
Büyük dil modellerinin (LLM'ler) manzarası nefes kesici bir hızla gelişiyor. Sadece parametre sayısını artırmanın ötesinde, önde gelen araştırma laboratuvarları giderek muhakeme, karmaşık problem çözme ve verimlilik gibi belirli yetenekleri geliştirmeye odaklanıyor. Tsinghua Üniversitesi'nin Bilgi Mühendisliği Grubu (KEG) ve Zhipu AI (THUDM), özellikle GLM (Genel Dil Modeli) serileriyle bu gelişmelerin ön saflarında yer alıyor. GLM-4-32B-0414'ün ve daha sonraki özel varyantlarının – GLM-Z1-32B-0414, GLM-Z1-Rumination-32B-0414 ve şaşırtıcı derecede güçlü GLM-Z1-9B-0414 – tanıtımı, temel gücü hedeflenen geliştirmelerle birleştiren sofistike bir stratejiyi sergileyerek bu yönde önemli bir adımı işaret ediyor.
Geliştirici Ekibinizin birlikte maksimum verimlilikle çalışması için entegre, Hepsi Bir Arada bir platform mu istiyorsunuz?
Apidog tüm taleplerinizi karşılıyor ve Postman'in yerini çok daha uygun bir fiyata alıyor!

Temel: GLM-4-32B-0414
Sağlanan metin, türetilmiş 'Z1' modellerine yoğun bir şekilde odaklanırken, temel olan GLM-4-32B-0414'ü anlamak çok önemlidir. 32 milyar parametreli bir model olarak, LLM pazarının oldukça rekabetçi bir segmentinde yer almaktadır. Bu boyuttaki modeller tipik olarak, çok çeşitli görevlerde güçlü performans ile yüz milyarlarca veya trilyonlarca parametreye sahip devasa modellerle karşılaştırıldığında yönetilebilir hesaplama gereksinimleri arasında bir denge kurmayı amaçlar.
THUDM'nin iki dilli (Çince-İngilizce) modellerle geçmişi göz önüne alındığında, GLM-4-32B'nin her iki dilde de sağlam yeteneklere sahip olması muhtemeldir. Eğitimi, metin ve kod dahil olmak üzere geniş veri kümelerini içerecek ve metin oluşturma, çeviri, özetleme, soru yanıtlama ve temel kodlama yardımı gibi görevleri gerçekleştirmesini sağlayacaktır. '0414' soneki, devam eden geliştirme ve iyileştirmeyi gösteren belirli bir sürümü veya eğitim kontrol noktasını gösteriyor olabilir.
GLM-4-32B-0414, daha özel Z1 serisi için temel bir sıçrama tahtası görevi görür. Hedeflenen yeteneklerin üzerine inşa edilebileceği güçlü, genelci bir temel temsil eder. Standart ölçütlerdeki performansı muhtemelen güçlü olacak ve uzmanlaşma gerçekleşmeden önce yüksek bir temel oluşturacaktır. Bunu, gelişmiş, uzmanlaşmış eğitim için hazır, çok yönlü bir mezun olarak düşünün.
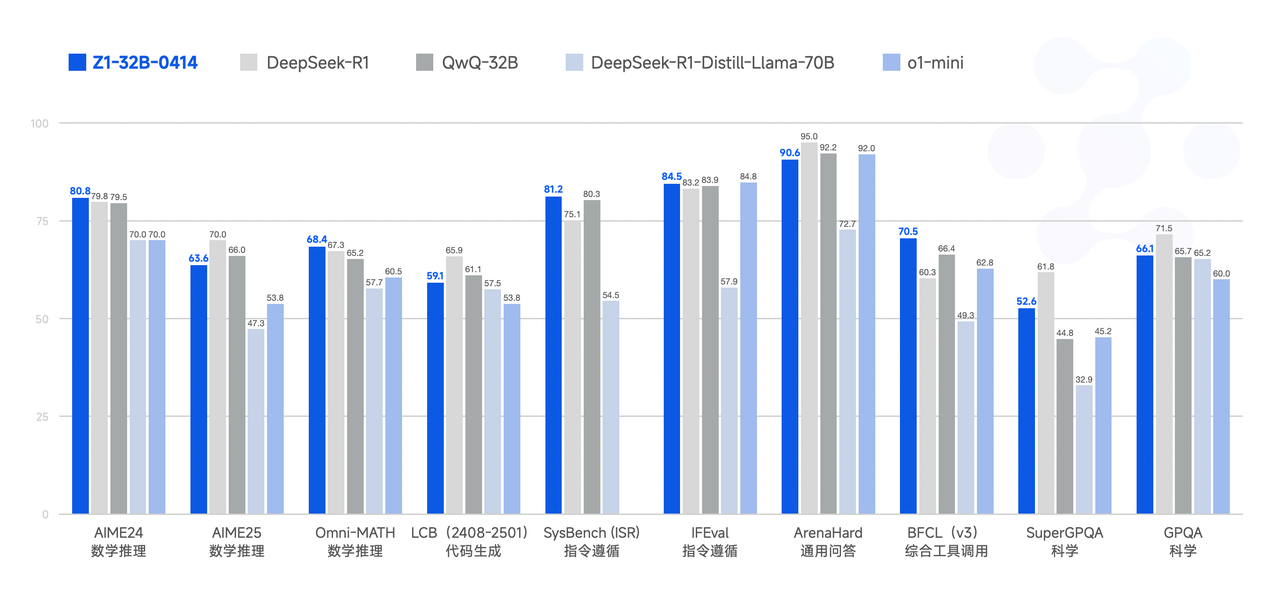
GLM-Z1-32B-0414: Muhakeme Kenarını Keskinleştirmek
İlk özel varyant olan GLM-Z1-32B-0414, özellikle teknik alanlarda modelin "derin düşünme" ve muhakeme yeteneklerini önemli ölçüde artırmaya yönelik odaklanmış bir çabayı temsil eder. Açıklanan geliştirme süreci çok yönlüdür ve gelişmiş ince ayar metodolojilerine işaret etmektedir:
- Cold Start (Soğuk Başlangıç): Bu ilgi çekici terim, uzmanlaşma sürecini yalnızca temel GLM-4-32B'yi ince ayar yaparak değil, aynı zamanda ağırlıklarını yeni, farklı muhakeme yollarının öğrenilmesini teşvik etmek için potansiyel olarak belirli katmanları veya iyileştiricileri sıfırlayarak, yalnızca mevcut olanları kademeli olarak iyileştirmek yerine yeni bir eğitim aşaması için daha akıllı bir başlatma noktası olarak kullanarak başlatmayı önerir.
- Genişletilmiş Takviyeli Öğrenme (RL): Standart RLHF (İnsan Geri Bildiriminden Takviyeli Öğrenme) modelleri insan tercihlerine göre hizalar. "Genişletilmiş" RL, daha uzun eğitim süreleri, daha sofistike ödül modelleri veya özellikle çok adımlı muhakeme süreçlerini geliştirmek için tasarlanmış yeni RL algoritmaları anlamına gelebilir. Amaç, modele yalnızca makul cevaplar vermeyi değil, mantıksal adımları takip etmeyi, örtük varsayımları belirlemeyi ve karmaşık talimatları işlemeyi öğretmektir.
- Belirli Görevler Üzerine Daha Fazla Eğitim: Matematik, kod ve mantığı açıkça hedeflemek, modelin bu alanlarda zenginleştirilmiş, küratörlü veri kümeleri üzerinde ince ayarlandığını gösterir. Bu, matematiksel teoremleri ve problem kümelerini (GSM8K, MATH veri kümeleri gibi), kod depolarını ve programlama problemlerini (HumanEval, MBPP gibi) ve mantıksal muhakeme bulmacalarını içerebilir. Bu doğrudan maruz kalma, modeli bu zorlu alanlara özgü kalıpları ve yapıları içselleştirmeye zorlar.
- Çift Yönlü Sıralama Geri Bildirimine Dayalı Genel RL: Bu katman, uzmanlaşmanın genel yeterlilik pahasına gelmemesini sağlamayı amaçlar. Çift yönlü karşılaştırmalar (genel istemler için iki yanıttan hangisinin daha iyi olduğuna karar vermek) kullanarak, model genel yeteneklerinin genişliğini korurken aynı zamanda muhakeme zirvelerini keskinleştirir. Bu, felaket unutmayı önler ve genel faydalılığı ve tutarlılığı korur.
Belirtilen sonuç, matematiksel yeteneklerde ve karmaşık görevleri çözmede önemli bir iyileşmedir. Bu, GLM-Z1-32B-0414'ün aşağıdakiler gibi ölçütlerde önemli ölçüde daha yüksek puanlar göstereceğini gösterir:
- GSM8K: Çok adımlı aritmetik muhakeme gerektiren İlkokul Matematik problemleri.
- MATH: Zorlu yarışma matematik problemleri.
- HumanEval / MBPP: İşlevsel doğruluğu test eden Python kod oluşturma görevleri.
- Mantık Ölçütleri: Tümdengelimli, tümevarımsal ve çıkarımsal muhakemeyi içeren testler.
Temel GLM-4-32B ile karşılaştırıldığında, Z1-32B'nin bu alanlarda belirgin yüzdesel kazançlar göstermesi ve potansiyel olarak bu tür odaklanmış muhakeme geliştirmesinden geçmemiş daha büyük, daha genelci modelleri bile geçmesi beklenir. Bu stratejik bir seçimdir: yetenekli bir modeli yüksek değerli, bilişsel olarak zorlu görevler için optimize etmek.
GLM-Z1-Rumination-32B-0414: Daha Derin, Aramayla Artırılmış Düşünmeyi Etkinleştirme
"Rumination" modeli, yalnızca mevcut bilgileri almaktan veya bunlar üzerinde muhakeme etmekten daha fazlasını gerektiren, açık uçlu ve karmaşık sorunları hedefleyerek başka bir sofistike katman sunar. "Rumination" kavramı, "OpenAI'nin Derin Araştırması"na (muhtemelen derinlemesine analiz veya çok adımlı düşünme süreçleri yapabilen modellere atıfta bulunarak) karşı konumlandırılmıştır. Bir modelin tek bir geçişte bir yanıt ürettiği standart çıkarımın aksine, rumination daha derin, potansiyel olarak yinelemeli ve daha uzun düşünme kapasitesi anlamına gelir.
GLM-Z1-Rumination-32B-0414'ün temel yönleri şunları içerir:
- Derin ve Uzun Düşünme: Bu, modelin zincir düşüncesi, düşünce ağacı veya dahili not defterleri gibi teknikleri daha kapsamlı bir şekilde veya hatta nihai yanıtı üretmeden önce kendi ara çıktılarının eleştirildiği ve iyileştirildiği yinelemeli bir iyileştirme süreci kullanabileceğini gösterir. Bu, tek, kolayca doğrulanabilir bir cevabın olmadığı görevler için çok önemlidir.
- Açık Uçlu Problemleri Çözme: Verilen örnek – "iki şehirdeki yapay zeka gelişiminin ve gelecekteki gelişim planlarının karşılaştırmalı bir analizini yazmak" – bunu mükemmel bir şekilde göstermektedir. Bu tür görevler, potansiyel olarak farklı kaynaklardan bilgi sentezlemeyi, karmaşık argümanlar oluşturmayı, nüanslı yargılarda bulunmayı ve tutarlı, uzun biçimli metinler üretmeyi gerektirir.
- Derecelendirilmiş Yanıtlarla Ölçeklendirilmiş Uçtan Uca RL: Eğitim RL'yi içerir, ancak geri bildirim mekanizması basit tercih sıralamasından daha sofistike. Yanıtlar, gerçeğe dayalı cevaplara (uygun olduğunda) veya ayrıntılı yönergelere (nitel görevler için) göre derecelendirilir. Bu, modele yalnızca "daha iyi" olanı değil, aynı zamanda belirli kriterlere göre (örneğin, analiz derinliği, tutarlılık, gerçek doğruluk, yapı) neden daha iyi olduğunu öğreten çok daha zengin bir öğrenme sinyali sağlar.
- Derin Düşünme Sırasında Arama Aracı Entegrasyonu: Bu kritik bir özelliktir. Karmaşık, araştırma tarzı görevler için, modelin dahili bilgisi yetersiz veya güncelliğini yitirmiş olabilir. Arama yeteneklerini üretim süreci sırasında entegre ederek, model aktif olarak ilgili, güncel bilgileri arayabilir, analiz edebilir ve "rumination"ına dahil edebilir. Bu, modeli statik bir bilgi deposundan dinamik bir araştırma asistanına dönüştürür.
Beklenen iyileştirmeler, araştırma tarzı yazma ve bilgi sentezi ve yapılandırılmış argümantasyon gerektiren karmaşık görevleri ele almada görülür. Bu tür yeteneklerin ölçütlenmesi, standart ölçümlerle oldukça zordur. Değerlendirme daha çok şunlara dayanabilir:
- İnsan Değerlendirmesi: Önceden tanımlanmış yönergelere göre uzun biçimli çıktıların kalitesini, derinliğini ve tutarlılığını değerlendirmek.
- Karmaşık QA Performansı: Birden fazla bilgi parçası üzerinde muhakeme gerektiren StrategyQA veya QuALITY gibi veri kümeleri.
- Göreve Özel Değerlendirmeler: Karşılaştırmalı analiz örneğine benzer ısmarlama görevlerde performansı değerlendirmek.
GLM-Z1-Rumination, konuları keşfedebilen, bilgi toplayabilen ve sofistike argümanlar oluşturabilen, karmaşık bilgi çalışmalarında gerçek işbirlikçiler olarak işlev görebilen modellere yönelik iddialı bir itişi temsil eder.
GLM-Z1-9B-0414: Hafif Güç Santrali
Belki de en ilgi çekici sürüm GLM-Z1-9B-0414'tür. Sektör genellikle ölçeği kovalarken, THUDM, daha büyük Z1 modelleri için geliştirilen gelişmiş eğitim metodolojilerini çok daha küçük bir 9 milyar parametreli tabana uygulamıştır. Bu önemlidir çünkü daha küçük modeller çok daha erişilebilirdir: çıkarım için daha az hesaplama gücü gerektirir, çalıştırılması daha ucuzdur ve kenar cihazlara veya standart donanıma daha kolay dağıtılabilir.
Önemli çıkarım, GLM-Z1-9B'nin sofistike eğitim hattının faydalarını miras almasıdır: Z1-32B'nin gelişiminden (muhtemelen göreve özel eğitim ve RL teknikleri dahil) muhakeme geliştirmeleri ve potansiyel olarak rumination eğitiminin yönleri (ancak belki de küçültülmüş). Sonuç, sınıfının üzerinde önemli ölçüde performans gösteren bir modeldir.
"Matematiksel muhakeme ve genel görevlerde mükemmel yetenekler" ve "aynı boyuttaki tüm açık kaynaklı modeller arasında en üst sırada yer alan" iddiaları, 7B-13B parametre aralığındaki diğer modellere (örneğin, Mistral 7B, Llama 2 7B/13B varyantları, Qwen 7B) göre ölçütlerde güçlü performans gösterdiğini göstermektedir. GLM-Z1-9B'nin özellikle şunlarda rekabetçi puanlar göstermesini bekleriz:
- MMLU: Geniş çok görevli anlayışı ölçmek.
- GSM8K/MATH: Boyutuna göre orantısız muhakeme yeteneklerini göstermek.
- HumanEval/MBPP: Sınıfı için güçlü kodlama yetenekleri göstermek.
Bu model, yapay zeka ekosisteminde kritik bir ihtiyacı ele almaktadır: verimlilik ve etkinlik arasında optimum bir denge sağlamak. Kaynak kısıtlamaları altında (sınırlı GPU erişimi, bütçe kısıtlamaları, yerel dağıtım ihtiyacı) çalışan kullanıcılar ve kuruluşlar için GLM-Z1-9B, çok daha büyük modellerin altyapısını talep etmeden gelişmiş muhakeme yetenekleri sağlayan cazip bir seçenek sunar. Sofistike yapay zekaya erişimi demokratikleştirir.
Ölçütler ve Performans Analizi (Örnekleyici)
Belirli, doğrulanmış üçüncü taraf ölçüt numaraları devam eden takibi gerektirse de, açıklamalara dayanarak, göreceli konumlandırmayı çıkarabiliriz:
| Model | Parametre Boyutu | Temel Güçlü Yönler | Muhtemel Yüksek Performanslı Ölçütler | Hedef Kullanım Durumu |
|---|---|---|---|---|
| GLM-4-32B-0414 (Temel) | 32B | Güçlü Genel Yetenekler, İki Dillilik | MMLU, C-Eval, Genel QA, Çeviri | Geniş amaçlı LLM görevleri |
| GLM-Z1-32B-0414 (Muhakeme) | 32B | Matematik, Kod, Mantık, Karmaşık Görev Çözme | GSM8K, MATH, HumanEval, Mantık Bulmacaları | Teknik problem çözme, analiz |
| GLM-Z1-Rumination-32B-0414 | 32B | Derin Muhakeme, Açık Uçlu Görevler, Arama Kullanımı | Uzun biçimli Değerlendirme, Karmaşık QA, Araştırma Görevleri | Araştırma, analiz, karmaşık yazma |
| GLM-Z1-9B-0414 (Verimli) | 9B | Yüksek Performans/Boyut Oranı, Matematik/Genel Görevler | MMLU, GSM8K, HumanEval (boyuta göre) | Kaynak kısıtlı dağıtım |
(Not: Bu tablo yapısı, farklılaşmayı görselleştirmeye yardımcı olur. Gerçek puanlar, böyle bir tabloyu resmi bir raporda dolduracaktır.)
Z1-32B modelinin, muhakeme yoğun görevlerde temel 32B modelinden önemli ölçüde daha iyi performans göstermesi beklenir. Rumination modeli standart ölçütlerde zirveye çıkmayabilir, ancak karmaşık, üretken görevlerin nitel değerlendirmelerinde mükemmel olacaktır. Z1-9B modelinin değeri, özel eğitimi nedeniyle ~13B parametrenin altındaki diğer modellere göre göreceli olarak yüksek puanlarında yatar ve potansiyel olarak matematik ve muhakemede onları aşar.
Derin İçgörüler ve Etkileri
Bu GLM varyantlarının piyasaya sürülmesi, THUDM'nin stratejisine ve LLM gelişiminin daha geniş yörüngesine ilişkin çeşitli içgörüler sunmaktadır:
- Ölçeklendirmenin Ötesinde: Bu paket, yalnızca parametre sayısını artırmaya güvenmek yerine, sofistike eğitim teknikleri aracılığıyla modelleri geliştirme konusunda net bir strateji sergilemektedir. Uzmanlaşma anahtardır.
- Gelişmiş Eğitim Metodolojileri: Soğuk başlangıçların, çeşitli RL yaklaşımlarının (çift yönlü sıralama, uçtan uca derecelendirilmiş), göreve özel müfredat öğreniminin ve arama entegrasyonunun açıkça belirtilmesi, standart ön eğitim ve ince ayarın ötesinde model eğitiminde meydana gelen karmaşıklığı ve yeniliği vurgulamaktadır.
- Muhakeme Temel Bir Odak Olarak: Her iki Z1-32B varyantı da muhakemeyi – mantıksal, matematiksel ve analitik – yoğun bir şekilde vurgular. Bu, gerçek yapay zeka yeteneğinin yalnızca desen eşleştirmeden daha fazlasını gerektirdiğini; sağlam çıkarımsal yetenekler talep ettiğini gösteren artan bir anlayışı yansıtır.
- Rumination Kavramı: "Rumination" ve aramayla artırılmış düşüncenin tanıtımı, LLM yeteneklerinin sınırlarını daha özerk araştırma ve analize doğru zorlar. Bu, bilgi çalışmalarını, içerik oluşturmayı ve bilimsel keşifleri önemli ölçüde etkileyebilir.
- Verimlilik Yoluyla Demokratikleşme: Z1-9B modeli kritik bir katkıdır. Gelişmiş eğitim tekniklerini daha küçük modellere basamaklandırarak, THUDM yüksek performanslı yapay zekayı daha erişilebilir hale getirerek daha geniş bir benimsemeyi ve yeniliği teşvik eder. En son yeteneklerin en büyük modellere özel olduğu düşüncesine meydan okur.
- Rekabetçi Konumlandırma: Vurgulanan belirli yetenekler (muhakeme, derin düşünme, verimlilik) ve örtük karşılaştırmalar (örneğin, "OpenAI'nin Derin Araştırmasına karşı"), THUDM'nin farklı güçlü yönlere odaklanarak modellerini küresel yapay zeka arenasında etkili bir şekilde rekabet edecek şekilde stratejik olarak konumlandırdığını göstermektedir.
Sonuç
GLM-4-32B-0414 ve özel Z1 yavruları, GLM ailesinde önemli bir ilerlemeyi temsil ediyor ve yapay zeka alanına anlamlı bir katkıda bulunuyor. GLM-4-32B sağlam bir temel sağlarken, GLM-Z1-32B modelin zekasını matematik, kod ve mantıktaki karmaşık muhakeme görevleri için keskinleştirir. GLM-Z1-Rumination, açık uçlu araştırma ve analiz için daha derin, aramayla entegre düşünmeye öncülük ediyor. Son olarak, GLM-Z1-9B, gelişmiş yetenekler ve verimliliğin etkileyici bir karışımını sunarak, güçlü yapay zekayı kaynak sınırlı senaryolarda bile erişilebilir hale getiriyor.
Birlikte, bu modeller yalnızca ölçeğe değil, aynı zamanda hedeflenen uzmanlaşmaya, yenilikçi eğitim metodolojilerine ve pratik dağıtım hususlarına değer veren sofistike bir yapay zeka geliştirme yaklaşımını sergiliyor. THUDM, bu modelleri yinelemeye ve potansiyel olarak açık kaynaklı hale getirmeye veya erişim sağlamaya devam ettikçe, gelişmiş muhakeme ve problem çözme yetenekleri arayan araştırmacılar, geliştiriciler ve kullanıcılar için cazip alternatifler ve güçlü araçlar sunuyorlar. Muhakeme ve verimliliğe odaklanma, yapay zekanın yalnızca daha büyük değil, aynı zamanda gösterilebilir şekilde daha akıllı ve daha erişilebilir olduğu bir geleceğe işaret ediyor.


