
Qwen โครงการโมเดลพื้นฐานแบบเปิดจาก Alibaba ผลักดันขีดจำกัดของปัญญาประดิษฐ์อย่างต่อเนื่องผ่านการทำซ้ำและเผยแพร่ที่รวดเร็ว นักพัฒนาและนักวิจัยต่างตั้งตารอการอัปเดตแต่ละครั้ง เนื่องจากโมเดล Qwen มักจะสร้างมาตรฐานใหม่ในด้านประสิทธิภาพและความหลากหลาย ล่าสุด Qwen ได้เปิดตัวสามโมเดลนวัตกรรมใหม่ ได้แก่ Qwen-Image-Edit-2509, Qwen3-TTS-Flash และ Qwen3-Omni การเปิดตัวเหล่านี้ช่วยเพิ่มขีดความสามารถในการแก้ไขรูปภาพ การสังเคราะห์เสียงพูดจากข้อความ และการประมวลผลแบบ omni-modal ตามลำดับ
ยิ่งไปกว่านั้น โมเดลเหล่านี้มาถึงในช่วงเวลาสำคัญของการพัฒนา AI ซึ่งการรวมระบบหลายโมดอลกลายเป็นสิ่งจำเป็นสำหรับแอปพลิเคชันเชิงปฏิบัติ Qwen-Image-Edit-2509 ตอบสนองความต้องการในการจัดการภาพที่แม่นยำ ในขณะที่ Qwen3-TTS-Flash แก้ปัญหาความล่าช้าในการสร้างเสียง ในขณะเดียวกัน การแนะนำ Qwen3-Omni รวมอินพุตที่หลากหลายเข้าไว้ในกรอบการทำงานที่สอดคล้องกัน โดยรวมแล้ว โมเดลเหล่านี้แสดงให้เห็นถึงความมุ่งมั่นของ Qwen ในการสร้าง AI ที่เข้าถึงได้และมีประสิทธิภาพสูง อย่างไรก็ตาม การทำความเข้าใจพื้นฐานทางเทคนิคของโมเดลเหล่านี้จำเป็นต้องมีการตรวจสอบอย่างใกล้ชิด บทความนี้จะวิเคราะห์แต่ละโมเดล โดยเน้นคุณสมบัติ สถาปัตยกรรม เกณฑ์มาตรฐาน และผลกระทบที่อาจเกิดขึ้น
Qwen-Image-Edit-2509: ยกระดับความแม่นยำในการแก้ไขรูปภาพ
Qwen-Image-Edit-2509 แสดงถึงความก้าวหน้าครั้งสำคัญในการจัดการรูปภาพที่ขับเคลื่อนด้วย AI วิศวกรของ Qwen ได้สร้างโมเดลนี้ขึ้นใหม่เพื่อตอบสนองความต้องการของนักสร้างสรรค์ นักออกแบบ และนักพัฒนาที่ต้องการการควบคุมเนื้อหาภาพอย่างละเอียด แตกต่างจากเวอร์ชันก่อนหน้า เวอร์ชันนี้รองรับการแก้ไขหลายรูปภาพ ทำให้ผู้ใช้สามารถรวมองค์ประกอบต่างๆ เช่น บุคคลกับผลิตภัณฑ์ หรือฉากได้อย่างง่ายดาย ด้วยเหตุนี้ จึงช่วยขจัดสิ่งแปลกปลอมทั่วไป เช่น การผสมที่ไม่เข้ากัน ทำให้ได้ผลลัพธ์ที่สอดคล้องกัน

โมเดลนี้โดดเด่นในเรื่องความสอดคล้องของรูปภาพเดียว มันรักษาเอกลักษณ์ของใบหน้าในท่าทาง สไตล์ และฟิลเตอร์ต่างๆ ซึ่งมีคุณค่าอย่างยิ่งสำหรับการใช้งานในการโฆษณาและการปรับเปลี่ยนในแบบของคุณ สำหรับรูปภาพผลิตภัณฑ์ Qwen-Image-Edit-2509 รักษาความสมบูรณ์ของวัตถุ ทำให้มั่นใจว่าการแก้ไขจะไม่บิดเบือนคุณสมบัติหลัก นอกจากนี้ ยังจัดการองค์ประกอบข้อความได้อย่างครอบคลุม ทำให้สามารถแก้ไขเนื้อหา แบบอักษร สี และแม้กระทั่งพื้นผิวได้ ความหลากหลายนี้เกิดจากกลไก ControlNet ที่รวมเข้าด้วยกัน ซึ่งรวมแผนที่ความลึก การตรวจจับขอบ และจุดสำคัญสำหรับการแนะนำที่แม่นยำ
ในทางเทคนิค Qwen-Image-Edit-2509 สร้างขึ้นบนสถาปัตยกรรม Qwen-Image พื้นฐาน แต่รวมเทคนิคการฝึกอบรมขั้นสูงเข้าไว้ด้วย นักพัฒนาฝึกอบรมโดยใช้วิธีการต่อภาพเพื่ออำนวยความสะดวกในการป้อนภาพหลายภาพ ตัวอย่างเช่น การรวม "บุคคล + บุคคล" หรือ "บุคคล + ฉาก" ใช้ประโยชน์จากสตรีมข้อมูลที่ต่อกัน ซึ่งช่วยเพิ่มความสามารถของโมเดลในการรวมภาพที่แตกต่างกัน ยิ่งไปกว่านั้น สถาปัตยกรรมยังรวมกระบวนการที่ใช้การแพร่กระจาย ซึ่งจะค่อยๆ ลบสัญญาณรบกวนออกเพื่อสร้างภาพที่ปรับปรุงแล้ว แนวทางนี้ ซึ่งเป็นเรื่องปกติในตัวแปรการแพร่กระจายที่เสถียร ช่วยให้สามารถสร้างแบบมีเงื่อนไขตามข้อความแจ้งของผู้ใช้ได้
ในแง่ของเกณฑ์มาตรฐาน Qwen-Image-Edit-2509 แสดงประสิทธิภาพที่เหนือกว่าในเมตริกความสอดคล้อง การประเมินภายในแสดงให้เห็นว่าโมเดลนี้มีประสิทธิภาพเหนือกว่าคู่แข่งในการรักษาใบหน้า โดยมีคะแนนความคล้ายคลึงกันเกิน 95% ในการแก้ไขที่หลากหลาย เกณฑ์มาตรฐานความสอดคล้องของผลิตภัณฑ์เผยให้เห็นการบิดเบือนน้อยที่สุด ทำให้เหมาะสำหรับอีคอมเมิร์ซ อย่างไรก็ตาม ข้อมูลเชิงปริมาณจากแหล่งภายนอกยังคงมีจำกัดเนื่องจากการเปิดตัวล่าสุด อย่างไรก็ตาม การสาธิตของผู้ใช้บนแพลตฟอร์มเช่น Hugging Face เน้นย้ำถึงความได้เปรียบเหนือโมเดลเช่น Stable Diffusion XL ในการผสมผสานหลายองค์ประกอบ
การใช้งานสำหรับ Qwen-Image-Edit-2509 มีมากมาย นักการตลาดใช้เพื่อสร้างโฆษณาที่กำหนดเองโดยการแก้ไขตำแหน่งผลิตภัณฑ์ได้อย่างราบรื่น นักออกแบบใช้สำหรับการสร้างต้นแบบอย่างรวดเร็ว โดยการเปลี่ยนฉากโดยไม่ต้องรีทัชด้วยตนเอง ยิ่งไปกว่านั้น ในเกม ยังช่วยอำนวยความสะดวกในการสร้างสินทรัพย์แบบไดนามิก ตัวอย่างที่ชัดเจนอย่างหนึ่งคือการเปลี่ยนชุดของบุคคล: รูปภาพอินพุตของผู้หญิงในชุดลำลอง รวมกับภาพอ้างอิงชุดเดรสสีดำ จะได้ผลลัพธ์ที่ชุดเดรสเข้ากับรูปร่างอย่างเป็นธรรมชาติ โดยรักษาสรีระและแสงไว้ ความสามารถนี้ ดังที่แสดงในการสาธิตด้วยภาพ เน้นย้ำถึงประโยชน์ใช้สอยจริง


ในการนำไปใช้งาน นักพัฒนาสามารถเข้าถึง Qwen-Image-Edit-2509 ได้ผ่านทาง ที่เก็บ GitHub และ พื้นที่ Hugging Face การติดตั้งโดยทั่วไปจะเกี่ยวข้องกับการโคลนที่เก็บและตั้งค่าการพึ่งพา เช่น PyTorch สคริปต์การใช้งานพื้นฐานอาจมีลักษณะดังนี้:
import torch
from qwen_image_edit import QwenImageEdit
model = QwenImageEdit.from_pretrained("Qwen/Qwen-Image-Edit-2509")
input_image = load_image("person.jpg")
reference_image = load_image("dress.jpg")
output = model.edit_multi(input_image, reference_image, prompt="Apply the black dress to the person")
output.save("edited.jpg")
โค้ดดังกล่าวช่วยให้สามารถทำซ้ำได้อย่างรวดเร็ว อย่างไรก็ตาม ผู้ใช้ต้องพิจารณาข้อกำหนดด้านการคำนวณ เนื่องจากอนุมานต้องการการเร่งความเร็ว GPU เพื่อความเร็วที่เหมาะสม
แม้จะมีจุดแข็ง แต่ Qwen-Image-Edit-2509 ก็ยังเผชิญกับความท้าทาย การแก้ไขที่มีความละเอียดสูงสามารถใช้หน่วยความจำจำนวนมาก และข้อความแจ้งที่ซับซ้อนบางครั้งอาจนำไปสู่ความไม่สอดคล้องกัน อย่างไรก็ตาม การมีส่วนร่วมของชุมชนอย่างต่อเนื่องผ่านช่องทางโอเพนซอร์สช่วยบรรเทาปัญหาเหล่านี้ได้ โดยรวมแล้ว โมเดลนี้กำหนดนิยามใหม่ของการแก้ไขรูปภาพโดยการรวมความแม่นยำเข้ากับการเข้าถึงได้
Qwen3-TTS-Flash: เร่งการสังเคราะห์เสียงพูดจากข้อความ
Qwen3-TTS-Flash ถือกำเนิดขึ้นเป็นขุมพลังในเทคโนโลยีข้อความเป็นคำพูด (TTS) โดยให้ความสำคัญกับความเร็วและความเป็นธรรมชาติ วิศวกรของ Qwen ออกแบบมาเพื่อให้เสียงเหมือนมนุษย์โดยมีความหน่วงน้อยที่สุด แก้ปัญหาคอขวดในแอปพลิเคชันแบบเรียลไทม์ โดยเฉพาะอย่างยิ่ง มันมีความหน่วงของแพ็กเก็ตแรกเพียง 97 มิลลิวินาทีในสภาพแวดล้อมแบบเธรดเดียว ทำให้สามารถโต้ตอบได้อย่างราบรื่นในแชทบอทและผู้ช่วยเสมือน
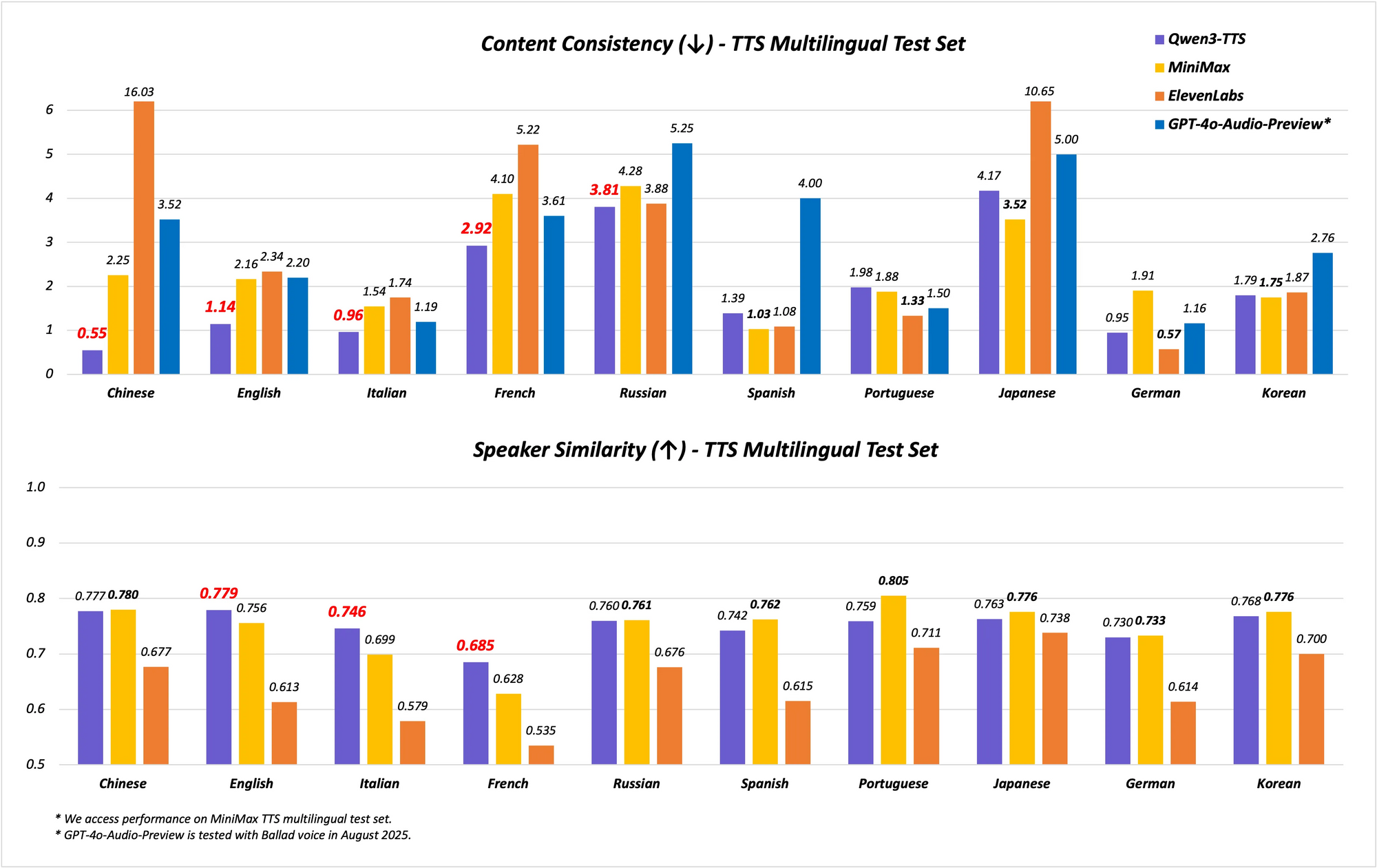
โมเดลนี้รองรับความสามารถหลายภาษาและหลายสำเนียง ครอบคลุม 10 ภาษาด้วยเสียงที่แสดงออกถึงอารมณ์ 17 เสียง มันโดดเด่นในด้านความเสถียรของภาษาจีนและอังกฤษ โดยบรรลุประสิทธิภาพระดับ State-of-the-Art (SOTA) ในเกณฑ์มาตรฐานเช่นชุดทดสอบ Seed-TTS-Eval ที่นี่ มันเหนือกว่าโมเดลเช่น SeedTTS, MiniMax และ GPT-4o-Audio-Preview ในเมตริกความเสถียร ยิ่งไปกว่านั้น ในการประเมินหลายภาษาบนชุดทดสอบ MiniMax TTS, Qwen3-TTS-Flash บันทึกอัตราความผิดพลาดของคำ (WER) ต่ำที่สุดสำหรับภาษาจีน อังกฤษ อิตาลี และฝรั่งเศส
การรองรับสำเนียงทำให้ Qwen3-TTS-Flash แตกต่าง มันจัดการสำเนียงจีนเก้าสำเนียง รวมถึงกวางตุ้ง ฮกเกี้ยน เสฉวน ปักกิ่ง หนานจิง เทียนจิน และฉ่านซี คุณสมบัตินี้ช่วยให้สามารถพูดได้ละเอียดอ่อนทางวัฒนธรรม ซึ่งจำเป็นในตลาดที่หลากหลาย นอกจากนี้ โมเดลยังปรับโทนเสียงโดยอัตโนมัติ โดยดึงข้อมูลจากการฝึกอบรมขนาดใหญ่เพื่อให้ตรงกับความรู้สึกของอินพุต การจัดการข้อความที่แข็งแกร่งช่วยเพิ่มความน่าเชื่อถือ เนื่องจากมันดึงข้อมูลสำคัญจากรูปแบบที่ซับซ้อน เช่น วันที่ ตัวเลข และตัวย่อ
ในทางสถาปัตยกรรม Qwen3-TTS-Flash ใช้กรอบการทำงานตัวเข้ารหัส-ตัวถอดรหัสที่ใช้หม้อแปลงไฟฟ้า ซึ่งปรับให้เหมาะสมสำหรับการอนุมานที่มีความหน่วงต่ำ มันใช้การแสดงรหัสหลายเล่มสำหรับการสร้างแบบจำลองเสียงที่สมบูรณ์ยิ่งขึ้น ปรับปรุงการแสดงออก การฝึกอบรมเกี่ยวข้องกับชุดข้อมูลขนาดใหญ่ที่ครอบคลุม 119 ภาษาสำหรับข้อความ และ 19 ภาษาสำหรับการทำความเข้าใจเสียงพูด แม้ว่าผลลัพธ์จะเน้นที่ 10 ภาษา การตั้งค่านี้ช่วยให้สามารถสร้างข้ามภาษาได้ โดยที่อินพุตในภาษาหนึ่งสร้างเอาต์พุตในอีกภาษาหนึ่งได้อย่างราบรื่น

เกณฑ์มาตรฐานแสดงให้เห็นถึงความสามารถ ในการทดสอบความเสถียร Qwen3-TTS-Flash ได้คะแนนสูงกว่าในด้านความคล้ายคลึงของโทนเสียงและความเป็นธรรมชาติเมื่อเทียบกับ ElevenLabs และ GPT-4o ตัวอย่างเช่น:
| เกณฑ์มาตรฐาน | Qwen3-TTS-Flash | MiniMax | GPT-4o-Audio-Preview |
|---|---|---|---|
| ความเสถียรของภาษาจีน | SOTA | ต่ำกว่า | ต่ำกว่า |
| WER ภาษาอังกฤษ | ต่ำที่สุด | สูงกว่า | สูงกว่า |
| ความคล้ายคลึงของโทนเสียงหลายภาษา | SOTA | ต่ำกว่า | ต่ำกว่า |
ผลลัพธ์เหล่านี้มาจากการประเมินที่เข้มงวด ทำให้เป็นผู้นำในด้าน TTS
ในการสาธิต Qwen3-TTS-Flash สร้างเสียงพูดที่แสดงออกถึงอารมณ์ เช่น การอธิบาย "ลาเต้ลาเวนเดอร์น้ำผึ้ง" ด้วยความกระตือรือร้น หรือการจัดการบทสนทนาในสำเนียงต่างๆ สคริปต์วิดีโอเผยให้เห็นความสามารถในการประมวลผลอินพุตภาษาผสม เช่น "I'm really happy today. I know that girl from China," ที่ส่งออกมาในเสียงที่มีสำเนียง แอปพลิเคชันรวมถึงระบบตอบรับด้วยเสียงแบบโต้ตอบ (IVR) NPC ในเกม และการสร้างเนื้อหา ซึ่งความหน่วงต่ำช่วยเพิ่มประสิทธิภาพเป็นสองเท่า
การนำไปใช้งานต้องเข้าถึงโมเดลผ่าน API หรือการสาธิตของ Hugging Face ตัวอย่างการเรียกใช้ Python:
from qwen_tts import QwenTTSFlash
model = QwenTTSFlash.from_pretrained("Qwen/Qwen3-TTS-Flash")
audio = model.synthesize(text="Hello, world!", voice="expressive_english", dialect="sichuanese")
audio.save("output.wav")
ความเรียบง่ายนี้ช่วยเร่งการพัฒนา อย่างไรก็ตาม ความแม่นยำของสำเนียงอาจแตกต่างกันไปตามอินพุตที่หายาก ซึ่งจำเป็นต้องมีการปรับแต่งอย่างละเอียด
Qwen3-TTS-Flash เปลี่ยนแปลง TTS โดยการรักษาสมดุลระหว่างความเร็ว คุณภาพ และความหลากหลาย ทำให้เป็นสิ่งจำเป็นสำหรับระบบ AI สมัยใหม่
ขอแนะนำ Qwen3-Omni: ขุมพลังหลายโมดอลแบบครบวงจร
การแนะนำ Qwen3-Omni ถือเป็นก้าวสำคัญใน AI หลายโมดอล เนื่องจาก Qwen ได้รวมข้อความ รูปภาพ เสียง และวิดีโอเข้าไว้ในโมเดลเดียวแบบครบวงจร การรวมระบบแบบเนทีฟนี้หลีกเลี่ยงการแลกเปลี่ยนโมดอล ทำให้สามารถให้เหตุผลข้ามโมดอลได้ลึกซึ้งยิ่งขึ้น โมเดลนี้ประมวลผล 119 ภาษาสำหรับข้อความ 19 ภาษาสำหรับอินพุตเสียง และ 10 ภาษาสำหรับเอาต์พุตเสียง โดยมีความหน่วงที่น่าทึ่งเพียง 211 มิลลิวินาทีสำหรับการตอบสนอง
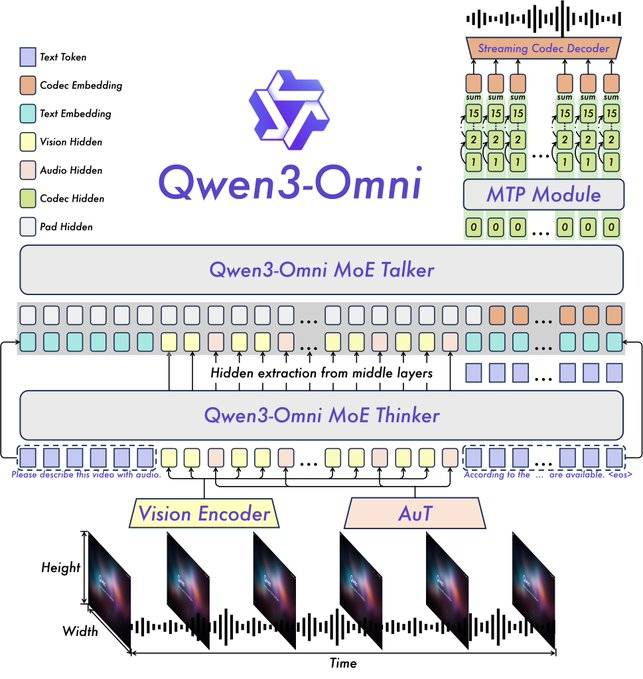
คุณสมบัติหลัก ได้แก่ ประสิทธิภาพ SOTA บนเกณฑ์มาตรฐานเสียงและภาพ-เสียง 22 จาก 36 รายการ ข้อความแจ้งระบบที่ปรับแต่งได้ การเรียกใช้เครื่องมือในตัว และโมเดลคำบรรยายโอเพนซอร์สที่มีอัตราการสร้างภาพหลอนต่ำ Qwen ได้เปิดซอร์สโค้ดตัวแปรต่างๆ เช่น Qwen3-Omni-30B-A3B-Instruct สำหรับการทำตามคำสั่ง และ Qwen3-Omni-30B-A3B-Thinking สำหรับการให้เหตุผลที่ได้รับการปรับปรุง
สถาปัตยกรรมนี้สร้างขึ้นบนกรอบการทำงาน Thinker-Talker จาก Qwen2.5-Omni โดยมีการอัปเกรด เช่น การแทนที่ตัวเข้ารหัสเสียง Whisper ด้วย Audio Transformer (AuT) เพื่อการแสดงผลที่ดีขึ้น การจัดการเสียงพูดแบบหลายรหัสช่วยเพิ่มความสมบูรณ์ของเอาต์พุตเสียง ในขณะที่บริบทที่ขยายออกไปรองรับเสียงนานกว่า 30 นาที สิ่งนี้ช่วยให้สามารถให้เหตุผลแบบเต็มโมดอลได้ โดยที่อินพุตวิดีโอจะแจ้งการตอบสนองด้วยเสียง
เกณฑ์มาตรฐานยืนยันความโดดเด่น มันบรรลุ SOTA โดยรวมบนเกณฑ์มาตรฐาน 32 รายการ โดยโดดเด่นในการทำความเข้าใจและการสร้างเสียง ตัวอย่างเช่น ในงานภาพ-เสียง มันมีประสิทธิภาพเหนือกว่าโมเดลเช่น GPT-4o ในด้านความหน่วงและความแม่นยำ ตารางเปรียบเทียบ:
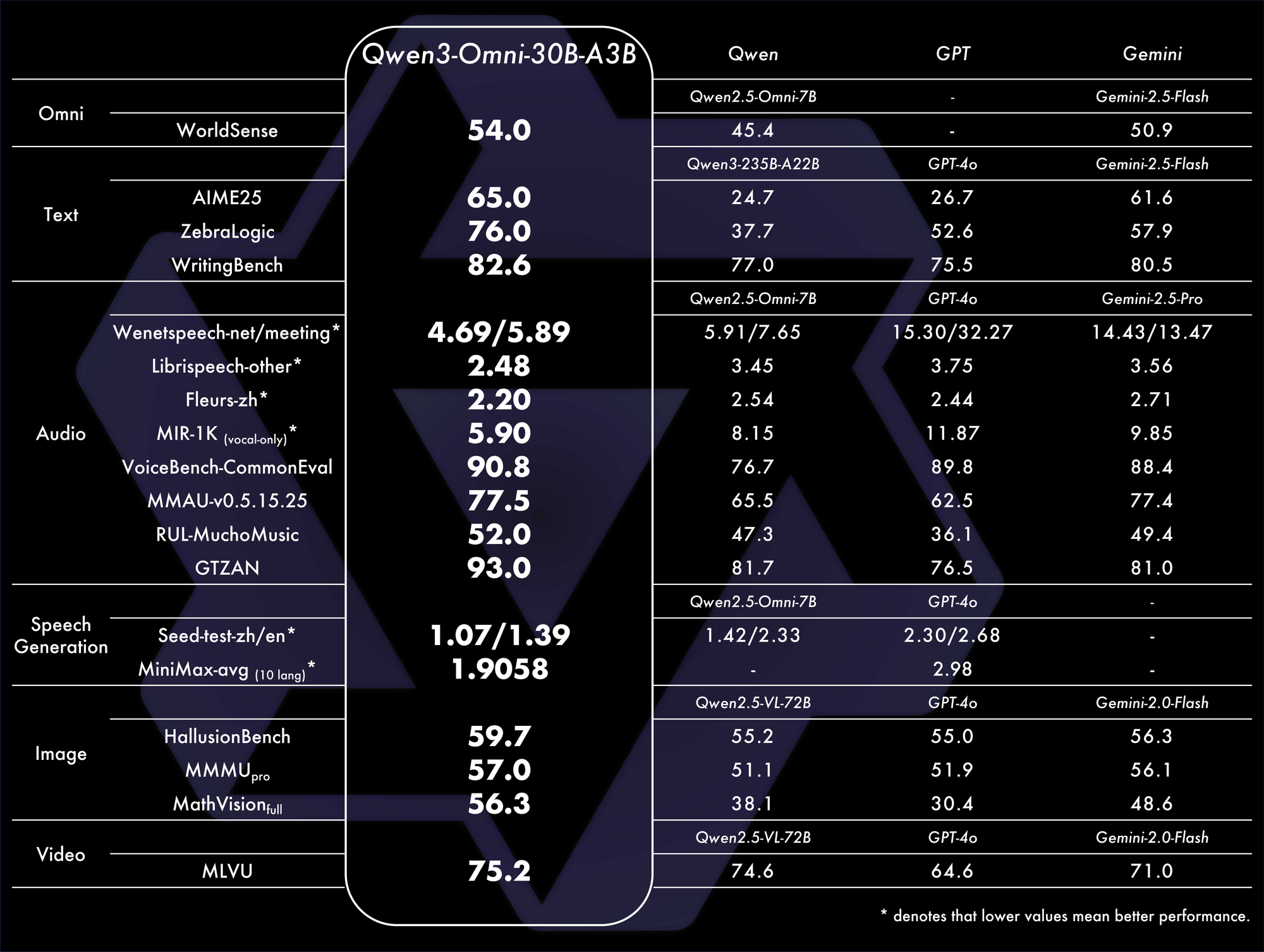
เมตริกเหล่านี้เน้นย้ำถึงประสิทธิภาพในสถานการณ์จริง
แอปพลิเคชันครอบคลุมการแชทด้วยเสียง การวิเคราะห์วิดีโอ และตัวแทนหลายโมดอล ตัวอย่างเช่น มันวิเคราะห์คลิปวิดีโอและสร้างสรุปด้วยเสียง ซึ่งเหมาะสำหรับเครื่องมือช่วยการเข้าถึง การสาธิตบน Qwen Chat แสดงการโต้ตอบด้วยเสียงและวิดีโอ โดยที่ผู้ใช้สอบถามรูปภาพหรือเสียงด้วยวาจา
จาก GitHub ไฟล์ README อธิบายว่ามันสามารถสร้างเสียงพูดแบบเรียลไทม์จากอินพุตที่หลากหลายได้ การตั้งค่าเกี่ยวข้องกับ:
from qwen_omni import Qwen3Omni
model = Qwen3Omni.from_pretrained("Qwen/Qwen3-Omni-30B-A3B-Instruct")
response = model.process(inputs={"text": "Describe this", "image": "img.jpg", "audio": "clip.wav"})
print(response.text)
response.audio.save("reply.wav")
แนวทางแบบโมดูลาร์นี้ช่วยอำนวยความสะดวกในการปรับแต่ง ความท้าทายรวมถึงความต้องการการคำนวณสูงสำหรับการประมวลผลวิดีโอ แต่การเพิ่มประสิทธิภาพเช่น quantization ช่วยได้
การแนะนำ Qwen3-Omni รวมโมดอลต่างๆ เข้าด้วยกัน ส่งเสริมระบบนิเวศ AI ที่เป็นนวัตกรรมใหม่
การทำงานร่วมกันระหว่างโมเดลใหม่ของ Qwen และผลกระทบในอนาคต
Qwen-Image-Edit-2509, Qwen3-TTS-Flash และ Qwen3-Omni เสริมซึ่งกันและกัน ทำให้สามารถสร้างเวิร์กโฟลว์แบบครบวงจรได้ ตัวอย่างเช่น แก้ไขรูปภาพด้วย Qwen-Image-Edit-2509 อธิบายผ่าน Qwen3-Omni และแปลงผลลัพธ์เป็นเสียงด้วย Qwen3-TTS-Flash การรวมระบบนี้ช่วยเพิ่มประโยชน์ในการสร้างเนื้อหาและระบบอัตโนมัติ
ยิ่งไปกว่านั้น ลักษณะโอเพนซอร์สของโมเดลเหล่านี้ยังเชิญชวนให้ชุมชนเข้ามาปรับปรุง นักพัฒนาที่ใช้ Apidog สามารถทดสอบ API ได้อย่างมีประสิทธิภาพ ทำให้มั่นใจได้ถึงการรวมระบบที่แข็งแกร่ง
อย่างไรก็ตาม ข้อพิจารณาด้านจริยธรรมก็เกิดขึ้น เช่น การนำไปใช้ในทางที่ผิดใน deepfakes Qwen ลดปัญหานี้ผ่านมาตรการป้องกัน
โดยสรุป การเปิดตัวของ Qwen ได้กำหนดนิยามใหม่ของภูมิทัศน์ AI ด้วยการผลักดันขอบเขตทางเทคนิค พวกเขาช่วยให้ผู้ใช้บรรลุผลสำเร็จได้มากขึ้น เมื่อมีการนำไปใช้มากขึ้น โมเดลเหล่านี้จะขับเคลื่อนคลื่นลูกใหม่ของนวัตกรรม