
นักพัฒนาซอฟต์แวร์ต่างมองหาวิธีที่มีประสิทธิภาพในการผสานรวมโมเดล AI ขั้นสูงเข้ากับแอปพลิเคชันของตน และ Qwen Next ก็เป็นตัวเลือกที่น่าสนใจ โมเดลนี้ซึ่งเป็นส่วนหนึ่งของซีรีส์ Qwen ของ Alibaba นำเสนอสถาปัตยกรรม Mixture of Experts (MoE) แบบกระจายที่เปิดใช้งานพารามิเตอร์เพียงบางส่วนระหว่างการอนุมาน ด้วยเหตุนี้ คุณจึงได้เวลาประมวลผลที่เร็วขึ้นและต้นทุนที่ต่ำลงโดยไม่ลดทอนประสิทธิภาพ
ทำความเข้าใจสถาปัตยกรรมหลักของ Qwen Next และความสำคัญสำหรับผู้ใช้ API
สถาปัตยกรรมไฮบริดของ Qwen Next ผสมผสานกลไกแบบ gated เข้ากับการทำให้เป็นมาตรฐานขั้นสูง เพิ่มประสิทธิภาพสำหรับงานที่ขับเคลื่อนด้วย API เลเยอร์ MoE จะส่งอินพุตไปยังผู้เชี่ยวชาญเฉพาะทาง 10 ใน 512 คนต่อโทเค็น บวกกับผู้เชี่ยวชาญที่ใช้ร่วมกันอีกหนึ่งคน ซึ่งเปิดใช้งานพารามิเตอร์เพียง 3 พันล้านตัวเท่านั้น ความเบาบางนี้ช่วยลดความต้องการทรัพยากร ทำให้การอนุมานเร็วขึ้นสำหรับผู้ใช้ Qwen API

นอกจากนี้ โมเดลยังใช้กลไก attention แบบ scaled dot-product พร้อมกับ Rotary Position Embeddings (RoPE) บางส่วน เพื่อรักษาบริบทในลำดับที่มีความยาวสูงสุดถึง 128K โทเค็น เลเยอร์ RMSNorm แบบศูนย์กลางช่วยให้ gradient มีเสถียรภาพ ทำให้มั่นใจได้ถึงผลลัพธ์ที่เชื่อถือได้ระหว่างการเรียกใช้ API ที่มีปริมาณมาก เส้นทาง DeltaNet ที่มีปัจจัยการขยาย 3 เท่า ใช้การทำให้เป็นมาตรฐานแบบ L2, เลเยอร์ convolutional และ SiLU activation เพื่อรองรับการถอดรหัสแบบ speculative ซึ่งสร้างโทเค็นหลายตัวพร้อมกัน
สำหรับนักพัฒนาซอฟต์แวร์ นี่หมายถึง Next Integration เข้าสู่แอปพลิเคชันอย่างเครื่องมือวิเคราะห์เอกสารนั้นมีประสิทธิภาพและปรับขนาดได้ ความเป็นโมดูลของสถาปัตยกรรมช่วยให้สามารถปรับแต่งได้อย่างละเอียดสำหรับโดเมนต่างๆ เช่น การเงิน ทำให้สามารถปรับเปลี่ยนได้ผ่าน Qwen API ต่อไป ให้พิจารณาว่าคุณสมบัติเหล่านี้แปลไปสู่ประสิทธิภาพที่วัดผลได้อย่างไร
การประเมินเกณฑ์มาตรฐานประสิทธิภาพสำหรับ Qwen Next ในแอปพลิเคชันที่ขับเคลื่อนด้วย API
นักพัฒนาที่ผสานรวม Qwen Next เข้ากับเวิร์กโฟลว์ที่ขับเคลื่อนด้วย API จะให้ความสำคัญกับโมเดลที่รักษาสมดุลระหว่างประสิทธิภาพสูงกับประสิทธิภาพการคำนวณ Qwen3-Next-80B-A3B ด้วยสถาปัตยกรรม Mixture of Experts (MoE) แบบกระจายที่เปิดใช้งานพารามิเตอร์เพียง 3 พันล้านตัวระหว่างการอนุมานนั้นมีความโดดเด่นในด้านนี้ ส่วนนี้จะประเมินเกณฑ์มาตรฐานที่สำคัญ โดยเน้นว่า Qwen Next มีประสิทธิภาพเหนือกว่าโมเดลที่หนาแน่นกว่า เช่น Qwen3-32B ในขณะที่ให้ความเร็วในการอนุมานที่เหนือกว่า ซึ่งสำคัญอย่างยิ่งสำหรับการตอบสนอง API แบบเรียลไทม์ การตรวจสอบเมตริกในด้านความรู้ทั่วไป การเขียนโค้ด การให้เหตุผล และงานบริบทที่ยาวนาน จะช่วยให้คุณเข้าใจถึงความเหมาะสมสำหรับแอปพลิเคชันที่ปรับขนาดได้
ประสิทธิภาพการฝึกอบรมล่วงหน้าและประสิทธิภาพของโมเดลพื้นฐาน
การฝึกอบรมล่วงหน้าของ Qwen Next แสดงให้เห็นถึงประสิทธิภาพที่โดดเด่น โมเดล Qwen3-Next-80B-A3B-Base ซึ่งได้รับการฝึกอบรมบนชุดข้อมูลย่อย 15 ล้านล้านโทเค็นจากคลังข้อมูล 36 ล้านล้านโทเค็นของ Qwen3 ใช้เวลา GPU น้อยกว่า 80% ของที่ Qwen3-30B-A3B ต้องการ และมีค่าใช้จ่ายในการคำนวณเพียง 9.3% ของ Qwen3-32B แม้กระนั้น โมเดลนี้เปิดใช้งานพารามิเตอร์ที่ไม่ใช่การฝังเพียงหนึ่งในสิบของที่ Qwen3-32B-Base ใช้ แต่กลับมีประสิทธิภาพเหนือกว่าในเกณฑ์มาตรฐานส่วนใหญ่ และมีประสิทธิภาพดีกว่า Qwen3-30B-A3B อย่างมีนัยสำคัญ
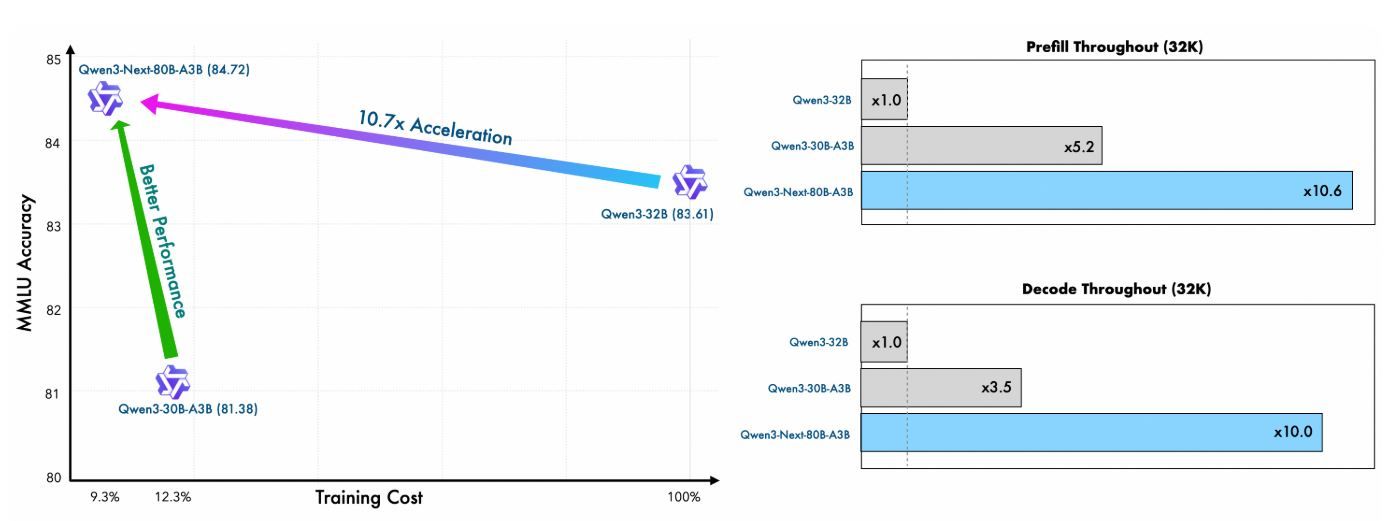
ประสิทธิภาพนี้เกิดจากสถาปัตยกรรมไฮบริด ซึ่งรวม Gated DeltaNet (75% ของเลเยอร์) เข้ากับ Gated Attention (25%) ซึ่งช่วยเพิ่มประสิทธิภาพทั้งความเสถียรในการฝึกอบรมและปริมาณงานในการอนุมาน สำหรับผู้ใช้ API สิ่งนี้หมายถึงต้นทุนการปรับใช้ที่ต่ำลงและการสร้างต้นแบบที่เร็วขึ้น เนื่องจากโมเดลสามารถลดความซับซ้อนและลดการสูญเสียได้ดีขึ้นด้วยทรัพยากรที่น้อยลง
เมตริก | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Qwen3-30B-A3B-Base |
|---|---|---|---|
ชั่วโมง GPU ในการฝึกอบรม (% ของ Qwen3-32B) | 9.3% | 100% | ~125% |
อัตราส่วนพารามิเตอร์ที่ใช้งานอยู่ | 10% | 100% | 10% |
ประสิทธิภาพเหนือกว่าเกณฑ์มาตรฐาน | เหนือกว่าในส่วนใหญ่ | เกณฑ์มาตรฐาน | ดีกว่าอย่างมีนัยสำคัญ |
ตัวเลขเหล่านี้เน้นย้ำถึงคุณค่าของ Qwen Next ในสภาพแวดล้อม API ที่มีทรัพยากรจำกัด ซึ่งการฝึกอบรมโมเดลที่กำหนดเองผ่านการปรับแต่งอย่างละเอียด (fine-tuning) ยังคงทำได้
ความเร็วในการอนุมาน: ขั้นตอน Prefill และ Decode สำหรับความหน่วงของ API
ความเร็วในการอนุมานส่งผลโดยตรงต่อเวลาตอบสนองของ API โดยเฉพาะอย่างยิ่งในสถานการณ์ที่มีปริมาณงานสูง เช่น บริการแชทหรือการสร้างเนื้อหา Qwen Next โดดเด่นในด้านนี้ โดยใช้ประโยชน์จาก MoE ที่เบาบางเป็นพิเศษ (ผู้เชี่ยวชาญ 512 คน, การส่งข้อมูล 10 + 1 คนที่ใช้ร่วมกัน) และ Multi-Token Prediction (MTP) สำหรับการถอดรหัสแบบ speculative
ในขั้นตอน prefill (การประมวลผลพร้อมท์) Qwen Next มีปริมาณงานสูงกว่า Qwen3-32B เกือบ 7 เท่า ที่ความยาวบริบท 4K โทเค็น เมื่อเกิน 32K โทเค็น ข้อได้เปรียบนี้จะสูงกว่า 10 เท่า ทำให้เหมาะสำหรับ API การวิเคราะห์เอกสารขนาดยาว
สำหรับขั้นตอน decode (การสร้างโทเค็น) ปริมาณงานสูงถึงเกือบ 4 เท่าที่บริบท 4K และสูงกว่า 10 เท่าที่ความยาวที่ยาวขึ้น กลไก MTP ซึ่งได้รับการปรับให้เหมาะสมสำหรับความสอดคล้องหลายขั้นตอน ช่วยเพิ่มอัตราการยอมรับในการถอดรหัสแบบ speculative ซึ่งช่วยเร่งการอนุมานในโลกแห่งความเป็นจริงให้เร็วขึ้นอีก
ความยาวบริบท | ปริมาณงาน Prefill (เทียบกับ Qwen3-32B) | ปริมาณงาน Decode (เทียบกับ Qwen3-32B) |
|---|---|---|
4K โทเค็น | เร็วขึ้น 7 เท่า | เร็วขึ้น 4 เท่า |
>32K โทเค็น | เร็วขึ้น >10 เท่า | เร็วขึ้น >10 เท่า |
นักพัฒนา API ได้รับประโยชน์อย่างมหาศาล: ความหน่วงที่ลดลงทำให้สามารถตอบสนองได้ภายในเสี้ยววินาทีในการผลิต ในขณะที่ประสิทธิภาพการใช้พลังงาน (จากการเปิดใช้งานพารามิเตอร์เพียง 3.7%) ช่วยลดค่าใช้จ่ายคลาวด์ เฟรมเวิร์กอย่าง vLLM และ SGLang ขยายผลประโยชน์เหล่านี้ โดยรองรับบริบทสูงสุด 256K ด้วย tensor parallelism
การเรียกใช้ API ครั้งแรกของคุณด้วย Qwen Next: การใช้งานทีละขั้นตอน
เพื่อใช้ประโยชน์จากความสามารถของ Qwen Next ให้ทำตามขั้นตอนที่ชัดเจนและนำไปปฏิบัติได้เหล่านี้เพื่อตั้งค่าและดำเนินการเรียกใช้ Qwen API ผ่านแพลตฟอร์ม DashScope ของ Alibaba คู่มือนี้ช่วยให้คุณสามารถผสานรวมโมเดลได้อย่างมีประสิทธิภาพ ไม่ว่าจะเป็นการสอบถามแบบง่ายๆ หรือสถานการณ์ Next Integration ที่ซับซ้อน
ขั้นตอนที่ 1: สร้างบัญชี Alibaba Cloud และเข้าถึง Model Studio
เริ่มต้นด้วยการลงทะเบียนบัญชี Alibaba Cloud ที่ alibabacloud.com หลังจากยืนยันบัญชีของคุณแล้ว ให้ไปที่คอนโซล Model Studio ภายในแพลตฟอร์ม DashScope เลือก Qwen3-Next-80B-A3B จากรายการโมเดล โดยเลือกเวอร์ชัน base, instruct หรือ thinking ตามกรณีการใช้งานของคุณ—เช่น instruct สำหรับงานสนทนา หรือ thinking สำหรับการให้เหตุผลที่ซับซ้อน
ขั้นตอนที่ 2: สร้างและรักษาความปลอดภัยคีย์ API ของคุณ
ในแดชบอร์ด DashScope ให้ค้นหาส่วน “API Keys” และสร้างคีย์ใหม่ คีย์นี้จะยืนยันการร้องขอ Qwen API ของคุณ โปรดทราบถึงขีดจำกัดอัตรา: ระดับฟรีมี 1 ล้านโทเค็นต่อเดือน ซึ่งเพียงพอสำหรับการทดสอบเบื้องต้น จัดเก็บคีย์อย่างปลอดภัยในตัวแปรสภาพแวดล้อมเพื่อป้องกันการเปิดเผย:
bash
export DASHSCOPE_API_KEY='your_key_here'วิธีปฏิบัตินี้ทำให้โค้ดของคุณสามารถพกพาและปลอดภัย
ขั้นตอนที่ 3: ติดตั้ง DashScope Python SDK
ติดตั้ง DashScope SDK เพื่อทำให้การโต้ตอบ Qwen API ง่ายขึ้น รันคำสั่งต่อไปนี้ในเทอร์มินัลของคุณ:
bash
pip install dashscopeSDK จัดการการจัดเรียงข้อมูล การลองใหม่ และการแยกวิเคราะห์ข้อผิดพลาด ทำให้กระบวนการผสานรวมของคุณง่ายขึ้น อีกทางเลือกหนึ่งคือใช้ไคลเอนต์ HTTP เช่น requests สำหรับการตั้งค่าที่กำหนดเอง แต่แนะนำให้ใช้ SDK เพื่อความสะดวก
ขั้นตอนที่ 4: กำหนดค่าปลายทาง API
สำหรับไคลเอนต์ที่เข้ากันได้กับ OpenAI ให้ตั้งค่า URL พื้นฐานเป็น:
text
https://dashscope.aliyuncs.com/compatible-mode/v1สำหรับการเรียกใช้ DashScope แบบ native ให้ใช้:
text
https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generationรวมคีย์ API ของคุณในส่วนหัวคำขอเป็น X-DashScope-API-Key การกำหนดค่านี้ช่วยให้มั่นใจได้ถึงการส่งเส้นทางที่เหมาะสมไปยัง Qwen Next
ขั้นตอนที่ 5: ทำการเรียกใช้ API ครั้งแรกของคุณ
สร้างคำขอการสร้างพื้นฐานโดยใช้เวอร์ชัน instruct ด้านล่างนี้คือสคริปต์ Python สำหรับสอบถาม Qwen Next:
python
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='อธิบายประโยชน์ของสถาปัตยกรรม MoE ใน LLM.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")สคริปต์นี้ส่งพร้อมท์ จำกัดผลลัพธ์ที่ 200 โทเค็น และควบคุมความคิดสร้างสรรค์ด้วย temperature=0.7 รหัสสถานะ 200 แสดงถึงความสำเร็จ มิฉะนั้น ให้จัดการข้อผิดพลาดเช่นขีดจำกัดโควต้า (รหัส 10402)
ขั้นตอนที่ 6: ใช้การสตรีมสำหรับการตอบสนองแบบเรียลไทม์
สำหรับแอปพลิเคชันที่ต้องการการตอบสนองทันที ให้ใช้การสตรีม:
python
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='สร้างฟังก์ชัน Python สำหรับการวิเคราะห์ความรู้สึก.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
breakสิ่งนี้ให้ผลลัพธ์แบบโทเค็นต่อโทเค็น ซึ่งเหมาะสำหรับอินเทอร์เฟซแชทสดใน Next Integration
ขั้นตอนที่ 7: เพิ่มการเรียกใช้ฟังก์ชันสำหรับเวิร์กโฟลว์แบบ Agentic
ขยายฟังก์ชันการทำงานด้วยการรวมเครื่องมือ กำหนด JSON schema สำหรับเครื่องมือ เช่น การดึงสภาพอากาศ:
python
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "รับสภาพอากาศปัจจุบัน",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='สภาพอากาศในปักกิ่งเป็นอย่างไร?',
tools=tools,
tool_choice='auto'
)Qwen API แยกวิเคราะห์พร้อมท์ ทำให้เกิดการเรียกใช้เครื่องมือ เรียกใช้ฟังก์ชันภายนอกและป้อนผลลัพธ์กลับ
ขั้นตอนที่ 8: ทดสอบและตรวจสอบด้วย Apidog
ใช้ Apidog เพื่อทดสอบการเรียกใช้ API ของคุณ นำเข้าสคีมา DashScope ไปยังโปรเจกต์ Apidog ใหม่ เพิ่มปลายทาง และรวมคีย์ API ของคุณในส่วนหัว สร้างเนื้อหา JSON ด้วยพร้อมท์ของคุณ จากนั้นรันกรณีทดสอบเพื่อตรวจสอบการตอบสนอง Apidog สร้างเมตริกเช่นความหน่วง และแนะนำกรณีขอบเขต ซึ่งช่วยเพิ่มความน่าเชื่อถือ
ขั้นตอนที่ 9: ตรวจสอบและแก้ไขข้อผิดพลาดการตอบสนอง
ตรวจสอบรหัสการตอบสนองสำหรับข้อผิดพลาด (เช่น 429 สำหรับขีดจำกัดอัตรา) บันทึกผลลัพธ์ที่ไม่ระบุชื่อสำหรับการตรวจสอบ ใช้แดชบอร์ดของ Apidog เพื่อติดตามการใช้โทเค็นและเวลาตอบสนอง เพื่อให้แน่ใจว่าการเรียกใช้ Qwen API ของคุณยังคงอยู่ภายในโควต้า
ขั้นตอนเหล่านี้เป็นรากฐานที่แข็งแกร่งสำหรับการผสานรวม Qwen Next ต่อไป ให้ปรับปรุงการทดสอบของคุณด้วย Apidog
การใช้ประโยชน์จากการเรียกใช้ฟังก์ชันใน Qwen Next API สำหรับเวิร์กโฟลว์แบบ Agentic
การเรียกใช้ฟังก์ชันขยายประโยชน์ของ Qwen Next นอกเหนือจากการสร้างข้อความ กำหนดเครื่องมือใน JSON schema โดยระบุชื่อ คำอธิบาย และพารามิเตอร์ สำหรับการสอบถามสภาพอากาศ ให้ระบุฟังก์ชัน get_weather ที่มีพารามิเตอร์ city
ในการเรียกใช้ API ของคุณ ให้รวมอาร์เรย์ tools และตั้งค่า tool_choice เป็น 'auto' โมเดลจะวิเคราะห์พร้อมท์ ระบุความตั้งใจ และส่งคืนการเรียกใช้เครื่องมือ เรียกใช้ฟังก์ชันภายนอกและป้อนผลลัพธ์กลับสำหรับการตอบสนองขั้นสุดท้าย
รูปแบบนี้สร้างระบบแบบ Agentic ซึ่ง Qwen Next จะประสานงานเครื่องมือหลายอย่าง ตัวอย่างเช่น รวมข้อมูลสภาพอากาศเข้ากับการวิเคราะห์ความรู้สึกเพื่อคำแนะนำส่วนบุคคล Qwen API จัดการการแยกวิเคราะห์ได้อย่างมีประสิทธิภาพ ลดความจำเป็นในการเขียนโค้ดที่กำหนดเอง
เพิ่มประสิทธิภาพโดยการตรวจสอบสคีมาอย่างเคร่งครัด ตรวจสอบให้แน่ใจว่าพารามิเตอร์ตรงกับประเภทที่คาดไว้เพื่อหลีกเลี่ยงข้อผิดพลาดขณะรันไทม์ ในขณะที่คุณผสานรวม ให้ทดสอบการเรียกใช้เหล่านี้อย่างละเอียด—เครื่องมืออย่าง Apidog มีคุณค่าอย่างยิ่งในที่นี้ โดยจำลองการตอบสนองโดยไม่ต้องเรียกใช้ API จริง
การผสานรวม Apidog สำหรับการทดสอบและจัดทำเอกสาร Qwen API อย่างมีประสิทธิภาพ
คู่มือนี้ให้เวิร์กโฟลว์ที่ครอบคลุมสำหรับการผสานรวม Apidog เข้ากับ Qwen API (Qwen Next/3.0 ของ Alibaba Cloud) เพื่อการทดสอบ การจัดทำเอกสาร และการจัดการวงจรชีวิต API อย่างมีประสิทธิภาพ
ระยะที่ 1: การตั้งค่าเริ่มต้นและการกำหนดค่าบัญชี
ขั้นตอนที่ 1: การตั้งค่าบัญชี
1.1 สร้างบัญชีที่จำเป็น
1. บัญชี Alibaba Cloud
2. เยี่ยมชม: https://www.alibabacloud.com
3. ลงทะเบียนและยืนยันให้เสร็จสมบูรณ์
4. เปิดใช้งานบริการ "Model Studio"
5. บัญชี Apidog
6. เยี่ยมชม: https://apidog.com
7. ลงทะเบียนด้วยอีเมล/Google/GitHub
1.2 รับข้อมูลรับรอง Qwen API
1. ไปที่: Alibaba cloud Console → Model Studio → API Keys
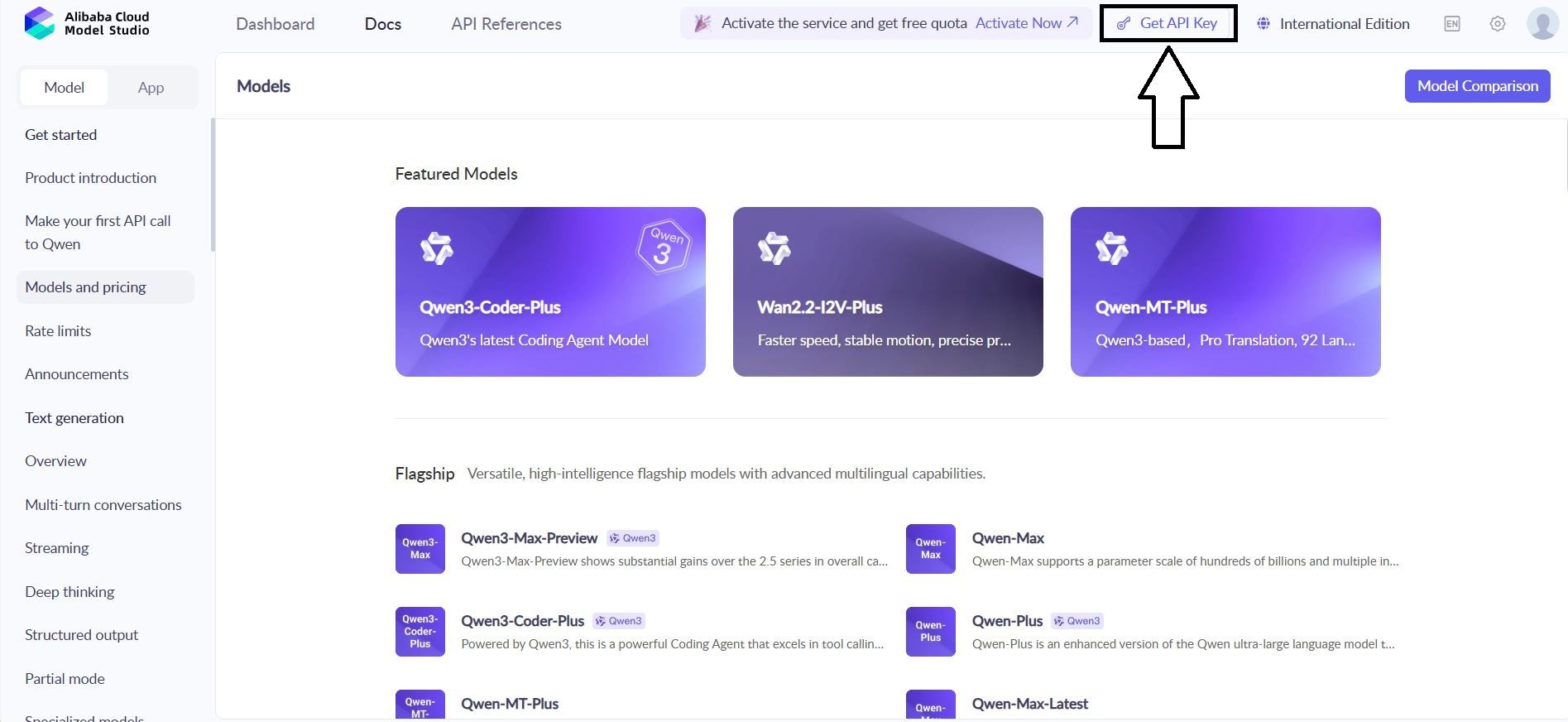
2. สร้างคีย์ใหม่: qwen-testing-key
3. บันทึกคีย์ของคุณ: sk-[your-actual-key-here]

1.3 สร้างโปรเจกต์ Apidog
- เข้าสู่ระบบ Apidog → คลิก "New Project"
2. กำหนดค่าโปรเจกต์:
1. ชื่อโปรเจกต์:Qwen API Integration
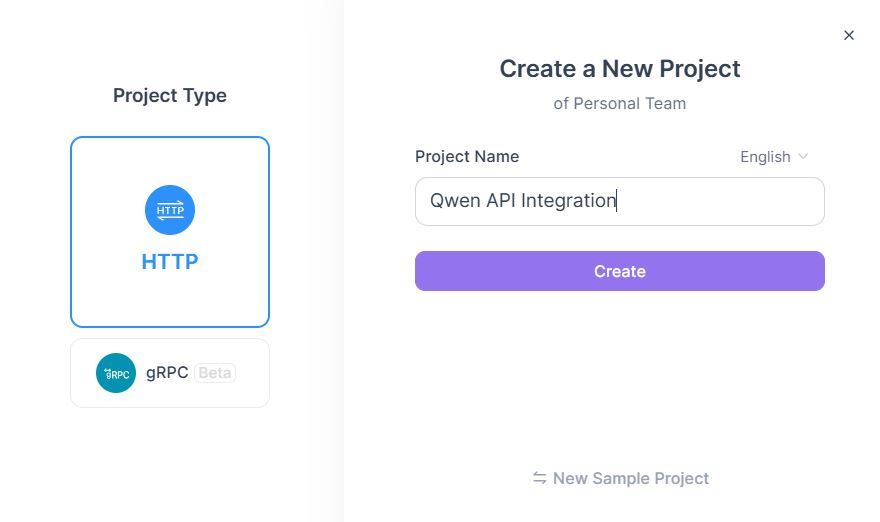
2. คำอธิบาย:การทดสอบและจัดทำเอกสาร Qwen Next API
ระยะที่ 2: การนำเข้าและการกำหนดค่า API
ขั้นตอนที่ 2: นำเข้าข้อมูลจำเพาะของ Qwen API
วิธี A: การสร้าง API ด้วยตนเอง
- เพิ่ม API ใหม่ → "สร้าง API ด้วยตนเอง"
- กำหนดค่าปลายทาง Qwen Chat:

3. ตั้งค่าการกำหนดค่าคำขอ:
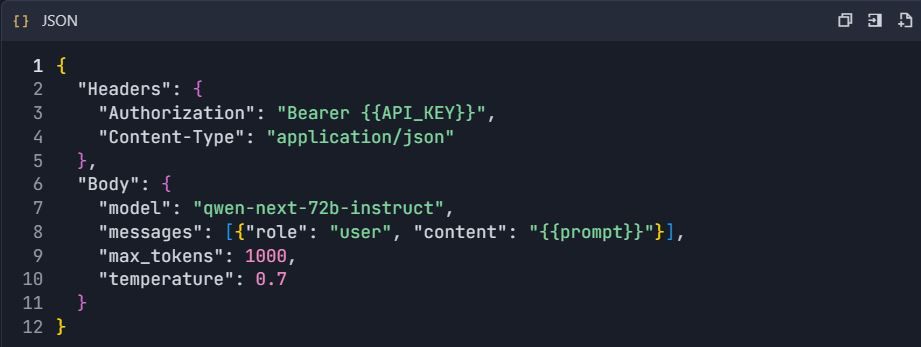
วิธี B: การนำเข้า OpenAPI
- ดาวน์โหลด Qwen OpenAPI spec (หากมี)
- ไปที่ Project → "Import" → "OpenAPI/Swagger"
- อัปโหลดไฟล์ spec → "Import"
ระยะที่ 3: การตั้งค่าสภาพแวดล้อมและการตรวจสอบสิทธิ์
ขั้นตอนที่ 3: กำหนดค่าสภาพแวดล้อม
3.1 สร้างตัวแปรสภาพแวดล้อม
- ไปที่ Project Settings → "Environments"
- สร้างสภาพแวดล้อม:
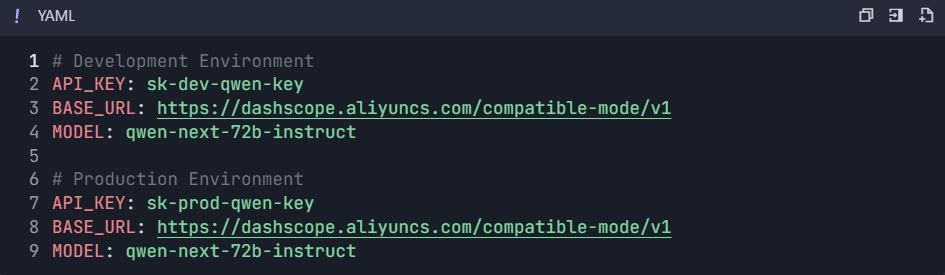
ระยะที่ 4: ชุดการทดสอบที่ครอบคลุม
ขั้นตอนที่ 4: สร้างสถานการณ์ทดสอบ
4.1 การทดสอบการสร้างข้อความพื้นฐาน
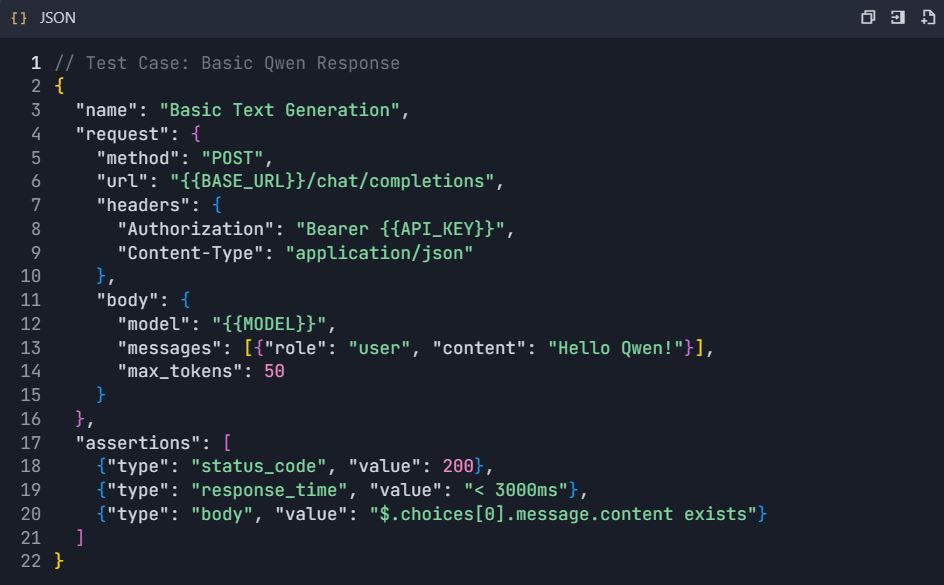
4.2 สถานการณ์การทดสอบขั้นสูง
ชุดทดสอบ: การทดสอบ Qwen API ที่ครอบคลุม
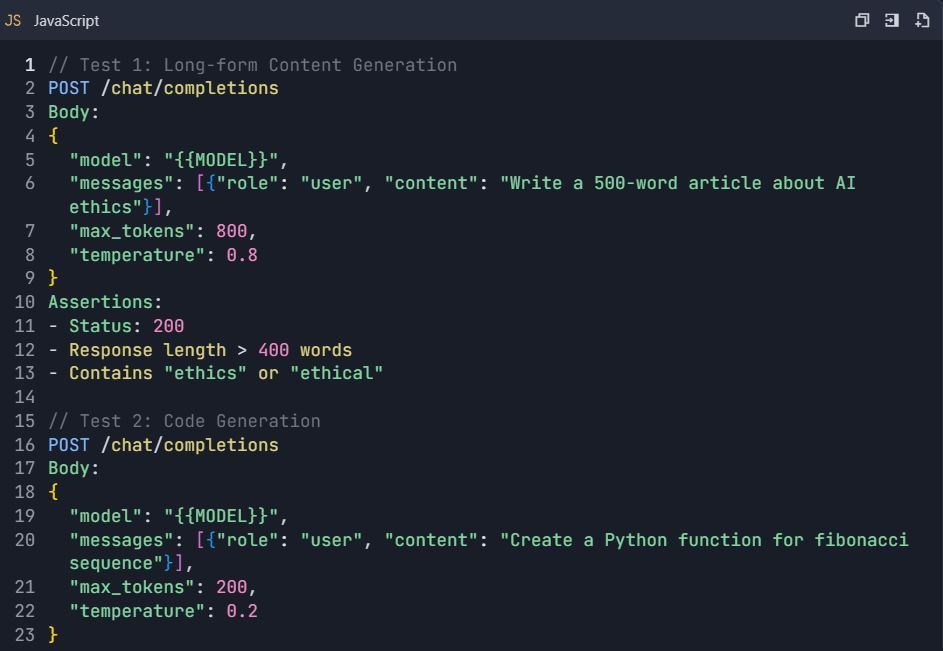
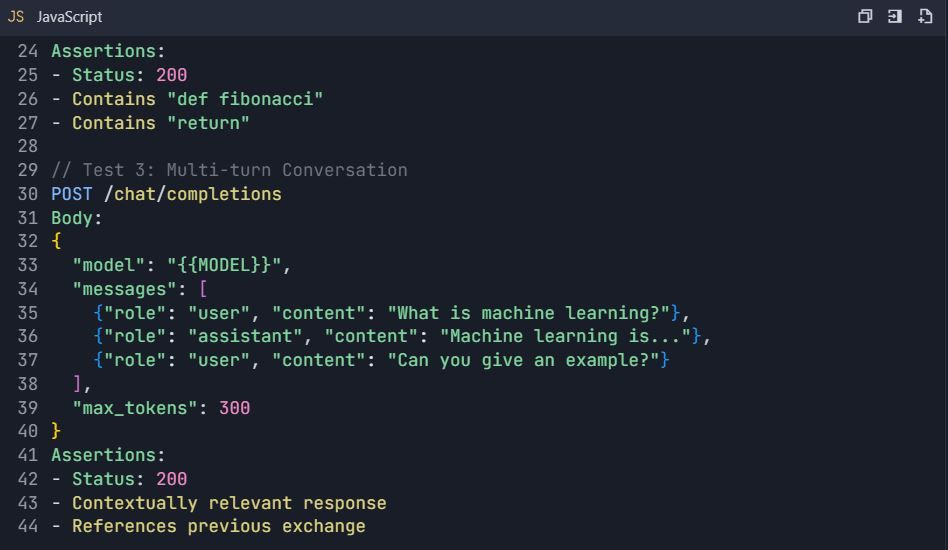
4.3 การทดสอบการจัดการข้อผิดพลาด
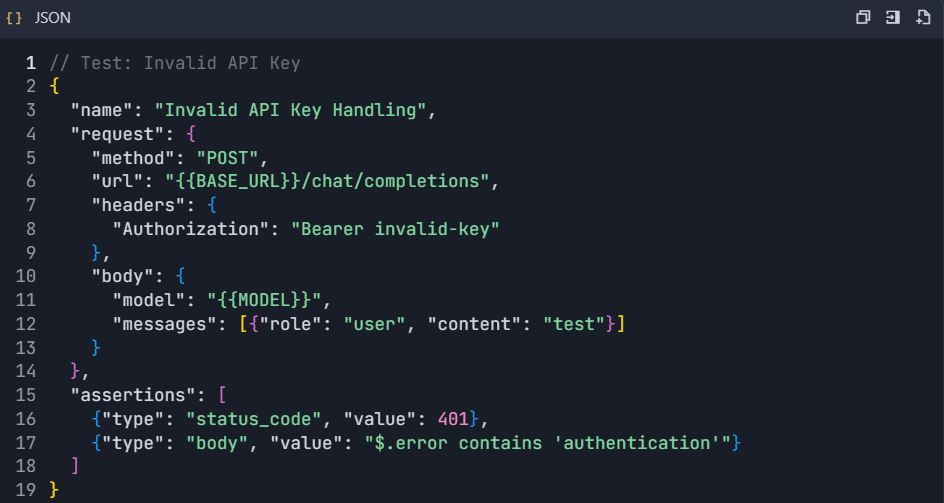
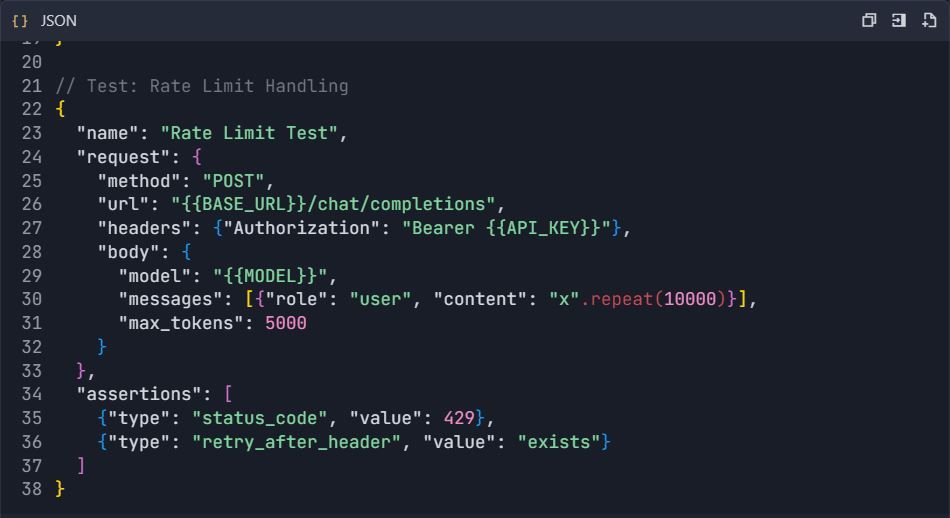
ระยะที่ 5: การสร้างเอกสาร
ขั้นตอนที่ 5: สร้างเอกสาร API อัตโนมัติ 5.1 สร้างโครงสร้างเอกสาร
- ไปที่ Project → "Documentation"
- สร้างส่วนต่างๆ:
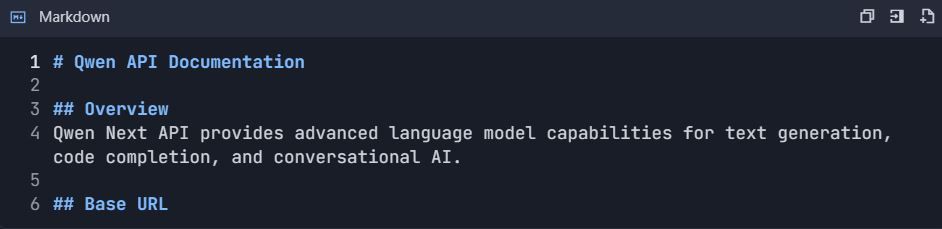
https://dashscope.aliyuncs.com/compatible-mode/v1

การอนุญาต: Bearer sk-[your-api-key]

5.2 API Explorer แบบโต้ตอบ
- กำหนดค่าตัวอย่างแบบโต้ตอบ:
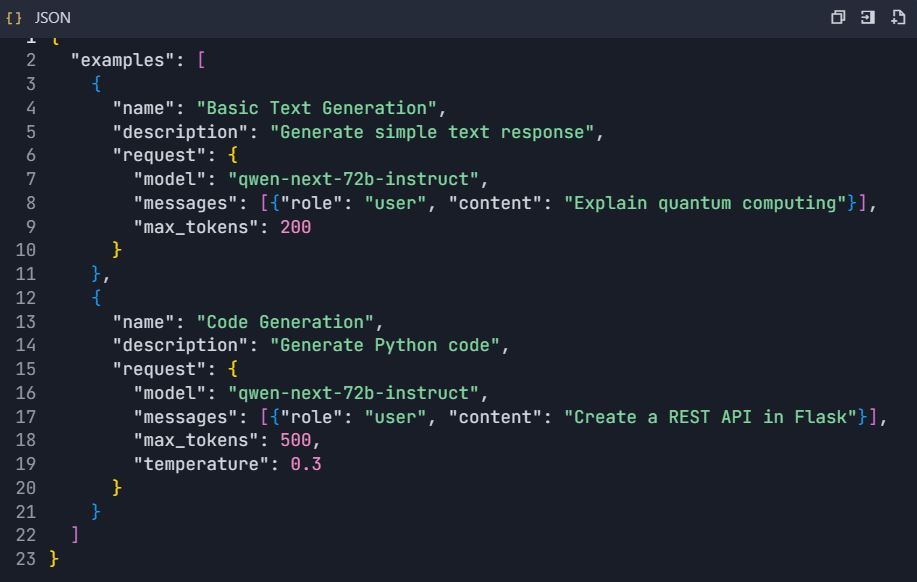
ระยะที่ 6: คุณสมบัติขั้นสูงและระบบอัตโนมัติ
ขั้นตอนที่ 6: เวิร์กโฟลว์การทดสอบอัตโนมัติ 6.1 การผสานรวม CI/CD
เวิร์กโฟลว์ GitHub Actions ( .github/workflows/qwen-tests.yml ):
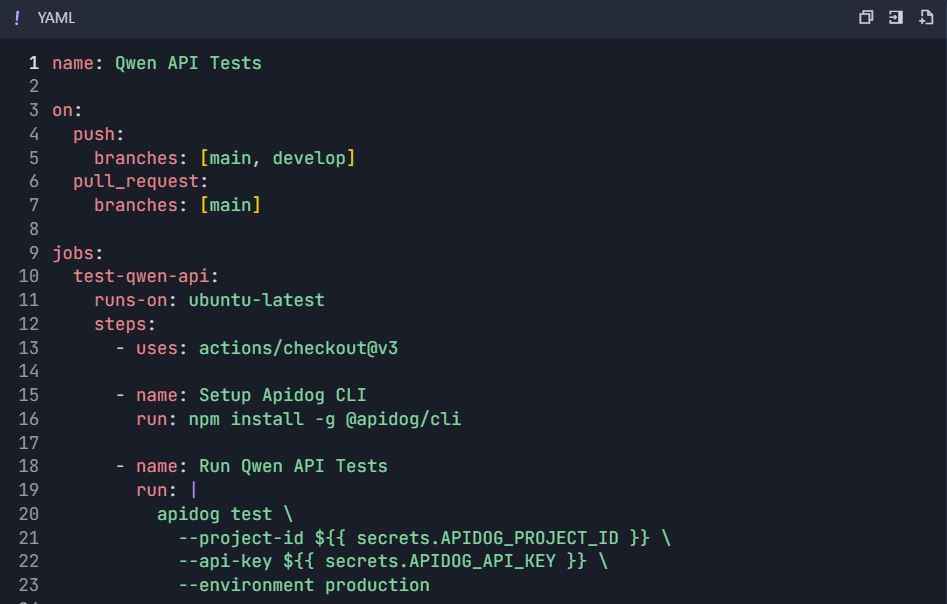
6.2 การทดสอบประสิทธิภาพ
- สร้างชุดทดสอบประสิทธิภาพ:

2. ตรวจสอบเมตริก:
- เวลาตอบสนอง (p50, p95, p99)
- ปริมาณงาน (คำขอ/วินาที)
- อัตราข้อผิดพลาด
- ประสิทธิภาพการใช้โทเค็น
6.3 การตั้งค่า Mock Server
- เปิดใช้งาน mock server:

2. กำหนด