
โลกของโมเดลภาษาขนาดใหญ่ (LLMs) กำลังก้าวหน้าอย่างรวดเร็ว แต่ความท้าทายด้านประสิทธิภาพและการปรับตัวแบบเรียลไทม์ยังคงมีอยู่ เมื่อวันที่ 10 กันยายน 2025 Moonshot AI ซึ่งเป็นผู้ขับเคลื่อนนวัตกรรมเบื้องหลังซีรีส์ Kimi ได้เปิดตัว checkpoint-engine ซึ่งเป็นมิดเดิลแวร์โอเพนซอร์สที่กำหนดนิยามใหม่ของการอัปเดตน้ำหนักในเอ็นจิ้นอนุมานของ LLM เครื่องมือที่มีน้ำหนักเบานี้ออกแบบมาสำหรับ Reinforcement Learning (RL) สามารถรีเฟรชโมเดลขนาดใหญ่ที่มีพารามิเตอร์ 1 ล้านล้านตัวอย่าง Kimi-K2 บน GPU หลายพันตัวได้ในเวลาเพียง 20 วินาที ช่วยลดเวลาหยุดทำงานและเพิ่มความสามารถในการปรับขนาด
บทความนี้จะเจาะลึกกลไกของ checkpoint-engine ตั้งแต่สถาปัตยกรรมไปจนถึงเกณฑ์มาตรฐาน พร้อมเน้นย้ำถึงนัยยะต่อ RL และการผสานรวมกับระบบนิเวศที่กว้างขึ้น ด้วยการเปิดโอเพนซอร์สเครื่องมืออันล้ำค่านี้ Moonshot AI ช่วยให้ชุมชนสามารถผลักดันขีดจำกัดของ LLM ให้ก้าวไกลยิ่งขึ้น มาทำความเข้าใจนวัตกรรมนี้ทีละชั้นกันเถอะ
ทำความเข้าใจ Checkpoint-Engine: แนวคิดหลักและสถาปัตยกรรม
Checkpoint-Engine คืออะไร?
หัวใจหลักของ checkpoint-engine คือมิดเดิลแวร์ที่ช่วยให้การอัปเดตน้ำหนักของ LLM แบบ in-place เป็นไปอย่างราบรื่นในระหว่างการอนุมาน สิ่งนี้มีความสำคัญอย่างยิ่งใน RL ซึ่งโมเดลจะพัฒนาผ่านการตอบรับแบบวนซ้ำโดยไม่ต้องฝึกใหม่ทั้งหมด วิธีการแบบดั้งเดิมทำให้ระบบทำงานช้าลงด้วยการโหลดซ้ำที่ใช้เวลานาน checkpoint-engine แก้ปัญหานี้ด้วยวิธีการที่คล่องตัวและใช้ทรัพยากรน้อย
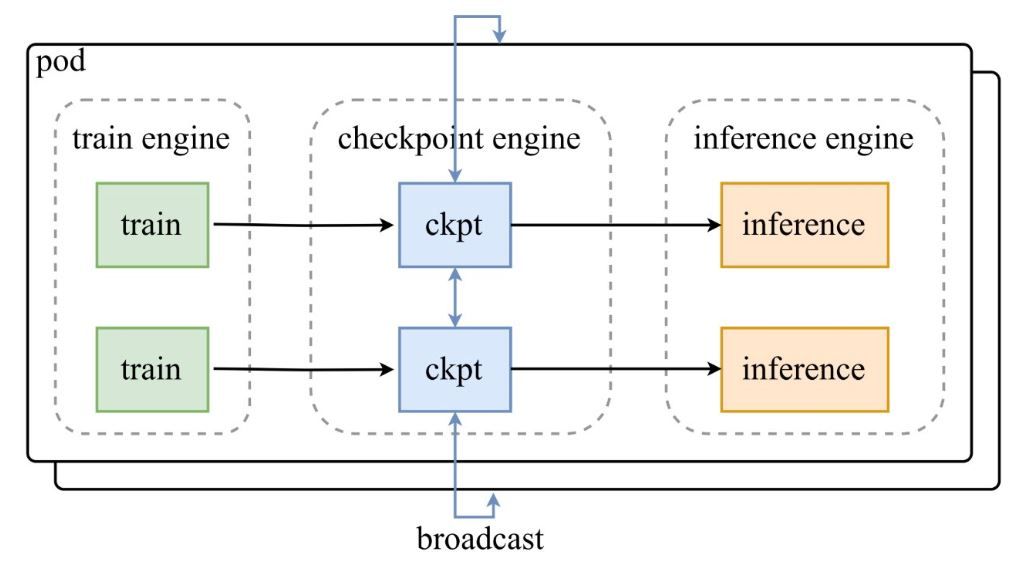
ดังที่แสดงในแผนภาพสถาปัตยกรรมจากทวีตประกาศของ Moonshot AI กลุ่มของเอนจินการฝึก (train engines) จะป้อนเช็คพอยต์ไปยัง checkpoint-engine ส่วนกลาง ซึ่งจะกระจายการอัปเดตไปยังเอนจินอนุมาน (inference engines) รีโพซิโทรี GitHub เจาะลึกโค้ด โดยเน้นที่คลาส ParameterServer ในฐานะผู้ประสานงานการอัปเดต
ส่วนประกอบทางสถาปัตยกรรม
- Train Engine: สร้างน้ำหนักใหม่จากการฝึก RL อย่างต่อเนื่อง เพื่อจับการปรับปรุงนโยบายในสภาพแวดล้อมแบบไดนามิก
- Checkpoint Engine: แกนหลักของมิดเดิลแวร์ ซึ่งอยู่ร่วมกับเอนจินอนุมานเพื่อลดความหน่วงให้เหลือน้อยที่สุด โดยจัดการการรวบรวมเมตาดาต้าและดำเนินการอัปเดตผ่านโหมด Broadcast หรือ P2P
- Inference Engine: ผสานรวมการอัปเดตแบบทันทีทันใด รักษาความต่อเนื่องของบริการในคลัสเตอร์ GPU แบบกระจาย
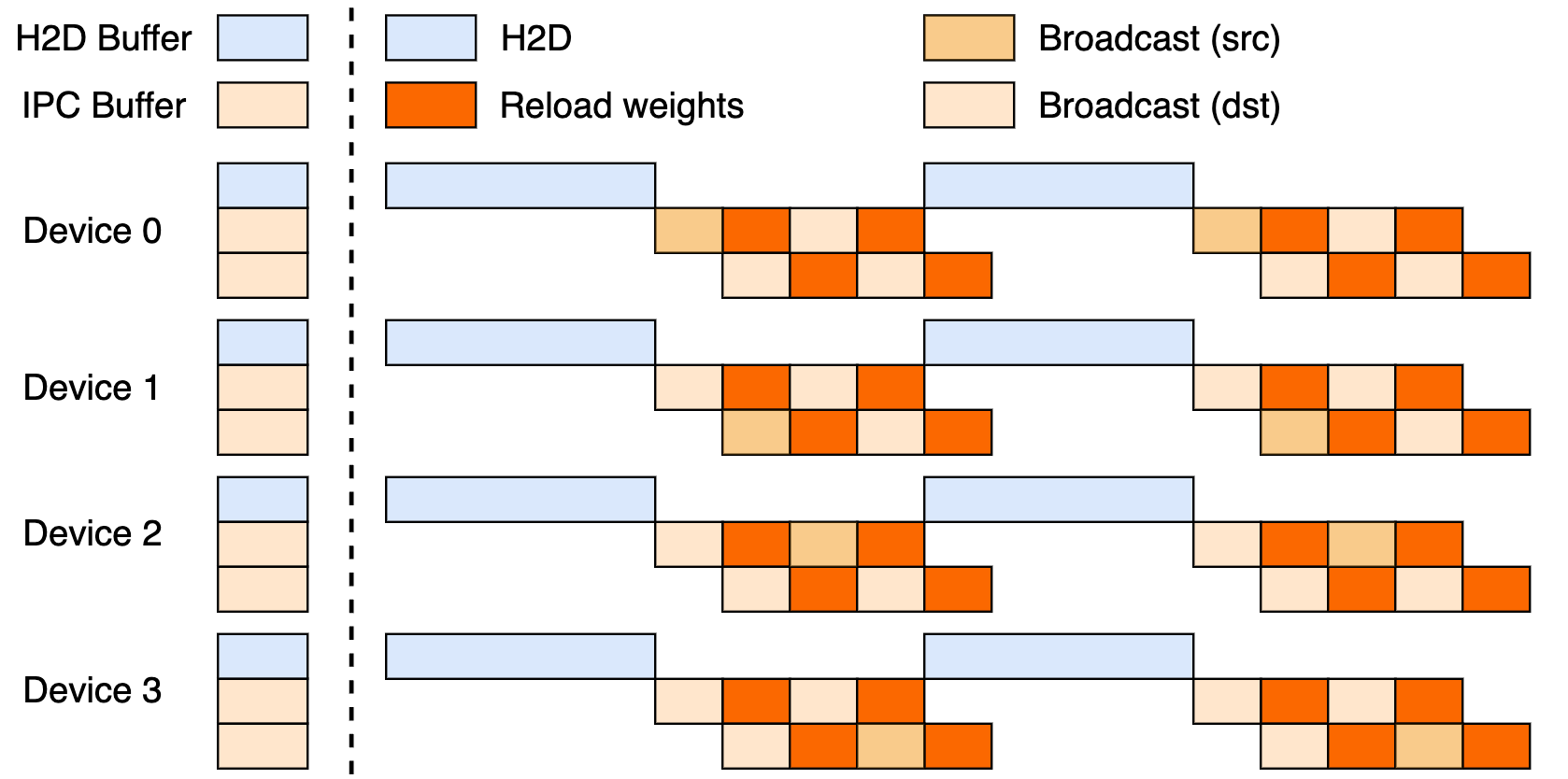
การตั้งค่านี้ใช้ประโยชน์จากไปป์ไลน์สามขั้นตอน: การถ่ายโอนจากโฮสต์ไปยังอุปกรณ์ (H2D), การกระจายสัญญาณระหว่างผู้ปฏิบัติงานโดยใช้ CUDA IPC และการโหลดซ้ำแบบกำหนดเป้าหมาย ด้วยการซ้อนทับกันของสิ่งเหล่านี้ จะช่วยเพิ่มการใช้งาน GPU และลดปัญหาคอขวดในการถ่ายโอน
การอัปเดตแบบ Broadcast เทียบกับ P2P
Broadcast โดดเด่นในการอัปเดตแบบซิงโครนัสทั่วทั้งคลัสเตอร์ ซึ่งเป็นโหมดเริ่มต้นสำหรับความเร็วสูงสุด โดยจัดกลุ่มข้อมูลเพื่อการไหลเวียนที่เหมาะสม ในขณะที่ P2P excels ในสถานการณ์ที่ยืดหยุ่น เช่น การขยายขนาดในช่วงเวลาสูงสุด โดยใช้ RDMA ผ่าน mooncake-transfer-engine เพื่อหลีกเลี่ยงการหยุดชะงัก ความสามารถสองแบบนี้ทำให้ checkpoint-engine มีความหลากหลายสำหรับการใช้งานทั้งแบบเสถียรและแบบยืดหยุ่น
เกณฑ์มาตรฐานประสิทธิภาพ: ความเร็วแค่ไหนถึงจะเพียงพอ?
การอัปเดตโมเดลพารามิเตอร์ 1 ล้านล้านตัวใน 20 วินาที
ความสำเร็จที่โดดเด่นของ Checkpoint-engine คืออะไร? การอัปเดตพารามิเตอร์ 1 ล้านล้านตัวของ Kimi-K2 บน GPU หลายพันตัวในเวลาประมาณ 20 วินาที สิ่งนี้เกิดจากไปป์ไลน์อัจฉริยะ: การวางแผนเมตาดาต้ากำหนดขนาดบัคเก็ตที่มีประสิทธิภาพ, ซ็อกเก็ต ZeroMQ ประสานงานการถ่ายโอน และขั้นตอน H2D/broadcast ที่ซ้อนทับกันจะซ่อนความหน่วงแฝง
เปรียบเทียบกับเทคนิคแบบเก่า ซึ่งอาจทำให้ระบบไม่ทำงานเป็นนาทีท่ามกลางการสลับข้อมูลจำนวนมาก หลักการ "in-place" ของ Checkpoint-engine ช่วยให้การอนุมานทำงานได้อย่างต่อเนื่อง ซึ่งเหมาะสำหรับความต้องการของ RL ในการปรับตัวอย่างรวดเร็ว
การวิเคราะห์เกณฑ์มาตรฐาน
ตารางเกณฑ์มาตรฐานแสดงผลลัพธ์ที่ยอดเยี่ยมในโมเดลและการตั้งค่าต่างๆ ซึ่งทดสอบด้วย vLLM v0.10.2rc1:
| โมเดล | ข้อมูลอุปกรณ์ | GatherMetas | อัปเดต (Broadcast) | อัปเดต (P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57GiB) |
สามารถทำซ้ำสิ่งเหล่านี้ได้ผ่าน examples/update.py ในรีโพซิโทรี การรัน FP8 ต้องใช้แพตช์ vLLM ซึ่งเน้นย้ำถึงประสิทธิภาพในระดับใหญ่
นัยยะต่อ Reinforcement Learning
RL เติบโตได้ดีจากการวนซ้ำอย่างรวดเร็ว วงจรของ checkpoint-engine ที่ใช้เวลาน้อยกว่า 20 วินาทีช่วยให้เกิดการเรียนรู้แบบต่อเนื่อง แซงหน้าวิธีการแบบแบตช์ สิ่งนี้ปลดล็อกแอปพลิเคชันที่ตอบสนองได้อย่างรวดเร็ว ตั้งแต่เอเจนต์ที่ปรับตัวได้ไปจนถึงแชทบอทที่พัฒนาตนเอง ซึ่งทุกวินาทีมีความสำคัญในการปรับแต่งนโยบาย
การนำไปใช้งานทางเทคนิค: เจาะลึกโค้ดเบส
การเข้าถึงแบบโอเพนซอร์ส
การเปิด GitHub ของ Moonshot AI ทำให้เครื่องมือ RL ระดับสูงเป็นประชาธิปไตย ParameterServer เป็นหัวใจหลักของการอัปเดต โดยนำเสนอ Broadcast (การแชร์ CUDA IPC ที่รวดเร็ว) และ P2P (RDMA สำหรับผู้เริ่มต้น) ตัวอย่างเช่น update.py และการทดสอบ (test_update.py) ช่วยให้การเริ่มต้นใช้งานง่ายขึ้น
ความเข้ากันได้เริ่มต้นด้วย vLLM (ผ่านส่วนขยาย worker) โดยมีแผนจะรองรับ SGLang ต่อไป ไปป์ไลน์สามขั้นตอนบางส่วนบ่งบอกถึงศักยภาพที่ยังไม่ได้ใช้
เทคนิคการเพิ่มประสิทธิภาพ
- Pipelined Overlaps: การสื่อสารและการคัดลอกทำงานพร้อมกัน ช่วยลดเวลาทำงานจริง
- Bucket Optimization: การปรับขนาดตามเมตาดาต้าให้เหมาะสมกับการแบ่งส่วนและเครือข่าย
- ZeroMQ Control: การส่งสัญญาณที่มีความหน่วงต่ำไปยังเอนจินอนุมาน
สิ่งเหล่านี้จัดการกับอุปสรรคของพารามิเตอร์นับล้านล้านตัว ตั้งแต่ความขัดแย้งของ PCIe ไปจนถึงปัญหาหน่วยความจำไม่พอ (โดยจะกลับไปใช้แบบอนุกรมหากจำเป็น)
ข้อจำกัดในปัจจุบัน
ช่องทาง rank-0 ของ P2P อาจเกิดปัญหาคอขวดเมื่อขยายขนาด และไปป์ไลน์เต็มรูปแบบยังรอการปรับปรุง การเน้นที่ vLLM ทำให้ขอบเขตจำกัด แต่แพตช์ช่วยเชื่อมช่องว่าง FP8 สำหรับโมเดลอย่าง DeepSeek-V3.1 ติดตามรีโพซิโทรีเพื่อดูการพัฒนาต่อไป
การผสานรวมกับเฟรมเวิร์กที่มีอยู่: vLLM และอื่นๆ
ความร่วมมือกับ vLLM
Checkpoint-engine ทำงานร่วมกับ PagedAttention ของ vLLM ได้อย่างราบรื่นเพื่อการอนุมาน RL ที่ลื่นไหล การทำงานร่วมกันนี้ช่วยให้สามารถซิงค์โมเดล 1 ล้านล้านตัวได้ใน 20 วินาที ดังที่กล่าวไว้ในการอัปเดตของ vLLM ซึ่งเป็นการแสดงให้เห็นถึงความร่วมมือแบบเปิดที่ช่วยเพิ่มปริมาณงาน
ส่วนขยายที่เป็นไปได้สำหรับ Claude และ Apidog
การขยายไปยัง Claude ของ Anthropic สามารถเพิ่มพลวัตของ RL เข้าไปในการสนทนาที่เน้นความปลอดภัย ทำให้สามารถปรับแต่งแบบเรียลไทม์ได้ Apidog เหมาะอย่างยิ่งสำหรับการจำลองปลายทาง (endpoint mocking) ในระหว่างการปรับแต่ง ZeroMQ — ดาวน์โหลด Apidog ฟรีเพื่อสร้างต้นแบบการเชื่อมต่อเหล่านี้ได้อย่างง่ายดาย
ผลกระทบต่อระบบนิเวศในวงกว้าง
การเชื่อมต่อกับ Ollama หรือ LM Studio สามารถทำให้พลังของโมเดลพารามิเตอร์นับล้านล้านตัวเข้าถึงได้ง่ายขึ้นในท้องถิ่น ทำให้เกิดความเท่าเทียมกันสำหรับนักพัฒนาอิสระ ผลกระทบแบบลูกโซ่นี้ส่งเสริมภูมิทัศน์ AI ที่ครอบคลุมมากยิ่งขึ้น
แนวโน้มในอนาคต: Checkpoint-Engine จะก้าวไปในทิศทางใด?
การปรับขนาดและการปรับปรุงประสิทธิภาพ
การเปิดตัวไปป์ไลน์เต็มรูปแบบอาจช่วยลดเวลาได้อีกหลายวินาที ในขณะที่การกระจายอำนาจ P2P ช่วยขจัดปัญหาคอขวดเพื่อความยืดหยุ่นที่แท้จริง การปรับแต่ง RDMA สัญญาว่าจะมอบความสามารถแบบคลาวด์เนทีฟ
การมีส่วนร่วมของชุมชน
โอเพนซอร์สเชิญชวนให้มีการแก้ไขและการพอร์ต เช่น การรวม SGLang หรือโหมดที่ไม่ขึ้นกับ PCIe การตอบกลับเบื้องต้นบนทวีตเต็มไปด้วยความตื่นเต้น ซึ่งช่วยผลักดันโมเมนตัม
การประยุกต์ใช้ในอุตสาหกรรม
ตั้งแต่การแปลแบบเรียลไทม์ไปจนถึง RL สำหรับรถยนต์ไร้คนขับ checkpoint-engine เหมาะสำหรับโดเมนที่มีการเปลี่ยนแปลงสูง ความเร็วของมันช่วยให้โมเดลทันสมัยอยู่เสมอ แซงหน้าคู่แข่งในด้านความคล่องตัว
ยุคใหม่ของการอนุมาน LLM?
Checkpoint-engine บ่งบอกถึงอนาคตของ LLM ที่คล่องตัว โดยจัดการกับปัญหาน้ำหนักด้วยความสามารถแบบโอเพนซอร์ส การรีเฟรชโมเดล 1 ล้านล้านตัวใน 20 วินาที ซึ่งได้รับการสนับสนุนจากสถาปัตยกรรมที่ชาญฉลาดและเกณฑ์มาตรฐาน ตอกย้ำตำแหน่งของมันใน RL—แม้จะมีข้อจำกัดก็ตาม
จับคู่กับ Apidog สำหรับเวิร์กโฟลว์การพัฒนา หรือ Claude สำหรับความสามารถอัจฉริยะแบบไฮบริด แล้วนวัตกรรมจะพุ่งทะยาน ติดตาม GitHub, รับ Apidog ฟรี และเข้าร่วมการปฏิวัติที่กำลังปรับเปลี่ยนการอนุมานในวันนี้!