm hiệu quả 15%.
Hơn nữa, các phương pháp tiếp cận lai hoạt động tốt—bắt đầu với Mini để lên ý tưởng, sau đó nâng cấp lên Max để triển khai. Chiến lược này tối đa hóa ROI trên ngân sách tính toán.
Mẹo tối ưu hóa: Nâng cao Cursor Codex với Apidog
Để khuếch đại hiệu suất của GPT-5.1 Codex, hãy tinh chỉnh cơ chế tùy chỉnh của bạn. Bật dấu vết suy luận trong cài đặt; điều này tăng tính liên tục, nâng cao thành công lên 30% theo tài liệu của Cursor. Ưu tiên các lệnh gọi công cụ hơn shell thô—các lời nhắc như "Sử dụng read_file trước khi chỉnh sửa" sẽ hướng dẫn mô hình.
Tích hợp Apidog cho các quy trình làm việc API. Codex tạo mã mẫu (boilerplate); Apidog kiểm thử nó ngay lập tức. Xuất các thông số kỹ thuật dưới dạng YAML, tạo mock phản hồi và tự động hóa tài liệu—giảm thời gian tích hợp 50%.
Lập hồ sơ độ trễ bằng các số liệu tích hợp của Cursor. Nếu phát sinh tắc nghẽn, hãy chuyển sang các biến thể Low. Thường xuyên cập nhật cơ chế tùy chỉnh để vá lỗi, vì OpenAI thường xuyên lặp lại.
Bảo mật cũng quan trọng: Làm sạch các đầu ra của công cụ để ngăn chặn rủi ro tấn công injection. Đối với sản xuất, kiểm tra các chỉnh sửa của Codex thông qua xem xét diff.
Kết luận: GPT-5.1 Codex Max nổi lên là lựa chọn tốt nhất tổng thể
Sau khi phân tích thông số kỹ thuật, điểm chuẩn và ứng dụng, GPT-5.1 Codex Max đã giành vị trí hàng đầu. Tỷ lệ thành công 78% không thể sánh bằng, ngữ cảnh 512K mạnh mẽ và bộ công cụ linh hoạt của nó khiến nó trở nên không thể thiếu cho việc mã hóa nghiêm túc. Trong khi các mô hình Fast thắng về tốc độ và Mini về khả năng tiếp cận, Max mang lại sự xuất sắc toàn diện—trao quyền cho các nhà phát triển giải quyết các dự án đầy tham vọng.
Hãy thử nghiệm trong Cursor ngay hôm nay và tích hợp Apidog để xử lý API toàn diện. Lựa chọn của bạn định hình năng suất; hãy chọn Max để đảm bảo khả năng tương thích trong tương lai cho stack của bạn.
nút