
นักพัฒนาและผู้ที่ชื่นชอบ AI ต่างมองหาโมเดลที่มีประสิทธิภาพสูงโดยไม่ต้องการทรัพยากรจำนวนมาก Google ได้เปิดตัว Gemma 3 270M ซึ่งเป็นโมเดลภาษาขนาดกะทัดรัดที่มีพารามิเตอร์ 270 ล้านตัว โมเดลนี้โดดเด่นในฐานะโมเดลที่เล็กที่สุดในตระกูล Gemma 3 ซึ่งได้รับการปรับแต่งมาสำหรับงานบนอุปกรณ์ คุณจะได้รับความสามารถในการสร้างข้อความ การตอบคำถาม การสรุป และการให้เหตุผล โดยทั้งหมดนี้สามารถทำงานได้บนอุปกรณ์ของคุณ
Gemma 3 270M รองรับความยาวคอนเท็กซ์ 32,000 โทเค็น ซึ่งช่วยให้สามารถจัดการอินพุตจำนวนมากได้อย่างมีประสิทธิภาพ นอกจากนี้ยังรวมเทคนิคการควอนไทเซชัน เช่น Q4_0 Quantization Aware Training (QAT) ซึ่งช่วยลดความต้องการทรัพยากรโดยไม่ลดทอนคุณภาพ ผลที่ได้คือคุณจะได้รับประสิทธิภาพใกล้เคียงกับโมเดลที่มีความแม่นยำเต็มรูปแบบ แต่ใช้หน่วยความจำและการประมวลผลน้อยลง
อย่างไรก็ตาม สิ่งที่ทำให้ Gemma 3 270M น่าสนใจเป็นพิเศษคือความสามารถในการเข้าถึง คุณสามารถรันได้บนฮาร์ดแวร์มาตรฐาน รวมถึงแล็ปท็อป หรือแม้แต่โทรศัพท์มือถือ ซึ่งส่งเสริมความเป็นส่วนตัวและแอปพลิเคชันที่มีความหน่วงต่ำ ถัดไป ลองพิจารณาว่าโมเดลนี้เข้ากับแนวโน้มการพัฒนา AI ในวงกว้างได้อย่างไร ซึ่งประสิทธิภาพเป็นตัวขับเคลื่อนนวัตกรรม
ทำความเข้าใจสถาปัตยกรรมของ Gemma 3 270M
Google สร้าง Gemma 3 270M บนสถาปัตยกรรมที่ใช้ Transformer โดยมีพารามิเตอร์ 170 ล้านตัวสำหรับการฝัง (embeddings) พร้อมคลังคำศัพท์ 256,000 โทเค็น และ 100 ล้านตัวสำหรับบล็อก Transformer การตั้งค่านี้ช่วยให้รองรับได้หลายภาษาและจัดการงานเฉพาะทางได้ คุณจะได้รับประโยชน์จากเทคนิคต่างๆ เช่น การควอนไทเซชันแบบ INT4, rotary position embeddings และ group query attention ซึ่งช่วยเพิ่มความเร็วในการอนุมานและความเบาของโมเดล
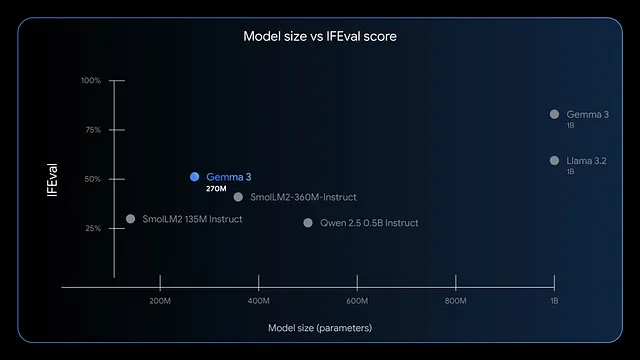
นอกจากนี้ โมเดลยังโดดเด่นในการทำตามคำสั่งและการดึงข้อมูล เกณฑ์มาตรฐานแสดงให้เห็นคะแนน F1 ที่สูงบน IFEval ซึ่งบ่งชี้ถึงประสิทธิภาพที่แข็งแกร่งในงานประเมิน เมื่อเทียบกับโมเดลขนาดใหญ่กว่าอย่าง GPT-4 หรือ Phi-3 Mini, Gemma 3 270M ให้ความสำคัญกับประสิทธิภาพ โดยใช้หน่วยความจำน้อยกว่า 200MB ในโหมด 4 บิตบนอุปกรณ์อย่าง Apple M4 Max
ดังนั้น คุณสามารถนำไปใช้งานในสถานการณ์ที่ต้องการการตอบสนองที่รวดเร็ว เช่น การวิเคราะห์ความรู้สึกแบบเรียลไทม์ หรือการดึงเอนทิตีทางการแพทย์ อย่างไรก็ตาม ขนาดที่เล็กของมันไม่ได้จำกัดความคิดสร้างสรรค์ คุณสามารถนำไปใช้กับการเขียนเชิงสร้างสรรค์หรือการตรวจสอบการปฏิบัติตามกฎระเบียบทางการเงินได้ ในลำดับถัดไป เราจะมาประเมินข้อดีของการรันโมเดลนี้บนเครื่องของคุณ
ประโยชน์ของการรัน Gemma 3 270M บนเครื่อง
คุณสามารถเพิ่มความเป็นส่วนตัวได้โดยการเก็บข้อมูลไว้บนอุปกรณ์ของคุณ หลีกเลี่ยงการส่งข้อมูลผ่านคลาวด์ที่อาจมีความเสี่ยงต่อการเปิดเผยข้อมูล Gemma 3 270M ช่วยลดความหน่วง ทำให้สามารถตอบสนองได้ภายในมิลลิวินาทีแทนที่จะเป็นวินาที นอกจากนี้ยังช่วยลดค่าใช้จ่ายเนื่องจากคุณไม่ต้องเสียค่าสมัครสมาชิกสำหรับ API ที่ใช้คลาวด์
นอกจากนี้ ประสิทธิภาพการใช้พลังงานของโมเดลยังโดดเด่น โดยใช้แบตเตอรี่เพียง 0.75% ของ Pixel 9 Pro สำหรับการสนทนา 25 ครั้งในโหมด INT4-quantized คุณสมบัตินี้เหมาะสำหรับการประมวลผลบนมือถือและ Edge Computing ซึ่งพลังงานเป็นสิ่งสำคัญ คุณยังสามารถปรับแต่งโมเดลได้อย่างง่ายดดายผ่านการ Fine-tuning ด้วยเครื่องมืออย่าง LoRA ซึ่งต้องการข้อมูลเพียงเล็กน้อย
อย่างไรก็ตาม การรันบนเครื่องช่วยเสริมศักยภาพให้กับทีมขนาดเล็กหรือนักพัฒนาแต่ละคน คุณสามารถทดลองได้อย่างอิสระ ปรับปรุงแอปพลิเคชันต่างๆ เช่น การกำหนดเส้นทางคำค้นหาอีคอมเมิร์ซ หรือการจัดโครงสร้างข้อความทางกฎหมาย เมื่อคุณดำเนินการต่อไป ให้ตรวจสอบว่าระบบของคุณตรงตามข้อกำหนดหรือไม่
ข้อกำหนดของระบบสำหรับการอนุมาน Gemma 3 270M
Gemma 3 270M ต้องการฮาร์ดแวร์ที่ไม่สูงมาก ทำให้สามารถเข้าถึงได้ สำหรับการอนุมานโดยใช้ CPU เท่านั้น คุณต้องมี RAM อย่างน้อย 4GB และโปรเซสเซอร์ที่ทันสมัย เช่น Intel Core i5 หรือเทียบเท่า อย่างไรก็ตาม การเร่งความเร็วด้วย GPU จะช่วยเพิ่มความเร็ว การ์ด NVIDIA ที่มี VRAM 2GB ก็เพียงพอสำหรับเวอร์ชันที่ผ่านการควอนไทซ์
โดยเฉพาะอย่างยิ่ง ในโหมด 4 บิต โมเดลจะใช้หน่วยความจำไม่เกิน 200MB ทำให้สามารถรันบนอุปกรณ์ที่มีทรัพยากรจำกัดได้ ผู้ใช้ Apple silicon จะได้รับประโยชน์จาก MLX-LM ซึ่งสามารถประมวลผลได้มากกว่า 650 โทเค็นต่อวินาทีบน M4 Max สำหรับการ Fine-tuning ให้จัดสรร RAM 8GB และ GPU ที่มี VRAM 4GB เพื่อจัดการชุดข้อมูลขนาดเล็กได้อย่างมีประสิทธิภาพ
ที่สำคัญ ระบบปฏิบัติการอย่าง Windows, macOS หรือ Linux สามารถใช้งานได้ แต่ต้องแน่ใจว่าใช้ Python 3.10+ เพื่อความเข้ากันได้ของไลบรารี พื้นที่เก็บข้อมูลต้องการประมาณ 1GB สำหรับไฟล์โมเดล เมื่อมีสิ่งเหล่านี้พร้อม คุณก็สามารถติดตั้งและรันได้โดยไม่มีปัญหา ตอนนี้ มาสำรวจวิธีการติดตั้งกัน
การเลือกเครื่องมือที่เหมาะสมเพื่อรัน Gemma 3 270M บนเครื่อง
มีเฟรมเวิร์กหลายตัวที่รองรับ Gemma 3 270M ซึ่งแต่ละตัวมีจุดแข็งเฉพาะตัว Hugging Face Transformers ให้ความยืดหยุ่นสำหรับการเขียนสคริปต์ Python และการรวมระบบ LM Studio นำเสนออินเทอร์เฟซที่ใช้งานง่ายสำหรับการจัดการโมเดล
นอกจากนี้ llama.cpp ยังช่วยให้การอนุมานที่ใช้ C++ มีประสิทธิภาพสูง เหมาะสำหรับการปรับแต่งระดับต่ำ สำหรับอุปกรณ์ Apple, MLX ช่วยเพิ่มประสิทธิภาพบนชิป M-series คุณเลือกได้ตามความเชี่ยวชาญของคุณ ผู้เริ่มต้นมักจะชอบ LM Studio ในขณะที่นักพัฒนาจะเลือกใช้ Transformers
ดังนั้น เครื่องมือเหล่านี้จึงทำให้การเข้าถึงเป็นประชาธิปไตย ในส่วนถัดไป โปรดทำตามคำแนะนำทีละขั้นตอนสำหรับวิธีการยอดนิยม
คู่มือทีละขั้นตอน: การรัน Gemma 3 270M ด้วย Hugging Face Transformers
คุณเริ่มต้นด้วยการติดตั้งไลบรารีที่จำเป็น เปิดเทอร์มินัลของคุณแล้วรันคำสั่ง:
pip install transformers torch
คำสั่งนี้จะดาวน์โหลด Transformers และ PyTorch ถัดไป ให้นำเข้าส่วนประกอบในสคริปต์ Python:
from transformers import AutoTokenizer, AutoModelForCausalLM
โหลดโมเดลและ Tokenizer:
model_name = "google/gemma-3-270m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
`device_map="auto"` จะวางโมเดลบน GPU หากมี เตรียมอินพุตของคุณ:
input_text = "Explain quantum computing in simple terms."
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
สร้างเอาต์พุต:
outputs = model.generate(**inputs, max_new_tokens=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
สิ่งนี้จะสร้างคำอธิบายที่สอดคล้องกัน หากต้องการปรับให้เหมาะสม ให้เพิ่มการควอนไทเซชัน:
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
การควอนไทเซชันช่วยลดการใช้หน่วยความจำ คุณสามารถจัดการข้อผิดพลาดได้โดยตรวจสอบให้แน่ใจว่าได้ล็อกอิน Hugging Face สำหรับโมเดลแบบ gated:
from huggingface_hub import login
login(token="your_hf_token")
รับโทเค็นจากบัญชี Hugging Face ของคุณ ด้วยการตั้งค่านี้ คุณสามารถรันการอนุมานซ้ำๆ ได้ อย่างไรก็ตาม สำหรับผู้ใช้ที่ไม่ใช่ Python ให้พิจารณา LM Studio ในลำดับถัดไป
คู่มือทีละขั้นตอน: การรัน Gemma 3 270M ด้วย LM Studio
LM Studio มีอินเทอร์เฟซที่ใช้งานง่าย ดาวน์โหลดได้จาก lmstudio.ai แล้วติดตั้ง
เปิดแอป จากนั้นค้นหา "gemma-3-270m" ในศูนย์รวมโมเดล
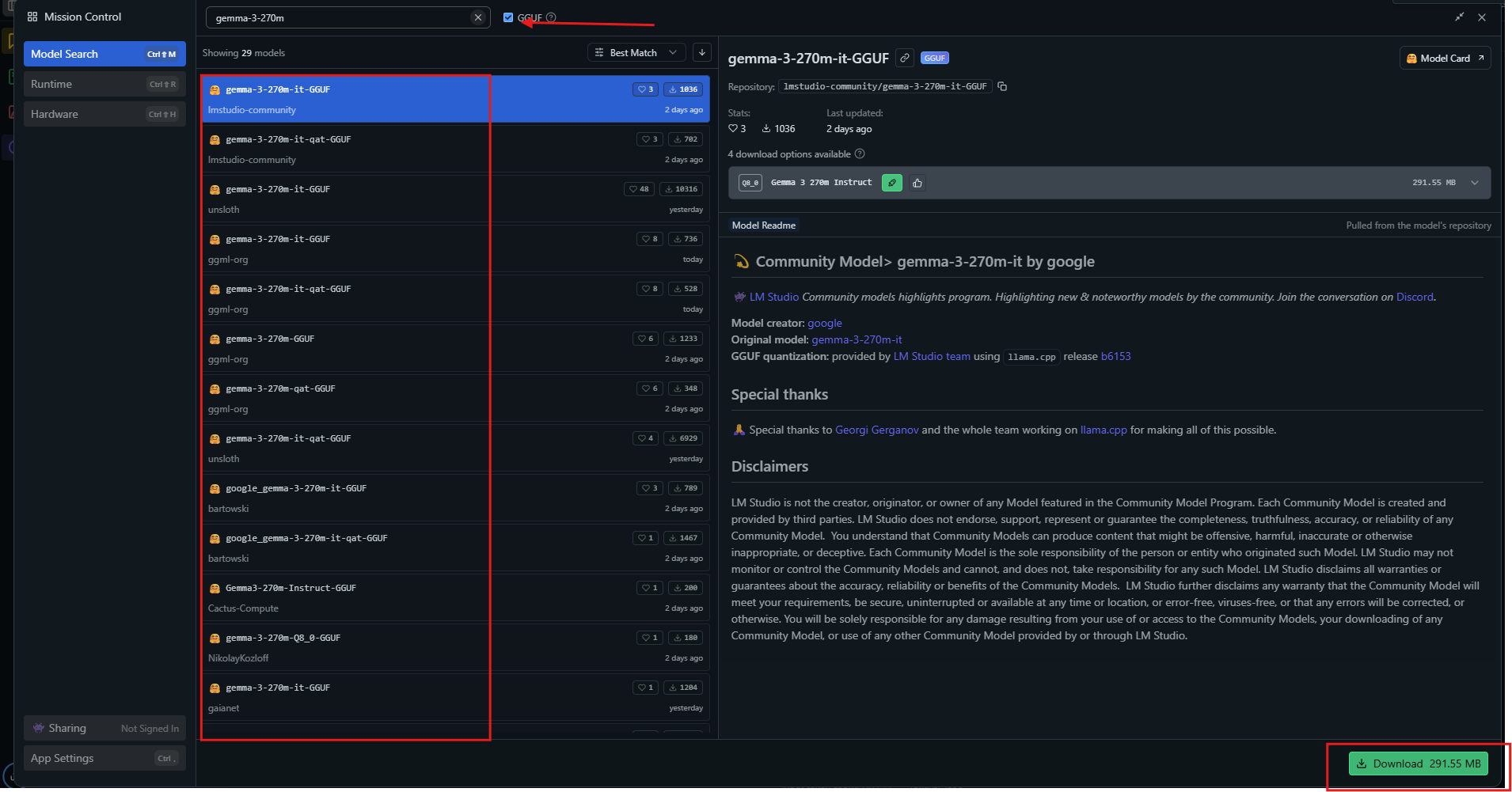
เลือกเวอร์ชันที่ผ่านการควอนไทซ์ เช่น Q4_0 แล้วดาวน์โหลด เมื่อพร้อมแล้ว ให้โหลดโมเดลจากแถบด้านข้าง ปรับการตั้งค่า: กำหนดคอนเท็กซ์เป็น 32k, อุณหภูมิเป็น 1.0
ป้อนข้อความแจ้งในหน้าต่างแชทแล้วกดส่ง LM Studio จะแสดงการตอบกลับพร้อมความเร็วโทเค็น ส่งออกการสนทนาหรือ Fine-tune ผ่านเครื่องมือในตัว
สำหรับการใช้งานขั้นสูง ให้เปิดใช้งาน GPU offloading ในการตั้งค่า LM Studio จะเลือกแหล่งข้อมูลที่เหมาะสมที่สุดโดยอัตโนมัติ เพื่อให้มั่นใจถึงความเข้ากันได้ วิธีนี้เหมาะสำหรับผู้ที่เรียนรู้ด้วยภาพ นอกจากนี้ ลองสำรวจ llama.cpp เพื่อปรับแต่งประสิทธิภาพ
คู่มือทีละขั้นตอน: การรัน Gemma 3 270M ด้วย llama.cpp
llama.cpp ให้การอนุมานที่มีประสิทธิภาพสูง โคลน repository:
git clone https://github.com/ggerganov/llama.cpp
สร้างมันขึ้นมา:
make -j
ดาวน์โหลดไฟล์ GGUF จาก Hugging Face:
huggingface-cli download unsloth/gemma-3-270m-it-GGUF --include "*.gguf"
รันการอนุมาน:
./llama-cli -m gemma-3-270m-it-Q4_K_M.gguf -p "Build a simple AI app."
ระบุพารามิเตอร์เช่น `--n-gpu-layers 999` สำหรับการใช้งาน GPU เต็มรูปแบบ llama.cpp รองรับระดับการควอนไทเซชัน โดยสร้างสมดุลระหว่างความเร็วและความแม่นยำ คุณสามารถคอมไพล์ด้วย CUDA สำหรับ NVIDIA GPUs:
make GGML_CUDA=1
สิ่งนี้ช่วยเร่งการประมวลผล llama.cpp มีความโดดเด่นในระบบฝังตัว ตอนนี้ ลองนำโมเดลไปใช้ในตัวอย่างเชิงปฏิบัติ
ตัวอย่างการใช้งาน Gemma 3 270M ในทางปฏิบัติบนเครื่อง
คุณสามารถสร้างเครื่องวิเคราะห์ความรู้สึกได้ ป้อนรีวิวจากลูกค้า แล้วโมเดลจะจำแนกประเภทว่าเป็นบวกหรือลบ เขียนสคริปต์ใน Python:
prompt = "Classify: This product is amazing!"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0]))
Gemma 3 270M จะแสดงผลลัพธ์ "Positive" ขยายไปสู่การสรุป:
text = "Long article here..."
prompt = f"Summarize: {text}"
# Generate summary
มันสามารถย่อเนื้อหาได้อย่างมีประสิทธิภาพ สำหรับการตอบคำถาม ให้สอบถาม:
"อะไรคือสาเหตุของการเปลี่ยนแปลงสภาพภูมิอากาศ?"
โมเดลจะอธิบายเกี่ยวกับก๊าซเรือนกระจก ในด้านการดูแลสุขภาพ คุณสามารถดึงเอนทิตีจากบันทึกได้ การใช้งานเหล่านี้แสดงให้เห็นถึงความหลากหลาย นอกจากนี้ยังสามารถ Fine-tune เพื่อความเชี่ยวชาญเฉพาะทางได้
การ Fine-tuning Gemma 3 270M บนเครื่อง
การ Fine-tuning เป็นการปรับโมเดล ใช้ไลบรารี PEFT ของ Hugging Face:
pip install peft
โหลดด้วยการกำหนดค่า LoRA:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
เตรียมชุดข้อมูล จากนั้นฝึก:
from transformers import Trainer, TrainingArguments
trainer = Trainer(model=model, args=TrainingArguments(output_dir="./results"))
trainer.train()
LoRA ต้องการข้อมูลเพียงเล็กน้อย และเสร็จสิ้นอย่างรวดเร็วบนฮาร์ดแวร์ที่ไม่สูงมาก บันทึกและโหลดอะแดปเตอร์ใหม่ สิ่งนี้ช่วยเพิ่มประสิทธิภาพในงานที่กำหนดเอง เช่น การทำนายการเดินหมากรุก อย่างไรก็ตาม ควรเฝ้าระวังการเกิด overfitting
เคล็ดลับการเพิ่มประสิทธิภาพสำหรับ Gemma 3 270M
คุณสามารถเพิ่มความเร็วได้สูงสุดโดยการควอนไทซ์เป็น 4 บิต หรือ 8 บิต ใช้การทำ Batching สำหรับการอนุมานหลายครั้ง ตั้งค่าอุณหภูมิเป็น 1.0, top_k=64, top_p=0.95 ตามที่แนะนำ
บน GPU ให้เปิดใช้งาน Mixed Precision สำหรับคอนเท็กซ์ที่ยาว ให้จัดการ KV cache อย่างระมัดระวัง ตรวจสอบ VRAM ด้วยเครื่องมือเช่น nvidia-smi อัปเดตไลบรารีเป็นประจำเพื่อการเพิ่มประสิทธิภาพ
ดังนั้น การปรับแต่งเหล่านี้จะให้ผลลัพธ์มากกว่า 130 โทเค็นต่อวินาทีบนฮาร์ดแวร์ที่เหมาะสม หลีกเลี่ยงข้อผิดพลาดทั่วไป เช่น การมี BOS token ซ้ำซ้อนในข้อความแจ้ง ด้วยการฝึกฝน คุณจะสามารถรันได้อย่างมีประสิทธิภาพ
บทสรุป
ตอนนี้คุณมีความรู้ในการรัน Gemma 3 270M บนเครื่องของคุณแล้ว ตั้งแต่การตั้งค่าไปจนถึงการเพิ่มประสิทธิภาพ แต่ละขั้นตอนจะช่วยเสริมสร้างความสามารถ ทดลอง Fine-tune และปรับใช้เพื่อดึงศักยภาพของมันออกมา โมเดลขนาดเล็กเช่นนี้สร้างผลกระทบที่ยิ่งใหญ่ต่อการเข้าถึง AI