
โมเดล gpt-oss-safeguard จาก OpenAI ตอบสนองความต้องการนี้โดยการเปิดใช้งานการให้เหตุผลตามนโยบายสำหรับงานการจัดประเภท วิศวกรนำโมเดลเหล่านี้ไปใช้เพื่อจัดประเภทเนื้อหาที่ผู้ใช้สร้างขึ้น ตรวจจับการละเมิด และรักษาความสมบูรณ์ของแพลตฟอร์ม
ทำความเข้าใจ GPT-OSS-Safeguard: คุณสมบัติและความสามารถ
วิศวกรของ OpenAI ได้พัฒนา gpt-oss-safeguard เป็นโมเดลการให้เหตุผลแบบ open-weight ที่ปรับแต่งมาสำหรับการจัดประเภทความปลอดภัย พวกเขาปรับแต่งโมเดลเหล่านี้จาก gpt-oss base และเผยแพร่ภายใต้ใบอนุญาต Apache 2.0 นักพัฒนาสามารถดาวน์โหลดโมเดลจาก Hugging Face และนำไปใช้งานได้อย่างอิสระ กลุ่มผลิตภัณฑ์ประกอบด้วย gpt-oss-safeguard-20b และ gpt-oss-safeguard-120b โดยตัวเลขแสดงถึงขนาดพารามิเตอร์
โมเดลเหล่านี้ประมวลผลอินพุตหลักสองอย่าง: นโยบายที่นักพัฒนากำหนด และเนื้อหาสำหรับการประเมิน ระบบใช้การให้เหตุผลแบบ chain-of-thought เพื่อตีความนโยบายและจัดประเภทเนื้อหา ตัวอย่างเช่น มันจะพิจารณาว่าข้อความของผู้ใช้ละเมิดกฎเกี่ยวกับการโกงในฟอรัมเกมหรือไม่ วิธีการนี้ช่วยให้สามารถอัปเดตนโยบายแบบไดนามิกได้โดยไม่ต้องฝึกซ้ำ ซึ่งแตกต่างจากตัวจัดประเภทแบบดั้งเดิม
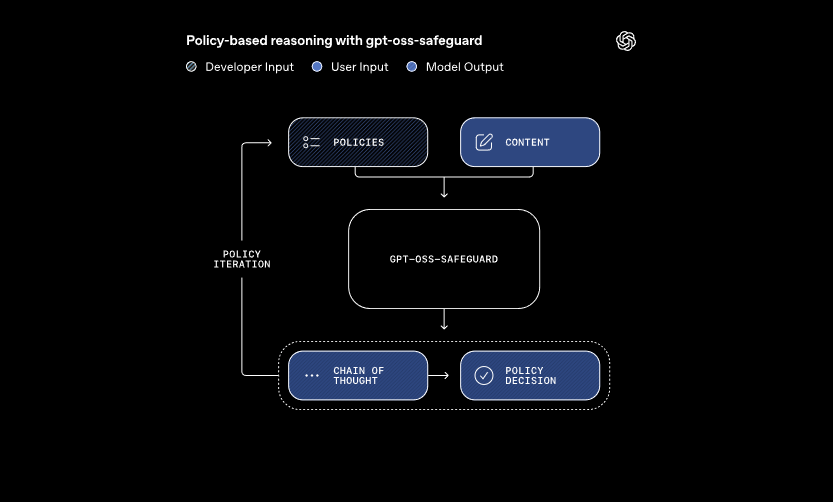
นอกจากนี้ gpt-oss-safeguard ยังรองรับหลายนโยบายพร้อมกัน นักพัฒนาสามารถป้อนกฎหลายข้อในการเรียกใช้การอนุมานเพียงครั้งเดียว และโมเดลจะประเมินเนื้อหาเทียบกับกฎทั้งหมด ความสามารถนี้ช่วยปรับปรุงขั้นตอนการทำงานสำหรับแพลตฟอร์มที่จัดการความเสี่ยงที่หลากหลาย เช่น ข้อมูลที่ผิดหรือคำพูดที่ก่อให้เกิดอันตราย อย่างไรก็ตาม ประสิทธิภาพอาจลดลงเล็กน้อยเมื่อเพิ่มนโยบาย ดังนั้นทีมงานจึงควรทดสอบการกำหนดค่าอย่างละเอียด
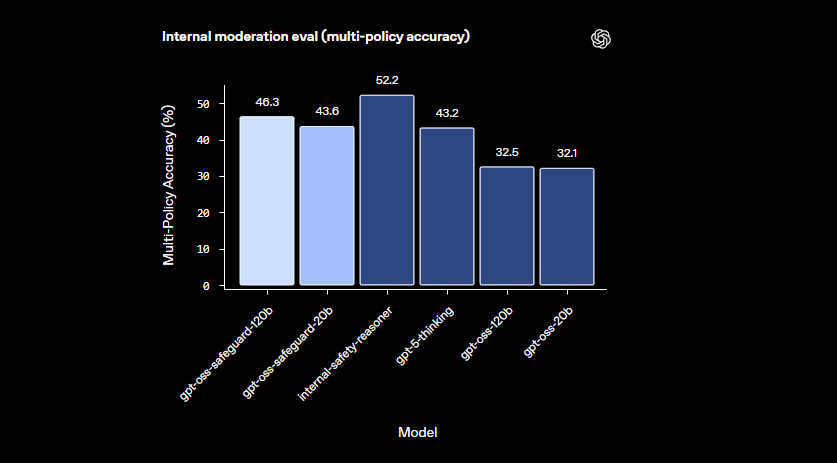
โมเดลมีความโดดเด่นในโดเมนที่ละเอียดอ่อนซึ่งตัวจัดประเภทขนาดเล็กทำได้ไม่ดีนัก พวกเขาสามารถจัดการกับอันตรายที่เกิดขึ้นใหม่ได้โดยการปรับให้เข้ากับนโยบายที่แก้ไขได้อย่างรวดเร็ว นอกจากนี้ เอาต์พุตแบบ chain-of-thought ยังให้ความโปร่งใส – นักพัฒนาสามารถตรวจสอบร่องรอยการให้เหตุผลเพื่อตรวจสอบการตัดสินใจ คุณสมบัตินี้มีค่าอย่างยิ่งสำหรับทีมงานที่ต้องการ AI ที่อธิบายได้
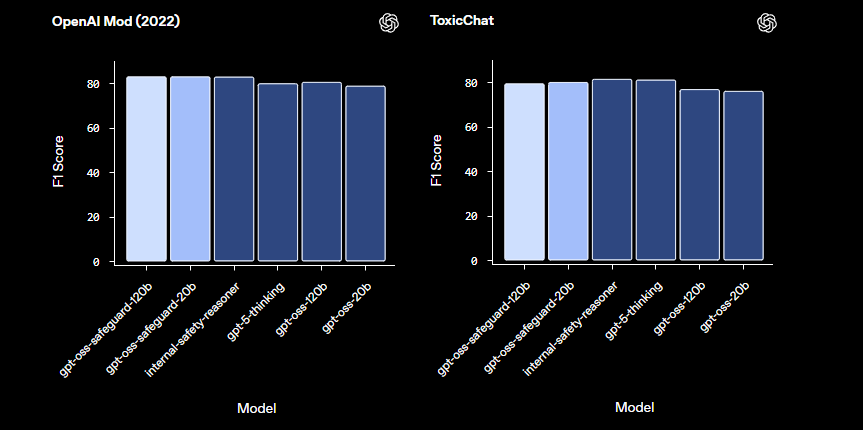
เมื่อเปรียบเทียบกับโมเดลความปลอดภัยสำเร็จรูป เช่น LlamaGuard แล้ว gpt-oss-safeguard มีความสามารถในการปรับแต่งที่มากกว่า มันหลีกเลี่ยงการจัดหมวดหมู่แบบตายตัว ทำให้องค์กรสามารถกำหนดเกณฑ์ของตนเองได้ ด้วยเหตุนี้ การผสานรวมจึงเหมาะสำหรับวิศวกรด้านความน่าเชื่อถือและความปลอดภัยที่สร้างไปป์ไลน์การดูแลเนื้อหาที่ปรับขนาดได้ เมื่อเราเข้าใจพื้นฐานแล้ว มาดำเนินการตั้งค่าสภาพแวดล้อมกันต่อ
การตั้งค่าสภาพแวดล้อมของคุณสำหรับการเข้าถึง GPT-OSS-Safeguard API
นักพัฒนาเริ่มต้นด้วยการเตรียมระบบของตนเพื่อรัน gpt-oss-safeguard เนื่องจากโมเดลเป็นแบบ open-weight คุณจึงสามารถปรับใช้ได้ทั้งแบบโลคัลหรือผ่านผู้ให้บริการโฮสต์ ความยืดหยุ่นนี้รองรับการตั้งค่าฮาร์ดแวร์ที่หลากหลาย ตั้งแต่เครื่องส่วนตัวไปจนถึงเซิร์ฟเวอร์คลาวด์
ขั้นแรก ให้ติดตั้งสิ่งที่จำเป็น Python 3.10 หรือสูงกว่าเป็นพื้นฐาน ใช้ pip เพื่อเพิ่มไลบรารีเช่น Hugging Face Transformers: pip install transformers สำหรับการอนุมานที่รวดเร็ว ให้รวม torch พร้อมการรองรับ CUDA หากคุณมี GPU ที่เข้ากันได้ วิศวกรที่มีฮาร์ดแวร์ NVIDIA สามารถเปิดใช้งานสิ่งนี้เพื่อการประมวลผลที่เร็วขึ้น
ถัดไป ดาวน์โหลดโมเดลจาก Hugging Face เข้าถึงคอลเลกชัน เลือก gpt-oss-safeguard-20b สำหรับความต้องการทรัพยากรที่น้อยลง หรือ gpt-oss-safeguard-120b เพื่อความแม่นยำที่เหนือกว่า คำสั่ง transformers-cli download openai/gpt-oss-safeguard-20b จะดึงไฟล์มา
หากต้องการเปิดเผย API ให้รันเซิร์ฟเวอร์โลคัล เครื่องมืออย่าง vLLM จัดการสิ่งนี้ได้อย่างมีประสิทธิภาพ ติดตั้ง vLLM ด้วย pip install vllm จากนั้น เปิดเซิร์ฟเวอร์: vllm serve openai/gpt-oss-safeguard-20b คำสั่งนี้จะเริ่มต้นปลายทางที่เข้ากันได้กับ OpenAI ที่ http://localhost:8000/v1 ในทำนองเดียวกัน Ollama ทำให้การปรับใช้ง่ายขึ้น: ollama run gpt-oss-safeguard:20b มันมี REST API สำหรับการผสานรวม
สำหรับการทดสอบแบบโลคัล LM Studio มีอินเทอร์เฟซที่ใช้งานง่าย รัน lms get openai/gpt-oss-safeguard-20b เพื่อดึงโมเดล ซอฟต์แวร์จำลอง OpenAI's Chat Completions API ทำให้สามารถเปลี่ยนโค้ดไปสู่การผลิตได้อย่างราบรื่น
ตัวเลือกแบบโฮสต์ช่วยลดความกังวลเกี่ยวกับฮาร์ดแวร์ ผู้ให้บริการเช่น Groq รองรับ gpt-oss-safeguard-20b ผ่าน API ของพวกเขา สมัครที่ https://console.groq.com สร้างคีย์ API และกำหนดเป้าหมายโมเดลในการร้องขอ ราคาเริ่มต้นที่ 0.075 ดอลลาร์ต่อล้านโทเค็นอินพุต OpenRouter ก็โฮสต์เช่นกัน
เมื่อตั้งค่าเสร็จแล้ว ให้ตรวจสอบการติดตั้ง ส่งคำขอทดสอบผ่าน curl: curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-safeguard-20b", "messages": [{"role": "system", "content": "Test policy"}, {"role": "user", "content": "Test content"}]}' การตอบสนองที่สำเร็จยืนยันความพร้อม เมื่อกำหนดค่าสภาพแวดล้อมแล้ว คุณจะสร้างนโยบายต่อไป
การสร้างนโยบายที่มีประสิทธิภาพสำหรับ GPT-OSS-Safeguard
นโยบายเป็นกระดูกสันหลังของการทำงานของ gpt-oss-safeguard นักพัฒนาเขียนนโยบายเหล่านี้เป็นข้อความแจ้งที่มีโครงสร้างซึ่งนำทางการจัดประเภท นโยบายที่ออกแบบมาอย่างดีจะเพิ่มพลังการให้เหตุผลของโมเดลให้สูงสุด ทำให้มั่นใจได้ถึงผลลัพธ์ที่แม่นยำและอธิบายได้
จัดโครงสร้างนโยบายของคุณด้วยส่วนที่แตกต่างกัน เริ่มต้นด้วยคำแนะนำ (Instructions) โดยระบุงานของโมเดล ตัวอย่างเช่น สั่งให้จัดประเภทเนื้อหาว่าละเมิด (1) หรือปลอดภัย (0) ตามด้วยคำจำกัดความ (Definitions) ชี้แจงคำสำคัญเช่น "ภาษาที่ลดทอนความเป็นมนุษย์" จากนั้น ให้ระบุเกณฑ์ (Criteria) สำหรับการละเมิดและเนื้อหาที่ปลอดภัย สุดท้าย ให้รวมตัวอย่าง (Examples) — ระบุกรณีขอบเขต 4-6 กรณีที่ติดป้ายกำกับไว้อย่างเหมาะสม
ใช้ Active Voice ในนโยบาย: "ตั้งค่าสถานะเนื้อหาที่ส่งเสริมความรุนแรง" แทนที่จะเป็นทางเลือกแบบ Passive รักษาภาษาให้แม่นยำ หลีกเลี่ยงความกำกวมเช่น "โดยทั่วไปไม่ปลอดภัย" หากเกิดความขัดแย้งระหว่างกฎ ให้กำหนดลำดับความสำคัญอย่างชัดเจน สำหรับสถานการณ์ที่มีหลายนโยบาย ให้รวมเข้าด้วยกันในข้อความระบบ
ควบคุมความลึกของการให้เหตุผลผ่านพารามิเตอร์ "reasoning_effort": ตั้งค่าเป็น "high" สำหรับกรณีที่ซับซ้อน หรือ "low" เพื่อความเร็ว รูปแบบ harmony ที่สร้างขึ้นใน gpt-oss-safeguard จะแยกการให้เหตุผลออกจากผลลัพธ์สุดท้าย สิ่งนี้ทำให้มั่นใจได้ว่าการตอบสนองของ API จะสะอาดตาในขณะที่ยังคงรักษาบันทึกการตรวจสอบไว้
ปรับความยาวนโยบายให้เหมาะสมที่ประมาณ 400-600 โทเค็น นโยบายที่สั้นเกินไปอาจเสี่ยงต่อการทำให้ง่ายเกินไป ในขณะที่นโยบายที่ยาวเกินไปอาจทำให้โมเดลสับสน ทดสอบซ้ำๆ: จัดประเภทเนื้อหาตัวอย่างและปรับปรุงตามผลลัพธ์ เครื่องมือเช่นตัวนับโทเค็นใน Hugging Face ช่วยได้ที่นี่
สำหรับรูปแบบเอาต์พุต ให้เลือกไบนารีเพื่อความเรียบง่าย: Return exactly 0 or 1. เพิ่มเหตุผลเพื่อความละเอียด: {"violation": 1, "rationale": "Explanation here"} โครงสร้าง JSON นี้สามารถผสานรวมกับระบบปลายน้ำได้อย่างง่ายดาย เมื่อคุณปรับปรุงนโยบายแล้ว ให้เปลี่ยนไปใช้การใช้งาน API
การใช้งาน API Calls ด้วย GPT-OSS-Safeguard
นักพัฒนาโต้ตอบกับ gpt-oss-safeguard ผ่านปลายทางที่เข้ากันได้กับ OpenAI ไม่ว่าจะแบบโลคัลหรือแบบโฮสต์ กระบวนการเป็นไปตามรูปแบบการสนทนาที่สมบูรณ์แบบมาตรฐาน
เตรียมไคลเอนต์ของคุณ ใน Python ให้ import OpenAI: from openai import OpenAI เริ่มต้นด้วย URL พื้นฐานและคีย์: client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy") สำหรับโลคัล หรือค่าเฉพาะของผู้ให้บริการ
สร้างข้อความ บทบาทของระบบเก็บนโยบาย: {"role": "system", "content": "Your detailed policy here"} บทบาทของผู้ใช้มีเนื้อหา: {"role": "user", "content": "Content to classify"}
เรียกใช้ API: completion = client.chat.completions.create(model="openai/gpt-oss-safeguard-20b", messages=messages, max_tokens=500, temperature=0.0) อุณหภูมิที่ 0 ทำให้มั่นใจได้ถึงผลลัพธ์ที่คาดเดาได้สำหรับงานด้านความปลอดภัย
แยกวิเคราะห์การตอบสนอง: result = completion.choices[0].message.content สำหรับเอาต์พุตที่มีโครงสร้าง ให้ใช้การแยกวิเคราะห์ JSON Groq ช่วยเพิ่มประสิทธิภาพนี้ด้วยการแคชนโยบาย — นำนโยบายกลับมาใช้ซ้ำในการเรียกใช้เพื่อลดต้นทุนได้ถึง 50%
จัดการการสตรีมสำหรับข้อเสนอแนะแบบเรียลไทม์: ตั้งค่า stream=True และวนซ้ำในแต่ละส่วน สิ่งนี้เหมาะสำหรับการดูแลเนื้อหาปริมาณมาก
รวมเครื่องมือหากจำเป็น แม้ว่า gpt-oss-safeguard จะเน้นการจัดประเภท กำหนดฟังก์ชันในพารามิเตอร์ tools สำหรับความสามารถเพิ่มเติม เช่น การดึงข้อมูลภายนอก
ตรวจสอบการใช้โทเค็น: อินพุตประกอบด้วยนโยบายและเนื้อหา เอาต์พุตเพิ่มการให้เหตุผล จำกัด max_tokens เพื่อป้องกันการโอเวอร์โฟลว์ เมื่อเชี่ยวชาญการเรียกใช้แล้ว ให้สำรวจตัวอย่าง
คุณสมบัติขั้นสูงใน GPT-OSS-Safeguard API
gpt-oss-safeguard นำเสนอเครื่องมือขั้นสูงสำหรับการควบคุมที่ละเอียดอ่อน การแคช Prompt บน Groq นำนโยบายกลับมาใช้ใหม่ ลดเวลาแฝงและค่าใช้จ่าย
ปรับ reasoning_effort ในข้อความระบบ: "Reasoning: high" สำหรับการวิเคราะห์เชิงลึก สิ่งนี้จัดการเนื้อหาที่คลุมเครือได้ดีขึ้น
ใช้ประโยชน์จากหน้าต่างบริบท 128k สำหรับการแชทหรือเอกสารขนาดยาว ป้อนการสนทนาทั้งหมดเพื่อการจัดประเภทแบบองค์รวม
ผสานรวมกับระบบขนาดใหญ่: ส่งออกผลลัพธ์ไปยังคิวการส่งต่อหรือการบันทึกข้อมูล ใช้ webhooks สำหรับการแจ้งเตือนแบบเรียลไทม์
ปรับแต่งเพิ่มเติมหากจำเป็น แม้ว่าฐานจะทำได้ดีในการปฏิบัติตามนโยบาย รวมกับโมเดลขนาดเล็กเพื่อการกรองล่วงหน้า ปรับการคำนวณให้เหมาะสม
เรื่องความปลอดภัย: รักษาความปลอดภัยคีย์ API และตรวจสอบการโจมตีแบบ Prompt Injection ตรวจสอบความถูกต้องของอินพุตเพื่อป้องกันการโจมตี
การปรับขนาด: ปรับใช้บนคลัสเตอร์ด้วย vLLM เพื่อปริมาณงานสูง ผู้ให้บริการเช่น Groq ส่งมอบ 1000+ โทเค็น/วินาที
คุณสมบัติเหล่านี้ยกระดับ gpt-oss-safeguard จากตัวจัดประเภทพื้นฐานไปสู่เครื่องมือระดับองค์กร อย่างไรก็ตาม ให้ปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดเพื่อผลลัพธ์ที่ดีที่สุด
แนวทางปฏิบัติที่ดีที่สุดและการเพิ่มประสิทธิภาพสำหรับ GPT-OSS-Safeguard
วิศวกรปรับปรุง gpt-oss-safeguard ให้เหมาะสมโดยการปรับปรุงนโยบาย ทดสอบด้วยชุดข้อมูลที่หลากหลาย วัดความแม่นยำด้วยเมตริกเช่น F1-score
ปรับสมดุลขนาดโมเดล: ใช้ 20b สำหรับความเร็ว 120b สำหรับความแม่นยำ ปรับลดความละเอียดของน้ำหนักโมเดลเพื่อลดการใช้หน่วยความจำ
ตรวจสอบประสิทธิภาพ: บันทึกร่องรอยการให้เหตุผลสำหรับการตรวจสอบ ปรับอุณหภูมิให้น้อยที่สุด — 0.0 เหมาะสำหรับความต้องการที่คาดเดาได้
จัดการข้อจำกัด: โมเดลอาจประสบปัญหาในโดเมนที่มีความเชี่ยวชาญสูง เสริมด้วยข้อมูลโดเมน
ตรวจสอบการใช้งานอย่างมีจริยธรรม: ปรับนโยบายให้สอดคล้องกับข้อบังคับ หลีกเลี่ยงอคติโดยการกระจายตัวอย่าง
อัปเดตเป็นประจำ: เมื่อ OpenAI พัฒนา gpt-oss-safeguard ให้รวมการปรับปรุง
การจัดการต้นทุน: สำหรับ API ที่โฮสต์ ให้ติดตามค่าใช้จ่ายโทเค็น การปรับใช้แบบโลคัลช่วยลดค่าใช้จ่าย
ด้วยการนำแนวทางปฏิบัติเหล่านี้ไปใช้ คุณจะเพิ่มประสิทธิภาพสูงสุด โดยสรุป gpt-oss-safeguard ช่วยเสริมสร้างระบบความปลอดภัยที่แข็งแกร่ง
สรุป: การผสานรวม GPT-OSS-Safeguard เข้ากับขั้นตอนการทำงานของคุณ
นักพัฒนาใช้ gpt-oss-safeguard เพื่อสร้างตัวจัดประเภทความปลอดภัยที่ปรับเปลี่ยนได้ ตั้งแต่การตั้งค่าไปจนถึงการใช้งานขั้นสูง คู่มือนี้จะให้ความรู้ทางเทคนิคแก่คุณ ใช้งานนโยบาย ดำเนินการเรียกใช้ API และเพิ่มประสิทธิภาพตามความต้องการของคุณ เมื่อแพลตฟอร์มพัฒนาขึ้น gpt-oss-safeguard จะปรับตัวได้อย่างราบรื่น ทำให้มั่นใจได้ถึงสภาพแวดล้อมที่ปลอดภัย