
ซีรีส์ Qwen ของ Alibaba ยังคงผลักดันขีดจำกัดในโมเดลภาษาขนาดใหญ่ และ Qwen3-Next-80B-A3B โดดเด่นในฐานะตัวอย่างสำคัญของประสิทธิภาพที่มาพร้อมกับสมรรถนะสูง วิศวกรและนักพัฒนาต่างมองหาโมเดลที่ให้การให้เหตุผลที่แข็งแกร่งโดยไม่มีภาระการคำนวณที่มากเกินไปของโมเดลขนาดใหญ่ที่หนาแน่น โมเดลนี้ตอบสนองความต้องการนั้นโดยตรง ด้วยพารามิเตอร์ 8 หมื่นล้านตัว แต่เปิดใช้งานเพียง 3 พันล้านตัวต่อโทเค็น ด้วยเหตุนี้ ทีมงานจึงสามารถบรรลุความเร็วในการอนุมานที่เร็วขึ้นและลดค่าใช้จ่ายในการฝึกอบรม ทำให้เหมาะสำหรับการใช้งานจริง
ในโพสต์นี้ คุณจะได้สำรวจส่วนประกอบหลักของ Qwen3-Next-80B-A3B วิเคราะห์สถาปัตยกรรมที่เป็นนวัตกรรมใหม่ ตรวจสอบข้อมูลประสิทธิภาพเชิงประจักษ์ และเรียนรู้การใช้งาน API ผ่านขั้นตอนปฏิบัติจริง นอกจากนี้ คุณยังจะได้รวมเครื่องมืออย่าง Apidog เพื่อปรับปรุงเวิร์กโฟลว์ของคุณ เมื่ออ่านจบ คุณจะมีความรู้ในการปรับใช้โมเดลนี้ในแอปพลิเคชันของคุณได้อย่างมีประสิทธิภาพ
อะไรคือนิยามของ Qwen3-Next-80B-A3B? คุณสมบัติหลักและนวัตกรรม
Qwen3-Next-80B-A3B เกิดขึ้นจากตระกูล Qwen ของ Alibaba ในฐานะโมเดล Mixture of Experts (MoE) แบบกระจายที่ได้รับการปรับให้เหมาะสมทั้งความเร็วและความสามารถ นักพัฒนาจะเปิดใช้งานเพียงเศษส่วนของพารามิเตอร์ในระหว่างการอนุมาน ซึ่งช่วยประหยัดทรัพยากรได้อย่างมาก โดยเฉพาะอย่างยิ่ง โมเดลนี้ใช้การตั้งค่า MoE ที่กระจายตัวอย่างยิ่งยวดด้วยผู้เชี่ยวชาญ 512 คน โดยส่งไปยัง 10 คนต่อโทเค็น พร้อมกับผู้เชี่ยวชาญที่ใช้ร่วมกันหนึ่งคน ผลที่ได้คือ มีประสิทธิภาพเทียบเท่ากับโมเดลที่หนาแน่นกว่า เช่น Qwen3-32B ในขณะที่ใช้พลังงานน้อยกว่ามาก
นอกจากนี้ โมเดลยังรองรับการคาดการณ์หลายโทเค็น ซึ่งเป็นเทคนิคที่ช่วยเร่งการถอดรหัสแบบคาดเดา คุณสมบัตินี้ช่วยให้โมเดลสามารถสร้างโทเค็นหลายตัวพร้อมกัน ซึ่งช่วยเพิ่มปริมาณงานในขั้นตอนการถอดรหัส นักพัฒนาชื่นชอบสิ่งนี้สำหรับแอปพลิเคชันที่ต้องการการตอบสนองที่รวดเร็ว เช่น แชทบอท หรือเครื่องมือวิเคราะห์แบบเรียลไทม์
ซีรีส์นี้มีตัวแปรที่ปรับให้เหมาะกับความต้องการเฉพาะ: โมเดลพื้นฐานสำหรับการฝึกอบรมล่วงหน้าทั่วไป, เวอร์ชัน instruct สำหรับงานสนทนาที่ได้รับการปรับแต่งอย่างละเอียด และเวอร์ชัน thinking สำหรับการให้เหตุผลขั้นสูง ตัวอย่างเช่น Qwen3-Next-80B-A3B-Thinking มีความเป็นเลิศในการแก้ปัญหาที่ซับซ้อน โดยมีประสิทธิภาพเหนือกว่าโมเดลอย่าง Gemini-2.5-Flash-Thinking ในการวัดประสิทธิภาพ นอกจากนี้ยังรองรับ 119 ภาษา ทำให้สามารถปรับใช้ได้หลายภาษาโดยไม่ต้องฝึกอบรมซ้ำ
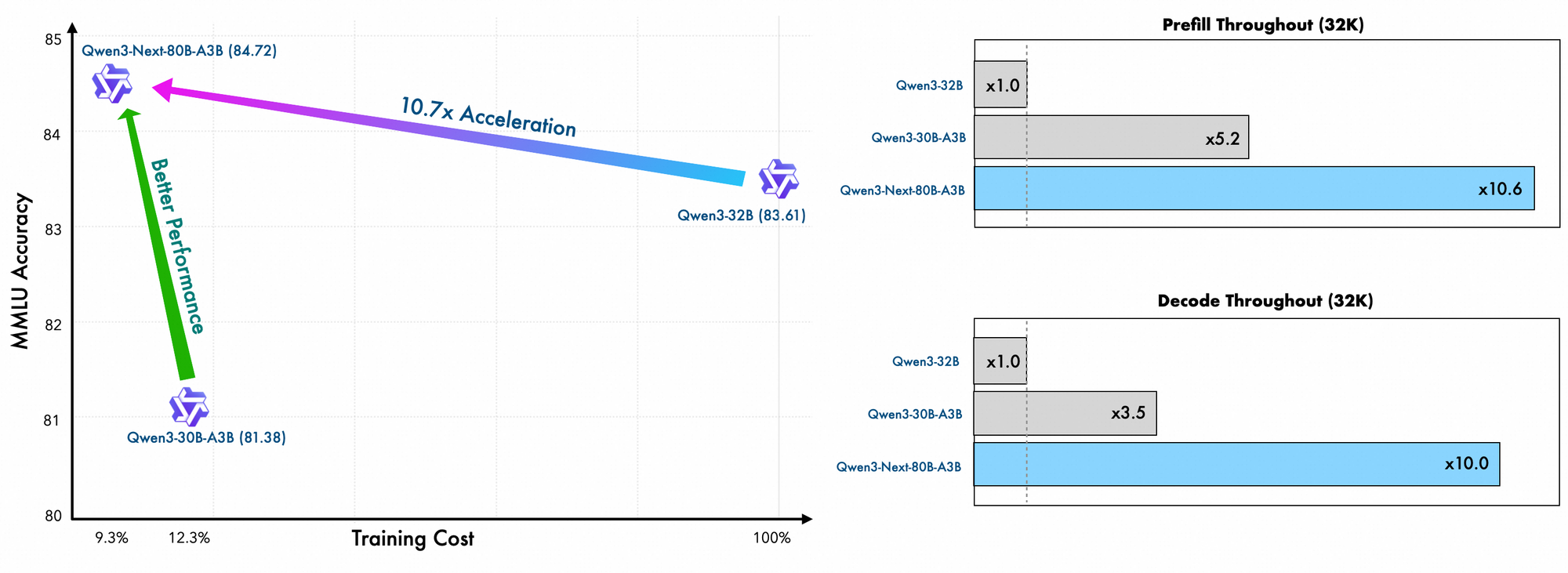
รายละเอียดการฝึกอบรมเผยให้เห็นประสิทธิภาพเพิ่มเติม วิศวกรของ Alibaba ฝึกอบรมโมเดลนี้ล่วงหน้าโดยใช้วิธีการที่ปรับขนาดได้อย่างมีประสิทธิภาพ โดยมีค่าใช้จ่ายเพียง 10% เมื่อเทียบกับ Qwen3-32B พวกเขาใช้เลย์เอาต์แบบไฮบริดใน 48 เลเยอร์พร้อมมิติที่ซ่อนอยู่ 2048 เพื่อให้มั่นใจว่ามีการกระจายการคำนวณที่สมดุล ผลที่ตามมาคือ โมเดลแสดงให้เห็นถึงความเข้าใจบริบทที่ยาวนานที่เหนือกว่า โดยรักษาความแม่นยำได้เกิน 32K โทเค็นในขณะที่โมเดลอื่น ๆ ล้มเหลว
ในทางปฏิบัติ คุณสมบัติเหล่านี้ช่วยให้นักพัฒนาสามารถขยายโซลูชัน AI ได้อย่างคุ้มค่า ไม่ว่าคุณจะสร้างเครื่องมือค้นหาสำหรับองค์กรหรือเครื่องมือสร้างเนื้อหาอัตโนมัติ Qwen3-Next-80B-A3B ก็เป็นรากฐานสำหรับแอปพลิเคชันที่เป็นนวัตกรรมใหม่ การสร้างบนรากฐานนี้ ส่วนถัดไปจะตรวจสอบองค์ประกอบทางสถาปัตยกรรมที่ทำให้ประสิทธิภาพดังกล่าวเป็นไปได้
การวิเคราะห์สถาปัตยกรรมของ Qwen3-Next-80B-A3B: พิมพ์เขียวทางเทคนิค
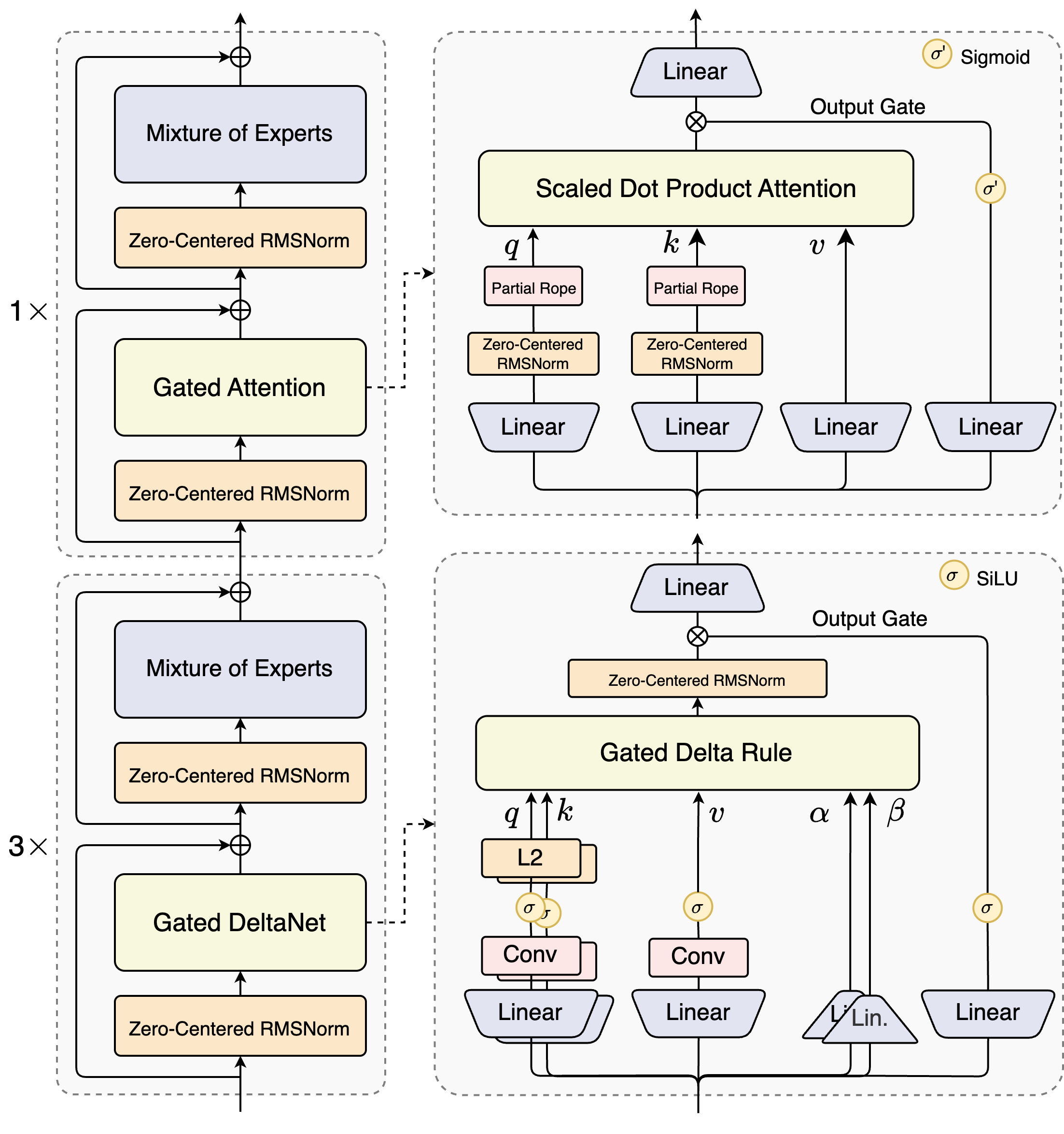
สถาปนิกของ Qwen3-Next-80B-A3B แนะนำการออกแบบไฮบริดที่รวมกลไกแบบ gated เข้ากับเทคนิคการทำให้เป็นมาตรฐานขั้นสูง หัวใจสำคัญคือเลเยอร์ Mixture of Experts (MoE) ซึ่งผู้เชี่ยวชาญจะเชี่ยวชาญในเส้นทางการคำนวณที่แตกต่างกัน โมเดลจะส่งอินพุตแบบไดนามิก โดยเปิดใช้งานชุดย่อยเพื่อลดโอเวอร์เฮด ตัวอย่างเช่น บล็อกความสนใจแบบ gated จะประมวลผลการสอบถาม (queries), คีย์ (keys) และค่า (values) ผ่านการฝัง RoPE บางส่วนและเลเยอร์ RMSNorm ที่มีศูนย์กลางเป็นศูนย์ ซึ่งช่วยเพิ่มความเสถียรในลำดับที่ยาวนาน
พิจารณาโมดูลความสนใจแบบ scaled dot-product มันรวมการฉายภาพเชิงเส้นตามด้วยเกตเอาต์พุตที่ปรับโดยการเปิดใช้งาน sigmoid การตั้งค่านี้ช่วยให้สามารถควบคุมการไหลของข้อมูลได้อย่างแม่นยำ ป้องกันการเจือจางในพื้นที่ที่มีมิติสูง นอกจากนี้ RMSNorm ที่มีศูนย์กลางเป็นศูนย์จะอยู่ก่อนและหลังการดำเนินการเหล่านี้ โดยจัดตำแหน่งการเปิดใช้งานให้อยู่รอบศูนย์เพื่อลดปัญหาการไล่ระดับสีในระหว่างการฝึกอบรม
แผนภาพแสดงบล็อกหลักสองบล็อก: บล็อกด้านบนเน้นที่ความสนใจแบบ gated ด้วยความสนใจแบบ scaled dot-product ในขณะที่บล็อกด้านล่างเน้นที่ gated DeltaNet ในเส้นทางความสนใจ (การขยาย 1x) อินพุตจะไหลผ่าน RMSNorm ที่มีศูนย์กลางเป็นศูนย์ จากนั้นเข้าสู่แกนความสนใจแบบ gated ที่นี่ การฉายภาพการสอบถาม (q), คีย์ (k) และค่า (v) ใช้ RoPE บางส่วนสำหรับการเข้ารหัสตำแหน่ง หลังความสนใจ RMSNorm และเลเยอร์เชิงเส้นอื่น ๆ จะป้อนเข้าสู่ MoE ซึ่งใช้เอาต์พุตแบบ sigmoid-gated
เมื่อเปลี่ยนไปที่เส้นทาง DeltaNet (การขยาย 3x) สถาปัตยกรรมจะใช้กฎ Delta แบบ gated สำหรับการคาดการณ์ที่ละเอียดอ่อนยิ่งขึ้น มันมี L2 normalization บน q และ k, เลเยอร์ convolutional สำหรับการสกัดคุณสมบัติในท้องถิ่น และการเปิดใช้งาน SiLU สำหรับการไม่เป็นเชิงเส้น เกตเอาต์พุตที่รวมกับการฉายภาพเชิงเส้นช่วยให้มั่นใจได้ถึงเอาต์พุตหลายโทเค็นที่สอดคล้องกัน การออกแบบบล็อกนี้รองรับการถอดรหัสแบบคาดเดาของโมเดล ซึ่งจะคาดการณ์โทเค็นหลายตัวล่วงหน้า ซึ่งได้รับการยืนยันในการผ่านครั้งต่อ ๆ ไป
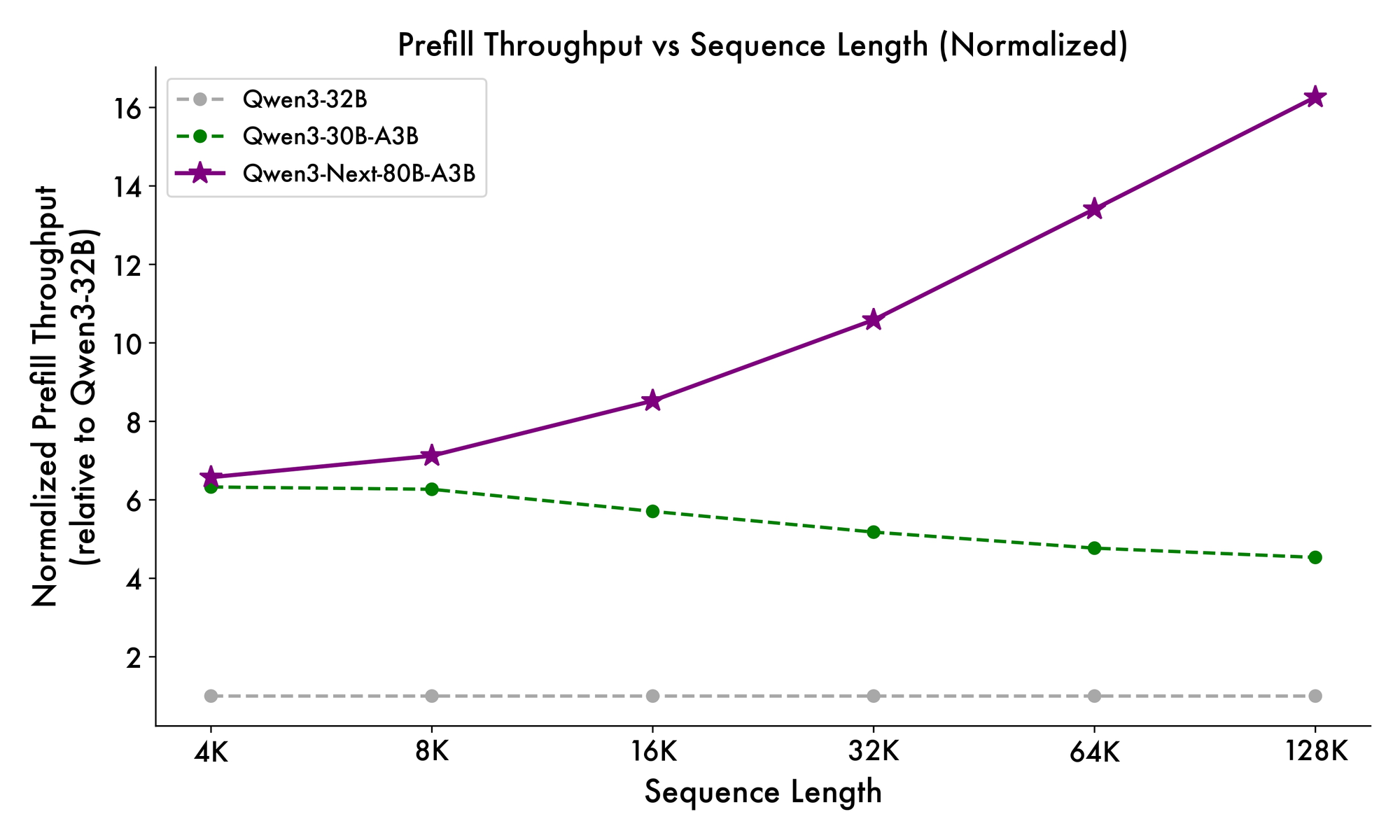
นอกจากนี้ โครงสร้างโดยรวมยังรวมผู้เชี่ยวชาญที่ใช้ร่วมกันใน MoE เพื่อจัดการกับรูปแบบทั่วไปในโทเค็น ลดความซ้ำซ้อน การฝัง rope บางส่วนในการฉายภาพช่วยรักษาความไม่แปรผันของการหมุนสำหรับบริบทที่ขยายออกไป ดังที่เห็นได้จากการวัดประสิทธิภาพ การกำหนดค่านี้ให้ปริมาณงานสูงขึ้นเกือบ 7 เท่าที่ความยาวบริบท 4K เมื่อเทียบกับ Qwen3-32B เกิน 32K โทเค็น ความเร็วเกิน 10 เท่า ทำให้เหมาะสำหรับการวิเคราะห์เอกสารหรืองานสร้างโค้ด
นักพัฒนาได้รับประโยชน์จากความเป็นโมดูลาร์นี้เมื่อปรับแต่ง คุณสามารถสลับผู้เชี่ยวชาญหรือปรับเกณฑ์การส่งเส้นทางเพื่อทำให้โมเดลเชี่ยวชาญสำหรับโดเมนต่างๆ เช่น การเงินหรือการดูแลสุขภาพ โดยพื้นฐานแล้ว สถาปัตยกรรมไม่เพียงแต่ปรับการคำนวณให้เหมาะสม แต่ยังส่งเสริมความสามารถในการปรับตัว ด้วยข้อมูลเชิงลึกเหล่านี้ คุณจะหันไปดูว่าองค์ประกอบเหล่านี้แปลไปสู่ประสิทธิภาพที่เพิ่มขึ้นได้อย่างไร
การวัดประสิทธิภาพ Qwen3-Next-80B-A3B: ตัวชี้วัดประสิทธิภาพที่สำคัญ
การประเมินเชิงประจักษ์ทำให้ Qwen3-Next-80B-A3B เป็นผู้นำในด้าน AI ที่ขับเคลื่อนด้วยประสิทธิภาพ ในการวัดประสิทธิภาพมาตรฐาน เช่น MMLU และ HumanEval โมเดลพื้นฐานมีประสิทธิภาพเหนือกว่า Qwen3-32B แม้จะใช้พารามิเตอร์ที่ใช้งานอยู่เพียงหนึ่งในสิบ โดยเฉพาะอย่างยิ่ง มันทำคะแนนได้ 78.5% ใน MMLU สำหรับความรู้ทั่วไป โดยนำคู่แข่ง 2-3 จุดในชุดย่อยการให้เหตุผล
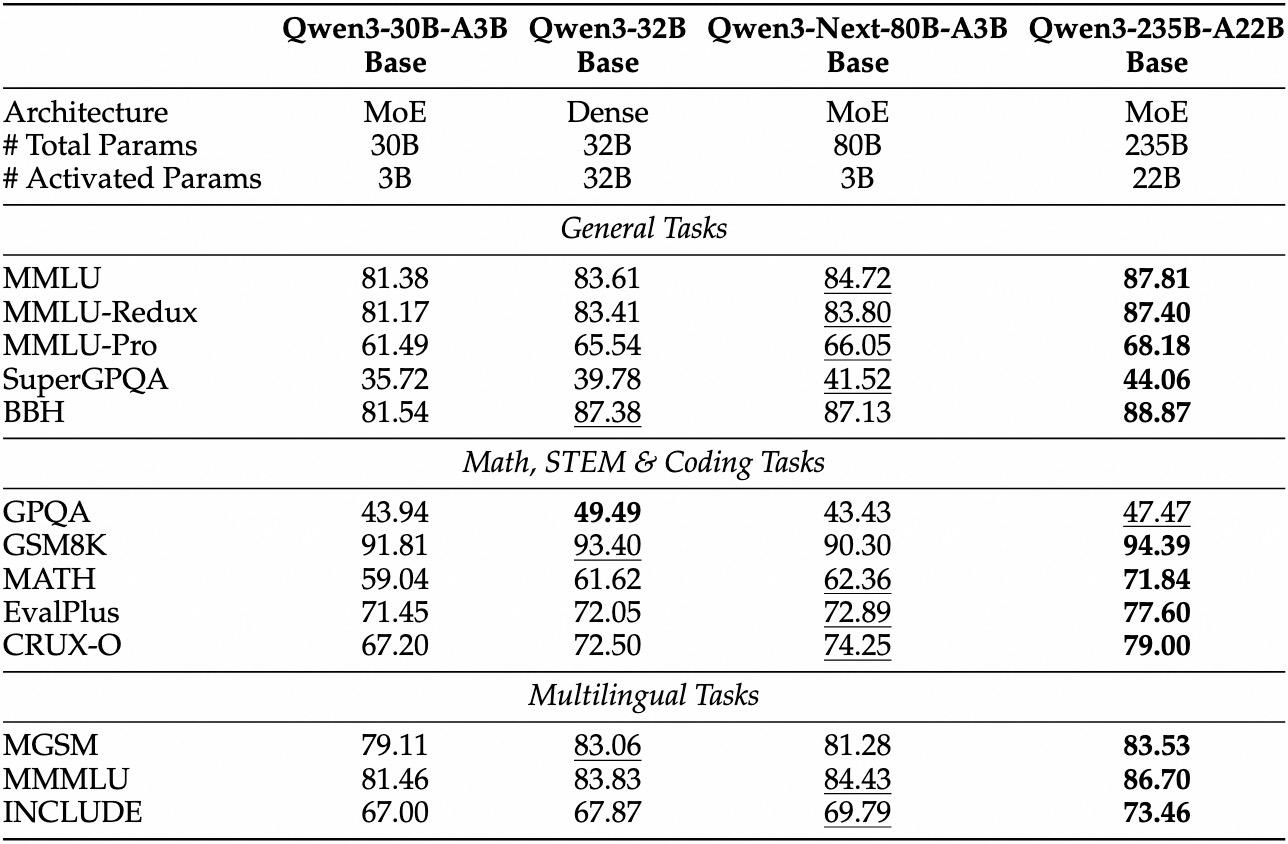
สำหรับเวอร์ชัน instruct งานสนทนาเผยให้เห็นจุดแข็งในการปฏิบัติตามคำแนะนำ มันทำคะแนนได้ 85% ใน MT-Bench ซึ่งแสดงให้เห็นบทสนทนาหลายรอบที่สอดคล้องกัน ในขณะเดียวกัน โมเดล thinking โดดเด่นในสถานการณ์ chain-of-thought โดยทำคะแนนได้ 92% ใน GSM8K สำหรับปัญหาคณิตศาสตร์—มีประสิทธิภาพเหนือกว่า Qwen3-30B-A3B-Thinking 4%
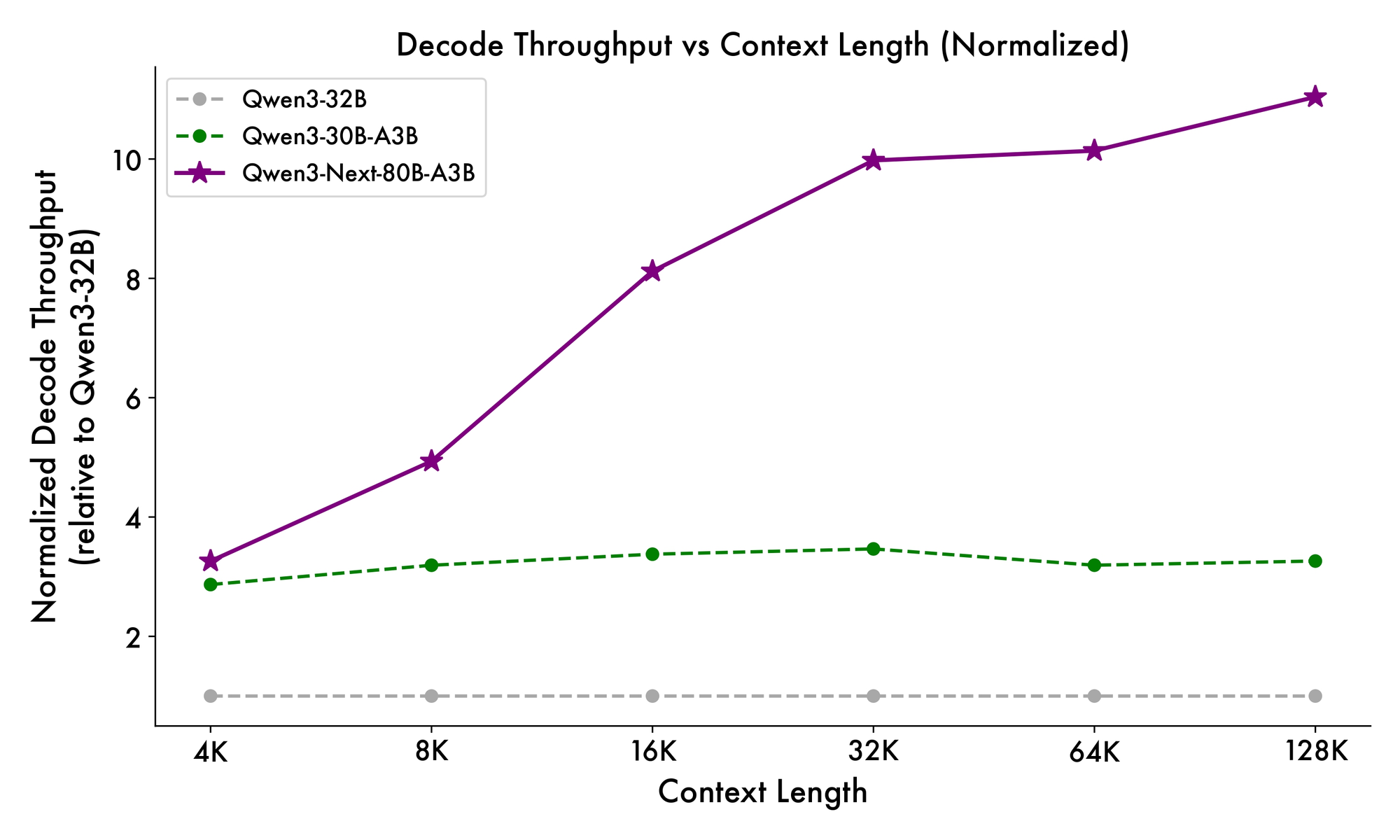
ความเร็วในการอนุมานเป็นรากฐานสำคัญของความน่าสนใจของมัน ที่บริบท 4K ปริมาณงานการถอดรหัสสูงถึง 4 เท่าของ Qwen3-32B โดยขยายเป็น 10 เท่าที่ความยาวที่ยาวขึ้น ขั้นตอนการ prefill ซึ่งสำคัญสำหรับการประมวลผลพรอมต์ แสดงให้เห็นการปรับปรุง 7 เท่า ต้องขอบคุณ MoE แบบกระจาย การใช้พลังงานลดลงตามไปด้วย โดยมีค่าใช้จ่ายในการฝึกอบรมที่ 10% ของโมเดลที่หนาแน่นกว่า
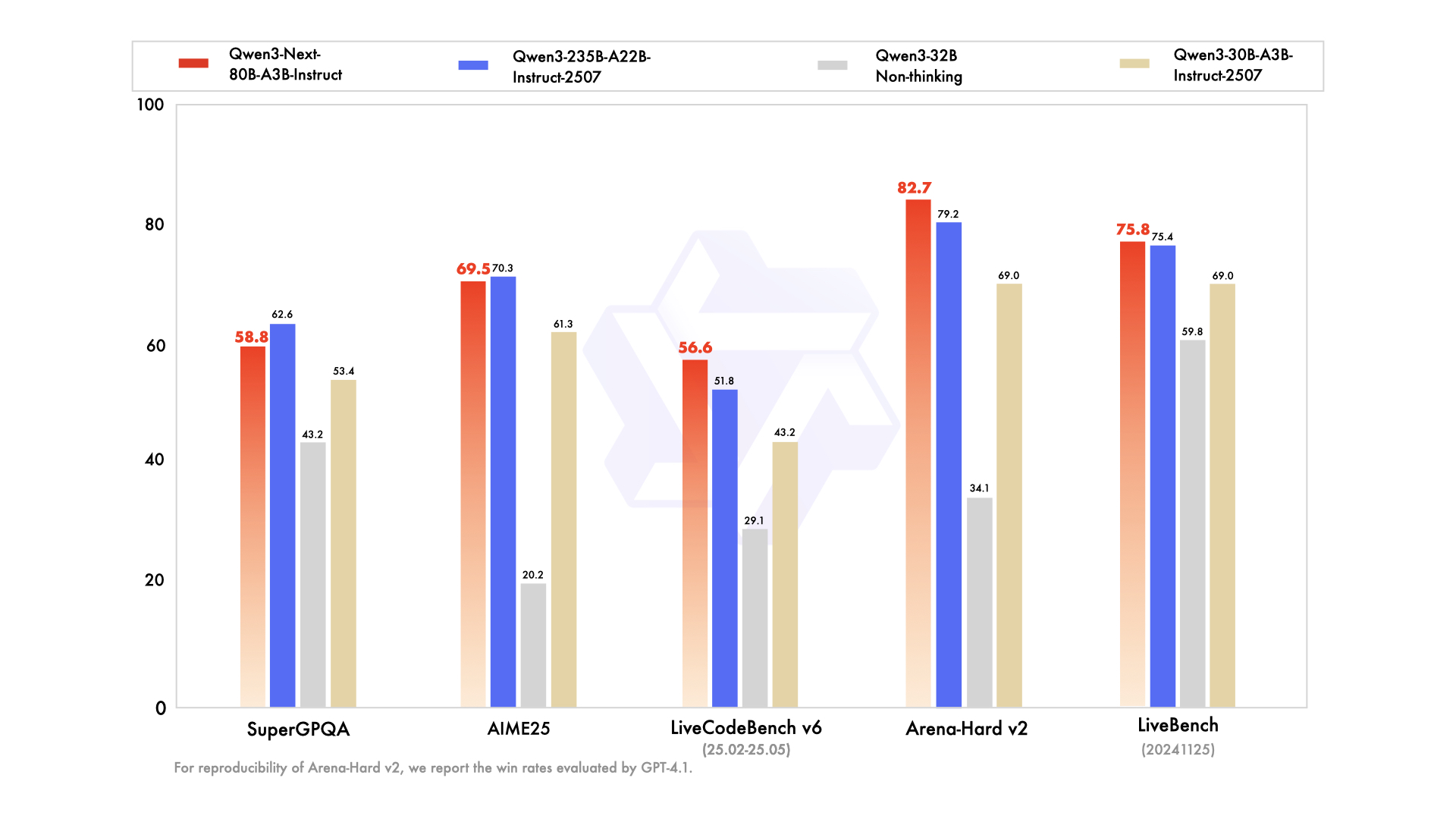
การเปรียบเทียบกับคู่แข่งเน้นย้ำถึงข้อได้เปรียบของมัน เมื่อเทียบกับ Llama 3.1-70B, Qwen3-Next-80B-A3B-Thinking เป็นผู้นำใน RULER (การเรียกคืนบริบทที่ยาวนาน) 15% โดยเรียกคืนรายละเอียดจาก 128K โทเค็นได้อย่างแม่นยำ เมื่อเทียบกับ DeepSeek-V2 มันให้การสนับสนุนหลายภาษาที่ดีกว่าโดยไม่ลดทอนความเร็ว

| การวัดประสิทธิภาพ | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Llama 3.1-70B |
|---|---|---|---|
| MMLU | 78.5% | 76.2% | 77.8% |
| HumanEval | 82.1% | 79.5% | 81.2% |
| GSM8K | 91.2% | 88.7% | 90.1% |
| MT-Bench | 84.3% (Instruct) | 81.9% | 83.5% |
ตารางนี้เน้นย้ำถึงประสิทธิภาพที่เหนือกว่าอย่างสม่ำเสมอ ด้วยเหตุนี้ องค์กรจึงนำไปใช้ในการผลิต โดยรักษาสมดุลระหว่างคุณภาพและต้นทุน การเปลี่ยนจากทฤษฎีสู่การปฏิบัติ ตอนนี้คุณจะเตรียมพร้อมด้วยเครื่องมือเข้าถึง API
การตั้งค่าการเข้าถึง API ของ Qwen3-Next-80B-A3B: ข้อกำหนดเบื้องต้นและการยืนยันตัวตน
Alibaba ให้บริการ Qwen API ผ่าน DashScope ซึ่งเป็นแพลตฟอร์มคลาวด์ของพวกเขา เพื่อให้มั่นใจถึงการรวมระบบที่ราบรื่น ขั้นแรก สร้างบัญชี Alibaba Cloud และไปที่คอนโซล Model Studio เลือก Qwen3-Next-80B-A3B จากรายการโมเดล—มีให้เลือกในโหมด base, instruct และ thinking
รับคีย์ API ของคุณจากแดชบอร์ดภายใต้ "API Keys" คีย์นี้ใช้ยืนยันคำขอ โดยมีขีดจำกัดอัตราขึ้นอยู่กับระดับของคุณ (ระดับฟรีเสนอ 1M โทเค็น/เดือน) สำหรับการเรียกที่เข้ากันได้กับ OpenAI ให้ตั้งค่า URL พื้นฐานเป็น https://dashscope.aliyuncs.com/compatible-mode/v1 ส่วนปลายทาง DashScope ดั้งเดิมใช้ https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation
ติดตั้ง Python SDK ผ่าน pip: pip install dashscope ไลบรารีนี้จัดการการจัดลำดับ การลองใหม่ และการแยกวิเคราะห์ข้อผิดพลาด หรือใช้ไคลเอนต์ HTTP เช่น requests สำหรับการใช้งานแบบกำหนดเอง
แนวทางปฏิบัติที่ดีที่สุดด้านความปลอดภัยกำหนดให้จัดเก็บคีย์ในตัวแปรสภาพแวดล้อม: export DASHSCOPE_API_KEY='your_key_here' ด้วยเหตุนี้ โค้ดของคุณจึงยังคงสามารถพกพาได้ในสภาพแวดล้อมต่างๆ เมื่อตั้งค่าเสร็จสิ้น คุณจะดำเนินการสร้างการเรียก API ครั้งแรกของคุณ
คู่มือปฏิบัติ: การใช้ Qwen3-Next-80B-A3B API กับ Python และ DashScope
DashScope ทำให้การโต้ตอบกับ Qwen3-Next-80B-A3B ง่ายขึ้น เริ่มต้นด้วยคำขอสร้างพื้นฐานโดยใช้เวอร์ชัน instruct สำหรับการตอบสนองแบบแชท
นี่คือสคริปต์เริ่มต้น:
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")
โค้ดนี้ส่งพรอมต์และดึงโทเค็นได้สูงสุด 200 โทเค็น โมเดลตอบสนองด้วยคำอธิบายที่กระชับ โดยเน้นถึงประสิทธิภาพที่เพิ่มขึ้น สำหรับโหมด thinking ให้เปลี่ยนเป็น 'qwen3-next-80b-a3b-thinking' และเพิ่มคำแนะนำการให้เหตุผล: "คิดทีละขั้นตอนก่อนตอบ"
พารามิเตอร์ขั้นสูงช่วยเพิ่มการควบคุม ตั้งค่า top_p=0.9 สำหรับการสุ่มตัวอย่างแบบ nucleus หรือ repetition_penalty=1.1 เพื่อหลีกเลี่ยงการวนซ้ำ สำหรับบริบทที่ยาว ให้ระบุ max_context_length=131072 เพื่อใช้ประโยชน์จากความสามารถ 128K ของโมเดล
จัดการการสตรีมสำหรับแอปแบบเรียลไทม์:
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
break
สิ่งนี้ให้เอาต์พุตแบบโทเค็นต่อโทเค็น ซึ่งเหมาะสำหรับการรวม UI การจัดการข้อผิดพลาดรวมถึงการตรวจสอบ response.code สำหรับปัญหาโควต้า (เช่น 10402 สำหรับยอดเงินไม่เพียงพอ)
นอกจากนี้ การเรียกใช้ฟังก์ชันยังช่วยเพิ่มประโยชน์ กำหนดเครื่องมือใน JSON schema:
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)
โมเดลจะแยกวิเคราะห์ความตั้งใจและส่งคืนการเรียกใช้เครื่องมือ ซึ่งคุณดำเนินการภายนอก รูปแบบนี้ขับเคลื่อนเวิร์กโฟลว์แบบ agentic ด้วยตัวอย่างเหล่านี้ คุณจะสร้างไปป์ไลน์ที่แข็งแกร่ง ถัดไป รวม Apidog เพื่อทดสอบและปรับปรุงการเรียกเหล่านี้โดยไม่ต้องเขียนโค้ดทุกครั้ง
การปรับปรุงเวิร์กโฟลว์ของคุณ: รวม Apidog สำหรับการทดสอบ Qwen3-Next-80B-A3B API
Apidog เปลี่ยนการพัฒนา API ให้เป็นกระบวนการที่คล่องตัว โดยเฉพาะอย่างยิ่งสำหรับปลายทาง AI เช่น Qwen3-Next-80B-A3B แพลตฟอร์มนี้รวมการออกแบบ การจำลอง การทดสอบ และการจัดทำเอกสารไว้ในอินเทอร์เฟซเดียว โดยขับเคลื่อนด้วย AI สำหรับการทำงานอัตโนมัติอัจฉริยะ
เริ่มต้นด้วยการนำเข้า DashScope schema เข้าสู่ Apidog สร้างโปรเจกต์ใหม่ เพิ่มปลายทาง POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation และวางคีย์ API ของคุณเป็นส่วนหัว: X-DashScope-API-Key: your_key
ออกแบบคำขอด้วยภาพ: ตั้งค่าพารามิเตอร์โมเดลเป็น 'qwen3-next-80b-a3b-instruct' ป้อนพรอมต์ในเนื้อหาเป็น JSON {"input": {"messages": [{"role": "user", "content": "Your prompt here"}]}} AI ของ Apidog แนะนำกรณีทดสอบ สร้างรูปแบบต่างๆ เช่น พรอมต์กรณีขอบ หรือตัวอย่างอุณหภูมิสูง
เรียกใช้ชุดการทดสอบตามลำดับ ตัวอย่างเช่น วัดเวลาแฝงในอุณหภูมิต่างๆ:
- การทดสอบ 1: อุณหภูมิ 0.1, ความยาวพรอมต์ 100 โทเค็น
- การทดสอบ 2: อุณหภูมิ 1.0, บริบท 10K โทเค็น
เครื่องมือนี้ติดตามตัวชี้วัด—เวลาตอบสนอง การใช้โทเค็น อัตราข้อผิดพลาด—และแสดงแนวโน้มในแดชบอร์ด จำลองการตอบสนองสำหรับการพัฒนาออฟไลน์: Apidog จำลองเอาต์พุต Qwen ตามข้อมูลย้อนหลัง ซึ่งช่วยเร่งการสร้างส่วนหน้า
เอกสารจะถูกสร้างขึ้นโดยอัตโนมัติจากชุดข้อมูลของคุณ ส่งออก OpenAPI specs พร้อมตัวอย่าง รวมถึงรายละเอียดเฉพาะของ Qwen3-Next-80B-A3B เช่น บันทึกการส่งเส้นทาง MoE คุณสมบัติการทำงานร่วมกันช่วยให้ทีมสามารถแชร์สภาพแวดล้อม ทำให้มั่นใจได้ถึงการทดสอบที่สอดคล้องกัน
ในสถานการณ์หนึ่ง นักพัฒนาทดสอบพรอมต์หลายภาษา AI ของ Apidog ตรวจพบความไม่สอดคล้องกัน โดยแนะนำการแก้ไข เช่น การเพิ่มคำใบ้ภาษา ผลลัพธ์คือ เวลาในการรวมระบบลดลง 40% ตามรายงานของผู้ใช้ สำหรับการทดสอบเฉพาะ AI ให้ใช้ประโยชน์จากการสร้างข้อมูลอัจฉริยะ: ป้อน schema และมันจะสร้างพรอมต์ที่สมจริงซึ่งเลียนแบบการจราจรในการผลิต
นอกจากนี้ Apidog ยังรองรับ CI/CD hooks โดยเรียกใช้การทดสอบ API ในไปป์ไลน์ เชื่อมต่อกับ GitHub Actions สำหรับการตรวจสอบอัตโนมัติหลังการปรับใช้ วิธีการแบบวงปิดนี้ช่วยลดข้อบกพร่องในแอปที่ขับเคลื่อนด้วย Qwen
กลยุทธ์ขั้นสูง: การปรับแต่งการเรียกใช้ Qwen3-Next-80B-A3B API สำหรับการผลิต
การปรับแต่งช่วยยกระดับการใช้งานพื้นฐานไปสู่ความน่าเชื่อถือระดับองค์กร ขั้นแรก รวมคำขอเป็นชุดเมื่อเป็นไปได้—DashScope รองรับได้สูงสุด 10 พรอมต์ต่อการเรียก ซึ่งช่วยลดโอเวอร์เฮดสำหรับงานคู่ขนาน เช่น ฟาร์มสรุป
ตรวจสอบเศรษฐศาสตร์โทเค็น: โมเดลจะคิดค่าใช้จ่ายต่อพารามิเตอร์ที่ใช้งานอยู่ ดังนั้นพรอมต์ที่กระชับจะช่วยประหยัดค่าใช้จ่าย ใช้ result_format='message' ของ API สำหรับเอาต์พุตที่มีโครงสร้าง การแยกวิเคราะห์ JSON โดยตรงเพื่อหลีกเลี่ยงการประมวลผลภายหลัง
สำหรับความพร้อมใช้งานสูง ให้ใช้การลองใหม่ด้วย exponential backoff:
import time
from dashscope import Generation
def call_with_retry(prompt, max_retries=3):
for attempt in range(max_retries):
response = Generation.call(model='qwen3-next-80b-a3b-instruct', prompt=prompt)
if response.status_code == 200:
return response
time.sleep(2 ** attempt)
raise Exception("Max retries exceeded")
สิ่งนี้จัดการข้อผิดพลาดชั่วคราว เช่น ขีดจำกัดอัตรา 429 ปรับขนาดในแนวนอนโดยกระจายการเรียกข้ามภูมิภาค—DashScope มีปลายทางในสิงคโปร์และสหรัฐอเมริกา
ข้อควรพิจารณาด้านความปลอดภัยรวมถึงการทำความสะอาดอินพุตเพื่อป้องกันการแทรกพรอมต์ ตรวจสอบอินพุตของผู้ใช้กับรายการที่อนุญาตก่อนส่งต่อไปยัง API นอกจากนี้ บันทึกการตอบสนองที่ไม่ระบุชื่อสำหรับการตรวจสอบ โดยปฏิบัติตาม GDPR
ในกรณีพิเศษ เช่น บริบทที่ยาวมาก ให้แบ่งอินพุตและคาดการณ์แบบลูกโซ่ เวอร์ชัน thinking ช่วยได้ที่นี่: พรอมต์ด้วย "ขั้นตอนที่ 1: วิเคราะห์ส่วน A; ขั้นตอนที่ 2: สังเคราะห์กับ B" สิ่งนี้ช่วยรักษาความสอดคล้องกันเหนือ 100K+ โทเค็น
นักพัฒนายังสำรวจการปรับแต่งผ่านแพลตฟอร์มของ Alibaba แม้ว่าผู้ใช้ API จะยึดติดกับการทำ prompt engineering ด้วยเหตุนี้ กลยุทธ์เหล่านี้จึงรับประกันการปรับใช้ที่ปรับขนาดได้และปลอดภัย
สรุป: ทำไม Qwen3-Next-80B-A3B จึงควรได้รับความสนใจจากคุณ
Qwen3-Next-80B-A3B กำหนดนิยามใหม่ของ AI ที่มีประสิทธิภาพด้วย MoE แบบกระจาย, gated แบบไฮบริด และการวัดประสิทธิภาพที่เหนือกว่า นักพัฒนาใช้ประโยชน์จาก API ผ่าน DashScope สำหรับการสร้างต้นแบบอย่างรวดเร็ว ซึ่งเสริมด้วยเครื่องมืออย่าง Apidog เพื่อความเข้มงวดในการทดสอบ
ตอนนี้คุณมีพิมพ์เขียวแล้ว: ตั้งแต่ความแตกต่างทางสถาปัตยกรรมไปจนถึงการปรับแต่งการผลิต ใช้ข้อมูลเชิงลึกเหล่านี้เพื่อสร้างระบบที่เร็วขึ้นและฉลาดขึ้น ทดลองวันนี้—อนาคตของปัญญาประดิษฐ์ที่ปรับขนาดได้กำลังรออยู่