

คุณเคยต้องการเรียกใช้โมเดล AI vision ที่ซับซ้อนบนเครื่องของคุณเอง โดยไม่ต้องพึ่งพาบริการคลาวด์ราคาแพง หรือกังวลเกี่ยวกับความเป็นส่วนตัวของข้อมูลหรือไม่? ถ้าใช่ คุณโชคดีแล้ว! วันนี้ เราจะมาเจาะลึกวิธีการเรียกใช้โมเดล Qwen 3 VL (Vision Language) บนเครื่องของคุณด้วย Ollama และเชื่อผมเถอะว่านี่จะเป็นตัวเปลี่ยนเกมสำหรับเวิร์กโฟลว์การพัฒนา AI ของคุณ
ก่อนที่เราจะลงลึกในเรื่องทางเทคนิค ผมขอถามคุณหน่อยว่า: คุณเบื่อกับการเจอข้อจำกัดอัตราการเรียกใช้ API, การจ่ายค่าใช้จ่ายที่สูงลิ่วสำหรับการอนุมานบนคลาวด์ หรือเพียงแค่ต้องการควบคุมโมเดล AI ของคุณมากขึ้นหรือไม่? หากคุณพยักหน้าตอบรับ คู่มือนี้ออกแบบมาเพื่อคุณโดยเฉพาะ นอกจากนี้ หากคุณกำลังมองหาเครื่องมืออันทรงพลังสำหรับทดสอบและดีบัก API AI ภายในเครื่องของคุณ ผมขอแนะนำให้ดาวน์โหลด Apidog ฟรี ซึ่งเป็นแพลตฟอร์มทดสอบ API ที่ยอดเยี่ยมซึ่งทำงานร่วมกับปลายทาง (endpoints) ภายในเครื่องของ Ollama ได้อย่างราบรื่น
ในคู่มือนี้ เราจะพาคุณไปดูทุกสิ่งที่คุณจำเป็นต้องรู้เพื่อเรียกใช้โมเดล Qwen 3 VL บนเครื่องของคุณโดยใช้ Ollama ตั้งแต่การติดตั้งไปจนถึงการอนุมาน การแก้ไขปัญหา และแม้แต่การผสานรวมกับเครื่องมืออย่าง Apidog เมื่อจบคู่มือฉบับสมบูรณ์นี้ คุณจะมี Qwen3-VL ที่เป็น Vision-Language Model ที่ทำงานได้อย่างสมบูรณ์ เป็นส่วนตัว และตอบสนองได้ดีบนเครื่องของคุณ และคุณจะได้รับความรู้ทั้งหมดที่จำเป็นในการนำไปผสานรวมกับโปรเจกต์ของคุณ
ดังนั้น รัดเข็มขัดให้พร้อม คว้าเครื่องดื่มแก้วโปรดของคุณ แล้วมาเริ่มต้นการเดินทางที่น่าตื่นเต้นนี้ไปด้วยกัน
ทำความเข้าใจ Qwen3-VL: โมเดล Vision-Language ที่ปฏิวัติวงการ

ทำไมต้อง Qwen 3 VL? และทำไมต้องเรียกใช้บนเครื่องของคุณ?
ก่อนที่เราจะเข้าสู่ขั้นตอนทางเทคนิค เรามาพูดถึง เหตุผลที่ Qwen 3 VL มีความสำคัญ และเหตุผลที่การเรียกใช้บนเครื่องของคุณเป็นการเปลี่ยนเกม
Qwen 3 VL เป็นส่วนหนึ่งของซีรีส์ Qwen ของ Alibaba แต่ได้รับการออกแบบมาโดยเฉพาะสำหรับ งานด้าน Vision-Language ซึ่งแตกต่างจาก LLM แบบดั้งเดิมที่เข้าใจเฉพาะข้อความ Qwen 3 VL สามารถ:
- วิเคราะห์รูปภาพและตอบคำถามเกี่ยวกับรูปภาพเหล่านั้น (“รูปภาพนี้มีอะไร?”)
- สร้างคำบรรยายภาพโดยละเอียด
- ดึงข้อมูลที่มีโครงสร้างจากแผนภูมิ แผนภาพ หรือเอกสาร
- รองรับ Multimodal RAG (retrieval-augmented generation) พร้อมบริบทภาพ
และเนื่องจากเป็นแบบ Open-weight (ภายใต้ใบอนุญาต Tongyi Qianwen) นักพัฒนาจึงสามารถ ใช้งาน ปรับเปลี่ยน และปรับใช้ได้อย่างอิสระ ตราบใดที่พวกเขายังคงปฏิบัติตามข้อกำหนดของใบอนุญาต
แล้วทำไมต้องเรียกใช้ บนเครื่องของคุณ?
- ความเป็นส่วนตัว: รูปภาพและข้อความแจ้งเตือนของคุณจะไม่ออกจากเครื่องของคุณ
- ค่าใช้จ่าย: ไม่มีค่าธรรมเนียม API หรือข้อจำกัดการใช้งาน
- การปรับแต่ง: Fine-tune, Quantize หรือผสานรวมกับไปป์ไลน์ของคุณเอง
- การเข้าถึงแบบออฟไลน์: เหมาะสำหรับสภาพแวดล้อมที่ปลอดภัยหรือไม่มีการเชื่อมต่ออินเทอร์เน็ต
แต่การปรับใช้บนเครื่องของคุณเคยหมายถึงการต้องจัดการกับเวอร์ชัน CUDA, สภาพแวดล้อม Python และ Dockerfile ขนาดใหญ่ แต่ Ollama ได้เข้ามาเปลี่ยนแปลงสิ่งนี้
รุ่นของโมเดล: มีให้เลือกสำหรับทุกกรณีการใช้งาน
Qwen3-VL มีขนาดหลากหลายเพื่อให้เหมาะกับการกำหนดค่าฮาร์ดแวร์และกรณีการใช้งานที่แตกต่างกัน ไม่ว่าคุณจะทำงานบนแล็ปท็อปน้ำหนักเบา หรือเข้าถึงเวิร์กสเตชันที่ทรงพลัง ก็มีโมเดล Qwen3-VL ที่ตอบสนองความต้องการของคุณได้อย่างสมบูรณ์แบบ
โมเดลแบบ Dense (สถาปัตยกรรมดั้งเดิม):
- Qwen3-VL-2B: เหมาะสำหรับอุปกรณ์ Edge และแอปพลิเคชันมือถือ
- Qwen3-VL-4B: สมดุลที่ดีระหว่างประสิทธิภาพและการใช้ทรัพยากร
- Qwen3-VL-8B: ยอดเยี่ยมสำหรับงานทั่วไปที่ต้องการการให้เหตุผลระดับปานกลาง
- Qwen3-VL-32B: งานระดับสูงที่ต้องการการให้เหตุผลที่แข็งแกร่งและบริบทที่กว้างขวาง
โมเดล Mixture-of-Experts (MoE) (สถาปัตยกรรมที่มีประสิทธิภาพ):
- Qwen3-VL-30B-A3B: ประสิทธิภาพสูงด้วยพารามิเตอร์ที่ใช้งานเพียง 3B
- Qwen3-VL-235B-A22B: แอปพลิเคชันขนาดใหญ่ที่มีพารามิเตอร์ทั้งหมด 235B แต่ใช้งานจริงเพียง 22B
ความสวยงามของโมเดล MoE คือการที่พวกมันจะเปิดใช้งานเฉพาะส่วนย่อยของเครือข่ายประสาท "ผู้เชี่ยวชาญ" สำหรับการอนุมานแต่ละครั้ง ทำให้สามารถมีจำนวนพารามิเตอร์มหาศาลในขณะที่ยังคงรักษาต้นทุนการคำนวณให้จัดการได้
Ollama: ประตูสู่ความเป็นเลิศด้าน AI ในเครื่องของคุณ
เมื่อเราเข้าใจแล้วว่า Qwen3-VL มีอะไรให้บ้าง เรามาพูดถึงเหตุผลที่ Ollama เป็นแพลตฟอร์มที่เหมาะสมที่สุดสำหรับการเรียกใช้โมเดลเหล่านี้บนเครื่องของคุณ ลองนึกภาพ Ollama เป็นเหมือนวาทยกรของวงออร์เคสตรา มันจะจัดการกระบวนการที่ซับซ้อนทั้งหมดที่เกิดขึ้นเบื้องหลัง เพื่อให้คุณสามารถมุ่งเน้นไปที่สิ่งที่สำคัญที่สุด: การใช้โมเดล AI ของคุณ
Ollama คืออะไร และทำไมจึงเหมาะสำหรับ Qwen 3 VL
Ollama เป็นเครื่องมือโอเพนซอร์สที่ช่วยให้คุณ เรียกใช้โมเดลภาษาขนาดใหญ่ (และตอนนี้คือโมเดล multimodal) บนเครื่องของคุณด้วยคำสั่งเดียว ลองนึกภาพว่าเป็น “Docker สำหรับ LLM” แต่ใช้ง่ายกว่านั้นอีก
คุณสมบัติหลัก:
- การเร่งความเร็ว GPU อัตโนมัติ (ผ่าน Metal บน macOS, CUDA บน Linux)
- ไลบรารีโมเดลในตัว (รวมถึง Llama 3, Mistral, Gemma และตอนนี้ Qwen)
- REST API สำหรับการผสานรวมที่ง่ายดาย
- น้ำหนักเบาและใช้งานง่ายสำหรับผู้เริ่มต้น
ที่สำคัญที่สุดคือ Ollama รองรับโมเดล Qwen 3 VL แล้ว รวมถึงรุ่นต่างๆ เช่น qwen3-vl:4b และ qwen3-vl:8b ซึ่งเป็นเวอร์ชันที่ถูก Quantize และปรับให้เหมาะสมสำหรับฮาร์ดแวร์ภายในเครื่อง ซึ่งหมายความว่าคุณสามารถเรียกใช้โมเดลเหล่านี้บน GPU ระดับผู้บริโภค หรือแม้แต่แล็ปท็อปที่ทรงพลังได้
ความมหัศจรรย์ทางเทคนิคเบื้องหลัง Ollama
เกิดอะไรขึ้นเบื้องหลังเมื่อคุณรันคำสั่ง Ollama? มันเหมือนกับการชมการเต้นรำที่จัดฉากไว้อย่างดีของกระบวนการทางเทคโนโลยี:
1.การดาวน์โหลดและแคชโมเดล: Ollama ดาวน์โหลดและแคชน้ำหนักโมเดลอย่างชาญฉลาด เพื่อให้มั่นใจว่าโมเดลที่ใช้งานบ่อยจะเริ่มต้นได้รวดเร็ว
2.การปรับแต่ง Quantization: โมเดลจะถูกปรับให้เหมาะสมกับการกำหนดค่าฮาร์ดแวร์ของคุณโดยอัตโนมัติ โดยเลือกวิธีการ Quantization ที่ดีที่สุด (4-bit, 8-bit ฯลฯ) สำหรับ GPU และ RAM ของคุณ
3.การจัดการหน่วยความจำ: เทคนิคการแมปหน่วยความจำขั้นสูงช่วยให้มั่นใจได้ถึงการใช้หน่วยความจำ GPU ที่มีประสิทธิภาพ ในขณะที่ยังคงรักษาประสิทธิภาพสูง
4.การประมวลผลแบบขนาน: Ollama ใช้ประโยชน์จากคอร์ CPU หลายตัวและสตรีม GPU เพื่อให้ได้ปริมาณงานสูงสุด
ข้อกำหนดเบื้องต้น: สิ่งที่คุณจะต้องมีก่อนการติดตั้ง
ก่อนที่เราจะติดตั้งอะไรก็ตาม มาตรวจสอบให้แน่ใจว่าระบบของคุณพร้อมแล้ว
ข้อกำหนดด้านฮาร์ดแวร์
- RAM: อย่างน้อย 16GB (แนะนำ 32GB สำหรับโมเดล 8B)
- GPU: NVIDIA GPU ที่มี VRAM 8GB+ (สำหรับ Linux) หรือ Apple Silicon Mac (M1/M2/M3 ที่มีหน่วยความจำรวม 16GB+)
- พื้นที่เก็บข้อมูล: พื้นที่ว่าง 10–20GB (โมเดลมีขนาดใหญ่!)
ข้อกำหนดด้านซอฟต์แวร์
- ระบบปฏิบัติการ: macOS (12+) หรือ Linux (แนะนำ Ubuntu 20.04+)
- Ollama: เวอร์ชันล่าสุด (v0.1.40+ สำหรับการรองรับ Qwen 3 VL)
- ทางเลือก: Docker (หากคุณต้องการการปรับใช้แบบ Containerized), Python (สำหรับการเขียนสคริปต์ขั้นสูง)
คู่มือการติดตั้งทีละขั้นตอน: เส้นทางสู่ความเป็นเลิศด้าน AI ในเครื่องของคุณ
ขั้นตอนที่ 1: การติดตั้ง Ollama - รากฐาน
มาเริ่มต้นด้วยรากฐานของการตั้งค่าทั้งหมดของเรา การติดตั้ง Ollama นั้นง่ายอย่างน่าประหลาดใจ มันถูกออกแบบมาให้ทุกคนเข้าถึงได้ ตั้งแต่มือใหม่ด้าน AI ไปจนถึงนักพัฒนาที่มีประสบการณ์
สำหรับผู้ใช้ macOS:
1.เยี่ยมชม ollama.com/download
2.ดาวน์โหลดตัวติดตั้ง macOS
3.เปิดไฟล์ที่ดาวน์โหลดมาแล้วลาก Ollama ไปยังโฟลเดอร์ Applications ของคุณ
4.เปิด Ollama จากโฟลเดอร์ Applications ของคุณ หรือค้นหาด้วย Spotlight
กระบวนการติดตั้งบน macOS นั้นราบรื่นอย่างเหลือเชื่อ และคุณจะเห็นไอคอน Ollama ปรากฏในแถบเมนูของคุณเมื่อการติดตั้งเสร็จสมบูรณ์
สำหรับผู้ใช้ Windows:
1.ไปที่ ollama.com/download
2.ดาวน์โหลดตัวติดตั้ง Windows (.exe file)
3.เรียกใช้ตัวติดตั้งด้วยสิทธิ์ผู้ดูแลระบบ
4.ทำตามวิซาร์ดการติดตั้ง (ใช้งานง่ายมาก)
5.เมื่อติดตั้งเสร็จแล้ว Ollama จะเริ่มทำงานโดยอัตโนมัติในเบื้องหลัง
ผู้ใช้ Windows อาจเห็นการแจ้งเตือนจาก Windows Defender ไม่ต้องกังวล นี่เป็นเรื่องปกติสำหรับการรันครั้งแรก เพียงแค่คลิก "อนุญาต" แล้ว Ollama ก็จะทำงานได้อย่างสมบูรณ์
สำหรับผู้ใช้ Linux:
ผู้ใช้ Linux มีสองทางเลือก:
ตัวเลือก A: สคริปต์การติดตั้ง (แนะนำ)
bash
curl -fsSL <https://ollama.com/install.sh> | sh
ตัวเลือก B: การติดตั้งด้วยตนเอง
bash
# Download the latest Ollama binarycurl -o ollama <https://ollama.com/download/ollama-linux-amd64>
# Make it executablechmod +x ollama
# Move to PATHsudo mv ollama /usr/local/bin/
ขั้นตอนที่ 2: การตรวจสอบการติดตั้งของคุณ
เมื่อติดตั้ง Ollama แล้ว มาตรวจสอบให้แน่ใจว่าทุกอย่างทำงานถูกต้อง ลองคิดว่านี่เป็นการทดสอบเบื้องต้นเพื่อให้แน่ใจว่ารากฐานของเราแข็งแกร่ง
เปิดเทอร์มินัลของคุณ (หรือ command prompt บน Windows) แล้วรัน:
bash
ollama --version
คุณควรเห็นผลลัพธ์ที่คล้ายกับ:
ollama version is 0.1.0
ถัดไป มาทดสอบฟังก์ชันพื้นฐานกัน:
bash
ollama serve
คำสั่งนี้จะเริ่มเซิร์ฟเวอร์ Ollama คุณควรเห็นผลลัพธ์ที่ระบุว่าเซิร์ฟเวอร์กำลังทำงานอยู่ที่ http://localhost:11434 ปล่อยให้เซิร์ฟเวอร์ทำงานต่อไป เราจะใช้มันเพื่อทดสอบการติดตั้ง Qwen3-VL ของเรา
ขั้นตอนที่ 3: การดึงและเรียกใช้โมเดล Qwen3-VL
มาถึงส่วนที่น่าตื่นเต้นแล้ว! มาดาวน์โหลดและเรียกใช้โมเดล Qwen3-VL ตัวแรกของเรากัน เราจะเริ่มต้นด้วยโมเดลขนาดเล็กเพื่อทดลอง จากนั้นจึงย้ายไปยังรุ่นที่ทรงพลังกว่า
การทดสอบด้วย Qwen3-VL-4B (จุดเริ่มต้นที่ดีเยี่ยม):
bash
ollama run qwen3-vl:4b
คำสั่งนี้จะ:
1.ดาวน์โหลดโมเดล Qwen3-VL-4B (ประมาณ 2.8GB)
2.ปรับให้เหมาะสมกับฮาร์ดแวร์ของคุณ
3.เริ่มเซสชันการสนทนาแบบโต้ตอบ
การเรียกใช้โมเดลรุ่นอื่นๆ:
หากคุณมีฮาร์ดแวร์ที่ทรงพลังกว่า ลองใช้ทางเลือกเหล่านี้:
bash
# สำหรับระบบ GPU 8GB+ollama run qwen3-vl:8b
# สำหรับระบบ RAM 16GB+ollama run qwen3-vl:32b
# สำหรับระบบไฮเอนด์ที่มี GPU หลายตัวollama run qwen3-vl:30b-a3b
# สำหรับประสิทธิภาพสูงสุด (ต้องใช้ฮาร์ดแวร์ที่จริงจัง)ollama run qwen3-vl:235b-a22b
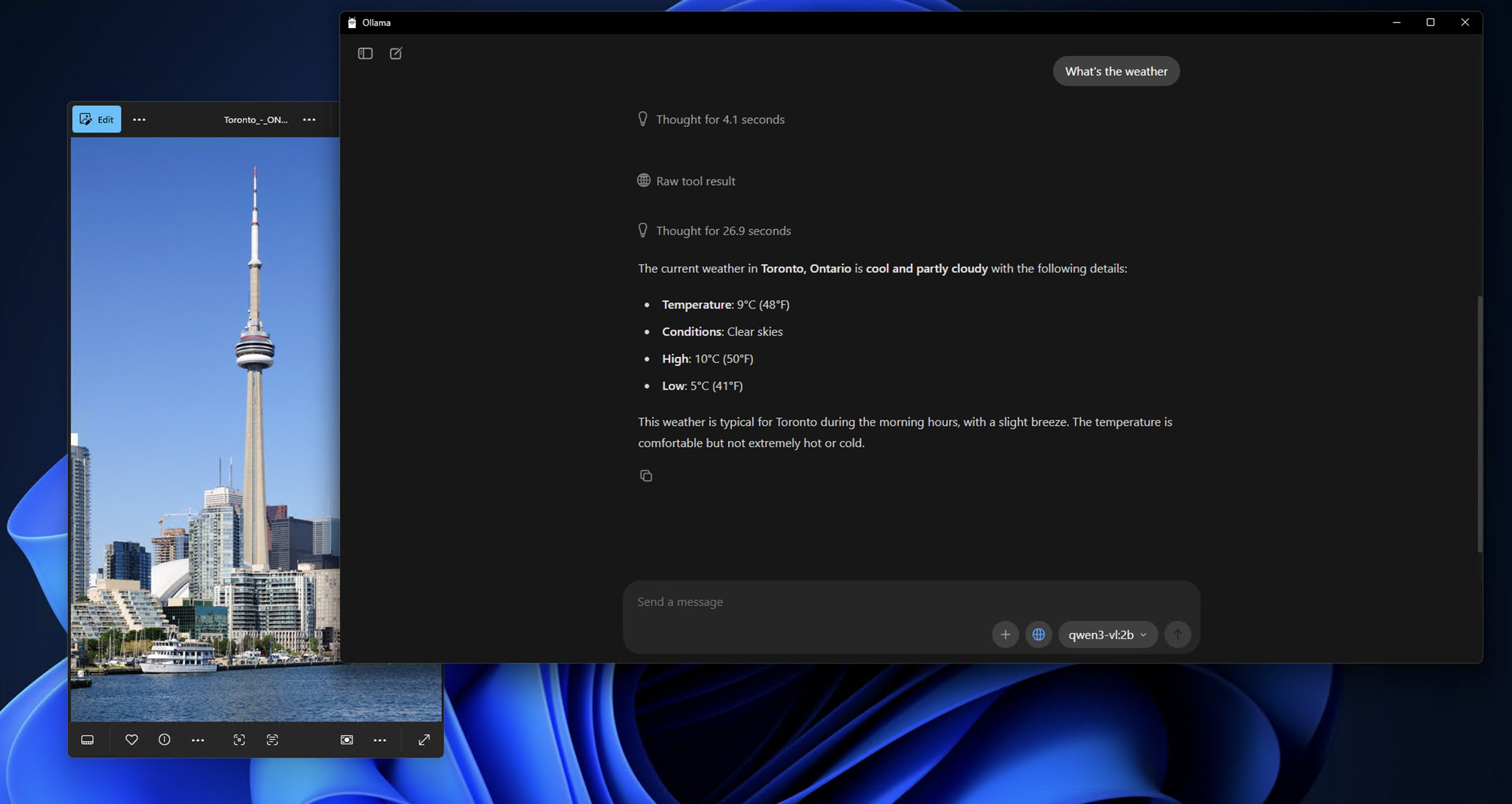
ขั้นตอนที่ 4: การโต้ตอบครั้งแรกกับ Qwen3-VL ในเครื่องของคุณ
เมื่อดาวน์โหลดและรันโมเดลแล้ว คุณจะเห็นข้อความแจ้งเตือนเช่นนี้:
Send a message (type /? for help)
มาทดสอบความสามารถของโมเดลด้วยการวิเคราะห์ภาพง่ายๆ กัน:
เตรียมรูปภาพสำหรับทดสอบ:
หารูปภาพใดก็ได้บนคอมพิวเตอร์ของคุณ ไม่ว่าจะเป็นรูปถ่าย สกรีนช็อต หรือภาพประกอบ สำหรับตัวอย่างนี้ ผมจะสมมติว่าคุณมีรูปภาพชื่อ test_image.jpg อยู่ในไดเรกทอรีปัจจุบันของคุณ

การทดสอบการสนทนาแบบโต้ตอบ:
bash
What do you see in this image? /path/to/your/image.jpg
ทางเลือก: การใช้ API สำหรับการทดสอบ
หากคุณต้องการทดสอบด้วยโปรแกรม คุณสามารถใช้ Ollama API ได้ นี่คือการทดสอบง่ายๆ โดยใช้ curl:
bash
curl <http://localhost:11434/api/generate> \\
-H "Content-Type: application/json" \\
-d '{
"model": "qwen3-vl:4b",
"prompt": "What is in this image? Describe it in detail.",
"images": ["base64_encoded_image_data_here"]
}'

ขั้นตอนที่ 5: ตัวเลือกการกำหนดค่าขั้นสูง
เมื่อคุณมีการติดตั้งที่ใช้งานได้แล้ว มาสำรวจตัวเลือกการกำหนดค่าขั้นสูงบางอย่างเพื่อปรับการตั้งค่าของคุณให้เหมาะสมกับฮาร์ดแวร์และกรณีการใช้งานเฉพาะของคุณ
การเพิ่มประสิทธิภาพหน่วยความจำ:
หากคุณประสบปัญหาเกี่ยวกับหน่วยความจำ คุณสามารถปรับพฤติกรรมการโหลดโมเดลได้:
bash
# ตั้งค่าการใช้หน่วยความจำสูงสุด (ปรับตาม RAM ของคุณ)export OLLAMA_MAX_LOADED_MODELS=1
# เปิดใช้งาน GPU offloadingexport OLLAMA_GPU=1
# ตั้งค่าพอร์ตที่กำหนดเอง (หาก 11434 ใช้งานอยู่แล้ว)export OLLAMA_HOST=0.0.0.0:11435
ตัวเลือก Quantization:
สำหรับระบบที่มี VRAM จำกัด คุณสามารถบังคับใช้ระดับ Quantization ที่เฉพาะเจาะจงได้:
bash
# โหลดโมเดลด้วย 4-bit quantization (เข้ากันได้ดีกว่า, ช้ากว่า)ollama run qwen3-vl:4b --format json
# โหลดด้วย 8-bit quantization (สมดุล)ollama run qwen3-vl:8b --format json
การกำหนดค่า Multi-GPU:
หากคุณมี GPU หลายตัว คุณสามารถระบุได้ว่าจะใช้ตัวใด:
bash
# ใช้ ID GPU ที่เฉพาะเจาะจง (Linux/macOS)export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
# บน macOS ที่มี Apple Silicon GPU หลายตัวexport CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
การทดสอบและการผสานรวมกับ Apidog: การรับประกันคุณภาพและประสิทธิภาพ

เมื่อคุณมี Qwen3-VL ทำงานบนเครื่องของคุณแล้ว มาพูดถึงวิธีการทดสอบและผสานรวมเข้ากับเวิร์กโฟลว์การพัฒนาของคุณอย่างเหมาะสม นี่คือจุดที่ Apidog โดดเด่นอย่างแท้จริงในฐานะเครื่องมือที่ขาดไม่ได้สำหรับนักพัฒนา AI
Apidog ไม่ใช่แค่เครื่องมือทดสอบ API ทั่วไป แต่เป็นแพลตฟอร์มที่ครอบคลุมซึ่งออกแบบมาโดยเฉพาะสำหรับเวิร์กโฟลว์การพัฒนา API สมัยใหม่ เมื่อทำงานกับโมเดล AI ในเครื่อง เช่น Qwen3-VL คุณต้องการเครื่องมือที่สามารถ:
1.จัดการโครงสร้าง JSON ที่ซับซ้อน: การตอบสนองของโมเดล AI มักจะมี JSON ซ้อนกันพร้อมประเภทเนื้อหาที่หลากหลาย
2.รองรับการอัปโหลดไฟล์: โมเดล AI จำนวนมากต้องการอินพุตเป็นรูปภาพ วิดีโอ หรือเอกสาร
3.จัดการการยืนยันตัวตน: การทดสอบปลายทางอย่างปลอดภัยด้วยการจัดการการยืนยันตัวตนที่เหมาะสม
4.สร้างการทดสอบอัตโนมัติ: การทดสอบการถดถอย (Regression testing) เพื่อความสอดคล้องของประสิทธิภาพโมเดล
5.สร้างเอกสารประกอบ: สร้างเอกสารประกอบ API โดยอัตโนมัติจากกรณีทดสอบของคุณ
การแก้ไขปัญหาที่พบบ่อย
แม้ว่า Ollama จะใช้งานง่าย แต่คุณอาจพบปัญหาได้ นี่คือวิธีแก้ไขสำหรับปัญหาที่พบบ่อย
❌ “ไม่พบโมเดล” หรือ “โมเดลไม่รองรับ”
- ตรวจสอบให้แน่ใจว่าคุณใช้ Ollama v0.1.40 หรือใหม่กว่า
- ลองรัน
ollama pull qwen3-vl:4bอีกครั้ง บางครั้งการดาวน์โหลดอาจล้มเหลวโดยไม่มีการแจ้งเตือน
❌ “หน่วยความจำไม่พอ” บน GPU
- ลองใช้ เวอร์ชัน 4B แทน 8B
- ปิดแอปพลิเคชันที่ใช้ GPU หนักอื่นๆ (Chrome, เกม ฯลฯ)
- บน Linux ให้ตรวจสอบ VRAM ด้วย
nvidia-smi
❌ รูปภาพไม่ถูกจดจำ
- ยืนยันว่ารูปภาพมีขนาด ไม่เกิน 4MB
- ใช้ PNG หรือ JPG (หลีกเลี่ยง HEIC, BMP)
- ตรวจสอบให้แน่ใจว่าสตริง base64 ไม่มีบรรทัดใหม่ (ใช้
base64 -w 0บน Linux)
❌ การอนุมานช้าบน CPU
- Qwen 3 VL มีขนาดใหญ่แม้จะถูก Quantize คาดว่าจะได้ 1–5 โทเค็น/วินาทีบน CPU
- อัปเกรดเป็น Apple Silicon หรือ NVIDIA GPU เพื่อเพิ่มความเร็ว 10 เท่า
กรณีการใช้งานจริงสำหรับ Qwen 3 VL ในเครื่องของคุณ
ทำไมต้องลำบากขนาดนี้? นี่คือแอปพลิเคชันที่ใช้งานได้จริง:
- Document Intelligence: ดึงตาราง ลายเซ็น หรือข้อความจากไฟล์ PDF ที่สแกน
- เครื่องมือช่วยการเข้าถึง: อธิบายรูปภาพสำหรับผู้ใช้ที่มีความบกพร่องทางสายตา
- บอทความรู้ภายใน: ตอบคำถามเกี่ยวกับแผนภาพภายในหรือแดชบอร์ด
- การศึกษา: สร้างติวเตอร์ที่อธิบายโจทย์คณิตศาสตร์จากรูปถ่าย
- การวิเคราะห์ความปลอดภัย: วิเคราะห์แผนภาพเครือข่ายหรือสกรีนช็อตสถาปัตยกรรมระบบ
เนื่องจากเป็นแบบ ในเครื่อง คุณจึงหลีกเลี่ยงการส่งภาพที่ละเอียดอ่อนไปยัง API ของบุคคลที่สาม ซึ่งเป็นประโยชน์อย่างมากสำหรับองค์กรและนักพัฒนาที่ใส่ใจเรื่องความเป็นส่วนตัว
บทสรุป: การเดินทางสู่ความเป็นเลิศด้าน AI ในเครื่องของคุณ
ขอแสดงความยินดี! คุณได้เสร็จสิ้นการเดินทางอันยิ่งใหญ่สู่โลกของ AI ในเครื่องของคุณด้วย Qwen3-VL และ Ollama แล้ว ณ ตอนนี้ คุณควรจะมี:
- การติดตั้ง Qwen3-VL ที่ทำงานได้อย่างสมบูรณ์ในเครื่องของคุณ
- การตั้งค่าการทดสอบที่ครอบคลุมด้วย Apidog
- ความเข้าใจอย่างลึกซึ้งเกี่ยวกับความสามารถและข้อจำกัดของโมเดล
- ความรู้เชิงปฏิบัติสำหรับการผสานรวมโมเดลเหล่านี้เข้ากับแอปพลิเคชันในโลกแห่งความเป็นจริง
- ทักษะการแก้ไขปัญหาเพื่อจัดการกับปัญหาทั่วไป
- กลยุทธ์การป้องกันความล้าสมัยเพื่อความสำเร็จอย่างต่อเนื่อง
การที่คุณมาถึงจุดนี้ได้แสดงให้เห็นถึงความมุ่งมั่นของคุณในการทำความเข้าใจและใช้ประโยชน์จากเทคโนโลยี AI ที่ล้ำสมัย คุณไม่ได้เพียงแค่ติดตั้งโมเดลเท่านั้น แต่คุณยังได้รับความเชี่ยวชาญในเทคโนโลยีที่กำลังปรับเปลี่ยนวิธีการที่เราโต้ตอบกับข้อมูลภาพและข้อความ
อนาคตคือ AI ในเครื่องของคุณ
สิ่งที่เราทำสำเร็จที่นี่เป็นมากกว่าแค่การตั้งค่าทางเทคนิค มันคือการก้าวไปสู่อนาคตที่ AI สามารถเข้าถึงได้ เป็นส่วนตัว และอยู่ภายใต้การควบคุมของแต่ละบุคคล เมื่อโมเดลเหล่านี้ยังคงพัฒนาและมีประสิทธิภาพมากขึ้น เรากำลังก้าวไปสู่โลกที่ความสามารถ AI ที่ซับซ้อนมีให้ทุกคน ไม่ว่าจะมีงบประมาณหรือความเชี่ยวชาญทางเทคนิคเท่าใดก็ตาม
โปรดจำไว้ว่า การเดินทางไม่ได้สิ้นสุดที่นี่ เทคโนโลยี AI พัฒนาอย่างรวดเร็ว และการรักษาความอยากรู้อยากเห็น การปรับตัว และการมีส่วนร่วมกับชุมชน จะช่วยให้คุณสามารถใช้ประโยชน์จากเครื่องมืออันทรงพลังเหล่านี้ได้อย่างมีประสิทธิภาพต่อไป
ข้อคิดสุดท้าย
การเรียกใช้ Qwen 3 VL บนเครื่องของคุณด้วย Ollama ไม่ใช่แค่การสาธิตเทคโนโลยี หรือเรื่องของความสะดวกสบายหรือการประหยัดค่าใช้จ่าย แต่มันคือภาพรวมของอนาคตของ AI บนอุปกรณ์ เมื่อโมเดลมีประสิทธิภาพมากขึ้นและฮาร์ดแวร์ทรงพลังขึ้น เราจะเห็นนักพัฒนาจำนวนมากขึ้นนำเสนอคุณสมบัติ multimodal ที่เป็นส่วนตัวโดยตรงในแอปของตน ตอนนี้คุณมีเครื่องมือในการสำรวจเทคโนโลยี AI โดยไม่มีข้อจำกัด ทดลองได้อย่างอิสระ และสร้างแอปพลิเคชันที่สำคัญสำหรับคุณและองค์กรของคุณ
การผสมผสานระหว่างความสามารถ multimodal ที่น่าประทับใจของ Qwen3-VL และอินเทอร์เฟซที่ใช้งานง่ายของ Ollama สร้างโอกาสในการสร้างสรรค์นวัตกรรมที่ก่อนหน้านี้มีให้เฉพาะบริษัทขนาดใหญ่ที่มีทรัพยากรมหาศาลเท่านั้น ตอนนี้คุณเป็นส่วนหนึ่งของชุมชนนักพัฒนาที่กำลังเติบโตซึ่งทำให้เทคโนโลยี AI เป็นประชาธิปไตย
และด้วยเครื่องมืออย่าง Ollama ที่ทำให้การปรับใช้ง่ายขึ้น และ Apidog ที่ช่วยปรับปรุงการพัฒนา API อุปสรรคในการเข้าถึงจึงไม่เคยต่ำขนาดนี้มาก่อน
ดังนั้น ไม่ว่าคุณจะเป็นนักพัฒนาอิสระ ผู้ก่อตั้งสตาร์ทอัพ หรือวิศวกรองค์กร ตอนนี้เป็นเวลาที่เหมาะสมที่สุดในการทดลองกับโมเดล Vision-Language อย่างปลอดภัย ราคาไม่แพง และในเครื่องของคุณเอง