
วิศวกรของ Mistral AI ได้ออกแบบ Magistral Small 1.2 ให้เป็นโมเดลขนาด 24 พันล้านพารามิเตอร์ที่ให้ความสำคัญกับประสิทธิภาพการให้เหตุผล เวอร์ชันนี้สร้างขึ้นโดยตรงบน Mistral Small 1.1 วิศวกรได้ใช้การปรับแต่งแบบละเอียดภายใต้การควบคุม (supervised fine-tuning) โดยใช้ร่องรอยจาก Magistral Medium ตามด้วยขั้นตอนการเรียนรู้แบบเสริมแรง (reinforcement learning) ส่งผลให้โมเดลมีความสามารถโดดเด่นในด้านตรรกะหลายขั้นตอนโดยไม่ต้องการทรัพยากรการประมวลผลที่มากเกินไป
ทำความเข้าใจวิวัฒนาการของตระกูลโมเดล Magistral
รากฐานสถาปัตยกรรมและข้อมูลจำเพาะทางเทคนิค
Magistral Small 1.2 สร้างขึ้นบนรากฐานที่แข็งแกร่งของ Magistral 1.1 โดยรวมความสามารถในการให้เหตุผลขั้นสูงผ่านการปรับแต่งแบบละเอียดภายใต้การควบคุม (SFT) จากร่องรอยของ Magistral Medium ผสมผสานกับการเพิ่มประสิทธิภาพการเรียนรู้แบบเสริมแรง (RL) สร้างขึ้นบน Magistral 1.1 พร้อมความสามารถในการให้เหตุผลที่เพิ่มขึ้น ผ่าน SFT จากร่องรอยของ Magistral Medium และ RL เพิ่มเติม ทำให้เป็นโมเดลการให้เหตุผลขนาดเล็กที่มีประสิทธิภาพพร้อมพารามิเตอร์ 24 พันล้านตัว

นอกจากนี้ การออกแบบสถาปัตยกรรมยังช่วยให้สถานการณ์การปรับใช้มีประสิทธิภาพ Magistral Small สามารถปรับใช้ในเครื่องได้ โดยสามารถทำงานได้บน RTX 4090 เพียงเครื่องเดียว หรือ MacBook ที่มี RAM 32GB เมื่อทำการ Quantize แล้ว การเข้าถึงนี้ทำให้โมเดลเหมาะสำหรับทั้งสภาพแวดล้อมองค์กรและนักพัฒนาแต่ละคน
การปรับปรุงทางเทคนิคที่สำคัญในเวอร์ชัน 1.2
การเปลี่ยนจากเวอร์ชัน 1.1 ไปยัง 1.2 ได้นำมาซึ่งการปรับปรุงที่สำคัญหลายประการที่ส่งผลกระทบอย่างมีนัยสำคัญต่อประสิทธิภาพและการใช้งานของโมเดล โดยเฉพาะอย่างยิ่ง การอัปเดตเหล่านี้ได้แก้ไขข้อจำกัดพื้นฐานในขณะที่ขยายขอบเขตความสามารถ
ความก้าวหน้าในการผสานรวมแบบ Multimodal
ปัจจุบันโมเดลเหล่านี้มาพร้อมกับตัวเข้ารหัสวิสัยทัศน์ (vision encoder) ทำให้สามารถจัดการทั้งข้อความและรูปภาพได้อย่างราบรื่น การผสานรวมนี้แสดงถึงการเปลี่ยนแปลงกระบวนทัศน์จากการให้เหตุผลที่ใช้ข้อความเป็นหลักไปสู่ความเข้าใจแบบ Multimodal ที่ครอบคลุม สถาปัตยกรรมตัวเข้ารหัสวิสัยทัศน์ช่วยให้โมเดลสามารถประมวลผลข้อมูลภาพในขณะที่ยังคงความสามารถในการให้เหตุผลด้วยข้อความ
ผลลัพธ์การเพิ่มประสิทธิภาพ
ปรับปรุง 15% ในเกณฑ์มาตรฐานทางคณิตศาสตร์และการเขียนโค้ด เช่น AIME 24/25 และ LiveCodeBench v5/v6 ประสิทธิภาพที่เพิ่มขึ้นเหล่านี้ส่งผลโดยตรงต่อการใช้งานจริง โดยเฉพาะอย่างยิ่งเป็นประโยชน์ต่อนักพัฒนาที่ทำงานเกี่ยวกับการคำนวณทางคณิตศาสตร์ การพัฒนาอัลกอริทึม และสถานการณ์การแก้ปัญหาที่ซับซ้อน
การวิเคราะห์คุณสมบัติที่ครอบคลุม
ความสามารถในการให้เหตุผลขั้นสูง
สถาปัตยกรรมการให้เหตุผลได้รวมโทเค็นการคิดเฉพาะ (specialized thinking tokens) ที่จัดโครงสร้างกระบวนการให้เหตุผลภายในของโมเดล การใช้งานใช้โทเค็น [THINK] และ [/THINK] เพื่อห่อหุ้มเนื้อหาการให้เหตุผล สร้างความโปร่งใสในกระบวนการตัดสินใจของโมเดล ในขณะที่ป้องกันความสับสนในระหว่างการประมวลผลคำสั่ง
นอกจากนี้ ระบบการให้เหตุผลยังทำงานผ่านลูกโซ่การอนุมานเชิงตรรกะที่ยาวนานก่อนที่จะสร้างการตอบสนองขั้นสุดท้าย วิธีการนี้ช่วยให้โมเดลสามารถจัดการกับปัญหาที่ซับซ้อนซึ่งต้องใช้การวิเคราะห์หลายขั้นตอน การอนุพันธ์ทางคณิตศาสตร์ และการหักล้างเชิงตรรกะ
โครงสร้างพื้นฐานการสนับสนุนหลายภาษา
โมเดลแสดงให้เห็นถึงการสนับสนุนภาษาที่ครอบคลุมในตระกูลภาษาที่หลากหลาย ภาษาที่รองรับครอบคลุมภูมิภาคยุโรป เอเชีย ตะวันออกกลาง และเอเชียใต้ รวมถึงภาษาอังกฤษ ฝรั่งเศส เยอรมัน กรีก ฮินดี อินโดนีเซีย อิตาลี ญี่ปุ่น เกาหลี มาเลย์ เนปาล โปแลนด์ โปรตุเกส โรมาเนีย รัสเซีย เซอร์เบีย สเปน ตุรกี ยูเครน เวียดนาม อาหรับ เบงกาลี จีน และฟาร์ซี
นอกจากนี้ ความสามารถหลายภาษาที่กว้างขวางนี้ยังช่วยให้เข้าถึงได้ทั่วโลกและช่วยให้นักพัฒนาสามารถสร้างแอปพลิเคชันที่ให้บริการตลาดต่างประเทศโดยไม่จำเป็นต้องมีการใช้งานโมเดลแยกต่างหากสำหรับภาษาที่แตกต่างกัน
สถาปัตยกรรมประมวลผลภาพ
การผสานรวมตัวเข้ารหัสวิสัยทัศน์ช่วยให้สามารถวิเคราะห์และให้เหตุผลภาพที่ซับซ้อนได้ โมเดลจะประมวลผลเนื้อหาภาพและรวมเข้ากับข้อมูลข้อความเพื่อสร้างการตอบสนองที่ครอบคลุม ความสามารถนี้ขยายไปไกลกว่าการรู้จำภาพอย่างง่าย รวมถึงความเข้าใจตามบริบท การให้เหตุผลเชิงพื้นที่ และการแก้ปัญหาด้วยภาพ
เกณฑ์มาตรฐานประสิทธิภาพและการวิเคราะห์เชิงเปรียบเทียบ
ประสิทธิภาพการให้เหตุผลทางคณิตศาสตร์
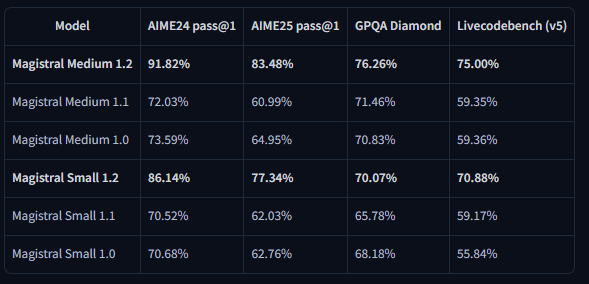
ผลลัพธ์เกณฑ์มาตรฐานแสดงให้เห็นถึงการปรับปรุงที่สำคัญในเมตริกการประเมินหลัก Magistral Small 1.2 บรรลุ 86.14% ใน AIME24 pass@1 และ 77.34% ใน AIME25 pass@1 ซึ่งแสดงถึงความก้าวหน้าที่สำคัญเหนือเวอร์ชัน 1.1 ที่ 70.52% และ 62.03% ตามลำดับ
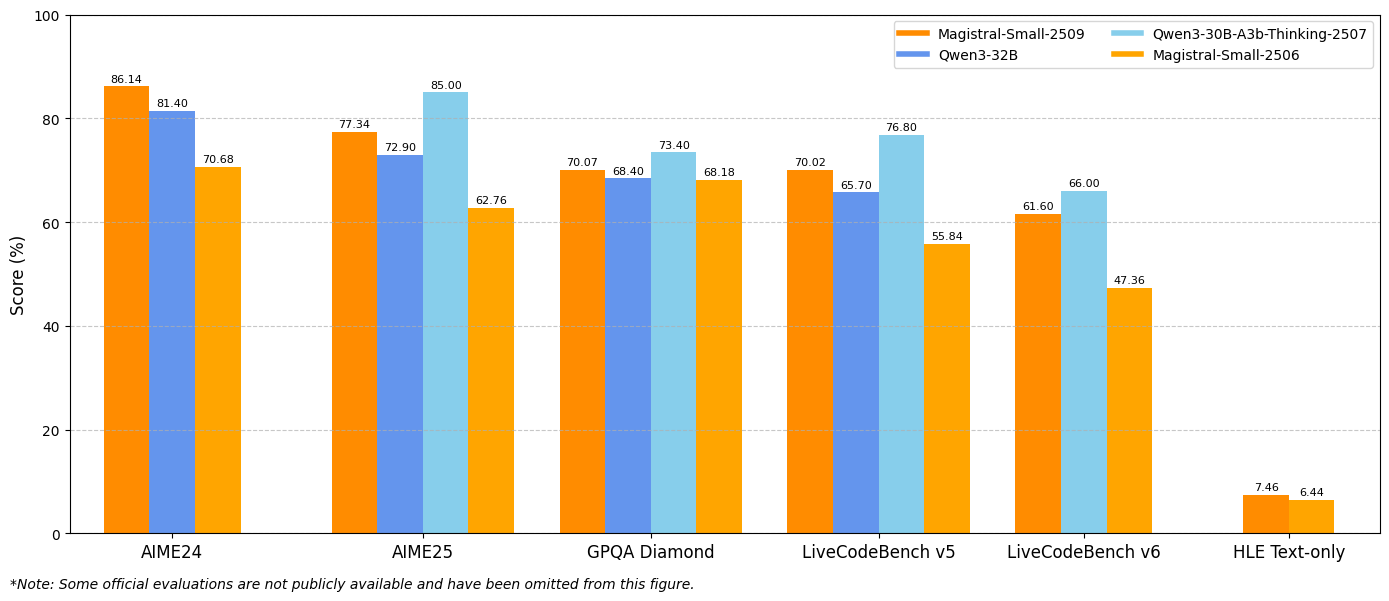
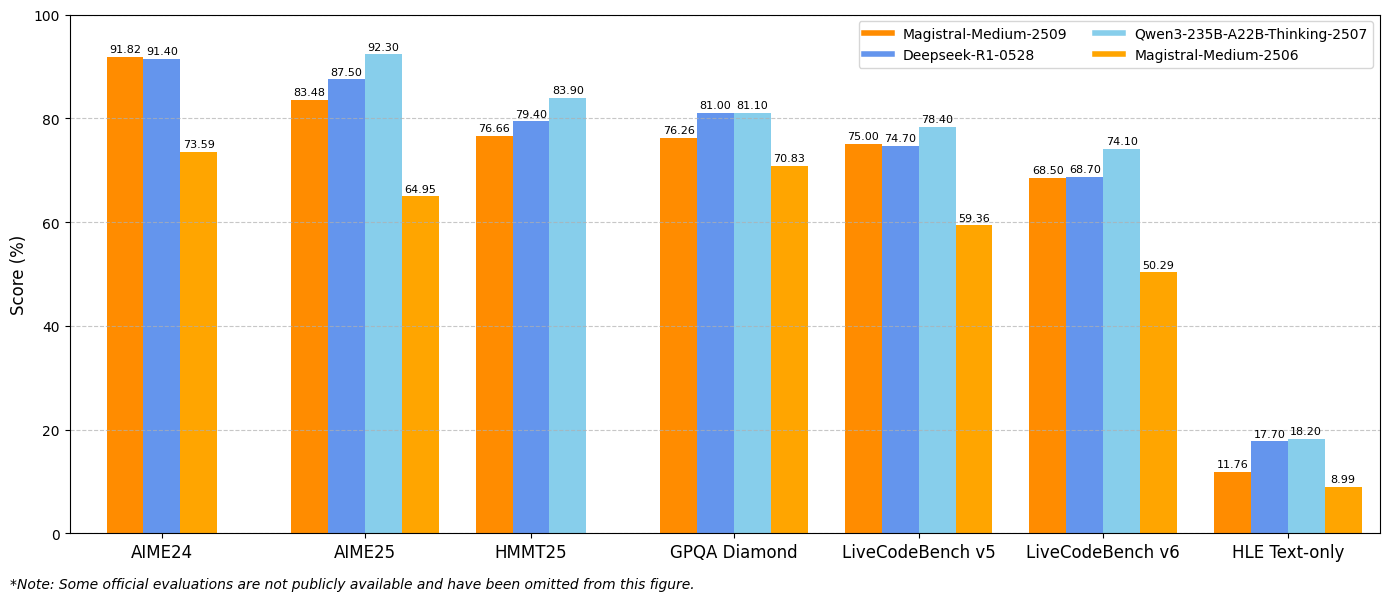
ในทำนองเดียวกัน Magistral Medium 1.2 ให้ประสิทธิภาพที่ยอดเยี่ยมด้วย 91.82% ใน AIME24 pass@1 และ 83.48% ใน AIME25 pass@1 ซึ่งสูงกว่าเวอร์ชัน 1.1 ที่ 72.03% และ 60.99% การปรับปรุงเหล่านี้บ่งชี้ถึงความสามารถในการให้เหตุผลทางคณิตศาสตร์ที่เพิ่มขึ้นซึ่งเป็นประโยชน์โดยตรงต่อการคำนวณทางวิทยาศาสตร์ แอปพลิเคชันทางวิศวกรรม และสภาพแวดล้อมการวิจัย
เมตริกประสิทธิภาพการเขียนโค้ด
การประเมิน LiveCodeBench เผยให้เห็นการปรับปรุงความสามารถในการเขียนโค้ดอย่างมีนัยสำคัญ Magistral Small 1.2 ได้คะแนน 70.88% ใน LiveCodeBench v5 ในขณะที่ Magistral Medium 1.2 ได้ 75.00% คะแนนเหล่านี้แสดงถึงความก้าวหน้าที่มีความหมายในการสร้างโค้ด การดีบัก และงานการใช้งานอัลกอริทึม
นอกจากนี้ โมเดลยังแสดงให้เห็นถึงความเข้าใจที่ดีขึ้นเกี่ยวกับแนวคิดการเขียนโปรแกรม รูปแบบสถาปัตยกรรมซอฟต์แวร์ และระเบียบวิธีดีบัก ประสิทธิภาพการเขียนโค้ดที่เพิ่มขึ้นนี้เป็นประโยชน์ต่อทีมพัฒนาซอฟต์แวร์ เฟรมเวิร์กการทดสอบอัตโนมัติ และสภาพแวดล้อมการเขียนโปรแกรมเพื่อการศึกษา
ผลลัพธ์ GPQA Diamond
ผลลัพธ์เกณฑ์มาตรฐาน General Purpose Question Answering (GPQA) Diamond แสดงให้เห็นถึงความสามารถในการประยุกต์ใช้ความรู้ที่กว้างขวางของโมเดล Magistral Small 1.2 บรรลุ 70.07% ในขณะที่ Magistral Medium 1.2 บรรลุ 76.26% คะแนนเหล่านี้สะท้อนถึงความสามารถของโมเดลในการจัดการกับคำถามประเภทต่างๆ ที่ต้องใช้ความรู้และการให้เหตุผลแบบสหวิทยาการ
กลยุทธ์การนำไปใช้งานและการผสานรวม
การกำหนดค่าสภาพแวดล้อมการพัฒนา
การนำ Magistral Small 1.2 และ Magistral Medium 1.2 ไปใช้งานต้องมีการกำหนดค่าทางเทคนิคเฉพาะเพื่อเพิ่มประสิทธิภาพ พารามิเตอร์การสุ่มตัวอย่างที่แนะนำ ได้แก่ top_p: 0.95, temperature: 0.7 และ max_tokens: 131072 การตั้งค่าเหล่านี้สร้างสมดุลระหว่างความคิดสร้างสรรค์และความสอดคล้องในขณะที่รองรับลำดับการให้เหตุผลที่ยาวนาน
นอกจากนี้ โมเดลยังรองรับเฟรมเวิร์กการปรับใช้ที่หลากหลาย รวมถึง vLLM, Transformers, llama.cpp และรูปแบบการ Quantization เฉพาะ ความยืดหยุ่นนี้ช่วยให้สามารถผสานรวมเข้ากับสภาพแวดล้อมการประมวลผลและกรณีการใช้งานที่แตกต่างกันได้
การผสานรวม API กับ Apidog
Apidog มีเครื่องมือที่ครอบคลุมสำหรับการทดสอบและผสานรวม Magistral APIs เข้ากับแอปพลิเคชันของคุณ แพลตฟอร์มนี้รองรับสถานการณ์การทดสอบ API ขั้นสูง รวมถึงการจัดการอินพุตแบบ Multimodal การวิเคราะห์ร่องรอยการให้เหตุผล และการตรวจสอบประสิทธิภาพ ผ่านอินเทอร์เฟซของ Apidog นักพัฒนาสามารถทดสอบการรวมกันของรูปภาพและข้อความ ตรวจสอบผลลัพธ์การให้เหตุผล และเพิ่มประสิทธิภาพพารามิเตอร์การเรียกใช้ API ได้อย่างมีประสิทธิภาพ
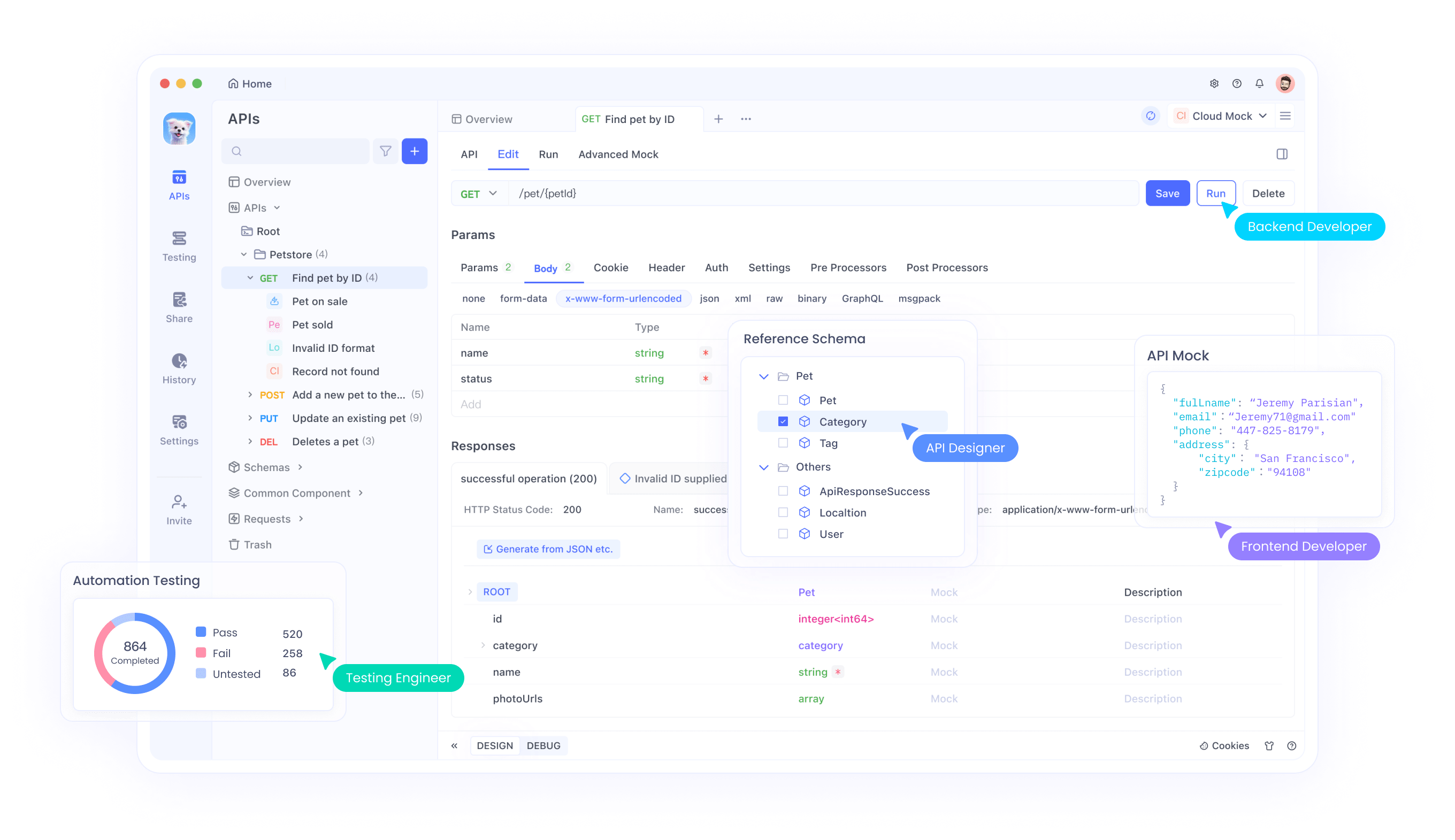
นอกจากนี้ คุณสมบัติการทำงานร่วมกันของ Apidog ยังช่วยให้ทีมสามารถแบ่งปันการกำหนดค่าการทดสอบ API จัดทำเอกสารรูปแบบการผสานรวม และรักษามาตรฐานการทดสอบที่สอดคล้องกันตลอดวงจรการพัฒนา วิธีการทำงานร่วมกันนี้ช่วยเร่งระยะเวลาการพัฒนาในขณะที่รับรองการใช้งาน API ที่แข็งแกร่ง
การเพิ่มประสิทธิภาพ System Prompt
โมเดลต้องการ system prompt ที่สร้างขึ้นอย่างพิถีพิถันเพื่อให้ได้ประสิทธิภาพสูงสุด โครงสร้าง system prompt ที่แนะนำประกอบด้วยคำแนะนำการให้เหตุผล แนวทางการจัดรูปแบบ และข้อมูลจำเพาะของภาษา prompt ควรขอให้กระบวนการคิดอย่างชัดเจนโดยใช้โทเค็นเฉพาะในขณะที่รักษาการจัดรูปแบบการตอบสนองที่สอดคล้องกัน
นอกจากนี้ การปรับแต่ง system prompt ยังช่วยให้สามารถเพิ่มประสิทธิภาพเฉพาะแอปพลิเคชันได้ นักพัฒนาสามารถปรับเปลี่ยน prompt เพื่อเน้นรูปแบบการให้เหตุผลเฉพาะ ปรับรูปแบบเอาต์พุต หรือรวมข้อกำหนดความรู้เฉพาะโดเมน
เจาะลึกการนำไปใช้งานทางเทคนิค
ข้อกำหนดด้านหน่วยความจำและการคำนวณ
Magistral Small 1.2 ทำงานได้อย่างมีประสิทธิภาพในสภาพแวดล้อมฮาร์ดแวร์ที่มีข้อจำกัดในขณะที่ยังคงประสิทธิภาพสูง สถาปัตยกรรมพารามิเตอร์ 24 พันล้านตัวช่วยให้สามารถปรับใช้บนฮาร์ดแวร์ระดับผู้บริโภคเมื่อทำการ Quantize อย่างเหมาะสม ทำให้ความสามารถในการให้เหตุผลขั้นสูงเข้าถึงได้สำหรับนักพัฒนาแต่ละคนและทีมขนาดเล็ก
นอกจากนี้ การปรับปรุงประสิทธิภาพการคำนวณในเวอร์ชัน 1.2 ยังช่วยลดความหน่วงของการอนุมานในขณะที่ยังคงคุณภาพการให้เหตุผล การเพิ่มประสิทธิภาพนี้ช่วยให้แอปพลิเคชันแบบเรียลไทม์และระบบโต้ตอบที่ต้องการการสร้างการตอบสนองทันที
Context Window และความสามารถในการประมวลผล
โมเดลรองรับ context window ขนาด 128,000 โทเค็น ทำให้สามารถประมวลผลเอกสารที่กว้างขวาง การสนทนาที่ซับซ้อน และงานวิเคราะห์ขนาดใหญ่ แม้ว่าประสิทธิภาพอาจลดลงเมื่อเกิน 40,000 โทเค็น โมเดลยังคงรักษาฟังก์ชันการทำงานที่สมเหตุสมผลตลอดช่วงบริบททั้งหมด
นอกจากนี้ ความสามารถของบริบทที่ขยายออกไปยังช่วยให้สามารถวิเคราะห์เอกสารที่ครอบคลุม งานการให้เหตุผลแบบยาว และการสนทนาหลายรอบโดยยังคงการรับรู้บริบท ความสามารถนี้รองรับแอปพลิเคชันองค์กรที่ต้องการการประมวลผลข้อมูลที่กว้างขวาง
เทคนิคการ Quantization และการเพิ่มประสิทธิภาพ
โมเดลรองรับรูปแบบการ Quantization ที่หลากหลายผ่านการใช้งาน GGUF ทำให้สามารถปรับใช้กับการกำหนดค่าฮาร์ดแวร์ที่แตกต่างกันได้ การเพิ่มประสิทธิภาพเหล่านี้ช่วยลดความต้องการหน่วยความจำในขณะที่ยังคงรักษาความสามารถในการให้เหตุผล ทำให้โมเดลสามารถเข้าถึงได้ในสภาพแวดล้อมที่จำกัดทรัพยากร
นอกจากนี้ เทคนิคการเพิ่มประสิทธิภาพเฉพาะยังคงรักษาความเร็วในการอนุมานในขณะที่รองรับการดำเนินการให้เหตุผลที่ซับซ้อน การปรับปรุงทางเทคนิคเหล่านี้รับประกันความเป็นไปได้ในการปรับใช้จริงในสภาพแวดล้อมการประมวลผลที่หลากหลาย
การทดสอบและการตรวจสอบด้วย Apidog
กลยุทธ์การทดสอบ API ที่ครอบคลุม
Apidog มีเครื่องมือที่จำเป็นสำหรับการตรวจสอบการผสานรวมโมเดล Magistral ผ่านเฟรมเวิร์กการทดสอบที่ครอบคลุม แพลตฟอร์มนี้รองรับการทดสอบอินพุตแบบ Multimodal การตรวจสอบร่องรอยการให้เหตุผล และการเปรียบเทียบประสิทธิภาพ ทีมสามารถสร้างชุดทดสอบที่ตรวจสอบทั้งความถูกต้องของฟังก์ชันและลักษณะประสิทธิภาพ
ความสามารถในการทดสอบอัตโนมัติของ Apidog ช่วยให้เวิร์กโฟลว์การผสานรวมอย่างต่อเนื่องที่รับประกันความสอดคล้องของประสิทธิภาพโมเดลตลอดวงจรการพัฒนา ระบบอัตโนมัตินี้ช่วยลดภาระการทดสอบด้วยตนเองในขณะที่รักษามาตรฐานการประกันคุณภาพ
การตรวจสอบและเพิ่มประสิทธิภาพ
ด้วยความสามารถในการตรวจสอบของ Apidog ทีมพัฒนาสามารถติดตามเมตริกประสิทธิภาพ API ระบุโอกาสในการเพิ่มประสิทธิภาพ และรักษาความน่าเชื่อถือของบริการ แพลตฟอร์มนี้ให้การวิเคราะห์โดยละเอียดเกี่ยวกับเวลาตอบสนอง คุณภาพการให้เหตุผล และรูปแบบการใช้ทรัพยากร
นอกจากนี้ ข้อมูลการตรวจสอบยังช่วยให้กลยุทธ์การเพิ่มประสิทธิภาพเชิงรุกที่ปรับปรุงประสิทธิภาพของแอปพลิเคชันและประสบการณ์ของผู้ใช้ แนวทางที่ขับเคลื่อนด้วยข้อมูลนี้ช่วยให้มั่นใจถึงการใช้โมเดลอย่างเหมาะสมที่สุดในสภาพแวดล้อมการผลิต
สรุป
Magistral Small 1.2 และ Magistral Medium 1.2 แสดงถึงความก้าวหน้าที่สำคัญในเทคโนโลยีการให้เหตุผล AI แบบ Multimodal การรวมกันของประสิทธิภาพทางคณิตศาสตร์ที่เพิ่มขึ้น ความสามารถด้านวิสัยทัศน์ และความโปร่งใสในการให้เหตุผลที่ปรับปรุงใหม่ สร้างเครื่องมืออันทรงพลังสำหรับการใช้งานที่หลากหลาย ตั้งแต่การวิจัยทางวิทยาศาสตร์ไปจนถึงการพัฒนาซอฟต์แวร์
การปรับปรุงการเข้าถึงผ่านตัวเลือกการปรับใช้ในเครื่องและการสนับสนุน API ที่ครอบคลุมทำให้ความสามารถในการให้เหตุผลขั้นสูงเป็นประชาธิปไตย องค์กรต่างๆ สามารถผสานรวมการให้เหตุผล AI ที่ซับซ้อนเข้ากับเวิร์กโฟลว์ของตนได้โดยไม่จำเป็นต้องลงทุนโครงสร้างพื้นฐานจำนวนมาก
ไม่ว่าคุณจะกำลังพัฒนาแอปพลิเคชันเพื่อการศึกษา ดำเนินการวิจัยทางวิทยาศาสตร์ หรือสร้างระบบซอฟต์แวร์ที่ซับซ้อน Magistral Small 1.2 และ Magistral Medium 1.2 มอบความสามารถในการให้เหตุผลที่จำเป็นสำหรับแอปพลิเคชัน AI ยุคหน้า เมื่อรวมกับเครื่องมือทดสอบและผสานรวมที่แข็งแกร่งเช่น Apidog โมเดลเหล่านี้ช่วยให้เวิร์กโฟลว์การพัฒนาที่ครอบคลุมซึ่งเร่งนวัตกรรมในขณะที่รักษามาตรฐานคุณภาพ