
วันนี้เป็นอีกวันที่ยอดเยี่ยมสำหรับชุมชน AI แบบโอเพนซอร์ส โดยเฉพาะอย่างยิ่ง ชุมชนนี้เติบโตได้ดีในสถานการณ์เช่นนี้ ด้วยการถอดรหัส ทดสอบ และสร้างสรรค์สิ่งใหม่ๆ บนเทคโนโลยีที่ล้ำสมัย ในเดือนกรกฎาคม 2025 ทีม Qwen ของ Alibaba ได้จุดประกายเหตุการณ์ดังกล่าวด้วยการเปิดตัวซีรีส์ Qwen3 ซึ่งเป็นตระกูลโมเดลใหม่ที่ทรงพลังซึ่งพร้อมที่จะกำหนดนิยามใหม่ของมาตรฐานประสิทธิภาพ หัวใจหลักของการเปิดตัวครั้งนี้คือโมเดลย่อยที่น่าสนใจและมีความเชี่ยวชาญสูง: Qwen3-235B-A22B-Thinking-2507
โมเดลนี้ไม่ใช่แค่การอัปเดตเพิ่มเติม แต่เป็นการก้าวไปข้างหน้าอย่างตั้งใจและมีกลยุทธ์เพื่อสร้างระบบ AI ที่มีความสามารถในการให้เหตุผลอย่างลึกซึ้ง ชื่อของมันเพียงอย่างเดียวก็เป็นการประกาศเจตนาที่ชัดเจน ซึ่งบ่งบอกถึงการมุ่งเน้นไปที่ตรรกะ การวางแผน และการแก้ปัญหาแบบหลายขั้นตอน บทความนี้จะเจาะลึกถึงสถาปัตยกรรม วัตถุประสงค์ และผลกระทบที่เป็นไปได้ของ Qwen3-Thinking โดยพิจารณาถึงตำแหน่งของมันภายในระบบนิเวศ Qwen3 ที่กว้างขึ้น และความหมายของมันต่ออนาคตของการพัฒนา AI
ต้องการแพลตฟอร์มแบบครบวงจรสำหรับทีมพัฒนาของคุณเพื่อทำงานร่วมกันด้วย ประสิทธิภาพสูงสุด หรือไม่?
Apidog ตอบสนองทุกความต้องการของคุณ และ แทนที่ Postman ในราคาที่ย่อมเยาลงมาก!
ตระกูล Qwen3: การโจมตีหลายแง่มุมต่อเทคโนโลยีที่ล้ำสมัย
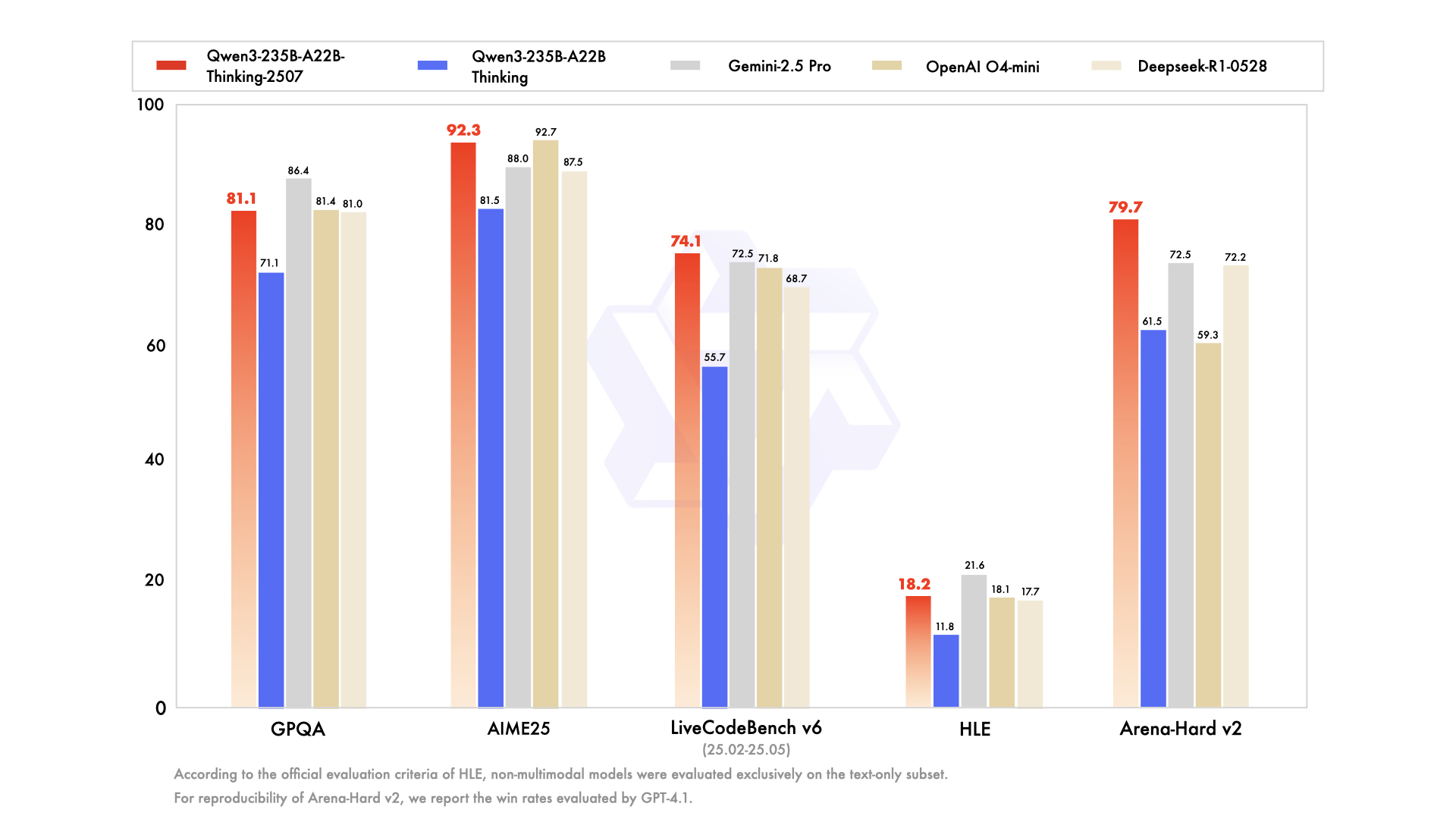
ในการทำความเข้าใจโมเดล Thinking เราต้องเข้าใจบริบทของการกำเนิดของมันก่อน มันไม่ได้เกิดขึ้นมาอย่างโดดเดี่ยว แต่เป็นส่วนหนึ่งของตระกูลโมเดล Qwen3 ที่ครอบคลุมและมีความหลากหลายเชิงกลยุทธ์ ซีรีส์ Qwen ได้สร้างฐานผู้ติดตามจำนวนมากอยู่แล้ว โดยมีประวัติการดาวน์โหลดนับร้อยล้านครั้ง และส่งเสริมชุมชนที่มีชีวิตชีวาซึ่งได้สร้างโมเดลอนุพันธ์มากกว่า 100,000 โมเดลบนแพลตฟอร์มต่างๆ เช่น Hugging Face
ซีรีส์ Qwen3 ประกอบด้วยโมเดลย่อยที่สำคัญหลายรุ่น ซึ่งแต่ละรุ่นได้รับการปรับแต่งให้เหมาะกับโดเมนที่แตกต่างกัน:
- Qwen3-Instruct: โมเดลสำหรับตามคำสั่งทั่วไปที่ออกแบบมาสำหรับการสนทนาและการประยุกต์ใช้งานที่เน้นงานที่หลากหลาย ตัวอย่างเช่น โมเดลย่อย
Qwen3-235B-A22B-Instruct-2507มีชื่อเสียงในด้านการปรับให้เข้ากับความต้องการของผู้ใช้ในงานปลายเปิดและการครอบคลุมความรู้ที่กว้างขวาง - Qwen3-Coder: ซีรีส์ของโมเดลที่ออกแบบมาโดยเฉพาะสำหรับการเขียนโค้ดแบบ agentic โมเดลที่ทรงพลังที่สุดในกลุ่มนี้ ซึ่งเป็นโมเดลขนาดใหญ่ที่มีพารามิเตอร์ 480 พันล้านตัว ได้สร้างมาตรฐานใหม่สำหรับการสร้างโค้ดแบบโอเพนซอร์สและการทำงานอัตโนมัติในการพัฒนาซอฟต์แวร์ มาพร้อมกับเครื่องมือบรรทัดคำสั่ง Qwen Code เพื่อใช้ประโยชน์จากความสามารถแบบ agentic ได้ดียิ่งขึ้น
- Qwen3-Thinking: จุดมุ่งเน้นของการวิเคราะห์ของเรา ซึ่งเชี่ยวชาญสำหรับงานด้านการรับรู้ที่ซับซ้อนที่นอกเหนือจากการทำตามคำสั่งง่ายๆ หรือการสร้างโค้ด
แนวทางแบบครอบครัวนี้แสดงให้เห็นถึงกลยุทธ์ที่ซับซ้อน: แทนที่จะเป็นโมเดลเดียวแบบรวมศูนย์ที่พยายามทำได้ทุกอย่าง Alibaba กำลังนำเสนอชุดเครื่องมือเฉพาะทาง ช่วยให้นักพัฒนาสามารถเลือกรากฐานที่เหมาะสมกับความต้องการเฉพาะของตนได้
มาพูดถึงส่วน "Thinking" ของ Qwen3-235B-A22B-Thinking-2507 กัน
ชื่อโมเดล Qwen3-235B-A22B-Thinking-2507 เต็มไปด้วยข้อมูลที่เผยให้เห็นสถาปัตยกรรมและปรัชญาการออกแบบที่ซ่อนอยู่ มาดูกันทีละส่วน
Qwen3: หมายความว่าโมเดลนี้เป็นของซีรีส์ Qwen รุ่นที่สาม โดยสร้างขึ้นจากความรู้และความก้าวหน้าของรุ่นก่อนหน้า235B-A22B(Mixture of Experts - MoE): นี่คือรายละเอียดทางสถาปัตยกรรมที่สำคัญที่สุด โมเดลนี้ไม่ใช่เครือข่ายที่มีพารามิเตอร์หนาแน่น 235 พันล้านตัว ซึ่งทุกพารามิเตอร์ถูกใช้สำหรับการคำนวณทุกครั้ง แต่กลับใช้สถาปัตยกรรมแบบ Mixture-of-Experts (MoE)Thinking: คำต่อท้ายนี้บ่งบอกถึงความเชี่ยวชาญของโมเดล ซึ่งได้รับการปรับแต่งอย่างละเอียดบนข้อมูลที่ให้ผลตอบแทนในการอนุมานเชิงตรรกะและการวิเคราะห์แบบทีละขั้นตอน2507: นี่คือแท็กเวอร์ชัน ซึ่งน่าจะหมายถึงเดือนกรกฎาคม 2025 ซึ่งบ่งชี้ถึงวันที่เผยแพร่โมเดลหรือวันที่ฝึกอบรมเสร็จสิ้น
สถาปัตยกรรม MoE เป็นกุญแจสำคัญในการรวมพลังและประสิทธิภาพของโมเดลนี้ อาจเปรียบได้กับทีมขนาดใหญ่ของ "ผู้เชี่ยวชาญ" เฉพาะทาง ซึ่งเป็นเครือข่ายประสาทเทียมขนาดเล็กที่บริหารจัดการโดย "เครือข่ายเกต" หรือ "เราเตอร์" สำหรับโทเค็นอินพุตใดๆ เราเตอร์จะเลือกชุดย่อยขนาดเล็กของผู้เชี่ยวชาญที่เกี่ยวข้องมากที่สุดเพื่อประมวลผลข้อมูลแบบไดนามิก
ในกรณีของ Qwen3-235B-A22B รายละเอียดเฉพาะคือ:
- พารามิเตอร์ทั้งหมด (
235B): สิ่งนี้แสดงถึงคลังความรู้ขนาดใหญ่ที่กระจายอยู่ทั่วผู้เชี่ยวชาญทั้งหมดที่มีอยู่ โมเดลนี้ประกอบด้วย ผู้เชี่ยวชาญที่แตกต่างกัน 128 คน - พารามิเตอร์ที่ใช้งานอยู่ (
A22B): สำหรับการอนุมานแต่ละครั้ง เครือข่ายเกตจะเลือก ผู้เชี่ยวชาญ 8 คน เพื่อเปิดใช้งาน ขนาดรวมของผู้เชี่ยวชาญที่ใช้งานอยู่เหล่านี้อยู่ที่ประมาณ 22 พันล้านพารามิเตอร์
ประโยชน์ของแนวทางนี้มีมากมาย ช่วยให้โมเดลมีความรู้ ความละเอียดอ่อน และความสามารถอันกว้างใหญ่ของโมเดลพารามิเตอร์ 235B ในขณะที่มีต้นทุนการคำนวณและความเร็วในการอนุมานใกล้เคียงกับโมเดลหนาแน่นที่มีพารามิเตอร์ 22B ที่เล็กกว่ามาก สิ่งนี้ทำให้การปรับใช้และรันโมเดลขนาดใหญ่ดังกล่าวเป็นไปได้มากขึ้นโดยไม่สูญเสียความลึกของความรู้
ข้อมูลจำเพาะทางเทคนิคและโปรไฟล์ประสิทธิภาพ
นอกเหนือจากสถาปัตยกรรมระดับสูงแล้ว ข้อมูลจำเพาะโดยละเอียดของโมเดลยังให้ภาพที่ชัดเจนยิ่งขึ้นเกี่ยวกับความสามารถของมัน
- สถาปัตยกรรมโมเดล: Mixture-of-Experts (MoE)
- พารามิเตอร์ทั้งหมด: ประมาณ 235 พันล้าน
- พารามิเตอร์ที่ใช้งานอยู่: ประมาณ 22 พันล้านต่อโทเค็น
- จำนวนผู้เชี่ยวชาญ: 128
- ผู้เชี่ยวชาญที่เปิดใช้งานต่อโทเค็น: 8
- ความยาวบริบท: โมเดลรองรับ หน้าต่างบริบท 128,000 โทเค็น นี่เป็นการปรับปรุงครั้งใหญ่ที่ช่วยให้สามารถประมวลผลและให้เหตุผลกับเอกสารที่ยาวมาก ฐานโค้ดทั้งหมด หรือประวัติการสนทนาที่ยาวนาน โดยไม่สูญเสียข้อมูลสำคัญจากจุดเริ่มต้นของอินพุต
- ตัวแยกโทเค็น (Tokenizer): ใช้ตัวแยกโทเค็น Byte Pair Encoding (BPE) แบบกำหนดเองที่มีคำศัพท์มากกว่า 150,000 โทเค็น ขนาดคำศัพท์ที่ใหญ่เช่นนี้บ่งบอกถึงการฝึกอบรมหลายภาษาที่แข็งแกร่ง ทำให้สามารถเข้ารหัสข้อความจากภาษาต่างๆ ได้อย่างมีประสิทธิภาพ รวมถึงภาษาอังกฤษ จีน เยอรมัน สเปน และอื่นๆ อีกมากมาย ตลอดจนภาษาโปรแกรม
- ข้อมูลการฝึกอบรม: แม้ว่าองค์ประกอบที่แน่นอนของคลังข้อมูลการฝึกอบรมจะเป็นกรรมสิทธิ์ แต่โมเดล
Thinkingได้รับการฝึกอบรมบนชุดข้อมูลเฉพาะที่ออกแบบมาเพื่อส่งเสริมการให้เหตุผล ชุดข้อมูลนี้จะก้าวข้ามข้อความเว็บมาตรฐานไปมาก และน่าจะรวมถึง: - เอกสารทางวิชาการและวิทยาศาสตร์: ข้อความจำนวนมากจากแหล่งข้อมูลเช่น arXiv, PubMed และคลังข้อมูลการวิจัยอื่นๆ เพื่อซึมซับการให้เหตุผลทางวิทยาศาสตร์และคณิตศาสตร์ที่ซับซ้อน
- ชุดข้อมูลเชิงตรรกะและคณิตศาสตร์: ชุดข้อมูลเช่น GSM8K (คณิตศาสตร์ระดับประถม) และชุดข้อมูล MATH ซึ่งมีโจทย์ปัญหาที่ต้องใช้การแก้ปัญหาแบบทีละขั้นตอน
- ปัญหาการเขียนโปรแกรมและโค้ด: ชุดข้อมูลเช่น HumanEval และ MBPP ซึ่งทดสอบการให้เหตุผลเชิงตรรกะผ่านการสร้างโค้ด
- ข้อความปรัชญาและกฎหมาย: เอกสารที่ต้องการความเข้าใจข้อโต้แย้งเชิงตรรกะที่หนาแน่น เป็นนามธรรม และมีโครงสร้างสูง
- ข้อมูล Chain-of-Thought (CoT): ตัวอย่างที่สร้างขึ้นสังเคราะห์หรือคัดสรรโดยมนุษย์ ซึ่งโมเดลจะได้รับการแสดงวิธี "คิดทีละขั้นตอน" เพื่อให้ได้คำตอบอย่างชัดเจน
ชุดข้อมูลที่คัดสรรมาอย่างดีนี้คือสิ่งที่แยกโมเดล Thinking ออกจากโมเดล Instruct มันไม่ได้ถูกฝึกมาเพื่อให้เป็นประโยชน์เท่านั้น แต่ยังถูกฝึกมาให้มีความแม่นยำและเข้มงวด
พลังแห่ง "การคิด": การมุ่งเน้นไปที่การรับรู้ที่ซับซ้อน
คำมั่นสัญญาของโมเดล Qwen3-Thinking อยู่ที่ความสามารถในการจัดการกับปัญหาที่ในอดีตเป็นความท้าทายสำคัญสำหรับโมเดลภาษาขนาดใหญ่ งานเหล่านี้เป็นงานที่การจับคู่รูปแบบง่ายๆ หรือการดึงข้อมูลไม่เพียงพอ ความเชี่ยวชาญด้าน "การคิด" บ่งบอกถึงความเชี่ยวชาญในด้านต่างๆ เช่น:
- การให้เหตุผลแบบหลายขั้นตอน: การแก้ปัญหาที่ต้องแบ่งคำถามออกเป็นลำดับขั้นตอนเชิงตรรกะ ตัวอย่างเช่น การคำนวณผลกระทบทางการเงินของการตัดสินใจทางธุรกิจโดยอิงจากตัวแปรตลาดหลายตัว หรือการวางแผนวิถีของกระสุนโดยพิจารณาจากข้อจำกัดทางกายภาพ
- การอนุมานเชิงตรรกะ: การวิเคราะห์ชุดของข้อสมมติฐานและการสรุปผลที่ถูกต้อง ซึ่งอาจเกี่ยวข้องกับการแก้ปริศนากริดเชิงตรรกะ การระบุข้อผิดพลาดทางตรรกะในข้อความ หรือการกำหนดผลลัพธ์ของชุดกฎในบริบททางกฎหมายหรือสัญญา
- การวางแผนเชิงกลยุทธ์: การคิดค้นลำดับของการกระทำเพื่อให้บรรลุเป้าหมาย สิ่งนี้มีการประยุกต์ใช้ในการเล่นเกมที่ซับซ้อน (เช่น หมากรุกหรือโกะ) การจำลองกลยุทธ์ทางธุรกิจ การเพิ่มประสิทธิภาพห่วงโซ่อุปทาน และการจัดการโครงการอัตโนมัติ
- การอนุมานเชิงสาเหตุ: การพยายามระบุความสัมพันธ์ระหว่างเหตุและผลภายในระบบที่ซับซ้อนที่อธิบายในข้อความ ซึ่งเป็นรากฐานสำคัญของการให้เหตุผลทางวิทยาศาสตร์และการวิเคราะห์ที่โมเดลมักประสบปัญหา
- การให้เหตุผลเชิงนามธรรม: การทำความเข้าใจและการจัดการแนวคิดเชิงนามธรรมและการเปรียบเทียบ สิ่งนี้จำเป็นสำหรับการแก้ปัญหาเชิงสร้างสรรค์และสติปัญญาในระดับมนุษย์อย่างแท้จริง โดยก้าวข้ามข้อเท็จจริงที่เป็นรูปธรรมไปสู่ความสัมพันธ์ระหว่างสิ่งเหล่านั้น
โมเดลนี้ได้รับการออกแบบมาให้โดดเด่นในเกณฑ์มาตรฐานที่วัดความสามารถทางปัญญาขั้นสูงเหล่านี้โดยเฉพาะ เช่น MMLU (Massive Multitask Language Understanding) สำหรับความรู้ทั่วไปและการแก้ปัญหา และ GSM8K และ MATH ที่กล่าวมาข้างต้นสำหรับการให้เหตุผลทางคณิตศาสตร์
การเข้าถึง, การควอนไทซ์ และการมีส่วนร่วมของชุมชน
พลังของโมเดลจะมีความหมายก็ต่อเมื่อสามารถเข้าถึงและใช้งานได้เท่านั้น Alibaba ยังคงยึดมั่นในพันธกิจโอเพนซอร์ส โดยได้ทำให้ตระกูล Qwen3 รวมถึงโมเดลย่อย Thinking พร้อมใช้งานอย่างกว้างขวางบนแพลตฟอร์มต่างๆ เช่น Hugging Face และ ModelScope
ตระหนักถึงทรัพยากรการคำนวณจำนวนมากที่จำเป็นในการรันโมเดลขนาดนี้ จึงมีเวอร์ชันที่ผ่านการควอนไทซ์ (quantized) ให้ใช้งานด้วย โมเดล Qwen3-235B-A22B-Thinking-2507-FP8 เป็นตัวอย่างที่สำคัญ FP8 (8-bit floating point) เป็นเทคนิคการควอนไทซ์ที่ล้ำสมัยซึ่งช่วยลดการใช้หน่วยความจำของโมเดลลงอย่างมากและเพิ่มความเร็วในการอนุมาน
มาดูผลกระทบกัน:
- โมเดลพารามิเตอร์ 235B ในความแม่นยำมาตรฐาน 16 บิต (BF16/FP16) จะต้องใช้ VRAM มากกว่า 470 GB ซึ่งเป็นจำนวนที่มากเกินไปสำหรับเซิร์ฟเวอร์คลัสเตอร์ระดับองค์กรที่ใหญ่ที่สุดเท่านั้น
- อย่างไรก็ตาม เวอร์ชัน FP8 ที่ผ่านการควอนไทซ์ จะลดความต้องการนี้ลงเหลือไม่ถึง 250 GB แม้จะยังคงมีขนาดใหญ่ แต่ก็ทำให้โมเดลนี้สามารถใช้งานได้สำหรับสถาบันวิจัย สตาร์ทอัพ และแม้แต่บุคคลที่มีเวิร์กสเตชันหลาย GPU ที่ติดตั้งฮาร์ดแวร์ระดับผู้บริโภคหรือมืออาชีพระดับสูง
สิ่งนี้ทำให้การให้เหตุผลขั้นสูงสามารถเข้าถึงได้สำหรับผู้ใช้ในวงกว้างขึ้น สำหรับผู้ใช้ระดับองค์กรที่ต้องการบริการที่มีการจัดการ โมเดลเหล่านี้กำลังถูกรวมเข้ากับแพลตฟอร์มคลาวด์ของ Alibaba การเข้าถึง API ผ่าน Model Studio และการรวมเข้ากับผู้ช่วย AI เรือธงของ Alibaba อย่าง Quark ทำให้มั่นใจได้ว่าเทคโนโลยีนี้สามารถนำไปใช้ประโยชน์ได้ทุกขนาด
บทสรุป: เครื่องมือใหม่สำหรับปัญหาประเภทใหม่
การเปิดตัว Qwen3-235B-A22B-Thinking-2507 เป็นมากกว่าเพียงแค่จุดหนึ่งบนกราฟประสิทธิภาพของโมเดล AI ที่เพิ่มขึ้นอย่างต่อเนื่อง มันเป็นการประกาศทิศทางในอนาคตของการพัฒนา AI: การเปลี่ยนผ่านจากโมเดลแบบรวมศูนย์และใช้งานทั่วไป ไปสู่ระบบนิเวศที่หลากหลายของเครื่องมือที่ทรงพลังและเชี่ยวชาญ ด้วยการใช้สถาปัตยกรรม Mixture-of-Experts ที่มีประสิทธิภาพ Alibaba ได้นำเสนอโมเดลที่มีความรู้กว้างขวางเทียบเท่าเครือข่ายพารามิเตอร์ 235 พันล้านตัว และความเป็นมิตรต่อการคำนวณที่ใกล้เคียงกับโมเดลพารามิเตอร์ 22 พันล้านตัว
ด้วยการปรับแต่งโมเดลนี้อย่างชัดเจนสำหรับ "การคิด" ทีม Qwen ได้มอบเครื่องมือที่อุทิศให้กับการแก้ไขความท้าทายในการวิเคราะห์และการให้เหตุผลที่ยากที่สุดให้แก่โลก มันมีศักยภาพในการเร่งการค้นพบทางวิทยาศาสตร์โดยช่วยให้นักวิจัยวิเคราะห์ข้อมูลที่ซับซ้อน เสริมสร้างศักยภาพให้ธุรกิจสามารถตัดสินใจเชิงกลยุทธ์ได้ดีขึ้น และทำหน้าที่เป็นรากฐานสำหรับแอปพลิเคชันอัจฉริยะรุ่นใหม่ที่สามารถวางแผน อนุมาน และให้เหตุผลด้วยความซับซ้อนที่ไม่เคยมีมาก่อน เมื่อชุมชนโอเพนซอร์สเริ่มสำรวจความลึกของมันอย่างเต็มที่ Qwen3-Thinking ก็พร้อมที่จะกลายเป็นองค์ประกอบสำคัญในการแสวงหา AI ที่มีความสามารถและฉลาดอย่างแท้จริงอย่างต่อเนื่อง
ต้องการแพลตฟอร์มแบบครบวงจรสำหรับทีมพัฒนาของคุณเพื่อทำงานร่วมกันด้วย ประสิทธิภาพสูงสุด หรือไม่?
Apidog ตอบสนองทุกความต้องการของคุณ และ แทนที่ Postman ในราคาที่ย่อมเยาลงมาก!