
Qwen-Image โมเดลรากฐานภาพ MMDiT ขนาด 20B ที่ล้ำสมัยจากทีม Qwen ของ Alibaba Cloud กำลังนิยามความเป็นไปได้ใหม่ของการสร้างสรรค์ภาพด้วย AI โมเดลนี้เปิดตัวเมื่อวันที่ 4 สิงหาคม 2025 มอบความสามารถที่เหนือชั้นในการสร้างภาพคุณภาพสูง การแสดงผลข้อความหลายภาษาที่ซับซ้อน และการแก้ไขภาพที่แม่นยำ ไม่ว่าคุณจะสร้างสรรค์ภาพทางการตลาดที่น่าดึงดูด หรือวิเคราะห์ข้อมูลภาพที่ซับซ้อน Qwen-Image มอบเครื่องมือที่แข็งแกร่งแก่นักพัฒนาเพื่อนำแนวคิดไปสู่ความเป็นจริง
Qwen-Image คืออะไร? ภาพรวมทางเทคนิค
Qwen-Image ซึ่งเป็นส่วนหนึ่งของซีรีส์ Qwen ของ Alibaba Cloud เป็นโมเดล Multimodal Diffusion Transformer (MMDiT) ที่มีพารามิเตอร์ 20 พันล้านตัว ออกแบบมาสำหรับการสร้างภาพและการแก้ไขภาพ แตกต่างจากโมเดลทั่วไปที่เน้นเพียงการสร้างภาพ Qwen-Image ผสานรวมการแสดงผลข้อความขั้นสูงและความเข้าใจภาพ ทำให้เป็นเครื่องมืออเนกประสงค์สำหรับงานสร้างสรรค์และการวิเคราะห์ โมเดลนี้เป็นโอเพนซอร์สภายใต้ใบอนุญาต Apache 2.0 สามารถเข้าถึงได้ผ่านแพลตฟอร์มต่างๆ เช่น GitHub, Hugging Face และ ModelScope ช่วยให้นักพัฒนาสามารถผสานรวมเข้ากับเวิร์กโฟลว์ที่หลากหลายได้

นอกจากนี้ Qwen-Image ยังใช้ชุดข้อมูลการฝึกฝนล่วงหน้าที่แข็งแกร่ง ซึ่งรวมโทเค็นกว่า 30 ล้านล้านรายการใน 119 ภาษา โดยเน้นภาษาจีนและอังกฤษ ชุดข้อมูลที่ครอบคลุมนี้ เมื่อรวมกับเทคนิคการเรียนรู้แบบเสริมกำลัง ช่วยให้โมเดลสามารถจัดการงานที่ซับซ้อน เช่น การแสดงผลข้อความหลายภาษาและการจัดการวัตถุที่แม่นยำ ด้วยเหตุนี้ จึงมีประสิทธิภาพเหนือกว่าโมเดลที่มีอยู่หลายตัวในการวัดประสิทธิภาพต่างๆ เช่น GenEval, DPG และ LongText-Bench
คุณสมบัติหลักของ Qwen-Image
การแสดงผลข้อความที่เหนือกว่าสำหรับภาพหลายภาษา
Qwen-Image มีความเป็นเลิศในการแสดงผลข้อความที่ซับซ้อนภายในภาพ ซึ่งเป็นคุณสมบัติที่ทำให้แตกต่างจากคู่แข่ง รองรับทั้งภาษาที่ใช้ตัวอักษร (เช่น ภาษาอังกฤษ) และสคริปต์ที่ใช้สัญลักษณ์ (เช่น ภาษาจีน) รับประกันการรวมข้อความที่มีความแม่นยำสูง ตัวอย่างเช่น โมเดลสามารถสร้างโปสเตอร์ภาพยนตร์ที่มีการจัดวางข้อความที่แม่นยำ เช่น ชื่อเรื่องว่า “Imagination Unleashed” และคำบรรยายหลายบรรทัด รักษาความสอดคล้องของการจัดพิมพ์ ความสามารถนี้เกิดจากการฝึกฝนด้วยชุดข้อมูลที่หลากหลาย รวมถึง LongText-Bench และ ChineseWord ซึ่งทำให้ได้ประสิทธิภาพที่ล้ำสมัยที่สุด
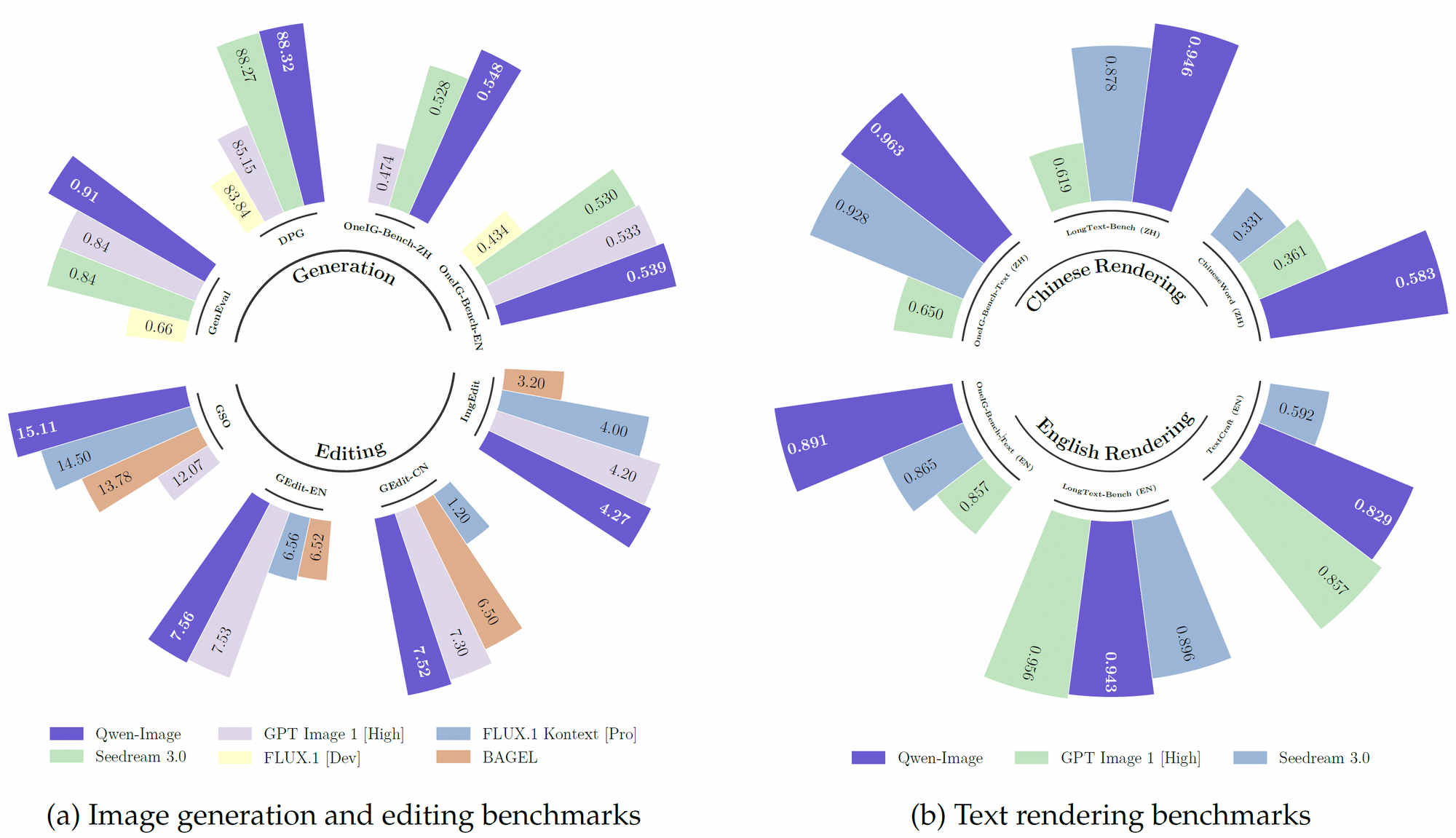
นอกจากนี้ Qwen-Image ยังจัดการการจัดวางหลายบรรทัดและความหมายระดับย่อหน้าได้อย่างแม่นยำอย่างน่าทึ่ง ในสถานการณ์การทดสอบ โมเดลได้แสดงผลบทกวีที่เขียนด้วยลายมือบนกระดาษสีเหลืองภายในภาพได้อย่างแม่นยำ แม้ว่าข้อความจะกินพื้นที่ภาพน้อยกว่าหนึ่งในสิบก็ตาม ความแม่นยำนี้ทำให้เหมาะสำหรับแอปพลิเคชันต่างๆ เช่น ป้ายดิจิทัล การออกแบบโปสเตอร์ และการแสดงผลเอกสาร
ความสามารถในการแก้ไขภาพขั้นสูง
นอกเหนือจากการแสดงผลข้อความแล้ว Qwen-Image ยังมีคุณสมบัติการแก้ไขภาพที่ซับซ้อน รองรับการทำงาน เช่น การถ่ายโอนสไตล์ การแทรกวัตถุ การปรับปรุงรายละเอียด และการจัดการท่าทางของมนุษย์ ตัวอย่างเช่น ผู้ใช้สามารถสั่งให้โมเดล “เพิ่มท้องฟ้าที่สดใสให้กับภาพนี้” หรือ “เปลี่ยนภาพวาดนี้ให้เป็นสไตล์ Van Gogh” และ Qwen-Image ก็จะให้ผลลัพธ์ที่สอดคล้องกัน กระบวนทัศน์การฝึกอบรมแบบหลายงานที่ได้รับการปรับปรุงทำให้มั่นใจว่าการแก้ไขจะรักษาสื่อความหมายและความสมจริงของภาพ
นอกจากนี้ ความสามารถของโมเดลในการแก้ไขข้อความภายในภาพนั้นน่าสนใจเป็นพิเศษ นักพัฒนาสามารถแก้ไขข้อความบนป้ายหรือโปสเตอร์ได้โดยไม่รบกวนบริบทภาพโดยรอบ ซึ่งเป็นคุณสมบัติที่มีคุณค่าสำหรับการโฆษณาและการสร้างเนื้อหา ความสามารถเหล่านี้ได้รับการสนับสนุนจากความเข้าใจภาพอย่างลึกซึ้งของ Qwen-Image ซึ่งช่วยให้สามารถตีความและจัดการองค์ประกอบภาพได้อย่างแม่นยำ
ความเข้าใจภาพที่ครอบคลุม
Qwen-Image ไม่เพียงแค่สร้างหรือแก้ไขเท่านั้น แต่ยังเข้าใจอีกด้วย โมเดลรองรับชุดงานความเข้าใจภาพ รวมถึงการตรวจจับวัตถุ, การแบ่งส่วนเชิงความหมาย (semantic segmentation), การประมาณความลึก, การตรวจจับขอบ (Canny), การสังเคราะห์มุมมองใหม่ และ super-resolution งานเหล่านี้ขับเคลื่อนด้วยความสามารถในการประมวลผลอินพุตความละเอียดสูงและดึงรายละเอียดที่ละเอียด ตัวอย่างเช่น Qwen-Image สามารถสร้างกล่องขอบเขตสำหรับวัตถุที่อธิบายด้วยภาษาธรรมชาติ เช่น “ตรวจจับสุนัขพันธุ์ฮัสกี้ในฉากรถไฟใต้ดิน” ทำให้เป็นเครื่องมือที่มีประสิทธิภาพสำหรับการวิเคราะห์ภาพ
นอกจากนี้ การรองรับหลายภาษาช่วยเพิ่มความสามารถในการใช้งานในแอปพลิเคชันระดับโลก ด้วยการผสานรวมกับเครื่องมือต่างๆ เช่น Qwen-Plus Prompt Enhancement Tool นักพัฒนาสามารถปรับปรุงพรอมต์เพื่อประสิทธิภาพหลายภาษาที่ดีขึ้น รับประกันผลลัพธ์ที่แม่นยำในบริบททางภาษาที่หลากหลาย
ความเป็นเลิศด้านประสิทธิภาพข้ามการวัดประสิทธิภาพ
Qwen-Image มีประสิทธิภาพเหนือกว่าคู่แข่งอย่างสม่ำเสมอในการวัดประสิทธิภาพสาธารณะหลายรายการ รวมถึง GenEval, DPG, OneIG-Bench, GEdit, ImgEdit และ GSO ประสิทธิภาพที่เหนือกว่าในการแสดงผลข้อความ โดยเฉพาะภาษาจีน ปรากฏชัดในการวัดประสิทธิภาพอย่าง TextCraft ซึ่งเหนือกว่าโมเดลล้ำสมัยที่มีอยู่ นอกจากนี้ ความสามารถในการสร้างภาพทั่วไปรองรับสไตล์ศิลปะที่หลากหลาย ตั้งแต่ฉากที่สมจริงไปจนถึงสุนทรียภาพแบบอนิเมะ ทำให้เป็นตัวเลือกที่หลากหลายสำหรับมืออาชีพด้านความคิดสร้างสรรค์
สถาปัตยกรรมทางเทคนิคของ Qwen-Image
Multimodal Diffusion Transformer (MMDiT)
โดยแก่นแท้แล้ว Qwen-Image ใช้สถาปัตยกรรม Multimodal Diffusion Transformer (MMDiT) ซึ่งรวมจุดแข็งของโมเดล diffusion และ transformer เข้าไว้ด้วยกัน แนวทางแบบไฮบริดนี้ช่วยให้โมเดลสามารถประมวลผลอินพุตทั้งภาพและข้อความได้อย่างมีประสิทธิภาพ กระบวนการ diffusion จะปรับปรุงอินพุตที่มีสัญญาณรบกวนให้เป็นภาพที่สอดคล้องกันซ้ำๆ ในขณะที่ส่วนประกอบ transformer จัดการความสัมพันธ์ที่ซับซ้อนระหว่างข้อความและองค์ประกอบภาพ
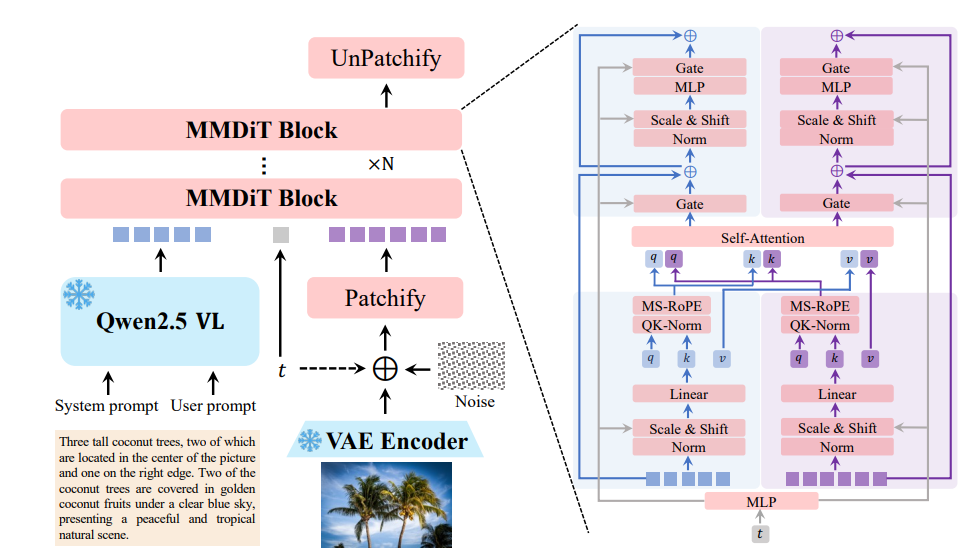
พารามิเตอร์ 20 พันล้านตัวของโมเดลได้รับการปรับให้เหมาะสมเพื่อประสิทธิภาพ ทำให้สามารถทำงานบนฮาร์ดแวร์ระดับผู้บริโภคได้ด้วย VRAM เพียง 4GB เมื่อใช้เทคนิคเช่น FP8 quantization และ layer-by-layer offloading การเข้าถึงนี้ทำให้ Qwen-Image เหมาะสำหรับทั้งนักพัฒนาระดับองค์กรและบุคคลทั่วไป
การฝึกฝนล่วงหน้าและการปรับแต่ง
ชุดข้อมูลการฝึกฝนล่วงหน้าของ Qwen-Image เป็นรากฐานสำคัญของประสิทธิภาพ ครอบคลุมโทเค็นกว่า 30 ล้านล้านรายการ ชุดข้อมูลประกอบด้วยข้อมูลเว็บ เอกสารคล้าย PDF และข้อมูลสังเคราะห์ที่สร้างโดยโมเดลอย่าง Qwen2.5-VL และ Qwen2.5-Coder กระบวนการฝึกฝนล่วงหน้าแบ่งออกเป็นสามขั้นตอน:

- ขั้นตอนที่ 1 (S1): โมเดลได้รับการฝึกฝนล่วงหน้าด้วยโทเค็น 30 ล้านล้านรายการ โดยมีความยาวบริบท 4K โทเค็น เพื่อสร้างทักษะพื้นฐานด้านภาษาและภาพ
- ขั้นตอนที่ 2: การเรียนรู้แบบเสริมกำลังช่วยเพิ่มความสามารถในการให้เหตุผลและความสามารถเฉพาะงานของโมเดล
- ขั้นตอนที่ 3: การปรับแต่งด้วยชุดข้อมูลที่คัดสรรแล้วช่วยปรับปรุงความสอดคล้องกับความต้องการของผู้ใช้และงานเฉพาะ เช่น การแสดงผลข้อความและการแก้ไขภาพ
แนวทางหลายขั้นตอนนี้นับประกันว่า Qwen-Image มีความแข็งแกร่งและปรับตัวได้ สามารถจัดการงานที่หลากหลายได้อย่างแม่นยำสูง
การผสานรวมกับเครื่องมือสำหรับนักพัฒนา
Qwen-Image ผสานรวมได้อย่างราบรื่นกับเฟรมเวิร์กการพัฒนาที่ได้รับความนิยมอย่าง Diffusers และ DiffSynth-Studio ตัวอย่างเช่น นักพัฒนาสามารถใช้โค้ด Python ต่อไปนี้เพื่อสร้างภาพด้วย Qwen-Image:
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
prompt = "A coffee shop entrance with a chalkboard sign reading 'Qwen Coffee 😊 $2 per cup.'"
image = pipe(prompt).images[0]
image.save("qwen_coffee.png")
ส่วนของโค้ดนี้แสดงให้เห็นว่านักพัฒนาสามารถใช้ประโยชน์จากความสามารถของ Qwen-Image ได้อย่างไร เพื่อสร้างภาพคุณภาพสูงด้วยการตั้งค่าที่น้อยที่สุด เครื่องมืออย่าง Apidog ช่วยให้การผสานรวม API ง่ายขึ้นอีก ทำให้สามารถสร้างต้นแบบและปรับใช้ได้อย่างรวดเร็ว
การประยุกต์ใช้งานจริงของ Qwen-Image
การสร้างเนื้อหาเชิงสร้างสรรค์
ความสามารถของ Qwen-Image ในการสร้างฉากที่สมจริง ภาพวาดสไตล์อิมเพรสชันนิสต์ และภาพสไตล์อนิเมะ ทำให้เป็นเครื่องมือที่มีประสิทธิภาพสำหรับศิลปินและนักออกแบบ ตัวอย่างเช่น นักออกแบบกราฟิกสามารถสร้างโปสเตอร์ภาพยนตร์ที่มีการจัดวางข้อความที่น่าสนใจและภาพที่สดใส ดังที่แสดงให้เห็นในกรณีทดสอบที่ Qwen-Image สร้างโปสเตอร์สำหรับ “Imagination Unleashed” โดยมีคอมพิวเตอร์แห่งอนาคตปล่อยสิ่งมีชีวิตแปลกๆ ออกมา

การโฆษณาและการตลาด
ในการโฆษณา ความสามารถในการแสดงผลข้อความและการแก้ไขของ Qwen-Image ช่วยให้สามารถสร้างแคมเปญที่ดึงดูดสายตาได้ นักการตลาดสามารถสร้างโปสเตอร์ที่มีการจัดวางข้อความที่แม่นยำ หรือแก้ไขภาพที่มีอยู่เพื่ออัปเดตข้อความส่งเสริมการขาย รับประกันความสอดคล้องของแบรนด์และความกลมกลืนทางภาพ

การวิเคราะห์ภาพและระบบอัตโนมัติ
สำหรับอุตสาหกรรมต่างๆ เช่น อีคอมเมิร์ซและระบบอัตโนมัติ งานความเข้าใจภาพของ Qwen-Image เช่น การตรวจจับวัตถุและการแบ่งส่วนเชิงความหมาย (semantic segmentation) มอบมูลค่าที่สำคัญ แพลตฟอร์มค้าปลีกสามารถใช้โมเดลเพื่อแท็กผลิตภัณฑ์ในภาพโดยอัตโนมัติ ในขณะที่ยานพาหนะอัตโนมัติสามารถใช้การประมาณความลึกเพื่อการนำทาง
เครื่องมือทางการศึกษา
ความสามารถของ Qwen-Image ในการสร้างภาพประกอบการศึกษา เช่น แผนภาพที่มีคำอธิบายประกอบข้อความที่แม่นยำ รองรับแพลตฟอร์มอีเลิร์นนิง ตัวอย่างเช่น สามารถสร้างภาพประกอบโดยละเอียดของแนวคิดทางวิทยาศาสตร์พร้อมส่วนประกอบที่มีป้ายกำกับ ช่วยเพิ่มการมีส่วนร่วมและความเข้าใจของนักเรียน

การเปรียบเทียบ Qwen-Image กับคู่แข่ง
เมื่อเปรียบเทียบกับโมเดลอย่าง DALL-E 3 และ Stable Diffusion, Qwen-Image โดดเด่นด้วยการแสดงผลข้อความหลายภาษาและความสามารถในการแก้ไขขั้นสูง ในขณะที่ DALL-E 3 มีความเป็นเลิศในการสร้างภาพเชิงสร้างสรรค์ แต่ก็ประสบปัญหาในการจัดวางข้อความที่ซับซ้อน โดยเฉพาะอย่างยิ่งสำหรับสคริปต์ที่ใช้สัญลักษณ์ Stable Diffusion แม้จะมีความหลากหลาย แต่ก็ขาดความเข้าใจภาพอย่างลึกซึ้งที่นำเสนอโดยชุดงานความเข้าใจของ Qwen-Image
นอกจากนี้ ลักษณะโอเพนซอร์สและความเข้ากันได้กับฮาร์ดแวร์ที่มีหน่วยความจำน้อยของ Qwen-Image ทำให้ได้เปรียบสำหรับนักพัฒนาที่มีทรัพยากรจำกัด ประสิทธิภาพในการวัดประสิทธิภาพอย่าง TextCraft และ GEdit ยิ่งเสริมความแข็งแกร่งให้กับตำแหน่งในฐานะโมเดลชั้นนำใน AI แบบหลายโมดอล
ความท้าทายและข้อจำกัด
แม้จะมีจุดแข็ง แต่ Qwen-Image ก็ยังเผชิญกับความท้าทาย การพึ่งพาชุดข้อมูลขนาดใหญ่ทำให้เกิดความกังวลเกี่ยวกับความเป็นส่วนตัวของข้อมูลและการจัดหาข้อมูลอย่างมีจริยธรรม แม้ว่า Alibaba Cloud จะปฏิบัติตามแนวทางที่เข้มงวดก็ตาม นอกจากนี้ ในขณะที่โมเดลรองรับกว่า 100 ภาษา ประสิทธิภาพอาจแตกต่างกันไปสำหรับภาษาถิ่นที่มีการนำเสนอน้อยกว่า ซึ่งต้องมีการปรับแต่งเพิ่มเติม
ยิ่งไปกว่านั้น ความต้องการในการประมวลผลของโมเดลพารามิเตอร์ 20B อาจมีนัยสำคัญหากไม่มีเทคนิคการเพิ่มประสิทธิภาพเช่น FP8 quantization นักพัฒนาต้องรักษาสมดุลระหว่างประสิทธิภาพและข้อจำกัดของทรัพยากรเมื่อปรับใช้ Qwen-Image ในสภาพแวดล้อมการผลิต
แนวโน้มในอนาคตของ Qwen-Image
ในอนาคต Qwen-Image พร้อมที่จะพัฒนาต่อไป ทีม Qwen วางแผนที่จะเปิดตัวโมเดลเวอร์ชันที่เน้นการแก้ไขโดยเฉพาะ เพิ่มความสามารถสำหรับแอปพลิเคชันระดับมืออาชีพ การผสานรวมกับเฟรมเวิร์กที่กำลังเกิดขึ้นอย่าง vLLM และการสนับสนุน LoRA และเวิร์กโฟลว์การปรับแต่งอย่างต่อเนื่องจะช่วยขยายการเข้าถึง
ยิ่งไปกว่านั้น ความก้าวหน้าในการเรียนรู้แบบเสริมกำลัง ดังที่เห็นในโมเดลอย่าง Qwen3 ชี้ให้เห็นว่า Qwen-Image สามารถรวมความสามารถในการให้เหตุผลที่ลึกซึ้งยิ่งขึ้นได้ ทำให้สามารถทำงานการให้เหตุผลทางภาพที่ซับซับซ้อนมากขึ้นได้ ในขณะที่ชุมชน AI ยังคงมีส่วนร่วมในการพัฒนา Qwen-Image มีศักยภาพที่จะกำหนดนิยามใหม่ของการสร้างสรรค์และความเข้าใจภาพ
เริ่มต้นใช้งาน Qwen-Image
ในการเริ่มต้นใช้งาน Qwen-Image นักพัฒนาสามารถเข้าถึงน้ำหนักโมเดลได้ที่ GitHub หรือ Hugging Face บล็อกอย่างเป็นทางการที่ qwenlm.github.io มีคำแนะนำการตั้งค่าโดยละเอียดและกรณีการใช้งาน สำหรับประสบการณ์จริง โปรดเยี่ยมชม Qwen Chat และเลือก “Image Generation” เพื่อทดสอบความสามารถของโมเดล
สำหรับการผสานรวม API เครื่องมืออย่าง Apidog ช่วยให้กระบวนการง่ายขึ้นด้วยการนำเสนออินเทอร์เฟซที่ใช้งานง่ายเพื่อทดสอบและปรับใช้คุณสมบัติของ Qwen-Image ดาวน์โหลด Apidog ฟรีเพื่อปรับปรุงเวิร์กโฟลว์การพัฒนาของคุณ
สรุป: เหตุใด Qwen-Image จึงมีความสำคัญ
Qwen-Image แสดงถึงความก้าวหน้าครั้งสำคัญใน AI แบบหลายโมดอล โดยรวมการแสดงผลข้อความขั้นสูง การแก้ไขภาพที่แม่นยำ และความเข้าใจภาพที่แข็งแกร่งเข้าไว้ด้วยกัน การเป็นโอเพนซอร์ส การฝึกฝนล่วงหน้าที่ครอบคลุม และความเข้ากันได้กับเครื่องมือสำหรับนักพัฒนา ทำให้เป็นตัวเลือกที่หลากหลายสำหรับนักสร้างสรรค์ นักพัฒนา และนักวิจัย ด้วยการจัดการกับความท้าทายต่างๆ เช่น การรองรับหลายภาษาและประสิทธิภาพของทรัพยากร Qwen-Image จึงกำหนดมาตรฐานใหม่สำหรับการสร้างสรรค์ภาพด้วย AI
ในขณะที่ AI ยังคงพัฒนาอย่างต่อเนื่อง โมเดลอย่าง Qwen-Image จะมีบทบาทสำคัญในการเชื่อมช่องว่างระหว่างภาษาและภาพ ปลดล็อกความเป็นไปได้ใหม่ๆ สำหรับแอปพลิเคชันเชิงสร้างสรรค์และการวิเคราะห์ ไม่ว่าคุณจะสร้างแคมเปญการตลาด วิเคราะห์ข้อมูลภาพ หรือสร้างเนื้อหาทางการศึกษา Qwen-Image มีเครื่องมือที่จะทำให้วิสัยทัศน์ของคุณเป็นจริง