
นักพัฒนาที่สร้างแอปพลิเคชันอัจฉริยะมีความต้องการโมเดลที่สามารถจัดการข้อมูลประเภทต่างๆ ได้อย่างหลากหลายโดยไม่ลดทอนความเร็วหรือความแม่นยำ GLM-4.6V ตอบสนองความต้องการนี้โดยตรง Z.ai ได้เปิดตัวซีรีส์นี้ในฐานะโมเดลภาษาขนาดใหญ่แบบ Multimodal (หลายรูปแบบ) โอเพนซอร์ส ที่ผสานรวมข้อความ รูปภาพ วิดีโอ และไฟล์เข้ากับการโต้ตอบที่ราบรื่น API นี้ช่วยให้คุณสามารถผสานรวมความสามารถเหล่านี้เข้ากับโปรเจกต์ของคุณได้โดยตรง ไม่ว่าจะเป็นสำหรับการวิเคราะห์เอกสารหรือเป็นเอเจนต์ค้นหาด้วยภาพ
เมื่อเราพิจารณาสถาปัตยกรรม วิธีการเข้าถึง และราคาของ GLM-4.6V คุณจะเห็นว่ามันทำงานได้ดีกว่าคู่แข่งในการเปรียบเทียบมาตรฐาน นอกจากนี้ เคล็ดลับการผสานรวมกับเครื่องมืออย่าง Apidog จะช่วยให้คุณปรับใช้ได้เร็วขึ้น มาเริ่มต้นด้วยการออกแบบหลักของโมเดลกัน
ทำความเข้าใจ GLM-4.6V: สถาปัตยกรรมและความสามารถหลัก
Z.ai ออกแบบ GLM-4.6V เพื่อประมวลผลอินพุตแบบหลายรูปแบบโดยกำเนิด และส่งออกการตอบสนองที่เป็นข้อความที่มีโครงสร้าง โมเดลซีรีส์นี้ประกอบด้วยสองรุ่นย่อย: GLM-4.6V (พารามิเตอร์ 106B) ซึ่งเป็นรุ่นเรือธงสำหรับงานประสิทธิภาพสูง และ GLM-4.6V-Flash (พารามิเตอร์ 9B) สำหรับการปรับใช้ในเครื่องที่มีประสิทธิภาพ ทั้งสองรุ่นรองรับหน้าต่างบริบท 128K โทเค็น ทำให้สามารถวิเคราะห์เอกสารจำนวนมากได้สูงสุดถึง 150 หน้า หรือวิดีโอที่มีความยาวเป็นชั่วโมงได้ในการประมวลผลครั้งเดียว

หัวใจสำคัญของ GLM-4.6V คือการรวมตัวเข้ารหัสภาพที่สอดคล้องกับโปรโตคอลบริบทแบบยาว การจัดเรียงนี้ช่วยให้โมเดลสามารถรักษาLรายละเอียดที่ละเอียดอ่อนไว้ได้ตลอดอินพุตทั้งหมด ตัวอย่างเช่น มันสามารถจัดการลำดับข้อความ-ภาพที่สลับกัน โดยเชื่อมโยงการตอบสนองกับองค์ประกอบภาพที่เฉพาะเจาะจง เช่น พิกัดวัตถุในรูปภาพ การเรียกใช้ฟังก์ชันแบบเนทีฟทำให้มันแตกต่างออกไป นักพัฒนาสามารถเรียกใช้เครื่องมือได้โดยตรงด้วยพารามิเตอร์ภาพ และโมเดลจะตีความวงจรตอบรับด้วยภาพ
นอกจากนี้ การเรียนรู้แบบเสริมกำลังยังช่วยปรับปรุงการเรียกใช้เครื่องมือ โมเดลเรียนรู้ที่จะเชื่อมโยงการกระทำ เช่น การสอบถามเครื่องมือค้นหาด้วยภาพหน้าจอและการให้เหตุผลกับผลลัพธ์ สิ่งนี้นำไปสู่เวิร์กโฟลว์แบบครบวงจร ตั้งแต่การรับรู้ไปจนถึงการตัดสินใจ ด้วยเหตุนี้ แอปพลิเคชันจึงได้รับความเป็นอิสระโดยไม่ต้องผ่านกระบวนการหลังการประมวลผลที่ซับซ้อน

ในทางปฏิบัติ คุณสมบัติเหล่านี้ทำให้สามารถจัดการข้อมูลในโลกจริงได้อย่างแข็งแกร่ง โมเดลนี้มีความสามารถโดดเด่นในการสร้างข้อความแบบ Rich-text โดยสร้างเอาต์พุตภาพ-ข้อความที่สลับกันสำหรับรายงานหรืออินโฟกราฟิก นอกจากนี้ยังรองรับ Extended Model Context Protocol (MCP) ซึ่งอนุญาตให้อินพุตหลายรูปแบบที่ใช้ URL เพื่อการประมวลผลที่ปรับขนาดได้
การเปรียบเทียบมาตรฐานและประสิทธิภาพ: การวัด GLM-4.6V เทียบกับคู่แข่ง
ข้อมูลเชิงปริมาณยืนยันถึงความได้เปรียบของ GLM-4.6V ใน MMBench ได้คะแนน 82.5% ใน multimodal QA ซึ่งนำหน้า LLaVA-1.6 ไป 4 จุด MathVista แสดงให้เห็นความแม่นยำ 68% ในสมการภาพ ต้องขอบคุณตัวเข้ารหัสที่จัดเรียงไว้
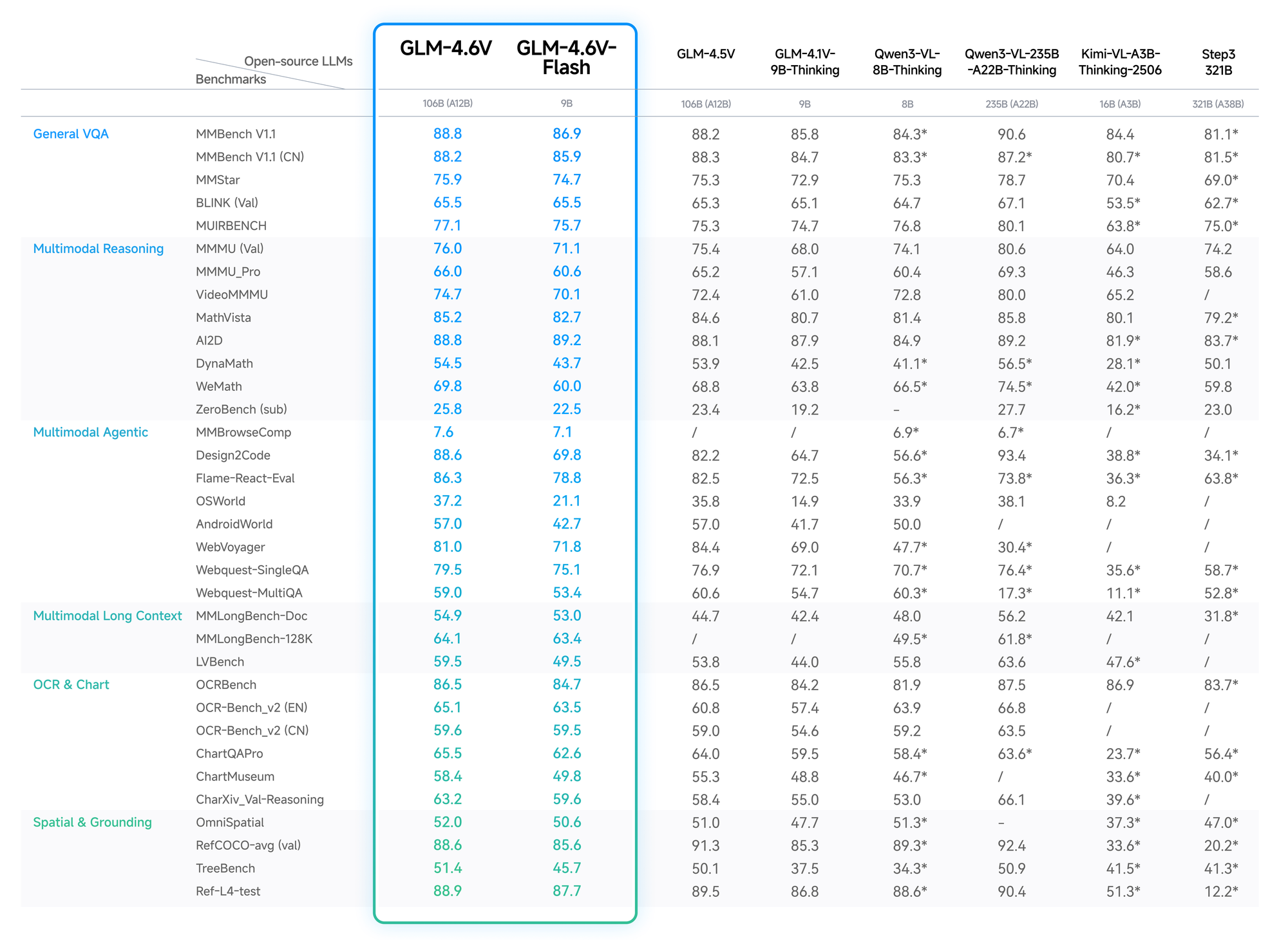
การทดสอบ OCRBench ให้ผลลัพธ์ 91% สำหรับการแยกข้อความจากภาพที่บิดเบี้ยว ซึ่งสูงกว่า GPT-4V ในกลุ่มโอเพนซอร์ส การประเมินบริบทแบบยาว เช่น Video-MME ทำได้ถึง 75% สำหรับคลิปความยาวหนึ่งชั่วโมง โดยยังคงรายละเอียดข้ามเฟรมไว้ได้
รุ่น Flash ลดความแม่นยำลงเล็กน้อย (2-3%) เพื่อเพิ่มความเร็วถึง 5 เท่า เหมาะสำหรับแอปพลิเคชันแบบเรียลไทม์ บล็อกของ Z.ai มีรายละเอียดเหล่านี้ พร้อมการตั้งค่าที่สามารถทำซ้ำได้บน Hugging Face
ดังนั้น นักพัฒนาจึงเลือก GLM-4.6V เพื่อประสิทธิภาพที่เชื่อถือได้และคุ้มค่า
คุณสมบัติหลักของซีรีส์โมเดล GLM-4.6V
GLM-4.6V มาพร้อมคุณสมบัติขั้นสูงที่ยกระดับ AI แบบหลายรูปแบบ ประการแรก รูปแบบอินพุตของมันครอบคลุมข้อความ รูปภาพ วิดีโอ และไฟล์ โดยมีเอาต์พุตที่เน้นการสร้างข้อความที่แม่นยำ นักพัฒนาชื่นชอบความยืดหยุ่น: อัปโหลดไฟล์ PDF ทางการเงิน แล้วโมเดลจะแยกตาราง ให้เหตุผลเกี่ยวกับแนวโน้ม และแนะนำการแสดงผลข้อมูล
การใช้เครื่องมือแบบเนทีฟถือเป็นความก้าวหน้าครั้งสำคัญ แตกต่างจากโมเดลทั่วไปที่ต้องอาศัยการจัดการภายนอก GLM-4.6V ได้ฝังความสามารถในการเรียกใช้ฟังก์ชันไว้ คุณสามารถกำหนดเครื่องมือในคำขอ เช่น เครื่องมือครอบตัดภาพ และโมเดลจะส่งผ่านข้อมูลภาพเป็นพารามิเตอร์ จากนั้นจะเข้าใจผลลัพธ์และทำซ้ำหากจำเป็น สิ่งนี้ช่วยปิดวงจรสำหรับงานต่างๆ เช่น การค้นหาเว็บด้วยภาพ: การจดจำความตั้งใจจากภาพคำค้น การวางแผนการเรียกค้น การรวมผลลัพธ์ และการส่งออกข้อมูลเชิงลึกที่มีเหตุผล
นอกจากนี้ บริบท 128K ยังช่วยให้สามารถวิเคราะห์รูปแบบยาวได้ ประมวลผลสไลด์ 200 สไลด์จากการนำเสนอ โมเดลจะสรุปประเด็นสำคัญพร้อมกับการประทับเวลาเหตุการณ์วิดีโอ เช่น การทำประตูในการแข่งขันฟุตบอล สำหรับการพัฒนาส่วนหน้า (frontend) โมเดลสามารถจำลอง UI จากภาพหน้าจอ โดยส่งออกโค้ด HTML/CSS/JS ที่แม่นยำระดับพิกเซล การแก้ไขด้วยภาษาธรรมชาติจะตามมา ซึ่งเป็นการปรับปรุงต้นแบบแบบโต้ตอบ
รุ่น Flash ได้รับการปรับให้เหมาะสมสำหรับความหน่วง (latency) ด้วยพารามิเตอร์ 9B ทำให้สามารถทำงานบนฮาร์ดแวร์ของผู้ใช้ทั่วไปผ่านเอนจินการอนุมาน vLLM หรือ SGLang น้ำหนักโมเดลที่มีให้ดาวน์โหลดบน Hugging Face ช่วยให้สามารถปรับแต่ง (fine-tuning) ได้ แม้ว่าคอลเล็กชันจะเน้นไปที่โมเดลพื้นฐานที่ยังไม่มีสถิติที่ครอบคลุมก็ตาม โดยรวมแล้ว คุณสมบัติเหล่านี้ทำให้ GLM-4.6V เป็นแกนหลักที่หลากหลายสำหรับเอเจนต์ในด้านธุรกิจอัจฉริยะหรือเครื่องมือสร้างสรรค์
วิธีเข้าถึง GLM-4.6V API: การตั้งค่าทีละขั้นตอน
การเข้าถึง GLM-4.6V API ทำได้ง่ายดาย ด้วยอินเทอร์เฟซที่เข้ากันได้กับ OpenAI เริ่มต้นด้วยการลงทะเบียนที่พอร์ทัลนักพัฒนา Z.ai (z.ai) สร้างคีย์ API ใต้แดชบอร์ดบัญชีของคุณ—โทเค็น Bearer นี้จะใช้ยืนยันตัวตนสำหรับคำขอทั้งหมด
ปลายทางพื้นฐาน (base endpoint) อยู่ที่ https://api.z.ai/api/paas/v4/chat/completions ใช้วิธีการ POST พร้อมเพย์โหลด JSON ส่วนหัวการยืนยันตัวตน (authentication headers) ประกอบด้วย Authorization: Bearer <your-api-key> และ Content-Type: application/json อาร์เรย์ Messages จะจัดโครงสร้างการสนทนา โดยรองรับเนื้อหาแบบหลายรูปแบบ
ตัวอย่างเช่น ส่ง URL รูปภาพพร้อมกับข้อความแจ้ง (text prompts) เพย์โหลดจะระบุ "model": "glm-4.6v" หรือ "glm-4.6v-flash" เปิดใช้งานขั้นตอนการคิดด้วย "thinking": {"type": "enabled"} เพื่อการติดตามเหตุผลที่โปร่งใส โหมดสตรีมมิ่งเพิ่ม "stream": true สำหรับการตอบสนองแบบเรียลไทม์ผ่านเหตุการณ์ที่เซิร์ฟเวอร์ส่ง
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.jpg"}
},
{"type": "text", "text": "Describe the key elements in this image and suggest improvements."}
]
}
],
"thinking": {"type": "enabled"}
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
print(response.json())
โค้ดนี้ดึงคำอธิบายพร้อมเหตุผล สำหรับวิดีโอหรือไฟล์ สามารถขยายอาร์เรย์เนื้อหาได้ในลักษณะเดียวกัน—ใช้ URL หรือการเข้ารหัส Base64 การจำกัดอัตรา (rate limits) จะขึ้นอยู่กับแผนของคุณ; ตรวจสอบได้ผ่านแดชบอร์ด
Apidog ช่วยเสริมกระบวนการนี้ นำเข้า OpenAPI spec จากเอกสาร Z.ai ลงใน Apidog จากนั้นจำลองคำขอด้วยภาพ ทดสอบการเรียกใช้ฟังก์ชันโดยไม่ต้องเขียนโค้ด ตรวจสอบความถูกต้องของเพย์โหลดก่อนนำไปใช้จริง ผลที่ได้คือ คุณสามารถทำซ้ำได้เร็วขึ้น และตรวจจับข้อผิดพลาดได้ตั้งแต่เนิ่นๆ
การเข้าถึงในเครื่องเสริมการใช้งานบนคลาวด์ ดาวน์โหลดน้ำหนักโมเดลจากคอลเล็กชัน GLM-4.6V ของ Hugging Face และให้บริการผ่านเฟรมเวิร์กที่เข้ากันได้ การตั้งค่านี้เหมาะสำหรับแอปที่คำนึงถึงความเป็นส่วนตัว แม้ว่าจะต้องใช้ทรัพยากร GPU สำหรับโมเดล 106B
รายละเอียดราคา: การปรับขนาดที่คุ้มค่าด้วย GLM-4.6V
Z.ai กำหนดโครงสร้างราคา GLM-4.6V เพื่อให้สมดุลระหว่างการเข้าถึงและประสิทธิภาพ โมเดลเรือธงคิดค่าบริการ 0.6 ดอลลาร์ต่อล้านโทเค็นอินพุต และ 0.9 ดอลลาร์ต่อล้านโทเค็นเอาต์พุต โมเดลแบบแบ่งระดับนี้คำนึงถึงความซับซ้อนแบบหลายรูปแบบ—รูปภาพและวิดีโอจะใช้โทเค็นตามความละเอียดและความยาว
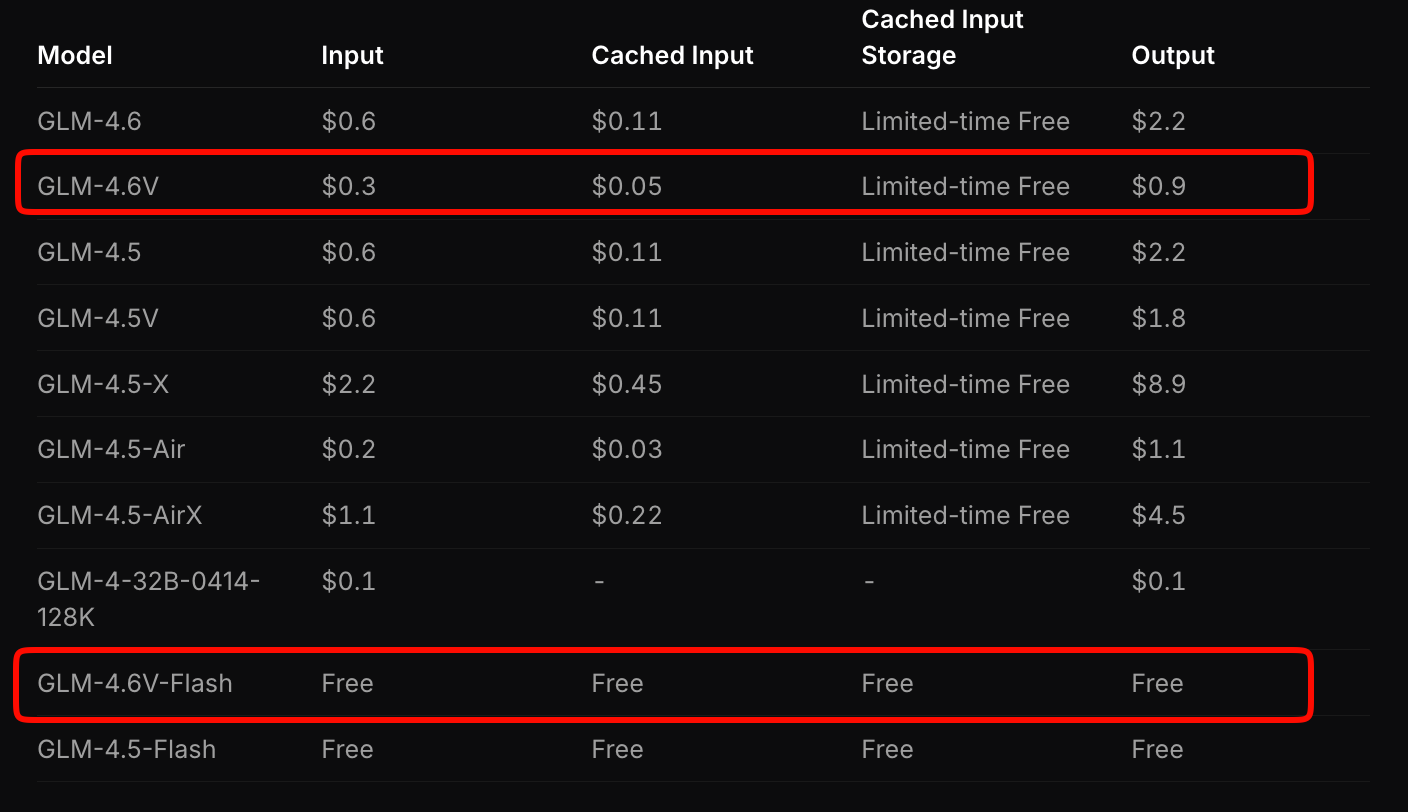
ในทางตรงกันข้าม GLM-4.6V-Flash ให้การเข้าถึงฟรี เหมาะสำหรับการสร้างต้นแบบหรือการปรับใช้ที่ปลายทาง (edge deployments) ไม่มีค่าธรรมเนียมโทเค็น อย่างไรก็ตาม ค่าใช้จ่ายในการอนุมานจะผูกกับฮาร์ดแวร์ของคุณ โปรโมชั่นจำกัดเวลาเพิ่มโควตาการใช้งานเป็นสามเท่าในราคาหนึ่งในเจ็ดสำหรับแพลนแบบชำระเงิน ทำให้การทดลองใช้งานมีราคาไม่แพง
เปรียบเทียบกับคู่แข่ง: GLM-4.6V มีราคาต่ำกว่า API แบบหลายรูปแบบที่คล้ายกันถึง 20-30% ในขณะที่ยังคงให้ประสิทธิภาพที่เหนือกว่า สำหรับแอปพลิเคชันที่มีปริมาณมาก ให้คำนวณค่าใช้จ่ายผ่านเครื่องมือประมาณการของ Z.ai ป้อนปริมาณงานตัวอย่าง เช่น การวิเคราะห์เอกสาร 100 รายการต่อวัน แล้วมันจะประมาณการค่าใช้จ่ายรายเดือน
นอกจากนี้ น้ำหนักโมเดลแบบโอเพนซอร์สยังช่วยลดต้นทุนในระยะยาว ปรับแต่งบนข้อมูลของคุณเพื่อลดการพึ่งพาการเรียกใช้บริการคลาวด์ โดยรวมแล้ว การกำหนดราคานี้ช่วยให้สตาร์ทอัพสามารถขยายขนาดได้โดยไม่มีข้อจำกัดด้านงบประมาณ
การผสานรวม GLM-4.6V API กับ Apidog: การเพิ่มประสิทธิภาพเวิร์กโฟลว์เชิงปฏิบัติ
Apidog เปลี่ยนการผสานรวม GLM-4.6V จากการทำงานที่น่าเบื่อด้วยมือเป็นการทำงานร่วมกันที่มีประสิทธิภาพ ในฐานะไคลเอนต์ API และเครื่องมือออกแบบ มันนำเข้าข้อมูลจำเพาะของ Z.ai โดยสร้างเทมเพลตคำขอโดยอัตโนมัติ คุณสามารถลากและวางเพย์โหลดแบบหลายรูปแบบ ดูตัวอย่างการตอบสนอง และส่งออกเป็นโค้ดส Snippets ใน Python, Node.js หรือ cURL ได้
เริ่มต้นด้วยการสร้างโปรเจกต์ใหม่ใน Apidog วาง URL ของปลายทาง (endpoint) และยืนยันตัวตนด้วยคีย์ของคุณ สำหรับงาน visual grounding ให้สร้างคำขอ: เพิ่มประเภท image_url, ป้อนข้อความแจ้งพิกัด และกดส่ง Apidog จะแสดงผลลัพธ์ด้วยภาพ โดยเน้นขั้นตอนการคิด
การทำงานร่วมกันโดดเด่นที่นี่ แบ่งปันคอลเล็กชันกับทีม; ควบคุมเวอร์ชันของปลายทางเมื่อคุณเพิ่มเครื่องมือ ตัวแปรสภาพแวดล้อมช่วยรักษาความปลอดภัยคีย์ในสภาพแวดล้อม dev, staging และ prod ผลที่ตามมาคือ วงจรการปรับใช้จะสั้นลง—ทดสอบสายโซ่เอเจนต์ทั้งหมดได้ภายในไม่กี่นาที
ขยายไปยังการตรวจสอบ: Apidog จะบันทึกความล่าช้าและข้อผิดพลาด ชี้ให้เห็นถึงปัญหาคอขวดในขั้นตอนการทำงานแบบหลายรูปแบบ จับคู่กับ GLM-4.6V-Flash สำหรับการทดสอบในเครื่องฟรี จากนั้นปรับขนาดไปยังคลาวด์ นักพัฒนารายงานว่าการสร้างต้นแบบเร็วขึ้น 40% ด้วยเครื่องมือดังกล่าว
กรณีการใช้งานจริง: การนำ GLM-4.6V ไปใช้ในการผลิต
GLM-4.6V โดดเด่นในอุตสาหกรรมที่ต้องใช้เอกสารจำนวนมาก นักวิเคราะห์ทางการเงินอัปโหลดรายงาน; โมเดลจะวิเคราะห์แผนภูมิ คำนวณอัตราส่วน และสร้างบทสรุปสำหรับผู้บริหารพร้อมภาพประกอบ บริษัทแห่งหนึ่งลดเวลาการวิเคราะห์จากหลายชั่วโมงเหลือเพียงไม่กี่นาที โดยใช้บริบท 128K สำหรับการยื่นรายงานประจำปี
ในอีคอมเมิร์ซ เอเจนต์ค้นหาด้วยภาพจะทำงาน ลูกค้าอัปโหลดรูปภาพผลิตภัณฑ์; GLM-4.6V วางแผนการค้นหา ดึงข้อมูลที่ตรงกัน และให้เหตุผลเกี่ยวกับคุณลักษณะต่างๆ เช่น สีที่แตกต่างกัน สิ่งนี้ช่วยเพิ่มอัตราการแปลงได้ 15% ตามที่ผู้ใช้งานกลุ่มแรกๆ รายงาน

ทีม Frontend เร่งการสร้างต้นแบบ ป้อนภาพหน้าจอ; ได้รับโค้ดที่สามารถแก้ไขได้ ทำซ้ำด้วยข้อความแจ้ง เช่น "เพิ่ม navbar ที่ตอบสนองต่อขนาดหน้าจอ" ความแม่นยำระดับพิกเซลของโมเดลช่วยลดการแก้ไข ทำให้ลดเวลาตั้งแต่การออกแบบจนถึงการปรับใช้ลงครึ่งหนึ่ง

แพลตฟอร์มวิดีโอได้รับประโยชน์จากการให้เหตุผลเชิงเวลา (temporal reasoning) สรุปการบรรยายพร้อมการประทับเวลา หรือตรวจจับเหตุการณ์ในฟีดกล้องวงจรปิด การใช้เครื่องมือแบบเนทีฟช่วยให้ผสานรวมกับฐานข้อมูลได้ และระบุความผิดปกติโดยอัตโนมัติ
กรณีเหล่านี้แสดงให้เห็นถึงความหลากหลายในการใช้งานของ GLM-4.6V อย่างไรก็ตาม ความสำเร็จขึ้นอยู่กับวิศวกรรมพร้อมต์ (prompt engineering)—การสร้างคำแนะนำที่ชัดเจนเพื่อเพิ่มความแม่นยำสูงสุด
ความท้าทายและแนวปฏิบัติที่ดีที่สุดสำหรับการใช้ GLM-4.6V API
แม้จะมีจุดแข็ง แต่โมเดลแบบหลายรูปแบบก็เผชิญกับอุปสรรค อินพุตที่มีความละเอียดสูงจะเพิ่มจำนวนโทเค็น ทำให้ต้นทุนสูงขึ้น—ควรบีบอัดรูปภาพให้มีขนาด 512x512 พิกเซลก่อน ความเสี่ยงของบริบทเกินจะนำไปสู่การสร้างข้อมูลที่ผิดพลาด; ควรแบ่งวิดีโอที่มีความยาวออกเป็นส่วนๆ
แนวปฏิบัติที่ดีที่สุดช่วยลดปัญหาเหล่านี้ ใช้โหมดการคิดเพื่อดีบัก; ซึ่งจะแสดงขั้นตอนกลางๆ ตรวจสอบผลลัพธ์ของเครื่องมือด้วยการยืนยันในโค้ดของคุณ สำหรับผู้ใช้ Apidog ให้ตั้งค่าการทดสอบอัตโนมัติบนปลายทางเพื่อบังคับใช้ schema
ตรวจสอบโควตาอย่างใกล้ชิด—Flash แบบฟรีช่วยหลีกเลี่ยงความประหลาดใจ แต่แพลนแบบชำระเงินต้องมีการวางแผนงบประมาณ สุดท้าย ปรับแต่งบนข้อมูลเฉพาะโดเมนผ่านน้ำหนักโมเดลแบบเปิดเพื่อเพิ่มความจำเพาะ
บทสรุป: ยกระดับโปรเจกต์ของคุณด้วย GLM-4.6V วันนี้
GLM-4.6V กำหนดนิยามใหม่ของ AI แบบหลายรูปแบบผ่านเครื่องมือแบบเนทีฟ บริบทที่กว้างขวาง และการเข้าถึงแบบเปิด API ของมันมีราคาที่แข่งขันได้ที่ 0.6 ดอลลาร์ต่อล้านอินพุตสำหรับโมเดลเต็ม และฟรีสำหรับ Flash ซึ่งสามารถผสานรวมกับแพลตฟอร์มอย่าง Apidog ได้อย่างราบรื่น ตั้งแต่เอเจนต์เอกสารไปจนถึงเครื่องมือสร้าง UI มันขับเคลื่อนนวัตกรรม
นำข้อมูลเชิงลึกเหล่านี้ไปใช้ตอนนี้: รับคีย์ API ของคุณ ทดสอบใน Apidog และเริ่มสร้าง อนาคตของ AI เป็นของผู้ที่ใช้ประโยชน์จากความสามารถเหล่านี้ได้ตั้งแต่เนิ่นๆ คุณจะเปลี่ยนแอปพลิเคชันใดต่อไป?