
นักพัฒนาต่างมองหาวิธีที่มีประสิทธิภาพในการผสานรวมโมเดล AI ขั้นสูงเข้ากับแอปพลิเคชันอย่างต่อเนื่อง Gemini 3 Flash API มอบทางเลือกอันทรงพลังที่สมดุลระหว่างความชาญฉลาดระดับสูง ความเร็ว และความคุ้มค่า
Google ยังคงพัฒนาข้อเสนอ AI แบบรู้สร้าง (Generative AI) อย่างต่อเนื่อง นอกจากนี้ โมเดล Gemini 3 Flash ยังโดดเด่นในกลุ่มผลิตภัณฑ์ปัจจุบัน วิศวกรสามารถเข้าถึงได้ผ่าน Gemini API ซึ่งช่วยให้การสร้างต้นแบบและการนำไปใช้งานจริงทำได้อย่างรวดเร็ว
การขอรับ Gemini API Key ของคุณ
คุณเริ่มต้นด้วยการรับ API key ก่อนอื่น ไปที่ Google AI Studio ที่ aistudio.google.com. ลงชื่อเข้าใช้ด้วยบัญชี Google ของคุณหากจำเป็น ถัดไป เลือกโมเดล Gemini 3 Flash preview จากตัวเลือกที่มี จากนั้น คลิกตัวเลือกเพื่อสร้าง API key
Google จะให้คีย์นี้ทันที ยิ่งไปกว่านั้น เก็บรักษาไว้อย่างปลอดภัย—ถือว่าเป็นข้อมูลรับรองที่ละเอียดอ่อน คุณใช้มันในส่วนหัว x-goog-api-key สำหรับคำขอทั้งหมด หรือตั้งเป็นตัวแปรสภาพแวดล้อมเพื่อความสะดวกในการใช้งานในสคริปต์
หากไม่มีคีย์ที่ถูกต้อง คำขอจะล้มเหลวทันทีพร้อมข้อผิดพลาดในการตรวจสอบสิทธิ์ ดังนั้น ตรวจสอบการทำงานของคีย์ตั้งแต่เนิ่นๆ โดยการทดสอบในอินเทอร์เฟซแบบโต้ตอบของ Google AI Studio
ทำความเข้าใจความสามารถของ Gemini 3 Flash
Gemini 3 Flash มอบความชาญฉลาดระดับ Pro ด้วยความเร็ว Flash โดยเฉพาะอย่างยิ่ง ID โมเดลยังคงเป็น gemini-3-flash-preview ในช่วงระยะเวลาพรีวิว มันรองรับบริบทอินพุตขนาดใหญ่ถึง 1,048,576 โทเค็น และขีดจำกัดเอาต์พุต 65,536 โทเค็น
นอกจากนี้ ยังสามารถจัดการอินพุตแบบหลายรูปแบบได้อย่างมีประสิทธิภาพ คุณสามารถป้อนข้อความ รูปภาพ วิดีโอ เสียง และ PDF ผลลัพธ์ส่วนใหญ่ประกอบด้วยข้อความ พร้อมตัวเลือกสำหรับ JSON แบบมีโครงสร้างผ่านการบังคับใช้ Schema
คุณสมบัติหลัก ได้แก่ การควบคุมการใช้เหตุผลในตัว นักพัฒนาสามารถปรับความลึกของการคิดโดยใช้พารามิเตอร์ thinking_level: minimal, low, medium หรือ high (ค่าเริ่มต้น) High จะเพิ่มคุณภาพการใช้เหตุผลให้สูงสุด ในขณะที่ระดับที่ต่ำกว่าจะให้ความสำคัญกับความหน่วงแฝงสำหรับสถานการณ์ที่มีปริมาณงานสูง
นอกจากนี้ ควบคุมความละเอียดของสื่อสำหรับงานการมองเห็น ตัวเลือกมีตั้งแต่ low ถึง ultra_high ซึ่งส่งผลต่อการใช้โทเค็นต่อเฟรมหรือรูปภาพ เลือกให้เหมาะสม—สูงสำหรับรูปภาพที่มีรายละเอียดมาก ปานกลางสำหรับเอกสาร
โมเดลนี้รวมเครื่องมือต่างๆ เช่น การอ้างอิงข้อมูลจาก Google Search, การดำเนินการโค้ด และการเรียกใช้ฟังก์ชัน อย่างไรก็ตาม ไม่รวมการสร้างภาพและเครื่องมือหุ่นยนต์ขั้นสูงบางอย่าง
ราคาสำหรับ Gemini 3 Flash API
การจัดการต้นทุนเป็นสิ่งสำคัญในการรวม API Gemini 3 Flash ทำงานบนโมเดลแบบจ่ายตามการใช้งานจริง (pay-as-you-go) โทเค็นอินพุตมีค่าใช้จ่าย $0.50 ต่อล้านโทเค็น ในขณะที่โทเค็นเอาต์พุต (รวมถึงโทเค็นการคิด) มีค่าใช้จ่าย $3 ต่อล้านโทเค็น
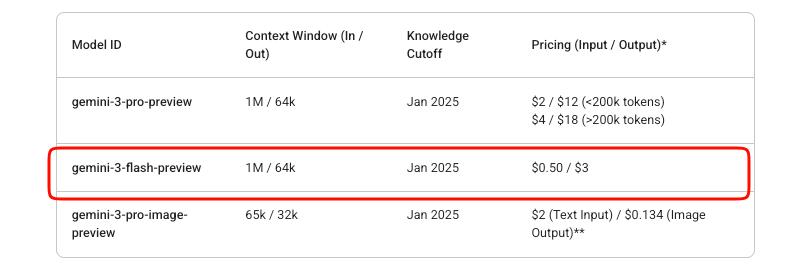
Google เสนอการทดลองฟรีใน AI Studio อย่างไรก็ตาม การใช้งาน API ในการผลิตจะมีการเรียกเก็บเงินเมื่อมีการเปิดใช้งานการเรียกเก็บเงิน ไม่มีระดับฟรีที่นอกเหนือจากการทดลองใช้ Studio สำหรับโมเดลพรีวิวนี้
การแคชบริบทและการประมวลผลเป็นชุดช่วยเพิ่มประสิทธิภาพต้นทุนได้อีก การแคชช่วยลดการประมวลผลโทเค็นที่ซ้ำซ้อนสำหรับบริบทที่ซ้ำกัน Batch API เหมาะสำหรับงานที่มีปริมาณมากแบบอะซิงโครนัส
ตรวจสอบการใช้งานผ่านแดชบอร์ด Google Cloud Billing การเพิ่มขึ้นอย่างกะทันหันมักเกิดจากการตั้งค่า media_resolution สูงหรือการใช้เหตุผลอย่างละเอียด
การสร้างคำขอ API ครั้งแรกของคุณ
คุณเริ่มต้นด้วยการสร้างข้อความธรรมดา เอนด์พอยต์คือ https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent
สร้างคำขอ POST ใส่ API key ของคุณในส่วนหัว เนื้อหาประกอบด้วย contents เป็นอาร์เรย์ของออบเจกต์ role-part
นี่คือตัวอย่าง cURL พื้นฐาน:
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Explain quantum entanglement briefly."}]
}]
}'
การตอบกลับจะส่งคืนผู้สมัครที่มีส่วนข้อความ นอกจากนี้ จัดการข้อมูลเมตาการใช้งานสำหรับจำนวนโทเค็น
สำหรับการตอบกลับแบบสตรีมมิ่ง ให้ใช้เอนด์พอยต์ :streamGenerateContent ซึ่งจะให้ผลลัพธ์บางส่วนทีละน้อย ซึ่งช่วยปรับปรุงความหน่วงแฝงที่รับรู้ได้ในแอปพลิเคชัน
การผสานรวมกับ SDK อย่างเป็นทางการ
Google บำรุงรักษา SDKs ที่ทำให้การโต้ตอบง่ายขึ้น ติดตั้งแพ็คเกจ Python ผ่าน pip install google-generativeai
เริ่มต้นไคลเอ็นต์:
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash-preview")
response = model.generate_content("Summarize recent AI advancements.")
print(response.text)
SDK จะจัดการลายเซ็นความคิด (thought signatures) โดยอัตโนมัติสำหรับการสนทนาหลายรอบและการใช้เครื่องมือ ดังนั้น ควรใช้ SDK มากกว่า HTTP แบบดิบสำหรับโค้ดที่ใช้งานจริง
ผู้ใช้ Node.js สามารถเข้าถึงความสะดวกสบายที่คล้ายกันผ่าน @google/generative-ai
การจัดการอินพุตแบบหลายรูปแบบ
Gemini 3 Flash มีความโดดเด่นในการประมวลผลแบบหลายรูปแบบ อัปโหลดไฟล์หรือระบุ URI ข้อมูลแบบอินไลน์
ใน Python:
model = genai.GenerativeModel("gemini-3-flash-preview")
image = genai.upload_file("diagram.png")
response = model.generate_content(["Describe this image in detail.", image])
print(response.text)
ปรับ media_resolution ในการกำหนดค่าการสร้างเพื่อประสิทธิภาพโทเค็น:
generation_config = {
"media_resolution": "media_resolution_high"
}
วิดีโอและ PDF มีรูปแบบที่คล้ายกัน ยิ่งไปกว่านั้น รวมโมดูลัลลิตี้หลายรายการในคำขอเดียวสำหรับงานวิเคราะห์ที่ซับซ้อน
คุณสมบัติขั้นสูง: ระดับความคิดและเครื่องมือ
ควบคุมการใช้เหตุผลอย่างชัดเจน ตั้งค่า thinking_level เป็น "low" เพื่อการตอบสนองที่รวดเร็ว:
"generationConfig": {
"thinking_level": "low"
}
ระดับความคิดสูงช่วยให้กระบวนการ Chain-of-Thought (การคิดเป็นขั้นตอน) ภายในลึกซึ้งยิ่งขึ้น
เปิดใช้งานเครื่องมือต่างๆ เช่น การเรียกใช้ฟังก์ชัน กำหนดฟังก์ชันในคำขอ; โมเดลจะส่งคืนการเรียกเมื่อเหมาะสม
เอาต์พุตแบบมีโครงสร้างบังคับใช้ JSON schemas:
"generationConfig": {
"response_mime_type": "application/json",
"response_schema": {...}
}
รวมสิ่งเหล่านี้เข้าด้วยกันสำหรับขั้นตอนการทำงานแบบ Agentic ตัวอย่างเช่น การอ้างอิงข้อมูลการตอบสนองกับการค้นหาแบบเรียลไทม์
การทดสอบและการแก้ไขข้อบกพร่องด้วย Apidog
การทดสอบที่มีประสิทธิภาพช่วยให้การผสานรวมเชื่อถือได้ Apidog เป็นเครื่องมือที่แข็งแกร่งสำหรับวัตถุประสงค์นี้ มันรวมการออกแบบ API, การแก้ไขข้อบกพร่อง, การจำลอง และการทดสอบอัตโนมัติไว้ในแพลตฟอร์มเดียว
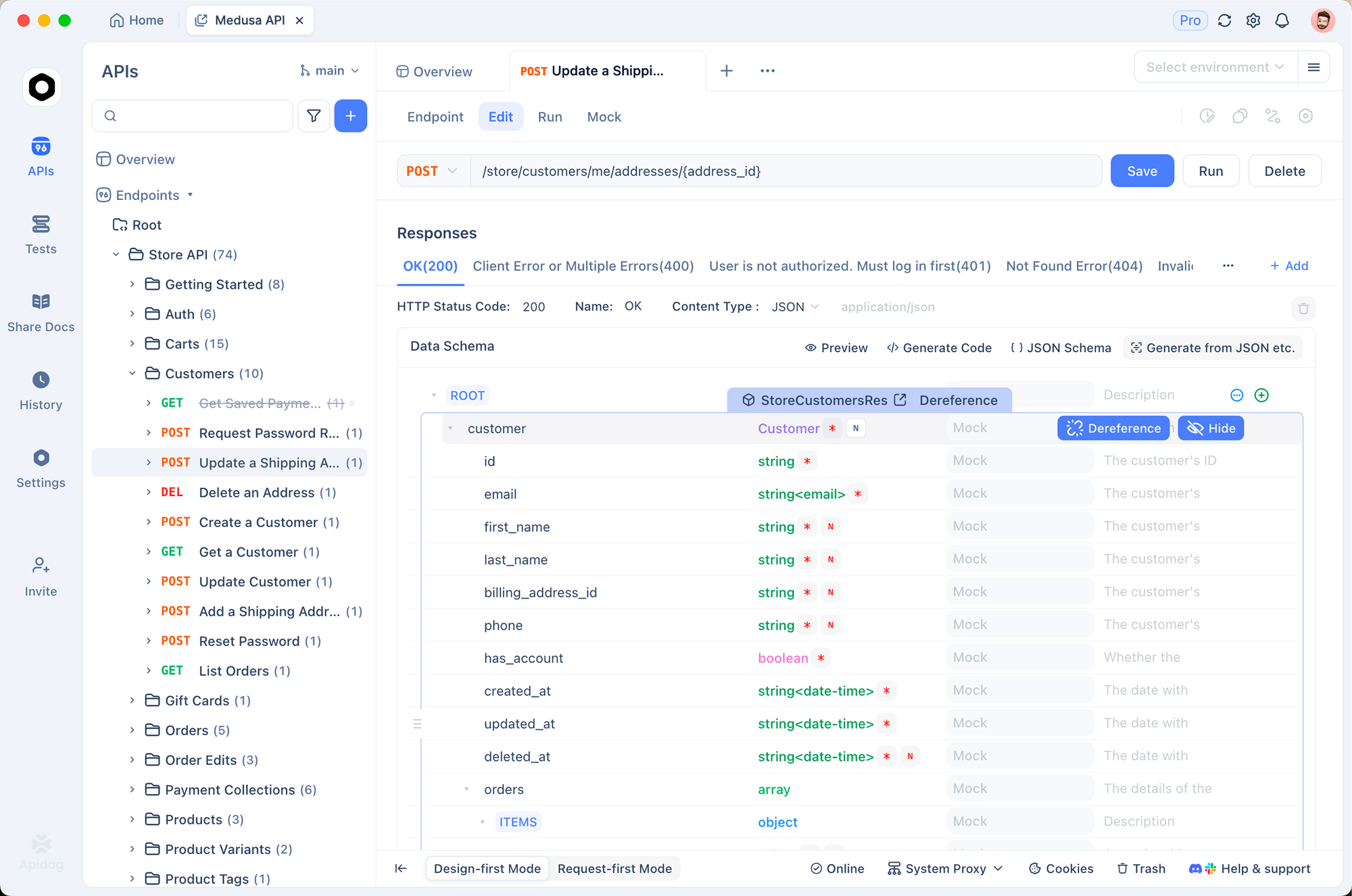
ก่อนอื่น นำเข้าเอนด์พอยต์ Gemini เข้าสู่ Apidog สร้างคำขอใหม่ที่ชี้ไปยังเมธอด generateContent จัดเก็บ API key ของคุณเป็นตัวแปรสภาพแวดล้อม—Apidog รองรับสภาพแวดล้อมหลายรูปแบบสำหรับ dev, staging และ prod
ส่งคำขอด้วยภาพ Apidog แสดงการตอบกลับอย่างชัดเจน โดยเน้นการใช้โทเค็นและข้อผิดพลาด นอกจากนี้ ตั้งค่าการยืนยันเพื่อตรวจสอบโครงสร้างการตอบกลับโดยอัตโนมัติ
สำหรับการแชทหลายรอบ รักษาประวัติการสนทนาข้ามคำขอโดยใช้สคริปต์หรือตัวแปรของ Apidog ซึ่งจำลองเซสชันผู้ใช้จริงได้อย่างมีประสิทธิภาพ
Apidog ยังสร้างเซิร์ฟเวอร์จำลอง (mock servers) จำลองการตอบกลับของ Gemini ระหว่างการพัฒนาส่วนหน้าโดยไม่ต้องใช้โควต้า
ยิ่งไปกว่านั้น ทำให้ชุดทดสอบเป็นอัตโนมัติ กำหนดสถานการณ์ที่ครอบคลุมระดับความคิดที่แตกต่างกัน อินพุตหลายรูปแบบ และกรณีข้อผิดพลาด เรียกใช้ใน CI/CD pipelines
นักพัฒนาหลายคนพบว่า Apidog ช่วยลดเวลาในการแก้ไขข้อบกพร่องได้อย่างมากเมื่อเทียบกับ cURL แบบดิบหรือไคลเอ็นต์พื้นฐาน อินเทอร์เฟซที่ใช้งานง่ายสามารถจัดการกับเนื้อหา JSON ที่ซับซ้อนได้อย่างง่ายดาย
แนวทางปฏิบัติที่ดีที่สุดสำหรับการใช้งานจริง
ใช้ตรรกะการลองใหม่ (retry logic) พร้อมการหน่วงเวลาแบบทวีคูณ (exponential backoff) มีการจำกัดอัตรา โดยเฉพาะอย่างยิ่งในช่วงพรีวิว
แคชบริบทในที่ที่ทำได้เพื่อลดโทเค็น ใช้ลายเซ็นความคิด (thought signatures) อย่างแม่นยำในคำขอแบบดิบเพื่อหลีกเลี่ยงข้อผิดพลาดในการตรวจสอบความถูกต้อง
ตรวจสอบต้นทุนเชิงรุก บันทึกจำนวนโทเค็นอินพุต/เอาต์พุตต่อคำขอ
รักษาระดับอุณหภูมิไว้ที่ 1.0 ตามค่าเริ่มต้น—การเบี่ยงเบนจะลดประสิทธิภาพการใช้เหตุผล
สุดท้าย อัปเดตข้อมูลผ่านเอกสารอย่างเป็นทางการ โมเดลพรีวิวมีการพัฒนา; วางแผนสำหรับการเปลี่ยนแปลงที่อาจเกิดขึ้น
บทสรุป
ตอนนี้คุณมีความรู้ในการผสานรวม Gemini 3 Flash ได้อย่างมีประสิทธิภาพ เริ่มต้นด้วยคำของ่ายๆ จากนั้นขยายไปยังแอปพลิเคชันแบบหลายรูปแบบและที่เสริมด้วยเครื่องมือ ใช้ประโยชน์จากเครื่องมืออย่าง Apidog เพื่อปรับปรุงขั้นตอนการทำงานของการพัฒนา
Gemini 3 Flash ช่วยให้นักพัฒนาสร้างระบบอัจฉริยะที่ตอบสนองได้ในราคาที่เอื้อมถึง ทดลองใช้ได้อย่างอิสระใน AI Studio จากนั้นเปลี่ยนไปใช้ API สำหรับการนำไปใช้งานจริง