
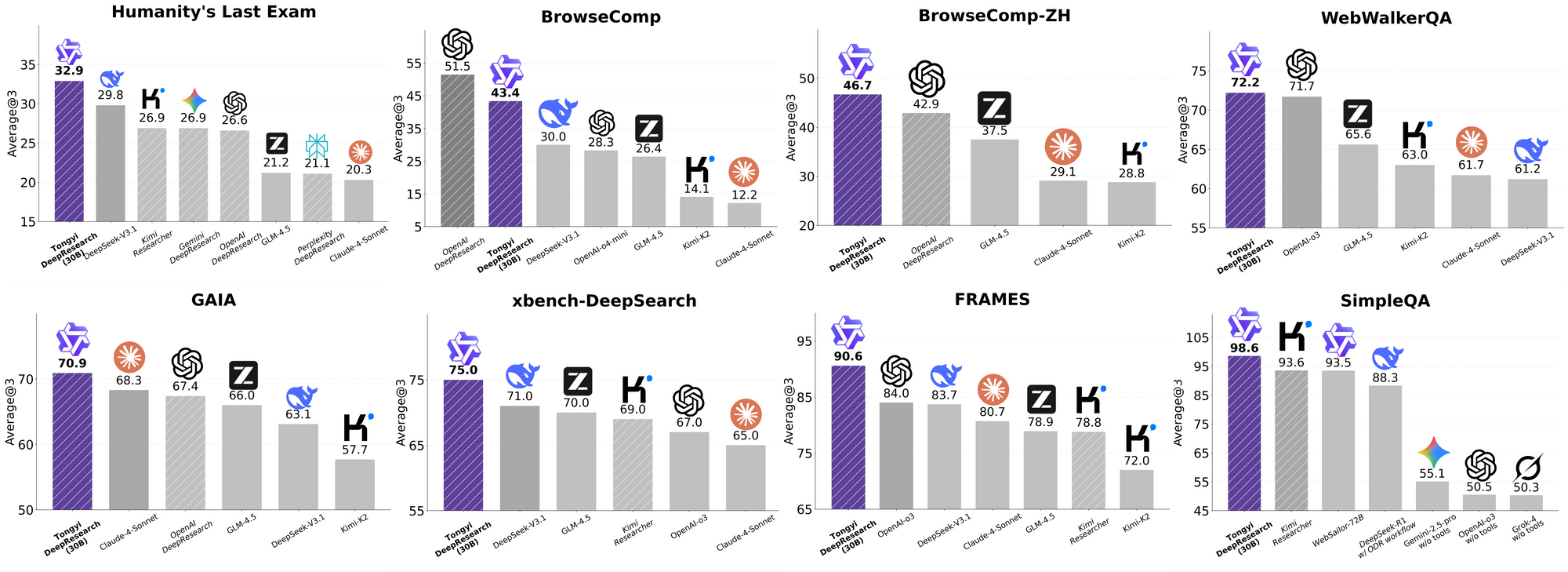
Tongyi DeepResearch ของ Alibaba กำหนดนิยามใหม่ของเอเจนต์ AI อัตโนมัติด้วยโมเดล Mixture of Experts (MoE) ที่มีพารามิเตอร์ 30B ซึ่งเปิดใช้งานเพียง 3B พารามิเตอร์ต่อโทเค็นเพื่อการวิจัยเว็บที่มีประสิทธิภาพและแม่นยำสูง ขุมพลังโอเพนซอร์สนี้ทำลายสถิติเกณฑ์มาตรฐาน เช่น Humanity's Last Exam (32.9% เทียบกับ 24.9% ของ OpenAI o3) และ xbench-DeepSearch (75.0% เทียบกับ 67.0%) ช่วยให้นักพัฒนาสามารถจัดการกับคำถามที่ซับซ้อนและหลายขั้นตอน ตั้งแต่การวิเคราะห์ทางกฎหมายไปจนถึงแผนการเดินทาง โดยไม่ต้องผูกมัดกับเจ้าของลิขสิทธิ์
วิศวกรที่ Tongyi Lab ได้ออกแบบเอเจนต์นี้เพื่อพิชิตการให้เหตุผลระยะยาวและการใช้เครื่องมือแบบไดนามิกโดยตรง ผลลัพธ์คือมันทำงานได้ดีกว่าโมเดลแบบปิดในการสังเคราะห์ข้อมูลในโลกจริง ทั้งหมดนี้ในขณะที่ทำงานแบบโลคัลผ่าน Hugging Face ในการวิเคราะห์เชิงเทคนิคนี้ เราจะเจาะลึกสถาปัตยกรรมแบบเบาบาง (sparse architecture) ไปป์ไลน์ข้อมูลอัตโนมัติ การฝึกอบรมที่ปรับให้เหมาะสมกับ RL การครองเกณฑ์มาตรฐาน และกลเม็ดในการปรับใช้ เมื่อจบบทความนี้ คุณจะเห็นว่า Tongyi DeepResearch และเครื่องมืออย่าง Apidog ปลดล็อก AI แบบเอเจนต์ที่ปรับขนาดได้สำหรับโครงการของคุณได้อย่างไร
ทำความเข้าใจ Tongyi DeepResearch: แนวคิดหลักและนวัตกรรม
Tongyi DeepResearch กำหนดนิยามใหม่ของ AI แบบเอเจนต์โดยเน้นที่การดึงข้อมูลเชิงลึกและการสังเคราะห์ข้อมูล แตกต่างจากโมเดลภาษาขนาดใหญ่ (LLMs) แบบดั้งเดิมที่เก่งในการสร้างเนื้อหาสั้นๆ เอเจนต์นี้จะนำทางในสภาพแวดล้อมแบบไดนามิก เช่น เว็บเบราว์เซอร์ เพื่อค้นหาข้อมูลเชิงลึกที่ละเอียดอ่อน โดยเฉพาะอย่างยิ่ง มันใช้สถาปัตยกรรม Mixture of Experts (MoE) ซึ่งพารามิเตอร์ 30B ทั้งหมดจะเปิดใช้งานแบบเลือกสรรเพียง 3B ต่อโทเค็น ประสิทธิภาพนี้ช่วยให้การทำงานบนฮาร์ดแวร์ที่มีทรัพยากรจำกัดเป็นไปอย่างแข็งแกร่ง ในขณะที่ยังคงรักษาความเข้าใจบริบทได้สูงถึง 128K โทเค็น
นอกจากนี้ โมเดลยังผสานรวมเข้ากับกระบวนทัศน์การอนุมานที่เลียนแบบการตัดสินใจของมนุษย์ได้อย่างราบรื่น ในโหมด ReAct มันจะวนซ้ำผ่านขั้นตอนการคิด การกระทำ และการสังเกตโดยกำเนิด โดยไม่ต้องใช้การออกแบบพรอมต์ที่ซับซ้อน สำหรับงานที่ซับซ้อนมากขึ้น โหมด Heavy จะเปิดใช้งานเฟรมเวิร์ก IterResearch ซึ่งประสานงานการสำรวจของเอเจนต์แบบขนานเพื่อหลีกเลี่ยงการโอเวอร์โหลดบริบท ด้วยเหตุนี้ ผู้ใช้จึงได้รับผลลัพธ์ที่เหนือกว่าในสถานการณ์ที่ต้องการการปรับปรุงซ้ำๆ เช่น การทบทวนวรรณกรรมทางวิชาการ หรือการวิเคราะห์ตลาด
สิ่งที่ทำให้ Tongyi DeepResearch แตกต่างคือความมุ่งมั่นในการเปิดกว้าง สแต็กทั้งหมด ตั้งแต่น้ำหนักโมเดลไปจนถึงโค้ดการฝึกอบรม อยู่บนแพลตฟอร์มเช่น Hugging Face และ GitHub นักพัฒนาสามารถเข้าถึงตัวแปร Tongyi-DeepResearch-30B-A3B ได้โดยตรง ซึ่งช่วยให้การปรับแต่งสำหรับความต้องการเฉพาะโดเมนเป็นไปได้ง่ายขึ้น นอกจากนี้ ความเข้ากันได้กับสภาพแวดล้อม Python มาตรฐานยังช่วยลดอุปสรรคในการเริ่มต้นใช้งาน ตัวอย่างเช่น การติดตั้งเกี่ยวข้องกับคำสั่ง pip ง่ายๆ หลังจากตั้งค่าสภาพแวดล้อม Conda ด้วย Python 3.10
เมื่อเปลี่ยนไปสู่การใช้งานจริง Tongyi DeepResearch ขับเคลื่อนแอปพลิเคชันที่ต้องการผลลัพธ์ที่ตรวจสอบได้ ในการวิจัยทางกฎหมาย มันจะแยกวิเคราะห์กฎหมายและคดีตัวอย่าง โดยอ้างอิงแหล่งที่มาได้อย่างแม่นยำ ในทำนองเดียวกัน ในการวางแผนการเดินทาง มันจะสร้างแผนการเดินทางหลายวันโดยการอ้างอิงข้อมูลแบบเรียลไทม์ ความสามารถเหล่านี้เกิดจากปรัชญาการออกแบบที่ตั้งใจไว้: ให้ความสำคัญกับการให้เหตุผลแบบเอเจนต์มากกว่าการคาดการณ์เพียงอย่างเดียว
สถาปัตยกรรมของ Tongyi DeepResearch: ประสิทธิภาพมาพร้อมกับพลัง
หัวใจสำคัญของ Tongyi DeepResearch คือการใช้การออกแบบ MoE แบบเบาบาง (sparse MoE) เพื่อสร้างสมดุลระหว่างความต้องการในการประมวลผลกับพลังในการแสดงออก โมเดลจะเปิดใช้งานผู้เชี่ยวชาญเพียงบางส่วนต่อโทเค็น โดยกำหนดเส้นทางอินพุตแบบไดนามิกตามความซับซ้อนของคำถาม แนวทางนี้ช่วยลดเวลาแฝงได้ถึง 90% เมื่อเทียบกับคู่แข่งแบบหนาแน่น ทำให้สามารถนำไปใช้ในการปรับใช้เอเจนต์แบบเรียลไทม์ได้ นอกจากนี้ หน้าต่างบริบทขนาด 128K ยังรองรับการโต้ตอบที่ยาวนาน ซึ่งสำคัญสำหรับงานที่เกี่ยวข้องกับเอกสารจำนวนมากหรือการค้นหาเว็บแบบมีเธรด
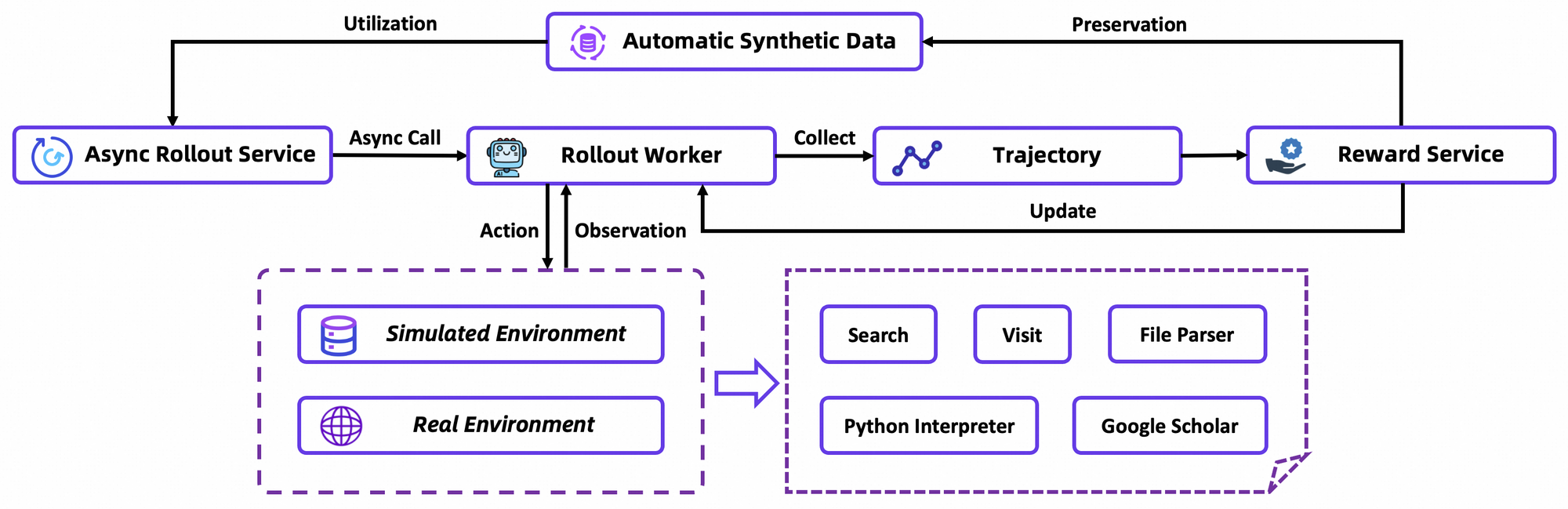
ส่วนประกอบทางสถาปัตยกรรมที่สำคัญประกอบด้วยตัวสร้างโทเค็นแบบกำหนดเองที่ปรับให้เหมาะสมสำหรับโทเค็นแบบเอเจนต์ เช่น คำนำหน้าการกระทำและตัวคั่นการสังเกต และชุดเครื่องมือฝังตัวสำหรับการนำทางเบราว์เซอร์ การดึงข้อมูล และการคำนวณ เฟรมเวิร์กนี้รองรับการรวมการเรียนรู้แบบเสริมแรง (RL) แบบ on-policy ซึ่งเอเจนต์เรียนรู้จากการจำลองการทำงานในสภาพแวดล้อมที่เสถียร ผลลัพธ์คือโมเดลแสดงอาการหลอนน้อยลงในการเรียกใช้เครื่องมือ ดังที่เห็นได้จากคะแนนสูงในการทดสอบการใช้เครื่องมือ
นอกจากนี้ Tongyi DeepResearch ยังรวมหน่วยความจำความรู้ที่ยึดตามเอนทิตี ซึ่งได้มาจากข้อมูลสังเคราะห์แบบกราฟ กลไกนี้ยึดคำตอบกับเอนทิตีที่เป็นข้อเท็จจริง ซึ่งช่วยเพิ่มความสามารถในการตรวจสอบย้อนกลับ ตัวอย่างเช่น ในระหว่างการสอบถามเกี่ยวกับความก้าวหน้าของการประมวลผลควอนตัม เอเจนต์จะดึงและสังเคราะห์เอกสารผ่านเครื่องมือคล้าย WebSailor โดยอ้างอิงผลลัพธ์จากแหล่งที่มาที่ตรวจสอบได้ ดังนั้น สถาปัตยกรรมจึงไม่เพียงแต่ประมวลผลข้อมูลเท่านั้น แต่ยังคัดสรรข้อมูลอย่างกระตือรือร้นอีกด้วย
เพื่อแสดงให้เห็น ลองพิจารณาการจัดการอินพุตหลายรูปแบบของโมเดล แม้ว่าจะเน้นข้อความเป็นหลัก แต่ส่วนขยายผ่าน GitHub repo อนุญาตให้รวมเข้ากับตัวแยกวิเคราะห์รูปภาพหรือตัวดำเนินการโค้ดได้ นักพัฒนาสามารถกำหนดค่าเหล่านี้ได้ในสคริปต์การอนุมาน โดยระบุเส้นทางสำหรับชุดข้อมูลในรูปแบบ JSONL ด้วยเหตุนี้ สถาปัตยกรรมจึงส่งเสริมความสามารถในการขยาย โดยเชิญชวนให้ชุมชนโอเพนซอร์สเข้ามามีส่วนร่วม
การสังเคราะห์ข้อมูลอัตโนมัติ: ขับเคลื่อนความสามารถของ Tongyi DeepResearch
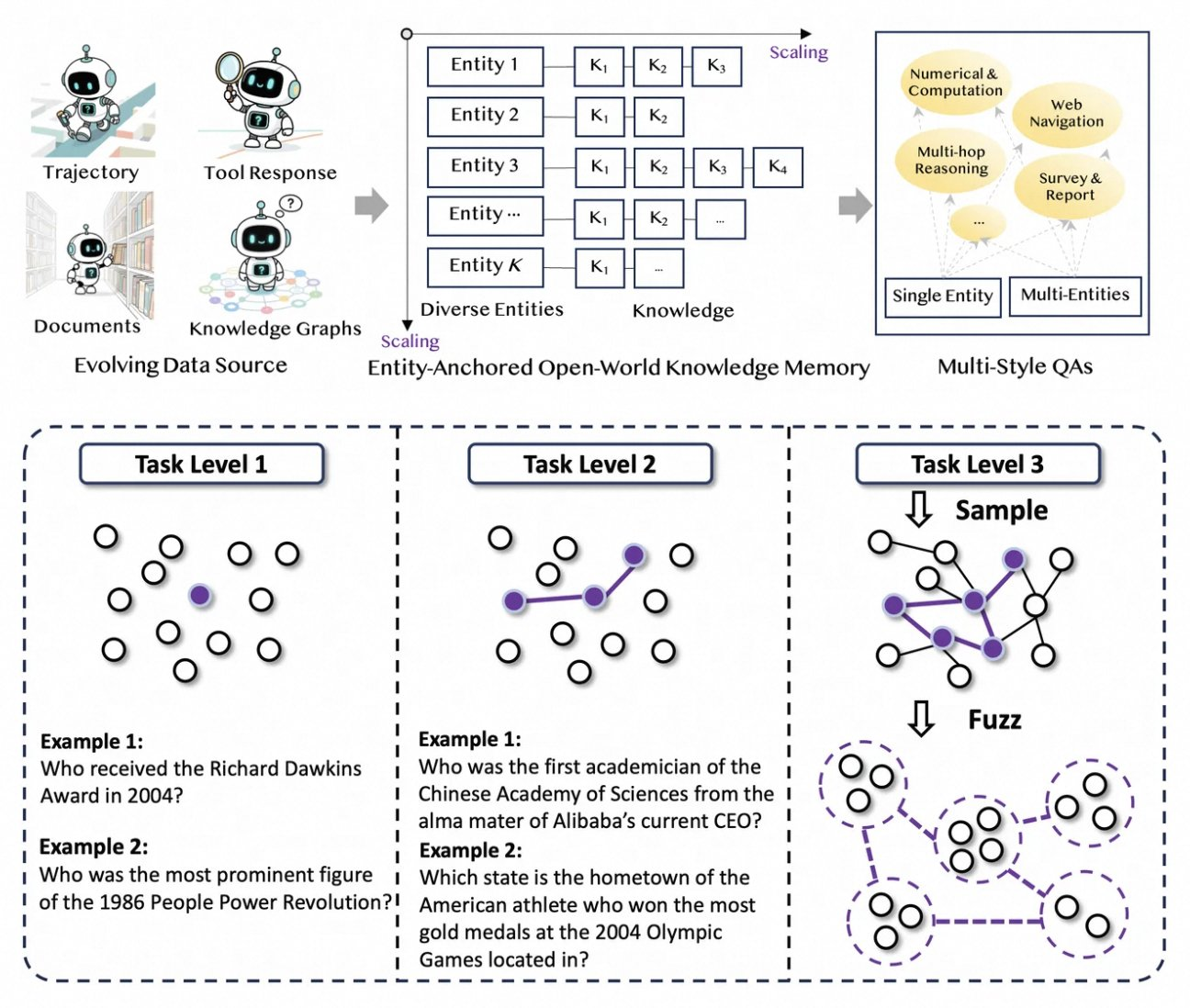
Tongyi DeepResearch เติบโตได้ด้วยไปป์ไลน์ข้อมูลอัตโนมัติแบบใหม่ที่สมบูรณ์แบบ ซึ่งช่วยขจัดปัญหาคอขวดจากการติดป้ายกำกับด้วยมนุษย์ กระบวนการนี้เริ่มต้นด้วย AgentFounder ซึ่งเป็นเอนจินสังเคราะห์ที่จัดระเบียบคลังข้อมูลดิบ เช่น เอกสาร การรวบรวมข้อมูลเว็บ และกราฟความรู้ ให้เป็นคู่คำถาม-คำตอบที่ยึดตามเอนทิตี ขั้นตอนนี้สร้างเส้นทางที่หลากหลายสำหรับการฝึกอบรมล่วงหน้าอย่างต่อเนื่อง (CPT) ครอบคลุมห่วงโซ่การให้เหตุผล การเรียกใช้เครื่องมือ และแผนผังการตัดสินใจ
ถัดไป ไปป์ไลน์จะเพิ่มความยากผ่านการอัปเกรดแบบวนซ้ำ สำหรับการฝึกอบรมหลังการใช้งาน มันใช้เมธอดแบบกราฟ เช่น WebSailor-V2 เพื่อจำลองความท้าทายระดับ "เหนือมนุษย์" เช่น คำถามระดับปริญญาเอกที่จำลองผ่านทฤษฎีเซต ผลลัพธ์คือชุดข้อมูลครอบคลุมการโต้ตอบที่มีความแม่นยำสูงหลายล้านครั้ง ทำให้มั่นใจว่าโมเดลสามารถทำงานได้ทั่วไปในหลายโดเมน ที่น่าสังเกตคือ ระบบอัตโนมัตินี้ปรับขนาดได้เชิงเส้นตามการคำนวณ ทำให้สามารถอัปเดตได้อย่างต่อเนื่องโดยไม่ต้องมีการดูแลด้วยตนเอง
นอกจากนี้ Tongyi DeepResearch ยังรวมข้อมูลหลายรูปแบบเพื่อความทนทาน บันทึกการสังเคราะห์การกระทำจะบันทึกรูปแบบการใช้เครื่องมือ ในขณะที่คู่คำถาม-คำตอบหลายขั้นตอนจะปรับปรุงทักษะการวางแผน ในทางปฏิบัติ สิ่งนี้ทำให้เกิดเอเจนต์ที่ปรับตัวเข้ากับสภาพแวดล้อมเว็บที่มีเสียงรบกวน โดยกรองข้อมูลที่ไม่เกี่ยวข้องได้อย่างมีประสิทธิภาพ สำหรับนักพัฒนา repo มีสคริปต์เพื่อจำลองไปป์ไลน์นี้ ทำให้สามารถสร้างชุดข้อมูลแบบกำหนดเองได้
ด้วยการให้ความสำคัญกับคุณภาพมากกว่าปริมาณ กลยุทธ์การสังเคราะห์นี้ช่วยแก้ไขข้อผิดพลาดทั่วไปในการฝึกอบรมเอเจนต์ เช่น การเปลี่ยนแปลงการกระจายข้อมูล ผลลัพธ์คือ โมเดลที่ฝึกด้วยวิธีนี้แสดงให้เห็นถึงความสอดคล้องที่เหนือกว่ากับงานในโลกจริง ดังที่เห็นได้จากการครองเกณฑ์มาตรฐาน
ไปป์ไลน์การฝึกอบรมแบบ End-to-End: จาก CPT สู่การเพิ่มประสิทธิภาพ RL
การฝึกอบรมของ Tongyi DeepResearch ดำเนินไปในไปป์ไลน์ที่ราบรื่น: Agentic CPT, Supervised Fine-Tuning (SFT) และ Reinforcement Learning (RL) ขั้นแรก CPT จะเปิดเผยโมเดลพื้นฐานต่อข้อมูลเอเจนต์จำนวนมาก โดยเติมเต็มด้วยความรู้พื้นฐานเกี่ยวกับการนำทางเว็บและสัญญาณความสดใหม่ของข้อมูล ขั้นตอนนี้จะเปิดใช้งานความสามารถที่ซ่อนอยู่ เช่น การวางแผนโดยนัย ผ่านการสร้างแบบจำลองภาษาแบบมาสก์บนเส้นทาง

หลังจาก CPT, SFT จะปรับโมเดลให้เข้ากับรูปแบบการสอน โดยใช้การจำลองการทำงานสังเคราะห์เพื่อสอนการกำหนดการกระทำที่แม่นยำ ที่นี่ โมเดลเรียนรู้ที่จะสร้างวงจร ReAct ที่สอดคล้องกัน ลดข้อผิดพลาดในการแยกวิเคราะห์การสังเกต การเปลี่ยนผ่านอย่างราบรื่น ขั้นตอน RL ใช้ Group Relative Policy Optimization (GRPO) ซึ่งเป็นอัลกอริทึมแบบ on-policy ที่กำหนดเอง
GRPO คำนวณการไล่ระดับนโยบายระดับโทเค็นด้วยการประมาณค่าความได้เปรียบแบบ leave-one-out ซึ่งช่วยลดความแปรปรวนในการตั้งค่าที่ไม่หยุดนิ่ง นอกจากนี้ยังกรองตัวอย่างเชิงลบอย่างระมัดระวัง ทำให้การอัปเดตในตัวจำลองแบบกำหนดเองมีความเสถียรยิ่งขึ้น ซึ่งเป็นฐานข้อมูล Wikipedia แบบออฟไลน์ที่จับคู่กับแซนด์บ็อกซ์เครื่องมือ การจำลองการทำงานแบบอะซิงโครนัสผ่านเฟรมเวิร์ก rLLM ช่วยเร่งการบรรจบกัน ทำให้ได้ผลลัพธ์ SOTA ด้วยการคำนวณที่ไม่มาก
ในรายละเอียด สภาพแวดล้อม RL จำลองการโต้ตอบของเบราว์เซอร์อย่างซื่อสัตย์ ให้รางวัลความสำเร็จหลายขั้นตอนมากกว่าการกระทำเดียว สิ่งนี้ส่งเสริมการวางแผนระยะยาว ซึ่งเอเจนต์จะทำซ้ำเมื่อเกิดความล้มเหลวบางส่วน ข้อสังเกตทางเทคนิคคือ ฟังก์ชันการสูญเสียรวมการเบี่ยงเบน KL เพื่อความอนุรักษ์นิยม ป้องกันการยุบโหมด นักพัฒนาสามารถจำลองสิ่งนี้ได้ผ่านสคริปต์การประเมินของ repo เพื่อเปรียบเทียบนโยบายที่กำหนดเอง
โดยรวมแล้ว ไปป์ไลน์นี้ถือเป็นความก้าวหน้า: มันเชื่อมโยงการฝึกอบรมล่วงหน้ากับการปรับใช้โดยไม่มีการแบ่งแยก ทำให้เกิดเอเจนต์ที่พัฒนาผ่านการลองผิดลองถูก
ประสิทธิภาพเกณฑ์มาตรฐาน: Tongyi DeepResearch ทำผลงานได้ดีเยี่ยมอย่างไร
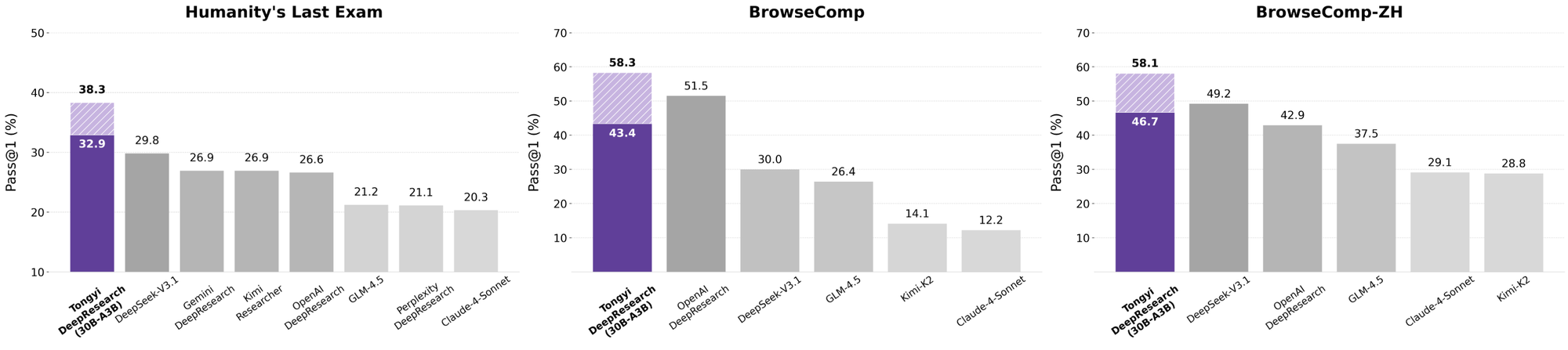
Tongyi DeepResearch โดดเด่นในการทดสอบเกณฑ์มาตรฐานเอเจนต์ที่เข้มงวด ซึ่งยืนยันการออกแบบของมัน ในการทดสอบ Humanity's Last Exam (HLE) ซึ่งเป็นการทดสอบการให้เหตุผลเชิงวิชาการ มันได้คะแนน 32.9 ในโหมด ReAct ซึ่งสูงกว่า OpenAI o3 ที่ 24.9 ช่องว่างนี้กว้างขึ้นในโหมด Heavy เป็น 38.3 ซึ่งเน้นย้ำถึงประสิทธิภาพของ IterResearch
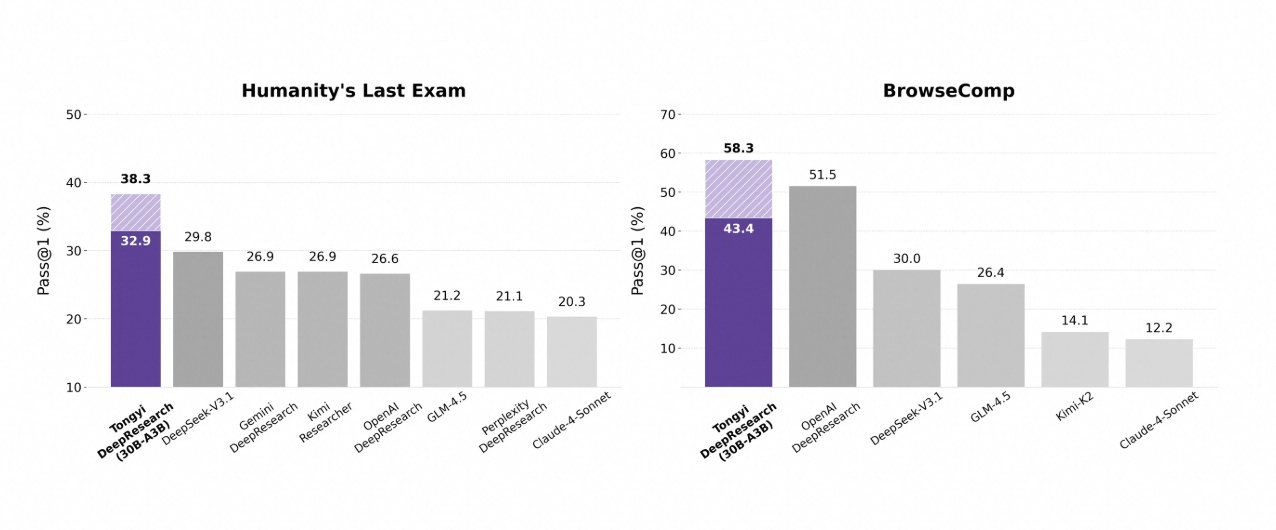
ในทำนองเดียวกัน BrowseComp ประเมินการค้นหาข้อมูลที่ซับซ้อน; Tongyi ทำคะแนนได้ 43.4 (EN) และ 46.7 (ZH) ซึ่งเฉือนชนะ o3 ที่ 49.7 และ 58.1 ตามลำดับในด้านประสิทธิภาพ เกณฑ์มาตรฐาน xbench-DeepSearch ซึ่งเน้นผู้ใช้สำหรับการค้นหาเชิงลึก พบว่า Tongyi ทำคะแนนได้ 75.0 เทียบกับ 67.0 ของ o3 ซึ่งเน้นย้ำถึงการสังเคราะห์ข้อมูลที่เหนือกว่า
เมตริกอื่นๆ ยืนยันสิ่งนี้: FRAMES ที่ 90.6 (เทียบกับ 84.0 ของ o3), GAIA ที่ 70.9 และ SimpleQA ที่ 95.0 แผนภูมิเปรียบเทียบแสดงให้เห็นสิ่งเหล่านี้ โดยมีแท่งสำหรับ Tongyi DeepResearch ที่สูงกว่า Gemini, Claude และอื่นๆ ใน HLE, BrowseComp, xbench, FRAMES และอีกมากมาย แท่งสีน้ำเงินแสดงถึงความเป็นผู้นำของ Tongyi ในขณะที่เส้นฐานสีเทาแสดงถึงข้อบกพร่องของคู่แข่ง
ผลลัพธ์เหล่านี้เกิดจากการปรับแต่งที่ตรงเป้าหมาย เช่น การกำหนดเส้นทางผู้เชี่ยวชาญแบบเลือกสรรสำหรับงานค้นหา ดังนั้น Tongyi DeepResearch จึงไม่เพียงแค่แข่งขันเท่านั้น แต่ยังเป็นผู้นำในด้านเอเจนต์โอเพนซอร์สอีกด้วย
การเปรียบเทียบ Tongyi DeepResearch กับผู้นำในอุตสาหกรรม
เมื่อนักพัฒนาประเมินเอเจนต์ AI การเปรียบเทียบจะเผยให้เห็นคุณค่าที่แท้จริง Tongyi DeepResearch ที่ 30B-A3B มีประสิทธิภาพเหนือกว่า OpenAI o3 ใน HLE (32.9 เทียบกับ 24.9) และ xbench (75.0 เทียบกับ 67.0) แม้ว่า o3 จะมีขนาดใหญ่กว่าก็ตาม เมื่อเทียบกับ Gemini ของ Google มันทำคะแนนได้ 35.2 ใน BrowseComp-ZH ซึ่งเป็นคะแนนที่เหนือกว่า 10 จุด
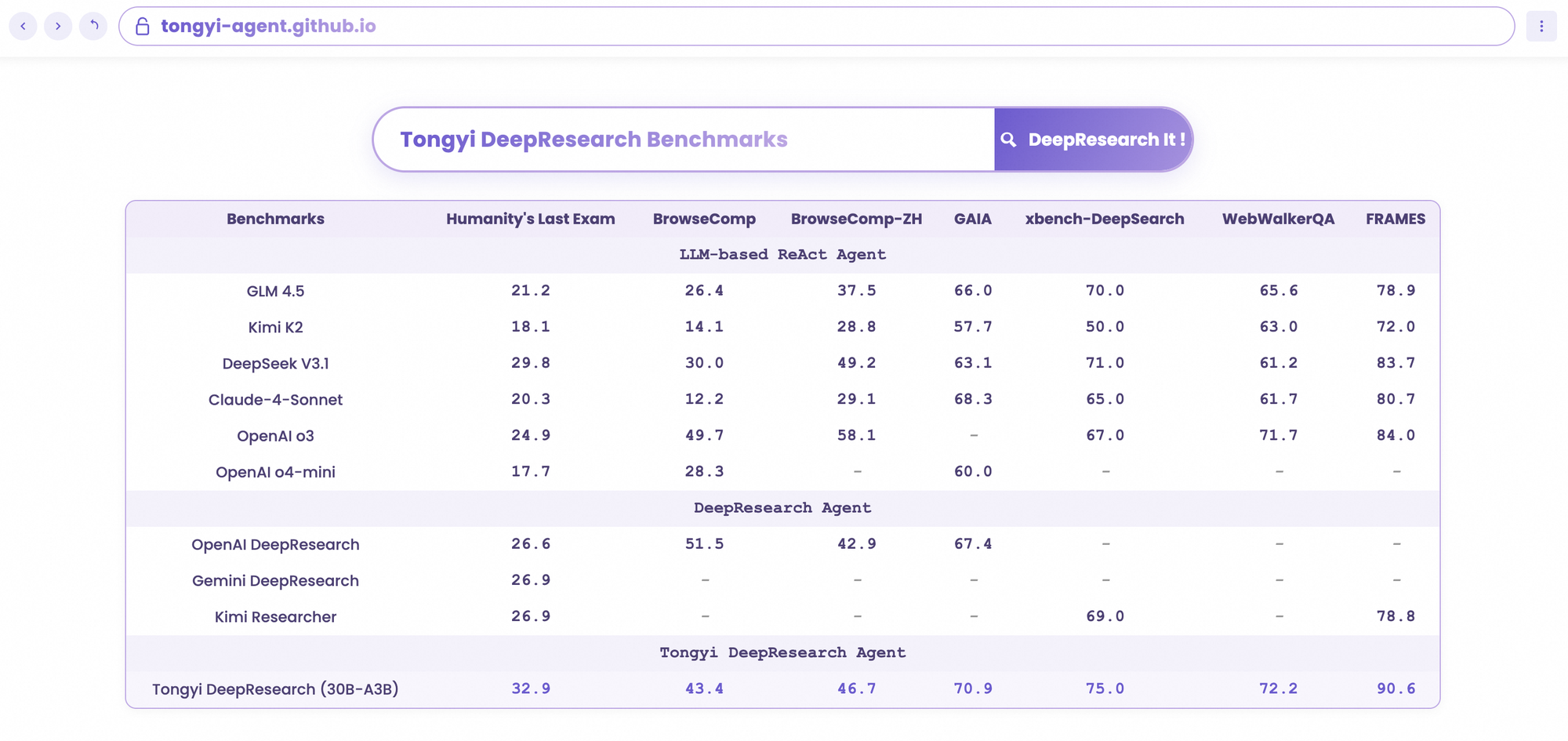
โมเดลที่เป็นกรรมสิทธิ์เช่น Claude 3.5 Sonnet ล้าหลังในการใช้เครื่องมือ; Tongyi ทำคะแนนได้ 90.6 ใน FRAMES ซึ่งสูงกว่า Sonnet ที่ 84.3 อย่างมาก คู่แข่งโอเพนซอร์ส เช่น Llama variants ล้าหลังกว่านั้นอีก เช่น 21.1 ใน HLE ความเบาบางของ MoE ของ Tongyi ช่วยให้เกิดความเท่าเทียมกันนี้ โดยใช้การคำนวณในการอนุมานน้อยลง
นอกจากนี้ การเข้าถึงยังเป็นปัจจัยสำคัญ: ในขณะที่ o3 ต้องการเครดิต API แต่ Tongyi สามารถทำงานได้แบบโลคัลผ่าน Hugging Face สำหรับเวิร์กโฟลว์ที่เน้น API ให้จับคู่กับ Apidog เพื่อจำลองเอนด์พอยต์ จำลองการเรียกใช้เครื่องมือได้อย่างมีประสิทธิภาพ
โดยพื้นฐานแล้ว Tongyi DeepResearch ทำให้ประสิทธิภาพระดับสูงเป็นประชาธิปไตย ท้าทายระบบนิเวศแบบปิด
การใช้งานในโลกจริง: Tongyi DeepResearch ในการปฏิบัติงาน
Tongyi DeepResearch ก้าวข้ามเกณฑ์มาตรฐาน สร้างผลกระทบที่จับต้องได้ ใน Gaode Mate ซึ่งเป็นแอปนำทางของ Alibaba มันวางแผนการเดินทางที่ซับซ้อน โดยสอบถามเที่ยวบิน โรงแรม และกิจกรรมต่างๆ พร้อมกันผ่านโหมด Heavy ผู้ใช้ได้รับแผนการเดินทางที่สังเคราะห์พร้อมการอ้างอิง ซึ่งช่วยลดเวลาการวางแผนได้ถึง 70%
ในทำนองเดียวกัน Tongyi FaRui ปฏิวัติการวิจัยทางกฎหมาย เอเจนต์จะวิเคราะห์กฎหมาย อ้างอิงคดีตัวอย่าง และสร้างบทสรุปพร้อมลิงก์ที่ตรวจสอบได้ ผู้เชี่ยวชาญตรวจสอบผลลัพธ์ได้อย่างรวดเร็ว ลดข้อผิดพลาดในโดเมนที่มีความเสี่ยงสูง
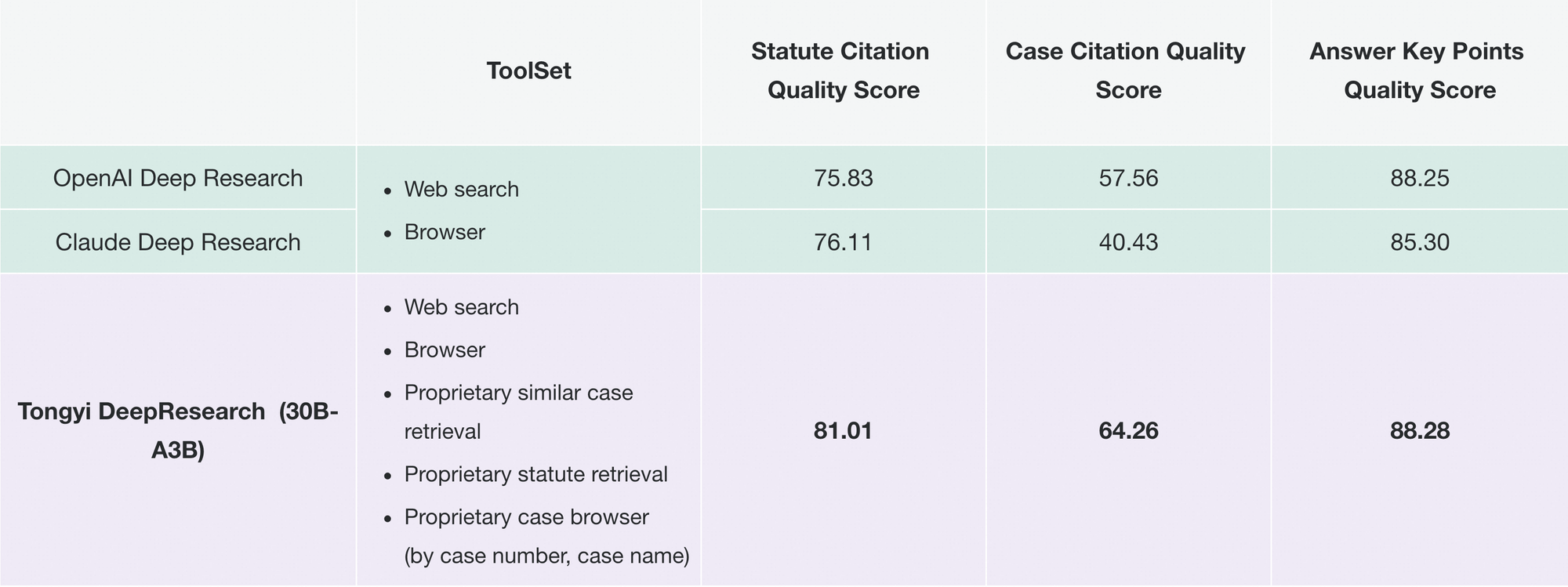
นอกเหนือจากนี้ องค์กรต่างๆ ยังนำไปปรับใช้สำหรับข้อมูลเชิงลึกทางการตลาด: การรวบรวมข้อมูลคู่แข่ง การสังเคราะห์แนวโน้ม ความยืดหยุ่นของ repo รองรับการขยายเหล่านี้—เพิ่มเครื่องมือที่กำหนดเองผ่านการกำหนดค่า JSON
เมื่อมีการนำไปใช้มากขึ้น Tongyi DeepResearch จะรวมเข้ากับระบบนิเวศเช่น LangChain ซึ่งช่วยขยายกลุ่มเอเจนต์ สำหรับนักพัฒนา API, Apidog เสริมสิ่งนี้โดยการตรวจสอบความถูกต้องของการรวมระบบก่อนการปรับใช้
กรณีเหล่านี้แสดงให้เห็นถึงความสามารถในการปรับขนาด: ตั้งแต่แอปสำหรับผู้บริโภคไปจนถึงเครื่องมือ B2B โมเดลนี้ให้ความเป็นอิสระที่เชื่อถือได้
เริ่มต้นใช้งาน Tongyi DeepResearch: คู่มือสำหรับนักพัฒนา
นำ Tongyi DeepResearch ไปใช้งานได้อย่างง่ายดายด้วย GitHub repo เริ่มต้นด้วยการสร้าง Conda env: conda create -n deepresearch python=3.10 เปิดใช้งานและติดตั้ง: pip install -r requirements.txt
เตรียมข้อมูลใน eval_data/ เป็น JSONL โดยมีคีย์ question และ answer สำหรับไฟล์ ให้เพิ่มชื่อไฟล์นำหน้าคำถามและจัดเก็บใน file_corpus/ แก้ไข run_react_infer.sh สำหรับเส้นทางโมเดล (เช่น URL ของ Hugging Face) และคีย์ API สำหรับเครื่องมือ
เรียกใช้: bash run_react_infer.sh ผลลัพธ์จะอยู่ในเส้นทางที่ระบุ พร้อมสำหรับการวิเคราะห์
สำหรับโหมด Heavy ให้กำหนดค่าพารามิเตอร์ IterResearch ในโค้ด—ตั้งค่าจำนวนเอเจนต์และรอบการทำงาน ทดสอบประสิทธิภาพผ่านสคริปต์ evaluation/ โดยเปรียบเทียบกับเกณฑ์มาตรฐาน
แก้ไขปัญหาด้วยบันทึก (logs); ปัญหาทั่วไป เช่น ความไม่ตรงกันของ tokenizer สามารถแก้ไขได้ผ่านการตรวจสอบ BF16 tensor เพื่อเพิ่มประสิทธิภาพ ดาวน์โหลด Apidog ฟรีสำหรับการจำลอง API ทดสอบเอนด์พอยต์ของเครื่องมือโดยไม่ต้องเรียกใช้จริง
การตั้งค่านี้ช่วยให้คุณสร้างต้นแบบเอเจนต์ได้อย่างรวดเร็ว
ทิศทางในอนาคต: การขยาย Tongyi DeepResearch ให้ก้าวหน้ายิ่งขึ้น
ในอนาคต Tongyi Lab ตั้งเป้าที่จะขยายบริบทเกิน 128K ทำให้สามารถวิเคราะห์ระยะยาวเป็นพิเศษได้ เช่น การวิเคราะห์ที่มีความยาวเท่าหนังสือ พวกเขาวางแผนที่จะตรวจสอบความถูกต้องบนฐาน MoE ที่ใหญ่ขึ้น เพื่อสำรวจขีดจำกัดของความสามารถในการปรับขนาด
การปรับปรุง RL รวมถึงการจำลองการทำงานบางส่วนเพื่อประสิทธิภาพ และวิธีการแบบ off-policy เพื่อลดการเปลี่ยนแปลง การมีส่วนร่วมของชุมชนสามารถรวมเครื่องมือด้านวิสัยทัศน์หรือหลายภาษา ซึ่งจะช่วยขยายขอบเขต
เมื่อโอเพนซอร์สพัฒนาขึ้น Tongyi DeepResearch จะเป็นหลักในการขับเคลื่อนความก้าวหน้าร่วมกัน ส่งเสริมการแสวงหา AGI
บทสรุป: โอบรับยุค Tongyi DeepResearch
Tongyi DeepResearch เปลี่ยนโฉม AI แบบเอเจนต์ ผสมผสานประสิทธิภาพ การเปิดกว้าง และความเชี่ยวชาญ เกณฑ์มาตรฐาน สถาปัตยกรรม และแอปพลิเคชันของมันทำให้เป็นผู้นำ แซงหน้าคู่แข่งอย่างผลิตภัณฑ์ของ OpenAI นักพัฒนาทั้งหลาย จงใช้พลังนี้—ดาวน์โหลดโมเดล ทดลอง และรวมเข้ากับ Apidog เพื่อ API ที่ราบรื่น
ในสาขาที่กำลังมุ่งหน้าสู่ความเป็นอิสระ Tongyi DeepResearch เร่งความก้าวหน้า เริ่มสร้างสรรค์วันนี้ ข้อมูลเชิงลึกรออยู่