
หากคุณติดตามความเคลื่อนไหวของ AI ในปี 2025 คุณคงได้ยินเสียงฮือฮาเกี่ยวกับ Google Gemini 3 ซึ่งเป็นโมเดล AI มัลติโมดอลเจเนอเรชันถัดไปที่ออกแบบมาเพื่อแข่งขัน (และบางครั้งก็ทำได้ดีกว่า) GPT-5 ไม่ว่าคุณจะเป็นวิศวกรซอฟต์แวร์ ผู้ก่อตั้งสตาร์ทอัพ ผู้หลงใหล AI หรือเพียงแค่คนที่อยากรู้ว่า Gemini 3 ทำอะไรได้บ้าง การเรียนรู้วิธีใช้งาน Google Gemini 3 API จะเปิดประตูสู่การสร้างแอปพลิเคชันที่ฉลาดขึ้นและมีประสิทธิภาพมากขึ้นอย่างมาก
แต่พูดตามตรง เอกสารของ Google อาจจะค่อนข้างซับซ้อนสำหรับผู้เริ่มต้น ดังนั้นในคู่มือนี้ เราจะอธิบายทุกอย่างในรูปแบบที่ ชัดเจน เป็นมิตร และเหมาะสำหรับผู้เริ่มต้น
เอาล่ะ ตอนนี้เรามาปลดล็อกพลังของโมเดล AI ที่ล้ำหน้าที่สุดของ Google กัน!
Google Gemini 3 คืออะไร?
Google Gemini 3 เป็นโมเดลล่าสุดในตระกูล AI มัลติโมดอลของ Google ซึ่งแตกต่างจากโมเดลก่อนหน้า Gemini 3 ได้รับการปรับปรุงเพื่อ:
- การให้เหตุผลและการแก้ปัญหา
- การป้อน/แสดงผลแบบมัลติโมดอล (ข้อความ รูปภาพ เสียง การฝังวิดีโอ)
- การใช้เครื่องมือและเวิร์กโฟลว์แบบ Agent
- การอนุมานที่รวดเร็วด้วยปลายทางที่มีความหน่วงต่ำ
- การสลับโมเดลแบบไดนามิกขึ้นอยู่กับงานของคุณ
แต่จุดเด่นที่สำคัญที่สุดคือ:
Gemini 3 แนะนำ “โหมดการคิด” หลักสองโหมด:
พารามิเตอร์ thinking_level ควบคุม ความลึกสูงสุด ของกระบวนการให้เหตุผลภายในของโมเดลก่อนที่จะสร้างการตอบสนอง Gemini 3 ถือว่าระดับเหล่านี้เป็นขีดจำกัดสัมพัทธ์สำหรับการคิดมากกว่าการรับประกันโทเค็นที่เข้มงวด หากไม่ได้ระบุ thinking_level, Gemini 3 Pro จะใช้ค่าเริ่มต้นเป็น high
- การคิดระดับสูง/ไดนามิก: เพิ่มความลึกของการให้เหตุผลสูงสุด โมเดลอาจใช้เวลานานขึ้นอย่างมากในการสร้างโทเค็นแรก แต่ผลลัพธ์จะได้รับการให้เหตุผลอย่างรอบคอบมากขึ้น
- การคิดระดับต่ำ: ลดความหน่วงและค่าใช้จ่าย เหมาะที่สุดสำหรับการทำตามคำสั่งง่ายๆ การสนทนา หรือแอปพลิเคชันที่มีปริมาณงานสูง
ผู้เริ่มต้นหลายคนยังไม่ทราบเรื่องนี้ แต่การเลือกโหมดที่ถูกต้องช่วยปรับปรุงคุณภาพของผลลัพธ์ได้อย่างมาก และ ช่วยคุณควบคุมค่าใช้จ่ายได้
เราจะมาดูกันว่าวิธีการเลือกโหมดโดยใช้ API เร็วๆ นี้
ทำไมต้องใช้ Gemini 3 API แทนเครื่องมือ UI?
แน่นอน คุณสามารถใช้ Gemini ภายใน Google AI Studio ได้ แต่ถ้าคุณต้องการ:
- สร้างแอปพลิเคชัน
- ทำงานอัตโนมัติ
- รวมโมเดลเข้ากับเวิร์กโฟลว์
- สร้างแชทบอท
- ประมวลผลข้อมูล
- ฝึกเอเจนต์
- ดำเนินการงานมัลติโมดอล
คุณจะต้องใช้ Gemini 3 API
คู่มือนี้เน้นที่ REST API เพราะ:
- ง่ายสำหรับผู้เริ่มต้น
- ไม่ต้องใช้ไลบรารีไคลเอนต์
- คุณสามารถทดสอบได้อย่างรวดเร็วใน Apidog หรือ Postman
- ทำงานได้ในทุกสภาพแวดล้อมแบ็กเอนด์
การทำงานของ Gemini 3 API (ภาพรวมง่ายๆ)
แม้ว่า Gemini จะมีความสามารถขั้นสูง แต่ API เองก็ค่อนข้างตรงไปตรงมา
คุณส่งคำขอ POST ไปยัง…
<https://generativelanguage.googleapis.com/v1beta/models/{MODEL_ID}:generateContent?key=YOUR_API_KEY>
คุณรวม JSON เช่น:
- พร้อมต์ข้อความ
- รายการข้อความ (ไม่บังคับ)
- การตั้งค่าโมเดล
- การตั้งค่าความปลอดภัย
คุณได้รับ…
- ข้อความเอาต์พุตของโมเดล
- โครงสร้างการให้เหตุผล (สำหรับการคิดระดับสูง/ไดนามิก)
- การอ้างอิง
- ข้อมูลเมตา
- ออบเจกต์มัลติโมดอล (ถ้ามี)
เมื่อคุณเข้าใจโครงสร้างนี้แล้ว ทุกอย่างก็จะง่ายขึ้น
เริ่มต้นใช้งาน: ขั้นตอนแรกของคุณกับ Gemini API
ขั้นตอนที่ 1: รับคีย์ API ของคุณ
ลองนึกภาพคีย์ API ของคุณเป็นรหัสผ่านพิเศษที่บอก Google ว่า "ใช่ ฉันได้รับอนุญาตให้ใช้ Gemini" นี่คือวิธีการรับ:
- ไปที่ Google AI Studio
- ลงชื่อเข้าใช้ด้วยบัญชี Google ของคุณ
- คลิก "สร้างคีย์ API" ในแถบด้านซ้าย
- ตั้งชื่อคีย์ของคุณแล้วสร้างมันขึ้นมา
- คัดลอกและบันทึกคีย์นี้ไว้ในที่ปลอดภัย! คุณจะไม่สามารถเห็นมันได้อีก
สำคัญ: อย่าแชร์คีย์ API ของคุณหรือส่งไปเก็บในที่เก็บโค้ดสาธารณะ ปฏิบัติต่อมันเหมือนรหัสผ่านของคุณ
ขั้นตอนที่ 2: เลือกแนวทางของคุณ
คุณสามารถโต้ตอบกับ Gemini ได้สองวิธีหลักๆ:
- REST API: แนวทางที่เป็นสากล ใช้งานได้กับภาษาโปรแกรมใดก็ได้ที่สามารถสร้างคำขอ HTTP เราจะเน้นที่วิธีนี้
- SDK อย่างเป็นทางการ: Google มีไลบรารีที่สะดวกสำหรับ Python, Node.js และภาษาอื่นๆ ที่จัดการรายละเอียด HTTP ให้คุณ
เนื่องจากเรากำลังเน้นที่พื้นฐาน เราจะใช้วิธี REST API ซึ่งทำงานได้ทุกที่และช่วยให้คุณเข้าใจสิ่งที่เกิดขึ้นภายใต้พื้นฐาน
ทำความเข้าใจโหมดการคิดของ Gemini
หนึ่งในคุณสมบัติที่ทรงพลังที่สุดของ Gemini คือความสามารถในการทำงานใน "โหมดการคิด" ที่แตกต่างกัน นี่ไม่ใช่แค่การตลาด แต่เป็นการเปลี่ยนวิธีที่โมเดลประมวลผลคำขอของคุณโดยพื้นฐาน
การคิดระดับต่ำ (The Speed Demon)
เมื่อใดควรใช้: สำหรับงานง่ายๆ การตอบสนองที่รวดเร็ว และเมื่อคุณต้องการเพิ่มประสิทธิภาพด้านความเร็วและค่าใช้จ่าย
- ความเร็ว: การตอบสนองที่รวดเร็วมาก
- ค่าใช้จ่าย: ราคาไม่แพง
- กรณีการใช้งาน: ถาม-ตอบง่ายๆ, การจัดหมวดหมู่ข้อความ, การสรุปพื้นฐาน, การแปลตรงไปตรงมา
ตัวอย่างเช่น:
gemini-3-flash
gemini-3-mini
ลองนึกภาพโหมดการคิดระดับต่ำว่าเหมือนกับการสนทนาสั้นๆ กับเพื่อนที่มีความรู้ที่ให้คำตอบทันที
การคิดระดับสูง/ไดนามิก (The Thoughtful Analyst)
เมื่อใดควรใช้: สำหรับการให้เหตุผลที่ซับซ้อน ปัญหาหลายขั้นตอน และงานที่ต้องวิเคราะห์เชิงลึก
- ความเร็ว: ช้ากว่า (มัน "คิด" มากขึ้นก่อนตอบสนอง)
- ค่าใช้จ่าย: แพงกว่า
- กรณีการใช้งาน: ปัญหาคณิตศาสตร์ที่ซับซ้อน, การให้เหตุผลเชิงตรรกะ, การดีบักโค้ด, การเขียนเชิงสร้างสรรค์, การวางแผนเชิงกลยุทธ์
การคิดระดับสูง/ไดนามิกเหมือนกับการปรึกษาผู้เชี่ยวชาญที่ใช้เวลาพิจารณาทุกมุมมองก่อนที่จะให้คำตอบที่สมเหตุสมผลแก่คุณ
ตัวอย่างเช่น:
gemini-3-pro
gemini-3-pro-thinking
โมเดลเหล่านี้ให้การให้เหตุผลที่ลึกซึ้งยิ่งขึ้น หน้าต่างความสนใจที่ยาวนานขึ้น และความสามารถในการวางแผนที่ดีขึ้น
ความสวยงามคือคุณสามารถเลือกได้ ทั้งสองโมเดล: การคิดระดับสูง/ไดนามิก และการคิดระดับต่ำ ขึ้นอยู่กับความต้องการเฉพาะของคุณ สำหรับแอปพลิเคชันง่ายๆ ส่วนใหญ่ การคิดระดับต่ำนั้นสมบูรณ์แบบ เมื่อคุณต้องการการให้เหตุผลที่ลึกซึ้งยิ่งขึ้น ให้เปลี่ยนไปใช้การคิดระดับสูง
ตามกฎทั่วไป:
| ประเภทงาน | โหมดโมเดล |
|---|---|
| การวิจัย | การคิดระดับสูง/ไดนามิก |
| คณิตศาสตร์/ตรรกะ | การคิดระดับสูง/ไดนามิก |
| การสร้างโค้ด | การคิดระดับสูง/ไดนามิก |
| แชทลูกค้า | การคิดระดับต่ำ |
| การสร้างข้อความพื้นฐาน | การคิดระดับต่ำ |
| ผู้ช่วย UI | การคิดระดับต่ำ |
| แอปแบบเรียลไทม์ | การคิดระดับต่ำ |
เราจะแสดงวิธีเลือกแต่ละโมเดลใน REST API
สร้างการเรียก Gemini 3 REST API ครั้งแรกของคุณ
มาเริ่มต้นด้วยตัวอย่างที่ง่ายที่สุดเท่าที่จะเป็นไปได้
Endpoint
POST <https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=YOUR_API_KEY>
ตัวอย่างเนื้อหาคำขอ (JSON)
{
"contents": [
{ "role": "user",
"parts": [{ "text": "Explain how airplanes fly." }]
}
]
}
ตัวอย่างคำสั่ง Curl
curl -X POST \\
-H "Content-Type: application/json" \\
-d '{
"contents": [
{
"role": "user",
"parts": [{ "text": "Explain how airplanes fly." }]
}
]
}' \\
"<https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=YOUR_API_KEY>"
การใช้โหมดการคิดระดับสูง/ไดนามิก
ในการเปิดใช้งานโหมดการให้เหตุผล คุณต้องใช้โมเดลที่รองรับ เช่น gemini-3-pro-thinking
ตัวอย่าง REST API
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Find the race condition in this multi-threaded C++ snippet: [code here]"}]
}]
}'เมื่อใช้โหมดการคิดระดับสูง/ไดนามิก คุณมักจะได้รับ:
- โครงสร้างการคิดแบบลูกโซ่ (ซ่อนอยู่เว้นแต่จะมีการร้องขอ)
- คำตอบที่สอดคล้องกันมากขึ้น
- เวลาตอบสนองช้าลง
- ค่าใช้จ่ายในการอนุมานที่สูงขึ้น
ฉันแนะนำให้ใช้โหมดนี้เมื่อมีความสำคัญจริงๆ เช่น การให้เหตุผลระยะยาวหรือการวางแผนโค้ด
การใช้โหมดการคิดระดับต่ำ
โมเดลการคิดระดับต่ำได้รับการปรับให้เหมาะสมกับความเร็วและเหมาะสำหรับ:
- การเติมข้อความอัตโนมัติ
- ข้อความสั้นๆ
- การตอบสนอง UI
- ผู้ช่วยขนาดเล็ก
- คุณสมบัติเสริมของแชทบอท
ตัวอย่าง REST API โดยใช้ “Flash”
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "How does AI work?"}]
}],
"generationConfig": {
thinkingConfig: {
thinkingLevel: "low"
}
}
}'โมเดลการคิดระดับต่ำมีค่าใช้จ่ายน้อยกว่ามากและให้การตอบสนองเกือบจะทันที
การจัดการอินพุตแบบมัลติโมดอล (รูปภาพ, PDF, เสียง, วิดีโอ)
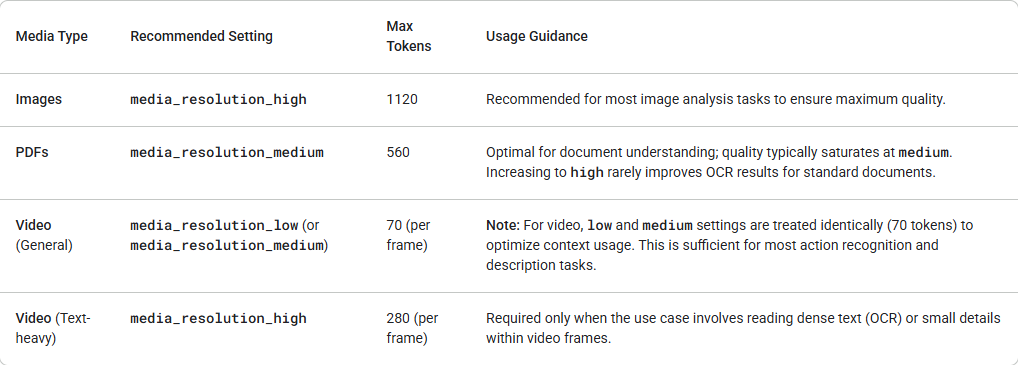
Gemini 3 แนะนำการควบคุมที่ละเอียดยิ่งขึ้นสำหรับการประมวลผลวิสัยทัศน์แบบมัลติโมดอลผ่านพารามิเตอร์ media_resolution ความละเอียดที่สูงขึ้นช่วยเพิ่มความสามารถของโมเดลในการอ่านข้อความละเอียดหรือระบุรายละเอียดเล็กๆ แต่จะเพิ่มการใช้โทเค็นและความหน่วง พารามิเตอร์ media_resolution กำหนด จำนวนโทเค็นสูงสุดที่จัดสรรต่อรูปภาพหรือเฟรมวิดีโออินพุตแต่ละรายการ
ตอนนี้คุณสามารถตั้งค่าความละเอียดเป็น media_resolution_low, media_resolution_medium, หรือ media_resolution_high ต่อส่วนสื่อแต่ละส่วนหรือทั่วโลก (ผ่าน generation_config) หากไม่ได้ระบุ โมเดลจะใช้ค่าเริ่มต้นที่เหมาะสมตามประเภทสื่อ
Gemini 3 รองรับการฝังแบบมัลติโมดอลใน:
- รูปภาพ
- เสียง
- เฟรมวิดีโอ
- เอกสาร
ตัวอย่างการอัปโหลดรูปภาพ (base64):
curl "https://generativelanguage.googleapis.com/v1alpha/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [
{ "text": "What is in this image?" },
{
"inlineData": {
"mimeType": "image/jpeg",
"data": "..."
},
"mediaResolution": {
"level": "media_resolution_high"
}
}
]
}]
}'การทดสอบและดีบักด้วย Apidog
แม้ว่าคำสั่ง curl จะดีสำหรับการทดสอบอย่างรวดเร็ว แต่ก็จะยุ่งยากเมื่อคุณกำลังพัฒนาแอปพลิเคชันจริง นี่คือจุดที่ Apidog โดดเด่น
ด้วย Apidog คุณสามารถ:
- บันทึกการกำหนดค่า API ของคุณ: ตั้งค่า Gemini endpoint และคีย์ API เพียงครั้งเดียว จากนั้นนำกลับมาใช้ใหม่กับการทดสอบทั้งหมดของคุณ
- สร้างเทมเพลตคำขอ: บันทึกประเภทพร้อมต์ต่างๆ (การเริ่มต้นการสนทนา, คำขอวิเคราะห์, การเขียนเชิงสร้างสรรค์) เป็นเทมเพลต
- ทดสอบโหมดการคิดแบบเคียงข้างกัน: สลับระหว่างโหมดการคิดระดับต่ำและระดับสูงได้อย่างง่ายดายเพื่อเปรียบเทียบการตอบสนองและประสิทธิภาพ
- จัดการประวัติการสนทนา: ใช้ตัวแปรสภาพแวดล้อมของ Apidog เพื่อรักษาสภาพแวดล้อมการสนทนาในคำขอหลายรายการ
- ทำให้การทดสอบเป็นอัตโนมัติ: สร้างชุดทดสอบที่ยืนยันว่าการรวม Gemini ของคุณทำงานได้อย่างถูกต้อง
นี่คือวิธีที่คุณอาจตั้งค่าคำขอ Gemini ใน Apidog:
- สร้างคำขอ POST ใหม่ไปยัง:
https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key={{api_key}} - ตั้งค่าตัวแปรสภาพแวดล้อม
api_keyด้วยคีย์ API จริงของคุณ - ในส่วนเนื้อหา ใช้ JSON:
{
"contents": [{
"parts": [{
"text": "{{prompt}}"
}]
}],
"generationConfig": {
"temperature": 0.7,
"maxOutputTokens": 800
}
}
4. ตั้งค่าตัวแปรสภาพแวดล้อม prompt อีกตัวด้วยสิ่งที่คุณต้องการถาม Gemini
แนวทางนี้ทำให้การทดลองรวดเร็วและเป็นระเบียบมากขึ้น
แนวทางปฏิบัติที่ดีที่สุดสำหรับ Gemini API
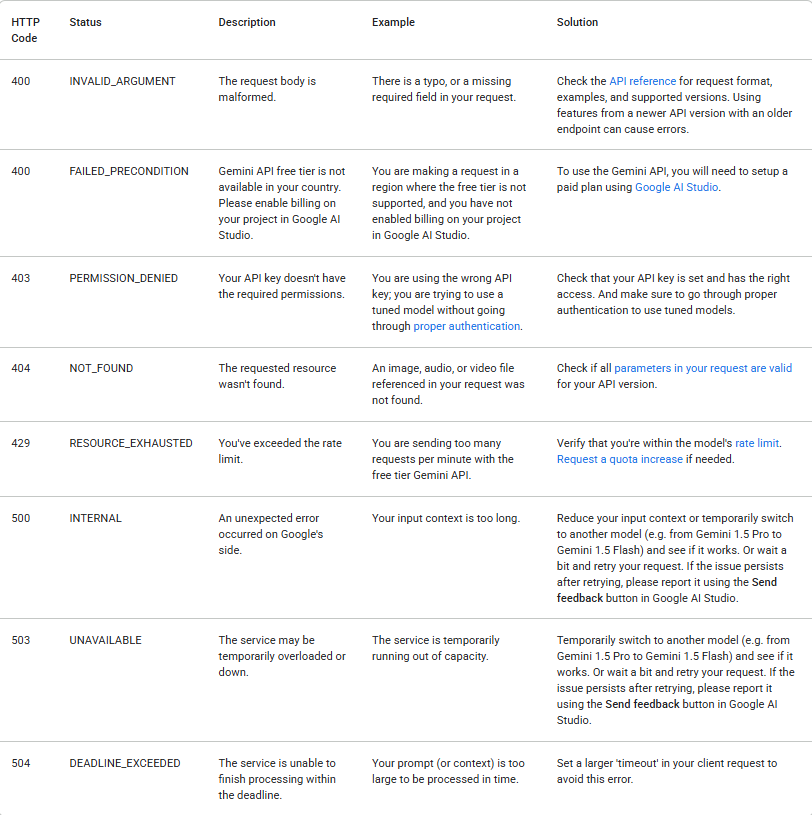
1. จัดการข้อผิดพลาดอย่างเหมาะสม
การเรียก API อาจล้มเหลวได้หลายสาเหตุ ตรวจสอบสถานะการตอบสนองเสมอและจัดการข้อผิดพลาดอย่างเหมาะสม ตารางต่อไปนี้แสดงรหัสข้อผิดพลาดแบ็กเอนด์ทั่วไปที่คุณอาจพบ พร้อมคำอธิบายสาเหตุและขั้นตอนการแก้ไขปัญหา:
2. จัดการค่าใช้จ่ายของคุณ
การใช้งาน Gemini API มีการคิดค่าบริการและมีค่าใช้จ่าย (หลังจากขีดจำกัดชั้นฟรี) โปรดจำเคล็ดลับเหล่านี้ไว้:
- เริ่มต้นด้วยชั้นฟรีเพื่อทดลอง
- ใช้โหมดการคิดระดับต่ำเมื่อเป็นไปได้สำหรับงานง่ายๆ
- ตั้งค่าขีดจำกัด
maxOutputTokensที่สมเหตุสมผล - ตรวจสอบการใช้งานของคุณใน Google AI Studio
โทเค็นอาจเป็นอักขระตัวเดียวเช่น z หรือคำเต็มเช่น cat คำยาวๆ จะถูกแบ่งออกเป็นหลายโทเค็น ชุดของโทเค็นทั้งหมดที่โมเดลใช้เรียกว่าคำศัพท์ และกระบวนการแบ่งข้อความเป็นโทเค็นเรียกว่า tokenization
เมื่อมีการเรียกเก็บเงิน ค่าใช้จ่ายของการเรียก Gemini API จะถูกกำหนดส่วนหนึ่งโดยจำนวนโทเค็นอินพุตและเอาต์พุต ดังนั้นการรู้วิธีนับโทเค็นจึงเป็นประโยชน์
3. สร้างพร้อมต์ที่ดีขึ้น
คุณภาพของผลลัพธ์ของคุณขึ้นอยู่กับอินพุตของคุณอย่างมาก นี่คือเคล็ดลับบางประการในการทำ Prompt Engineering:
แทนที่จะเป็น: "เขียนเกี่ยวกับสุนัข"
ลองใช้: "เขียนบล็อกโพสต์ให้ความรู้ 200 คำเกี่ยวกับประโยชน์ของการรับเลี้ยงสุนัขจากศูนย์พักพิง โดยใช้โทนเสียงที่เป็นมิตรและให้กำลังใจสำหรับผู้ที่อาจเป็นเจ้าของสัตว์เลี้ยง"
แทนที่จะเป็น: "แก้โค้ดนี้"
ลองใช้: "โปรดดีบักฟังก์ชัน Python นี้ที่ควรจะคำนวณแฟกทอเรียลแต่ให้ผลลัพธ์ที่ไม่ถูกต้องสำหรับอินพุต 5 อธิบายข้อผิดพลาดและให้โค้ดที่แก้ไขแล้ว"

4. เลือกโมเดลที่เหมาะสม
Google มีโมเดล Gemini หลายตัว แต่ละตัวมีจุดแข็งที่แตกต่างกัน ตรวจสอบว่าพารามิเตอร์โมเดลของคุณอยู่ในค่าต่อไปนี้:
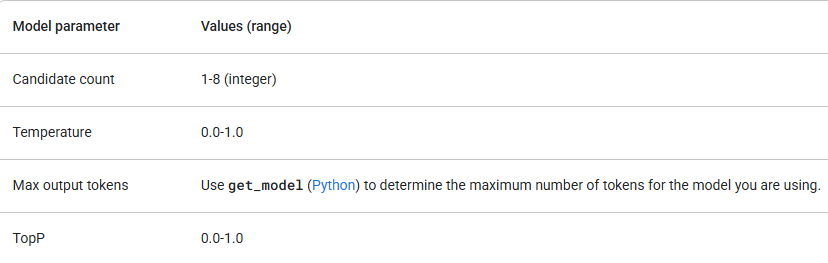
เริ่มต้นด้วย gemini-1.5-flash และอัปเกรดก็ต่อเมื่อคุณต้องการความสามารถในการให้เหตุผลที่มากขึ้น นอกจากการตรวจสอบค่าพารามิเตอร์แล้ว ตรวจสอบให้แน่ใจว่าคุณใช้เวอร์ชัน API ที่ถูกต้อง (เช่น /v1 หรือ /v1beta) และโมเดลที่รองรับคุณสมบัติที่คุณต้องการ ตัวอย่างเช่น หากคุณสมบัติอยู่ในรุ่นเบต้า จะมีให้ใช้งานเฉพาะในเวอร์ชัน API /v1beta เท่านั้น
สรุป: การเดินทางสู่ AI ของคุณเริ่มต้นขึ้นแล้ว
ตอนนี้คุณมีทุกสิ่งที่จำเป็นในการเริ่มต้นสร้างด้วย Google Gemini API คุณได้เรียนรู้วิธีรับคีย์ API สร้างคำขอพื้นฐาน เข้าใจโหมดการคิดที่แตกต่างกัน และแม้กระทั่งดูตัวอย่างขั้นสูงบางส่วน
โปรดจำไว้ว่าการทำงานกับ AI API เป็นกระบวนการที่ทำซ้ำ คุณจะเก่งขึ้นในการสร้างพร้อมต์และเลือกการตั้งค่าที่ถูกต้องด้วยการฝึกฝน อย่ากลัวที่จะทดลอง นั่นคือวิธีที่คุณจะค้นพบศักยภาพทั้งหมดของสิ่งที่คุณสามารถสร้างได้
ขั้นตอนต่อไปที่สำคัญที่สุดคือการเริ่มต้นการทดลอง นำตัวอย่างในคู่มือนี้ไปปรับเปลี่ยน ทำให้พัง และดูว่าจะเกิดอะไรขึ้น วิธีที่ดีที่สุดในการเรียนรู้คือการลงมือทำ
สำหรับผู้เริ่มต้น ผมขอแนะนำอย่างยิ่งให้ใช้ Apidog เป็นเครื่องมือทดสอบ REST API ของคุณ ซึ่งช่วยคุณ:
- ดีบักคำขอ
- จัดเก็บตัวแปรสภาพแวดล้อม
- เรียกใช้คอลเลกชัน
- เปรียบเทียบผลลัพธ์ของโมเดลได้อย่างรวดเร็ว
- แชร์กรณีทดสอบ API ของคุณกับเพื่อนร่วมทีม
และเนื่องจากฟรี จึงไม่มีข้อเสียใดๆ