
Eğer bir PDF'e veya teknik kılavuza doğrudan soru sormayı dilediyseniz, bu rehber tam size göre. Bugün, açık kaynaklı bir akıl yürütme gücü olan Retrieval-Augmented Generation (RAG) sistemini DeepSeek R1 ve yerel yapay zeka modellerini çalıştırmak için hafif bir çerçeve olan Ollama kullanarak oluşturacağız.
API Testinizi Güçlendirmeye Hazır mısınız? Apidog'u kontrol etmeyi unutmayın! Apidog, testler ve sahte sunucular oluşturmak, yönetmek ve çalıştırmak için tek duraklı bir platform görevi görür, darboğazları belirlemenize ve API'lerinizin güvenilir kalmasını sağlar.
Birden fazla araçla uğraşmak veya kapsamlı komut dosyaları yazmak yerine, iş akışınızın kritik bölümlerini otomatikleştirerek, sorunsuz CI/CD boru hatları elde edebilir ve ürün özelliklerinizi cilalamak için daha fazla zaman harcayabilirsiniz.
Bu hayatınızı kolaylaştıracak bir şeye benziyorsa, Apidog'u deneyin!
Bu yazıda, OpenAI'nin o1 performansına rakip olan ancak %95 daha az maliyetli bir model olan DeepSeek R1'in RAG sistemlerinizi nasıl güçlendirebileceğini inceleyeceğiz. Geliştiricilerin neden bu teknolojiye akın ettiğini ve sizin bununla kendi RAG boru hattınızı nasıl oluşturabileceğinizi inceleyelim.
Bu Yerel RAG Sistemi Ne Kadar Maliyetli?
| Bileşen | Maliyet |
|---|---|
| DeepSeek R1 1.5B | Ücretsiz |
| Ollama | Ücretsiz |
| 16GB RAM PC | $0 |
DeepSeek R1'in 1.5B modeli burada parlıyor çünkü:
- Odaklanmış alma: Her cevaba yalnızca 3 belge parçası beslenir
- Sıkı istem: "Bilmiyorum" halüsinasyonları engeller
- Yerel yürütme: Bulut API'lerine karşı sıfır gecikme
İhtiyacınız Olanlar
Kodlamaya başlamadan önce, araç takımlarımızı ayarlayalım:
1. Ollama
Ollama, DeepSeek R1 gibi modelleri yerel olarak çalıştırmanıza olanak tanır.
- İndir: https://ollama.com/
- Kurun, ardından terminalinizi açın ve şunu çalıştırın:
ollama run deepseek-r1 # 7B modeli için (varsayılan)
2. DeepSeek R1 Model Varyantları
DeepSeek R1, 1.5B'den 671B parametreye kadar boyutlarda gelir. Bu demo için, 1.5B modelini kullanacağız—hafif RAG için mükemmel:
ollama run deepseek-r1:1.5b
Profesyonel ipucu: 70B gibi daha büyük modeller daha iyi akıl yürütme sunar ancak daha fazla RAM gerektirir. Küçük başlayın, sonra ölçeklendirin!

RAG Boru Hattını Oluşturma: Kod İncelemesi
Adım 1: Kütüphaneleri İçe Aktar
Şunları kullanacağız:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
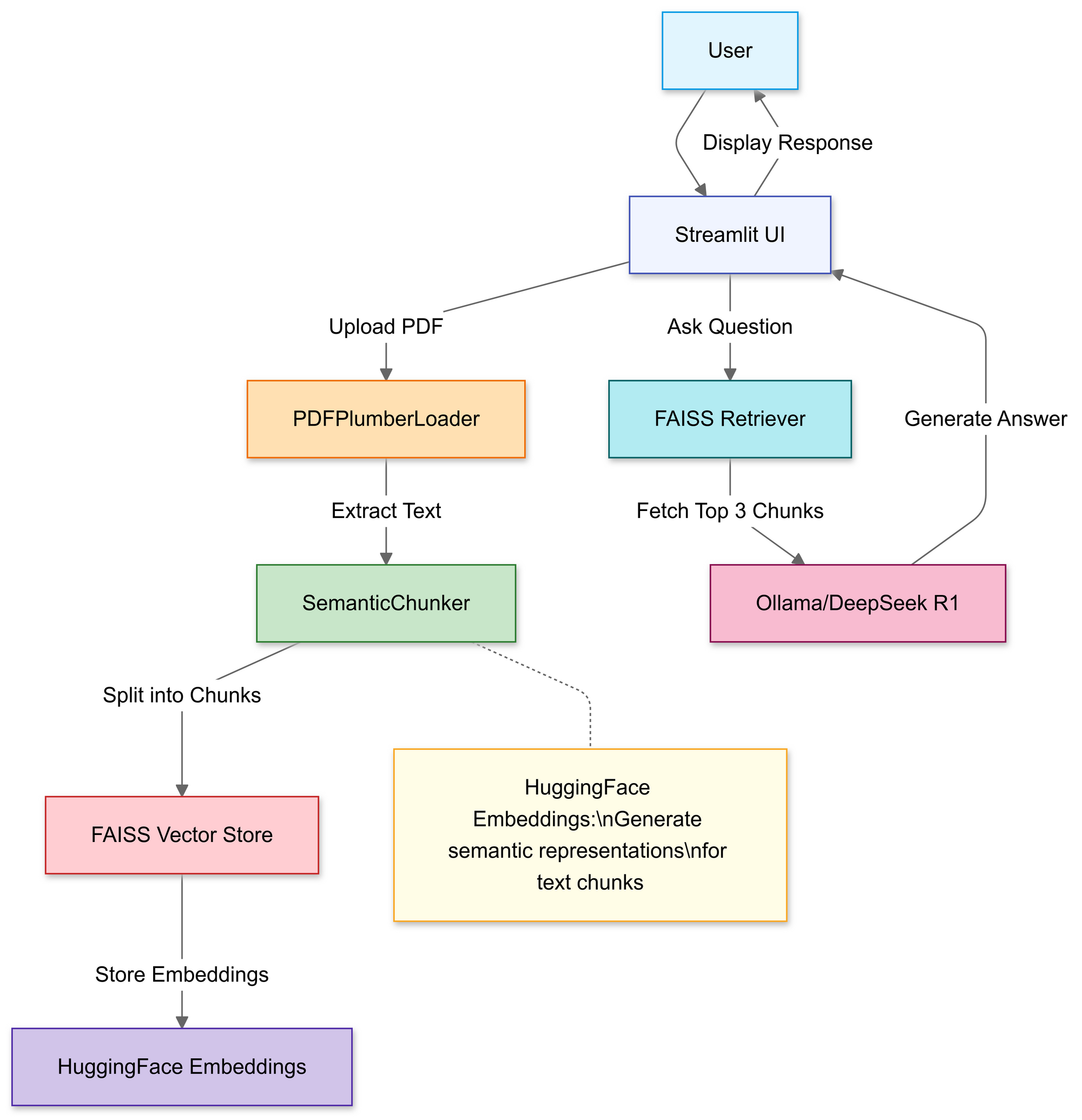
Adım 2: PDF'leri Yükle ve İşle
Bu bölümde, kullanıcıların yerel bir PDF dosyası seçmelerine izin vermek için Streamlit'in dosya yükleyicisini kullanırsınız.
# Streamlit dosya yükleyicisi
uploaded_file = st.file_uploader("Bir PDF dosyası yükleyin", type="pdf")
if uploaded_file:
# PDF'yi geçici olarak kaydet
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# PDF metnini yükle
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
Yüklendikten sonra, PDFPlumberLoader işlevi PDF'den metin çıkarır ve boru hattının sonraki aşamasına hazırlar. Bu yaklaşım uygundur çünkü dosya içeriğini okuma işlemini, kapsamlı manuel ayrıştırma talep etmeden halleder.
Adım 3: Belgeleri Stratejik Olarak Parçalara Ayırın
RecursiveCharacterTextSplitter'ı kullanmak istiyoruz, kod orijinal PDF metnini daha küçük segmentlere (parçalara) ayırır. İşte iyi parçalama ve kötü parçalama kavramlarını açıklayalım:
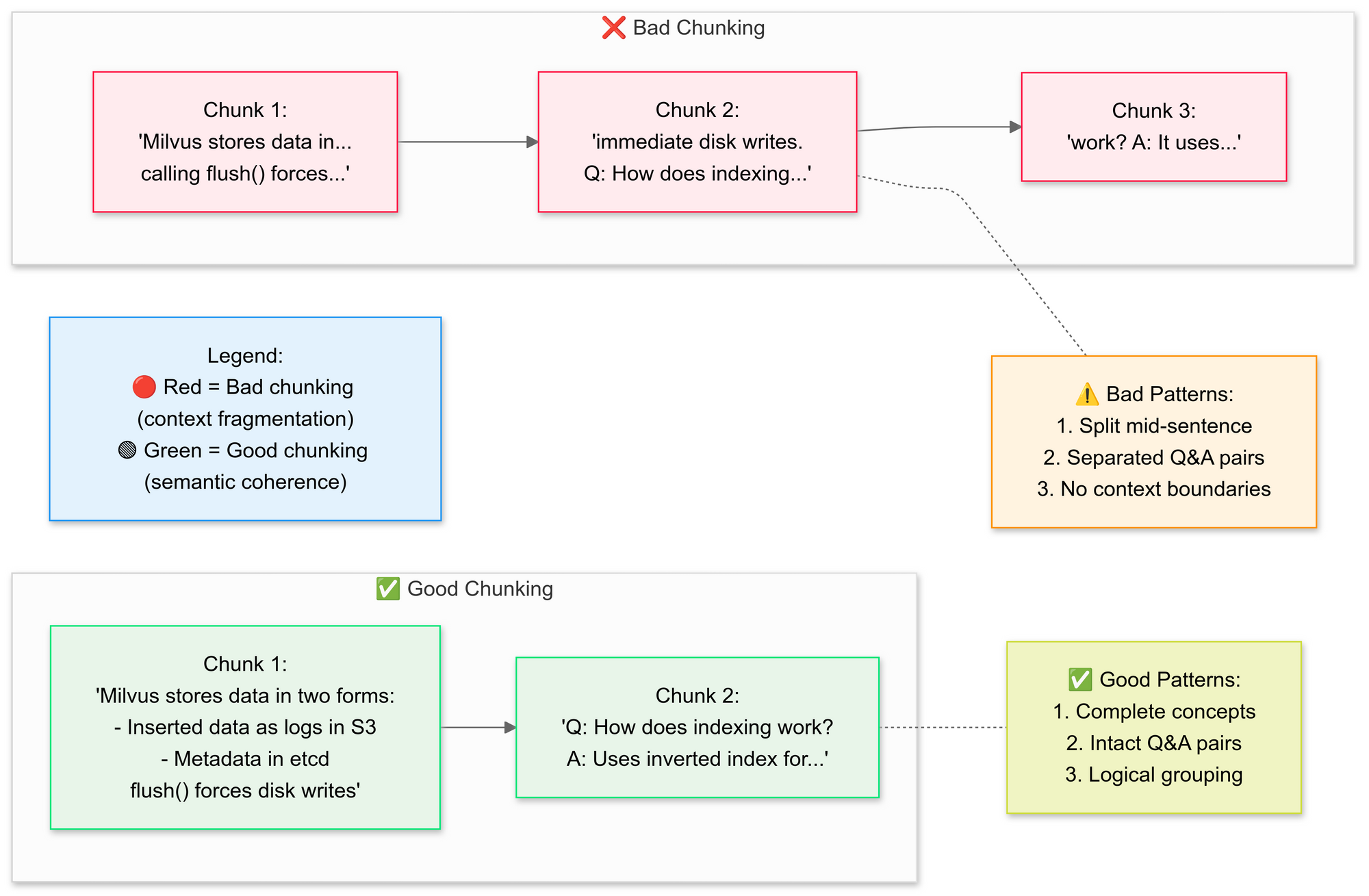
Neden semantik parçalama?
- İlgili cümleleri gruplandırır (örneğin, "Milvus verileri nasıl depolar" bozulmadan kalır)
- Tabloları veya diyagramları bölmekten kaçınır
# Metni semantik parçalara ayırın
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
Bu adım, segmentleri hafifçe üst üste bindirerek bağlamı korur, bu da dil modelinin soruları daha doğru yanıtlamasına yardımcı olur. Küçük, iyi tanımlanmış belge parçaları da aramaları daha verimli ve alakalı hale getirir.
Adım 4: Aranabilir Bir Bilgi Tabanı Oluşturun
Bölündükten sonra, boru hattı segmentler için vektör gömüleri oluşturur ve bunları bir FAISS dizininde depolar.
# Gömüler oluştur
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# Alıcıyı bağla
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # İlk 3 parçayı getir
Bu, metni sorgulaması çok daha kolay olan sayısal bir temsile dönüştürür. Daha sonra, en bağlamsal olarak alakalı parçaları bulmak için bu dizine karşı sorgular çalıştırılır.
Adım 5: DeepSeek R1'i Yapılandırın
Burada, yerel LLM olarak Deepseek R1 1.5B kullanarak bir RetrievalQA zinciri örneği oluşturursunuz.
llm = Ollama(model="deepseek-r1:1.5b") # 1.5B parametre modelimiz
# İstek şablonunu oluştur
prompt = """
1. YALNIZCA aşağıdaki bağlamı kullanın.
2. Emin değilseniz, "Bilmiyorum" deyin.
3. Cevapları 4 cümlenin altında tutun.
Bağlam: {context}
Soru: {question}
Cevap:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
Bu şablon, modeli cevapları PDF'nizin içeriğine dayandırmaya zorlar. Dil modelini FAISS dizinine bağlı bir alıcı ile sararak, zincir aracılığıyla yapılan herhangi bir sorgu, PDF'nin içeriğinden bağlam arayacak ve cevapları kaynak materyale dayandıracaktır.
Adım 6: RAG Zincirini Birleştirin
Ardından, yükleme, parçalama ve alma adımlarını tutarlı bir boru hattında birleştirebilirsiniz.
# Zincir 1: Cevaplar oluştur
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Zincir 2: Belge parçalarını birleştir
document_prompt = PromptTemplate(
template="Bağlam:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
# Son RAG boru hattı
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
Bu, RAG (Retrieval-Augmented Generation) tasarımının özüdür ve büyük dil modeline, tamamen dahili eğitimine güvenmek yerine doğrulanmış bağlam sağlar.
Adım 7: Web Arayüzünü Başlatın
Son olarak, kod, kullanıcıların soruları yazabilmeleri ve yanıtları hemen görüntüleyebilmeleri için Streamlit'in metin girişi ve yazma işlevlerini kullanır.
# Streamlit UI
user_input = st.text_input("PDF'nize bir soru sorun:")
if user_input:
with st.spinner("Düşünüyor..."):
response = qa(user_input)["result"]
st.write(response)
Kullanıcı bir sorgu girer girmez, zincir en iyi eşleşen parçaları alır, bunları dil modeline besler ve bir cevap görüntüler. Langchain kütüphanesi düzgün bir şekilde yüklendiğinde, kod artık eksik modül hatasını tetiklemeden çalışmalıdır.
Sorular sorun ve gönderin ve anında cevap alın!
İşte tam kod:
DeepSeek ile RAG'in Geleceği
Kendi kendini doğrulama ve çok adımlı akıl yürütme gibi geliştirme aşamasındaki özelliklerle, DeepSeek R1 daha da gelişmiş RAG uygulamalarının kilidini açmaya hazırlanıyor. Sadece soruları yanıtlamakla kalmayıp, kendi mantığını da tartışan bir yapay zeka hayal edin—otonom olarak.


