
นักพัฒนาซอฟต์แวร์ต่างแสวงหาเครื่องมืออันทรงพลังเพื่อสร้างแอปพลิเคชันอัจฉริยะอยู่เสมอ OpenAI ตอบสนองความต้องการนี้ด้วยการเปิดตัว GPT-OSS ซึ่งเป็นชุดโมเดลภาษาแบบ open-weight ที่มีความสามารถในการให้เหตุผลขั้นสูง โมเดลเหล่านี้ รวมถึง gpt-oss-120b และ gpt-oss-20b ช่วยให้สามารถปรับแต่งและนำไปใช้งานได้ในสภาพแวดล้อมที่หลากหลาย ผู้ใช้สามารถเข้าถึงโมเดลเหล่านี้ผ่าน API ที่จัดหาโดยแพลตฟอร์มโฮสติ้ง ซึ่งช่วยให้สามารถผสานรวมเข้ากับโปรเจกต์ได้อย่างราบรื่น
ในการเริ่มต้นใช้งาน GPT-OSS API นักพัฒนาสามารถเข้าถึงได้ผ่านผู้ให้บริการ เช่น OpenRouter หรือ Together AI แพลตฟอร์มเหล่านี้เป็นผู้โฮสต์โมเดลและเปิดเผยเอนด์พอยต์มาตรฐานที่เข้ากันได้กับรูปแบบ API ของ OpenAI ความเข้ากันได้นี้ช่วยลดความซับซ้อนในการย้ายข้อมูลจากโมเดลที่เป็นกรรมสิทธิ์
GPT-OSS คืออะไร? คุณสมบัติและความสามารถหลัก
OpenAI ออกแบบ GPT-OSS ให้เป็นตระกูลของโมเดล Mixture-of-Experts (MoE) สถาปัตยกรรมนี้จะเปิดใช้งานเพียงส่วนย่อยของพารามิเตอร์ต่อโทเค็น ซึ่งช่วยเพิ่มประสิทธิภาพ ตัวอย่างเช่น gpt-oss-120b มีพารามิเตอร์รวม 117 พันล้านตัว แต่เปิดใช้งานเพียง 5.1 พันล้านตัวต่อโทเค็น ในทำนองเดียวกัน gpt-oss-20b ใช้พารามิเตอร์ 21 พันล้านตัว โดยมี 3.6 พันล้านตัวที่เปิดใช้งาน
โมเดลเหล่านี้ใช้โครงสร้างแบบ Transformer-based ที่มีเลเยอร์ความสนใจแบบหนาแน่นและแบบเบาบางสลับกัน พวกมันรวม Rotary Positional Embeddings (RoPE) เพื่อจัดการกับบริบทที่ยาวได้ถึง 128,000 โทเค็น นักพัฒนาจะได้รับประโยชน์จากสิ่งนี้ในแอปพลิเคชันที่ต้องการอินพุตจำนวนมาก เช่น การสรุปเอกสาร
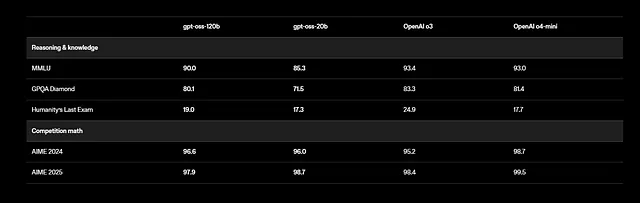
นอกจากนี้ GPT-OSS ยังรองรับงานหลายภาษา แม้ว่าการฝึกอบรมจะเน้นภาษาอังกฤษโดยเน้นข้อมูล STEM และการเขียนโค้ด ผลการทดสอบมาตรฐานแสดงให้เห็นผลลัพธ์ที่น่าประทับใจ: gpt-oss-120b ได้คะแนน 94.2% ใน MMLU (Massive Multitask Language Understanding) และ 96.6% ใน AIME (American Invitational Mathematics Examination) มันมีประสิทธิภาพเหนือกว่าโมเดลอย่าง o4-mini ในการสอบถามที่เกี่ยวข้องกับสุขภาพและคณิตศาสตร์เชิงแข่งขัน
นักพัฒนาใช้คุณสมบัติการเรียกใช้เครื่องมือ (tool calling) ซึ่งโมเดลจะเรียกใช้ฟังก์ชันภายนอก เช่น การค้นหาเว็บหรือการดำเนินการโค้ด ความสามารถแบบ agentic นี้ช่วยให้สามารถสร้างระบบอัตโนมัติได้ ตัวอย่างเช่น โมเดลสามารถเชื่อมโยงการเรียกใช้เครื่องมือหลายรายการในการตอบสนองเดียวเพื่อแก้ไขปัญหาทีละขั้นตอน
นอกจากนี้ โมเดลยังปฏิบัติตามใบอนุญาต Apache 2.0 ซึ่งอนุญาตให้แก้ไขและนำไปใช้งานได้ฟรี OpenAI มีน้ำหนักโมเดล (weights) ให้ดาวน์โหลดบน Hugging Face ซึ่งถูกควอนไทซ์ในรูปแบบ MXFP4 เพื่อลดการใช้หน่วยความจำ ผู้ใช้สามารถรันโมเดลเหล่านี้ได้ทั้งแบบโลคอลหรือผ่านผู้ให้บริการคลาวด์
อย่างไรก็ตาม มีข้อควรพิจารณาด้านความปลอดภัย OpenAI ดำเนินการประเมินภายใต้ Preparedness Framework ของตน โดยทดสอบความเสี่ยงต่างๆ เช่น ข้อมูลที่บิดเบือน นักพัฒนาควรใช้มาตรการป้องกัน เช่น การกรองผลลัพธ์ เพื่อลดปัญหา
โดยสรุปแล้ว GPT-OSS ผสมผสานพลังเข้ากับการเข้าถึงได้ง่าย ลักษณะที่เปิดกว้างของมันส่งเสริมการมีส่วนร่วมของชุมชน ซึ่งนำไปสู่การปรับปรุงที่รวดเร็ว ถัดไป เราจะระบุผู้ให้บริการที่เสนอการเข้าถึง API สำหรับโมเดลเหล่านี้
การเลือกผู้ให้บริการสำหรับการเข้าถึง GPT-OSS API
มีหลายแพลตฟอร์มที่เป็นผู้โฮสต์โมเดล GPT-OSS และมีเอนด์พอยต์ API ให้บริการ นักพัฒนาสามารถเลือกได้ตามความต้องการ เช่น ความเร็ว ค่าใช้จ่าย และความสามารถในการปรับขนาด ตัวอย่างเช่น OpenRouter เสนอ gpt-oss-120b ด้วยราคาที่แข่งขันได้และผสานรวมได้ง่าย
Together AI เป็นอีกทางเลือกหนึ่งที่เน้นการนำไปใช้งานในระดับองค์กร มันรองรับโมเดลผ่านเอนด์พอยต์ /v1/chat/completions ซึ่งเข้ากันได้กับไคลเอนต์ของ OpenAI นักพัฒนาสามารถส่งเพย์โหลด JSON ที่ระบุข้อความ, max_tokens และ temperature
นอกจากนี้ Fireworks AI และ Cerebras ยังให้การอนุมาน (inference) ที่ความเร็วสูง Cerebras สามารถทำได้สูงสุดถึง 3,000 โทเค็นต่อวินาที ซึ่งเหมาะสำหรับแอปพลิเคชันแบบเรียลไทม์ ราคาแตกต่างกันไป: OpenRouter คิดค่าบริการประมาณ $0.15 ต่อล้านโทเค็นอินพุต ในขณะที่ Together AI เสนออัตราที่คล้ายกันพร้อมส่วนลดสำหรับการใช้งานจำนวนมาก
นักพัฒนายังพิจารณาการโฮสต์ด้วยตนเองเพื่อความเป็นส่วนตัว เครื่องมืออย่าง vLLM หรือ Ollama ช่วยให้สามารถรัน GPT-OSS บนเซิร์ฟเวอร์โลคอล โดยเปิดเผย API ตัวอย่างเช่น vLLM ให้บริการโมเดลด้วยเส้นทางที่เข้ากันได้กับ OpenAI โดยต้องใช้คำสั่งเดียวในการเริ่มต้น
อย่างไรก็ตาม ผู้ให้บริการคลาวด์ช่วยให้การปรับขนาดทำได้ง่ายขึ้น AWS, Azure และ Vercel ผสานรวม GPT-OSS ผ่านความร่วมมือกับ OpenAI ตัวเลือกเหล่านี้จัดการการกระจายโหลด (load balancing) และการปรับขนาดอัตโนมัติ (auto-scaling) โดยอัตโนมัติ
นอกจากนี้ ให้ประเมินความหน่วง (latency) gpt-oss-20b เหมาะสำหรับอุปกรณ์ปลายทาง (edge devices) ที่มีความต้องการต่ำกว่า ในขณะที่ gpt-oss-120b ต้องการ GPU เช่น NVIDIA H100 ผู้ให้บริการจะปรับแต่งสำหรับฮาร์ดแวร์ เพื่อให้มั่นใจถึงประสิทธิภาพที่สม่ำเสมอ
กล่าวโดยสรุป ผู้ให้บริการที่เหมาะสมจะสอดคล้องกับเป้าหมายของโปรเจกต์ เมื่อเลือกได้แล้ว ให้ดำเนินการขอข้อมูลประจำตัว API ต่อไป
การขอสิทธิ์เข้าถึง API และการตั้งค่าสภาพแวดล้อมของคุณ
นักพัฒนาเริ่มต้นด้วยการลงทะเบียนบนเว็บไซต์ของผู้ให้บริการ สำหรับ OpenRouter ให้ไปที่ openrouter.ai สร้างบัญชี และไปที่ส่วน Keys สร้างคีย์ API ใหม่ ตั้งชื่อเพื่ออ้างอิง และคัดลอกอย่างปลอดภัย
ถัดไป ติดตั้งไลบรารีไคลเอนต์ ใน Python ใช้ pip เพื่อเพิ่ม openai: pip install openai กำหนดค่าไคลเอนต์ด้วย base URL และคีย์ ตัวอย่างเช่น:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
การตั้งค่านี้ช่วยให้สามารถส่งคำขอไปยังโมเดล gpt-oss ได้
นอกจากนี้ สำหรับ Together AI ให้ใช้ SDK ของพวกเขา: pip install together เริ่มต้นด้วย:
import together
together.api_key = "your_together_api_key"
ทดสอบการเชื่อมต่อโดยการแสดงรายการโมเดลหรือส่งคำถามง่ายๆ
อย่างไรก็ตาม ให้ตรวจสอบฮาร์ดแวร์หากทำการโฮสต์ด้วยตนเอง ดาวน์โหลดน้ำหนักโมเดล (weights) จาก Hugging Face: huggingface-cli download openai/gpt-oss-120b จากนั้น ใช้ vLLM เพื่อให้บริการ: vllm serve openai/gpt-oss-120b
นอกจากนี้ ให้ตั้งค่าตัวแปรสภาพแวดล้อม (environment variables) เพื่อความปลอดภัย จัดเก็บคีย์ในไฟล์ .env และโหลดด้วยไลบรารี dotenv
ในกรณีที่เกิดปัญหา ให้ตรวจสอบเอกสารของผู้ให้บริการสำหรับข้อจำกัดอัตรา (rate limits) หรือข้อผิดพลาดในการตรวจสอบสิทธิ์ การเตรียมการนี้ช่วยให้มั่นใจได้ถึงการโต้ตอบ API ที่ราบรื่น
การเรียกใช้ API ครั้งแรกของคุณไปยัง GPT-OSS
นักพัฒนาสร้างคำขอโดยใช้เอนด์พอยต์ chat completions ระบุโมเดล เช่น "openai/gpt-oss-120b" ในเพย์โหลด
สำหรับการเรียกใช้พื้นฐาน ให้เตรียมข้อความเป็นรายการของพจนานุกรม แต่ละรายการประกอบด้วยบทบาท (system, user, assistant) และเนื้อหา
นี่คือตัวอย่างใน Python:
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
สิ่งนี้จะสร้างการตอบสนองที่อธิบายแนวคิดทางเทคนิค
นอกจากนี้ ให้ปรับพารามิเตอร์เพื่อควบคุม Temperature มีอิทธิพลต่อความคิดสร้างสรรค์ – ค่าที่ต่ำกว่าจะให้ผลลัพธ์ที่กำหนดได้ Top_p จำกัดการสุ่มโทเค็น ในขณะที่ presence_penalty จะยับยั้งการทำซ้ำ
ถัดไป รวมการเรียกใช้เครื่องมือ (tool calling) กำหนดเครื่องมือในคำขอ:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
โมเดลจะตอบกลับด้วยการเรียกใช้เครื่องมือ ซึ่งนักพัฒนาจะดำเนินการและป้อนกลับ
อย่างไรก็ตาม ให้จัดการการตอบสนองอย่างระมัดระวัง แยกวิเคราะห์ JSON สำหรับเนื้อหา, finish_reason และสถิติการใช้งาน เช่น จำนวนโทเค็น
นอกจากนี้ สำหรับ chain-of-thought ให้พร้อมต์ด้วย "Think step by step." กำหนดความพยายามในการให้เหตุผล (reasoning effort) ในข้อความระบบ: "reasoning_effort: medium"
ทดลองใช้ gpt-oss-20b สำหรับการทดสอบที่รวดเร็วขึ้น: แทนที่ชื่อโมเดลในการเรียกใช้
ในสถานการณ์ขั้นสูง ให้สตรีมการตอบสนองโดยใช้ stream=True สำหรับเอาต์พุตแบบเรียลไทม์
ขั้นตอนเหล่านี้สร้างทักษะพื้นฐาน ตอนนี้ ให้ผสานรวมเครื่องมือทดสอบเช่น Apidog
การผสานรวม Apidog เพื่อการทดสอบ GPT-OSS API อย่างมีประสิทธิภาพ
นักพัฒนาอาศัย Apidog ในการทดสอบและดีบักการโต้ตอบ API เครื่องมือนี้มีอินเทอร์เฟซที่ใช้งานง่ายสำหรับการส่งคำขอไปยังเอนด์พอยต์ gpt-oss
ขั้นแรก ติดตั้ง Apidog จากเว็บไซต์ของพวกเขา สร้างโปรเจกต์ใหม่และเพิ่มเอนด์พอยต์ API เช่น https://openrouter.ai/api/v1/chat/completions
ถัดไป กำหนดค่าส่วนหัว (headers): เพิ่ม Authorization ด้วย Bearer token และ Content-Type เป็น application/json
นอกจากนี้ ให้สร้างเนื้อหาคำขอ (request body) ใช้ตัวแก้ไข JSON ของ Apidog เพื่อป้อนโมเดล, ข้อความ และพารามิเตอร์ ตัวอย่างเช่น ทดสอบการเรียกใช้ gpt-oss สำหรับการสร้างโค้ด
Apidog แสดงผลการตอบสนองเป็นภาพ โดยเน้นข้อผิดพลาดหรือความสำเร็จ มันรองรับตัวแปรสภาพแวดล้อม (environment variables) สำหรับการสลับคีย์ API ระหว่างผู้ให้บริการ
อย่างไรก็ตาม ให้ใช้ประโยชน์จากคอลเลกชันเพื่อจัดระเบียบการทดสอบ จัดกลุ่มการสอบถาม GPT-OSS ตามงาน เช่น การให้เหตุผลหรือการใช้เครื่องมือ และรันเป็นชุด
นอกจากนี้ Apidog ยังสร้างส่วนย่อยโค้ด (code snippets) ในภาษาต่างๆ เช่น Python หรือ cURL จากคำขอของคุณ ซึ่งช่วยเร่งการพัฒนา
สำหรับการทำงานร่วมกัน ให้แชร์โปรเจกต์กับทีม สิ่งนี้ช่วยให้มั่นใจได้ถึงการทดสอบการผสานรวม gpt-oss ที่สอดคล้องกัน
ในทางปฏิบัติ ให้ใช้ Apidog เพื่อตรวจสอบการใช้โทเค็นและปรับแต่งพร้อมต์ ซึ่งช่วยลดค่าใช้จ่าย
โดยรวมแล้ว Apidog ช่วยเพิ่มประสิทธิภาพการทำงานเมื่อทำงานกับ GPT-OSS API
การใช้งานขั้นสูง: การปรับแต่งและการนำไปใช้งาน
นักพัฒนาสามารถ fine-tune GPT-OSS สำหรับโดเมนเฉพาะได้ ใช้ไลบรารี transformers ของ Hugging Face เพื่อโหลดน้ำหนักโมเดล (weights) และฝึกอบรมบนชุดข้อมูลที่กำหนดเอง
ตัวอย่างเช่น เตรียมข้อมูลในรูปแบบ JSONL ที่มีคู่ prompt-completion รันสคริปต์ fine-tuning จาก GitHub repo
นอกจากนี้ ให้ปรับใช้โมเดลที่ปรับแต่งแล้วผ่าน vLLM สำหรับการให้บริการ API สิ่งนี้รองรับโหลดการผลิตด้วยคุณสมบัติต่างๆ เช่น dynamic batching
ถัดไป สำรวจส่วนขยาย multi-modal แม้ว่าจะเน้นข้อความ แต่ก็สามารถผสานรวมกับโมเดลวิชันสำหรับแอปพลิเคชันแบบไฮบริดได้
อย่างไรก็ตาม ให้ตรวจสอบการเกิด overfitting ระหว่างการ fine-tuning ใช้ชุดข้อมูลตรวจสอบ (validation sets) และ early stopping
นอกจากนี้ ให้ปรับขนาดด้วยการอนุมานแบบกระจาย (distributed inference) บนคลัสเตอร์ ผู้ให้บริการอย่าง AWS มีตัวเลือกการจัดการให้เลือก
ในการตั้งค่าแบบ agentic ให้เชื่อมโยง GPT-OSS กับ API ภายนอกสำหรับเวิร์กโฟลว์ต่างๆ เช่น การวิจัยอัตโนมัติ
เทคนิคเหล่านี้ขยายความสามารถนอกเหนือจากการเรียกใช้พื้นฐาน
แนวทางปฏิบัติที่ดีที่สุด ข้อจำกัด และการแก้ไขปัญหา
นักพัฒนาปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดเพื่อให้ได้ผลลัพธ์ที่ดีที่สุด สร้างพร้อมต์ที่ชัดเจน ใช้ตัวอย่างแบบ few-shot และทำซ้ำตามผลลัพธ์
นอกจากนี้ ให้เคารพข้อจำกัดอัตรา (rate limits) – ตรวจสอบแดชบอร์ดของผู้ให้บริการเพื่อหลีกเลี่ยงการถูกจำกัด
อย่างไรก็ตาม ให้ตระหนักถึงข้อจำกัด: GPT-OSS อาจสร้างข้อมูลที่ไม่ถูกต้อง (hallucinate) ดังนั้นควรตรวจสอบการตอบสนองที่สำคัญ มันขาดการอัปเดตความรู้แบบเรียลไทม์
นอกจากนี้ ให้รักษาความปลอดภัยคีย์ API และบันทึกการใช้งานเพื่อควบคุมค่าใช้จ่าย
แก้ไขปัญหาโดยการตรวจสอบรหัสข้อผิดพลาด; 401 บ่งชี้การตรวจสอบสิทธิ์ไม่ถูกต้อง, 429 หมายถึงถึงขีดจำกัดอัตราแล้ว
โดยสรุป ให้ปฏิบัติตามแนวทางเหล่านี้เพื่อประสิทธิภาพที่เชื่อถือได้
บทสรุป: เสริมพลังโปรเจกต์ของคุณด้วย GPT-OSS API
นักพัฒนาตอนนี้มีเครื่องมือที่จะผสานรวม GPT-OSS ได้อย่างมีประสิทธิภาพ ตั้งแต่การตั้งค่าไปจนถึงคุณสมบัติขั้นสูง คู่มือนี้จะช่วยให้คุณประสบความสำเร็จ ทดลอง ปรับปรุง และสร้างสรรค์สิ่งใหม่ๆ ด้วย gpt-oss และ Apidog เพื่อสร้างโซลูชัน AI ที่มีผลกระทบ