
Qwen3 gibi büyük dil modelleri (LLM'ler), kodlama, muhakeme ve doğal dil anlama konusundaki etkileyici yetenekleriyle yapay zeka dünyasında devrim yaratıyor. Alibaba'daki Qwen ekibi tarafından geliştirilen Qwen3, verimli yerel dağıtım sağlayan nicelleştirilmiş modeller sunarak, geliştiricilerin, araştırmacıların ve meraklıların bu güçlü modelleri kendi donanımlarında çalıştırmasını mümkün kılıyor. İster Ollama, LM Studio veya vLLM kullanıyor olun, bu kılavuz sizi Qwen3 nicelleştirilmiş modellerini yerel olarak kurma ve çalıştırma sürecinde yönlendirecektir.
Bu teknik kılavuzda, kurulum sürecini, model seçimini, dağıtım yöntemlerini ve API entegrasyonunu inceleyeceğiz. Hadi başlayalım.
Qwen3 Nicelleştirilmiş Modelleri Nelerdir?
Qwen3, kodlama, matematik ve genel muhakeme gibi görevlerde yüksek performans için tasarlanmış, Alibaba'nın en yeni nesil LLM'leridir. BF16, FP8, GGUF, AWQ ve GPTQ formatlarındaki nicelleştirilmiş modeller, hesaplama ve bellek gereksinimlerini azaltarak, bunları tüketici sınıfı donanımlarda yerel dağıtım için ideal hale getirir.
Qwen3 ailesi çeşitli modeller içerir:
- Qwen3-235B-A22B (MoE): BF16, FP8, GGUF ve GPTQ-int4 formatlarında bir uzmanlar karışımı modeli.
- Qwen3-30B-A3B (MoE): Benzer nicelleştirme seçeneklerine sahip başka bir MoE varyantı.
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense): BF16, FP8, GGUF, AWQ ve GPTQ-int8 formatlarında mevcut yoğun modeller.
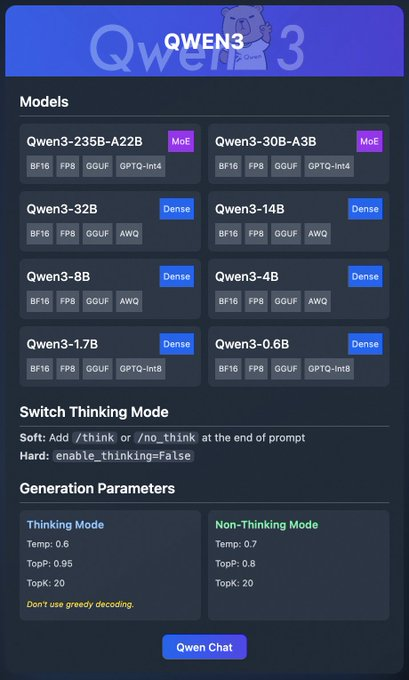
Bu modeller, Ollama, LM Studio ve vLLM gibi platformlar aracılığıyla esnek dağıtımı destekler; bunları ayrıntılı olarak ele alacağız. Ek olarak, Qwen3, daha iyi muhakeme için açılıp kapatılabilen "düşünme modu" ve çıktı kalitesini ince ayar yapmak için oluşturma parametreleri gibi özellikler sunar.
Temel bilgileri anladığımıza göre, Qwen3'ü yerel olarak çalıştırmanın önkoşullarına geçelim.
Qwen3'ü Yerel Olarak Çalıştırmanın Önkoşulları
Qwen3 nicelleştirilmiş modellerini dağıtmadan önce, sisteminizin aşağıdaki gereksinimleri karşıladığından emin olun:
Donanım:
- Modern bir CPU veya GPU (vLLM için NVIDIA GPU'ları önerilir).
- Qwen3-4B gibi daha küçük modeller için en az 16GB RAM; Qwen3-32B gibi daha büyük modeller için 32GB veya daha fazlası.
- Yeterli depolama alanı (örneğin, Qwen3-235B-A22B GGUF ~150GB gerektirebilir).
Yazılım:
- Uyumlu bir işletim sistemi (Windows, macOS veya Linux).
- vLLM ve API etkileşimleri için Python 3.8+.
- Docker (isteğe bağlı, vLLM için).
- Depoları klonlamak için Git.
Bağımlılıklar:
torch,transformersvevllm(vLLM için) gibi gerekli kitaplıkları yükleyin.- Resmi web sitelerinden Ollama veya LM Studio ikili dosyalarını indirin.
Bu önkoşullar yerine getirildikten sonra, Qwen3 nicelleştirilmiş modellerini indirmeye geçelim.
Adım 1: Qwen3 Nicelleştirilmiş Modellerini İndirin
İlk olarak, nicelleştirilmiş modelleri güvenilir kaynaklardan indirmeniz gerekir. Qwen ekibi, Hugging Face ve ModelScope üzerinde Qwen3 modelleri sağlar
- Hugging Face: Qwen3 Koleksiyonu
- ModelScope: Qwen3 Koleksiyonu
Hugging Face'ten Nasıl İndirilir
- Hugging Face Qwen3 koleksiyonunu ziyaret edin.
- Hafif dağıtım için GGUF formatında Qwen3-4B gibi bir model seçin.
- "İndir" düğmesini tıklayın veya model dosyalarını getirmek için
git clonekomutunu kullanın:
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- Model dosyalarını
/models/qwen3-4b-ggufgibi bir dizinde saklayın.
ModelScope'tan Nasıl İndirilir
- ModelScope Qwen3 koleksiyonuna gidin.
- İstediğiniz modeli ve nicelleştirme formatını (örneğin, AWQ veya GPTQ) seçin.
- Dosyaları manuel olarak indirin veya programlı erişim için API'lerini kullanın.
Modeller indirildikten sonra, bunları Ollama kullanarak nasıl dağıtacağımızı inceleyelim.
Adım 2: Ollama Kullanarak Qwen3'ü Dağıtın
Ollama , LLM'leri minimum kurulumla yerel olarak çalıştırmak için kullanıcı dostu bir yol sunar. Qwen3'ün GGUF formatını destekler ve bu da onu yeni başlayanlar için ideal hale getirir.
Ollama'yı Yükleyin
- Ollama'nın resmi web sitesini ziyaret edin ve işletim sisteminiz için ikili dosyayı indirin.
- Yükleyiciyi çalıştırarak veya komut satırı talimatlarını izleyerek Ollama'yı yükleyin:
curl -fsSL https://ollama.com/install.sh | sh
- Yüklemeyi doğrulayın:
ollama --version
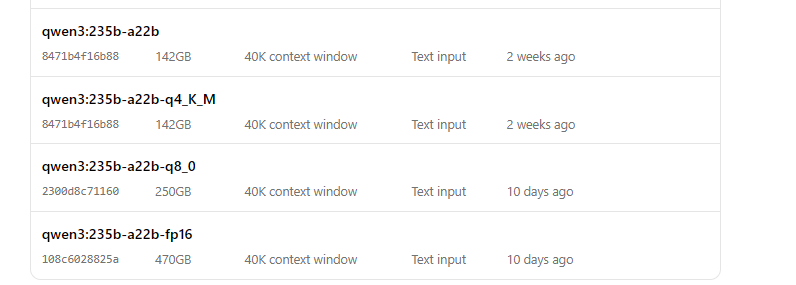
Ollama ile Qwen3'ü Çalıştırın
- Modeli başlatın:
ollama run qwen3:235b-a22b-q8_0- Model çalıştıktan sonra, komut satırı aracılığıyla onunla etkileşim kurabilirsiniz:
>>> Merhaba, bugün size nasıl yardımcı olabilirim?
Ollama ayrıca, programlı erişim için yerel bir API uç noktası (genellikle http://localhost:11434) sağlar; bunu daha sonra Apidog kullanarak test edeceğiz.
Şimdi, Qwen3'ü çalıştırmak için LM Studio'yu nasıl kullanacağımızı inceleyelim.
Adım 3: LM Studio Kullanarak Qwen3'ü Dağıtın
LM Studio, LLM'leri yerel olarak çalıştırmak için popüler bir araçtır ve model yönetimi için grafik bir arayüz sunar.
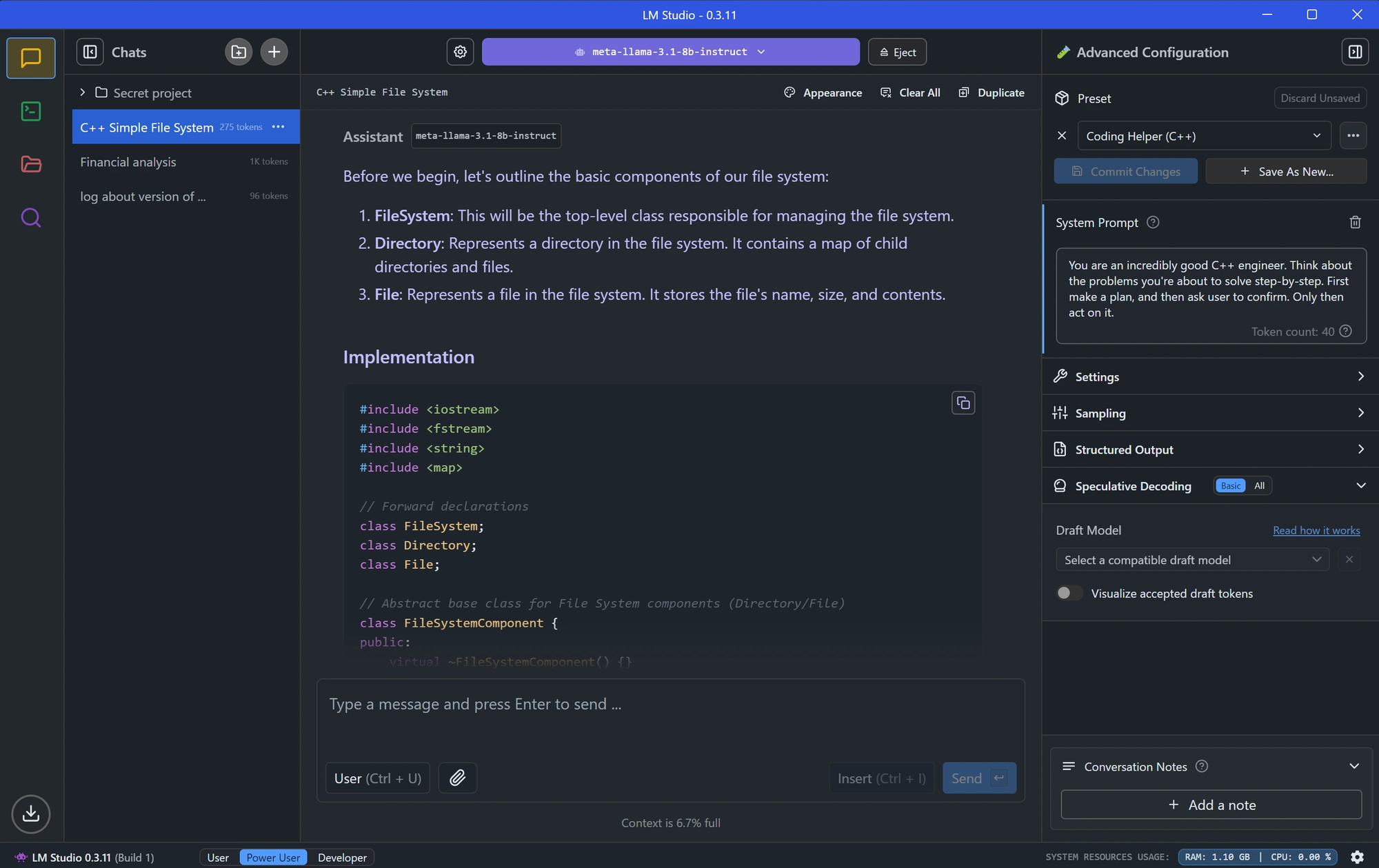
LM Studio'yu Yükleyin
- LM Studio'yu resmi web sitesinden indirin.
- Ekrandaki talimatları izleyerek uygulamayı yükleyin.
- LM Studio'yu başlatın ve çalıştığından emin olun.
LM Studio'da Qwen3'ü Yükleyin
LM Studio'da, "Yerel Modeller" bölümüne gidin.
"Model Ekle"ye tıklayın ve indirmek için modeli arayın:
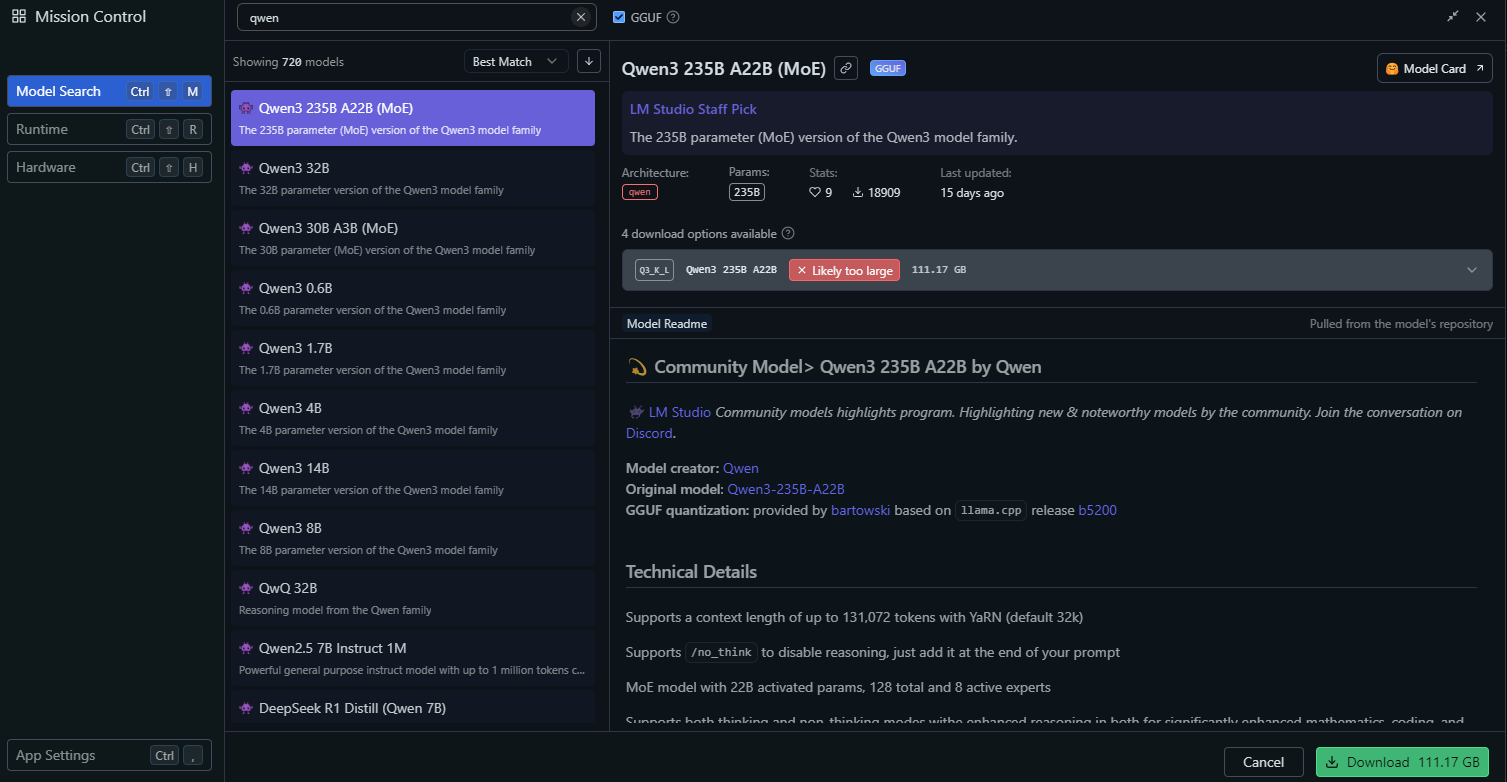
Model ayarlarını yapılandırın, örneğin:
- Sıcaklık: 0.6
- Top-P: 0.95
- Top-K: 20
Bu ayarlar, Qwen3'ün önerilen düşünme modu parametreleriyle eşleşir.
"Sunucuyu Başlat"a tıklayarak model sunucusunu başlatın. LM Studio, yerel bir API uç noktası sağlayacaktır (örneğin, http://localhost:1234).
LM Studio'da Qwen3 ile Etkileşim Kurun
- Modeli test etmek için LM Studio'nun yerleşik sohbet arayüzünü kullanın.
- Alternatif olarak, API test bölümünde inceleyeceğimiz modelin API uç noktası aracılığıyla modele erişin.
LM Studio kurulduktan sonra, vLLM kullanarak daha gelişmiş bir dağıtım yöntemine geçelim.
Adım 4: vLLM Kullanarak Qwen3'ü Dağıtın
vLLM , Qwen3'ün FP8 ve AWQ nicelleştirilmiş modellerini destekleyen, LLM'ler için optimize edilmiş yüksek performanslı bir hizmet çözümüdür. Sağlam uygulamalar geliştiren geliştiriciler için idealdir.
vLLM'yi Yükleyin
- Sisteminizde Python 3.8+ yüklü olduğundan emin olun.
- Pip kullanarak vLLM'yi yükleyin:
pip install vllm
- Yüklemeyi doğrulayın:
python -c "import vllm; print(vllm.__version__)"
vLLM ile Qwen3'ü Çalıştırın
Qwen3 modelinizle bir vLLM sunucusu başlatın
# Modeli yükleyin ve çalıştırın:
vllm serve "Qwen/Qwen3-235B-A22B"--enable-thinking=False bayrağı, Qwen3'ün düşünme modunu devre dışı bırakır.
Sunucu başladığında, http://localhost:8000 adresinde bir API uç noktası sağlayacaktır.
Optimal Performans için vLLM'yi Yapılandırın
vLLM, aşağıdakiler gibi gelişmiş yapılandırmaları destekler:
- Tensör Paralelliği: GPU kurulumunuza göre
--tensor-parallel-size'ı ayarlayın. - Bağlam Uzunluğu: Qwen3,
--max-model-len 32768aracılığıyla ayarlanabilen 32.768'e kadar belirteci destekler. - Oluşturma Parametreleri:
temperature,top_pvetop_k'yi ayarlamak için API'yi kullanın (örneğin, düşünme modu olmayan için 0.7, 0.8, 20).
vLLM çalışırken, Apidog kullanarak API uç noktasını test edelim.
Adım 5: Apidog ile Qwen3 API'sini Test Edin
Apidog, API uç noktalarını test etmek için güçlü bir araçtır ve yerel olarak dağıtılan Qwen3 modelinizle etkileşim kurmak için mükemmeldir.
Apidog'u Kurun
- Apidog'u resmi web sitesinden indirin ve yükleyin.
- Apidog'u başlatın ve yeni bir proje oluşturun.
Ollama API'sini Test Edin
- Apidog'da yeni bir API isteği oluşturun.
- Uç noktayı
http://localhost:11434/api/generateolarak ayarlayın. - İsteği yapılandırın:
- Yöntem: POST
- Gövde (JSON):
{
"model": "qwen3-4b",
"prompt": "Merhaba, bugün size nasıl yardımcı olabilirim?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- İsteği gönderin ve yanıtı doğrulayın.
vLLM API'sini Test Edin
- Apidog'da başka bir API isteği oluşturun.
- Uç noktayı
http://localhost:8000/v1/completionsolarak ayarlayın. - İsteği yapılandırın:
- Yöntem: POST
- Gövde (JSON):
{
"model": "qwen3-4b-awq",
"prompt": "Faktöriyel hesaplamak için bir Python betiği yazın.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- İsteği gönderin ve çıktıyı kontrol edin.
Apidog, Qwen3 dağıtımınızı doğrulamayı ve API'nin doğru çalıştığından emin olmayı kolaylaştırır. Şimdi, modelin performansını ince ayar yapalım.
Adım 6: Qwen3 Performansını İnce Ayar Yapın
Qwen3'ün performansını optimize etmek için, kullanım durumunuza göre aşağıdaki ayarları yapın:
Düşünme Modu
Qwen3, X gönderi görüntüsünde vurgulandığı gibi, gelişmiş muhakeme için bir "düşünme modu"nu destekler. Bunu iki şekilde kontrol edebilirsiniz:
- Yumuşak Geçiş: İsteminize
/thinkveya/no_thinkekleyin.
- Örnek:
Bu matematik problemini çöz /think.
- Sert Geçiş:
--enable-thinking=Falseile vLLM'de düşünmeyi tamamen devre dışı bırakın.
Oluşturma Parametreleri
Daha iyi çıktı kalitesi için oluşturma parametrelerini ince ayar yapın:
- Sıcaklık: Düşünme modu için 0.6 veya düşünme modu olmayan için 0.7 kullanın.
- Top-P: 0.95 (düşünme) veya 0.8 (düşünme olmayan) olarak ayarlayın.
- Top-K: Her iki mod için de 20 kullanın.
- Qwen ekibi tarafından önerildiği gibi açgözlü kod çözmeyi önleyin.
Yaratıcılık ve doğruluk arasında istenen dengeyi elde etmek için bu ayarları deneyin.
Yaygın Sorunları Giderme
Qwen3'ü dağıtırken bazı sorunlarla karşılaşabilirsiniz. İşte yaygın sorunlara çözümler:
Model Ollama'da Yüklenemiyor:
Modelfile'daki GGUF dosya yolunun doğru olduğundan emin olun.- Sisteminizin modeli yüklemek için yeterli belleğe sahip olup olmadığını kontrol edin.
vLLM Tensör Paralelliği Hatası:
- "output_size, weight quantization block_n tarafından bölünemiyor" gibi bir hata görürseniz,
--tensor-parallel-size'ı azaltın (örneğin, 4'e).
Apidog'da API İsteği Başarısız Oluyor:
- Sunucunun (Ollama, LM Studio veya vLLM) çalıştığını doğrulayın.
- Uç nokta URL'sini ve istek yükünü iki kez kontrol edin.
Bu sorunları ele alarak, sorunsuz bir dağıtım deneyimi sağlayabilirsiniz.
Sonuç
Qwen3 nicelleştirilmiş modellerini yerel olarak çalıştırmak, Ollama, LM Studio ve vLLM gibi araçlarla basit bir işlemdir. Uygulamalar geliştiren bir geliştirici veya LLM'lerle deneyler yapan bir araştırmacı olmanız fark etmez, Qwen3 ihtiyacınız olan esnekliği ve performansı sunar. Bu kılavuzu izleyerek, Hugging Face ve ModelScope'tan model indirmeyi, bunları çeşitli çerçeveler kullanarak dağıtmayı ve Apidog ile API uç noktalarını test etmeyi öğrendiniz.
Projeleriniz için yerel LLM'lerin gücünü açığa çıkarmak için bugün Qwen3'ü keşfetmeye başlayın!


