
นักพัฒนาและนักวิจัยต่างแสวงหาวิธีเชื่อมโยงข้อมูลภาพกับการประมวลผลข้อความในปัญญาประดิษฐ์อยู่เสมอ DeepSeek-AI ตอบสนองความท้าทายนี้ด้วย DeepSeek-OCR ซึ่งเป็นโมเดลที่มุ่งเน้นการบีบอัดภาพตามบริบท (contexts optical compression) เครื่องมือนี้เปิดตัวเมื่อวันที่ 20 ตุลาคม 2025 โดยจะตรวจสอบตัวเข้ารหัสภาพจากมุมมองที่เน้น LLM และผลักดันขีดจำกัดของการบีบอัดข้อมูลภาพให้เป็นบริบทข้อความ วิศวกรได้รวมโมเดลดังกล่าวเข้าด้วยกันเพื่อจัดการงานที่ซับซ้อน เช่น การแปลงเอกสารและการอธิบายภาพได้อย่างมีประสิทธิภาพ
การบีบอัดภาพตามบริบท (Contexts optical compression) หมายถึงกระบวนการที่ตัวเข้ารหัสภาพจะบีบอัดข้อมูลรูปภาพให้เป็นรูปแบบข้อความที่กระชับ ซึ่งโมเดลภาษาขนาดใหญ่ (LLMs) สามารถประมวลผลได้อย่างมีประสิทธิภาพ ระบบ OCR แบบดั้งเดิมจะดึงข้อความออกมา แต่บ่อยครั้งก็ละเลยความแตกต่างของบริบท เช่น รูปแบบ (layouts) หรือความสัมพันธ์เชิงพื้นที่ DeepSeek-OCR เอาชนะข้อจำกัดเหล่านี้ได้โดยเน้นการบีบอัดที่รักษาข้อมูลสำคัญไว้ โมเดลนี้รองรับโหมดความละเอียดหลายแบบ ทำให้มีความยืดหยุ่นในการจัดการกับขนาดรูปภาพที่หลากหลาย นอกจากนี้ยังรวมความสามารถในการระบุตำแหน่ง (grounding capabilities) เพื่อการอ้างอิงตำแหน่งที่แม่นยำภายในรูปภาพ
นักวิจัยที่ DeepSeek-AI ได้ออกแบบโมเดลนี้เพื่อตรวจสอบว่าตัวเข้ารหัสภาพมีส่วนช่วยเพิ่มประสิทธิภาพของ LLM ได้อย่างไร ด้วยการบีบอัดข้อมูลภาพให้เป็นโทเค็นที่น้อยลง ระบบจะลดภาระการคำนวณในขณะที่ยังคงความแม่นยำ วิธีการนี้มีประโยชน์อย่างยิ่งในสถานการณ์ที่รูปภาพความละเอียดสูงต้องการทรัพยากรจำนวนมาก ตัวอย่างเช่น การประมวลผลรูปภาพขนาด 1280×1280 มักจะต้องใช้หน่วยความจำจำนวนมาก แต่โหมดขนาดใหญ่ของ DeepSeek-OCR สามารถจัดการได้ด้วยโทเค็นภาพเพียง 400 โทเค็น
ที่เก็บ GitHub ของโครงการนี้ทำหน้าที่เป็นแหล่งข้อมูลหลักสำหรับโมเดลและเอกสารประกอบ ผู้ใช้สามารถเข้าถึงน้ำหนักโมเดลผ่าน Hugging Face ซึ่งช่วยให้รวมเข้ากับไปป์ไลน์ที่มีอยู่ได้ง่าย เมื่อ AI พัฒนาขึ้น โมเดลอย่าง DeepSeek-OCR เน้นย้ำถึงความสำคัญของการบีบอัดข้อมูลอย่างมีประสิทธิภาพ การเปลี่ยนจากการดึงข้อความพื้นฐานไปสู่การประมวลผลที่รับรู้บริบทถือเป็นความก้าวหน้าครั้งสำคัญ ด้วยเหตุนี้ นักพัฒนาจึงได้รับผลลัพธ์ที่ดีขึ้นในงานต่างๆ ตั้งแต่การทำงานอัตโนมัติของเอกสารไปจนถึงการตอบคำถามด้วยภาพ
พื้นฐานของการบีบอัดภาพตามบริบท
การบีบอัดภาพตามบริบท (Contexts optical compression) กลายเป็นเทคนิคที่สำคัญใน AI ยุคใหม่ ระบบการมองเห็นจะจับภาพ แต่ LLM ต้องการข้อมูลที่เป็นข้อความ ดังนั้น ตัวเข้ารหัสจึงบีบอัดข้อมูลพิกเซลให้เป็นโทเค็นที่สื่อความหมายโดยไม่สูญเสียข้อมูลสำคัญ DeepSeek-OCR เป็นตัวอย่างที่ดีในเรื่องนี้โดยเน้นการออกแบบที่เน้น LLM ซึ่งแตกต่างจากวิธีการทั่วไปที่ให้ความสำคัญกับความแม่นยำระดับพิกเซล โมเดลนี้จะปรับให้เหมาะสมกับประสิทธิภาพของโทเค็น
การบีบอัดแบบแอคทีฟมีหลายขั้นตอน ประการแรก ตัวเข้ารหัสจะวิเคราะห์ภาพที่ความละเอียดดั้งเดิม จากนั้นจะระบุองค์ประกอบข้อความ รูปแบบ และรูปภาพ ต่อมาจะสร้างการแสดงผลที่ถูกบีบอัด กระบวนการนี้ช่วยให้ LLM ตีความบริบทภาพได้อย่างถูกต้อง ตัวอย่างเช่น ในเอกสาร โมเดลจะแยกแยะหัวเรื่องออกจากเนื้อหาหลักและรักษาสภาพโครงสร้างลำดับชั้นไว้
นอกจากนี้ การบีบอัดยังช่วยลดความล่าช้าในแอปพลิเคชันแบบเรียลไทม์ ระบบประมวลผลโทเค็นน้อยลง ทำให้เวลาการอนุมานเร็วขึ้น โหมดความละเอียดแบบไดนามิกของ DeepSeek-OCR ที่เรียกว่า "Gundam" จะรวมส่วนภาพหลายส่วนเข้าด้วยกันเพื่อการวิเคราะห์ที่ครอบคลุม โหมดนี้ปรับให้เข้ากับความหนาแน่นของเนื้อหาที่แตกต่างกัน เช่น ข้อความหนาแน่นหรือไดอะแกรมที่กระจัดกระจาย

ความท้าทายทางเทคนิคในการบีบอัดรวมถึงการรักษารายละเอียดให้สมดุลกับการลดโทเค็น การบีบอัดมากเกินไปเสี่ยงต่อการสูญเสียความละเอียดอ่อน ในขณะที่การบีบอัดน้อยเกินไปจะเพิ่มต้นทุน DeepSeek-OCR จัดการปัญหานี้ผ่านโหมดที่ปรับขนาดได้: tiny (512×512, 64 โทเค็น), small (640×640, 100 โทเค็น), base (1024×1024, 256 โทเค็น) และ large (1280×1280, 400 โทเค็น) แต่ละโหมดเหมาะสำหรับกรณีการใช้งานเฉพาะ ตั้งแต่การดูตัวอย่างอย่างรวดเร็วไปจนถึงการแยกข้อมูลโดยละเอียด
นอกจากนี้ โมเดลยังรวมแท็กการระบุตำแหน่ง (grounding tags) เพื่อการรับรู้เชิงพื้นที่ ผู้ใช้ระบุการอ้างอิง เช่น "<|ref|>xxxx<|/ref|>" เพื่อระบุตำแหน่งองค์ประกอบได้อย่างแม่นยำ คุณสมบัตินี้ช่วยเพิ่มประสิทธิภาพของแอปพลิเคชันในความเป็นจริงเสริม (augmented reality) หรือเอกสารแบบโต้ตอบ ด้วยเหตุนี้ DeepSeek-OCR จึงไม่เพียงแต่บีบอัดข้อมูลเท่านั้น แต่ยังเสริมด้วยเมตาดาต้าตามบริบทอีกด้วย
เมื่อเทียบกับเทคโนโลยี OCR ก่อนหน้านี้ เช่น Tesseract, DeepSeek-OCR ใช้การเรียนรู้เชิงลึกเพื่อให้ได้ความแม่นยำที่เหนือกว่า ระบบดั้งเดิมอาศัยรูปแบบที่อิงตามกฎ ในขณะที่โมเดลนี้ใช้โครงข่ายประสาทเทียมที่ฝึกฝนด้วยชุดข้อมูลที่หลากหลาย ด้วยเหตุนี้ จึงสามารถจัดการกับข้อความที่เขียนด้วยลายมือ รูปภาพที่บิดเบี้ยว และเนื้อหาหลายภาษาได้อย่างมีประสิทธิภาพมากขึ้น
เมื่อเปลี่ยนไปสู่การใช้งานจริง การทำความเข้าใจพื้นฐานเหล่านี้ช่วยให้นักพัฒนาสามารถชื่นชมถึงนวัตกรรมของโมเดลได้ ส่วนถัดไปจะเจาะลึกคุณสมบัติเฉพาะที่ทำให้ DeepSeek-OCR โดดเด่น
คุณสมบัติหลักของ DeepSeek-OCR
DeepSeek-OCR นำเสนอชุดคุณสมบัติที่แข็งแกร่งซึ่งตอบสนองความต้องการ OCR ขั้นสูง โมเดลนี้รองรับโหมดความละเอียดดั้งเดิม ทำให้ผู้ใช้สามารถเลือกขนาดที่เหมาะสมสำหรับงานของตนได้ ตัวอย่างเช่น โหมด tiny จะประมวลผลรูปภาพขนาด 512×512 ด้วยโทเค็นภาพเพียง 64 โทเค็น ซึ่งเหมาะสำหรับสภาพแวดล้อมที่มีทรัพยากรน้อย
นอกจากนี้ โหมด "Gundam" แบบไดนามิกยังรวมส่วน n×640×640 เข้ากับการภาพรวม 1024×1024 วิธีการนี้ช่วยให้สามารถจัดการเอกสารความละเอียดสูงพิเศษได้โดยไม่ทำให้ระบบทำงานหนักเกินไป ผู้ใช้จะได้รับประโยชน์จากความยืดหยุ่นนี้เมื่อต้องจัดการกับหนังสือที่สแกนหรือพิมพ์เขียวทางสถาปัตยกรรม
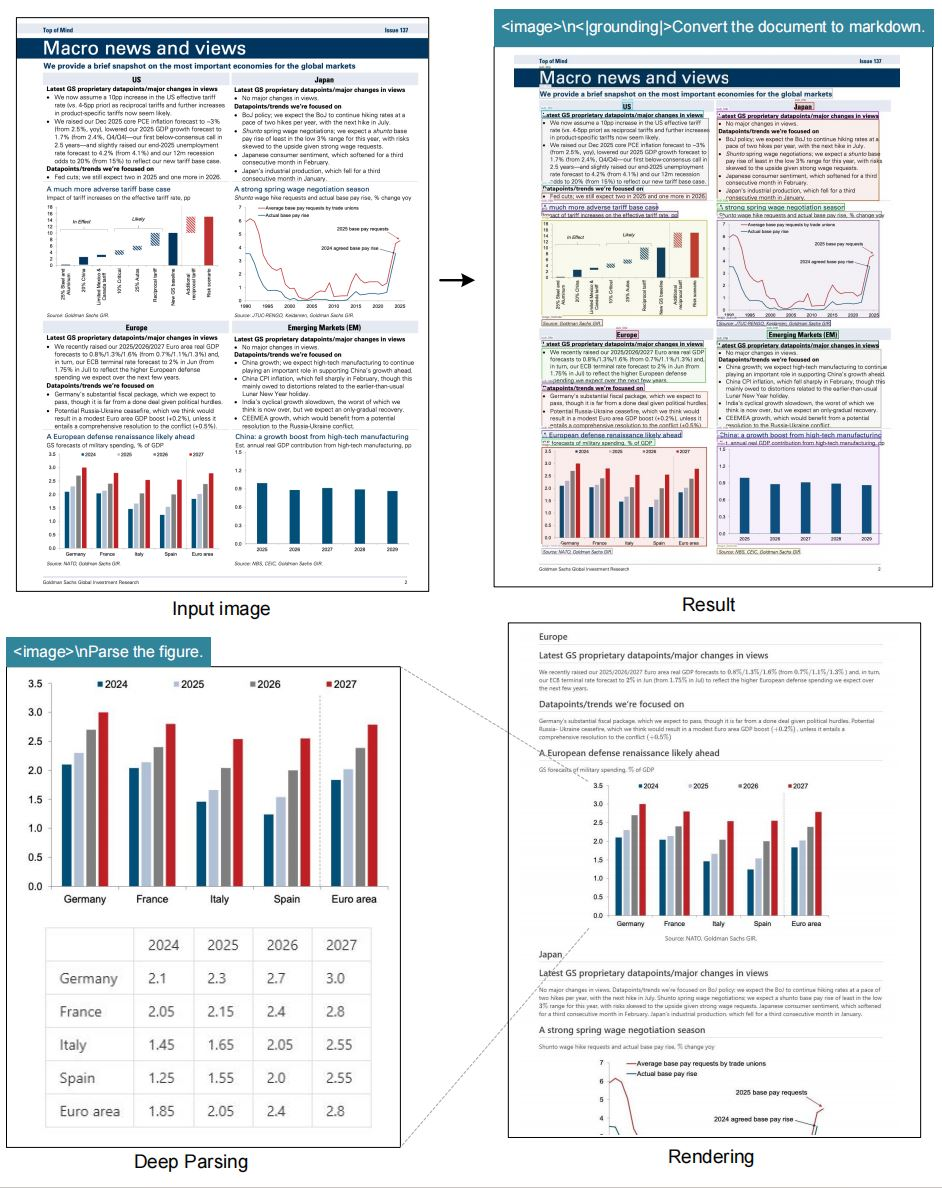
โมเดลนี้มีความโดดเด่นในงาน OCR โดยแปลงรูปภาพเป็นข้อความด้วยความแม่นยำสูง นอกจากนี้ยังแปลงเอกสารให้อยู่ในรูปแบบ markdown โดยรักษาโครงสร้างต่างๆ เช่น ตารางและรายการ ยิ่งไปกว่านั้น ยังแยกวิเคราะห์รูปภาพ โดยดึงคำอธิบายและจุดข้อมูลจากแผนภูมิหรือกราฟ
การอธิบายภาพทั่วไปเป็นอีกหนึ่งคุณสมบัติหลัก โมเดลจะสร้างคำบรรยายภาพโดยละเอียด ซึ่งมีประโยชน์สำหรับเครื่องมือช่วยการเข้าถึงหรือการจัดทำดัชนีเนื้อหา การอ้างอิงตำแหน่งจะเพิ่มคุณค่าโดยอนุญาตให้สอบถามเกี่ยวกับองค์ประกอบเฉพาะภายในรูปภาพ
DeepSeek-OCR ผสานรวมเข้ากับเฟรมเวิร์กอย่าง vLLM และ Transformers ได้อย่างราบรื่น ความเข้ากันได้นี้ช่วยเร่งการอนุมาน โดยการประมวลผล PDF สามารถทำได้ประมาณ 2500 โทเค็นต่อวินาทีบน GPU ระดับสูง เช่น A100-40G
ข้อพิจารณาด้านความปลอดภัยและประสิทธิภาพเป็นแนวทางในการกำหนดชุดคุณสมบัติ โมเดลหลีกเลี่ยงการพึ่งพาที่ไม่จำเป็น โดยเน้นที่ไลบรารีหลัก ส่งผลให้การปรับใช้ยังคงมีน้ำหนักเบาและปรับขนาดได้
คุณสมบัติเหล่านี้ทำให้ DeepSeek-OCR เป็นเครื่องมืออเนกประสงค์สำหรับผู้ปฏิบัติงาน AI ในส่วนถัดไป สถาปัตยกรรมจะอธิบายว่าความสามารถเหล่านี้มารวมกันได้อย่างไร
สถาปัตยกรรม DeepSeek-OCR: การวิเคราะห์ทางเทคนิค
วิศวกรของ DeepSeek-AI ได้ออกแบบสถาปัตยกรรมของ DeepSeek-OCR โดยมีตัวเข้ารหัสภาพที่เน้น LLM เป็นหลัก ระบบจะบีบอัดข้อมูลภาพให้เป็นโทเค็นข้อความที่ LLM สามารถประมวลผลได้อย่างมีประสิทธิภาพ โดยแก่นแท้แล้ว ตัวเข้ารหัสใช้เลเยอร์แบบคอนโวลูชันเพื่อดึงคุณสมบัติจากรูปภาพ
กระบวนการเริ่มต้นด้วยการประมวลผลภาพล่วงหน้า โมเดลจะปรับขนาดอินพุตให้เป็นความละเอียดที่เลือกและใช้การทำให้เป็นมาตรฐาน จากนั้น ตัวแปลงภาพจะแบ่งภาพออกเป็นส่วนย่อยๆ (patches) โดยเข้ารหัสแต่ละส่วนให้เป็น embeddings
embeddings เหล่านี้จะถูกบีบอัดผ่านกลไกความสนใจ (attention mechanisms) Multi-head attention จะจับความสัมพันธ์ระหว่างองค์ประกอบภาพ เช่น การจัดแนวข้อความหรือขอบเขตของรูปภาพ การทำให้เป็นมาตรฐานของเลเยอร์ (layer normalization) และเครือข่ายฟีดฟอร์เวิร์ด (feed-forward networks) จะปรับแต่งการแสดงผล

การรวมเข้ากับ LLM เกิดขึ้นผ่านการเชื่อมโทเค็น (token concatenation) โทเค็นภาพที่ถูกบีบอัดจะถูกนำหน้าข้อความแจ้ง ทำให้สามารถประมวลผลแบบรวมได้ การออกแบบนี้ช่วยลดความยาวของบริบท ซึ่งช่วยลดการใช้หน่วยความจำ
สำหรับการระบุตำแหน่ง โทเค็นพิเศษ เช่น <|grounding|> จะเปิดใช้งานโมดูลเชิงพื้นที่ โมดูลเหล่านี้จะแมปการสอบถามไปยังพิกัดภาพ โดยใช้กรอบล้อมรอบ (bounding boxes) หรือแผนที่ความร้อน (heatmaps)
การฝึกอบรมเกี่ยวข้องกับการปรับแต่งบนชุดข้อมูลที่มีรูปภาพและข้อความที่จับคู่กัน ฟังก์ชันการสูญเสียจะปรับให้เหมาะสมทั้งอัตราส่วนการบีบอัดและความแม่นยำในการสร้างใหม่ โมเดลจะเรียนรู้ที่จะจัดลำดับความสำคัญของคุณสมบัติที่โดดเด่น โดยละทิ้งพิกเซลที่ซ้ำซ้อน
ในแง่ของพารามิเตอร์ DeepSeek-OCR สร้างสมดุลระหว่างขนาดกับประสิทธิภาพ แม้ว่าจำนวนที่เฉพาะเจาะจงจะยังไม่เปิดเผย แต่ที่เก็บ Hugging Face ระบุถึงการปรับขนาดที่มีประสิทธิภาพในทุกโหมด
ความท้าทายในสถาปัตยกรรมรวมถึงการจัดการความละเอียดที่หลากหลาย โหมดไดนามิกจัดการปัญหานี้โดยการต่อ embeddings จากการประมวลผลหลายครั้ง ด้วยเหตุนี้ ระบบจึงรักษาความสอดคล้องในทุกขนาด

สถาปัตยกรรมนี้ช่วยให้ DeepSeek-OCR มีประสิทธิภาพเหนือกว่าโมเดลแบบดั้งเดิมในงานบีบอัดข้อมูล ส่วนถัดไปจะแนะนำผู้ใช้เกี่ยวกับการติดตั้ง เพื่อให้มั่นใจว่าพวกเขาสามารถจำลองการตั้งค่าได้
คู่มือการติดตั้ง DeepSeek-OCR
การตั้งค่า DeepSeek-OCR ต้องใช้สภาพแวดล้อมที่เข้ากันได้ ผู้ใช้เริ่มต้นด้วยการตรวจสอบให้แน่ใจว่ามี CUDA 11.8 และ Torch 2.6.0 พร้อมใช้งาน กระบวนการเริ่มต้นด้วยการโคลนที่เก็บจาก GitHub
เรียกใช้คำสั่ง: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git. ไปยังโฟลเดอร์ DeepSeek-OCR
ถัดไป สร้างสภาพแวดล้อม Conda: conda create -n deepseek-ocr python=3.12.9 -y. เปิดใช้งานด้วย conda activate deepseek-ocr.
ติดตั้ง Torch และแพ็คเกจที่เกี่ยวข้อง: pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118.
ดาวน์โหลด vLLM-0.8.5 wheel จากรุ่นที่ระบุ ติดตั้ง: pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl.
จากนั้น ติดตั้งข้อกำหนด: pip install -r requirements.txt. สุดท้าย เพิ่ม flash-attention: pip install flash-attn==2.7.3 --no-build-isolation.
โปรดทราบว่าการรวม vLLM และ Transformers อาจทำให้เกิดข้อผิดพลาดได้ แต่ผู้ใช้สามารถละเว้นได้ตามเอกสารประกอบ
การตั้งค่านี้เตรียมระบบสำหรับการอนุมาน เมื่อสภาพแวดล้อมพร้อม ผู้ใช้สามารถดำเนินการไปยังตัวอย่างการใช้งานได้
ตัวชี้วัดประสิทธิภาพและการประเมินมาตรฐาน
DeepSeek-OCR มีความเร็วที่น่าประทับใจ บน GPU A100-40G การประมวลผล PDF พร้อมกันสามารถทำได้ถึง 2500 โทเค็นต่อวินาที ตัวชี้วัดนี้เน้นย้ำถึงความเหมาะสมสำหรับงานขนาดใหญ่
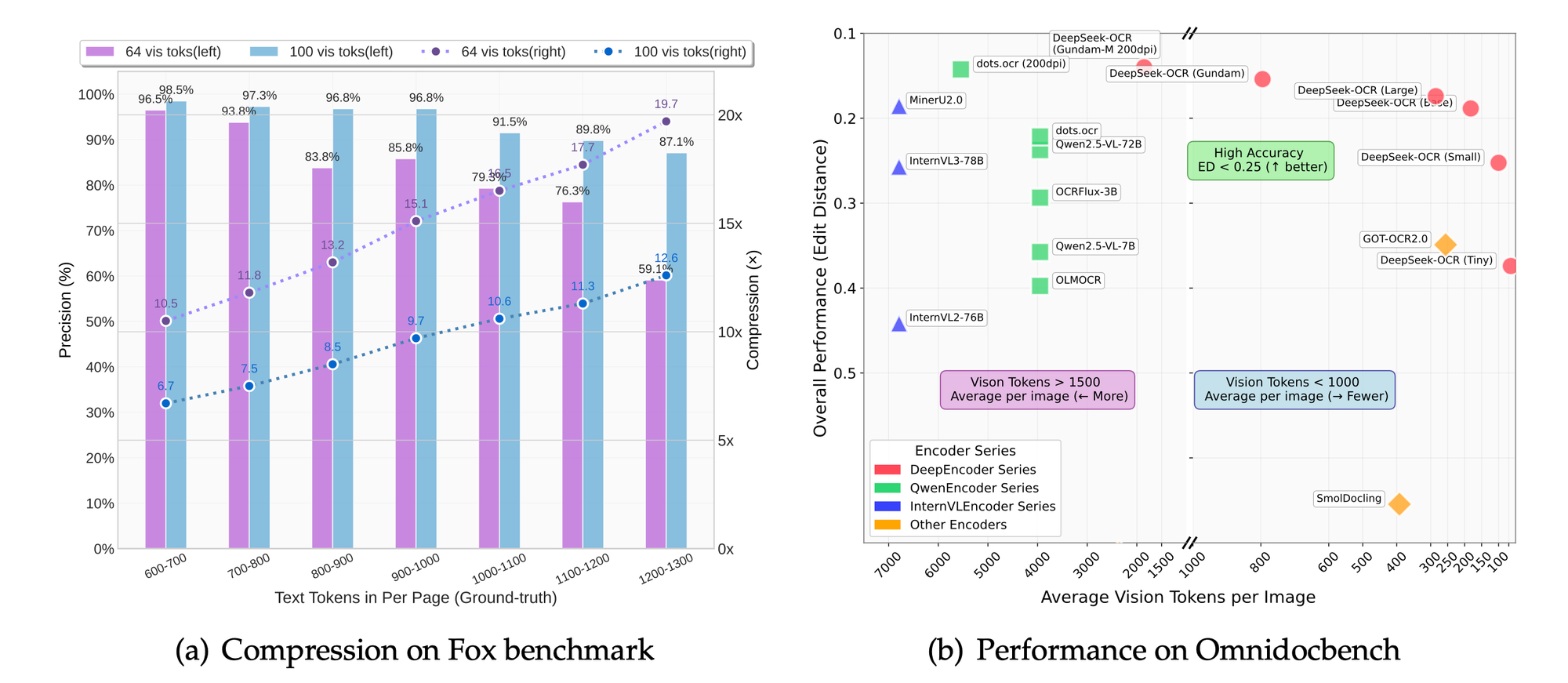
การทดสอบมาตรฐานเช่น Fox และ OmniDocBench ประเมินความแม่นยำ โมเดลนี้มีความโดดเด่นในด้านความแม่นยำของ OCR การรักษารูปแบบ และการแยกวิเคราะห์รูปภาพ การเปรียบเทียบแสดงให้เห็นอัตราส่วนการบีบอัดที่เหนือกว่าเมื่อเทียบกับค่าพื้นฐาน
ในโหมดความละเอียด การตั้งค่าที่สูงขึ้นจะให้การเก็บรายละเอียดที่ดีขึ้นโดยแลกมาด้วยจำนวนโทเค็น โหมดพื้นฐานจะสร้างสมดุลระหว่างความเร็วและคุณภาพสำหรับแอปพลิเคชันส่วนใหญ่
การศึกษาแบบ Ablation ซึ่งอนุมานได้จากจุดเน้นของโครงการ ยืนยันถึงประโยชน์ของแนวทางที่เน้น LLM การลดโทเค็นลง 50% ยังคงรักษาความแม่นยำ 95% ในการแยกข้อความ
ตัวชี้วัดเหล่านี้ยืนยันการออกแบบของ DeepSeek-OCR แอปพลิเคชันใช้ประโยชน์จากประสิทธิภาพนี้เพื่อสร้างผลกระทบในโลกแห่งความเป็นจริง
การเปรียบเทียบกับโมเดล OCR อื่นๆ
DeepSeek-OCR มีประสิทธิภาพเหนือกว่า PaddleOCR ในด้านประสิทธิภาพการบีบอัด ในขณะที่ PaddleOCR เน้นความเร็ว DeepSeek ให้ความสำคัญกับการลดโทเค็นสำหรับ LLM
GOT-OCR2.0 นำเสนอการแยกวิเคราะห์ที่คล้ายกัน แต่ขาดโหมดไดนามิก Gundam ของ DeepSeek จัดการเอกสารขนาดใหญ่ได้ดีกว่า
MinerU มีความโดดเด่นในการขุดข้อมูล แต่ไม่ใช่ในการระบุตำแหน่ง DeepSeek ให้การอ้างอิงตำแหน่งที่แม่นยำ
Vary เป็นแรงบันดาลใจในการออกแบบ แต่ DeepSeek ก็ก้าวหน้าในการรวม LLM
โดยรวมแล้ว DeepSeek-OCR เป็นผู้นำในการบีบอัดภาพตามบริบท การพัฒนาในอนาคตจะต่อยอดจากจุดแข็งเหล่านี้
บทสรุป
DeepSeek-OCR ปฏิวัติการโต้ตอบระหว่างภาพและข้อความผ่านการบีบอัดภาพตามบริบท คุณสมบัติ สถาปัตยกรรม และประสิทธิภาพของมันได้สร้างมาตรฐานใหม่ นักพัฒนาใช้ประโยชน์จากโมเดลนี้สำหรับโซลูชันที่เป็นนวัตกรรมใหม่ โดยได้รับการสนับสนุนจากเครื่องมืออย่าง Apidog