
คุณต้องการเครื่องมือที่มีประสิทธิภาพในการสร้างภาพคุณภาพสูงจากข้อความแจ้ง (text prompts) ในแอปพลิเคชันยุคใหม่ Z-Image API ตอบสนองความต้องการนี้โดยตรง นักพัฒนาสามารถเข้าถึงโมเดลข้อความเป็นภาพอันทรงพลังผ่านอินเทอร์เฟซที่ไม่มีค่าใช้จ่าย ซึ่งให้ผลลัพธ์ที่สมจริงรวดเร็ว API นี้ใช้ประโยชน์จากโมเดล Z-Image-Turbo แบบโอเพ่นซอร์สจากทีม Tongyi-MAI ของ Alibaba ซึ่งทำงานภายใต้ใบอนุญาต Apache 2.0 คุณจะได้รับประโยชน์จากการอนุมานที่ใช้เวลาไม่ถึงวินาทีบนฮาร์ดแวร์ที่เหมาะสม ทำให้เหมาะสำหรับคุณสมบัติแบบเรียลไทม์ในเว็บแอป เครื่องมือบนมือถือ หรือเวิร์กโฟลว์อัตโนมัติ
ต่อไป คุณจะได้สำรวจพื้นฐานโอเพ่นซอร์สของ Z-Image-Turbo จากนั้น คุณจะได้รับข้อมูลเชิงลึกเกี่ยวกับวิธีการเข้าถึง API และยืนยันโครงสร้างราคาฟรี สุดท้าย คุณจะนำการผสานรวมเชิงปฏิบัติไปใช้งาน ขั้นตอนเหล่านี้จะช่วยให้คุณสามารถปรับใช้ความสามารถในการสร้างภาพได้อย่างมีประสิทธิภาพ
ทำความเข้าใจโมเดล Z-Image-Turbo แบบโอเพ่นซอร์ส
คุณเริ่มต้นด้วยเทคโนโลยีหลักที่อยู่เบื้องหลัง Z-Image API: โมเดล Z-Image-Turbo ทีม Tongyi-MAI ของ Alibaba เผยแพร่โมเดลขนาด 6 พันล้านพารามิเตอร์นี้เป็นโอเพ่นซอร์สเต็มรูปแบบภายใต้ใบอนุญาต Apache 2.0 ใบอนุญาตนี้อนุญาตให้ใช้งานเชิงพาณิชย์, การปรับเปลี่ยน และการเผยแพร่โดยไม่มีข้อจำกัด ซึ่งช่วยเร่งการนำไปใช้ในสภาพแวดล้อมการผลิต
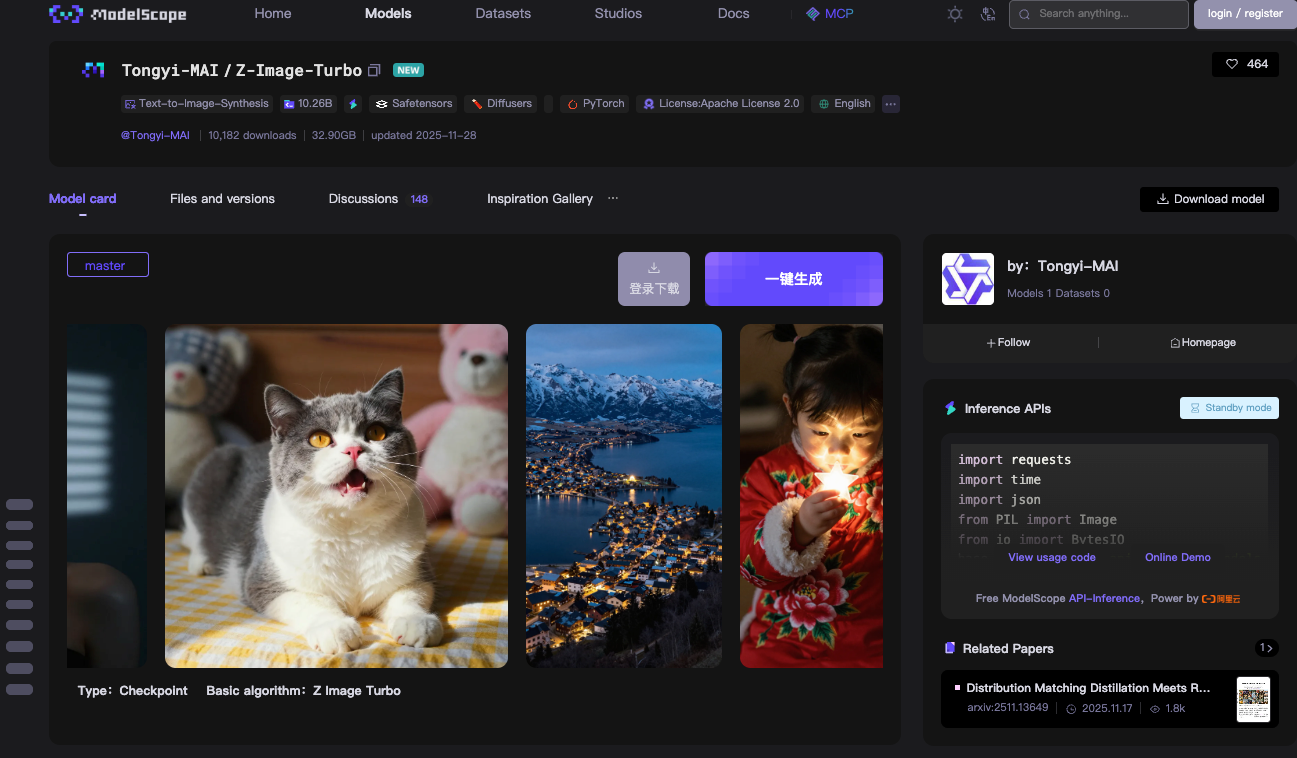
Z-Image-Turbo สร้างขึ้นบนสถาปัตยกรรม Scalable Single-Stream Diffusion Transformer (S3-DiT) โมเดลแบบดูอัลสตรีมแบบดั้งเดิมจะแยกการประมวลผลข้อความและภาพ ซึ่งทำให้สิ้นเปลืองพารามิเตอร์ อย่างไรก็ตาม S3-DiT จะรวมโทเค็นข้อความ, โทเค็นความหมายภาพ และโทเค็น VAE ของภาพเข้าด้วยกันเป็นสตรีมเดียว การออกแบบนี้ช่วยเพิ่มประสิทธิภาพสูงสุด ผลลัพธ์คือ โมเดลสามารถทำงานได้ภายใน VRAM 16GB บน GPU สำหรับผู้บริโภค เช่น การ์ด NVIDIA RTX 40-series คุณสามารถทำเช่นนี้ได้โดยไม่ลดทอนคุณภาพของผลลัพธ์
โมเดลนี้มีความโดดเด่นในการสังเคราะห์ภาพที่สมจริง สามารถสร้างฉาก, ภาพบุคคล และทิวทัศน์ที่มีรายละเอียดจากข้อความแจ้งที่อธิบายได้ดี ตัวอย่างเช่น ข้อความแจ้งว่า "ทะเลสาบภูเขาอันเงียบสงบยามพลบค่ำพร้อมป้ายสองภาษาทั้งภาษาอังกฤษและจีน" จะสร้างภาพที่คมชัดและเข้าใจบริบทได้ Z-Image-Turbo จัดการกับคำสั่งที่ซับซ้อนได้ดี ด้วย Prompt Enhancer ที่ผสานรวมอยู่ภายใน ส่วนประกอบนี้ช่วยปรับปรุงอินพุตเพื่อให้เป็นไปตามคำสั่งได้ดียิ่งขึ้น ลดสิ่งแปลกปลอมที่มักพบในโมเดล Diffusion รุ่นก่อนๆ
ความเร็วในการอนุมานเป็นจุดเด่นของ Z-Image-Turbo โดยต้องใช้เพียง 8 จำนวนการประเมินฟังก์ชัน (NFE) ซึ่งเทียบเท่ากับ 9 ขั้นตอนการอนุมานในการใช้งานจริง บน GPU ระดับองค์กร H800 คุณจะเห็นความล่าช้าไม่ถึงวินาที—บ่อยครั้งต่ำกว่า 500ms ต่อภาพ การตั้งค่าสำหรับผู้บริโภคจะใช้เวลา 2-5 วินาที ขึ้นอยู่กับฮาร์ดแวร์ ประสิทธิภาพนี้มาจากเทคนิคการกลั่น (distillation techniques) เช่น Decoupled-DMD และ DMDR ซึ่งบีบอัดโมเดล Z-Image พื้นฐานในขณะที่ยังคงประสิทธิภาพไว้
คุณสามารถดาวน์โหลดน้ำหนักโมเดลจาก ModelScope หรือคลังข้อมูล Hugging Face สาขาหลักมีไฟล์ checkpoint รวมประมาณ 24GB ความเข้ากันได้กับ PyTorch รับประกันการผสานรวมที่กว้างขวาง สำหรับการทดสอบในเครื่อง คุณสามารถติดตั้งส่วนที่ต้องพึ่งพาผ่าน pip: `torch`, `torchvision` และ `modelscope>=1.18.0` สคริปต์ไปป์ไลน์พื้นฐานจะโหลดโมเดลและสร้างภาพได้ภายในไม่ถึง 10 บรรทัดของโค้ด
พิจารณาตัวอย่างนี้สำหรับการอนุมานในเครื่อง:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import torch
device = "cuda" if torch.cuda_is_available() else "cpu"
pipe = pipeline(Tasks.text_to_image_synthesis, model="Tongyi-MAI/Z-Image-Turbo", device=device)
output = pipe({
"text": "A photorealistic golden retriever playing in a sunlit park, 1024x1024",
"width": 1024,
"height": 1024,
"num_inference_steps": 9
})
output["output_imgs"][0].save("generated_image.png")
โค้ดนี้จะเริ่มต้นไปป์ไลน์ ประมวลผลข้อความแจ้ง และบันทึกผลลัพธ์ คุณจะสังเกตเห็นพารามิเตอร์ `num_inference_steps: 9` ซึ่งจะกระตุ้นการกลั่นแบบ 8 ขั้นตอนเพื่อความเร็วสูงสุด ระดับ Guidance scale ยังคงอยู่ที่ 0.0 เนื่องจากเวอร์ชัน Turbo จะข้าม classifier-free guidance เพื่อรักษาระดับความเร็ว
ผลการทดสอบยืนยันความสามารถในการแข่งขันของ Z-Image-Turbo บน AI Arena ของ Alibaba โมเดลนี้ได้คะแนนสูงในการประเมินความชอบของมนุษย์แบบ Elo ซึ่งทำผลงานได้ดีกว่าโมเดลโอเพ่นซอร์สอื่นๆ มากมายในด้านความสมจริงของภาพและความแม่นยำของข้อความ เมื่อเปรียบเทียบกับโมเดลอย่าง Stable Diffusion 3 โมเดลนี้ใช้ขั้นตอนน้อยกว่าและใช้หน่วยความจำน้อยกว่า แต่ให้รายละเอียดที่เทียบเท่ากัน
อย่างไรก็ตาม ยังมีข้อจำกัดอยู่ โมเดลนี้ให้ความสำคัญกับความเร็วมากกว่าความละเอียดที่สูงมาก การผลักดันเกิน 1536x1536 อาจทำให้เกิดความเบลอโดยไม่มีการปรับแต่งละเอียด นอกจากนี้ยังขาดการแก้ไขภาพเป็นภาพ (image-to-image editing) แบบเนทีฟในเวอร์ชัน Turbo ซึ่งจะอยู่ใน Z-Image-Edit ที่จะออกในอนาคต อย่างไรก็ตาม สำหรับงานข้อความเป็นภาพ Z-Image-Turbo ก็เป็นรากฐานที่มั่นคงและเข้าถึงได้ง่าย
คุณสามารถขยายโมเดลนี้ผ่าน Z-Image API ซึ่งโฮสต์อยู่บนโครงสร้างพื้นฐานของ ModelScope การเปลี่ยนจากเครื่องในองค์กรไปสู่คลาวด์ช่วยขจัดภาระการตั้งค่า ด้วยเหตุนี้ คุณจึงมุ่งเน้นไปที่ตรรกะของแอปพลิเคชันแทนที่จะเป็นการปรับแต่งฮาร์ดแวร์
การเข้าถึง Z-Image API ฟรี: การตั้งค่าทีละขั้นตอน
คุณเปลี่ยนผ่านสู่การผสานรวม API ได้อย่างราบรื่น Z-Image API ทำงานผ่านบริการอนุมานของ ModelScope ซึ่งโฮสต์ Z-Image-Turbo สำหรับการเรียกใช้ระยะไกล การตั้งค่านี้ต้องการการกำหนดค่าน้อยที่สุด แต่ให้ความน่าเชื่อถือระดับองค์กร
อันดับแรก คุณลงทะเบียนบน แพลตฟอร์ม ModelScope สร้างบัญชีด้วยอีเมลหรือข้อมูลรับรอง GitHub ของคุณ เมื่อเข้าสู่ระบบแล้ว ให้ไปที่ส่วน API ใต้โปรไฟล์ของคุณ สร้าง ModelScope Token ซึ่งทำหน้าที่เป็นคีย์การรับรองความถูกต้องแบบ Bearer ของคุณ จัดเก็บไว้อย่างปลอดภัย เนื่องจากคำขอทั้งหมดบังคับให้ต้องมีคีย์นี้ในส่วนหัว Authorization
ปลายทาง API เน้นการประมวลผลแบบอะซิงโครนัส ซึ่งเหมาะสำหรับความต้องการที่มีปริมาณงานสูง คุณส่งงานสร้างภาพผ่าน POST ไปยัง `https://api-inference.modelscope.cn/v1/images/generations` การตอบกลับจะส่งคืน task_id ทันที จากนั้น คุณตรวจสอบสถานะ `https://api-inference.modelscope.cn/v1/tasks/{task_id}` ทุก 5-10 วินาทีจนกว่าจะเสร็จสมบูรณ์ การออกแบบนี้ช่วยป้องกันการหมดเวลาสำหรับการสร้างภาพที่ใช้เวลานาน แม้ว่าความเร็วของ Z-Image-Turbo จะทำให้การรอสั้นลง—โดยทั่วไปคือ 5-15 วินาทีตั้งแต่ต้นจนจบ
ส่วนหัวที่สำคัญประกอบด้วย:
Authorization: Bearer {your_token}Content-Type: application/jsonX-ModelScope-Async-Mode: true(สำหรับการส่ง)X-ModelScope-Task-Type: image_generation(สำหรับการตรวจสอบสถานะ)
เนื้อหาของคำขอจะระบุพารามิเตอร์ต่างๆ เช่น รหัสโมเดล (model ID), ข้อความแจ้ง (prompt), ขนาด และขั้นตอน คุณตั้งค่า "model": "Tongyi-MAI/Z-Image-Turbo" เพื่อกำหนดเป้าหมายรูปแบบนี้ ขนาดเริ่มต้นคือ 1024x1024 แต่คุณสามารถปรับ height และ width สำหรับอัตราส่วนภาพที่กำหนดเองได้ รักษา guidance_scale: 0.0 และ num_inference_steps: 9 เพื่อผลลัพธ์ที่ดีที่สุด
ตัวอย่าง curl ฉบับสมบูรณ์แสดงให้เห็นถึงกระบวนการ:
# ขั้นตอนที่ 1: ส่งงาน
curl -X POST "https://api-inference.modelscope.cn/v1/images/generations" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-H "X-ModelScope-Async-Mode: true" \
-d '{
"model": "Tongyi-MAI/Z-Image-Turbo",
"prompt": "A futuristic cityscape at night with neon signs in Chinese and English",
"height": 1024,
"width": 1024,
"num_inference_steps": 9,
"guidance_scale": 0.0
}'
# ดึง task_id จากการตอบกลับ ตัวอย่างเช่น {"task_id": "abc123"}
# ขั้นตอนที่ 2: ตรวจสอบสถานะ
curl -X GET "https://api-inference.modelscope.cn/v1/tasks/abc123" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "X-ModelScope-Task-Type: image_generation"
เมื่อสำเร็จ การตอบกลับสถานะจะรวม "task_status": "SUCCEED" และอาร์เรย์ output_images พร้อม URL ที่สามารถดาวน์โหลดได้ คุณสามารถเรียกภาพผ่าน GET และบันทึกเป็น PNG หรือ JPEG
สำหรับทางเลือกแบบซิงโครนัส ModelScope มีการสาธิตออนไลน์ที่ modelscope.cn/aigc/imageGeneration เลือก Z-Image-Turbo เป็นโมเดลเริ่มต้น โหมด Quick จะสร้างภาพโดยไม่มีพารามิเตอร์ ในขณะที่โหมด Advanced จะเปิดเผยการควบคุมทั้งหมด อินเทอร์เฟซนี้ใช้สำหรับการสร้างต้นแบบ แต่คุณควรใช้ API สำหรับระบบอัตโนมัติ
การจัดการข้อผิดพลาดเป็นสิ่งสำคัญ รหัสทั่วไปได้แก่ 401 (โทเค็นไม่ถูกต้อง), 429 (เกินขีดจำกัดการเรียกใช้), และ 500 (ปัญหาเซิร์ฟเวอร์) ใช้การลองใหม่ด้วย Exponential Backoff ในโค้ดเวอร์ชันใช้งานจริง ขีดจำกัดการเรียกใช้จะอยู่ที่ประมาณ 10-20 คำขอต่อนาทีสำหรับบัญชีฟรี แม้ว่าโควตาที่แน่นอนจะแตกต่างกันไปตามบัญชี
คุณสามารถผสานรวม API นี้เข้ากับสภาพแวดล้อมที่หลากหลาย นักพัฒนา Python ใช้ requests สำหรับการเรียกใช้ HTTP ดังที่แสดงไว้ก่อนหน้านี้ ผู้ใช้ Node.js ใช้ประโยชน์จาก axios สำหรับการตรวจสอบแบบ promises-based แม้แต่ฟังก์ชันไร้เซิร์ฟเวอร์บน AWS Lambda หรือ Vercel ก็สามารถปรับใช้ได้อย่างง่ายดาย เมื่อพิจารณาถึงขนาดของเพย์โหลดที่เบา
Apidog ช่วยเพิ่มประสิทธิภาพขั้นตอนการเข้าถึงนี้ นำเข้าข้อมูลจำเพาะ API เข้าสู่ Apidog ซึ่งจะสร้างเอกสารและกรณีทดสอบโดยอัตโนมัติ คุณสามารถจำลองการตอบกลับ, เชื่อมโยงคำขอสำหรับการตรวจสอบสถานะ และส่งออกคอลเลกชันสำหรับการแชร์ในทีม แพลตฟอร์มนี้ช่วยลดเวลาในการดีบัก ทำให้คุณสามารถมุ่งเน้นไปที่การออกแบบพรอมต์
ด้วยขั้นตอนเหล่านี้ คุณจะสร้างการเชื่อมต่อที่เชื่อถือได้กับ Z-Image API ตอนนี้ คุณจะตรวจสอบราคาเพื่อยืนยันความคุ้มค่า
ราคาและโควตาสำหรับ Z-Image API
คุณยืนยันความสามารถในการจ่ายได้ต่อไป Z-Image API ไม่มีค่าใช้จ่ายสำหรับการอนุมาน ModelScope ให้บริการประมวลผลฟรีไม่จำกัดสำหรับการเรียกใช้ Z-Image-Turbo ตามที่ประกาศในโพสต์ X อย่างเป็นทางการ โมเดลที่ไม่มีค่าใช้จ่ายนี้รวมถึงการโฮสต์, แบนด์วิธ และทรัพยากร GPU— ซึ่งเป็นสิ่งที่หาได้ยากในบริการ AI
แนวทางปฏิบัติที่ดีที่สุดสำหรับการปรับปรุงประสิทธิภาพ Z-Image API
คุณปรับปรุงการใช้งานของคุณด้วยกลยุทธ์ที่ตรงเป้าหมาย ประการแรก เลือกพารามิเตอร์ที่เหมาะสม ยึดติดกับ 1024x1024 เพื่อความสมดุล; ขยายขนาดหลังการสร้างหากจำเป็น จำกัดขั้นตอนไว้ที่ 9—ค่าที่สูงขึ้นจะทำให้การอนุมานช้าลงโดยไม่เกิดประโยชน์
การเร่งฮาร์ดแวร์ช่วยเพิ่มประสิทธิภาพการทำงานแบบไฮบริดในเครื่อง เปิดใช้งาน Flash Attention ใน Diffusers: pipe.transformer.set_attention_backend("flash") สิ่งนี้ช่วยลดหน่วยความจำลง 20-30% บน Ampere GPU
Prompt Engineering ช่วยยกระดับคุณภาพ กำหนดโครงสร้างอินพุตเป็น "หัวข้อ + การกระทำ + สภาพแวดล้อม + สไตล์" ทดสอบรูปแบบต่างๆ ในโหมดจำลองของ Apidog เพื่อวนซ้ำได้อย่างรวดเร็ว
แนวทางปฏิบัติด้านความปลอดภัยช่วยปกป้องการผสานรวม ไม่ควรเปิดเผยโทเค็นในโค้ดฝั่งไคลเอ็นต์; ใช้พร็อกซีเซิร์ฟเวอร์ ตรวจสอบความถูกต้องของอินพุตเพื่อป้องกันการโจมตีแบบ Injection
เครื่องมือตรวจสอบช่วยติดตามเมตริก บันทึกเวลาการสร้าง, อัตราความสำเร็จ และการใช้โทเค็น เครื่องมืออย่าง Prometheus สามารถผสานรวมได้อย่างง่ายดายสำหรับแดชบอร์ด
บทสรุป
ตอนนี้คุณสามารถควบคุม Z-Image API ได้อย่างสมบูรณ์ ตั้งแต่การทำความเข้าใจสถาปัตยกรรมโอเพ่นซอร์สของ Z-Image-Turbo ไปจนถึงการเรียกใช้ API และการเพิ่มประสิทธิภาพเวิร์กโฟลว์ คู่มือนี้จะช่วยให้คุณประสบความสำเร็จ โมเดลราคาฟรีทำให้การสร้างภาพขั้นสูงเป็นประชาธิปไตยมากขึ้น ในขณะที่เครื่องมืออย่าง Apidog ช่วยให้การพัฒนาเป็นไปอย่างราบรื่น
นำเทคนิคเหล่านี้ไปใช้ในโครงการถัดไปของคุณ ทดลองกับข้อความแจ้ง (prompts) ขยายการผสานรวม และมีส่วนร่วมในระบบนิเวศ เมื่อ AI พัฒนาขึ้น Z-Image-Turbo จะทำให้คุณเป็นผู้นำในด้านเครื่องมือที่มีประสิทธิภาพและสร้างสรรค์