
วงการปัญญาประดิษฐ์ยังคงพัฒนาอย่างรวดเร็วอย่างต่อเนื่อง นำมาซึ่งโมเดลใหม่ๆ ที่สร้างสรรค์และกำหนดขอบเขตการคำนวณขึ้นใหม่ ในบรรดาความก้าวหน้าเหล่านี้ MiniMax-M1 โดดเด่นในฐานะการพัฒนาที่ก้าวล้ำ โดยได้รับการยอมรับว่าเป็นโมเดลการให้เหตุผลแบบไฮบริด-แอตเทนชันขนาดใหญ่แบบโอเพนเวทตัวแรกของโลก พัฒนาโดย MiniMax โมเดลนี้สัญญาว่าจะเปลี่ยนวิธีการที่เราเข้าถึงงานให้เหตุผลที่ซับซ้อน โดยนำเสนอหน้าต่างบริบท (context window) ที่น่าประทับใจ รองรับอินพุตได้ 1 ล้านโทเค็น และเอาต์พุตได้ 80,000 โทเค็น
ทำความเข้าใจสถาปัตยกรรมหลักของ MiniMax-M1
MiniMax-M1 โดดเด่นด้วยสถาปัตยกรรม Mixture-of-Experts (MoE) แบบไฮบริดที่ไม่เหมือนใคร ผสมผสานกับกลไกความสนใจ (attention mechanism) ที่รวดเร็วอย่างยิ่ง การออกแบบนี้สร้างขึ้นบนรากฐานที่วางไว้โดยรุ่นก่อนหน้า MiniMax-Text-01 ซึ่งมีพารามิเตอร์จำนวนมหาศาลถึง 456 พันล้านพารามิเตอร์ โดยมีการเปิดใช้งาน 45.9 พันล้านพารามิเตอร์ต่อโทเค็น แนวทาง MoE ช่วยให้โมเดลเปิดใช้งานเพียงส่วนย่อยของพารามิเตอร์ตามอินพุต ซึ่งช่วยเพิ่มประสิทธิภาพการคำนวณและรองรับความสามารถในการปรับขนาด ขณะเดียวกัน กลไกไฮบริด-แอตเทนชันช่วยเพิ่มความสามารถของโมเดลในการประมวลผลข้อมูลบริบทขนาดยาว ทำให้เหมาะสำหรับงานที่ต้องการความเข้าใจอย่างลึกซึ้งในลำดับที่ยาว

การผสานรวมส่วนประกอบเหล่านี้ส่งผลให้ได้โมเดลที่สร้างสมดุลระหว่างประสิทธิภาพและการใช้ทรัพยากรได้อย่างมีประสิทธิภาพ ด้วยการเลือกใช้ผู้เชี่ยวชาญ (experts) ภายในเฟรมเวิร์ก MoE ทำให้ MiniMax-M1 ลดภาระการคำนวณที่มักเกี่ยวข้องกับโมเดลขนาดใหญ่ นอกจากนี้ กลไก lightning attention ยังช่วยเร่งการประมวลผลน้ำหนักความสนใจ (attention weights) ทำให้มั่นใจได้ว่าโมเดลจะยังคงมีปริมาณงานสูงแม้จะมีหน้าต่างบริบทที่กว้างขวาง
ประสิทธิภาพการฝึกฝน: บทบาทของการเรียนรู้แบบเสริมกำลัง (Reinforcement Learning)
หนึ่งในแง่มุมที่น่าทึ่งที่สุดของ MiniMax-M1 คือกระบวนการฝึกฝน ซึ่งใช้ประโยชน์จากการเรียนรู้แบบเสริมกำลัง (Reinforcement Learning หรือ RL) ขนาดใหญ่ด้วยประสิทธิภาพที่ไม่เคยมีมาก่อน โมเดลได้รับการฝึกฝนด้วยต้นทุนเพียง 534,700 ดอลลาร์สหรัฐ ซึ่งเป็นตัวเลขที่เน้นย้ำถึงเฟรมเวิร์กการปรับขนาด RL ที่สร้างสรรค์ซึ่งพัฒนาโดย MiniMax เฟรมเวิร์กนี้นำเสนอ CISPO (Clipped Importance Sampling with Policy Optimization) ซึ่งเป็นอัลกอริทึมใหม่ที่ตัดน้ำหนักความสำคัญของการสุ่มตัวอย่าง (importance sampling weights) แทนที่จะอัปเดตโทเค็น แนวทางนี้มีประสิทธิภาพเหนือกว่า RL รูปแบบดั้งเดิม ทำให้กระบวนการฝึกฝนมีความเสถียรและมีประสิทธิภาพมากขึ้น

นอกจากนี้ การออกแบบไฮบริด-แอตเทนชันยังมีบทบาทสำคัญในการเพิ่มประสิทธิภาพ RL ด้วยการจัดการกับความท้าทายเฉพาะที่เกี่ยวข้องกับการปรับขนาด RL ภายในสถาปัตยกรรมไฮบริด MiniMax-M1 สามารถบรรลุระดับประสิทธิภาพที่เทียบเท่ากับโมเดลแบบปิด (closed-weight models) แม้จะเป็นโอเพนซอร์สก็ตาม วิธีการฝึกฝนนี้ไม่เพียงแต่ลดต้นทุน แต่ยังสร้างมาตรฐานใหม่สำหรับการพัฒนาโมเดล AI ประสิทธิภาพสูงด้วยทรัพยากรที่จำกัด
ตัวชี้วัดประสิทธิภาพ: การเปรียบเทียบประสิทธิภาพของ MiniMax-M1
เพื่อประเมินความสามารถของ MiniMax-M1 นักพัฒนาได้ทำการเปรียบเทียบประสิทธิภาพอย่างครอบคลุมในหลากหลายงาน รวมถึงคณิตศาสตร์ระดับการแข่งขัน การเขียนโค้ด วิศวกรรมซอฟต์แวร์ การใช้เครื่องมือแบบ Agentic และความเข้าใจบริบทขนาดยาว ผลลัพธ์เน้นย้ำถึงความเหนือกว่าของโมเดลเมื่อเทียบกับโมเดลโอเพนเวทอื่นๆ เช่น DeepSeek-R1 และ Qwen3-235B-A22B
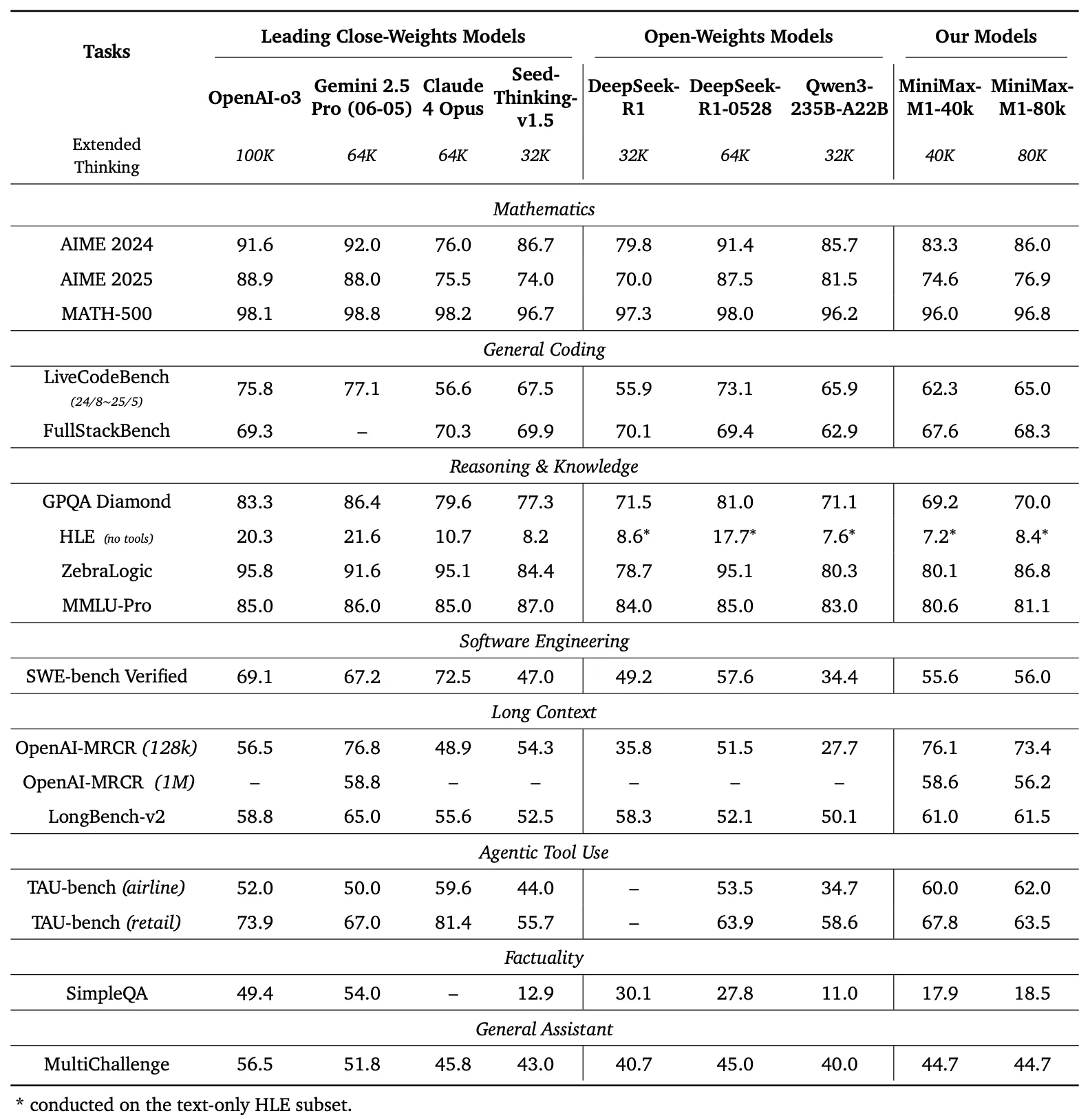
การเปรียบเทียบประสิทธิภาพ
แผงด้านซ้ายของรูปที่ 1 เปรียบเทียบประสิทธิภาพของ MiniMax-M1 กับโมเดลเชิงพาณิชย์และโมเดลโอเพนเวทชั้นนำในหลายๆ เกณฑ์มาตรฐาน

- AIME 2024: MiniMax-M1 มีความแม่นยำ 86.0% เหนือกว่า OpenAI o3 (88.0%) และ Claude 4 Opus (80.0%) แสดงให้เห็นถึงความสามารถในการให้เหตุผลทางคณิตศาสตร์
- LiveCodeBench: ด้วยคะแนน 65.0% MiniMax-M1 มีประสิทธิภาพเหนือกว่า DeepSeek-R1-0528 (56.0%) และเทียบเท่ากับ Seed-Thinking v1.5 (65.0%) ซึ่งบ่งชี้ถึงความสามารถในการเขียนโค้ดที่แข็งแกร่ง
- SW-E Bench Verified: โมเดลทำคะแนนได้ 62.8% เหนือกว่า Qwen3-235B-A22B (60.0%) ในงานด้านวิศวกรรมซอฟต์แวร์
- TAU-bench: MiniMax-M1 มีความแม่นยำ 73.4% เหนือกว่า Gemini 2.5 Pro (70.0%) ในการใช้เครื่องมือแบบ Agentic
- MRCR (4-needle): ด้วยความแม่นยำ 74.4% โมเดลนี้เป็นผู้นำเหนือโมเดลอื่นๆ ในงานความเข้าใจบริบทขนาดยาว
ผลลัพธ์เหล่านี้เน้นย้ำถึงความหลากหลายของ MiniMax-M1 และความสามารถในการแข่งขันกับโมเดลที่เป็นกรรมสิทธิ์ ทำให้เป็นทรัพย์สินที่มีค่าสำหรับชุมชนโอเพนซอร์ส

MiniMax-M1 แสดงให้เห็นถึงการเพิ่มขึ้นเชิงเส้นของ FLOPs (Floating Point Operations) เมื่อความยาวของการสร้าง (generation length) ขยายจาก 32k เป็น 128k โทเค็น ความสามารถในการปรับขนาดนี้ทำให้มั่นใจได้ว่าโมเดลยังคงมีประสิทธิภาพแม้จะมีการสร้างเอาต์พุตที่ยาวขึ้น ซึ่งเป็นปัจจัยสำคัญสำหรับแอปพลิเคชันที่ต้องการการตอบสนองที่มีรายละเอียดและยาว
การให้เหตุผลในบริบทขนาดยาว: พรมแดนใหม่
คุณสมบัติที่โดดเด่นที่สุดของ MiniMax-M1 คือหน้าต่างบริบทที่ยาวเป็นพิเศษ รองรับอินพุตได้สูงสุด 1 ล้านโทเค็น และเอาต์พุต 80,000 โทเค็น ความสามารถนี้ช่วยให้โมเดลสามารถประมวลผลข้อมูลปริมาณมหาศาล ซึ่งเทียบเท่ากับนวนิยายทั้งเล่มหรือหนังสือหลายเล่ม ในรอบเดียว ซึ่งเกินขีดจำกัด 128,000 โทเค็นของโมเดลอย่าง GPT-4 ของ OpenAI อย่างมาก โมเดลมีโหมดการอนุมาน (inference modes) สองแบบ คือ งบประมาณความคิด (thought budgets) 40k และ 80k เพื่อรองรับความต้องการในสถานการณ์ที่หลากหลายและช่วยให้สามารถปรับใช้ได้อย่างยืดหยุ่น

หน้าต่างบริบทที่ขยายออกนี้ช่วยเพิ่มประสิทธิภาพของโมเดลในงานบริบทขนาดยาว เช่น การสรุปเอกสารขนาดยาว การสนทนาแบบหลายรอบ หรือการวิเคราะห์ชุดข้อมูลที่ซับซ้อน ด้วยการเก็บรักษาข้อมูลบริบทไว้ตลอดหลายล้านโทเค็น MiniMax-M1 จึงเป็นรากฐานที่แข็งแกร่งสำหรับแอปพลิเคชันในการวิจัย การวิเคราะห์ทางกฎหมาย และการสร้างเนื้อหา ซึ่งการรักษาความเชื่อมโยงตลอดลำดับที่ยาวเป็นสิ่งสำคัญยิ่ง
การใช้เครื่องมือแบบ Agentic และแอปพลิเคชันเชิงปฏิบัติ
นอกเหนือจากหน้าต่างบริบทที่น่าประทับใจแล้ว MiniMax-M1 ยังมีความโดดเด่นในการใช้เครื่องมือแบบ Agentic ซึ่งเป็นโดเมนที่โมเดล AI โต้ตอบกับเครื่องมือภายนอกเพื่อแก้ปัญหา ความสามารถของโมเดลในการผสานรวมกับแพลตฟอร์มอย่าง MiniMax Chat และสร้างเว็บแอปพลิเคชันที่ใช้งานได้จริง เช่น การทดสอบความเร็วในการพิมพ์ และตัวสร้างเขาวงกต แสดงให้เห็นถึงประโยชน์ในทางปฏิบัติ แอปพลิเคชันเหล่านี้สร้างขึ้นโดยมีการตั้งค่าน้อยที่สุดและไม่มีปลั๊กอิน แสดงให้เห็นถึงศักยภาพของโมเดลในการสร้างโค้ดพร้อมใช้งานสำหรับการผลิต

ตัวอย่างเช่น โมเดลสามารถสร้างเว็บแอปที่สะอาดและใช้งานได้จริงเพื่อติดตามคำต่อนาที (WPM) แบบเรียลไทม์ หรือสร้างตัวสร้างเขาวงกตที่สวยงามพร้อมการแสดงภาพอัลกอริทึม A* ความสามารถดังกล่าวทำให้ MiniMax-M1 เป็นเครื่องมือที่มีประสิทธิภาพสำหรับนักพัฒนาที่ต้องการทำให้ขั้นตอนการพัฒนาซอฟต์แวร์เป็นไปโดยอัตโนมัติ หรือสร้างประสบการณ์ผู้ใช้แบบโต้ตอบ
การเข้าถึงแบบโอเพนซอร์สและผลกระทบต่อชุมชน
การเปิดตัว MiniMax-M1 ภายใต้ใบอนุญาต Apache 2.0 ถือเป็นก้าวสำคัญสำหรับชุมชนโอเพนซอร์ส โมเดลนี้พร้อมใช้งานบน GitHub และ Hugging Face เชิญชวนนักพัฒนา นักวิจัย และธุรกิจต่างๆ ให้สำรวจ ปรับปรุง และนำไปใช้โดยไม่มีข้อจำกัดที่เป็นกรรมสิทธิ์ ความเปิดกว้างนี้ส่งเสริมการสร้างสรรค์นวัตกรรม ทำให้สามารถสร้างโซลูชันที่ปรับแต่งให้เข้ากับความต้องการเฉพาะได้
การเข้าถึงโมเดลยังช่วยให้เทคโนโลยี AI ขั้นสูงเข้าถึงได้ง่ายขึ้น ทำให้องค์กรขนาดเล็กและนักพัฒนาอิสระสามารถแข่งขันกับหน่วยงานขนาดใหญ่ได้ ด้วยการจัดทำเอกสารรายละเอียดและรายงานทางเทคนิค MiniMax ทำให้มั่นใจว่าผู้ใช้สามารถจำลองและขยายความสามารถของโมเดลได้ ซึ่งจะช่วยเร่งความก้าวหน้าในระบบนิเวศ AI ให้เร็วขึ้น
การนำไปใช้ทางเทคนิค: การติดตั้งใช้งานและการเพิ่มประสิทธิภาพ
การติดตั้งใช้งาน MiniMax-M1 ต้องพิจารณาอย่างรอบคอบเกี่ยวกับทรัพยากรการคำนวณและเทคนิคการเพิ่มประสิทธิภาพ รายงานทางเทคนิคแนะนำให้ใช้ vLLM (Virtual Large Language Model) สำหรับการติดตั้งใช้งานในระดับการผลิต ซึ่งช่วยเพิ่มประสิทธิภาพความเร็วในการอนุมานและการใช้หน่วยความจำ เครื่องมือนี้ใช้ประโยชน์จากสถาปัตยกรรมไฮบริดของโมเดลเพื่อกระจายภาระการคำนวณอย่างมีประสิทธิภาพ ทำให้มั่นใจได้ถึงการทำงานที่ราบรื่นแม้จะมีอินพุตขนาดใหญ่
นักพัฒนาสามารถปรับแต่ง MiniMax-M1 สำหรับงานเฉพาะได้โดยการปรับงบประมาณความคิด (40k หรือ 80k) ตามความต้องการ นอกจากนี้ เฟรมเวิร์กการฝึกฝน RL ที่มีประสิทธิภาพของโมเดลยังช่วยให้สามารถปรับแต่งเพิ่มเติมผ่านการเรียนรู้แบบเสริมกำลัง ทำให้สามารถปรับใช้กับแอปพลิเคชันเฉพาะกลุ่ม เช่น การแปลแบบเรียลไทม์ หรือการสนับสนุนลูกค้าอัตโนมัติ
บทสรุป: เปิดรับการปฏิวัติ MiniMax-M1
MiniMax-M1 แสดงถึงความก้าวหน้าครั้งสำคัญในวงการโมเดลการให้เหตุผลแบบไฮบริด-แอตเทนชันขนาดใหญ่แบบโอเพนเวท หน้าต่างบริบทที่น่าประทับใจ กระบวนการฝึกฝนที่มีประสิทธิภาพ และประสิทธิภาพเกณฑ์มาตรฐานที่เหนือกว่า ทำให้โมเดลนี้เป็นผู้นำในภูมิทัศน์ AI ด้วยการนำเสนอเทคโนโลยีนี้เป็นทรัพยากรโอเพนซอร์ส MiniMax ช่วยให้นักพัฒนาและนักวิจัยสามารถสำรวจความเป็นไปได้ใหม่ๆ ตั้งแต่วิศวกรรมซอฟต์แวร์ขั้นสูงไปจนถึงการวิเคราะห์บริบทขนาดยาว
ในขณะที่ชุมชน AI ยังคงเติบโต MiniMax-M1 เป็นเครื่องพิสูจน์ถึงพลังแห่งนวัตกรรมและความร่วมมือ สำหรับผู้ที่พร้อมจะสำรวจศักยภาพของมัน การดาวน์โหลด Apidog ฟรีเป็นจุดเริ่มต้นที่ใช้งานได้จริงเพื่อทดลองใช้โมเดลที่เปลี่ยนแปลงนี้ การเดินทางกับ MiniMax-M1 เพิ่งเริ่มต้นขึ้น และผลกระทบของมันจะกำหนดอนาคตของปัญญาประดิษฐ์อย่างไม่ต้องสงสัย
