
Yerel makinenizde bir LLM çalıştırmanın çeşitli avantajları vardır. İlk olarak, size verileriniz üzerinde tam kontrol sağlar ve gizliliğin korunmasını sağlar. İkincisi, pahalı API çağrıları veya aylık abonelikler konusunda endişelenmeden deney yapabilirsiniz. Ayrıca, yerel dağıtımlar, bu modellerin nasıl çalıştığını öğrenmek için uygulamalı bir yol sunar.
Ayrıca, LLM'leri yerel olarak çalıştırdığınızda, potansiyel ağ gecikmesi sorunlarından ve bulut hizmetlerine bağımlılıktan kaçınırsınız. Bu, özellikle kod tabanınızla sıkı entegrasyon gerektiren projeler üzerinde çalışıyorsanız, daha hızlı oluşturabileceğiniz, test edebileceğiniz ve yineleyebileceğiniz anlamına gelir.
LLM'leri Anlamak: Hızlı Bir Bakış
En iyi seçimlerimize dalmadan önce, bir LLM'nin ne olduğuna kısaca değinelim. Basit bir ifadeyle, büyük bir dil modeli (LLM), büyük miktarda metin verisi üzerinde eğitilmiş bir yapay zeka modelidir. Bu modeller, dil içindeki istatistiksel kalıpları öğrenir ve bu da sağladığınız istemlere göre insan benzeri metinler oluşturmalarını sağlar.
LLM'ler, birçok modern yapay zeka uygulamasının merkezinde yer alır. Sohbet robotlarına, yazma yardımcılarına, kod oluşturuculara ve hatta gelişmiş konuşma temsilcilerine güç verirler. Ancak, bu modelleri çalıştırmak—özellikle daha büyük olanları—kaynak yoğun olabilir. Bu nedenle, bunları yerel olarak çalıştırmak için güvenilir bir araca sahip olmak çok önemlidir.
Yerel LLM araçlarını kullanarak, verilerinizi uzak sunuculara göndermeden bu modellerle deney yapabilirsiniz. Bu, hem güvenliği hem de performansı artırabilir. Bu eğitim boyunca, her bir aracın bu güçlü modelleri kendi donanımınızda nasıl kullandığını araştırırken "LLM" anahtar kelimesinin vurgulandığını fark edeceksiniz.
Araç #1: Llama.cpp
Llama.cpp, LLM'leri yerel olarak çalıştırma söz konusu olduğunda muhtemelen en popüler araçlardan biridir. Georgi Gerganov tarafından oluşturulmuş ve canlı bir topluluk tarafından sürdürülen bu C/C++ kütüphanesi, LLaMA ve diğerleri gibi modellerde minimum bağımlılıklarla çıkarım yapmak için tasarlanmıştır.

Neden Llama.cpp'ye Bayılacaksınız
- Hafif ve Hızlı: Llama.cpp, hız ve verimlilik için tasarlanmıştır. Minimum kurulumla, mütevazı donanımlarda bile karmaşık modeller çalıştırabilirsiniz. AVX ve Neon gibi gelişmiş CPU talimatlarından yararlanır, yani sisteminizin performansından en iyi şekilde yararlanırsınız.
- Çok Yönlü Donanım Desteği: İster bir x86 makinesi, ister ARM tabanlı bir cihaz veya hatta bir Apple Silicon Mac kullanıyor olun, Llama.cpp sizi korur.
- Komut Satırı Esnekliği: Grafik arayüzler yerine terminali tercih ediyorsanız, Llama.cpp'nin komut satırı araçları, modelleri yüklemeyi ve yanıtları doğrudan kabuğunuzdan oluşturmayı kolaylaştırır.
- Topluluk ve Açık Kaynak: Açık kaynaklı bir proje olarak, dünyanın dört bir yanındaki geliştiricilerin sürekli katkılarından ve iyileştirmelerinden yararlanır.
Nasıl Başlanır
- Kurulum: GitHub'dan depoyu klonlayın ve kodu makinenizde derleyin.
- Model Kurulumu: Tercih ettiğiniz modeli (örneğin, nicelleştirilmiş bir LLaMA varyantı) indirin ve çıkarıma başlamak için sağlanan komut satırı yardımcı programlarını kullanın.
- Özelleştirme: Modelin çıktısının nasıl değiştiğini görmek için bağlam uzunluğu, sıcaklık ve ışın boyutu gibi parametreleri ayarlayın.
Örneğin, basit bir komut şöyle görünebilir:
./main -m ./models/llama-7b.gguf -p "Tell me a joke about programming" --temp 0.7 --top_k 100
Bu komut, modeli yükler ve isteminize göre metin oluşturur. Bu kurulumun basitliği, yerel LLM çıkarımına yeni başlayan herkes için büyük bir artıdır.
Llama.cpp'den sorunsuz bir şekilde geçerek, biraz farklı bir yaklaşım benimseyen başka bir harika aracı keşfedelim.
Araç #2: GPT4All
GPT4All, LLM'lere erişimi demokratikleştiren Nomic AI tarafından tasarlanmış açık kaynaklı bir ekosistemdir. GPT4All'un en heyecan verici yönlerinden biri, ister CPU'da ister GPU'da olun, tüketici sınıfı donanımda çalışacak şekilde tasarlanmış olmasıdır. Bu, pahalı makinelere ihtiyaç duymadan deney yapmak isteyen geliştiriciler için mükemmel hale getirir.
GPT4All'un Temel Özellikleri
- Yerel Öncelikli Yaklaşım: GPT4All, tamamen yerel cihazınızda çalışacak şekilde oluşturulmuştur. Bu, hiçbir verinin makinenizden ayrılmadığı, gizliliğin ve hızlı yanıt sürelerinin sağlandığı anlamına gelir.
- Kullanıcı Dostu: LLM'lere yeni başlasanız bile, GPT4All, derin teknik bilgi birikimi olmadan modelle etkileşim kurmanızı sağlayan basit, sezgisel bir arayüzle birlikte gelir.
- Hafif ve Verimli: GPT4All ekosistemindeki modeller performans için optimize edilmiştir. Bunları dizüstü bilgisayarınızda çalıştırabilirsiniz, bu da onları daha geniş bir kitleye erişilebilir hale getirir.
- Açık Kaynak ve Topluluk Odaklı: Açık kaynaklı yapısıyla GPT4All, topluluk katkılarını davet eder ve en son yeniliklerle güncel kalmasını sağlar.
GPT4All'a Başlarken
- Kurulum: GPT4All'u web sitesinden indirebilirsiniz. Kurulum süreci basittir ve Windows, macOS ve Linux için önceden derlenmiş ikililer mevcuttur.
- Modeli Çalıştırma: Kurulduktan sonra, uygulamayı başlatmanız ve çeşitli önceden ayarlanmış modeller arasından seçim yapmanız yeterlidir. Araç, gündelik deneyler için mükemmel olan bir sohbet arayüzü bile sunar.
- Özelleştirme: Çıktının nasıl değiştiğini görmek için modelin yanıt uzunluğu ve yaratıcılık ayarları gibi parametreleri ayarlayın. Bu, LLM'lerin farklı koşullar altında nasıl çalıştığını anlamanıza yardımcı olur.
Örneğin, şöyle bir istem yazabilirsiniz:
Yapay zeka hakkında bazı eğlenceli gerçekler nelerdir?
Ve GPT4All, internet bağlantısına ihtiyaç duymadan, samimi ve anlayışlı bir yanıt üretecektir.
Araç #3: LM Studio
Devam edersek, LM Studio , özellikle model yönetimini kolaylaştıran bir grafik arayüz arıyorsanız, LLM'leri yerel olarak çalıştırmak için başka bir mükemmel araçtır.
LM Studio'yu Farklı Kılan Nedir?
- Sezgisel Kullanıcı Arayüzü: LM Studio, şık ve kullanıcı dostu bir masaüstü uygulaması sunar. Bu, yalnızca komut satırında çalışmayı tercih etmeyenler için idealdir.
- Model Yönetimi: LM Studio ile farklı LLM'ler arasında kolayca göz atabilir, indirebilir ve geçiş yapabilirsiniz. Uygulama, projeniz için mükemmel modeli bulabilmeniz için yerleşik filtreler ve arama işlevleri sunar.
- Özelleştirilebilir Ayarlar: Sıcaklık, maksimum belirteçler ve bağlam penceresi gibi parametreleri doğrudan kullanıcı arayüzünden ayarlayın. Bu anında geri bildirim döngüsü, farklı yapılandırmaların model davranışını nasıl etkilediğini öğrenmek için mükemmeldir.
- Çapraz Platform Uyumluluğu: LM Studio, Windows, macOS ve Linux'ta çalışır ve çok çeşitli kullanıcıya erişilebilir hale getirir.
- Yerel Çıkarım Sunucusu: Geliştiriciler ayrıca, OpenAI API'sini taklit eden yerel HTTP sunucusundan da yararlanabilirler. Bu, LLM yeteneklerini uygulamalarınıza entegre etmeyi çok daha basit hale getirir.
LM Studio Nasıl Kurulur
- İndirme ve Kurulum: LM Studio web sitesini ziyaret edin, işletim sisteminiz için yükleyiciyi indirin ve kurulum talimatlarını izleyin.
- Başlat ve Keşfet: Uygulamayı açın, mevcut modellerin kitaplığını keşfedin ve ihtiyaçlarınıza uygun bir model seçin.
- Deney: Modelle etkileşim kurmak için yerleşik sohbet arayüzünü kullanın. Ayrıca, performansı ve kaliteyi karşılaştırmak için aynı anda birden fazla modelle deney yapabilirsiniz.
Yaratıcı bir yazma projesi üzerinde çalıştığınızı hayal edin; LM Studio'nun arayüzü, modeller arasında geçiş yapmayı ve çıktıyı gerçek zamanlı olarak ince ayar yapmayı kolaylaştırır. Görsel geri bildirimi ve kullanım kolaylığı, yeni başlayanlar veya sağlam bir yerel çözüme ihtiyaç duyan profesyoneller için güçlü bir seçimdir.
Araç #4: Ollama
Sırada, hem basitliğe hem de işlevselliğe odaklanan güçlü ancak basit bir komut satırı aracı olan Ollama var. Ollama, karmaşık kurulumların zorluğu olmadan LLM'leri çalıştırmanıza, oluşturmanıza ve paylaşmanıza yardımcı olmak için tasarlanmıştır.
Neden Ollama'yı Seçmelisiniz?
- Kolay Model Dağıtımı: Ollama, model ağırlıkları, yapılandırma ve hatta veriler dahil olmak üzere ihtiyacınız olan her şeyi "Modelfile" olarak bilinen tek, taşınabilir bir birimde paketler. Bu, minimum yapılandırmayla bir modeli hızlıca indirip çalıştırabileceğiniz anlamına gelir.
- Çok Modlu Yetenekler: Yalnızca metne odaklanan bazı araçların aksine, Ollama çok modlu girdileri destekler. Hem metin hem de görüntüleri istem olarak sağlayabilirsiniz ve araç her ikisini de dikkate alan yanıtlar üretecektir.
- Çapraz Platform Kullanılabilirliği: Ollama, macOS, Linux ve Windows'ta mevcuttur. Farklı sistemlerde çalışan geliştiriciler için harika bir seçenektir.
- Komut Satırı Verimliliği: Terminalde çalışmayı tercih edenler için Ollama, hızlı dağıtım ve etkileşim sağlayan temiz ve verimli bir komut satırı arayüzü sunar.
- Hızlı Güncellemeler: Araç, topluluğu tarafından sık sık güncellenir ve her zaman en son iyileştirmeler ve özelliklerle çalıştığınızdan emin olursunuz.
Ollama'yı Kurma
1. Kurulum: Ollama web sitesini ziyaret edin ve işletim sisteminiz için yükleyiciyi indirin. Kurulum, terminalinizde birkaç komut çalıştırmak kadar basittir.
2. Bir Model Çalıştırın: Kurulduktan sonra, aşağıdaki gibi bir komut kullanın:
ollama run llama3
Bu komut, Llama 3 modelini (veya desteklenen başka bir modeli) otomatik olarak indirecek ve çıkarım sürecini başlatacaktır.
3. Çok Modluluk ile Deney Yapın: Görüntüleri destekleyen bir model çalıştırmayı deneyin. Örneğin, hazır bir görüntü dosyanız varsa, modeli nasıl yanıtladığını görmek için onu isteminize sürükleyip bırakabilir (veya görüntüler için API parametresini kullanabilirsiniz).
Ollama, özellikle LLM'leri yerel olarak hızlı bir şekilde prototip oluşturmak veya dağıtmak istiyorsanız çekicidir. Basitliği, güçten ödün vermez ve hem yeni başlayanlar hem de deneyimli geliştiriciler için ideal hale getirir.
Araç #5: Jan
Son olarak, Jan var. Jan, veri gizliliğine ve çevrimdışı çalışmaya öncelik verenler arasında istikrarlı bir şekilde popülerlik kazanan, açık kaynaklı, yerel öncelikli bir platformdur. Felsefesi basittir: kullanıcıların güçlü LLM'leri tamamen kendi donanımlarında, gizli veri aktarımı olmadan çalıştırmasına izin vermek.
Jan'ı Farklı Kılan Nedir?
- Tamamen Çevrimdışı: Jan, internet bağlantısı olmadan çalışacak şekilde tasarlanmıştır. Bu, tüm etkileşimlerinizin ve verilerinizin yerel kalmasını sağlayarak gizliliği ve güvenliği artırır.
- Kullanıcı Odaklı ve Genişletilebilir: Araç, temiz bir arayüz sunar ve bir uygulama/eklenti çerçevesini destekler. Bu, yeteneklerini kolayca genişletebileceğiniz veya mevcut araçlarınızla entegre edebileceğiniz anlamına gelir.
- Verimli Model Yürütme: Jan, belirli görevler için ince ayar yapılmış olanlar da dahil olmak üzere çeşitli modelleri işlemek üzere oluşturulmuştur. Performanstan ödün vermeden, mütevazı donanımlarda bile çalışacak şekilde optimize edilmiştir.
- Topluluk Odaklı Geliştirme: Listemizdeki birçok araç gibi, Jan da açık kaynaktır ve özel bir geliştirici topluluğunun katkılarından yararlanır.
- Abonelik Ücreti Yok: Birçok bulut tabanlı çözümün aksine, Jan'ı kullanmak ücretsizdir. Bu, başlangıçlar, hobiler ve LLM'lerle finansal engeller olmadan deney yapmak isteyen herkes için mükemmel bir seçimdir.
Jan'a Nasıl Başlanır
- İndirin ve Kurun: Jan'ın resmi web sitesine veya GitHub deposuna gidin. Kurulum talimatlarını izleyin; bunlar basittir ve sizi hızlı bir şekilde çalışır duruma getirmek için tasarlanmıştır.
- Başlat ve Özelleştir: Jan'ı açın ve çeşitli önceden yüklenmiş modeller arasından seçim yapın. Gerekirse, Hugging Face gibi harici kaynaklardan modeller içe aktarabilirsiniz.
- Deney ve Genişlet: LLM'nizle etkileşim kurmak için sohbet arayüzünü kullanın. Parametreleri ayarlayın, eklentiler yükleyin ve Jan'ın iş akışınıza nasıl uyum sağladığını görün. Esnekliği, yerel LLM deneyiminizi tam ihtiyaçlarınıza göre uyarlamanıza olanak tanır.
Jan, yerel, gizliliğe odaklı LLM yürütme ruhunu gerçekten somutlaştırır. Tüm verileri kendi makinesinde tutan, sorunsuz ve özelleştirilebilir bir araç isteyen herkes için mükemmeldir.
Profesyonel İpucu: SSE Hata Ayıklama Kullanarak LLM Yanıtlarını Akışla Yayınlama
LLM'lerle (Büyük Dil Modelleri) çalışıyorsanız, gerçek zamanlı etkileşim kullanıcı deneyimini büyük ölçüde artırabilir. İster canlı yanıtlar veren bir sohbet robotu, ister veri üretildikçe dinamik olarak güncellenen bir içerik aracı olsun, akış yayınlama anahtardır. Sunucu Tarafından Gönderilen Etkinlikler (SSE), sunucuların tek bir HTTP bağlantısı aracılığıyla istemcilere güncellemeler göndermesini sağlayarak bunun için verimli bir çözüm sunar. WebSockets gibi çift yönlü protokollerin aksine, SSE daha basit ve daha anlaşılırdır, bu da onu gerçek zamanlı özellikler için harika bir seçim haline getirir.
SSE'nin hata ayıklaması zor olabilir. İşte Apidog devreye giriyor. Apidog'un SSE hata ayıklama özelliği, SSE akışlarını kolaylıkla test etmenize, izlemenize ve sorun gidermenize olanak tanır. Bu bölümde, SSE'nin LLM API'lerinin hata ayıklaması için neden önemli olduğunu inceleyeceğiz ve Apidog'u kullanarak SSE bağlantılarını kurma ve test etme konusunda adım adım bir eğitim sunacağız.
SSE'nin LLM API'lerinin Hata Ayıklaması İçin Neden Önemli Olduğu
Eğitime dalmadan önce, işte SSE'nin LLM API'lerinin hata ayıklaması için neden harika bir seçim olduğu:
- Gerçek Zamanlı Geri Bildirim: SSE, verileri oluşturulduğu anda akışla yayınlar ve kullanıcıların yanıtların doğal olarak ortaya çıkmasını sağlar.
- Düşük Ek Yük: Yoklama (polling) yönteminin aksine, SSE tek bir kalıcı bağlantı kullanır ve kaynak kullanımını en aza indirir.
- Kullanım Kolaylığı: SSE, istemci tarafında minimum kurulum gerektirerek web uygulamalarına sorunsuz bir şekilde entegre olur.
Test etmeye hazır mısınız? Apidog'da SSE hata ayıklamayı ayarlayalım.
Adım Adım Eğitim: Apidog'da SSE Hata Ayıklama Kullanma
Apidog ile bir SSE bağlantısını yapılandırmak ve test etmek için şu adımları izleyin.
Adım 1: Apidog'da Yeni Bir Uç Nokta Oluşturun
API isteklerini test etmek ve hata ayıklamak için Apidog'da yeni bir HTTP projesi oluşturun. Bu örnekte DeepSeek'i kullanarak, SSE akışı için yapay zeka modelinin URL'si ile bir uç nokta ekleyin. (PROFESYONEL İPUCU: Apidog'un API Hub'ından hazır DeepSeek API projesini klonlayın).
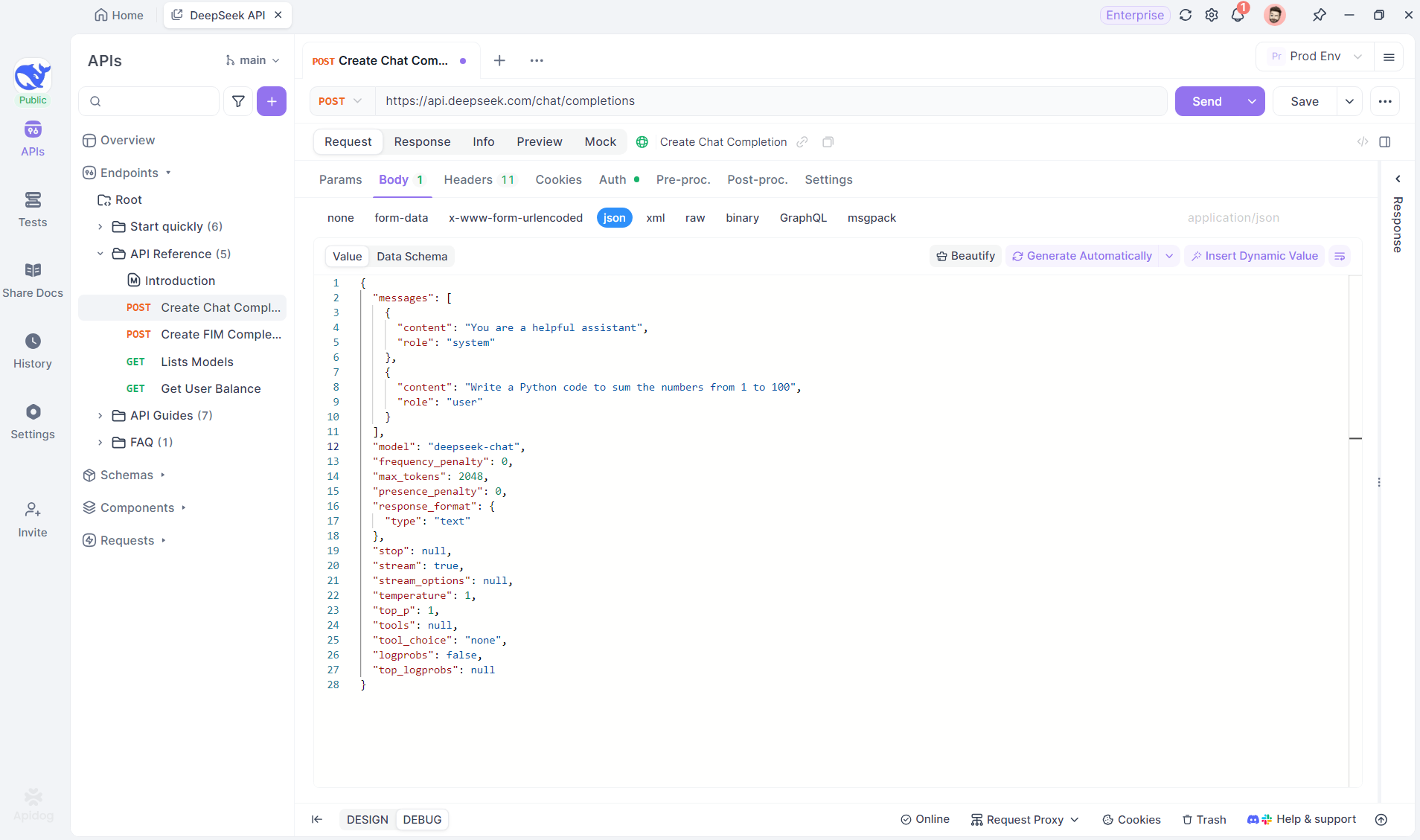
Adım 2: İsteği Gönderin
Uç noktayı ekledikten sonra, isteği göndermek için Gönder'e tıklayın. Yanıt başlığı Content-Type: text/event-stream içeriyorsa, Apidog SSE akışını algılar, verileri ayrıştırır ve gerçek zamanlı olarak görüntüler.
Adım 3: Gerçek Zamanlı Yanıtları Görüntüleyin
Apidog'un Zaman Çizelgesi Görünümü, yapay zeka modeli yanıtları akışla yayınladıkça gerçek zamanlı olarak güncellenir ve her bir parçayı dinamik olarak gösterir. Bu, yapay zekanın düşünce sürecini izlemenize ve çıktı oluşturma hakkında bilgi edinmenize olanak tanır.
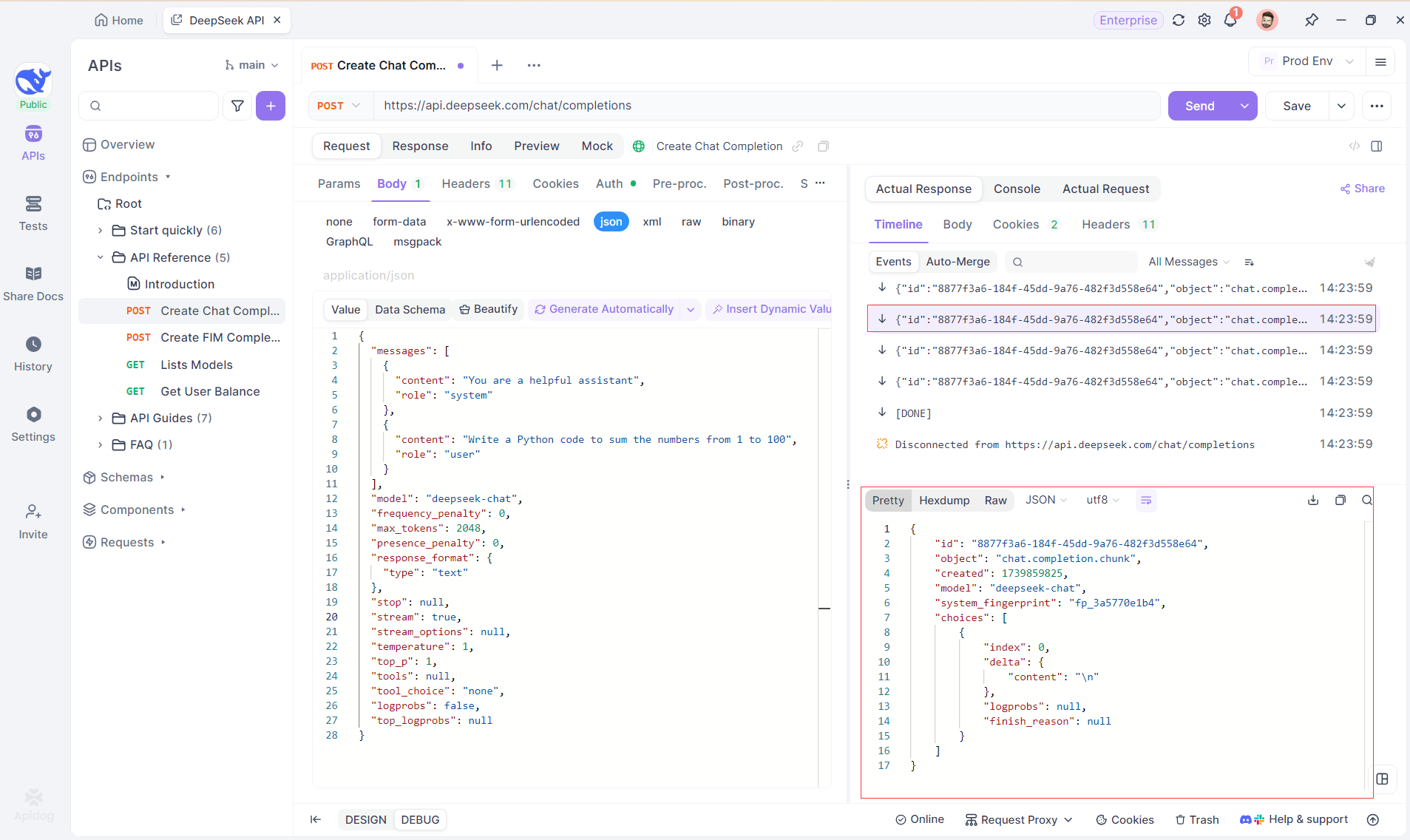
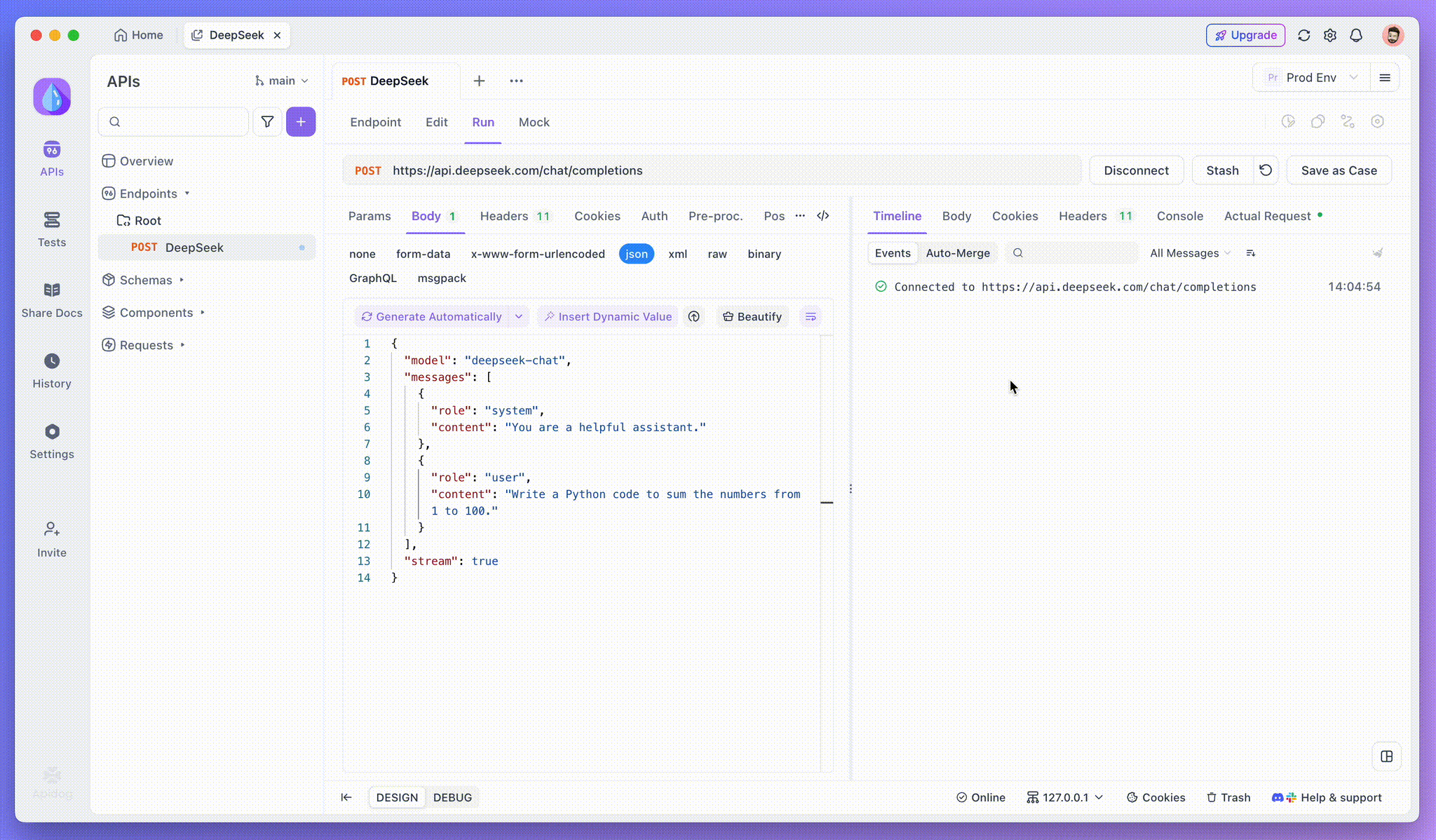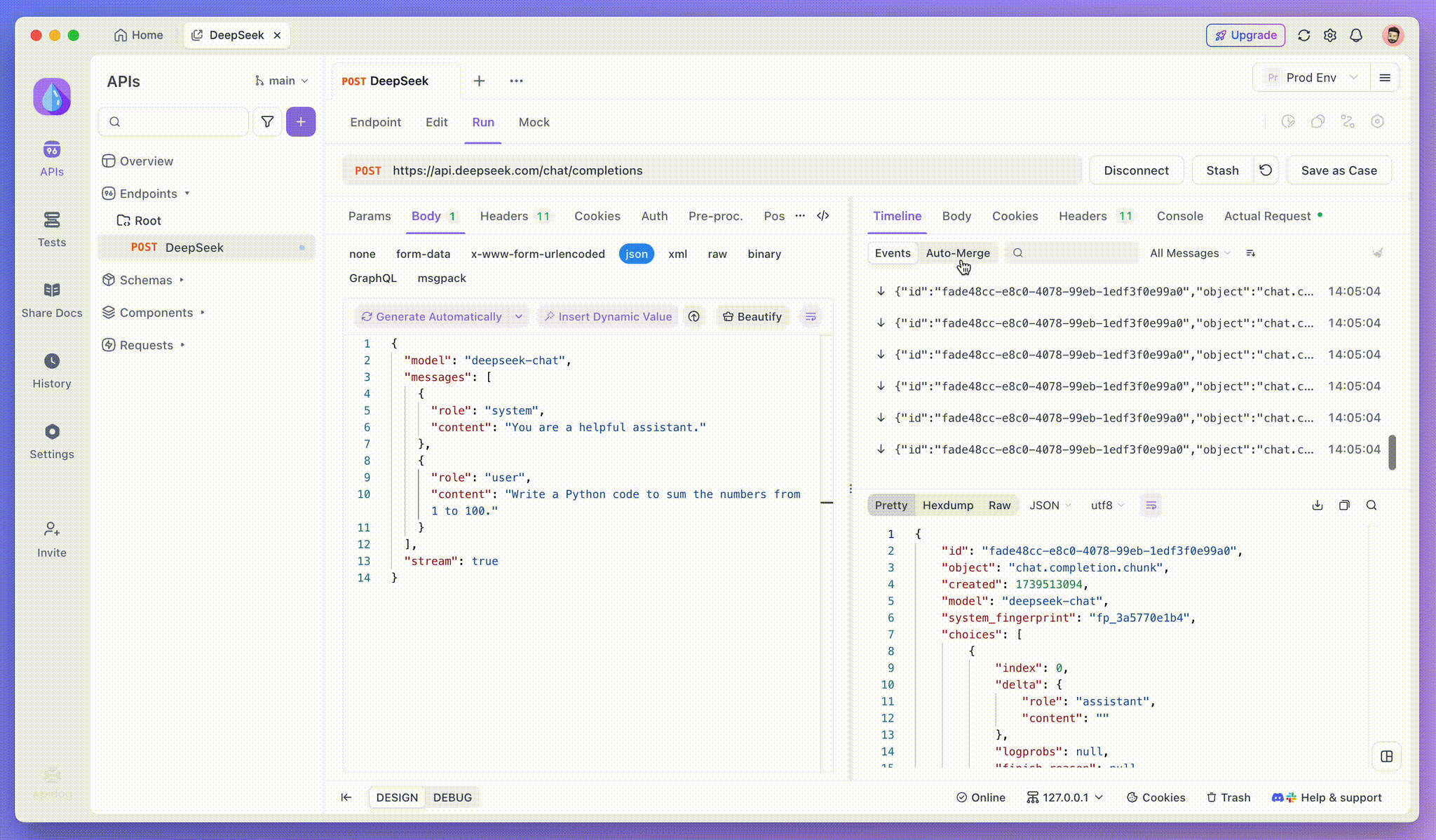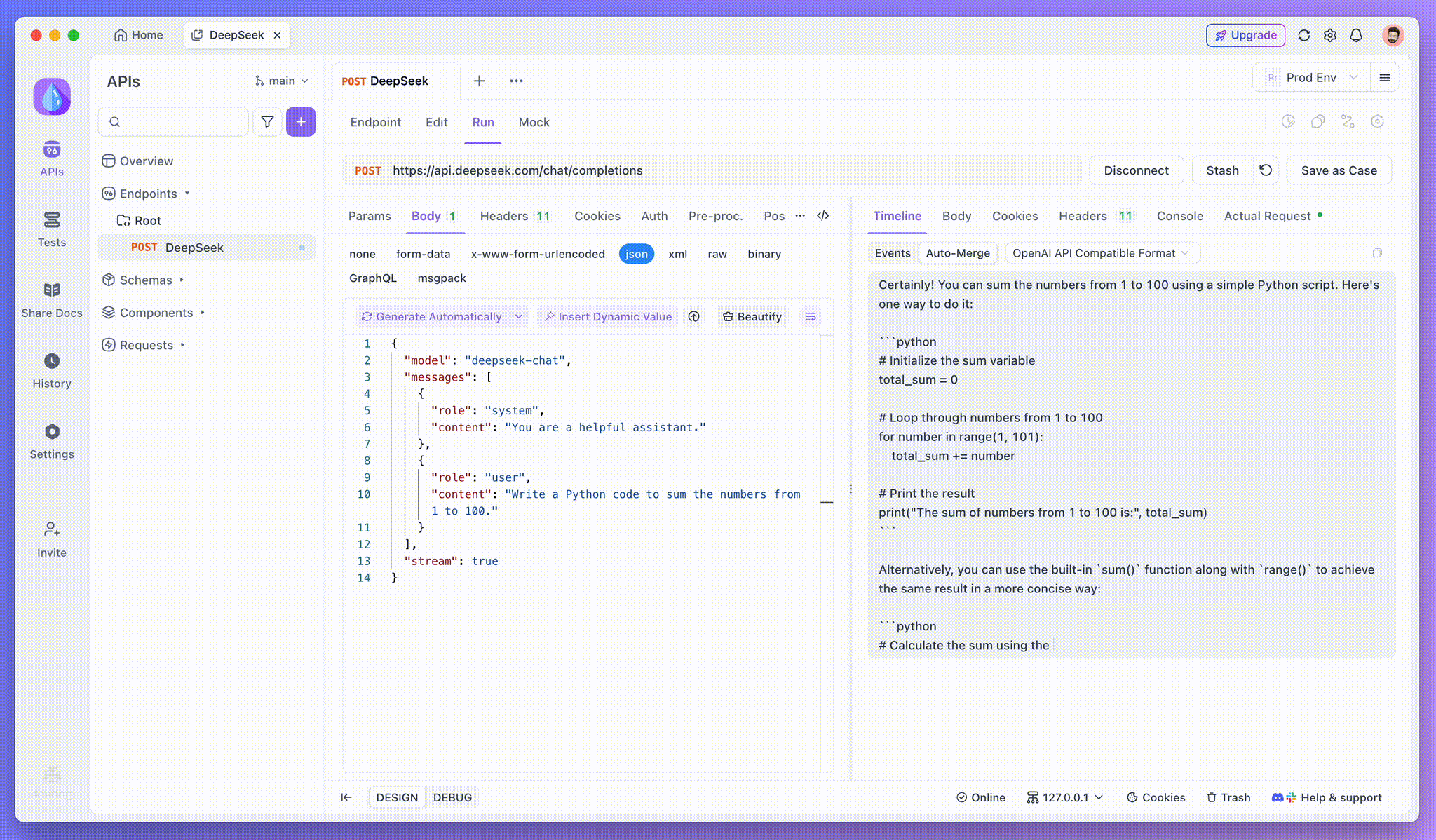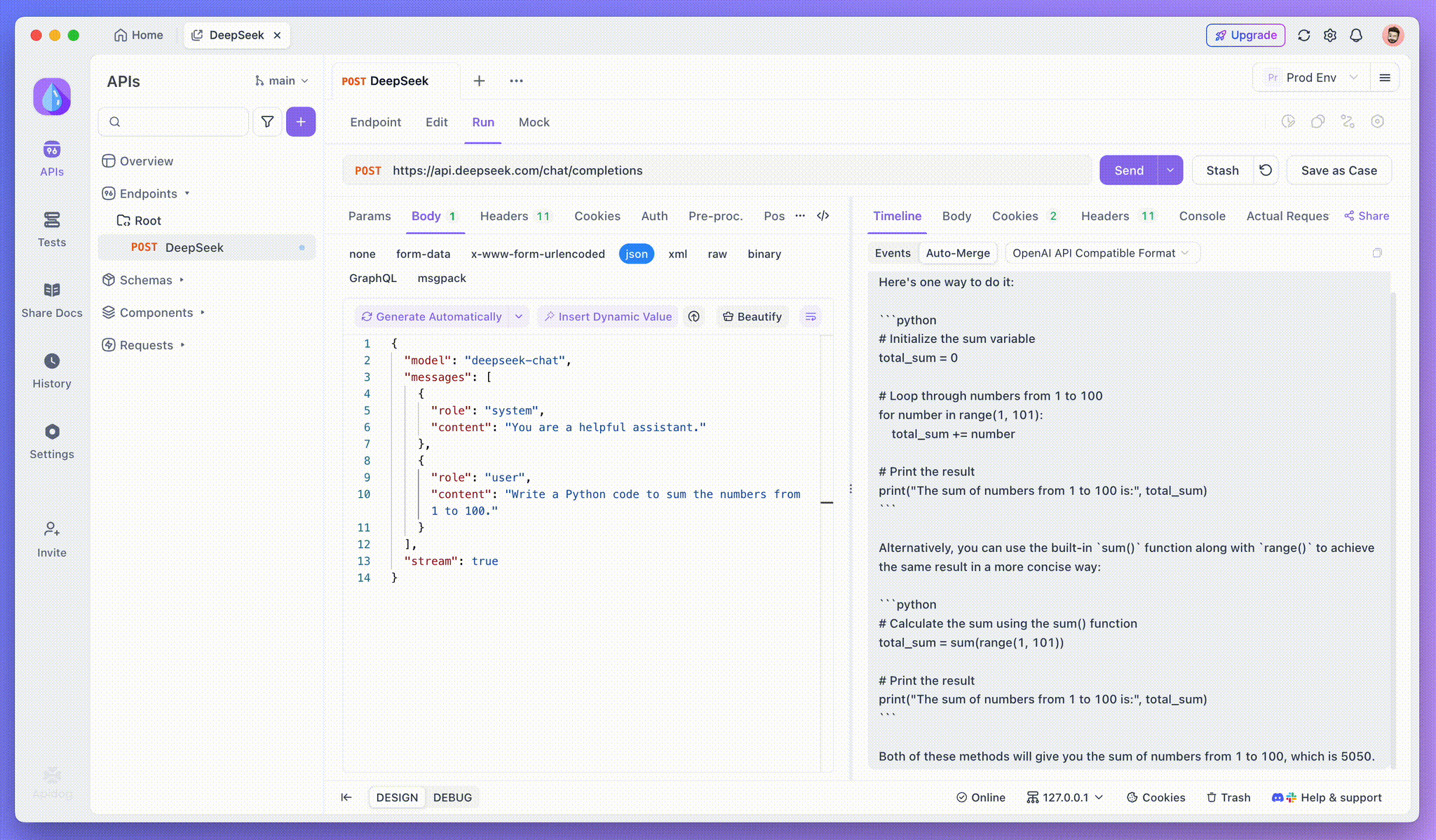
Adım 4: SSE Yanıtını Tam Bir Yanıtta Görüntüleme
SSE, verileri parçalar halinde akışla yayınlar ve ek işlem gerektirir. Apidog'un Otomatik Birleştirme özelliği, OpenAI, Gemini veya Claude gibi modellerden gelen parçalı yapay zeka yanıtlarını otomatik olarak birleştirerek bunu çözer.
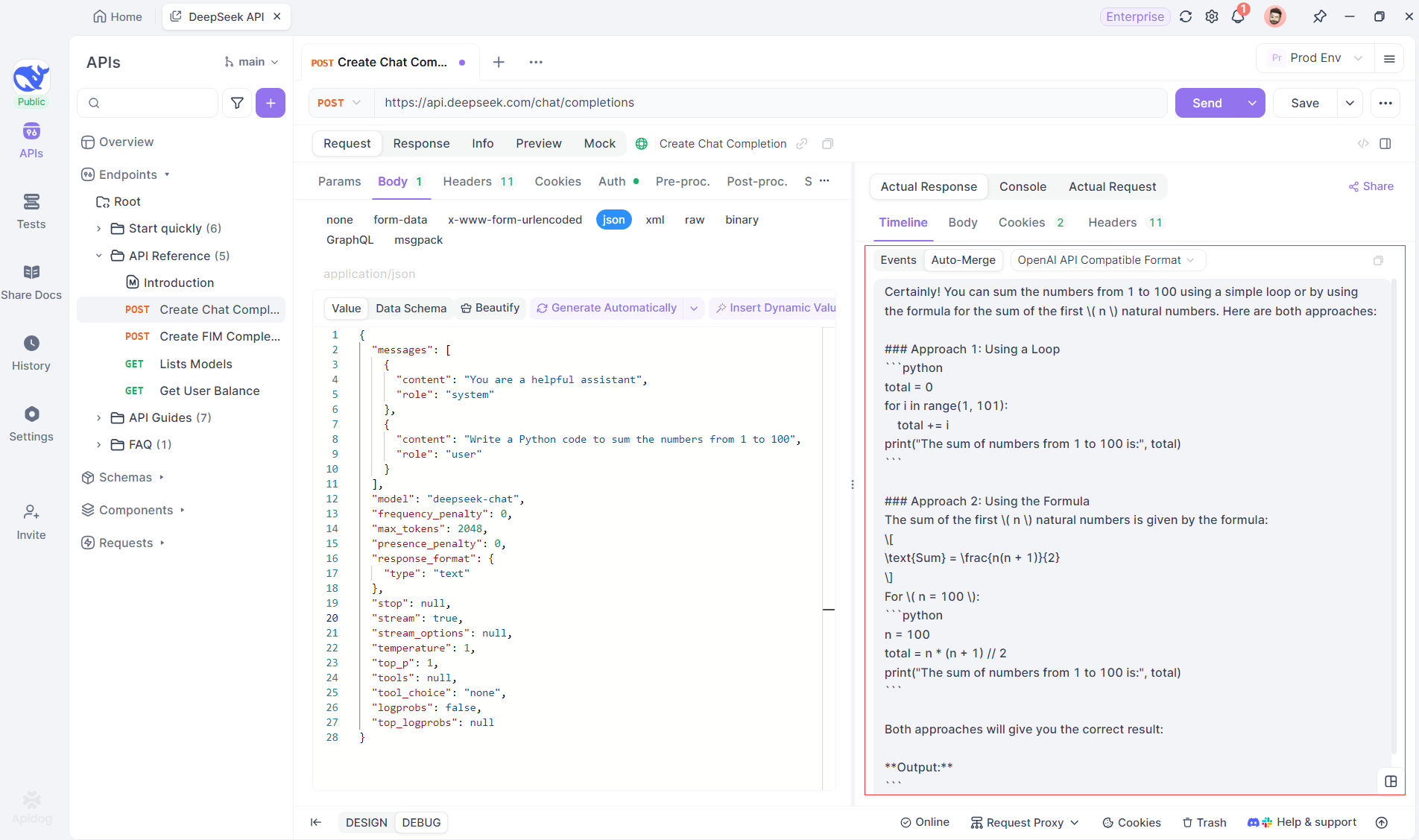
Apidog'un Otomatik Birleştirme özelliği, OpenAI, Gemini veya Claude gibi modellerden gelen parçalı yapay zeka yanıtlarını otomatik olarak birleştirerek manuel veri işlemini ortadan kaldırır.
DeepSeek R1 gibi akıl yürütme modelleri için, Apidog'un Zaman Çizelgesi Görünümü, yapay zekanın düşünce sürecini görsel olarak haritalandırarak, sonuçların nasıl oluştuğunu anlamayı ve hata ayıklamayı kolaylaştırır.
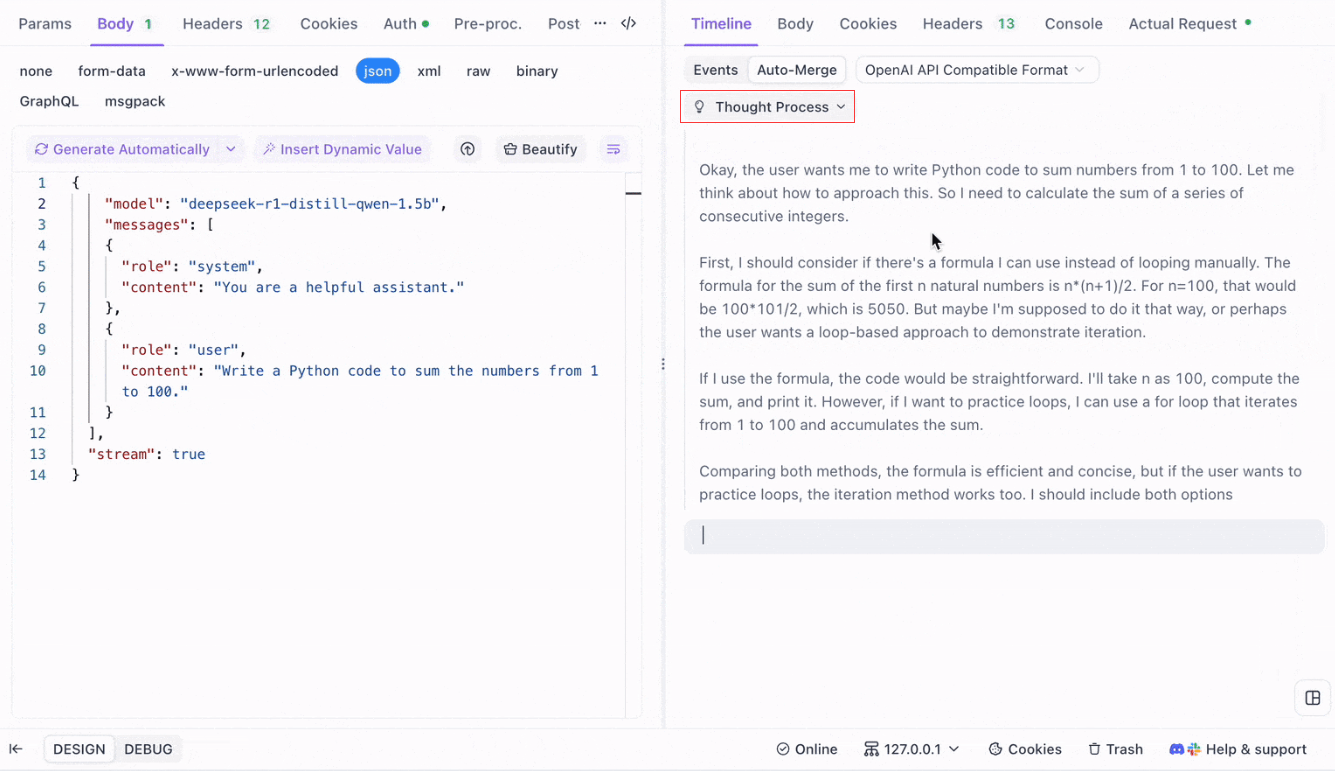
Apidog, yapay zeka yanıtlarını sorunsuz bir şekilde tanır ve birleştirir:
- OpenAI API Formatı
- Gemini API Formatı
- Claude API Formatı
Bir yanıt bu formatlarla eşleştiğinde, Apidog parçaları otomatik olarak birleştirir, manuel birleştirmeyi ortadan kaldırır ve SSE hata ayıklamasını kolaylaştırır.
Sonuç ve Sonraki Adımlar
Bugün çok yol katettik! Özetlemek gerekirse, işte LLM'leri yerel olarak çalıştırmak için beş öne çıkan araç:
- Llama.cpp: Geniş donanım desteğiyle hafif, hızlı ve son derece verimli bir komut satırı aracı isteyen geliştiriciler için idealdir.
- GPT4All: Tüketici sınıfı donanımda çalışan, sezgisel bir arayüz ve güçlü performans sunan yerel öncelikli bir ekosistem.
- LM Studio: Kolay model yönetimi ve kapsamlı özelleştirme seçenekleriyle grafik arayüzü tercih edenler için mükemmeldir.
- Ollama: "Modelfile" sistemi aracılığıyla çok modlu yeteneklere ve sorunsuz model paketlemeye sahip sağlam bir komut satırı aracı.
- Jan: Çeşitli LLM'leri entegre etmek için genişletilebilir bir çerçeve sunan, tamamen çevrimdışı çalışan, gizliliğe öncelik veren, açık kaynaklı bir platform.
Bu araçların her biri, performans, kullanım kolaylığı veya gizlilik olsun, benzersiz avantajlar sunar. Projenizin gereksinimlerine bağlı olarak, bu çözümlerden biri ihtiyaçlarınız için mükemmel olabilir. Yerel LLM araçlarının güzelliği, veri sızıntısı, abonelik maliyetleri veya ağ gecikmesi konusunda endişelenmeden keşfetmenizi ve deney yapmanızı sağlamasıdır.
Yerel LLM'lerle deney yapmanın bir öğrenme süreci olduğunu unutmayın. Bu araçları karıştırıp eşleştirmekten, çeşitli yapılandırmaları test etmekten ve hangisinin iş akışınızla en iyi şekilde uyduğunu görmekten çekinmeyin. Ayrıca, bu modelleri kendi uygulamalarınıza entegre ediyorsanız, Apidog gibi araçlar, Sunucu Tarafından Gönderilen Etkinlikler (SSE) kullanarak LLM API uç noktalarınızı sorunsuz bir şekilde yönetmenize ve test etmenize yardımcı olabilir. Apidog'u ücretsiz indirmeyi ve yerel geliştirme deneyiminizi yükseltmeyi unutmayın.
Sonraki Adımlar
- Deney: Listemizden bir araç seçin ve makinenize kurun. Değişikliklerin çıktıyı nasıl etkilediğini anlamak için farklı modeller ve ayarlar üzerinde oynayın.
- Entegre Et: Bir uygulama geliştiriyorsanız, yerel LLM aracını arka ucunuzun bir parçası olarak kullanın. Bu araçların çoğu, entegrasyonu daha sorunsuz hale getirebilen API uyumluluğu sunar (örneğin, LM Studio'nun yerel çıkarım sunucusu).
- Katkıda Bulun: Bu projelerin çoğu açık kaynaktır. Bir hata, eksik bir özellik bulursanız veya iyileştirme için fikirleriniz varsa, topluluğa katkıda bulunmayı düşünün. Girişiniz, bu araçları daha da iyi hale getirmeye yardımcı olabilir.
- Daha Fazla Bilgi Edinin: Model nicelleştirme, optimizasyon teknikleri ve istem mühendisliği gibi konuları okuyarak LLM'ler dünyasını keşfetmeye devam edin. Ne kadar çok anlarsanız, bu modelleri tam potansiyellerine o kadar çok kullanabilirsiniz.
Şimdiye kadar, projeleriniz için doğru yerel LLM aracını seçmek için sağlam bir temele sahip olmalısınız. LLM teknolojisi manzarası hızla gelişiyor ve modelleri yerel olarak çalıştırmak, özel, ölçeklenebilir ve yüksek performanslı yapay zeka çözümleri oluşturmaya yönelik önemli bir adımdır.
Bu araçlarla deney yaparken, olasılıkların sonsuz olduğunu keşfedeceksiniz. İster bir sohbet robotu, ister bir kod asistanı veya özel bir yaratıcı yazma aracı üzerinde çalışıyor olun, yerel LLM'ler ihtiyacınız olan esnekliği ve gücü sunabilir. Yolculuğun tadını çıkarın ve iyi kodlamalar!


