
นักพัฒนาที่สร้างแอปพลิเคชันอัจฉริยะมักเผชิญกับความท้าทายในการผสานรวมโมเดลที่ล้ำสมัยอย่าง GPT-5.2 เข้ากับขั้นตอนการทำงานของตน GPT-5.2 ซึ่งเปิดตัวโดย OpenAI ในฐานะขีดจำกัดล่าสุดของความสามารถด้าน AI ได้ผลักดันขอบเขตในการสร้างโค้ด, การรับรู้ภาพ และการให้เหตุผลแบบหลายขั้นตอน คุณผสานรวมมันไม่เพียงเพื่อการทดลองเท่านั้น แต่เพื่อปรับใช้โซลูชันที่แข็งแกร่งและปรับขนาดได้ ซึ่งสามารถจัดการกับงานมืออาชีพที่ซับซ้อน อย่างไรก็ตาม ความลึกของ API—ตั้งแต่การเลือกเวอร์ชันไปจนถึงการปรับแต่งพารามิเตอร์—ต้องการแนวทางที่เป็นระบบ นั่นคือที่มาของเครื่องมืออย่าง Apidog ที่ช่วยให้การออกแบบ, การทดสอบ และการจัดทำเอกสาร API ง่ายขึ้น เพื่อให้คุณมุ่งเน้นไปที่นวัตกรรมมากกว่างานซ้ำซาก
ทำความเข้าใจ GPT-5.2: ความสามารถหลักและเหตุใดจึงสำคัญต่อนักพัฒนา
คุณเลือก GPT-5.2 เพราะมันมีประสิทธิภาพเหนือกว่ารุ่นก่อนหน้าในด้านความแม่นยำและประสิทธิภาพ OpenAI วางตำแหน่งให้เป็นชุดเครื่องมือที่ปรับให้เหมาะสมสำหรับงานด้านความรู้ ซึ่งสามารถทำผลงานได้ในระดับสูงสุดในทุกการวัดผล ตัวอย่างเช่น มันได้คะแนน 80.0% จาก SWE-Bench Verified สำหรับงานเขียนโค้ด ซึ่งหมายความว่าคุณสามารถสร้างโซลูชันซอฟต์แวร์ที่แม่นยำยิ่งขึ้นโดยใช้การวนซ้ำน้อยลง นอกจากนี้ ความสามารถด้านการมองเห็นยังช่วยลดอัตราความผิดพลาดในการให้เหตุผลจากแผนภูมิลงครึ่งหนึ่ง ทำให้สามารถพัฒนาแอปพลิเคชันอย่างเครื่องมือแสดงข้อมูลอัตโนมัติได้
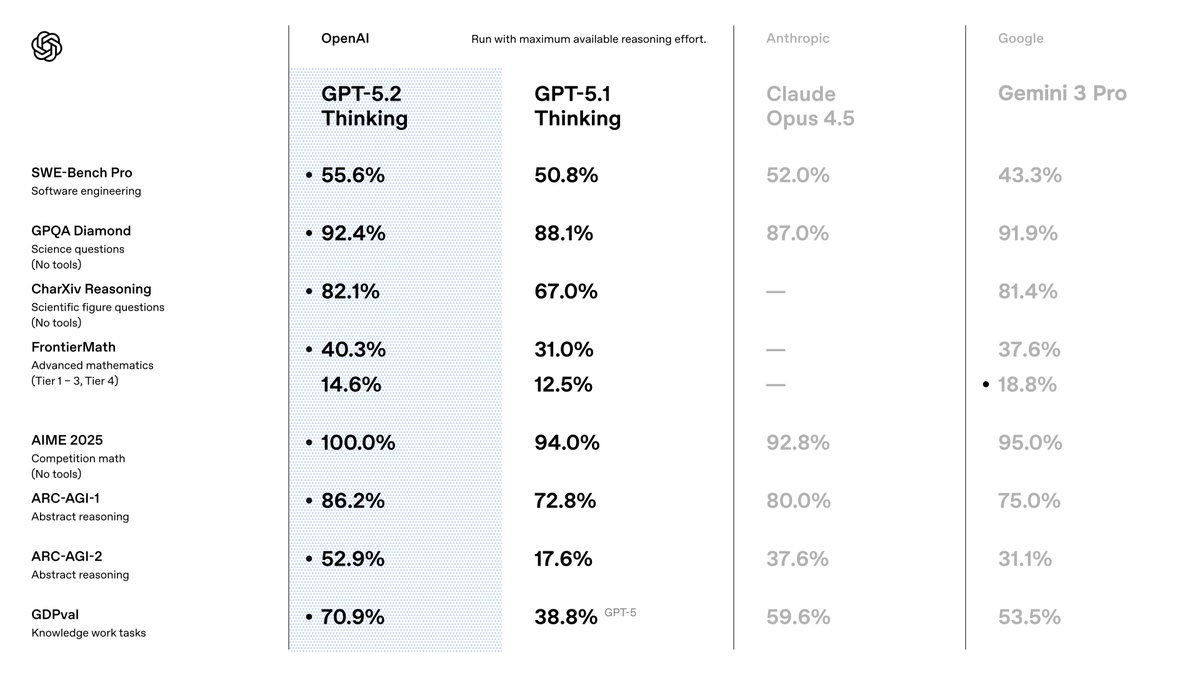
เมื่อเปลี่ยนจาก GPT-5.1 คุณจะสังเกตเห็นการปรับปรุงในด้านความถูกต้อง—ลดการหลอนลง 30% สำหรับการค้นหาที่เปิดใช้งาน—และการจัดการบริบทที่ยาวนาน ด้วยความแม่นยำเกือบสมบูรณ์แบบสูงสุดถึง 256k โทเค็น คุณสมบัติเหล่านี้มีความสำคัญเพราะช่วยลดความจำเป็นในการประมวลผลหลังการทำงานในไปป์ไลน์ของคุณ คุณยังได้รับประโยชน์จากการเรียกใช้เครื่องมือที่ได้รับการปรับปรุง โดยได้คะแนน 98.7% ในการวัดผลแบบหลายรอบ ซึ่งช่วยให้ระบบตัวแทนมีประสิทธิภาพยิ่งขึ้น
สำหรับผู้ใช้ API, GPT-5.2 สามารถผสานรวมเข้ากับระบบนิเวศ OpenAI ที่มีอยู่ได้อย่างราบรื่น คุณสามารถเข้าถึงได้ผ่าน Chat Completions หรือ Responses API ซึ่งรองรับพารามิเตอร์เช่น temperature เพื่อควบคุมความคิดสร้างสรรค์ อย่างไรก็ตาม ความสำเร็จขึ้นอยู่กับการเลือกเวอร์ชันที่เหมาะสม เราจะสำรวจสิ่งเหล่านั้นต่อไป
สำรวจ GPT-5.2 รุ่นต่างๆ: ปรับแต่งประสิทธิภาพให้ตรงกับความต้องการของคุณ
GPT-5.2 มีรุ่นต่างๆ ที่สมดุลระหว่างความเร็ว, ความลึก และต้นทุน ทำให้คุณสามารถปรับพฤติกรรมของโมเดลให้เข้ากับความต้องการของงานได้ ไม่เหมือนโมเดลแบบรวมศูนย์ ตัวเลือกเหล่านี้—Instant, Thinking และ Pro—ให้ความยืดหยุ่น คุณเปิดใช้งานพวกมันผ่านตัวระบุโมเดลเฉพาะในการร้องขอ API ของคุณ
เริ่มต้นด้วย GPT-5.2 Instant (gpt-5.2-chat-latest) รุ่นนี้ให้ความสำคัญกับการตอบสนองที่รวดเร็วสำหรับการโต้ตอบในชีวิตประจำวัน เช่น การค้นหาข้อมูลด่วนหรืองานเขียนทางเทคนิค นักพัฒนาชื่นชอบมันสำหรับแชทบอทหรือผู้ช่วยแบบเรียลไทม์ ซึ่งเวลาตอบสนองไม่เกิน 200ms เป็นสิ่งจำเป็นอย่างยิ่ง สามารถจัดการการแปลและคู่มือการใช้งานได้อย่างแม่นยำ ทำให้เหมาะสำหรับแอปพลิเคชันที่ต้องเผชิญหน้ากับผู้บริโภค
ถัดไป พิจารณา GPT-5.2 Thinking (gpt-5.2) คุณปรับใช้สิ่งนี้สำหรับการวิเคราะห์ที่ลึกซึ้งยิ่งขึ้น เช่น การสรุปเอกสารขนาดยาวหรือการวางแผนเชิงตรรกะ กลไกการให้เหตุผลของมันเก่งกาจในด้านคณิตศาสตร์และการตัดสินใจ โดยสามารถแก้ปัญหา FrontierMath ได้ถึง 40.3% ใช้พารามิเตอร์ reasoning ที่นี่—ตั้งค่าเป็น 'high' หรือ 'xhigh'—เพื่อเพิ่มคุณภาพของผลลัพธ์ในการสอบถามที่ซับซ้อน ตัวอย่างเช่น ในเครื่องมือจัดการโครงการ มันจะประสานงานเวิร์กโฟลว์แบบหลายขั้นตอนโดยมีข้อผิดพลาดน้อยที่สุด
สุดท้าย GPT-5.2 Pro (gpt-5.2-pro) มุ่งเป้าไปที่ประสิทธิภาพระดับสูงในโดเมนที่ท้าทาย มันทำได้ถึง 93.2% ใน GPQA Diamond สำหรับคำถามวิทยาศาสตร์ และโดดเด่นในการเขียนโปรแกรมโดยมีข้อผิดพลาดในกรณีพิเศษน้อยลง คุณสำรองสิ่งนี้ไว้สำหรับต้นแบบ R&D หรือสภาพแวดล้อมที่มีความเสี่ยงสูง เช่น การสร้างแบบจำลองทางการเงิน ที่ความแม่นยำมีความสำคัญกว่าความเร็ว
ภาพที่คุณแชร์เน้นสวิตช์สำหรับสิ่งเหล่านี้ ซึ่งรวมถึงโหมด "Max", "Mini", "High", "Low" และ "Fast" สิ่งเหล่านี้สอดคล้องกับความพยายามในการให้เหตุผล: 'none' สำหรับการตอบสนองทันที, 'low' สำหรับงานพื้นฐาน, ไปจนถึง 'xhigh' สำหรับการวิเคราะห์อย่างละเอียด คุณสามารถสลับพวกมันผ่านพารามิเตอร์ API เพื่อให้แน่ใจว่าโมเดลจะปรับตัวได้แบบไดนามิก ตัวอย่างเช่น สลับไปที่ "Max High Fast" สำหรับการเขียนโค้ดที่สมดุลซึ่งให้ความสำคัญกับความเร็วโดยไม่ลดทอนความลึก
การเลือกรุ่นต่างๆ อย่างรอบคอบจะช่วยให้คุณใช้ทรัพยากรได้อย่างเหมาะสม ตอนนี้ คุณก็ตั้งค่าการเข้าถึงเพื่อทำการเรียกใช้เหล่านี้ได้เลย
การตั้งค่าการเข้าถึง GPT-5.2 API ของคุณ: การยืนยันตัวตนและการเตรียมสภาพแวดล้อม
คุณเริ่มต้นการผสานรวมโดยการรักษาความปลอดภัยข้อมูลรับรอง API OpenAI กำหนดให้มี API key ซึ่งคุณสามารถสร้างได้จากแดชบอร์ดแพลตฟอร์ม ไปที่ platform.openai.com สร้างบัญชีหากจำเป็น และออก key ใต้ "API Keys"
ถัดไป ติดตั้ง OpenAI Python SDK รัน pip install openai ในเทอร์มินัลของคุณ ไลบรารีนี้จัดการคำขอ HTTP, การลองใหม่ และการสตรีมได้อย่างสมบูรณ์ สำหรับผู้ใช้ Node.js, npm install openai ให้ฟังก์ชันการทำงานที่คล้ายกัน คุณนำเข้ามันดังนี้:
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
ทดสอบการเชื่อมต่อด้วยการทำข้อความให้สมบูรณ์อย่างง่าย:
response = client.chat.completions.create(
model="gpt-5.2-chat-latest",
messages=[{"role": "user", "content": "Explain quantum entanglement briefly."}]
)
print(response.choices[0].message.content)
การเรียกนี้จะตรวจสอบการตั้งค่า หากเกิดข้อผิดพลาด ให้ตรวจสอบอัตราการเรียกใช้ (ค่าเริ่มต้น 3,500 RPM สำหรับ Tier 1) หรือความถูกต้องของคีย์ คุณยังสามารถกำหนดค่า base URL สำหรับปลายทางที่กำหนดเอง เช่น /compact สำหรับบริบทที่ขยายออกไป: client = OpenAI(base_url="https://api.openai.com/v1", api_key=...)
เมื่อตั้งค่าพื้นฐานเสร็จแล้ว คุณก็สามารถสำรวจการสร้างคำขอได้เลย
การสร้างคำขอ GPT-5.2 API ที่มีประสิทธิภาพ: พารามิเตอร์และแนวทางปฏิบัติที่ดีที่สุด
คุณสร้างคำขอโดยใช้ปลายทาง Chat Completions (/v1/chat/completions) เพย์โหลดประกอบด้วย model, messages และพารามิเตอร์เสริม เช่น temperature (0-2 สำหรับการกำหนด) และ max_tokens (สูงสุด 4096 โทเค็นเอาต์พุต)
สำหรับรายละเอียดเฉพาะของ GPT-5.2 ให้รวม reasoning_effort เพื่อควบคุมความลึก:
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Write a Python function for Fibonacci sequence."}],
reasoning_effort="high", # Aligns with "Max High" toggle
temperature=0.7,
max_tokens=500
)
สิ่งนี้สร้างโค้ดด้วยการให้เหตุผลแบบทีละขั้นตอน ซึ่งช่วยลดข้อผิดพลาด คุณเชื่อมโยงข้อความสำหรับการสนทนา โดยรักษาบริบทไว้ตลอดการสนทนา สำหรับงานด้านการมองเห็น ให้อัปโหลดรูปภาพผ่าน content ที่มีประเภท "image_url":
messages = [
{"role": "user", "content": [
{"type": "text", "text": "Describe this chart's trends."},
{"type": "image_url", "image_url": {"url": "https://example.com/chart.png"}}
]}
]
แนวทางปฏิบัติที่ดีที่สุดคือการรวมคำขอเป็นชุดเพื่อประหยัดค่าใช้จ่าย และใช้การสตรีม (stream=True) สำหรับ UI แบบเรียลไทม์ ตรวจสอบการใช้โทเค็นด้วย usage ในการตอบสนองเพื่อปรับปรุง prompt นอกจากนี้ ให้เปิดใช้งานเครื่องมือสำหรับการเรียกใช้ฟังก์ชัน—กำหนด schemas สำหรับ API ภายนอก และ GPT-5.2 จะดำเนินการโดยอัตโนมัติ
เพื่อทดสอบสิ่งเหล่านี้อย่างมีประสิทธิภาพ ให้ผสานรวม Apidog มันจำลองปลายทาง OpenAI ทำให้คุณสามารถจำลองรุ่นต่างๆ ได้โดยไม่กระทบต่อโควต้าจริง
การผสานรวม GPT-5.2 กับ Apidog: ทำให้การทดสอบและการจัดทำเอกสารง่ายขึ้น
Apidog เปลี่ยนแปลงวิธีการจัดการเวิร์กโฟลว์ GPT-5.2 API ของคุณ ในฐานะแพลตฟอร์มแบบครบวงจร มันรองรับการนำเข้า OpenAPI spec, การสร้างคำขอ และการทดสอบอัตโนมัติ คุณนำเข้า OpenAI schema เข้าสู่ Apidog จากนั้นออกแบบคอลเล็กชันสำหรับการเรียกใช้ GPT-5.2
เริ่มต้นด้วยการสร้างโปรเจกต์ใหม่ใน Apidog เพิ่มคำขอ HTTP ไปยัง https://api.openai.com/v1/chat/completions ตั้งค่าส่วนหัว (Authorization: Bearer YOUR_KEY, Content-Type: application/json) และวางตัวอย่างเนื้อหา สลับตัวแปรสำหรับโมเดลอย่าง "gpt-5.2-pro" เพื่อเปรียบเทียบผลลัพธ์แบบเคียงข้างกัน
จุดแข็งของ Apidog อยู่ที่ mocking server คุณสร้างการตอบสนองปลอมที่เลียนแบบโครงสร้าง JSON ของ GPT-5.2 ซึ่งเหมาะสำหรับการพัฒนาแบบออฟไลน์ ตัวอย่างเช่น จำลองการตอบสนอง "Max Extra High" พร้อมร่องรอยการให้เหตุผลโดยละเอียด เรียกใช้การทดสอบด้วยการยืนยันจำนวนโทเค็นหรืออัตราการหลอน

ยิ่งไปกว่านั้น คุณสามารถจัดทำเอกสาร API ของคุณด้วยเอดิเตอร์ในตัวของ Apidog สร้างเอกสารเชิงโต้ตอบที่เพื่อนร่วมงานใช้สำรวจปลายทาง ส่งออกไปยัง Postman หรือ HAR เพื่อความสะดวกในการพกพา ในการใช้งานจริง Apidog จะตรวจสอบการเรียกใช้ แจ้งเตือนความผิดปกติ เช่น ความล่าช้าสูงในโหมด "Low Fast"
ด้วยการรวม Apidog เข้ากับกระบวนการของคุณ คุณจะเร่งการทำซ้ำได้ ดาวน์โหลดฟรีและนำเข้าคำขอ GPT-5.2 ครั้งแรกของคุณ—สัมผัสความแตกต่างได้ภายในไม่กี่นาที
ราคา API ของ GPT-5.2: สร้างสมดุลระหว่างต้นทุนและความสามารถเชิงกลยุทธ์
คุณไม่สามารถละเลยเรื่องราคาได้เมื่อขยายขนาดแอปพลิเคชัน GPT-5.2 OpenAI กำหนดโครงสร้างต้นทุนต่อล้านโทเค็น โดยมีระดับชั้นที่สะท้อนปริมาณการใช้งาน สำหรับ GPT-5.2 Instant (gpt-5.2-chat-latest) คาดว่าจะมีค่าใช้จ่าย $1.75 ต่อ 1 ล้านโทเค็นอินพุต และ $14 ต่อ 1 ล้านโทเค็นเอาต์พุต อินพุตที่แคชไว้จะลดลงเหลือ $0.175—ประหยัดได้ 90%—ซึ่งส่งเสริมการใช้บริบทซ้ำ
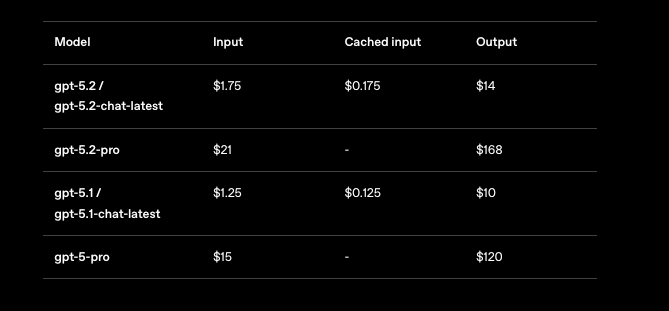
GPT-5.2 Thinking (gpt-5.2) มีอัตราที่คล้ายกัน ทำให้คุ้มค่าสำหรับงานที่สมดุล อย่างไรก็ตาม GPT-5.2 Pro (gpt-5.2-pro) มีราคาที่สูงกว่า: $21 ต่อ 1 ล้านโทเค็นอินพุต และ $168 ต่อ 1 ล้านโทเค็นเอาต์พุต ราคาพรีเมียมนี้สะท้อนถึงความแม่นยำที่เหนือกว่าในการสืบค้นระดับมืออาชีพ แต่คุณควรประเมิน ROI อย่างรอบคอบ
โดยรวมแล้ว GPT-5.2 แสดงให้เห็นถึงประสิทธิภาพการใช้โทเค็น มักจะลดค่าใช้จ่ายรวมเมื่อเทียบกับ GPT-5.1 สำหรับผลลัพธ์ที่มีคุณภาพ คุณติดตามได้ผ่านเครื่องมือวิเคราะห์การใช้งานของแดชบอร์ด สำหรับองค์กร ให้เจรจาชั้นการใช้งานแบบกำหนดเอง เครื่องมืออย่าง Apidog ช่วยในการคาดการณ์ต้นทุนโดยการบันทึกการไหลของโทเค็นจำลอง
เมื่อเข้าใจตัวเลขเหล่านี้แล้ว คุณก็สามารถดำเนินการกับตัวอย่างภาคปฏิบัติได้เลย
ตัวอย่างการใช้งานจริง: การสร้างโค้ดและงานด้านการมองเห็นด้วย GPT-5.2
คุณนำ GPT-5.2 ไปใช้ในสถานการณ์ที่จับต้องได้ พิจารณาการสร้างโค้ด: สั่งให้สร้างคอมโพเนนต์ React พร้อมการจัดการสถานะ
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Build a React todo list with useReducer."}],
reasoning_effort="medium"
)
ผลลัพธ์ที่ได้คือโค้ดที่สะอาด มีคอมเมนต์—สอดคล้องกับเกณฑ์มาตรฐาน 80% คุณปรับปรุงโดยการวนซ้ำ: ติดตามด้วยคำว่า "Optimize for performance."
สำหรับงานด้านการมองเห็น ให้วิเคราะห์ภาพหน้าจอ อัปโหลด UI mockup และสอบถาม: "แนะนำการปรับปรุงการเข้าถึง" GPT-5.2 ระบุปัญหาต่างๆ เช่น ความคมชัดของสี โดยใช้ประโยชน์จากอัตราข้อผิดพลาดที่ลดลงครึ่งหนึ่ง
ในตัวแทนที่มีเครื่องมือหลายอย่าง ให้กำหนดฟังก์ชันสำหรับการสืบค้นฐานข้อมูล GPT-5.2 ประสานงานการเรียกใช้ ลดความล่าช้าใน mega-agents ที่มีเครื่องมือมากกว่า 20 รายการ
ตัวอย่างเหล่านี้แสดงให้เห็นถึงความหลากหลาย อย่างไรก็ตาม ข้อผิดพลาดอาจเกิดขึ้น—จัดการด้วยการลองใหม่และกลไกสำรอง
การจัดการข้อผิดพลาดและกรณีพิเศษในการเรียก GPT-5.2 API
คุณอาจพบข้อจำกัดอัตราการเรียกใช้หรือพารามิเตอร์ที่ไม่ถูกต้อง ครอบการเรียกใช้ด้วย try-except:
try:
response = client.chat.completions.create(...)
except openai.RateLimitError:
time.sleep(60) # Backoff
response = client.chat.completions.create(...)
สำหรับการหลอน ให้ตรวจสอบซ้ำกับเครื่องมือค้นหา ในบริบทที่ยาว ให้ใช้ /compact เพื่อบีบอัดประวัติ ตรวจสอบหาอคติในแอปพลิเคชันที่ละเอียดอ่อน โดยใช้ตัวกรอง
Apidog ช่วยได้ที่นี่: เขียนสคริปต์ทดสอบสำหรับสถานการณ์ข้อผิดพลาด เพื่อให้มั่นใจถึงความทนทาน
การเพิ่มประสิทธิภาพขั้นสูง: การขยายขนาด GPT-5.2 สำหรับการใช้งานจริง
คุณขยายขนาดโดยการปรับแต่ง prompt และใช้ Assistants API สำหรับเธรดที่คงอยู่ ใช้การแคชสำหรับอินพุตที่ซ้ำกัน สำหรับแอปพลิเคชันทั่วโลก ให้กำหนดเส้นทางผ่านเซิร์ฟเวอร์เอดจ์
ผสานรวมกับเฟรมเวิร์กอย่าง LangChain: เชื่อมโยง GPT-5.2 กับ vector stores สำหรับระบบ RAG
สุดท้ายนี้ โปรดติดตามข่าวสาร—OpenAI พัฒนาอย่างรวดเร็ว
สรุป: เชี่ยวชาญ GPT-5.2 API และสร้างอนาคต
ตอนนี้คุณมีเครื่องมือที่จะใช้ GPT-5.2 ได้อย่างมีประสิทธิภาพแล้ว ตั้งแต่การเลือกรุ่นต่างๆ ไปจนถึงการทดสอบที่เสริมด้วย Apidog นำขั้นตอนเหล่านี้ไปใช้เพื่อยกระดับโครงการของคุณ ราคาที่เข้าถึงได้สำหรับการใช้งานอย่างรอบคอบ ปลดล็อกความสามารถที่เคยจำกัดอยู่ในห้องปฏิบัติการ
ทดลองวันนี้: สร้างต้นแบบตัวแทน GPT-5.2 และวัดผลกำไร แบ่งปันสิ่งที่คุณสร้างในความคิดเห็น—คุณเผชิญกับความท้าทายอะไรบ้าง? สำหรับการเจาะลึกเพิ่มเติม โปรดสำรวจเอกสารของ OpenAI สร้างอย่างกล้าหาญ