
Alibaba'nın açık temel model girişimi Qwen, hızlı yinelemeler ve sürümler aracılığıyla yapay zekanın sınırlarını sürekli olarak zorluyor. Geliştiriciler ve araştırmacılar her güncellemeyi hevesle bekliyorlar, çünkü Qwen modelleri genellikle performans ve çok yönlülükte yeni standartlar belirliyor. Yakın zamanda Qwen, üç yenilikçi model yayınladı: Qwen-Image-Edit-2509, Qwen3-TTS-Flash ve Qwen3-Omni. Bu sürümler sırasıyla görüntü düzenleme, metinden konuşmaya sentezleme ve çok modlu işleme yeteneklerini geliştiriyor.
Dahası, bu modeller, çok modlu entegrasyonun pratik uygulamalar için vazgeçilmez hale geldiği yapay zeka geliştirme açısından kritik bir anda ortaya çıkıyor. Qwen-Image-Edit-2509, hassas görsel manipülasyonlara olan talebi karşılarken, Qwen3-TTS-Flash ses üretimindeki gecikme sorunlarını gideriyor. Bu arada, Qwen3-Omni'nin tanıtımı, farklı girdileri tek bir tutarlı çerçevede birleştiriyor. Hep birlikte, Qwen'in erişilebilir, yüksek performanslı yapay zekaya olan bağlılığını gösteriyorlar. Ancak, teknik temellerini anlamak daha yakından bir inceleme gerektiriyor. Bu makale, her modeli özelliklerini, mimarilerini, kıyaslamalarını ve potansiyel etkilerini vurgulayarak inceliyor.
Qwen-Image-Edit-2509: Görüntü Düzenleme Hassasiyetini Yükseltiyor
Qwen-Image-Edit-2509, yapay zeka destekli görüntü manipülasyonunda önemli bir ilerlemeyi temsil ediyor. Qwen mühendisleri, görsel içerik üzerinde ayrıntılı kontrol gerektiren içerik oluşturucular, tasarımcılar ve geliştiriciler için bu modeli yeniden inşa ettiler. Önceki yinelemelerin aksine, bu sürüm çoklu görüntü düzenlemeyi destekleyerek kullanıcıların bir kişiyi bir ürünle veya bir sahneyi zahmetsizce birleştirmesine olanak tanıyor. Sonuç olarak, uyumsuz karışımlar gibi yaygın artefaktları ortadan kaldırarak tutarlı çıktılar üretiyor.

Model, tek görüntü tutarlılığında üstün başarı gösteriyor. Reklamcılık ve kişiselleştirme uygulamaları için paha biçilmez olan pozlar, stiller ve filtreler arasında yüz kimliklerini koruyor. Ürün görselleri için Qwen-Image-Edit-2509, nesne bütünlüğünü koruyarak düzenlemelerin temel nitelikleri bozmadığından emin oluyor. Ek olarak, metin öğelerini kapsamlı bir şekilde ele alarak içerik, yazı tipleri, renkler ve hatta dokularda değişiklik yapılmasına olanak tanıyor. Bu çok yönlülük, hassas rehberlik için derinlik haritaları, kenar algılama ve anahtar noktaları içeren entegre ControlNet mekanizmalarından kaynaklanıyor.
Teknik olarak, Qwen-Image-Edit-2509, temel Qwen-Image mimarisi üzerine inşa edilmiştir ancak gelişmiş eğitim tekniklerini içerir. Geliştiriciler, çoklu görüntü girişlerini kolaylaştırmak için görüntü birleştirme yöntemleri kullanarak onu eğittiler. Örneğin, "kişi + kişi" veya "kişi + sahne" birleştirmesi, birleştirilmiş veri akışlarından yararlanarak modelin farklı görselleri birleştirme yeteneğini geliştirir. Ayrıca, mimari, rafine görüntüler oluşturmak için gürültünün kademeli olarak kaldırıldığı difüzyon tabanlı süreçleri entegre eder. Sabit difüzyon varyantlarında yaygın olan bu yaklaşım, kullanıcı istemlerine dayalı koşullu üretim sağlar.
Kıyaslamalar açısından, Qwen-Image-Edit-2509, tutarlılık metriklerinde üstün performans sergiliyor. Dahili değerlendirmeler, yüz korumasında rakiplerinden daha iyi performans gösterdiğini ve çeşitli düzenlemelerde %95'i aşan benzerlik puanları elde ettiğini gösteriyor. Ürün tutarlılığı kıyaslamaları, minimum bozulmayı ortaya koyarak e-ticaret için ideal hale getiriyor. Ancak, yakın zamanda piyasaya sürülmesi nedeniyle harici kaynaklardan nicel veriler sınırlı kalmaktadır. Bununla birlikte, Hugging Face gibi platformlardaki kullanıcı gösterileri, çoklu öğe karıştırmada Stable Diffusion XL gibi modellere göre üstünlüğünü vurgulamaktadır.
Qwen-Image-Edit-2509 için uygulamalar çoktur. Pazarlamacılar, ürün yerleşimlerini sorunsuz bir şekilde düzenleyerek özelleştirilmiş reklamlar oluşturmak için kullanır. Tasarımcılar, manuel rötuş yapmadan sahneleri değiştirerek hızlı prototipleme için kullanır. Ayrıca, oyunlarda dinamik varlık üretimini kolaylaştırır. Açıklayıcı bir örnek, bir kişinin kıyafetini dönüştürmeyi içerir: gündelik kıyafetli bir kadının giriş görüntüsü, siyah bir elbise referansıyla birleştirildiğinde, elbisenin duruşu ve aydınlatmayı koruyarak doğal bir şekilde oturduğu bir çıktı verir. Görsel demoların gösterdiği gibi bu yetenek, pratik faydasının altını çizmektedir.


Uygulamaya geçişte, geliştiriciler Qwen-Image-Edit-2509'a GitHub depoları ve Hugging Face alanları aracılığıyla erişirler. Kurulum genellikle depoyu klonlamayı ve PyTorch gibi bağımlılıkları kurmayı içerir. Temel bir kullanım betiği şöyle görünebilir:
import torch
from qwen_image_edit import QwenImageEdit
model = QwenImageEdit.from_pretrained("Qwen/Qwen-Image-Edit-2509")
input_image = load_image("person.jpg")
reference_image = load_image("dress.jpg")
output = model.edit_multi(input_image, reference_image, prompt="Apply the black dress to the person")
output.save("edited.jpg")
Böyle bir kod, hızlı yinelemeler sağlar. Ancak, kullanıcılar hesaplama gereksinimlerini göz önünde bulundurmalıdır, çünkü çıkarım optimum hız için GPU hızlandırması gerektirir.
Güçlü yönlerine rağmen, Qwen-Image-Edit-2509 zorluklarla karşılaşıyor. Yüksek çözünürlüklü düzenlemeler önemli miktarda bellek tüketebilir ve karmaşık istemler ara sıra tutarsızlıklara yol açabilir. Bununla birlikte, açık kaynak kanalları aracılığıyla devam eden topluluk katkıları bu sorunları hafifletmektedir. Genel olarak, bu model hassasiyeti erişilebilirlikle birleştirerek görüntü düzenlemeyi yeniden tanımlıyor.
Qwen3-TTS-Flash: Metinden Konuşmaya Sentezlemeyi Hızlandırıyor
Qwen3-TTS-Flash, hız ve doğallığı önceliklendiren metinden konuşmaya (TTS) teknolojisinde bir güç merkezi olarak ortaya çıkıyor. Qwen mühendisleri, gerçek zamanlı uygulamalardaki darboğazları gidererek, minimum gecikmeyle insan benzeri sesler sunmak için tasarladılar. Özellikle, tek iş parçacıklı ortamlarda sadece 97ms'lik ilk paket gecikmesi elde ederek sohbet robotlarında ve sanal asistanlarda akıcı etkileşimler sağlıyor.
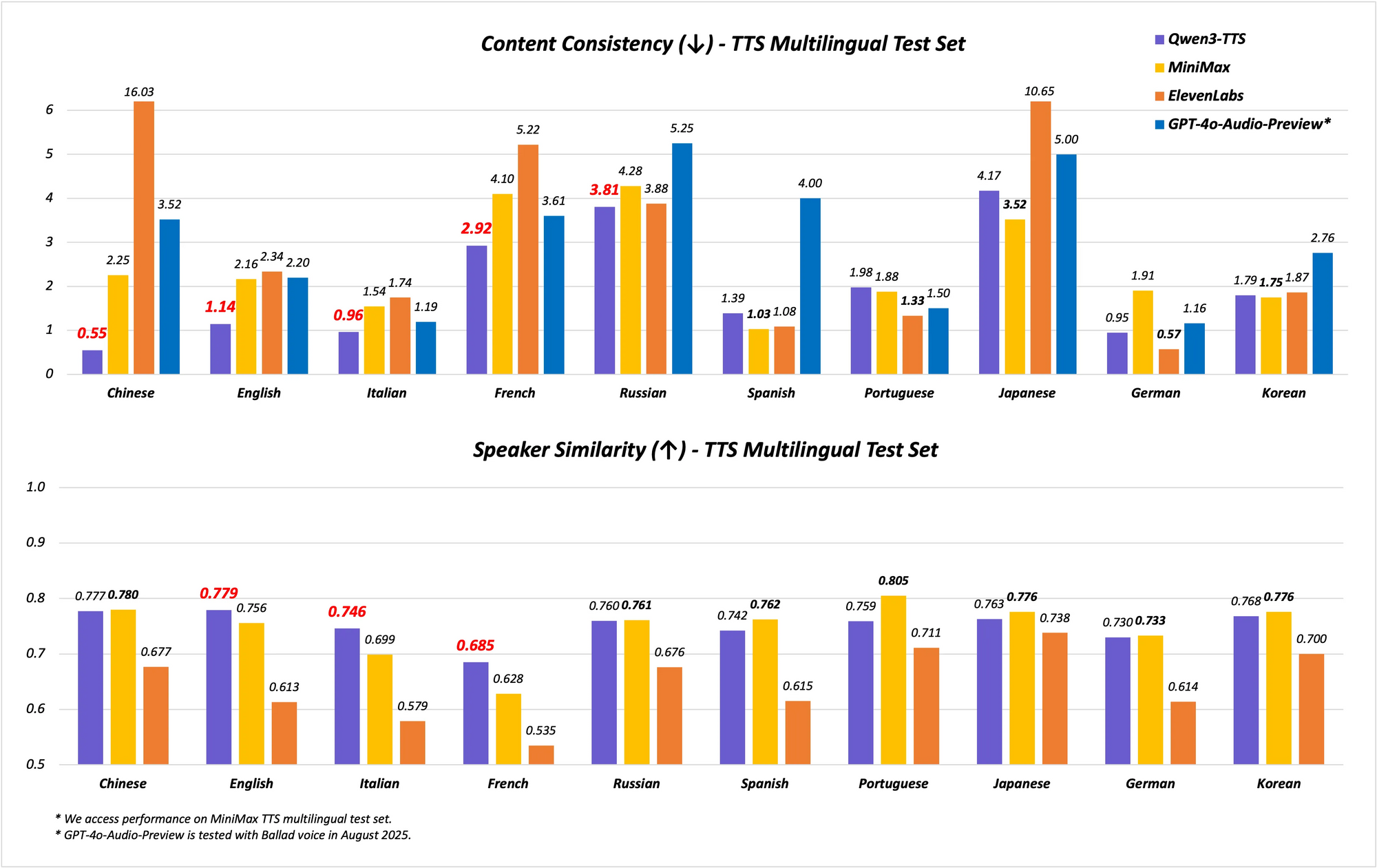
Model, 17 etkileyici sesle 10 dili kapsayan çok dilli ve çok lehçeli yetenekleri destekliyor. Çince ve İngilizce kararlılığında üstün başarı göstererek Seed-TTS-Eval test seti gibi kıyaslamalarda son teknoloji (SOTA) performansına ulaşıyor. Burada, kararlılık metriklerinde SeedTTS, MiniMax ve GPT-4o-Audio-Preview gibi modelleri geride bırakıyor. Ayrıca, MiniMax TTS test setindeki çok dilli değerlendirmelerde, Qwen3-TTS-Flash, Çince, İngilizce, İtalyanca ve Fransızca için en düşük Kelime Hata Oranını (WER) kaydediyor.
Lehçe desteği, Qwen3-TTS-Flash'ı farklı kılıyor. Kantonca, Hokkien, Siçuanese, Pekin, Nanjing, Tianjin ve Shaanxi dahil olmak üzere dokuz Çince lehçesini işliyor. Bu özellik, farklı pazarlarda kültürel olarak nüanslı konuşma için temeldir. Ek olarak, model, giriş duygusuna uyacak şekilde geniş ölçekli eğitim verilerinden yararlanarak tonları otomatik olarak ayarlar. Sağlam metin işleme, tarihler, sayılar ve kısaltmalar gibi karmaşık biçimlerden anahtar bilgileri çıkararak güvenilirliği daha da artırır.
Mimari olarak, Qwen3-TTS-Flash, düşük gecikmeli çıkarım için optimize edilmiş transformatör tabanlı bir kodlayıcı-kod çözücü çerçevesi kullanır. Daha zengin ses modellemesi için çoklu kod defteri temsilleri kullanır ve ifade gücünü artırır. Eğitim, metin için 119 dil ve konuşma anlayışı için 19 dil içeren geniş veri kümelerini içeriyordu, ancak çıktı 10 dile odaklanıyor. Bu kurulum, bir dildeki girdilerin başka bir dilde sorunsuz çıktılar üretmesini sağlayan diller arası üretim sağlar.

Kıyaslamalar, yeteneğini gösteriyor. Kararlılık testlerinde, Qwen3-TTS-Flash, ElevenLabs ve GPT-4o'ya kıyasla tını benzerliği ve doğallıkta daha yüksek puanlar alıyor. Örneğin:
| Kıyaslama | Qwen3-TTS-Flash | MiniMax | GPT-4o-Audio-Preview |
|---|---|---|---|
| Çince Kararlılık | SOTA | Daha Düşük | Daha Düşük |
| İngilizce WER | En Düşük | Daha Yüksek | Daha Yüksek |
| Çok Dilli Tını Benzerliği | SOTA | Daha Düşük | Daha Düşük |
Bu sonuçlar, onu TTS'de lider konumuna getiren titiz değerlendirmelerden kaynaklanmaktadır.
Gösterilerde, Qwen3-TTS-Flash, "ballı lavantalı latte"yi coşkuyla anlatmak veya lehçelerde diyalogları ele almak gibi etkileyici konuşmalar üretiyor. Video transkriptleri, "Bugün gerçekten mutluyum. O kızı Çin'den tanıyorum," gibi karma dilli girdileri aksanlı seslerle işleme yeteneğini ortaya koyuyor. Uygulamalar arasında etkileşimli sesli yanıt (IVR) sistemleri, oyun NPC'leri ve düşük gecikmenin verimliliği ikiye katladığı içerik oluşturma yer alıyor.
Uygulama, modele API'ler veya Hugging Face demoları aracılığıyla erişim gerektirir. Örnek bir Python çağrısı:
from qwen_tts import QwenTTSFlash
model = QwenTTSFlash.from_pretrained("Qwen/Qwen3-TTS-Flash")
audio = model.synthesize(text="Hello, world!", voice="expressive_english", dialect="sichuanese")
audio.save("output.wav")
Bu basitlik, geliştirmeyi hızlandırır. Ancak, lehçe doğruluğu nadir girdilerle değişebilir ve ince ayar gerektirebilir.
Qwen3-TTS-Flash, hızı, kaliteyi ve çeşitliliği dengeleyerek TTS'yi dönüştürüyor ve modern yapay zeka sistemleri için vazgeçilmez hale getiriyor.
Qwen3-Omni Tanıtımı: Birleşik Çok Modlu Güç Merkezi
Qwen3-Omni'nin tanıtımı, çok modlu yapay zekada bir dönüm noktasıdır, çünkü Qwen metin, görüntü, ses ve videoyu tek bir uçtan uca modele entegre ediyor. Bu yerel birleşme, modalite ödünleşmelerini önleyerek daha derin çapraz modlu akıl yürütmeyi sağlıyor. Model, metin için 119 dil, ses girişi için 19 dil ve ses çıkışı için 10 dil işliyor ve yanıtlar için dikkat çekici bir 211ms gecikme süresine sahip.
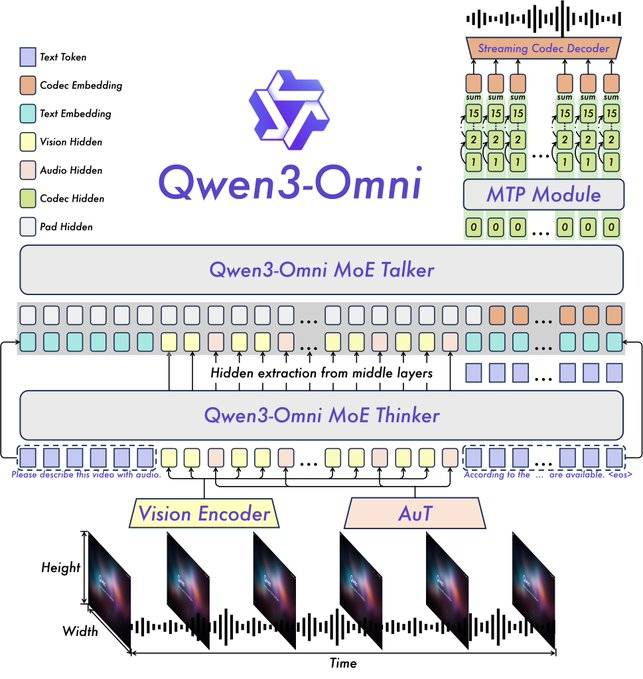
Temel özellikler arasında 36 ses ve görsel-işitsel kıyaslamadan 22'sinde SOTA performansı, özelleştirilebilir sistem istemleri, yerleşik araç çağırma ve düşük halüsinasyon oranlarına sahip açık kaynaklı bir altyazı modeli bulunuyor. Qwen, talimat takibi için Qwen3-Omni-30B-A3B-Instruct ve gelişmiş akıl yürütme için Qwen3-Omni-30B-A3B-Thinking gibi açık kaynaklı varyantları yayınladı.
Mimari, Qwen2.5-Omni'den Thinker-Talker çerçevesi üzerine inşa edilmiştir ve daha iyi temsil için Whisper ses kodlayıcısını bir Ses Transformatörü (AuT) ile değiştirme gibi yükseltmeler içerir. Çoklu kod defteri ses işleme, ses çıkışını zenginleştirirken, genişletilmiş bağlam 30 dakikadan fazla sesi destekler. Bu, video girişlerinin sesli yanıtları bilgilendirdiği tam modlu akıl yürütmeyi sağlar.
Kıyaslamalar, üstünlüğünü doğruluyor. 32 kıyaslamada genel SOTA'ya ulaşarak ses anlama ve üretiminde üstün başarı gösteriyor. Örneğin, görsel-işitsel görevlerde, gecikme ve doğruluk açısından GPT-4o gibi modelleri geride bırakıyor. Bir karşılaştırma tablosu:
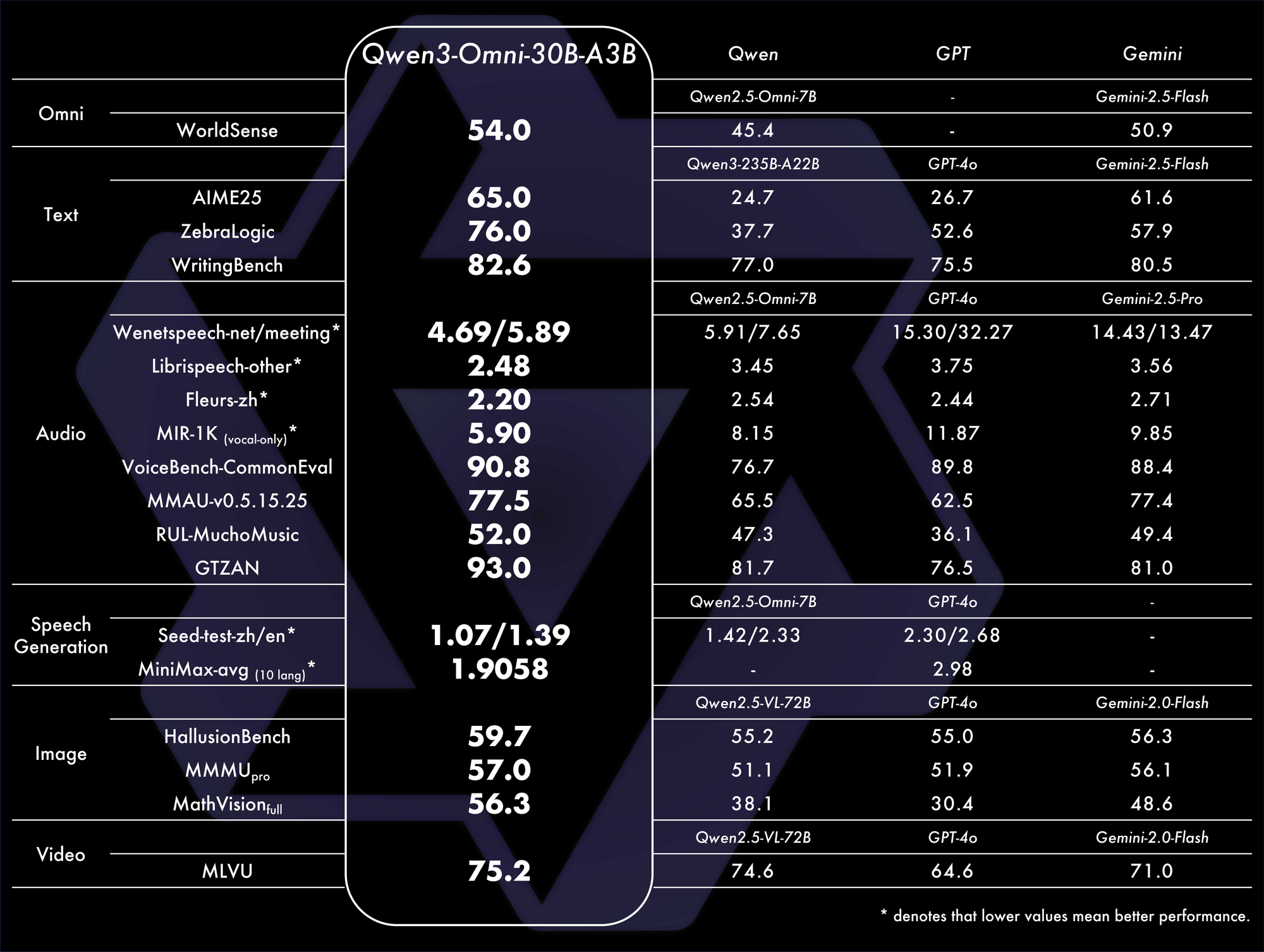
Bu metrikler, gerçek dünya senaryolarındaki verimliliğini vurgulamaktadır.
Uygulamalar sesli sohbet, video analizi ve çok modlu aracılara kadar uzanır. Örneğin, bir video klibi analiz eder ve erişilebilirlik araçları için ideal olan sözlü özetler oluşturur. Qwen Chat'teki demolar, kullanıcıların görüntüleri veya sesleri sözlü olarak sorguladığı sesli ve görüntülü etkileşimleri sergiliyor.
GitHub'dan README, onu farklı girdilerden gerçek zamanlı konuşma üretme yeteneğine sahip olarak tanımlıyor. Kurulum şunları içerir:
from qwen_omni import Qwen3Omni
model = Qwen3Omni.from_pretrained("Qwen/Qwen3-Omni-30B-A3B-Instruct")
response = model.process(inputs={"text": "Describe this", "image": "img.jpg", "audio": "clip.wav"})
print(response.text)
response.audio.save("reply.wav")
Bu modüler yaklaşım, özelleştirmeyi kolaylaştırır. Zorluklar arasında video işleme için yüksek hesaplama gereksinimleri bulunur, ancak niceleme gibi optimizasyonlar yardımcı olur.
Qwen3-Omni'nin tanıtımı, yenilikçi yapay zeka ekosistemlerini teşvik ederek modaliteleri birleştiriyor.
Qwen'in Yeni Modelleri Arasındaki Sinerjiler ve Gelecekteki Etkileri
Qwen-Image-Edit-2509, Qwen3-TTS-Flash ve Qwen3-Omni birbirini tamamlayarak uçtan uca iş akışlarını mümkün kılıyor. Örneğin, Qwen-Image-Edit-2509 ile bir görüntüyü düzenleyin, Qwen3-Omni aracılığıyla açıklayın ve çıktıyı Qwen3-TTS-Flash ile seslendirin. Bu entegrasyon, içerik oluşturma ve otomasyonda faydayı artırıyor.
Ayrıca, açık kaynaklı doğaları topluluk geliştirmelerini davet ediyor. Apidog kullanan geliştiriciler, sağlam entegrasyonlar sağlayarak API'leri verimli bir şekilde test edebilirler.
Ancak, deepfake'lerde kötüye kullanım gibi etik hususlar ortaya çıkıyor. Qwen bunu güvenlik önlemleriyle hafifletiyor.
Sonuç olarak, Qwen'in yeni sürümleri yapay zeka manzaralarını yeniden tanımlıyor. Teknik sınırları zorlayarak, kullanıcıları daha fazlasını başarmaları için güçlendiriyorlar. Benimsenme arttıkça, bu modeller bir sonraki inovasyon dalgasını yönlendirecek.