
```html
การรัน Gemma 3 ในเครื่องของคุณด้วย Ollama ช่วยให้คุณควบคุมสภาพแวดล้อม AI ของคุณได้อย่างเต็มที่โดยไม่ต้องพึ่งพาบริการคลาวด์ คู่มือนี้จะแนะนำคุณตลอดการตั้งค่า Ollama, ดาวน์โหลด Gemma 3 และทำให้มันทำงานบนเครื่องของคุณ
มาเริ่มกันเลย
ทำไมต้องรัน Gemma 3 ในเครื่องของคุณด้วย Ollama?
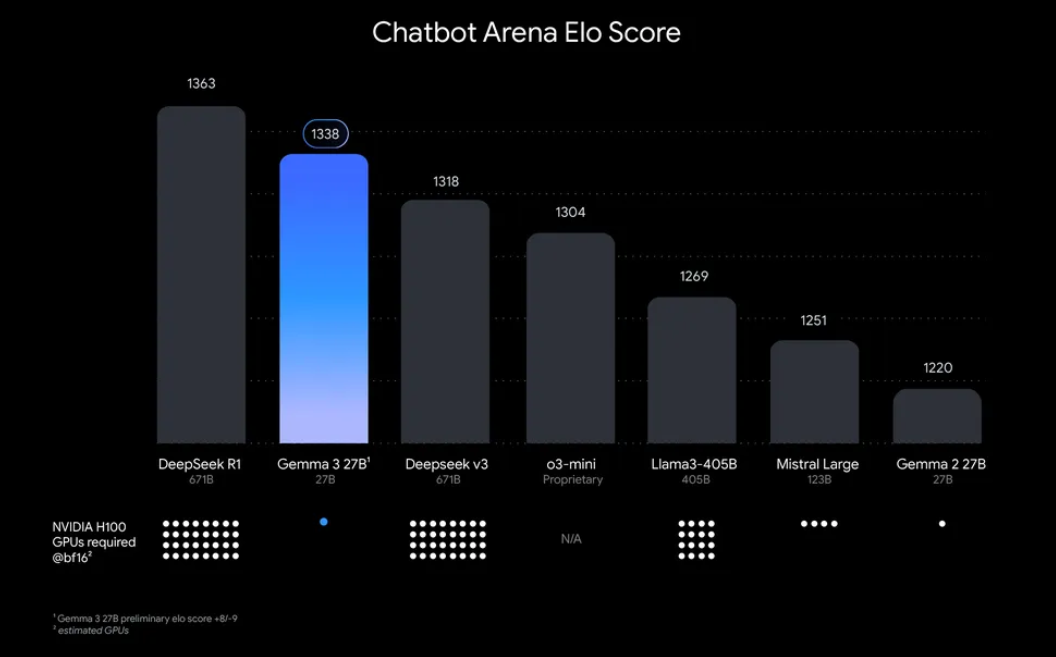
“ทำไมต้องรัน Gemma 3 ในเครื่องของคุณ?” มีเหตุผลที่น่าสนใจอยู่บ้าง อย่างแรก การปรับใช้ในเครื่องช่วยให้คุณควบคุมข้อมูลและความเป็นส่วนตัวของคุณได้อย่างเต็มที่ ไม่จำเป็นต้องส่งข้อมูลที่ละเอียดอ่อนไปยังคลาวด์ นอกจากนี้ ยังคุ้มค่าใช้จ่าย เนื่องจากคุณหลีกเลี่ยงค่าธรรมเนียมการใช้งาน API ที่ต่อเนื่อง นอกจากนี้ ประสิทธิภาพของ Gemma 3 ยังหมายความว่าแม้แต่โมเดล 27B ก็สามารถทำงานบน GPU เดียวได้ ทำให้เข้าถึงได้สำหรับนักพัฒนาที่มีฮาร์ดแวร์ขนาดพอประมาณ
Ollama ซึ่งเป็นแพลตฟอร์มน้ำหนักเบาสำหรับการรันโมเดลภาษาขนาดใหญ่ (LLMs) ในเครื่อง ช่วยลดความซับซ้อนของกระบวนการนี้ มันบรรจุทุกสิ่งที่คุณต้องการ น้ำหนักของโมเดล การกำหนดค่า และการพึ่งพาเข้าในรูปแบบที่ใช้งานง่าย การรวมกันของ Gemma 3 และ Ollama นี้เหมาะสำหรับการปรับแต่ง การสร้างแอปพลิเคชัน หรือการทดสอบเวิร์กโฟลว์ AI บนเครื่องของคุณ ดังนั้น มาเริ่มกันเลย!
สิ่งที่คุณต้องใช้ในการรัน Gemma 3 ด้วย Ollama
ก่อนที่เราจะเข้าสู่การตั้งค่า ตรวจสอบให้แน่ใจว่าคุณมีข้อกำหนดเบื้องต้นดังต่อไปนี้:
- เครื่องที่เข้ากันได้: คุณจะต้องมีคอมพิวเตอร์ที่มี GPU (โดยเฉพาะ NVIDIA เพื่อประสิทธิภาพสูงสุด) หรือ CPU ที่มีประสิทธิภาพ โมเดล 27B ต้องการทรัพยากรจำนวนมาก แต่รุ่นที่เล็กกว่า เช่น 1B หรือ 4B สามารถทำงานบนฮาร์ดแวร์ที่มีประสิทธิภาพน้อยกว่าได้
- ติดตั้ง Ollama: ดาวน์โหลดและติดตั้ง Ollama ซึ่งมีให้สำหรับ MacOS, Windows และ Linux คุณสามารถรับได้จาก ollama.com
- ทักษะ Command-Line พื้นฐาน: คุณจะโต้ตอบกับ Ollama ผ่านเทอร์มินัลหรือพรอมต์คำสั่ง
- การเชื่อมต่ออินเทอร์เน็ต: ในขั้นต้น คุณจะต้องดาวน์โหลดโมเดล Gemma 3 แต่เมื่อดาวน์โหลดแล้ว คุณสามารถรันแบบออฟไลน์ได้
- ตัวเลือก: Apidog สำหรับการทดสอบ API: หากคุณวางแผนที่จะรวม Gemma 3 เข้ากับ API หรือทดสอบการตอบสนองในเชิงโปรแกรม อินเทอร์เฟซที่ใช้งานง่ายของ Apidog สามารถช่วยคุณประหยัดเวลาและความพยายามได้
ตอนนี้คุณพร้อมแล้ว มาเจาะลึกกระบวนการติดตั้งและการตั้งค่ากันเลย
คู่มือทีละขั้นตอน: การติดตั้ง Ollama และการดาวน์โหลด Gemma 3
1. ติดตั้ง Ollama บนเครื่องของคุณ
Ollama ทำให้การปรับใช้ LLM ในเครื่องเป็นเรื่องง่าย และการติดตั้งก็ตรงไปตรงมา นี่คือวิธีการ:
- สำหรับ MacOS/Windows: ไปที่ ollama.com และดาวน์โหลดตัวติดตั้งสำหรับระบบปฏิบัติการของคุณ ทำตามคำแนะนำบนหน้าจอเพื่อทำการติดตั้งให้เสร็จสิ้น
- สำหรับ Linux (เช่น Ubuntu): เปิดเทอร์มินัลของคุณและรันคำสั่งต่อไปนี้:
curl -fsSL https://ollama.com/install.sh | sh
สคริปต์นี้จะตรวจจับฮาร์ดแวร์ของคุณโดยอัตโนมัติ (รวมถึง GPU) และติดตั้ง Ollama
เมื่อติดตั้งแล้ว ให้ตรวจสอบการติดตั้งโดยการรัน:
ollama --version

คุณควรเห็นหมายเลขเวอร์ชันปัจจุบัน ยืนยันว่า Ollama พร้อมใช้งาน
2. ดึงโมเดล Gemma 3 โดยใช้ Ollama
ไลบรารีโมเดลของ Ollama รวมถึง Gemma 3 ขอบคุณสำหรับการรวมเข้ากับแพลตฟอร์มต่างๆ เช่น Hugging Face และข้อเสนอ AI ของ Google ในการดาวน์โหลด Gemma 3 ให้ใช้คำสั่ง ollama pull
ollama pull gemma3

สำหรับโมเดลที่เล็กกว่า คุณสามารถใช้:
ollama pull gemma3:12bollama pull gemma3:4bollama pull gemma3:1b
ขนาดการดาวน์โหลดแตกต่างกันไปตามโมเดล คาดว่าโมเดล 27B จะมีขนาดหลายกิกะไบต์ ดังนั้นตรวจสอบให้แน่ใจว่าคุณมีพื้นที่เก็บข้อมูลเพียงพอ โมเดล Gemma 3 ได้รับการปรับให้เหมาะสมเพื่อประสิทธิภาพ แต่ก็ยังต้องการฮาร์ดแวร์ที่ดีสำหรับรุ่นที่ใหญ่กว่า
3. ตรวจสอบการติดตั้ง
เมื่อดาวน์โหลดแล้ว ให้ตรวจสอบว่าโมเดลพร้อมใช้งานโดยการแสดงรายการโมเดลทั้งหมด:
ollama list

คุณควรเห็น gemma3 (หรือขนาดที่คุณเลือก) ในรายการ หากมี คุณก็พร้อมที่จะรัน Gemma 3 ในเครื่องของคุณแล้ว!
การรัน Gemma 3 ด้วย Ollama: โหมดโต้ตอบและการรวม API
โหมดโต้ตอบ: แชทกับ Gemma 3
โหมดโต้ตอบของ Ollama ช่วยให้คุณแชทกับ Gemma 3 ได้โดยตรงจากเทอร์มินัล ในการเริ่มต้น ให้รัน:
ollama run gemma3
คุณจะเห็นพรอมต์ที่คุณสามารถพิมพ์แบบสอบถามได้ ตัวอย่างเช่น ลอง:
คุณสมบัติหลักของ Gemma 3 คืออะไร?
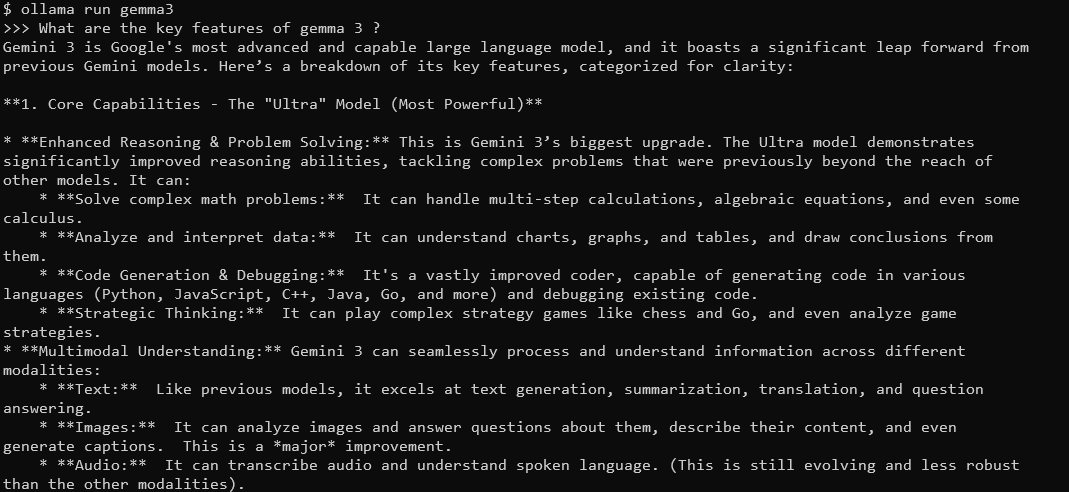
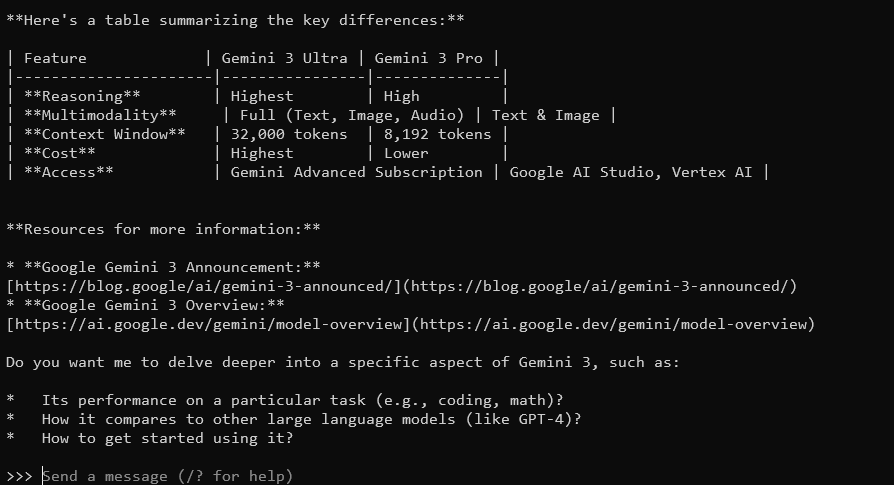
Gemma 3 พร้อมด้วยหน้าต่างบริบท 128K และความสามารถแบบหลายรูปแบบ จะตอบคำถามโดยละเอียดและคำนึงถึงบริบท รองรับมากกว่า 140 ภาษา และสามารถประมวลผลข้อความ รูปภาพ และแม้แต่การป้อนข้อมูลวิดีโอ (สำหรับบางขนาด)
ในการออก ให้พิมพ์ Ctrl+D หรือ /bye
การรวม Gemma 3 กับ Ollama API
หากคุณต้องการสร้างแอปพลิเคชันหรือทำให้การโต้ตอบเป็นไปโดยอัตโนมัติ Ollama มี API ที่คุณสามารถใช้ได้ นี่คือที่ที่ Apidog เปล่งประกาย อินเทอร์เฟซที่ใช้งานง่ายช่วยให้คุณทดสอบและจัดการคำขอ API ได้อย่างมีประสิทธิภาพ นี่คือวิธีการเริ่มต้น:
เริ่ม Ollama Server: รันคำสั่งต่อไปนี้เพื่อเปิดใช้เซิร์ฟเวอร์ API ของ Ollama:
ollama serve
สิ่งนี้จะเริ่มเซิร์ฟเวอร์บน localhost:11434 ตามค่าเริ่มต้น
สร้างคำขอ API: คุณสามารถโต้ตอบกับ Gemma 3 ผ่านคำขอ HTTP ตัวอย่างเช่น ใช้ curl เพื่อส่งพรอมต์:
curl http://localhost:11434/api/generate -d '{"model": "gemma3", "prompt": "What is the capital of France?"}'
การตอบสนองจะรวมเอาต์พุตของ Gemma 3 ซึ่งจัดรูปแบบเป็น JSON
ใช้ Apidog สำหรับการทดสอบ: ดาวน์โหลด Apidog ฟรีและสร้างคำขอ API เพื่อทดสอบการตอบสนองของ Gemma 3 อินเทอร์เฟซภาพของ Apidog ช่วยให้คุณป้อนปลายทาง (http://localhost:11434/api/generate) ตั้งค่าเพย์โหลด JSON และวิเคราะห์การตอบสนองโดยไม่ต้องเขียนโค้ดที่ซับซ้อน สิ่งนี้มีประโยชน์อย่างยิ่งสำหรับการแก้ไขข้อบกพร่องและปรับปรุงการรวมของคุณ
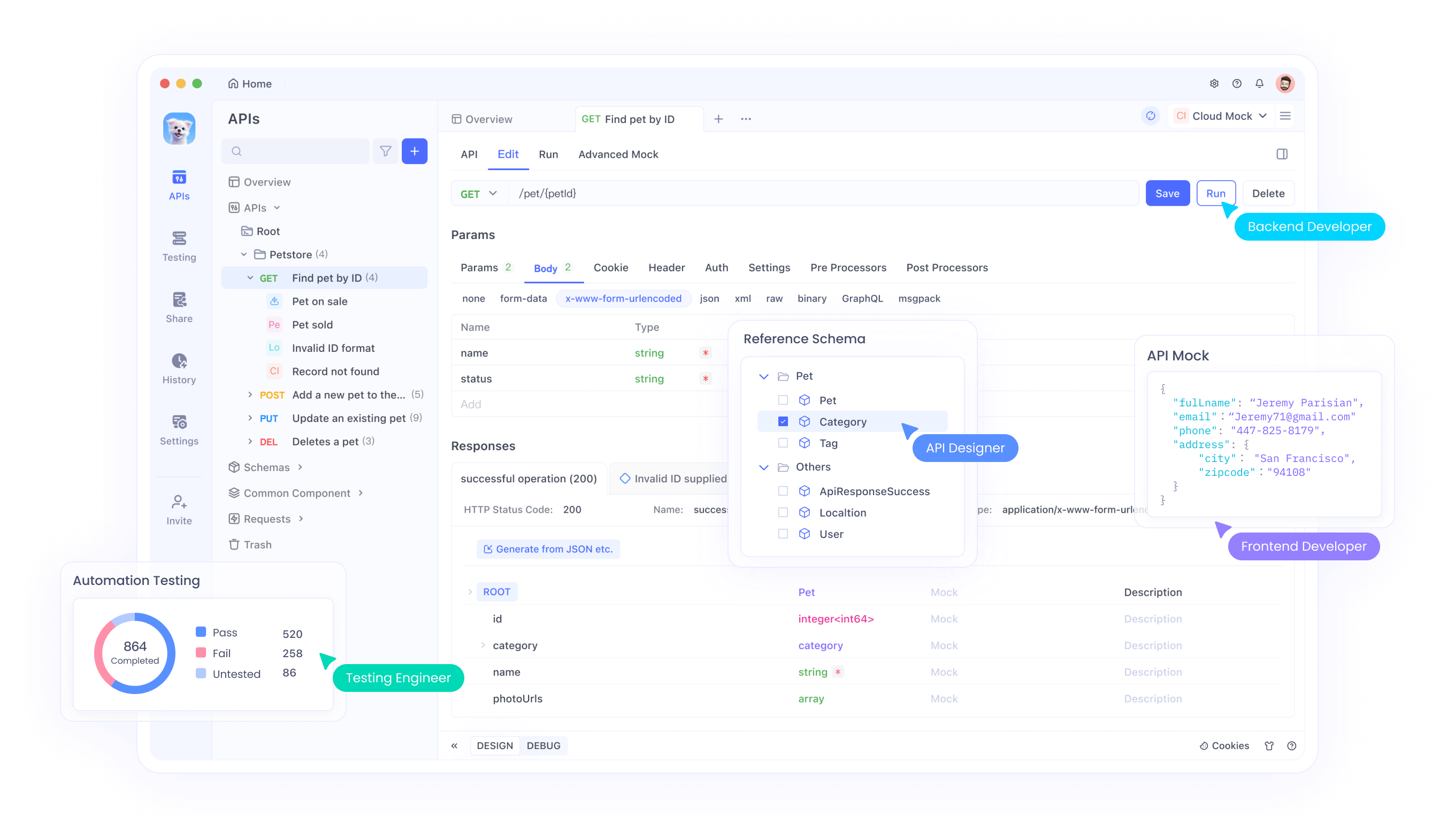
คู่มือทีละขั้นตอนในการใช้การทดสอบ SSE บน Apidog
มาดูขั้นตอนการใช้คุณสมบัติการทดสอบ SSE ที่ปรับให้เหมาะสมบน Apidog พร้อมด้วยการปรับปรุง Auto-Merge ใหม่ ทำตามขั้นตอนเหล่านี้เพื่อตั้งค่าและเพิ่มประสบการณ์การแก้ไขข้อบกพร่องแบบเรียลไทม์ของคุณให้สูงสุด
ขั้นตอนที่ 1: สร้างคำขอ API ใหม่
เริ่มต้นด้วยการเปิดตัวโปรเจกต์ HTTP ใหม่บน Apidog เพิ่มปลายทางใหม่และป้อน URL สำหรับปลายทาง API หรือโมเดล AI ของคุณ นี่คือจุดเริ่มต้นสำหรับการทดสอบและแก้ไขข้อบกพร่องของสตรีมข้อมูลแบบเรียลไทม์ของคุณ
ขั้นตอนที่ 2: ส่งคำขอ
เมื่อคุณตั้งค่าปลายทางของคุณแล้ว ให้ส่งคำขอ API สังเกตส่วนหัวการตอบสนองอย่างระมัดระวัง หากส่วนหัวรวม Content-Type: text/event-stream Apidog จะรับรู้และตีความการตอบสนองเป็นสตรีม SSE โดยอัตโนมัติ การตรวจจับนี้มีความสำคัญอย่างยิ่งสำหรับกระบวนการผสานรวมอัตโนมัติในภายหลัง

ขั้นตอนที่ 3: ตรวจสอบไทม์ไลน์แบบเรียลไทม์
หลังจากสร้างการเชื่อมต่อ SSE แล้ว Apidog จะเปิดมุมมองไทม์ไลน์เฉพาะที่ซึ่งกิจกรรม SSE ขาเข้าทั้งหมดจะแสดงแบบเรียลไทม์ ไทม์ไลน์นี้จะอัปเดตอย่างต่อเนื่องเมื่อข้อมูลใหม่มาถึง ทำให้คุณสามารถตรวจสอบการไหลของข้อมูลได้อย่างแม่นยำ ไทม์ไลน์ไม่ใช่แค่การถ่ายโอนข้อมูลดิบเท่านั้น มันคือการแสดงภาพที่มีโครงสร้างอย่างระมัดระวังที่ช่วยให้คุณเห็นได้อย่างชัดเจนว่าข้อมูลถูกส่งเมื่อใดและอย่างไร
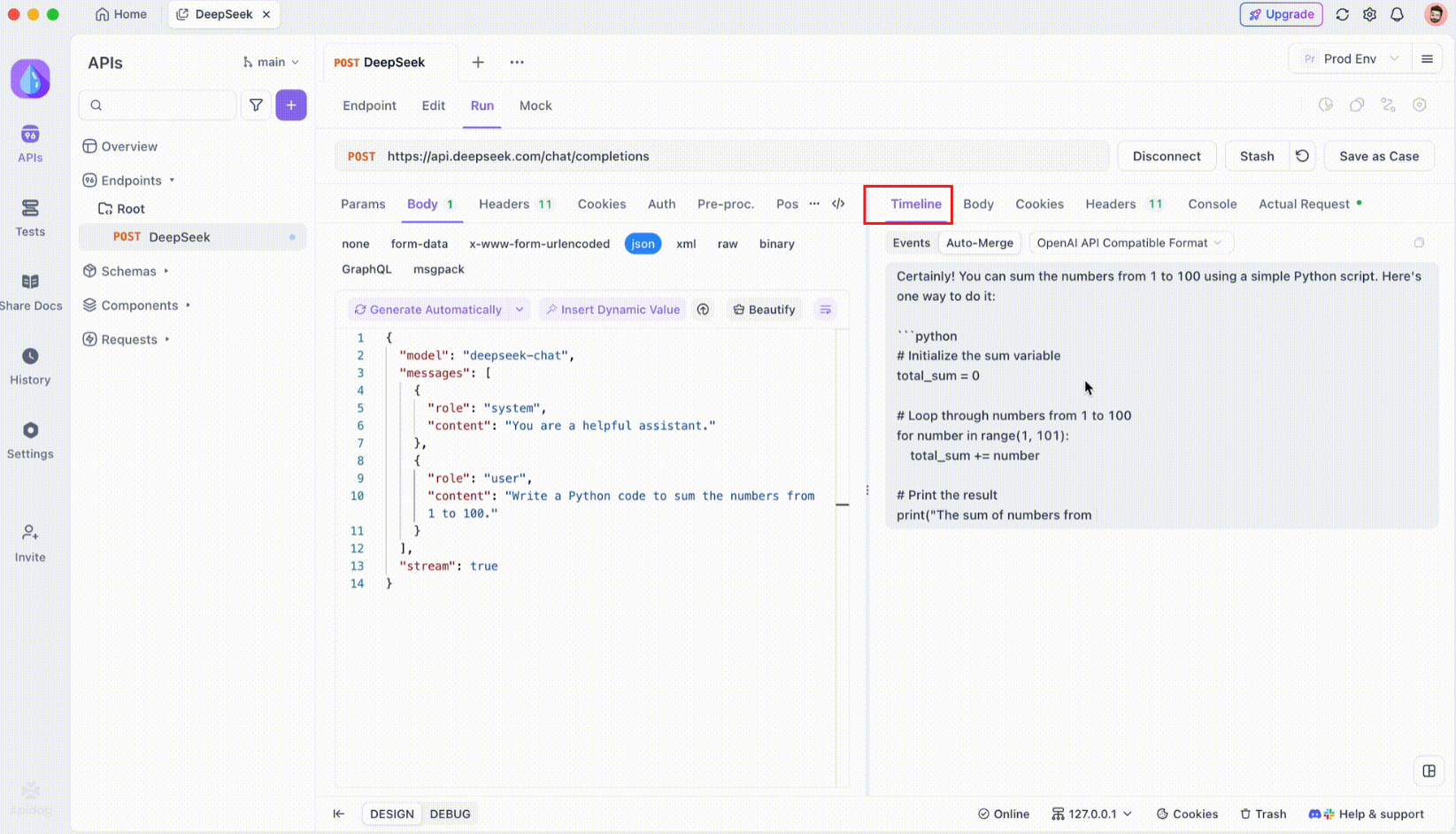
ขั้นตอนที่ 4: ข้อความ Auto-Merge
นี่คือที่ที่เวทมนตร์เกิดขึ้น ด้วยการปรับปรุง Auto-Merge Apidog จะรับรู้รูปแบบโมเดล AI ยอดนิยมโดยอัตโนมัติและผสานการตอบสนอง SSE ที่กระจัดกระจายเข้ากับการตอบกลับที่สมบูรณ์ ขั้นตอนนี้รวมถึง:
- การรับรู้อัตโนมัติ: Apidog ตรวจสอบว่าการตอบสนองอยู่ในรูปแบบที่รองรับ (OpenAI, Gemini หรือ Claude)
- การผสานข้อความ: หากรูปแบบได้รับการยอมรับ แพลตฟอร์มจะรวมชิ้นส่วน SSE ทั้งหมดโดยอัตโนมัติ ส่งมอบการตอบสนองที่ราบรื่นและสมบูรณ์
- การแสดงภาพที่ได้รับการปรับปรุง: สำหรับโมเดล AI บางประเภท เช่น DeepSeek R1 ไทม์ไลน์ยังแสดงกระบวนการคิดของโมเดล ซึ่งให้ข้อมูลเชิงลึกเพิ่มเติมเกี่ยวกับเหตุผลเบื้องหลังการตอบสนองที่สร้างขึ้น
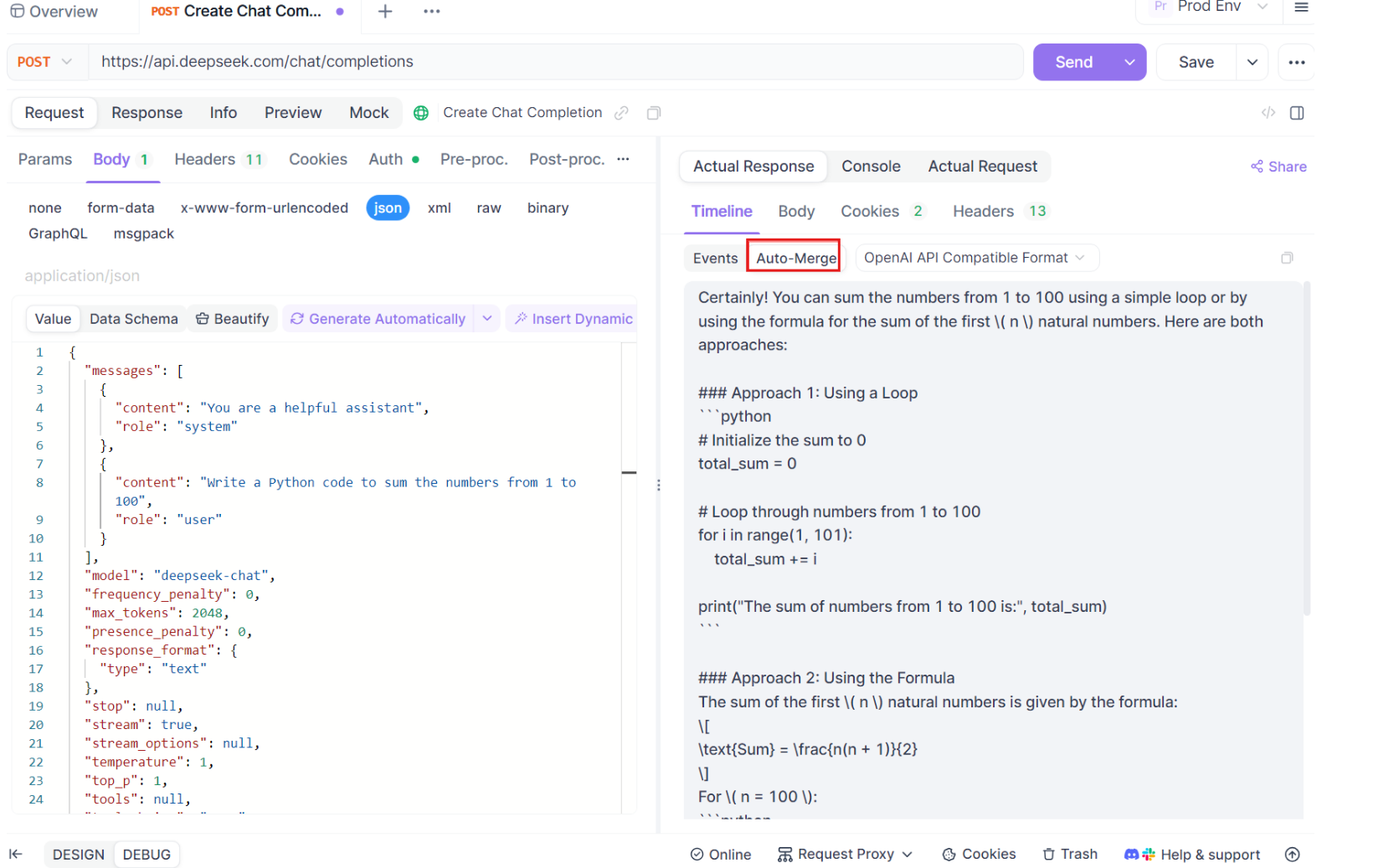
คุณสมบัตินี้มีประโยชน์อย่างยิ่งเมื่อจัดการกับแอปพลิเคชันที่ขับเคลื่อนด้วย AI ทำให้มั่นใจได้ว่าทุกส่วนของการตอบสนองจะถูกจับและนำเสนอทั้งหมดโดยไม่มีการแทรกแซงด้วยตนเอง
ขั้นตอนที่ 5: กำหนดค่ากฎการแยก JSONPath
ไม่ใช่การตอบสนอง SSE ทั้งหมดที่จะเป็นไปตามรูปแบบในตัวโดยอัตโนมัติ เมื่อจัดการกับการตอบสนอง JSON ที่ต้องมีการแยกแบบกำหนดเอง Apidog ช่วยให้คุณสามารถกำหนดค่ากฎ JSONPath ได้ ตัวอย่างเช่น หากการตอบสนอง SSE ดิบของคุณมีอ็อบเจกต์ JSON และคุณต้องแยกฟิลด์ content คุณสามารถตั้งค่าการกำหนดค่า JSONPath ได้ดังนี้:
- JSONPath:
$.choices[0].message.content - คำอธิบาย:
$อ้างถึงรากของอ็อบเจกต์ JSONchoices[0]เลือกองค์ประกอบแรกของอาร์เรย์choicesmessage.contentระบุฟิลด์เนื้อหาภายในอ็อบเจกต์ข้อความ
การกำหนดค่านี้จะสั่งให้ Apidog เกี่ยวกับวิธีการแยกข้อมูลที่ต้องการจากการตอบสนอง SSE ของคุณ ทำให้มั่นใจได้ว่าแม้แต่การตอบสนองที่ไม่เป็นไปตามมาตรฐานก็จะได้รับการจัดการอย่างมีประสิทธิภาพ
บทสรุป
การรัน Gemma 3 ในเครื่องของคุณด้วย Ollama เป็นวิธีที่น่าตื่นเต้นในการเข้าถึงความสามารถ AI ขั้นสูงของ Google โดยไม่ต้องออกจากเครื่องของคุณ ตั้งแต่การติดตั้ง Ollama และการดาวน์โหลดโมเดลไปจนถึงการโต้ตอบผ่านเทอร์มินัลหรือ API คู่มือนี้ได้แนะนำคุณตลอดทุกขั้นตอน ด้วยคุณสมบัติแบบหลายรูปแบบ การสนับสนุนหลายภาษา และประสิทธิภาพที่น่าประทับใจ Gemma 3 จึงเป็นตัวเปลี่ยนเกมสำหรับนักพัฒนาและผู้ที่สนใจ AI อย่าลืมใช้เครื่องมือต่างๆ เช่น Apidog สำหรับการทดสอบและการรวม API ที่ราบรื่น ดาวน์โหลดได้ฟรีวันนี้เพื่อปรับปรุงโปรเจกต์ Gemma 3 ของคุณ!
ไม่ว่าคุณจะกำลังปรับแต่งโมเดล 1B บนแล็ปท็อปหรือผลักดันขีดจำกัดของโมเดล 27B บน GPU rig ตอนนี้คุณก็พร้อมที่จะสำรวจความเป็นไปได้แล้ว ขอให้สนุกกับการเขียนโค้ด และมาดูกันว่าคุณจะสร้างสิ่งมหัศจรรย์อะไรด้วย Gemma 3!
```


