
การประมวลผลเอกสารเป็นหนึ่งในแอปพลิเคชันเชิงปฏิบัติของ AI ที่ใช้งานมาอย่างยาวนาน แต่โซลูชัน OCR ส่วนใหญ่กลับต้องแลกมาด้วยความไม่สะดวกสบายระหว่างความแม่นยำและประสิทธิภาพ ระบบดั้งเดิมอย่าง Tesseract ต้องการการประมวลผลล่วงหน้าอย่างละเอียดถี่ถ้วน Cloud API คิดค่าบริการต่อหน้าและเพิ่มความหน่วง แม้แต่โมเดลวิสัยทัศน์-ภาษาที่ทันสมัยก็ยังประสบปัญหาโทเค็นจำนวนมหาศาลที่มาจากภาพเอกสารความละเอียดสูง
DeepSeek-OCR 2 เปลี่ยนแปลงสมการนี้โดยสิ้นเชิง ด้วยการต่อยอดแนวทาง "Contexts Optical Compression" จากเวอร์ชัน 1 เวอร์ชันใหม่นี้ได้นำเสนอ "Visual Causal Flow" ซึ่งเป็นสถาปัตยกรรมที่ประมวลผลเอกสารในแบบที่มนุษย์อ่านจริง โดยทำความเข้าใจความสัมพันธ์ทางสายตาและบริบท แทนที่จะแค่จดจำตัวอักษร ผลลัพธ์คือโมเดลที่ให้ความแม่นยำถึง 97% พร้อมบีบอัดรูปภาพให้เหลือเพียง 64 โทเค็น ทำให้สามารถประมวลผลได้มากกว่า 200,000 หน้าต่อวันด้วย GPU เพียงตัวเดียว
คู่มือนี้ครอบคลุมทุกสิ่งตั้งแต่การตั้งค่าพื้นฐานไปจนถึงการนำไปใช้งานจริงในการผลิต—พร้อมโค้ดที่ใช้งานได้จริงที่คุณสามารถคัดลอก วาง และรันได้ทันที
DeepSeek-OCR 2 คืออะไร?
DeepSeek-OCR 2 เป็นโมเดลวิสัยทัศน์-ภาษาโอเพนซอร์สที่ออกแบบมาโดยเฉพาะสำหรับการทำความเข้าใจเอกสารและการแยกข้อความ เปิดตัวโดย DeepSeek AI ในเดือนมกราคม 2026 โดยต่อยอดจาก DeepSeek-OCR ดั้งเดิมด้วยสถาปัตยกรรม "Visual Causal Flow" ใหม่ที่จำลองว่าองค์ประกอบภาพในเอกสารมีความสัมพันธ์กันอย่างไรในเชิงเหตุและผล—ทำความเข้าใจว่าส่วนหัวของตารางกำหนดวิธีการตีความเซลล์ที่อยู่ด้านล่าง หรือคำบรรยายภาพอธิบายแผนภูมิที่อยู่ด้านบน
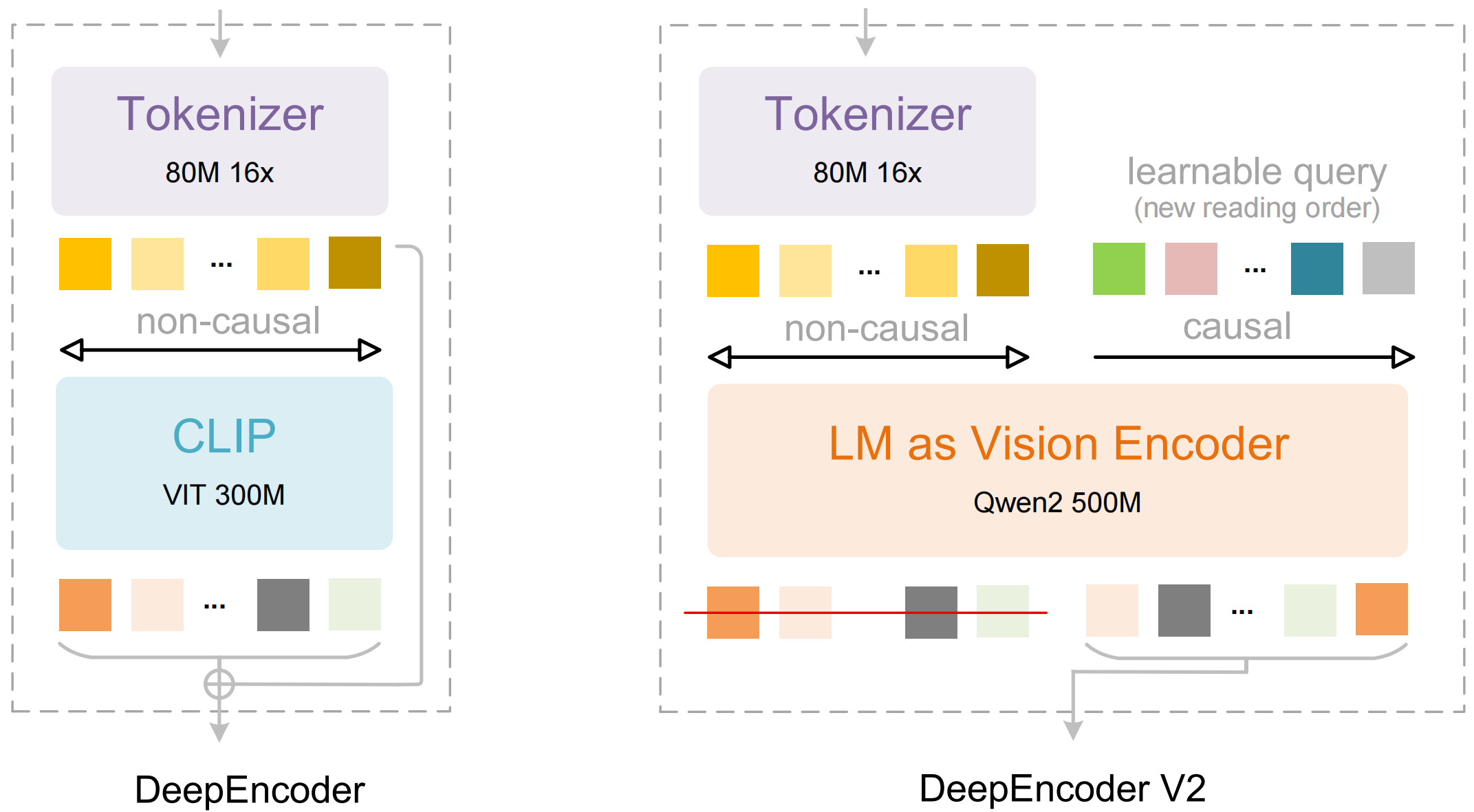
โมเดลประกอบด้วยสององค์ประกอบหลัก:
- DeepEncoder: ทรานสฟอร์เมอร์วิสัยทัศน์คู่ที่รวมการแยกรายละเอียดเฉพาะจุด (SAM-based, 80 ล้านพารามิเตอร์) เข้ากับการทำความเข้าใจเค้าโครงโดยรวม (CLIP-based, 300 ล้านพารามิเตอร์)
- DeepSeek3B-MoE Decoder: โมเดลภาษาแบบ Mixture-of-Experts ที่สร้างเอาต์พุตที่มีโครงสร้าง (Markdown, LaTeX, JSON) จากการนำเสนอภาพที่ถูกบีบอัด
DeepSeek-OCR 2 แตกต่างอย่างไร:
- **การบีบอัดขั้นสุด**: ลดขนาดภาพ 1024×1024 จาก 4,096 แพตช์ให้เหลือเพียง 256 โทเค็น—ลดลง 16 เท่า
- **เอาต์พุตที่มีโครงสร้าง**: สร้าง Markdown ที่สะอาดตาพร้อมตาราง ส่วนหัว และการจัดรูปแบบที่เหมาะสม
- **รองรับหลายรูปแบบ**: จัดการกับ PDF, เอกสารที่สแกน, สกรีนช็อต, บันทึกที่เขียนด้วยลายมือ และอื่นๆ
- **100+ ภาษา**: ฝึกฝนด้วยเอกสาร 30 ล้านหน้า ครอบคลุมประมาณ 100 ภาษา
- **น้ำหนักเปิด**: ได้รับอนุญาตภายใต้ MIT มีให้ใช้งานบน Hugging Face
คุณสมบัติหลักและสถาปัตยกรรม
Visual Causal Flow
คุณสมบัติเด่นของเวอร์ชัน 2 คือ "Visual Causal Flow"—แนวทางใหม่ในการทำความเข้าใจเอกสารที่ก้าวข้ามขีดจำกัดของ OCR แบบง่ายๆ แทนที่จะมองหน้าเอกสารเป็นเพียงตารางของตัวอักษร โมเดลนี้จะเรียนรู้ความสัมพันธ์เชิงสาเหตุระหว่างองค์ประกอบภาพต่างๆ:
- **การอนุมานลำดับการอ่าน**: กำหนดลำดับที่ถูกต้องสำหรับเค้าโครงแบบหลายคอลัมน์โดยอัตโนมัติ
- **การทำความเข้าใจโครงสร้างตาราง**: จดจำส่วนหัว เซลล์ที่รวมกัน และตารางซ้อน
- **การเชื่อมโยงรูปภาพ-คำบรรยาย**: เชื่อมโยงรูปภาพกับคำอธิบาย
- **การแยกวิเคราะห์นิพจน์ทางคณิตศาสตร์**: จัดการกับ LaTeX ทั้งแบบอินไลน์และบล็อกได้อย่างแม่นยำ
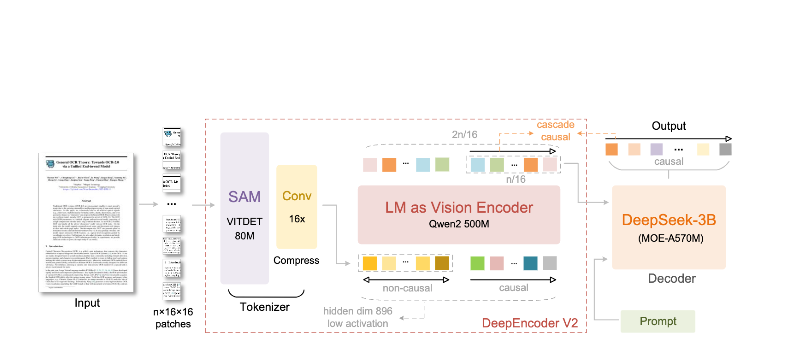
สถาปัตยกรรม DeepEncoder
DeepEncoder คือจุดที่ความมหัศจรรย์เกิดขึ้น มันประมวลผลรูปภาพความละเอียดสูงในขณะที่ยังคงจำนวนโทเค็นที่สามารถจัดการได้:
Input Image (1024×1024)
↓
SAM-base Block (80M params)
- Windowed attention for local detail
- Extracts fine-grained features
↓
CLIP-large Block (300M params)
- Global attention for layout
- Understands document structure
↓
Convolution Block
- 16× token reduction
- 4,096 patches → 256 tokens
↓
Output: Compressed Vision Tokens
การแลกเปลี่ยนระหว่างการบีบอัดและความแม่นยำ
| อัตราส่วนการบีบอัด | โทเค็นภาพ | ความแม่นยำ |
|---|---|---|
| 4× | 1,024 | 99%+ |
| 10× | 256 | 97% |
| 16× | 160 | 92% |
| 20× | 128 | ~60% |
จุดที่เหมาะสมที่สุดสำหรับแอปพลิเคชันส่วนใหญ่คืออัตราส่วนการบีบอัด 10 เท่า ซึ่งรักษาความแม่นยำที่ 97% ในขณะที่ช่วยให้มีปริมาณงานสูงที่ทำให้การนำไปใช้งานจริงในการผลิตเป็นไปได้
การติดตั้งและการตั้งค่า
ข้อกำหนดเบื้องต้น
- Python 3.10+ (แนะนำ 3.12.9)
- CUDA 11.8+ พร้อม NVIDIA GPU ที่เข้ากันได้
- หน่วยความจำ GPU อย่างน้อย 16GB (แนะนำ A100-40G สำหรับการใช้งานจริง)
วิธีที่ 1: การติดตั้ง vLLM (แนะนำ)
vLLM ให้ประสิทธิภาพที่ดีที่สุดสำหรับการนำไปใช้งานจริงในการผลิต:
# Create virtual environment
python -m venv deepseek-ocr-env
source deepseek-ocr-env/bin/activate
# Install vLLM with CUDA support
pip install vllm>=0.8.5
# Install flash attention for optimal performance
pip install flash-attn==2.7.3 --no-build-isolation
วิธีที่ 2: การติดตั้ง Transformers
สำหรับการพัฒนาและการทดลอง:
pip install transformers>=4.40.0
pip install torch>=2.6.0 torchvision>=0.21.0
pip install accelerate
pip install flash-attn==2.7.3 --no-build-isolation
วิธีที่ 3: Docker (สำหรับการผลิต)
FROM nvidia/cuda:11.8-devel-ubuntu22.04
RUN pip install vllm>=0.8.5 flash-attn==2.7.3
# Pre-download model
RUN python -c "from vllm import LLM; LLM(model='deepseek-ai/DeepSeek-OCR-2')"
EXPOSE 8000
CMD ["vllm", "serve", "deepseek-ai/DeepSeek-OCR-2", "--port", "8000"]
ตรวจสอบการติดตั้ง
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
import vllm
print(f"vLLM version: {vllm.__version__}")
ตัวอย่างโค้ด Python
OCR พื้นฐานด้วย vLLM
นี่คือวิธีที่ง่ายที่สุดในการแยกข้อความจากภาพเอกสาร:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# เริ่มต้นโมเดล
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
trust_remote_code=True,
)
# โหลดภาพเอกสารของคุณ
image = Image.open("document.png").convert("RGB")
# เตรียมพร้อมข้อความแจ้ง - "Free OCR." จะเรียกใช้การแยกมาตรฐาน
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": image}
}]
# กำหนดค่าพารามิเตอร์การสุ่มตัวอย่าง
sampling_params = SamplingParams(
temperature=0.0, # กำหนดผลลัพธ์ที่แน่นอนสำหรับ OCR
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822}, # <td>, </td> สำหรับตาราง
},
skip_special_tokens=False,
)
# สร้างเอาต์พุต
outputs = llm.generate(model_input, sampling_params)
# แยกข้อความ markdown
markdown_text = outputs[0].outputs[0].text
print(markdown_text)
การประมวลผลเอกสารหลายฉบับแบบแบตช์
ประมวลผลเอกสารหลายฉบับได้อย่างมีประสิทธิภาพในแบตช์เดียว:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
from pathlib import Path
def batch_ocr(image_paths: list[str], llm: LLM) -> list[str]:
"""ประมวลผลภาพหลายภาพในแบตช์เดียว"""
# โหลดภาพทั้งหมด
images = [Image.open(p).convert("RGB") for p in image_paths]
# เตรียมอินพุตแบบแบตช์
prompt = "<image>\nFree OCR."
model_inputs = [
{"prompt": prompt, "multi_modal_data": {"image": img}}
for img in images
]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
# สร้างเอาต์พุตทั้งหมดในการเรียกครั้งเดียว
outputs = llm.generate(model_inputs, sampling_params)
return [out.outputs[0].text for out in outputs]
# การใช้งาน
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
image_files = list(Path("documents/").glob("*.png"))
results = batch_ocr([str(f) for f in image_files], llm)
for path, text in zip(image_files, results):
print(f"--- {path.name} ---")
print(text[:500]) # 500 อักขระแรก
print()
การใช้ Transformers โดยตรง
สำหรับการควบคุมกระบวนการอนุมานได้มากขึ้น:
import torch
from transformers import AutoModel, AutoTokenizer
from PIL import Image
# ตั้งค่า GPU
device = "cuda:0"
# โหลดโมเดลและ tokenizer
model_name = "deepseek-ai/DeepSeek-OCR-2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True,
)
model = model.eval().to(device).to(torch.bfloat16)
# โหลดและปรับปรุงภาพล่วงหน้า
image = Image.open("document.png").convert("RGB")
# ข้อความแจ้งที่แตกต่างกันสำหรับงานที่แตกต่างกัน
prompts = {
"ocr": "<image>\nFree OCR.", # OCR มาตรฐาน - เร็วที่สุด, ดีสำหรับกรณีส่วนใหญ่
"markdown": "<image>\n<|grounding|>Convert the document to markdown.", # การแปลงเป็น Markdown - รักษาโครงสร้างได้ดีขึ้น
"table": "<image>\nExtract all tables as markdown.", # การแยกตาราง - เหมาะสำหรับข้อมูลเชิงตาราง
"math": "<image>\nExtract mathematical expressions as LaTeX.", # การแยกคณิตศาสตร์ - สำหรับเอกสารทางวิชาการ/วิทยาศาสตร์
"fields": "<image>\nExtract the following fields: name, date, amount, signature.", # ฟิลด์เฉพาะ - สำหรับการแยกแบบฟอร์ม
}
# ประมวลผลด้วยข้อความแจ้งที่คุณเลือก
prompt = prompts["markdown"]
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# เพิ่มรูปภาพไปยังอินพุต (การประมวลผลล่วงหน้าเฉพาะโมเดล)
with torch.no_grad():
outputs = model.generate(
**inputs,
images=[image],
max_new_tokens=4096,
do_sample=False,
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
การประมวลผลแบบอะซิงโครนัสสำหรับปริมาณงานสูง
import asyncio
from vllm import AsyncLLMEngine, AsyncEngineArgs, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
async def process_document(engine, image_path: str, request_id: str):
"""ประมวลผลเอกสารเดียวแบบอะซิงโครนัส"""
image = Image.open(image_path).convert("RGB")
prompt = "<image>\nFree OCR."
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
)
results = []
async for output in engine.generate(prompt, sampling_params, request_id):
results.append(output)
return results[-1].outputs[0].text
async def main():
# เริ่มต้นเอนจินแบบอะซิงโครนัส
engine_args = AsyncEngineArgs(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
# ประมวลผลเอกสารหลายฉบับพร้อมกัน
image_paths = ["doc1.png", "doc2.png", "doc3.png"]
tasks = [
process_document(engine, path, f"req_{i}")
for i, path in enumerate(image_paths)
]
results = await asyncio.gather(*tasks)
for path, text in zip(image_paths, results):
print(f"{path}: แยกอักขระได้ {len(text)} ตัว")
asyncio.run(main())
การใช้ vLLM สำหรับการผลิต
การเริ่มต้นเซิร์ฟเวอร์ที่เข้ากันได้กับ OpenAI
ปรับใช้ DeepSeek-OCR 2 เป็นเซิร์ฟเวอร์ API:
vllm serve deepseek-ai/DeepSeek-OCR-2 \
--host 0.0.0.0 \
--port 8000 \
--logits_processors vllm.model_executor.models.deepseek_ocr:NGramPerReqLogitsProcessor \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9
การเรียกใช้เซิร์ฟเวอร์ด้วย OpenAI SDK
from openai import OpenAI
import base64
# เริ่มต้นไคลเอนต์ที่ชี้ไปยังเซิร์ฟเวอร์ภายใน
client = OpenAI(
api_key="EMPTY", # ไม่จำเป็นสำหรับเซิร์ฟเวอร์ภายใน
base_url="http://localhost:8000/v1",
timeout=3600,
)
def encode_image(image_path: str) -> str:
"""เข้ารหัสรูปภาพเป็น base64"""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def ocr_document(image_path: str) -> str:
"""แยกข้อความจากเอกสารโดยใช้ OCR API"""
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
extra_body={
"skip_special_tokens": False,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822],
},
},
)
return response.choices[0].message.content
# การใช้งาน
result = ocr_document("invoice.png")
print(result)
การใช้งานกับ URL
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/document.png"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
)
การทดสอบด้วย Apidog
การทดสอบ OCR API อย่างมีประสิทธิภาพจำเป็นต้องเห็นภาพทั้งเอกสารที่ป้อนเข้าและผลลัพธ์ที่แยกออกมา Apidog มอบอินเทอร์เฟซที่ใช้งานง่ายสำหรับการทดลองใช้ DeepSeek-OCR 2
การตั้งค่า OCR Endpoint
ขั้นตอนที่ 1: สร้างคำขอใหม่
- เปิด Apidog และสร้างโปรเจกต์ใหม่
- เพิ่มคำขอ POST ไปยัง
http://localhost:8000/v1/chat/completions
ขั้นตอนที่ 2: กำหนดค่าส่วนหัว (Headers)
Content-Type: application/json
ขั้นตอนที่ 3: กำหนดค่าเนื้อหาคำขอ (Request Body)
{
"model": "deepseek-ai/DeepSeek-OCR-2",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64_image}}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
"max_tokens": 8192,
"temperature": 0,
"extra_body": {
"skip_special_tokens": false,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822]
}
}
}
การทดสอบเอกสารประเภทต่างๆ
สร้างคำขอที่บันทึกไว้สำหรับเอกสารประเภททั่วไป:
- **การแยกข้อมูลใบแจ้งหนี้** - ทดสอบการแยกข้อมูลที่มีโครงสร้าง
- **เอกสารทางวิชาการ** - ทดสอบการจัดการ LaTeX ทางคณิตศาสตร์
- **บันทึกที่เขียนด้วยลายมือ** - ทดสอบการจดจำลายมือ
- **เค้าโครงแบบหลายคอลัมน์** - ทดสอบการอนุมานลำดับการอ่าน
การเปรียบเทียบโหมดความละเอียด
ตั้งค่าตัวแปรสภาพแวดล้อมเพื่อทดสอบโหมดต่างๆ ได้อย่างรวดเร็ว:
| โหมด | ความละเอียด | โทเค็น | กรณีการใช้งาน |
|---|---|---|---|
tiny | 512×512 | 64 | การแสดงตัวอย่างอย่างรวดเร็ว |
small | 640×640 | 100 | เอกสารง่ายๆ |
base | 1024×1024 | 256 | เอกสารมาตรฐาน |
large | 1280×1280 | 400 | ข้อความหนาแน่น |
gundam | ไดนามิก | แปรผัน | เค้าโครงซับซ้อน |

โหมดความละเอียดและการบีบอัด
DeepSeek-OCR 2 รองรับโหมดความละเอียดห้าโหมด ซึ่งแต่ละโหมดได้รับการปรับให้เหมาะสมสำหรับกรณีการใช้งานที่แตกต่างกัน:
โหมด Tiny (64 โทเค็น)
ดีที่สุดสำหรับ: การตรวจจับข้อความอย่างรวดเร็ว, แบบฟอร์มง่ายๆ, อินพุตความละเอียดต่ำ
# กำหนดค่าสำหรับโหมด tiny
os.environ["DEEPSEEK_OCR_MODE"] = "tiny" # 512×512
โหมด Small (100 โทเค็น)
ดีที่สุดสำหรับ: เอกสารดิจิทัลที่สะอาดตา, ข้อความคอลัมน์เดียว
โหมด Base (256 โทเค็น) - ค่าเริ่มต้น
ดีที่สุดสำหรับ: เอกสารมาตรฐานส่วนใหญ่, ใบแจ้งหนี้, จดหมาย
โหมด Large (400 โทเค็น)
ดีที่สุดสำหรับ: เอกสารทางวิชาการที่มีข้อความหนาแน่น, เอกสารทางกฎหมาย
โหมด Gundam (ไดนามิก)
ดีที่สุดสำหรับ: เอกสารหลายหน้าที่มีความซับซ้อนและเค้าโครงที่แตกต่างกัน
# โหมด Gundam รวมมุมมองหลายแบบเข้าด้วยกัน
# - ไทล์ท้องถิ่นขนาด n × 640×640 สำหรับรายละเอียด
# - มุมมองทั่วโลกขนาด 1 × 1024×1024 สำหรับโครงสร้าง
การเลือกโหมดที่เหมาะสม
def select_mode(document_type: str, page_count: int) -> str:
"""เลือกโหมดความละเอียดที่เหมาะสมที่สุดตามลักษณะของเอกสาร"""
if document_type == "simple_form":
return "tiny"
elif document_type == "digital_document" and page_count == 1:
return "small"
elif document_type == "academic_paper":
return "large"
elif document_type == "mixed_layout" or page_count > 1:
return "gundam"
else:
return "base" # ค่าเริ่มต้น
การประมวลผลไฟล์ PDF และเอกสาร
การแปลง PDF เป็นรูปภาพ
import fitz # PyMuPDF
from PIL import Image
import io
def pdf_to_images(pdf_path: str, dpi: int = 150) -> list[Image.Image]:
"""แปลงหน้า PDF เป็นรูปภาพ PIL"""
doc = fitz.open(pdf_path)
images = []
for page_num in range(len(doc)):
page = doc[page_num]
# เรนเดอร์ที่ DPI ที่ระบุ
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
# แปลงเป็นรูปภาพ PIL
img_data = pix.tobytes("png")
img = Image.open(io.BytesIO(img_data))
images.append(img)
doc.close()
return images
# การใช้งาน
images = pdf_to_images("report.pdf", dpi=200)
print(f"แยกออกมาได้ {len(images)} หน้า")
ไปป์ไลน์การประมวลผล PDF แบบสมบูรณ์
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from pathlib import Path
import fitz
from PIL import Image
import io
class PDFProcessor:
def __init__(self, model_name: str = "deepseek-ai/DeepSeek-OCR-2"):
self.llm = LLM(
model=model_name,
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
self.sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
def process_pdf(self, pdf_path: str, dpi: int = 150) -> str:
"""ประมวลผล PDF ทั้งหมดและคืนค่า markdown ที่รวมกัน"""
doc = fitz.open(pdf_path)
all_text = []
for page_num in range(len(doc)):
# แปลงหน้าเป็นรูปภาพ
page = doc[page_num]
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
img = Image.open(io.BytesIO(pix.tobytes("png")))
# ทำ OCR หน้าเอกสาร
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": img}
}]
output = self.llm.generate(model_input, self.sampling_params)
page_text = output[0].outputs[0].text
all_text.append(f"## Page {page_num + 1}\n\n{page_text}")
doc.close()
return "\n\n---\n\n".join(all_text)
# การใช้งาน
processor = PDFProcessor()
markdown = processor.process_pdf("annual_report.pdf")
# บันทึกลงไฟล์
Path("output.md").write_text(markdown)
ประสิทธิภาพการทดสอบมาตรฐาน
การทดสอบมาตรฐานความแม่นยำ
| การทดสอบมาตรฐาน | DeepSeek-OCR 2 | GOT-OCR2.0 | MinerU2.0 |
|---|---|---|---|
| OmniDocBench | 94.2% |