Yapay zeka hızla gelişmeye devam ediyor ve geliştiriciler artık gelişmiş muhakeme yetenekleri sunan araçlar talep ediyor. NVIDIA, bu ihtiyacı NVIDIA Llama Nemotron model ailesiyle karşılıyor. Bu modeller, karmaşık muhakeme gerektiren görevlerde mükemmel sonuçlar verir, hesaplama verimliliği sunar ve kurumsal kullanım için açık bir lisansa sahiptir. Geliştiriciler, bu modellere NVIDIA’nın NIM mikro hizmetleri aracılığıyla sağlanan NVIDIA Llama Nemotron API'si aracılığıyla erişebilir ve uygulamalara entegrasyonu sorunsuz hale getirebilir.
NVIDIA Llama Nemotron Modellerini Anlamak
API'ye dalmadan önce, NVIDIA Llama Nemotron modellerini inceleyelim. Bu aile üç varyant içerir: Nano, Super ve Ultra. Her biri, performans ve kaynak taleplerini dengeleyerek belirli dağıtım ihtiyaçlarını hedefler.
- Nano (8B parametre): Mühendisler bu modeli uç cihazlar ve PC'ler için optimize eder. Minimum hesaplama gücüyle yüksek doğruluk sağlar ve bu da onu hafif uygulamalar için ideal hale getirir.
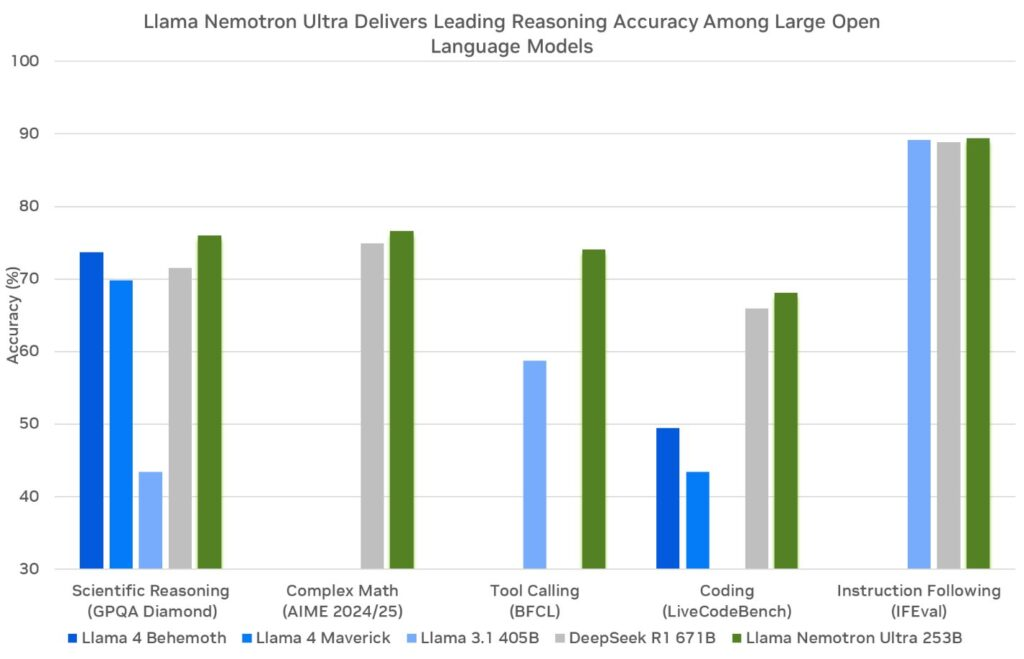
- Super (49B parametre): Geliştiriciler bu modeli tek GPU kurulumları için tasarlar. Orta derecede karmaşık görevler için uygun, verim ve doğruluk arasında bir denge kurar.
- Ultra (253B parametre): Uzmanlar bu modeli çoklu GPU veri merkezi sunucuları için hazırlar. En zorlu yapay zeka aracı uygulamaları için en üst düzeyde doğruluk sağlar.
NVIDIA, bu modelleri Meta'nın Llama çerçevesi üzerine inşa ederek, bunları damıtma ve takviyeli öğrenme gibi eğitim sonrası tekniklerle geliştirir. Sonuç olarak, bilimsel analiz, ileri matematik, kodlama ve talimat takibi gibi muhakeme görevlerinde mükemmel sonuçlar verirler. Her model, 128.000 token'lık bir bağlam uzunluğunu destekler ve uzun belgeleri işlemelerine veya uzun etkileşimlerde bağlamı korumalarına olanak tanır.
Öne çıkan bir özellik, sistem istemi aracılığıyla muhakemeyi açma veya kapatma yeteneğidir. Geliştiriciler, sorun giderme gibi karmaşık sorgular için muhakemeyi etkinleştirir ve statik bilgileri alma gibi basit görevler için devre dışı bırakır. Bu esneklik, gerçek dünya uygulamalarında kritik bir avantaj olan kaynak kullanımını optimize eder.
NVIDIA Llama Nemotron API'sini Kurma
NVIDIA Llama Nemotron API'sinden yararlanmak için önce onu kurmanız gerekir. NVIDIA, bu API'yi bulut, şirket içi veya uç ortamlarda dağıtımı destekleyen NIM mikro hizmetleri aracılığıyla sunar. Başlamak için şu adımları izleyin:
NVIDIA Geliştirici Programına Katılın: Kaynaklara, belgelere ve araçlara erişmek için kaydolun. Bu adım, ihtiyacınız olan ekosistemin kilidini açar.
API Kimlik Bilgilerini Edinin: NVIDIA, API anahtarları sağlar. İsteklerinizi güvenli bir şekilde doğrulamak için bunları kullanın.
Gerekli Kütüphaneleri Yükleyin: Python geliştiricileri için, HTTP çağrılarını işlemek üzere requests kütüphanesini yükleyin. Terminalinizde bu komutu çalıştırın:
pip install requests
Bu adımlar tamamlandığında, ortamınızı NVIDIA Llama Nemotron API'si ile etkileşim kurmaya hazırlarsınız. Ardından, isteklerin nasıl yapılacağını inceleyeceğiz.
API İstekleri Yapma
NVIDIA Llama Nemotron API'si, projelerinize entegrasyonu basitleştiren RESTful standartlarına uyar. İstek gövdesine parametreler yerleştirerek API uç noktasına POST istekleri gönderirsiniz. Bunu pratik bir örnekle inceleyelim.
İşte API'yi Python kullanarak nasıl sorgulayacağınız:
import requests
import json
# API uç noktasını ve kimlik doğrulamasını tanımlayın
endpoint = "https://your-nim-endpoint.com/api/v1/generate"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# İstek yükünü oluşturun
payload = {
"model": "llama-nemotron-super",
"prompt": "How many R's are in the word 'strawberry'?",
"max_tokens": 100,
"temperature": 0.7,
"reasoning": "on"
}
# İsteği gönderin
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# Yanıtı işleyin
if response.status_code == 200:
result = response.json()
print(result["text"])
else:
print(f"Error: {response.status_code} - {response.text}")
Temel Parametreler Açıklandı
model: Model varyantını belirtir—Nano, Super veya Ultra. Dağıtımınıza göre seçin.prompt: Modelin işlemesi için girdi metnini sağlar.max_tokens: Yanıt uzunluğunu token cinsinden sınırlar. Çıktı boyutunu kontrol etmek için bunu ayarlayın.temperature: 0 ile 1 arasında değişir. Daha düşük değerler (örneğin, 0,5) tahmin edilebilir çıktılar verirken, daha yüksek değerler (örneğin, 0,9) yaratıcılığı artırır.reasoning: Muhakeme yeteneklerini açar veya kapatır. Karmaşık görevler için "on" ve basit görevler için "off" olarak ayarlayın.
Örneğin, muhakemeyi etkinleştirmek matematik problemlerini çözmek gibi görevlere uygundur, devre dışı bırakmak ise temel aramalar için işe yarar. Ayrıca, çeşitlilik kontrolü için top_p veya "\n\n" gibi belirli token'larda üretimi durdurmak için stop_sequences gibi parametreler de ekleyebilirsiniz.
İşte genişletilmiş bir örnek:
payload = {
"model": "llama-nemotron-super",
"prompt": "Explain recursion in programming.",
"max_tokens": 200,
"temperature": 0.6,
"top_p": 0.9,
"reasoning": "on",
"stop_sequences": ["\n\n"]
}
Bu istek, özyinelemenin ayrıntılı bir açıklamasını oluşturur ve çift satır başı karakterinde durur. Apidog gibi araçlar, bu istekleri verimli bir şekilde test etmenize ve iyileştirmenize yardımcı olur.
API Yanıtlarını İşleme
Bir istek gönderdikten sonra, NVIDIA Llama Nemotron API'si bir JSON yanıtı döndürür. Bu, oluşturulan metni ve meta verileri içerir. İşte örnek bir yanıt:
{
"text": "There are three R's in the word 'strawberry'.",
"tokens_generated": 10,
"time_taken": 0.5
}
text: Modelin çıktısını içerir.tokens_generated: Üretilen token sayısını gösterir.time_taken: Üretim süresini saniye cinsinden ölçer.
Her zaman durum kodunu doğrulayın. 200 kodu başarıyı işaret eder ve JSON'u ayrıştırmanıza olanak tanır. Hatalar, hata ayıklama için yanıt gövdesinde ayrıntılarla birlikte 400 veya 500 gibi kodlar döndürür. Üretimde sağlamlığı sağlamak için yeniden denemeler veya yedekler gibi hata işleme uygulayın.
Örneğin, önceki kodu genişletin:
if response.status_code == 200:
result = response.json()
print(f"Response: {result['text']}")
print(f"Tokens used: {result['tokens_generated']}")
else:
print(f"Failed: {response.text}")
# Add retry logic here if needed
Bu yaklaşım, uygulamanızı değişen koşullar altında güvenilir tutar.
En İyi Uygulamalar ve Kullanım Alanları
NVIDIA Llama Nemotron API'sinin potansiyelini en üst düzeye çıkarmak için şu en iyi uygulamaları benimseyin:
- Kaynak Kullanımını Optimize Edin: Muhakemeyi yalnızca karmaşık görevler için etkinleştirin. Bu, hesaplama maliyetlerini önemli ölçüde azaltır.
- Performansı İzleyin: Özellikle gerçek zamanlı uygulamalar için zamanında yanıtlar sağlamak için
time_taken'ı izleyin. - Parametreleri Ayarlayın: Yaratıcılık ve hassasiyeti dengelemek için
temperaturevemax_tokensile deneyler yapın. - Kimlik Bilgilerini Güvenceye Alın: API anahtarlarını kodda asla değil, ortam değişkenlerinde veya güvenli kasalarda saklayın.
- Toplu İstekler: Verimliliği artırmak için birden fazla istemi tek bir çağrıda işleyin.
Pratik Kullanım Alanları
API'nin çok yönlülüğü çeşitli uygulamaları destekler:
- Müşteri Desteği: Donanım sorunlarını giderme gibi muhakeme ile karmaşık sorguları çözen sohbet robotları geliştirin.
- Eğitim: Kademeli mantıkla, örneğin hesap gibi kavramları açıklayan eğitmenler oluşturun.
- Araştırma: Bilim insanlarına verileri analiz etmede veya hipotez taslağı hazırlamada yardımcı olun.
- Yazılım Geliştirme: Doğal dil girdilerine dayalı olarak kod oluşturun veya komut dosyalarını hata ayıklayın.
Bir kodlama örneği için:
payload = {
"model": "llama-nemotron-super",
"prompt": "Write a Python function to calculate a factorial.",
"max_tokens": 200,
"temperature": 0.5,
"reasoning": "on"
}
Model şunları döndürebilir:
def factorial(n):
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)
Bu, özyinelemeli mantık yoluyla muhakeme etme yeteneğini gösterir. Apidog, bu tür API çağrılarını test etmede ve doğruluğu sağlamada yardımcı olabilir.
Sonuç
NVIDIA Llama Nemotron API'si, geliştiricilere sağlam muhakeme yeteneklerine sahip gelişmiş yapay zeka aracıları oluşturma olanağı sağlar. Açılıp kapatılabilen muhakeme özelliği performansı optimize ederken, Nano, Super ve Ultra modelleri arasındaki ölçeklenebilirliği çeşitli ihtiyaçlara uygundur. İster sohbet robotları, eğitim araçları veya kodlama yardımcıları oluşturun, bu API esneklik ve güç sunar.
Ayrıca, Apidog gibi araçlarla entegre etmek iş akışınızı geliştirir. Uç noktaları test edin, yanıtları doğrulayın ve yeniliğe odaklanmak için hızlı bir şekilde yineleyin. Yapay zeka geliştikçe, NVIDIA Llama Nemotron API'sine hakim olmak sizi bu dönüştürücü alanın ön saflarına yerleştirir.