
Belge işleme, yapay zekanın en pratik uygulamalarından biri olmuştur; ancak çoğu OCR çözümü doğruluk ve verimlilik arasında rahatsız edici bir denge kurmayı gerektirir. Tesseract gibi geleneksel sistemler kapsamlı ön işleme ihtiyaç duyar. Bulut API'leri sayfa başına ücret alır ve gecikme yaratır. Modern görüntü-dil modelleri bile yüksek çözünürlüklü belge görüntülerinden kaynaklanan belirteç patlamasıyla mücadele eder.
DeepSeek-OCR 2 bu denklemi tamamen değiştiriyor. Sürüm 1'deki "Bağlamsal Optik Sıkıştırma" yaklaşımına dayanarak, yeni sürüm "Görsel Nedensel Akış"ı sunuyor—bu mimari, karakterleri sadece tanımak yerine görsel ilişkileri ve bağlamı anlayarak belgeleri insanların gerçekte okuduğu gibi işliyor. Sonuç olarak, görüntüleri 64 belirtece kadar sıkıştırırken %97 doğruluk elde eden ve tek bir GPU'da günde 200.000'den fazla sayfa işleme kapasitesi sağlayan bir model ortaya çıkıyor.
Bu kılavuz, temel kurulumdan üretim ortamına dağıtıma kadar her şeyi kapsar—hemen kopyalayıp çalıştırabileceğiniz çalışan kodlarla birlikte.
DeepSeek-OCR 2 Nedir?
DeepSeek-OCR 2, belge anlama ve metin çıkarımı için özel olarak tasarlanmış açık kaynaklı bir görüntü-dil modelidir. DeepSeek AI tarafından Ocak 2026'da yayınlanan bu model, orijinal DeepSeek-OCR üzerine yeni bir "Görsel Nedensel Akış" mimarisiyle inşa edilmiştir. Bu mimari, belgelerdeki görsel öğelerin birbirleriyle nasıl nedensel olarak ilişkili olduğunu modeller—bir tablo başlığının altındaki hücrelerin nasıl yorumlanması gerektiğini veya bir şekil açıklamasının üzerindeki grafiği nasıl açıkladığını anlar.
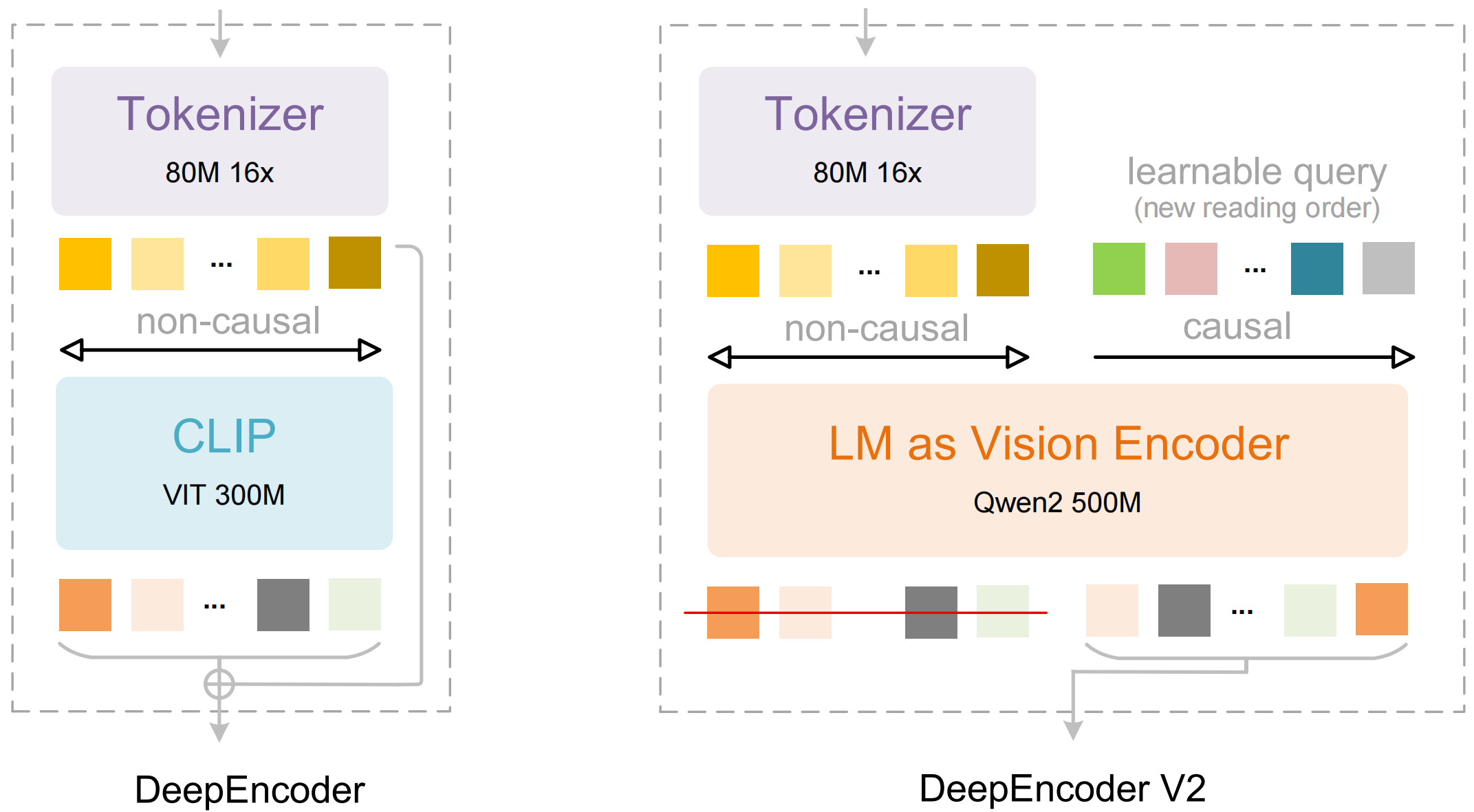
Model iki ana bileşenden oluşur:
- DeepEncoder: Yerel detay çıkarımını (SAM tabanlı, 80M parametre) küresel düzen anlama ile (CLIP tabanlı, 300M parametre) birleştiren çift görüntü dönüştürücü
- DeepSeek3B-MoE Kod Çözücü: Sıkıştırılmış görsel temsilinden yapılandırılmış çıktı (Markdown, LaTeX, JSON) üreten uzmanlar karışımı dil modeli
DeepSeek-OCR 2'yi farklı kılan özellikler:
- Uç düzeyde sıkıştırma: 1024×1024'lük bir görüntüyü 4.096 yamadan sadece 256 belirtece indirger—16 kat azalma
- Yapılandırılmış çıktı: Uygun tablolar, başlıklar ve biçimlendirmeyle temiz Markdown üretir
- Çoklu format desteği: PDF'leri, taranmış belgeleri, ekran görüntülerini, el yazısı notları ve daha fazlasını işler
- 100'den fazla dil: Yaklaşık 100 dili kapsayan 30 milyon sayfa üzerinde eğitilmiştir
- Açık ağırlıklar: MIT lisanslı, Hugging Face'te mevcut
Temel Özellikler ve Mimari
Görsel Nedensel Akış
Sürüm 2'nin ana özelliği "Görsel Nedensel Akış"tır—basit OCR'nin ötesine geçen belgeleri anlama konusunda yeni bir yaklaşımdır. Bir sayfayı düz bir karakter ızgarası olarak ele almak yerine, model görsel öğeler arasındaki nedensel ilişkileri öğrenir:
- Okuma sırası çıkarımı: Çok sütunlu düzenler için doğru sırayı otomatik olarak belirler
- Tablo yapısı anlama: Başlıkları, birleştirilmiş hücreleri ve iç içe tabloları tanır
- Şekil-açıklama bağlama: Görüntüleri açıklamalarıyla ilişkilendirir
- Matematiksel ifade ayrıştırma: Satır içi ve blok LaTeX'i doğru bir şekilde işler
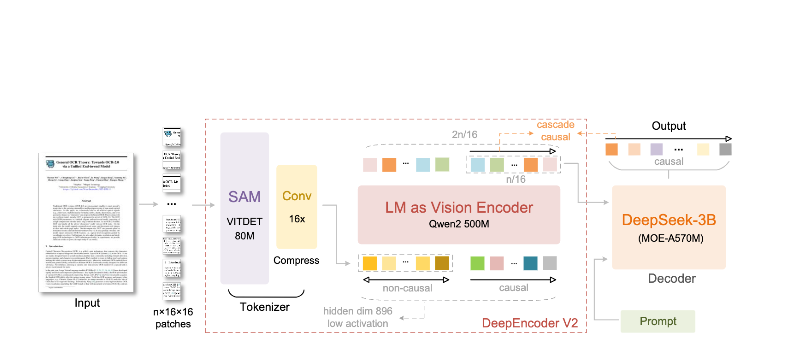
DeepEncoder Mimarisi
DeepEncoder'da sihir gerçekleşir. Yüksek çözünürlüklü görüntüleri yönetilebilir bir belirteç sayısını koruyarak işler:
Input Image (1024×1024)
↓
SAM-base Block (80M params)
- Windowed attention for local detail
- Extracts fine-grained features
↓
CLIP-large Block (300M params)
- Global attention for layout
- Understands document structure
↓
Convolution Block
- 16× token reduction
- 4,096 patches → 256 tokens
↓
Output: Compressed Vision Tokens
Sıkıştırma ve Doğruluk Dengesi
| Sıkıştırma Oranı | Görsel Belirteçler | Doğruluk |
|---|---|---|
| 4× | 1.024 | %99+ |
| 10× | 256 | %97 |
| 16× | 160 | %92 |
| 20× | 128 | ~%60 |
Çoğu uygulama için ideal nokta, %97 doğruluğu korurken üretim dağıtımını pratik hale getiren yüksek verimi sağlayan 10 kat sıkıştırma oranıdır.
Kurulum ve Ayarlar
Ön Koşullar
- Python 3.10+ (3.12.9 önerilir)
- Uyumlu NVIDIA GPU ile CUDA 11.8+
- En az 16GB GPU belleği (üretim için A100-40G önerilir)
Yöntem 1: vLLM Kurulumu (Önerilen)
vLLM, üretim dağıtımları için en iyi performansı sağlar:
# Sanal ortam oluştur
python -m venv deepseek-ocr-env
source deepseek-ocr-env/bin/activate
# CUDA desteğiyle vLLM kur
pip install vllm>=0.8.5
# Optimal performans için flash attention kur
pip install flash-attn==2.7.3 --no-build-isolation
Yöntem 2: Transformers Kurulumu
Geliştirme ve deneyler için:
pip install transformers>=4.40.0
pip install torch>=2.6.0 torchvision>=0.21.0
pip install accelerate
pip install flash-attn==2.7.3 --no-build-isolation
Yöntem 3: Docker (Üretim)
FROM nvidia/cuda:11.8-devel-ubuntu22.04
RUN pip install vllm>=0.8.5 flash-attn==2.7.3
# Modeli önceden indir
RUN python -c "from vllm import LLM; LLM(model='deepseek-ai/DeepSeek-OCR-2')"
EXPOSE 8000
CMD ["vllm", "serve", "deepseek-ai/DeepSeek-OCR-2", "--port", "8000"]
Kurulumu Doğrulama
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
import vllm
print(f"vLLM version: {vllm.__version__}")
Python Kod Örnekleri
vLLM ile Temel OCR
Bir belge görüntüsünden metin çıkarmak için en basit yol şudur:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Modeli başlat
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
trust_remote_code=True,
)
# Belge görüntünüzü yükleyin
image = Image.open("document.png").convert("RGB")
# Komut istemini hazırla - "Free OCR." standart çıkarmayı tetikler
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": image}
}]
# Örnekleme parametrelerini yapılandır
sampling_params = SamplingParams(
temperature=0.0, # OCR için deterministik
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822}, # Tablolar için <td>, </td>
},
skip_special_tokens=False,
)
# Çıktıyı oluştur
outputs = llm.generate(model_input, sampling_params)
# Markdown metnini çıkar
markdown_text = outputs[0].outputs[0].text
print(markdown_text)
Birden Fazla Belgenin Toplu İşlenmesi
Birden fazla belgeyi tek bir toplu işlemde verimli bir şekilde işleyin:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
from pathlib import Path
def batch_ocr(image_paths: list[str], llm: LLM) -> list[str]:
"""Birden fazla görüntüyü tek bir toplu işlemde işleyin."""
# Tüm görüntüleri yükle
images = [Image.open(p).convert("RGB") for p in image_paths]
# Toplu girişi hazırla
prompt = "<image>\nFree OCR."
model_inputs = [
{"prompt": prompt, "multi_modal_data": {"image": img}}
for img in images
]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
# Tüm çıktıları tek bir çağrıda oluştur
outputs = llm.generate(model_inputs, sampling_params)
return [out.outputs[0].text for out in outputs]
# Kullanım
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
image_files = list(Path("documents/").glob("*.png"))
results = batch_ocr([str(f) for f in image_files], llm)
for path, text in zip(image_files, results):
print(f"--- {path.name} ---")
print(text[:500]) # İlk 500 karakter
print()
Transformers Doğrudan Kullanma
Çıkarım süreci üzerinde daha fazla kontrol için:
import torch
from transformers import AutoModel, AutoTokenizer
from PIL import Image
# GPU'yu ayarla
device = "cuda:0"
# Model ve tokenlaştırıcıyı yükle
model_name = "deepseek-ai/DeepSeek-OCR-2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True,
)
model = model.eval().to(device).to(torch.bfloat16)
# Görüntüyü yükle ve ön işle
image = Image.open("document.png").convert("RGB")
# Farklı görevler için farklı komut istemleri
prompts = {
"ocr": "<image>\nFree OCR.",
"markdown": "<image>\n<|grounding|>Convert the document to markdown.",
"table": "<image>\nExtract all tables as markdown.",
"math": "<image>\nExtract mathematical expressions as LaTeX.",
}
# Seçtiğiniz komut istemiyle işleyin
prompt = prompts["markdown"]
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Görüntüyü girişlere ekle (modele özgü ön işleme)
with torch.no_grad():
outputs = model.generate(
**inputs,
images=[image],
max_new_tokens=4096,
do_sample=False,
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
Yüksek Verim için Asenkron İşleme
import asyncio
from vllm import AsyncLLMEngine, AsyncEngineArgs, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
async def process_document(engine, image_path: str, request_id: str):
"""Bir belgeyi asenkron olarak işler."""
image = Image.open(image_path).convert("RGB")
prompt = "<image>\nFree OCR."
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
)
results = []
async for output in engine.generate(prompt, sampling_params, request_id):
results.append(output)
return results[-1].outputs[0].text
async def main():
# Asenkron motoru başlat
engine_args = AsyncEngineArgs(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
# Birden fazla belgeyi eşzamanlı olarak işle
image_paths = ["doc1.png", "doc2.png", "doc3.png"]
tasks = [
process_document(engine, path, f"req_{i}")
for i, path in enumerate(image_paths)
]
results = await asyncio.gather(*tasks)
for path, text in zip(image_paths, results):
print(f"{path}: {len(text)} characters extracted")
asyncio.run(main())
Üretim İçin vLLM Kullanımı
OpenAI Uyumlu Sunucuyu Başlatma
DeepSeek-OCR 2'yi bir API sunucusu olarak dağıtın:
vllm serve deepseek-ai/DeepSeek-OCR-2 \
--host 0.0.0.0 \
--port 8000 \
--logits_processors vllm.model_executor.models.deepseek_ocr:NGramPerReqLogitsProcessor \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9
OpenAI SDK ile Sunucuyu Çağırma
from openai import OpenAI
import base64
# Yerel sunucuya işaret eden istemciyi başlat
client = OpenAI(
api_key="EMPTY", # Yerel sunucu için gerekli değil
base_url="http://localhost:8000/v1",
timeout=3600,
)
def encode_image(image_path: str) -> str:
"""Görüntüyü base64'e kodla."""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def ocr_document(image_path: str) -> str:
"""OCR API kullanarak belgeden metin çıkar."""
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
extra_body={
"skip_special_tokens": False,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822],
},
},
)
return response.choices[0].message.content
# Kullanım
result = ocr_document("invoice.png")
print(result)
URL'lerle Kullanım
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/document.png"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
)
Apidog ile Test Etme
OCR API'lerini etkili bir şekilde test etmek, hem giriş belgelerini hem de çıkarılan çıktıyı görselleştirmeyi gerektirir. Apidog, DeepSeek-OCR 2 ile denemeler yapmak için sezgisel bir arayüz sağlar.
OCR Uç Noktasını Ayarlama
Adım 1: Yeni Bir İstek Oluşturun
- Apidog'u açın ve yeni bir proje oluşturun
- `http://localhost:8000/v1/chat/completions` adresine bir POST isteği ekleyin
Adım 2: Başlıkları Yapılandırın
Content-Type: application/json
Adım 3: İstek Gövdesini Yapılandırın
{
"model": "deepseek-ai/DeepSeek-OCR-2",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64_image}}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
"max_tokens": 8192,
"temperature": 0,
"extra_body": {
"skip_special_tokens": false,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822]
}
}
}
Farklı Belge Türlerini Test Etme
Yaygın belge türleri için kayıtlı istekler oluşturun:
- Fatura çıkarımı - Yapılandırılmış veri çıkarımını test edin
- Akademik makale - LaTeX matematik işlemeyi test edin
- El yazısı notlar - El yazısı tanımayı test edin
- Çok sütunlu düzen - Okuma sırası çıkarımını test edin
Çözünürlük Modlarını Karşılaştırma
Farklı modları hızlıca test etmek için ortam değişkenlerini ayarlayın:
| Mod | Çözünürlük | Belirteçler | Kullanım Durumu |
|---|---|---|---|
tiny | 512×512 | 64 | Hızlı önizlemeler |
small | 640×640 | 100 | Basit belgeler |
base | 1024×1024 | 256 | Standart belgeler |
large | 1280×1280 | 400 | Yoğun metin |
gundam | Dinamik | Değişken | Karmaşık düzenler |

Çözünürlük Modları ve Sıkıştırma
DeepSeek-OCR 2, her biri farklı kullanım durumları için optimize edilmiş beş çözünürlük modunu destekler:
Küçük Mod (64 belirteç)
En iyisi: Hızlı metin algılama, basit formlar, düşük çözünürlüklü girdiler
# Küçük mod için yapılandır
os.environ["DEEPSEEK_OCR_MODE"] = "tiny" # 512×512
Küçük Mod (100 belirteç)
En iyisi: Temiz dijital belgeler, tek sütunlu metin
Temel Mod (256 belirteç) - Varsayılan
En iyisi: Çoğu standart belge, fatura, mektup
Büyük Mod (400 belirteç)
En iyisi: Yoğun akademik makaleler, hukuki belgeler
Gundam Modu (Dinamik)
En iyisi: Değişen düzenlere sahip karmaşık çok sayfalı belgeler
# Gundam modu birden fazla görünümü birleştirir
# - Detay için n × 640×640 yerel döşeme
# - Yapı için 1 × 1024×1024 küresel görünüm
Doğru Modu Seçme
def select_mode(document_type: str, page_count: int) -> str:
"""Belge özelliklerine göre optimal çözünürlük modunu seç."""
if document_type == "simple_form":
return "tiny"
elif document_type == "digital_document" and page_count == 1:
return "small"
elif document_type == "academic_paper":
return "large"
elif document_type == "mixed_layout" or page_count > 1:
return "gundam"
else:
return "base" # Varsayılan
PDF'leri ve Belgeleri İşleme
PDF'leri Görüntülere Dönüştürme
import fitz # PyMuPDF
from PIL import Image
import io
def pdf_to_images(pdf_path: str, dpi: int = 150) -> list[Image.Image]:
"""PDF sayfalarını PIL Görüntülerine dönüştürür."""
doc = fitz.open(pdf_path)
images = []
for page_num in range(len(doc)):
page = doc[page_num]
# Belirtilen DPI'da oluştur
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
# PIL Görüntüsüne dönüştür
img_data = pix.tobytes("png")
img = Image.open(io.BytesIO(img_data))
images.append(img)
doc.close()
return images
# Kullanım
images = pdf_to_images("report.pdf", dpi=200)
print(f"Extracted {len(images)} pages") # {len(images)} sayfa çıkarıldı
Tam PDF İşleme Hattı
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from pathlib import Path
import fitz
from PIL import Image
import io
class PDFProcessor:
def __init__(self, model_name: str = "deepseek-ai/DeepSeek-OCR-2"):
self.llm = LLM(
model=model_name,
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
self.sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
def process_pdf(self, pdf_path: str, dpi: int = 150) -> str:
"""Tüm PDF'yi işler ve birleştirilmiş markdown'ı döndürür."""
doc = fitz.open(pdf_path)
all_text = []
for page_num in range(len(doc)):
# Sayfayı görüntüye dönüştür
page = doc[page_num]
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
img = Image.open(io.BytesIO(pix.tobytes("png")))
# Sayfayı OCR ile işle
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": img}
}]
output = self.llm.generate(model_input, self.sampling_params)
page_text = output[0].outputs[0].text
all_text.append(f"## Page {page_num + 1}\n\n{page_text}")
doc.close()
return "\n\n---\n\n".join(all_text)
# Kullanım
processor = PDFProcessor()
markdown = processor.process_pdf("annual_report.pdf")
# Dosyaya kaydet
Path("output.md").write_text(markdown)
Kıyaslama Performansı
Doğruluk Kıyaslamaları
| Kıyaslama | DeepSeek-OCR 2 | GOT-OCR2.0 | MinerU2.0 |
|---|---|---|---|
| OmniDocBench | %94,2 | %91,8 | %89,5 |
| Belirteç/sayfa | 100-256 | 256 | 6.000+ |
| Fox (10× sıkıştırma) | %97 | -- | -- |
| Fox (20× sıkıştırma) | %60 | -- | -- |
Verim Performansı
| Donanım | Sayfa/Gün | Sayfa/Saat |
|---|---|---|
| A100-40G (tek) | 200.000+ | ~8.300 |
| A100-40G × 20 | 33M+ | ~1,4M |
| RTX 4090 | ~80.000 | ~3.300 |
| RTX 3090 | ~50.000 | ~2.100 |
Belge Türüne Göre Gerçek Dünya Doğruluğu
| Belge Türü | Doğruluk | Notlar |
|---|---|---|
| Dijital PDF'ler | %98+ | En iyi performans |
| Taranmış belgeler | %95+ | İyi kaliteli taramalar |
| Finansal raporlar | %92 | Karmaşık tablolar |
| El yazısı notlar | %85 | Okunabilirliğe bağlıdır |
| Tarihi belgeler | %80 | Bozulmuş kalite |
En İyi Uygulamalar ve Optimizasyon
Görüntü Ön İşleme
from PIL import Image, ImageEnhance, ImageFilter
def preprocess_document(image: Image.Image) -> Image.Image:
"""Optimal OCR için belge görüntüsünü ön işler."""
# Gerekirse RGB'ye dönüştür
if image.mode != "RGB":
image = image.convert("RGB")
# Çok küçükse yeniden boyutlandır (en kısa kenarda minimum 512 piksel)
min_dim = min(image.size)
if min_dim < 512:
scale = 512 / min_dim
new_size = (int(image.width * scale), int(image.height * scale))
image = image.resize(new_size, Image.Resampling.LANCZOS)
# Taranmış belgeler için kontrastı artır
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(1.2)
# Hafifçe keskinleştir
image = image.filter(ImageFilter.SHARPEN)
return image
Komut Mühendisliği
# Farklı görevler için farklı komut istemleri
PROMPTS = {
# Standart OCR - en hızlı, çoğu durum için iyi
"ocr": "<image>\nFree OCR.",
# Markdown dönüştürme - daha iyi yapı koruma
"markdown": "<image>\n<|grounding|>Convert the document to markdown.",
# Tablo çıkarımı - tablosal veriler için optimize edilmiştir
"table": "<image>\nExtract all tables in markdown format.",
# Matematik çıkarımı - akademik/bilimsel belgeler için
"math": "<image>\nExtract all text and mathematical expressions. Use LaTeX for math.",
# Belirli alanlar - form çıkarımı için
"fields": "<image>\nExtract the following fields: name, date, amount, signature.",
}
Bellek Optimizasyonu
# Sınırlı GPU belleği için
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
gpu_memory_utilization=0.8, # Boş alan bırak
max_model_len=8192, # Maksimum bağlamı azalt
enable_chunked_prefill=True, # Daha iyi bellek verimliliği
)
Toplu İşleme Stratejisi
def optimal_batch_size(gpu_memory_gb: int, avg_image_size: tuple) -> int:
"""GPU belleğine göre optimal toplu iş boyutunu hesapla."""
# Görüntü başına yaklaşık bellek (GB cinsinden)
pixels = avg_image_size[0] * avg_image_size[1]
mem_per_image = (pixels * 4) / (1024**3) # Piksel başına 4 bayt
# Model için GPU belleğinin %60'ını ayır
available = gpu_memory_gb * 0.4
return max(1, int(available / mem_per_image))
# Örnek: 1024x1024 görüntülerle A100-40G
batch_size = optimal_batch_size(40, (1024, 1024))
print(f"Recommended batch size: {batch_size}") # ~10