
สวัสดีครับ ผู้ที่ชื่นชอบ AI! เตรียมตัวให้พร้อม เพราะ Open AI เพิ่งเปิดตัวโมเดลแบบ open-weight ใหม่ล่าสุดอย่าง GPT-OSS-120B ซึ่งกำลังสร้างความฮือฮาในวงการ AI โมเดลอันทรงพลังนี้เปิดตัวภายใต้ใบอนุญาต Apache 2.0 ถูกออกแบบมาสำหรับการให้เหตุผล การเขียนโค้ด และงานที่ต้องใช้เอเจนต์ โดยทั้งหมดนี้สามารถทำงานได้บน GPU เพียงตัวเดียว ในคู่มือนี้ เราจะเจาะลึกถึงสิ่งที่ทำให้ GPT-OSS-120B โดดเด่น เกณฑ์มาตรฐานที่ยอดเยี่ยม ราคาที่เข้าถึงได้ และวิธีที่คุณสามารถใช้งานผ่าน OpenRouter API มาสำรวจอัญมณีโอเพนซอร์สชิ้นนี้ และช่วยให้คุณเริ่มต้นเขียนโค้ดด้วยมันได้ในเวลาอันรวดเร็วกันเถอะ!
อยากได้แพลตฟอร์มแบบครบวงจร All-in-One สำหรับทีมพัฒนาของคุณ เพื่อให้ทำงานร่วมกันด้วย ประสิทธิภาพสูงสุด ไหม?
Apidog ตอบสนองทุกความต้องการของคุณ และ เข้ามาแทนที่ Postman ในราคาที่ย่อมเยากว่ามาก!
GPT-OSS-120B คืออะไร?
GPT-OSS-120B ของ Open AI เป็นโมเดลภาษาขนาด 117 พันล้านพารามิเตอร์ (โดยมี 5.1 พันล้านพารามิเตอร์ที่ทำงานต่อโทเค็น) ซึ่งเป็นส่วนหนึ่งของซีรีส์ GPT-OSS แบบ open-weight ใหม่ของพวกเขา เคียงข้างกับ GPT-OSS-20B ที่มีขนาดเล็กกว่า เปิดตัวเมื่อวันที่ 5 สิงหาคม 2025 เป็นโมเดล Mixture-of-Experts (MoE) ที่ปรับให้เหมาะสมเพื่อประสิทธิภาพ สามารถทำงานได้บน NVIDIA H100 GPU เพียงตัวเดียว หรือแม้แต่บนฮาร์ดแวร์สำหรับผู้บริโภคทั่วไปด้วยการควอนไทซ์แบบ MXFP4 โมเดลนี้ถูกสร้างขึ้นสำหรับงานต่างๆ เช่น การให้เหตุผลที่ซับซ้อน การสร้างโค้ด และการใช้เครื่องมือ โดยมีหน้าต่างบริบทขนาดใหญ่ถึง 128K โทเค็น — เทียบเท่ากับข้อความ 300–400 หน้า! ภายใต้ใบอนุญาต Apache 2.0 คุณสามารถปรับแต่ง นำไปใช้งาน หรือแม้แต่นำไปใช้ในเชิงพาณิชย์ได้ ทำให้เป็นความฝันสำหรับนักพัฒนาและธุรกิจที่ต้องการการควบคุมและความเป็นส่วนตัว

เกณฑ์มาตรฐาน: GPT-OSS-120B มีประสิทธิภาพเป็นอย่างไร?
GPT-OSS-120B ไม่ได้ด้อยประสิทธิภาพเลยเมื่อพูดถึงเรื่องการทำงาน เกณฑ์มาตรฐานของ Open AI แสดงให้เห็นว่าโมเดลนี้เป็นคู่แข่งที่น่ากลัวกับโมเดลกรรมสิทธิ์อย่าง o4-mini ของพวกเขาเอง และแม้กระทั่ง Claude 3.5 Sonnet นี่คือรายละเอียด:
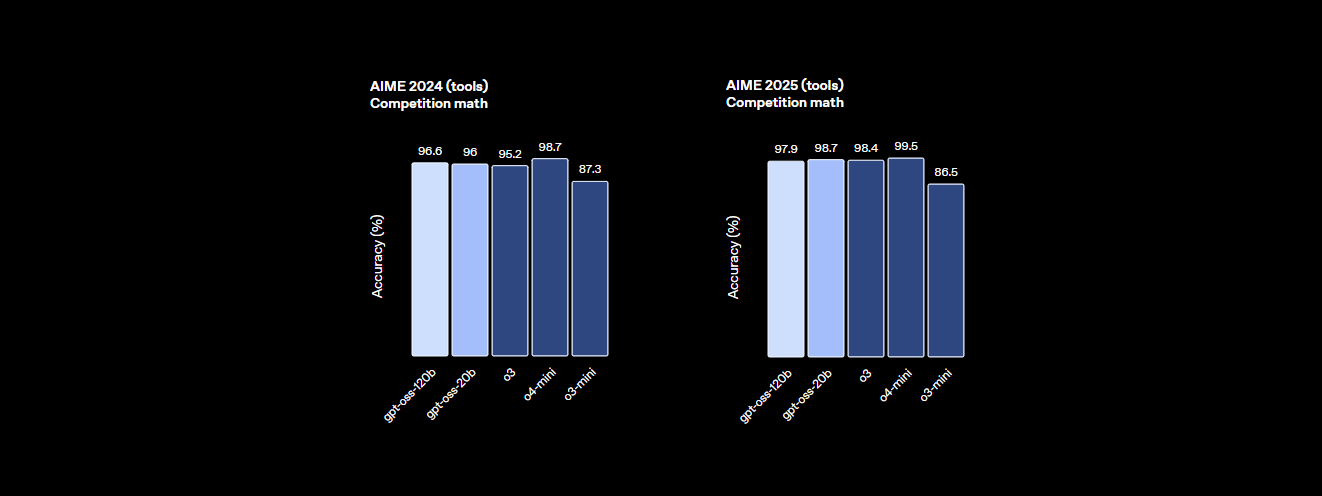
- พลังการให้เหตุผล: ทำคะแนนได้ 94.2% ใน MMLU (Massive Multitask Language Understanding) ซึ่งเกือบจะเท่ากับ 95.1% ของ GPT-4 และทำคะแนนได้ 96.6% ในการแข่งขันคณิตศาสตร์ AIME ซึ่งเหนือกว่าโมเดลแบบปิดหลายตัว
- ความสามารถในการเขียนโค้ด: ใน Codeforces ทำคะแนน Elo ได้ 2622 และผ่านการทดสอบ HumanEval สำหรับการสร้างโค้ดได้ 87.3% ทำให้เป็นเพื่อนที่ดีที่สุดของนักเขียนโค้ด
- สุขภาพและการใช้เครื่องมือ: เหนือกว่า o4-mini ใน HealthBench สำหรับคำถามที่เกี่ยวข้องกับสุขภาพ และโดดเด่นในงานที่ต้องใช้เอเจนต์ เช่น TauBench ด้วยความสามารถในการให้เหตุผลแบบ chain-of-thought (CoT) และการเรียกใช้เครื่องมือ
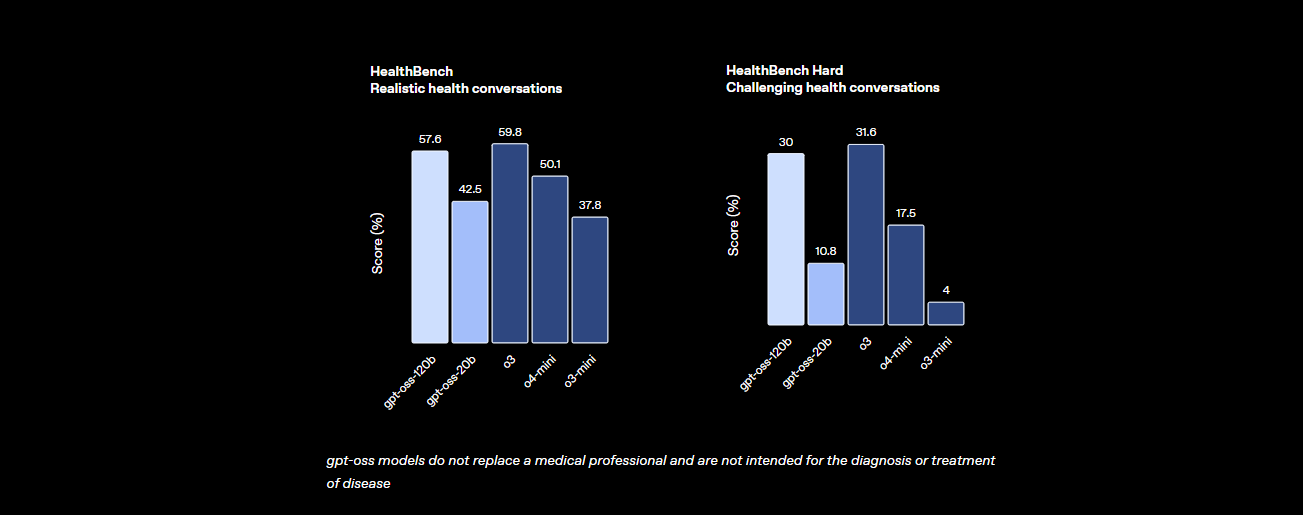
- ความเร็ว: บน H100 GPU สามารถประมวลผลได้ 45 โทเค็นต่อวินาที โดยผู้ให้บริการอย่าง Cerebras สามารถทำได้สูงสุดถึง 3,000 โทเค็นต่อวินาทีสำหรับความต้องการปริมาณมาก OpenRouter ให้ความเร็วประมาณ 500 โทเค็นต่อวินาที ซึ่งเร็วกว่าโมเดลแบบปิดหลายตัว
สถิติเหล่านี้แสดงให้เห็นว่า GPT-OSS-120B มีประสิทธิภาพเกือบเท่ากับโมเดลกรรมสิทธิ์ระดับสูง ในขณะที่เป็นแบบเปิดและปรับแต่งได้ เป็นโมเดลที่ยอดเยี่ยมสำหรับคณิตศาสตร์ การเขียนโค้ด และการแก้ปัญหาทั่วไป โดยมีระบบความปลอดภัยในตัวผ่านการปรับแต่งแบบ adversarial fine-tuning เพื่อลดความเสี่ยง
ราคา: เข้าถึงได้และโปร่งใส
หนึ่งในส่วนที่ดีที่สุดของ GPT-OSS-120B? คือมันคุ้มค่า โดยเฉพาะเมื่อเทียบกับโมเดลกรรมสิทธิ์ นี่คือรายละเอียดราคาจากผู้ให้บริการหลักๆ โดยอิงจากข้อมูลล่าสุดสำหรับหน้าต่างบริบทขนาด 131K:
- การติดตั้งใช้งานในเครื่อง: รันบนฮาร์ดแวร์ของคุณเอง (เช่น H100 GPU หรือการตั้งค่า 80GB VRAM) โดยไม่มีค่าใช้จ่าย API การตั้งค่า GMKTEC EVO-X2 มีราคาประมาณ 2000 ยูโร และใช้พลังงานน้อยกว่า 200W เหมาะสำหรับบริษัทขนาดเล็กที่ให้ความสำคัญกับความเป็นส่วนตัว
- Baseten: $0.10/M โทเค็นอินพุต, $0.50/M โทเค็นเอาต์พุต ความหน่วง: 0.20 วินาที, ปริมาณงาน: 491.1 โทเค็น/วินาที เอาต์พุตสูงสุด: 131K โทเค็น
- Fireworks: $0.15/M อินพุต, $0.60/M เอาต์พุต ความหน่วง: 0.56 วินาที, ปริมาณงาน: 258.9 โทเค็น/วินาที เอาต์พุตสูงสุด: 33K โทเค็น
- Together: $0.15/M อินพุต, $0.60/M เอาต์พุต ความหน่วง: 0.28 วินาที, ปริมาณงาน: 131.1 โทเค็น/วินาที เอาต์พุตสูงสุด: 131K โทเค็น
- Parasail: $0.15/M อินพุต, $0.60/M เอาต์พุต (FP4 quantization) ความหน่วง: 0.40 วินาที, ปริมาณงาน: 94.3 โทเค็น/วินาที เอาต์พุตสูงสุด: 131K โทเค็น
- Groq: $0.15/M อินพุต, $0.75/M เอาต์พุต ความหน่วง: 0.24 วินาที, ปริมาณงาน: 1,065 โทเค็น/วินาที เอาต์พุตสูงสุด: 33K โทเค็น
- Cerebras: $0.25/M อินพุต, $0.69/M เอาต์พุต ความหน่วง: 0.42 วินาที, ปริมาณงาน: 1,515 โทเค็น/วินาที เอาต์พุตสูงสุด: 33K โทเค็น เหมาะสำหรับความต้องการความเร็วสูง ทำได้สูงสุดถึง 3,000 โทเค็น/วินาทีในการตั้งค่าบางอย่าง
ด้วย GPT-OSS-120B คุณจะได้รับประสิทธิภาพสูงในราคาเพียงเสี้ยวหนึ่งของ GPT-4 (ประมาณ $20.00/M โทเค็น) โดยผู้ให้บริการอย่าง Groq และ Cerebras เสนอปริมาณงานที่รวดเร็วเป็นพิเศษสำหรับการใช้งานแบบเรียลไทม์
วิธีใช้ GPT-OSS-120B กับ Cline ผ่าน OpenRouter
ต้องการใช้ประโยชน์จากพลังของ GPT-OSS-120B สำหรับโปรเจกต์การเขียนโค้ดของคุณหรือไม่? แม้ว่า Claude Desktop และ Claude Code จะไม่รองรับการรวมเข้ากับโมเดล OpenAI โดยตรงอย่าง GPT-OSS-120B เนื่องจากต้องพึ่งพาระบบนิเวศของ Anthropic แต่คุณสามารถใช้โมเดลนี้กับ Cline ซึ่งเป็นส่วนขยาย VS Code แบบโอเพนซอร์สฟรี ได้อย่างง่ายดายผ่าน OpenRouter API นอกจากนี้ Cursor เพิ่งจำกัดตัวเลือก Bring Your Own Key (BYOK) สำหรับผู้ใช้ที่ไม่ใช่ Pro โดยล็อกฟีเจอร์ต่างๆ เช่น โหมด Agent และ Edit ไว้หลังการสมัครสมาชิกรายเดือน $20 ทำให้ Cline เป็นทางเลือกที่ยืดหยุ่นกว่าสำหรับผู้ใช้ BYOK นี่คือวิธีตั้งค่า GPT-OSS-120B กับ Cline และ OpenRouter ทีละขั้นตอน
ขั้นตอนที่ 1: รับ OpenRouter API Key
- สมัครสมาชิกกับ OpenRouter:
- ไปที่ openrouter.ai และสร้างบัญชีฟรีโดยใช้ Google หรือ GitHub
2. ค้นหา GPT-OSS-120B:
- ในแท็บ Models ให้ค้นหา “gpt-oss-120b” แล้วเลือก
3. สร้าง API Key:
- ไปที่ส่วน Keys คลิก Create API Key ตั้งชื่อ (เช่น “GPT-OSS-Cursor”) แล้วคัดลอกเก็บไว้ให้ปลอดภัย
ขั้นตอนที่ 2: ใช้ Cline ใน VS Code ด้วย BYOK
สำหรับการเข้าถึง BYOK แบบไม่จำกัด Cline (ส่วนขยาย VS Code แบบโอเพนซอร์ส) เป็นทางเลือกที่ยอดเยี่ยมแทน Cursor รองรับ GPT-OSS-120B ผ่าน OpenRouter โดยไม่มีการล็อกฟีเจอร์ นี่คือวิธีการตั้งค่า:
- ติดตั้ง Cline:
- เปิด VS Code (code.visualstudio.com)
- ไปที่แผงส่วนขยาย (
Ctrl+Shift+XหรือCmd+Shift+X) - ค้นหา “Cline” และติดตั้ง (โดย nickbaumann98, github.com/cline/cline)
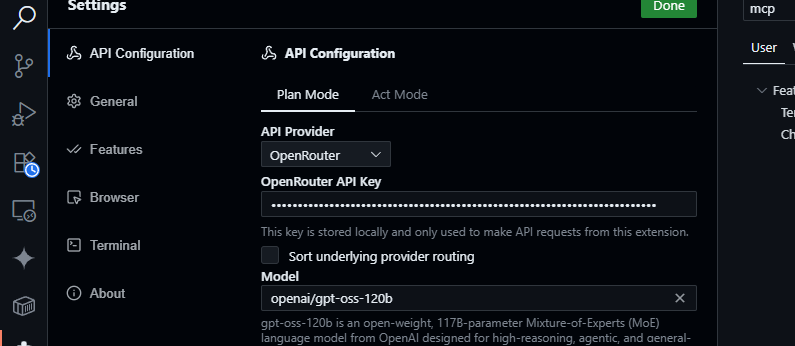
2. กำหนดค่า OpenRouter:
- เปิดแผง Cline (คลิกไอคอน Cline ใน Activity Bar)
- คลิก ไอคอนรูปเฟือง ในแผง Cline
- เลือก OpenRouter เป็นผู้ให้บริการ
- วาง OpenRouter API key ของคุณ
- เลือก
openai/gpt-oss-120bเป็นโมเดล
3. บันทึกและทดสอบ:
- บันทึกการตั้งค่า ในแผงแชทของ Cline ลอง:
สร้างฟังก์ชัน JavaScript เพื่อแยกวิเคราะห์ข้อมูล JSON
- คาดว่าจะได้รับคำตอบดังนี้:
function parseJSON(data) {
try {
return JSON.parse(data);
} catch (e) {
console.error("Invalid JSON:", e.message);
return null;
}
}
- ทดสอบการสอบถามโค้ดเบส:
สรุป src/api/server.js
- Cline จะวิเคราะห์โปรเจกต์ของคุณและส่งคืนสรุป โดยใช้ประโยชน์จากหน้าต่างบริบท 128K ของ GPT-OSS-120B
ทำไมต้อง Cline เหนือกว่า Cursor หรือ Claude?
- ไม่รองรับการรวม Claude: Claude Desktop และ Claude Code ถูกจำกัดให้ใช้เฉพาะโมเดลของ Anthropic (เช่น Claude 3.5 Sonnet) และไม่รองรับโมเดล OpenAI อย่าง GPT-OSS-120B เนื่องจากข้อจำกัดของระบบนิเวศ
- ข้อจำกัด BYOK ของ Cursor: การที่ Cursor เพิ่งแบน BYOK สำหรับผู้ใช้ที่ไม่ใช่ Pro หมายความว่าคุณไม่สามารถเข้าถึงโหมด Agent หรือ Edit ได้หากไม่มีการสมัครสมาชิกรายเดือน $20 แม้จะมี OpenRouter API key ที่ถูกต้องก็ตาม Cline ไม่มีข้อจำกัดดังกล่าว โดยเสนอการเข้าถึงฟีเจอร์ทั้งหมดฟรีด้วย API key ของคุณ
- ความเป็นส่วนตัวและการควบคุม: Cline ส่งคำขอโดยตรงไปยัง OpenRouter โดยข้ามเซิร์ฟเวอร์ของบุคคลที่สาม (ซึ่งต่างจาก Cursor ที่ใช้การกำหนดเส้นทาง AWS) ช่วยเพิ่มความเป็นส่วนตัว
เคล็ดลับการแก้ไขปัญหา
- API Key ไม่ถูกต้อง? ตรวจสอบคีย์ของคุณในแดชบอร์ดของ OpenRouter และตรวจสอบให้แน่ใจว่ามันใช้งานอยู่
- โมเดลไม่พร้อมใช้งาน? ตรวจสอบรายการโมเดลของ OpenRouter สำหรับ openai/gpt-oss-120b หากไม่มี ให้ลองผู้ให้บริการเช่น Fireworks AI หรือติดต่อฝ่ายสนับสนุนของ OpenRouter
- การตอบสนองช้า? ตรวจสอบให้แน่ใจว่าอินเทอร์เน็ตของคุณเสถียร เพื่อประสิทธิภาพที่เร็วขึ้น ให้พิจารณาโมเดลที่เบากว่าเช่น GPT-OSS-20B
- ข้อผิดพลาดของ Cline? อัปเดต Cline ผ่านแผง Extensions และตรวจสอบบันทึกในแผง Output ของ VS Code
ทำไมต้องใช้ GPT-OSS-120B?
โมเดล GPT-OSS-120B เป็นตัวเปลี่ยนเกมสำหรับนักพัฒนาและธุรกิจ โดยนำเสนอการผสมผสานที่น่าสนใจระหว่างประสิทธิภาพ ความยืดหยุ่น และความคุ้มค่า นี่คือเหตุผลที่มันโดดเด่น:
- อิสระแบบโอเพนซอร์ส: ได้รับอนุญาตภายใต้ Apache 2.0 คุณสามารถ fine-tune, deploy หรือ commercialize GPT-OSS-120B ได้โดยไม่มีข้อจำกัด ทำให้คุณควบคุมเวิร์กโฟลว์ AI ของคุณได้อย่างเต็มที่
- ประหยัดค่าใช้จ่าย: รันในเครื่องบน H100 GPU ตัวเดียว หรือฮาร์ดแวร์สำหรับผู้บริโภคทั่วไป (80GB VRAM) โดยไม่มีค่าใช้จ่าย API ผ่าน OpenRouter ราคาแข่งขันสูงที่ประมาณ $0.50/M โทเค็นอินพุต และ ~$2.00/M โทเค็นเอาต์พุต ซึ่งเป็นเพียงเศษเสี้ยวของ GPT-4 ที่ประมาณ ~$20.00/M โทเค็น ทำให้ประหยัดได้สูงสุดถึง 90% สำหรับผู้ใช้งานหนัก ผู้ให้บริการรายอื่นเช่น Groq ($0.15/M อินพุต, $0.75/M เอาต์พุต) และ Cerebras ($0.25/M อินพุต, $0.69/M เอาต์พุต) ก็ช่วยให้ต้นทุนต่ำเช่นกัน
- ประสิทธิภาพ: มีประสิทธิภาพเกือบเท่ากับ o4-mini ของ OpenAI โดยทำคะแนนได้ 94.2% ใน MMLU, 96.6% ในคณิตศาสตร์ AIME และ 87.3% ใน HumanEval สำหรับการเขียนโค้ด หน้าต่างบริบท 128K โทเค็น (300–400 หน้า) จัดการกับโค้ดเบสหรือเอกสารขนาดใหญ่ได้อย่างง่ายดาย
- การให้เหตุผลแบบ Chain-of-Thought (CoT): ความโปร่งใสของ CoT เต็มรูปแบบของโมเดลช่วยให้คุณเห็นการให้เหตุผลทีละขั้นตอน ทำให้ง่ายต่อการดีบักผลลัพธ์และตรวจจับอคติหรือข้อผิดพลาด คุณสามารถปรับความพยายามในการให้เหตุผล (ต่ำ, ปานกลาง, สูง) ผ่าน system prompts (เช่น “Reasoning: high”) สำหรับงานต่างๆ เช่น คณิตศาสตร์ที่ซับซ้อนหรือการเขียนโค้ด เพื่อรักษาสมดุลระหว่างความเร็วและความลึก การออกแบบ CoT แบบไม่ใช้การกำกับดูแลนี้ช่วยให้นักวิจัยสามารถตรวจสอบพฤติกรรมของโมเดลได้โดยไม่ต้องมีการกำกับดูแลโดยตรง ซึ่งช่วยเพิ่มความน่าเชื่อถือและความปลอดภัย
- ความสามารถแบบเอเจนต์: การรองรับการใช้เครื่องมือในตัว เช่น การท่องเว็บและการรันโค้ด Python ทำให้เหมาะสำหรับเวิร์กโฟลว์ที่ใช้เอเจนต์ สามารถเชื่อมโยงการเรียกใช้เครื่องมือหลายครั้ง (เช่น การค้นหาเว็บ 28 ครั้งติดต่อกันในการสาธิต) สำหรับงานที่ซับซ้อน เช่น การรวบรวมข้อมูลหรือระบบอัตโนมัติ
- ความเป็นส่วนตัว: โฮสต์ในองค์กรของคุณ (เช่น ผ่าน Dell Enterprise Hub) เพื่อการควบคุมข้อมูลที่สมบูรณ์แบบ เหมาะสำหรับองค์กรหรือผู้ใช้ที่ใส่ใจเรื่องความเป็นส่วนตัว
- ความยืดหยุ่น: เข้ากันได้กับ OpenRouter, Fireworks AI, Cerebras และการตั้งค่าในเครื่อง เช่น Ollama หรือ LM Studio สามารถทำงานบนฮาร์ดแวร์ที่หลากหลาย ตั้งแต่ RTX GPU ไปจนถึง Apple Silicon
กระแสในชุมชนบน X เน้นย้ำถึงความเร็ว (สูงสุด 1,515 โทเค็น/วินาทีบน Cerebras) และความสามารถในการเขียนโค้ด โดยนักพัฒนาชื่นชอบความสามารถในการจัดการโปรเจกต์หลายไฟล์และลักษณะ open-weight เพื่อการปรับแต่ง ไม่ว่าคุณจะสร้าง AI agents หรือ fine-tuning สำหรับงานเฉพาะทาง GPT-OSS-120B ก็มอบมูลค่าที่ไม่มีใครเทียบได้
บทสรุป
GPT-OSS-120B ของ Open AI เป็นโมเดล open-weight ที่ปฏิวัติวงการ โดยผสมผสานประสิทธิภาพระดับสูงเข้ากับการติดตั้งใช้งานที่คุ้มค่า เกณฑ์มาตรฐานของมันเทียบเท่ากับโมเดลกรรมสิทธิ์ ราคาเป็นมิตรกับกระเป๋า และง่ายต่อการรวมเข้ากับ Cursor หรือ Cline ผ่าน OpenRouter API ไม่ว่าคุณจะเขียนโค้ด ดีบัก หรือให้เหตุผลผ่านปัญหาที่ซับซ้อน โมเดลนี้ก็ตอบโจทย์ ลองใช้ดู ทดลองกับหน้าต่างบริบท 128K ของมัน และบอกเล่ากรณีการใช้งานเจ๋งๆ ของคุณในความคิดเห็นได้เลย—ผมพร้อมรับฟัง!
สำหรับรายละเอียดเพิ่มเติม ตรวจสอบ repo ได้ที่ github.com/openai/gpt-oss หรือประกาศของ Open AI ที่ openai.com.
อยากได้แพลตฟอร์มแบบครบวงจร All-in-One สำหรับทีมพัฒนาของคุณ เพื่อให้ทำงานร่วมกันด้วย ประสิทธิภาพสูงสุด ไหม?
Apidog ตอบสนองทุกความต้องการของคุณ และ เข้ามาแทนที่ Postman ในราคาที่ย่อมเยากว่ามาก!