
Geliştiriciler ve yapay zeka meraklıları, büyük kaynaklar talep etmeden iyi performans gösteren verimli modeller arayışındadır. Google, 270 milyon parametreye sahip kompakt bir dil modeli olan Gemma 3 270M'yi tanıttı. Bu model, Gemma 3 ailesinin en küçüğü olarak öne çıkıyor ve cihaz içi görevler için optimize edilmiştir. Metin oluşturma, soru yanıtlama, özetleme ve muhakeme yetenekleri kazanırken, tüm işlemleri yerel tutabilirsiniz.
Gemma 3 270M, 32.000 jetonluk bir bağlam uzunluğunu destekler, bu da önemli girdileri etkili bir şekilde işlemesine olanak tanır. Ek olarak, Q4_0 Nicemleme Farkındalıklı Eğitim (QAT) gibi nicemleme tekniklerini içerir, bu da kaliteden ödün vermeden kaynak ihtiyaçlarını azaltır. Sonuç olarak, tam hassasiyetli modellere yakın bir performans elde edersiniz, ancak daha düşük bellek ve işlem gereksinimleriyle.
Ancak, Gemma 3 270M'yi özellikle çekici kılan şey erişilebilirliğidir. Gizliliği ve düşük gecikmeli uygulamaları destekleyerek dizüstü bilgisayarlar veya hatta mobil cihazlar dahil olmak üzere standart donanımlarda çalıştırabilirsiniz. Ardından, verimliliğin inovasyonu yönlendirdiği daha geniş yapay zeka geliştirme eğilimlerine bu modelin nasıl uyduğunu düşünün.
Gemma 3 270M'nin Mimarisini Anlamak
Google, 256.000 jetonluk bir kelime dağarcığına sahip gömülmeler için 170 milyon parametre ve dönüştürücü blokları için 100 milyon parametre içeren dönüştürücü tabanlı bir mimari üzerine Gemma 3 270M'yi inşa etti. Bu kurulum, çok dilli desteği ve niş görevleri yerine getirmeyi sağlar. Çıkarım hızını ve hafifliği artıran INT4 nicemleme, döner konum gömülmeleri ve grup sorgu dikkat mekanizması gibi tekniklerden faydalanırsınız.
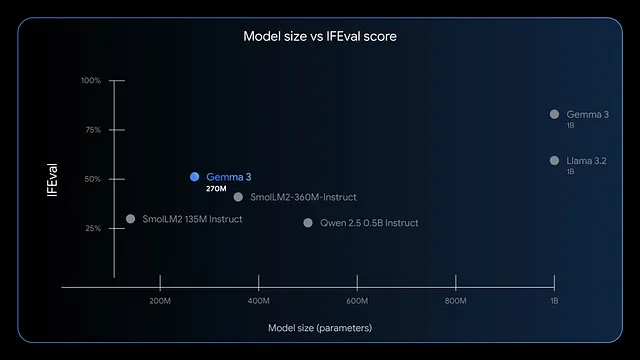
Ayrıca, model talimatları takip etme ve veri çıkarma konusunda üstündür. Kıyaslamalar, IFEval'de yüksek F1 puanları göstererek değerlendirme görevlerinde güçlü bir performans sergilediğini belirtmektedir. GPT-4 veya Phi-3 Mini gibi daha büyük modellerle karşılaştırıldığında, Gemma 3 270M verimliliğe öncelik verir ve Apple'ın M4 Max gibi cihazlarda 4 bit modunda 200 MB'tan daha az bellek kullanır.
Sonuç olarak, gerçek zamanlı duygu analizi veya sağlık kuruluşu çıkarma gibi hızlı yanıt gerektiren senaryolar için dağıtırsınız. Ancak, küçük boyutu yaratıcılığı sınırlamaz; yaratıcı yazarlık veya finansal uyumluluk kontrolleri için uygulayabilirsiniz. İlerleyen zamanlarda, bu modeli yerel olarak çalıştırmanın avantajlarını değerlendirin.
Gemma 3 270M'yi Yerel Olarak Çalıştırmanın Faydaları
Verileri cihazınızda tutarak, maruz kalma riski taşıyan bulut iletimlerinden kaçınarak gizliliği artırırsınız. Gemma 3 270M gecikmeyi azaltır, yanıtları saniyeler yerine milisaniyeler içinde verir. Ayrıca, bulut tabanlı API'ler için abonelik ücretlerinden kaçındığınız için maliyetleri düşürür.
Ek olarak, modelin enerji verimliliği öne çıkmaktadır. INT4 nicemlenmiş modda 25 konuşma için bir Pixel 9 Pro'nun pilinin yalnızca %0,75'ini tüketir. Bu özellik, gücün önemli olduğu mobil ve uç bilişim için uygundur. Ayrıca, LoRA gibi araçlarla ince ayar yaparak modeli kolayca özelleştirebilirsiniz, bu da minimum veri gerektirir.
Yine de, yerel yürütme küçük ekipleri veya bireysel geliştiricileri güçlendirir. E-ticaret sorgu yönlendirme veya yasal metin yapılandırma gibi uygulamalar üzerinde serbestçe deneyler yapabilir, yinelemeler gerçekleştirebilirsiniz. Devam ederken, sisteminizin gereksinimleri karşılayıp karşılamadığını kontrol edin.
Gemma 3 270M Çıkarımı İçin Sistem Gereksinimleri
Gemma 3 270M mütevazı donanım gerektirir, bu da onu erişilebilir kılar. Yalnızca CPU çıkarımı için en az 4GB RAM ve Intel Core i5 veya eşdeğeri gibi modern bir işlemciye ihtiyacınız var. Ancak, GPU hızlandırması hızı artırır; nicemlenmiş sürümler için 2GB VRAM'e sahip bir NVIDIA kartı yeterlidir.
Özellikle, 4 bit modunda, model 200MB belleğe sığar ve sınırlı kaynaklara sahip cihazlarda çalışmasına olanak tanır. Apple silicon kullanıcıları, MLX-LM'den faydalanarak bir M4 Max üzerinde saniyede 650'den fazla jeton elde eder. İnce ayar için, küçük veri kümelerini verimli bir şekilde işlemek üzere 8GB RAM ve 4GB VRAM'e sahip bir GPU ayırın.
Önemli olarak, Windows, macOS veya Linux gibi işletim sistemleri çalışır, ancak kütüphane uyumluluğu için Python 3.10+ olduğundan emin olun. Model dosyaları için yaklaşık 1GB depolama alanı gerekir. Bunlar mevcut olduğunda, sorunsuz bir şekilde kurar ve çalıştırırsınız. Şimdi, kurulum yöntemlerini keşfedin.
Gemma 3 270M'yi Yerel Olarak Çalıştırmak İçin Doğru Aracı Seçmek
Çeşitli çerçeveler Gemma 3 270M'yi destekler, her biri benzersiz güçlü yönler sunar. Hugging Face Transformers, Python betikleme ve entegrasyon için esneklik sağlar. LM Studio, model yönetimi için kullanıcı dostu bir arayüz sunar.
Ek olarak, llama.cpp düşük seviyeli optimizasyon için mükemmel olan verimli C++ tabanlı çıkarım sağlar. Apple cihazlar için MLX, M serisi çiplerde performansı optimize eder. Uzmanlığınıza göre seçim yaparsınız; yeni başlayanlar LM Studio'yu tercih ederken, geliştiriciler Transformers'a yönelir.
Böylece, bu araçlar erişimi demokratikleştirir. Aşağıdaki bölümlerde, popüler yöntemler için adım adım kılavuzları takip edin.
Adım Adım Kılavuz: Hugging Face Transformers ile Gemma 3 270M'yi Çalıştırma
Gerekli kütüphaneleri kurarak başlayın. Terminalinizi açın ve çalıştırın:
pip install transformers torch
Bu komut Transformers ve PyTorch'u getirir. Ardından, bir Python betiğinde bileşenleri içe aktarın:
from transformers import AutoTokenizer, AutoModelForCausalLM
Modeli ve jetonlayıcıyı yükleyin:
model_name = "google/gemma-3-270m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
`device_map="auto"` mevcutsa modeli GPU'ya yerleştirir. Girişinizi hazırlayın:
input_text = "Explain quantum computing in simple terms."
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
Çıktı oluşturun:
outputs = model.generate(**inputs, max_new_tokens=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Bu, tutarlı bir açıklama üretir. Optimize etmek için nicemleme ekleyin:
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
Nicemleme bellek kullanımını azaltır. Kilitli modeller için Hugging Face girişini sağlayarak hataları halledersiniz:
from huggingface_hub import login
login(token="your_hf_token")
Jetonu Hugging Face hesabınızdan alın. Bu kurulumla, çıkarımları tekrar tekrar çalıştırırsınız. Ancak, Python kullanmayanlar için sırada LM Studio'yu düşünün.
Adım Adım Kılavuz: LM Studio ile Gemma 3 270M'yi Çalıştırma
LM Studio sezgisel bir arayüz sağlar. lmstudio.ai adresinden indirin ve kurun.
Uygulamayı başlatın, ardından model merkezinde "gemma-3-270m" araması yapın.
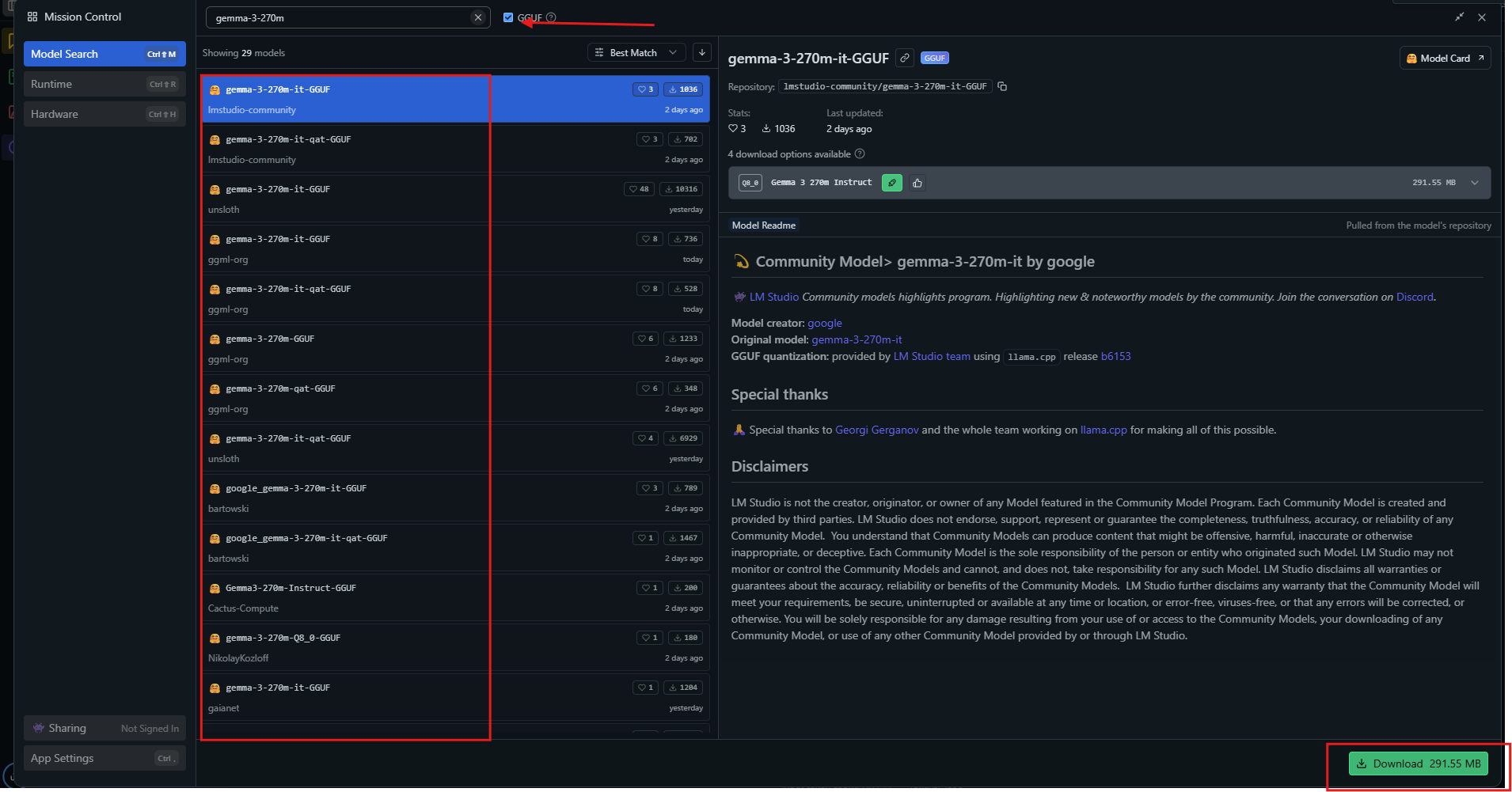
Q4_0 gibi nicemlenmiş bir varyant seçin ve indirin. Hazır olduğunda, modeli kenar çubuğundan yükleyin. Ayarları düzenleyin: bağlamı 32k, sıcaklığı 1.0 olarak ayarlayın.
Sohbet penceresine bir istem girin ve gönder'e basın. LM Studio, jeton hızlarıyla yanıtları görüntüler. Sohbetleri dışa aktarın veya entegre araçlar aracılığıyla ince ayar yapın.
Gelişmiş kullanım için, ayarlarda GPU boşaltmayı etkinleştirin. LM Studio, uyumluluğu sağlayarak en uygun kaynakları otomatik olarak seçer. Bu yöntem görsel öğrenenler için uygundur. Ek olarak, performans ayarlamaları için llama.cpp'yi keşfedin.
Adım Adım Kılavuz: llama.cpp ile Gemma 3 270M'yi Çalıştırma
llama.cpp yüksek verimli çıkarım sunar. Depoyu klonlayın:
git clone https://github.com/ggerganov/llama.cpp
Derleyin:
make -j
Hugging Face'ten GGUF dosyalarını indirin:
huggingface-cli download unsloth/gemma-3-270m-it-GGUF --include "*.gguf"
Çıkarımı çalıştırın:
./llama-cli -m gemma-3-270m-it-Q4_K_M.gguf -p "Build a simple AI app."
Tam GPU kullanımı için --n-gpu-layers 999 gibi parametreleri belirtin. llama.cpp, hız ve doğruluğu dengeleyen nicemleme seviyelerini destekler. NVIDIA GPU'lar için CUDA ile derlersiniz:
make GGML_CUDA=1
Bu, işlemeyi hızlandırır. llama.cpp gömülü sistemlerde üstündür. Şimdi, modeli pratik örneklerde uygulayın.
Gemma 3 270M'yi Yerel Olarak Kullanmanın Pratik Örnekleri
Bir duygu analizcisi oluşturursunuz. Müşteri yorumlarını girin ve model bunları olumlu veya olumsuz olarak sınıflandırır. Python'da betikleyin:
prompt = "Classify: This product is amazing!"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0]))
Gemma 3 270M "Olumlu" çıktısını verir. Özetlemeye genişletin:
text = "Long article here..."
prompt = f"Summarize: {text}"
# Generate summary
İçeriği etkili bir şekilde yoğunlaştırır. Soru yanıtlama için sorgulayın:
"İklim değişikliğine ne sebep olur?"
Model sera gazlarını açıklar. Sağlık hizmetlerinde, notlardan varlıkları çıkarın. Bu kullanımlar çok yönlülüğü gösterir. Ayrıca, uzmanlaşma için ince ayar yapın.
Gemma 3 270M'yi Yerel Olarak İnce Ayarlama
İnce ayar modeli uyarlar. Hugging Face'in PEFT kütüphanesini kullanın:
pip install peft
LoRA yapılandırmasıyla yükleyin:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
Bir veri kümesi hazırlayın, ardından eğitin:
from transformers import Trainer, TrainingArguments
trainer = Trainer(model=model, args=TrainingArguments(output_dir="./results"))
trainer.train()
LoRA az veri gerektirir, mütevazı donanımda hızla tamamlanır. Adaptörü kaydedin ve yeniden yükleyin. Bu, satranç hamlesi tahmini gibi özel görevlerde performansı artırır. Ancak, aşırı uyumu izleyin.
Gemma 3 270M İçin Performans Optimizasyon İpuçları
4 bit veya 8 bit'e nicemleyerek hızı en üst düzeye çıkarırsınız. Birden çok çıkarım için toplu işlem kullanın. Önerildiği gibi sıcaklığı 1.0, top_k=64, top_p=0.95 olarak ayarlayın.
GPU'larda karma hassasiyeti etkinleştirin. Uzun bağlamlar için KV önbelleğini dikkatlice yönetin. nvidia-smi gibi araçlarla VRAM'i izleyin. Optimizasyonlar için kütüphaneleri düzenli olarak güncelleyin.
Sonuç olarak, bu ayarlamalar uygun donanımda saniyede 130'dan fazla jeton sağlar. İstemlerdeki çift BOS jetonları gibi yaygın tuzaklardan kaçının. Pratikle, verimli çalıştırmalar elde edersiniz.
Sonuç
Artık Gemma 3 270M'yi yerel olarak çalıştırma bilgisine sahipsiniz. Kurulumdan optimizasyona kadar her adım yetenek oluşturur. Potansiyelini gerçekleştirmek için deney yapın, ince ayar yapın ve dağıtın. Bunun gibi küçük modeller, yapay zeka erişilebilirliğinde büyük etkiler yaratır.