
Alibaba'nın Qwen ekibi, Qwen2.5-VL-32B-Instruct modelini piyasaya sürerek yapay zeka sınırlarını bir kez daha zorladı. Bu model, hem daha akıllı hem de daha hafif olmayı vaat eden çığır açan bir vizyon-dil modelidir (VLM).
24 Mart 2025'te duyurulan bu 32 milyar parametreli model, performans ve verimlilik arasında optimum bir denge kurarak, onu geliştiriciler ve araştırmacılar için ideal bir seçim haline getiriyor. Qwen2.5-VL serisinin başarısı üzerine inşa edilen bu yeni sürüm, matematiksel muhakeme, insan tercih uyumu ve vizyon görevlerinde önemli gelişmeler sunarken, yerel dağıtım için yönetilebilir bir boyutu koruyor.
Bu güçlü modeli projelerine entegre etmek isteyen geliştiriciler için, sağlam API araçlarını keşfetmek esastır. Bu nedenle, ücretsiz olarak Apidog'u indirmenizi öneriyoruz; Qwen gibi modelleri uygulamalarınıza test etmeyi ve entegre etmeyi basitleştiren, kullanıcı dostu bir API geliştirme platformu. Apidog ile Qwen API'si ile sorunsuz bir şekilde etkileşim kurabilir, iş akışlarını kolaylaştırabilir ve bu yenilikçi VLM'nin tüm potansiyelini ortaya çıkarabilirsiniz. Apidog'u bugün indirin ve daha akıllı uygulamalar oluşturmaya başlayın!
Bu API aracı, modelinizin uç noktalarını zahmetsizce test etmenizi ve hata ayıklamanızı sağlar. Apidog'u bugün ücretsiz indirin ve Mistral Small 3.1'in yeteneklerini keşfederken iş akışınızı kolaylaştırın!
Qwen2.5-VL-32B: Daha Akıllı Bir Vizyon-Dil Modeli
Qwen2.5-VL-32B'yi Eşsiz Yapan Nedir?
Qwen2.5-VL-32B, Qwen ailesindeki hem daha büyük hem de daha küçük modellerin sınırlamalarını gidermek için tasarlanmış 32 milyar parametreli bir vizyon-dil modeli olarak öne çıkıyor. Qwen2.5-VL-72B gibi 72 milyar parametreli modeller sağlam yetenekler sunarken, genellikle önemli hesaplama kaynakları gerektirir ve bu da onları yerel dağıtım için pratik olmaktan çıkarır. Tersine, 7 milyar parametreli modeller, daha hafif olsalar da, karmaşık görevler için gereken derinlikten yoksun olabilirler. Qwen2.5-VL-32B, daha yönetilebilir bir ayak izi ile yüksek performans sunarak bu boşluğu dolduruyor.
Bu model, çok modlu yetenekleriyle geniş çapta beğeni toplayan Qwen2.5-VL serisi üzerine kuruludur. Ancak, Qwen2.5-VL-32B, takviyeli öğrenme (RL) yoluyla optimizasyon dahil olmak üzere kritik geliştirmeler sunuyor. Bu yaklaşım, modelin insan tercihlerine uyumunu iyileştirerek daha ayrıntılı, kullanıcı dostu çıktılar sağlıyor. Ek olarak, model, karmaşık problem çözme ve veri analizi içeren görevler için hayati bir özellik olan üstün matematiksel muhakeme yeteneği sergiliyor.

Temel Teknik Geliştirmeler
Qwen2.5-VL-32B, çıktı stilini iyileştirmek için takviyeli öğrenmeden yararlanarak, yanıtları daha tutarlı, ayrıntılı ve daha iyi insan etkileşimi için biçimlendirilmiş hale getiriyor. Ayrıca, matematiksel muhakeme yetenekleri, MathVista ve MMMU gibi kıyaslamalardaki performansıyla kanıtlandığı gibi, önemli ölçüde iyileştirildi. Bu geliştirmeler, özellikle metin ve görsel verilerin kesiştiği çok modlu bağlamlarda, doğruluk ve mantıksal çıkarıma öncelik veren ince ayarlı eğitim süreçlerinden kaynaklanmaktadır.
Model ayrıca, grafikler, çizelgeler ve belgeler gibi görsel içeriğin hassas analizini sağlayarak, ince taneli görüntü anlama ve muhakeme konusunda da mükemmeldir. Bu yetenek, Qwen2.5-VL-32B'yi gelişmiş görsel mantık çıkarımı ve içerik tanıma gerektiren uygulamalar için en iyi aday konumuna getiriyor.
Qwen2.5-VL-32B Performans Kıyaslamaları: Daha Büyük Modellerden Daha İyi Performans
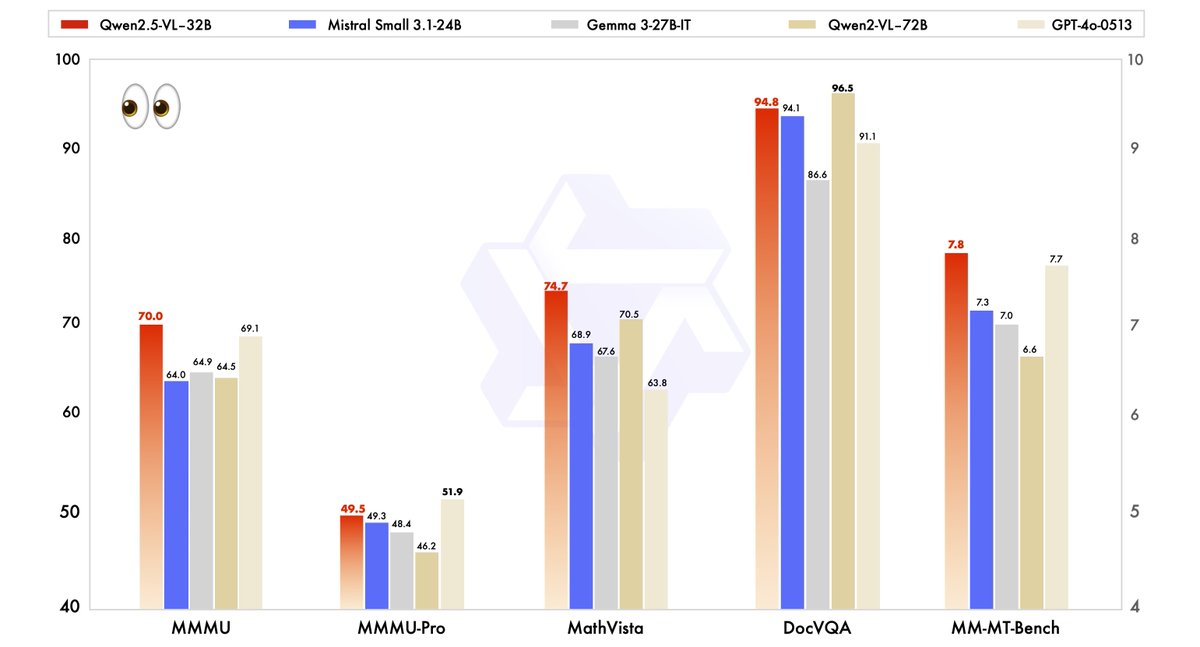
Qwen2.5-VL-32B'nin performansı, daha büyük kardeşi Qwen2.5-VL-72B'nin yanı sıra Mistral-Small-3.1–24B ve Gemma-3–27B-IT gibi rakipler de dahil olmak üzere, son teknoloji modellere karşı titizlikle değerlendirildi. Sonuçlar, modelin birkaç temel alandaki üstünlüğünü vurgulamaktadır.
- MMMU (Massive Multitask Language Understanding): Qwen2.5-VL-32B, Qwen2.5-VL-72B'nin 64,5'ini aşarak 70,0 puanına ulaşıyor. Bu kıyaslama, çeşitli görevlerde karmaşık, çok adımlı muhakemeyi test ederek, modelin gelişmiş bilişsel yeteneklerini gösteriyor.
- MathVista: 74,7 puanıyla Qwen2.5-VL-32B, matematiksel ve görsel muhakeme görevlerindeki gücünü vurgulayarak, Qwen2.5-VL-72B'nin 70,5'ini geride bırakıyor.
- MM-MT-Bench: Bu öznel kullanıcı deneyimi değerlendirme kıyaslaması, Qwen2.5-VL-32B'nin selefini önemli bir farkla geride bıraktığını gösteriyor ve gelişmiş insan tercih uyumunu yansıtıyor.
- Metin Tabanlı Görevler (örneğin, MMLU, MATH, HumanEval): Model, daha küçük parametre sayısına rağmen, MMLU'da 78,4, MATH'da 82,2 ve HumanEval'da 91,5 puan alarak, GPT-4o-Mini gibi daha büyük modellerle etkili bir şekilde rekabet ediyor.
Bu kıyaslamalar, Qwen2.5-VL-32B'nin yalnızca daha büyük modellerin performansına uymakla kalmayıp, aynı zamanda genellikle onları aştığını ve tüm bunları daha az hesaplama kaynağı gerektirerek yaptığını gösteriyor. Bu güç ve verimlilik dengesi, onu sınırlı donanımla çalışan geliştiriciler ve araştırmacılar için cazip bir seçenek haline getiriyor.
Neden Boyut Önemli: 32B Avantajı
Qwen2.5-VL-32B'nin 32 milyar parametreli boyutu, yerel dağıtım için uygun bir nokta yakalıyor. Kapsamlı GPU kaynakları talep eden 72B modellerin aksine, bu daha hafif model, ilgili web sonuçlarında belirtildiği gibi, SGLang ve vLLM gibi çıkarım motorlarıyla sorunsuz bir şekilde entegre olur. Bu uyumluluk, daha hızlı dağıtım ve daha düşük bellek kullanımı sağlar ve onu, yeni başlayanlardan büyük işletmelere kadar daha geniş bir kullanıcı yelpazesi için erişilebilir hale getirir.
Ayrıca, modelin hız ve verimlilik için optimizasyonu, yeteneklerinden ödün vermez. Nesneleri tanıma, çizelgeleri analiz etme ve faturalar ve tablolar gibi yapılandırılmış çıktıları işleme gibi çok modlu görevleri ele alma yeteneği sağlam kalır ve onu gerçek dünya uygulamaları için çok yönlü bir araç olarak konumlandırır.

Qwen2.5-VL-32B'yi MLX ile Yerel Olarak Çalıştırma
Bu güçlü modeli Apple Silicon ile Mac'inizde yerel olarak çalıştırmak için şu adımları izleyin:
Sistem Gereksinimleri
- Apple Silicon (M1, M2 veya M3 çip) ile bir Mac
- En az 32GB RAM (64GB önerilir)
- 60GB+ boş depolama alanı
- macOS Sonoma veya daha yenisi
Kurulum Adımları
- Python bağımlılıklarını yükleyin
pip install mlx mlx-llm transformers pillow
- Modeli indirin
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- Modeli MLX formatına dönüştürün
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- Model ile etkileşim kurmak için basit bir komut dosyası oluşturun
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# Modeli yükle
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# Bir resim yükle
image = Image.open("path/to/your/image.jpg")
# Resimle bir istem oluştur
prompt = "Bu resimde ne görüyorsunuz?"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
Pratik Uygulamalar: Qwen2.5-VL-32B'den Yararlanma
Vizyon Görevleri ve Ötesi
Qwen2.5-VL-32B'nin gelişmiş görsel yetenekleri, çok çeşitli uygulamaların kapılarını açıyor. Örneğin, gezinme veya veri çıkarma gibi görevleri gerçekleştirmek için bilgisayar veya telefon arayüzleriyle dinamik olarak etkileşim kuran bir görsel temsilci olarak hizmet edebilir. Uzun videoları (bir saate kadar) anlama ve ilgili segmentleri belirleme yeteneği, video analizi ve zamansal lokalizasyondaki faydasını daha da artırır.
Belge ayrıştırmada, model, el yazısı metinler, tablolar, çizelgeler ve kimyasal formüller dahil olmak üzere çok sahne, çok dilli içeriği işleme konusunda mükemmeldir. Bu, yapılandırılmış verilerin doğru bir şekilde çıkarılmasının kritik olduğu finans, eğitim ve sağlık gibi sektörler için paha biçilmez hale getirir.
Metin ve Matematiksel Muhakeme
Vizyon görevlerinin ötesinde, Qwen2.5-VL-32B, özellikle matematiksel muhakeme ve kodlama içeren metin tabanlı uygulamalarda parlıyor. MATH ve HumanEval gibi kıyaslamalardaki yüksek puanları, karmaşık cebirsel problemleri çözme, fonksiyon grafiklerini yorumlama ve doğru kod parçacıkları oluşturma konusundaki yeterliliğini gösteriyor. Vizyon ve metindeki bu ikili yeterlilik, Qwen2.5-VL-32B'yi çok modlu yapay zeka zorlukları için bütünsel bir çözüm olarak konumlandırıyor.

Qwen2.5-VL-32B'yi Nerede Kullanabilirsiniz?
Açık Kaynak ve API Erişimi
Qwen2.5-VL-32B, Apache 2.0 lisansı altında mevcuttur ve dünya çapındaki geliştiriciler için açık kaynaklı ve erişilebilir hale getirir. Modele çeşitli platformlar aracılığıyla erişebilirsiniz:
- Hugging Face: Model, Hugging Face'de barındırılıyor, burada yerel kullanım için indirebilir veya Transformers kitaplığı aracılığıyla entegre edebilirsiniz.
- ModelScope: Alibaba'nın ModelScope platformu, modele erişmek ve dağıtmak için başka bir yol sunuyor.
Sorunsuz entegrasyon için, geliştiriciler modelle etkileşimi basitleştiren Qwen API'sini kullanabilirler. İster özel bir uygulama oluşturuyor olun, ister çok modlu görevlerle denemeler yapıyor olun, Qwen API'si verimli bağlantı ve sağlam performans sağlar.
Çıkarım Motorlarıyla Dağıtım
Qwen2.5-VL-32B, SGLang ve vLLM gibi çıkarım motorlarıyla dağıtımı destekler. Bu araçlar, modeli hızlı çıkarım için optimize ederek, gecikmeyi ve bellek kullanımını azaltır. Bu motorlardan yararlanan geliştiriciler, modeli yerel donanım veya bulut platformlarında dağıtabilir ve belirli kullanım durumlarına göre uyarlayabilirler.
Başlamak için, gerekli kitaplıkları (örneğin, transformers, vllm) yükleyin ve Qwen GitHub sayfası veya Hugging Face belgelerindeki talimatları izleyin. Bu işlem, modelin tüm potansiyelinden yararlanmanıza olanak tanıyarak sorunsuz bir entegrasyon sağlar.
Yerel Performansı Optimize Etme
Qwen2.5-VL-32B'yi yerel olarak çalıştırırken, şu optimizasyon ipuçlarını göz önünde bulundurun:
- Kuantizasyon: Bellek gereksinimlerini azaltmak için dönüştürme sırasında
--quantizebayrağını ekleyin - Bağlam uzunluğunu yönetin: Daha hızlı yanıtlar için giriş belirteçlerini sınırlayın
- Modeli çalıştırırken kaynak yoğun uygulamaları kapatın
- Toplu işleme: Birden fazla görüntü için, bunları tek tek yerine toplu olarak işleyin
Sonuç: Qwen2.5-VL-32B Neden Önemli?
Qwen2.5-VL-32B, vizyon-dil modellerinin evriminde önemli bir kilometre taşını temsil ediyor. Daha akıllı muhakemeyi, daha hafif kaynak gereksinimlerini ve sağlam performansı birleştirerek, bu 32 milyar parametreli model, hem geliştiricilerin hem de araştırmacıların ihtiyaçlarını karşılıyor. Matematiksel muhakeme, insan tercih uyumu ve vizyon görevlerindeki geliştirmeleri, onu yerel dağıtım ve gerçek dünya uygulamaları için en iyi seçim haline getiriyor.
İster eğitim araçları, ister iş zekası sistemleri veya müşteri destek çözümleri oluşturuyor olun, Qwen2.5-VL-32B ihtiyacınız olan çok yönlülüğü ve verimliliği sunar. Açık kaynak platformlar ve Qwen API'si aracılığıyla erişim sayesinde, bu modeli projelerinize entegre etmek hiç olmadığı kadar kolay. Qwen ekibi yenilik yapmaya devam ettikçe, çok modlu yapay zekanın geleceğinde daha da heyecan verici gelişmeler bekleyebiliriz.
Bu API aracı, modelinizin uç noktalarını zahmetsizce test etmenizi ve hata ayıklamanızı sağlar. Apidog'u bugün ücretsiz indirin ve Mistral Small 3.1'in yeteneklerini keşfederken iş akışınızı kolaylaştırın!


