
```html
ลองนึกภาพว่ามีความสามารถในการดึงข้อมูลจากเว็บไซต์ใดก็ได้และรวบรวมข้อมูลเชิงลึกในระดับ—ทั้งหมดนี้ทำได้ด้วยโค้ดเพียงไม่กี่บรรทัด ฟังดูเหมือนเวทมนตร์ใช่ไหม? Firecrawl ทำให้สิ่งนี้เป็นไปได้
ในคู่มือสำหรับผู้เริ่มต้นนี้ ผมจะแนะนำคุณตลอดทุกสิ่งที่คุณจำเป็นต้องรู้เกี่ยวกับ Firecrawl ตั้งแต่การติดตั้งไปจนถึงเทคนิคการดึงข้อมูลขั้นสูง ไม่ว่าคุณจะเป็นนักพัฒนา นักวิเคราะห์ข้อมูล หรือเพียงแค่สนใจเกี่ยวกับการขูดเว็บ บทช่วยสอนนี้จะช่วยให้คุณเริ่มต้นใช้งาน Firecrawl และรวมเข้ากับเวิร์กโฟลว์ของคุณ

Firecrawl คืออะไร?
Firecrawl เป็นเครื่องมือขูดเว็บและรวบรวมข้อมูลที่เป็นนวัตกรรมใหม่ที่แปลงเนื้อหาเว็บไซต์เป็นรูปแบบต่างๆ เช่น markdown, HTML และข้อมูลที่มีโครงสร้าง ทำให้เหมาะสำหรับ Large Language Models (LLMs) และ แอปพลิเคชัน AI ด้วย Firecrawl คุณสามารถรวบรวมข้อมูลที่มีโครงสร้างและไม่มีโครงสร้างจากเว็บไซต์ได้อย่างมีประสิทธิภาพ ทำให้เวิร์กโฟลว์การวิเคราะห์ข้อมูลของคุณง่ายขึ้น
คุณสมบัติหลักของ Firecrawl
Crawl: การรวบรวมข้อมูลเว็บแบบครอบคลุม
จุดสิ้นสุด /crawl ของ Firecrawl ช่วยให้คุณสามารถสำรวจเว็บไซต์ซ้ำๆ โดยดึงเนื้อหาจากทุกหน้าย่อย คุณสมบัตินี้เหมาะสำหรับการค้นพบและจัดระเบียบข้อมูลเว็บจำนวนมาก โดยแปลงเป็นรูปแบบที่พร้อมสำหรับ LLM
Scrape: การดึงข้อมูลเป้าหมาย
ใช้คุณสมบัติ Scrape เพื่อดึงข้อมูลเฉพาะจาก URL เดียว Firecrawl สามารถส่งมอบเนื้อหาในรูปแบบต่างๆ รวมถึง markdown, ข้อมูลที่มีโครงสร้าง, ภาพหน้าจอ และ HTML สิ่งนี้มีประโยชน์อย่างยิ่งสำหรับการดึงข้อมูลเฉพาะจาก URL ที่รู้จัก
Map: การทำแผนผังไซต์อย่างรวดเร็ว
คุณสมบัติ Map จะดึง URL ทั้งหมดที่เกี่ยวข้องกับเว็บไซต์ที่กำหนดอย่างรวดเร็ว โดยให้ภาพรวมที่ครอบคลุมของโครงสร้าง สิ่งนี้มีค่าอย่างยิ่งสำหรับการค้นพบและจัดระเบียบเนื้อหา
Extract: การแปลงข้อมูลที่ไม่มีโครงสร้างเป็นรูปแบบที่มีโครงสร้าง
จุดสิ้นสุด /extract เป็นคุณสมบัติที่ขับเคลื่อนด้วย AI ของ Firecrawl ที่ช่วยลดความซับซ้อนของกระบวนการรวบรวมข้อมูลที่มีโครงสร้างจากเว็บไซต์ มันจัดการกับการยกของหนักในการรวบรวมข้อมูล การแยกวิเคราะห์ และการจัดระเบียบข้อมูลเป็นรูปแบบที่มีโครงสร้าง
เริ่มต้นใช้งาน Firecrawl
ขั้นตอนที่ 1: ลงทะเบียนและรับ API Key ของคุณ
เยี่ยมชม เว็บไซต์อย่างเป็นทางการของ Firecrawl และลงทะเบียนสำหรับบัญชี เมื่อเข้าสู่ระบบแล้ว ให้ไปที่แดชบอร์ดของคุณเพื่อค้นหา API key ของคุณ
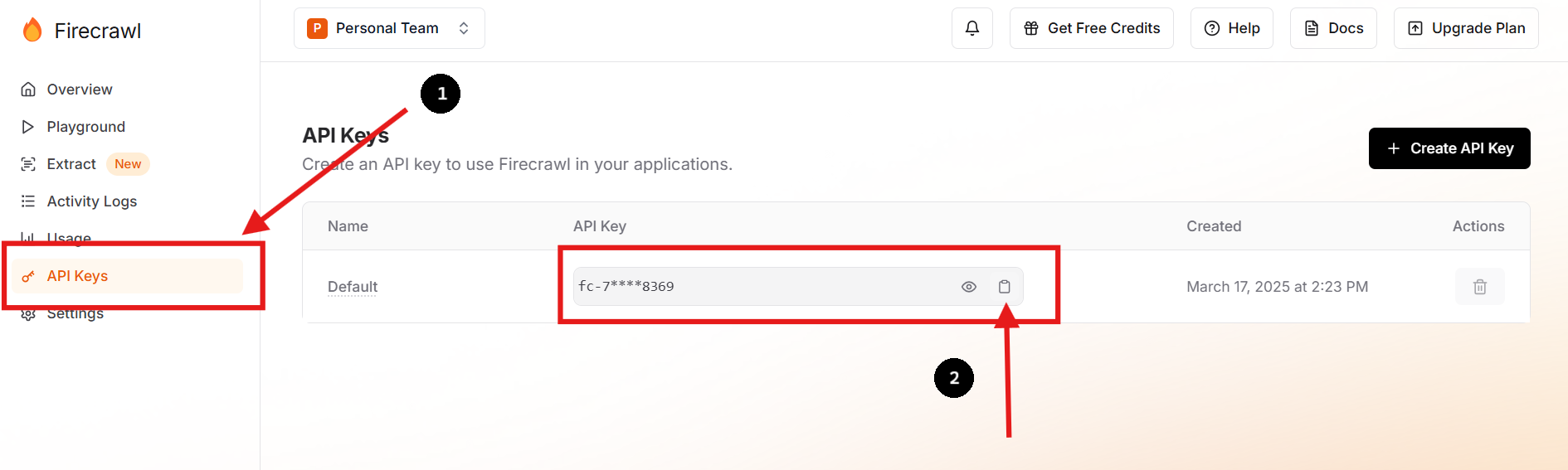
คุณยังสามารถสร้าง API key ใหม่และลบอันก่อนหน้าได้หากคุณต้องการหรือจำเป็นต้องทำเช่นนั้น

ขั้นตอนที่ 2: ตั้งค่าสภาพแวดล้อมของคุณ
ในไดเรกทอรีของโปรเจกต์ของคุณ ให้สร้างไฟล์ .env เพื่อจัดเก็บ API key ของคุณอย่างปลอดภัยเป็นตัวแปรสภาพแวดล้อม คุณสามารถทำได้โดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลของคุณ:
touch .env
echo "FIRECRAWL_API_KEY='fc-YOUR-KEY-HERE'" >> .envแนวทางนี้ช่วยให้ข้อมูลที่ละเอียดอ่อนออกจาก codebase หลักของคุณ ซึ่งช่วยเพิ่มความปลอดภัยและลดความซับซ้อนในการจัดการการกำหนดค่า
ขั้นตอนที่ 3: ติดตั้ง Firecrawl SDK
สำหรับผู้ใช้ Python ให้ติดตั้ง Firecrawl SDK โดยใช้ pip:
pip install firecrawl ขั้นตอนที่ 4: ใช้ฟังก์ชัน "Scrape" ของ Firecrawl
นี่คือตัวอย่างง่ายๆ ของวิธีการขูดเว็บไซต์โดยใช้ Python SDK:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Define the URL to scrape
url = "https://www.python-unlimited.com/webscraping/hotels.php?page=1"
# Scrape the website
response = app.scrape_url(url)
# Print the response
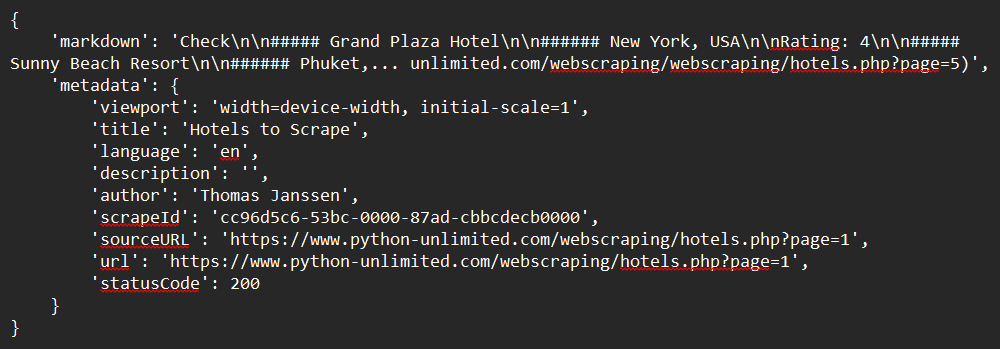
print(response)ตัวอย่างผลลัพธ์:
ขั้นตอนที่ 5: ใช้ฟังก์ชัน "Crawl" ของ Firecrawl
ที่นี่เราจะเห็นตัวอย่างง่ายๆ ของวิธีการรวบรวมข้อมูลเว็บไซต์โดยใช้ Python SDK:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Crawl a website and capture the response:
crawl_status = app.crawl_url(
'https://www.python-unlimited.com/webscraping/hotels.php?page=1',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
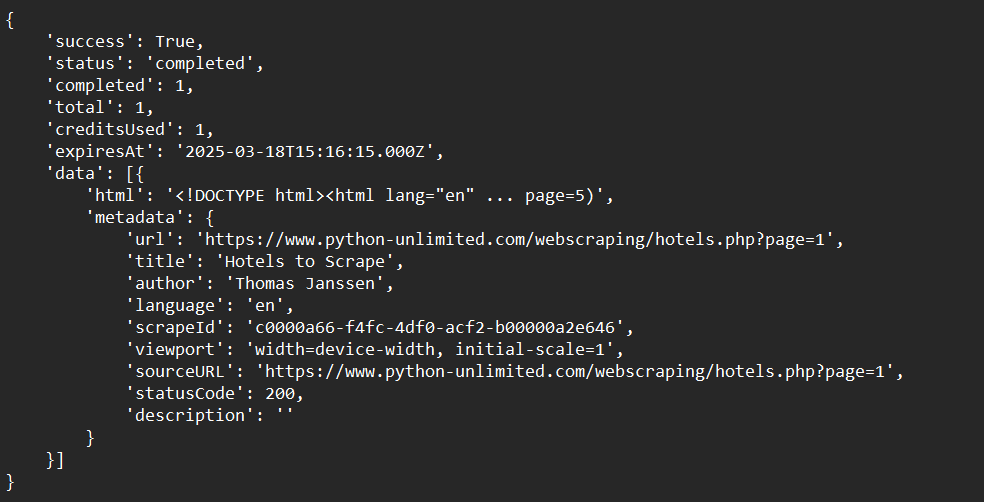
print(crawl_status)ตัวอย่างผลลัพธ์:
ขั้นตอนที่ 6: ใช้ฟังก์ชัน "Map" ของ Firecrawl
นี่คือตัวอย่างง่ายๆ ของวิธีการทำแผนผังข้อมูลเว็บไซต์โดยใช้ Python SDK:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Map a website:
map_result = app.map_url('https://www.python-unlimited.com/webscraping/hotels.php?page=1')
print(map_result)ตัวอย่างผลลัพธ์:

ขั้นตอนที่ 7: ใช้ฟังก์ชัน "Extract" ของ Firecrawl (Open Beta)
ด้านล่างนี้คือตัวอย่างง่ายๆ ของวิธีการดึงข้อมูลเว็บไซต์โดยใช้ Python SDK:
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Define schema to extract contents into
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
# Call the extract function and capture the response
response = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "Extract the data provided in the schema.",
'schema': ExtractSchema.model_json_schema()
})
# Print the response
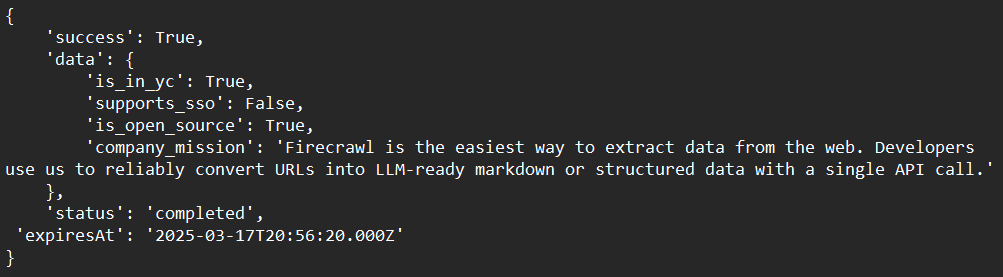
print(response)ตัวอย่างผลลัพธ์:
เทคนิคขั้นสูงด้วย Firecrawl
การจัดการเนื้อหาแบบไดนามิก
Firecrawl สามารถจัดการเนื้อหาแบบไดนามิกที่ใช้ JavaScript ได้โดยใช้เบราว์เซอร์แบบ headless เพื่อแสดงผลหน้าเว็บก่อนที่จะขูดข้อมูล สิ่งนี้ทำให้มั่นใจได้ว่าคุณจะได้รับเนื้อหาทั้งหมด แม้ว่าจะถูกโหลดแบบไดนามิกก็ตาม
การข้ามตัวบล็อกการขูดเว็บ
ใช้คุณสมบัติในตัวของ Firecrawl เพื่อข้ามตัวบล็อกการขูดเว็บทั่วไป เช่น CAPTCHA หรือขีดจำกัดอัตรา ซึ่งเกี่ยวข้องกับการหมุนตัวแทนผู้ใช้และที่อยู่ IP เพื่อเลียนแบบการเข้าชมตามธรรมชาติ
การผสานรวมกับ LLMs
รวม Firecrawl กับ LLMs เช่น LangChain เพื่อสร้างเวิร์กโฟลว์ AI ที่ทรงพลัง ตัวอย่างเช่น คุณสามารถใช้ Firecrawl เพื่อรวบรวมข้อมูล จากนั้นป้อนข้อมูลลงใน LLM สำหรับการวิเคราะห์หรือการสร้างงาน
การแก้ไขปัญหาทั่วไป
ปัญหา: "API Key ไม่เป็นที่รู้จัก"
วิธีแก้ไข: ตรวจสอบให้แน่ใจว่า API key ของคุณถูกจัดเก็บไว้อย่างถูกต้องเป็นตัวแปรสภาพแวดล้อมหรือในไฟล์ .env
ปัญหา: "การรวบรวมข้อมูลช้าเกินไป"
วิธีแก้ไข: ใช้การรวบรวมข้อมูลแบบอะซิงโครนัสเพื่อเพิ่มความเร็วให้กับกระบวนการ Firecrawl รองรับคำขอพร้อมกันเพื่อปรับปรุงประสิทธิภาพ
ปัญหา: "ไม่สามารถดึงเนื้อหาได้อย่างถูกต้อง"
วิธีแก้ไข: ตรวจสอบว่าเว็บไซต์ใช้เนื้อหาแบบไดนามิกหรือไม่ ถ้าเป็นเช่นนั้น ให้ตรวจสอบให้แน่ใจว่า Firecrawl ได้รับการกำหนดค่าให้จัดการการแสดงผล JavaScript
บทสรุป
ขอแสดงความยินดีกับการทำคู่มือสำหรับผู้เริ่มต้นที่ครอบคลุมนี้เกี่ยวกับ Firecrawl! เราได้ครอบคลุมทุกสิ่งที่คุณจำเป็นต้องเริ่มต้น—ตั้งแต่ Firecrawl คืออะไร ไปจนถึงคำแนะนำในการติดตั้งโดยละเอียด ตัวอย่างการใช้งาน และตัวเลือกการปรับแต่งขั้นสูง ตอนนี้คุณควรมีความเข้าใจที่ชัดเจนเกี่ยวกับวิธีการ:
- ตั้งค่าและติดตั้ง Firecrawl ในสภาพแวดล้อมการพัฒนาของคุณ
- กำหนดค่าและเรียกใช้ Firecrawl เพื่อขูด รวบรวมข้อมูล ทำแผนผัง และดึงข้อมูลอย่างมีประสิทธิภาพ
- แก้ไขปัญหา กระบวนการรวบรวมข้อมูลของคุณเพื่อให้ตรงกับความต้องการเฉพาะของคุณ
Firecrawl เป็นเครื่องมือที่ทรงพลังอย่างเหลือเชื่อ ซึ่งสามารถปรับปรุงเวิร์กโฟลว์การดึงข้อมูลของคุณได้อย่างมาก ความยืดหยุ่น ประสิทธิภาพ และความง่ายในการผสานรวมทำให้เป็นตัวเลือกที่เหมาะสำหรับความท้าทายในการรวบรวมข้อมูลเว็บสมัยใหม่
ตอนนี้ถึงเวลาที่จะนำทักษะใหม่ของคุณไปปฏิบัติจริง เริ่มทดลองกับเว็บไซต์ต่างๆ ปรับแต่งตัวแยกวิเคราะห์ของคุณ และผสานรวมกับเครื่องมือเพิ่มเติมเพื่อสร้างโซลูชันที่ปรับแต่งได้ตามความต้องการของคุณอย่างแท้จริง
พร้อมที่จะเพิ่มประสิทธิภาพเวิร์กโฟลว์การขูดเว็บของคุณ 10 เท่าแล้วหรือยัง? ดาวน์โหลด Apidog ได้ฟรี วันนี้และค้นพบว่ามันสามารถปรับปรุงการผสานรวม Firecrawl ของคุณได้อย่างไร!
```


