
ในโลกของแอปพลิเคชันที่ขับเคลื่อนด้วย AI, Claude API ของ Anthropic ได้กลายเป็นโซลูชันที่ได้รับความนิยมสำหรับนักพัฒนาหลายคนที่ต้องการความสามารถในการประมวลผลภาษาขั้นสูง อย่างไรก็ตาม เช่นเดียวกับบริการยอดนิยมอื่นๆ คุณมีแนวโน้มที่จะพบกับข้อจำกัดด้านอัตราที่อาจหยุดการทำงานของแอปพลิเคชันของคุณชั่วคราว การทำความเข้าใจขีดจำกัดเหล่านี้และการใช้กลยุทธ์ในการทำงานภายในขีดจำกัดเหล่านั้นเป็นสิ่งสำคัญสำหรับการรักษาประสบการณ์การใช้งานที่ราบรื่น
สำหรับ AI Coding, Claude ได้กลายเป็นผู้ช่วยที่มีประสิทธิภาพสำหรับทั้งผู้ใช้ทั่วไปและนักพัฒนา อย่างไรก็ตาม ผู้ใช้หลายคนพบกับความหงุดหงิดทั่วไป: ข้อจำกัดด้านอัตรา
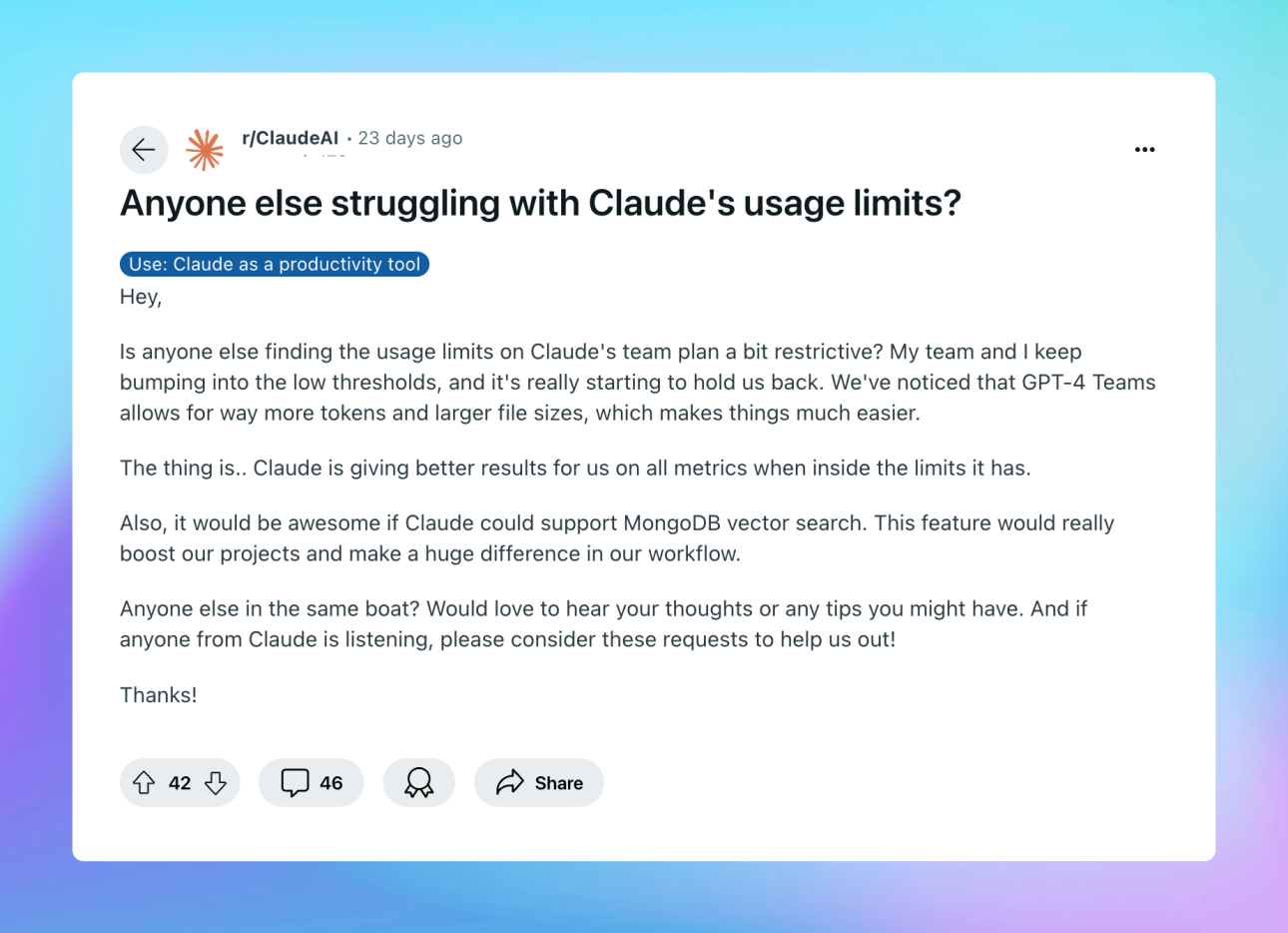
ไม่ว่าคุณจะใช้ส่วนต่อประสานเว็บของ Claude หรือผสานรวมกับ API ผ่านเครื่องมือต่างๆ เช่น Cursor หรือ Cline การเข้าถึงขีดจำกัดเหล่านี้อาจขัดขวางเวิร์กโฟลว์และประสิทธิภาพการทำงานของคุณ ในขณะที่เครื่องมือต่างๆ เช่น Claude มอบความสามารถด้าน AI ที่ทรงพลัง การจัดการการโต้ตอบ API อย่างมีประสิทธิภาพต้องใช้เครื่องมือทดสอบและแก้ไขข้อบกพร่องที่เหมาะสม Apidog ช่วยให้นักพัฒนาสามารถจัดการกับความซับซ้อนเหล่านี้เมื่อทำงานกับ AI และ API อื่นๆ
คู่มือที่ครอบคลุมนี้จะสำรวจว่าทำไมข้อจำกัดด้านอัตราของ Claude API จึงมีอยู่ วิธีระบุเมื่อคุณเข้าถึงขีดจำกัดเหล่านั้น และให้โซลูชันโดยละเอียดสามประการเพื่อช่วยให้คุณเอาชนะความท้าทายเหล่านี้ได้อย่างมีประสิทธิภาพ
ข้อจำกัดด้านอัตราของ Claude API คืออะไร และเหตุใดจึงมีอยู่
ข้อจำกัดด้านอัตราคือข้อจำกัดที่ผู้ให้บริการ API กำหนดเพื่อควบคุมปริมาณคำขอที่ผู้ใช้สามารถทำได้ภายในกรอบเวลาที่กำหนด Anthropic ใช้ขีดจำกัดเหล่านี้ด้วยเหตุผลสำคัญหลายประการ:
- การจัดการทรัพยากรเซิร์ฟเวอร์: ป้องกันไม่ให้ผู้ใช้รายใดรายหนึ่งใช้ทรัพยากรการคำนวณมากเกินไป
- การเข้าถึงอย่างเท่าเทียมกัน: สร้างความมั่นใจในการกระจายการเข้าถึง API ที่เป็นธรรมในหมู่ผู้ใช้ทั้งหมด
- การป้องกันการใช้งานในทางที่ผิด: ป้องกันกิจกรรมที่เป็นอันตราย เช่น การขูดข้อมูลหรือการโจมตีแบบ DDoS
- ความเสถียรของบริการ: รักษาประสิทธิภาพของระบบโดยรวมในช่วงเวลาที่มีการใช้งานสูงสุด
ข้อจำกัดด้านอัตราเฉพาะของ Claude API
ข้อจำกัดด้านอัตราของ Claude แตกต่างกันไปตามประเภทบัญชีของคุณ:
- ผู้ใช้ฟรี: ประมาณ 100 ข้อความต่อวัน โดยโควตาจะรีเซ็ตตอนเที่ยงคืน
- ผู้ใช้ Pro: ประมาณห้าเท่าของขีดจำกัดของผู้ใช้ฟรี (ประมาณ 500 ข้อความต่อวัน)
- ผู้ใช้ API: ขีดจำกัดที่กำหนดเองตามแผนและข้อตกลงเฉพาะของคุณกับ Anthropic
นอกจากนี้ ในช่วงเวลาที่มีการใช้งานสูงสุด ขีดจำกัดเหล่านี้อาจถูกบังคับใช้อย่างเข้มงวดมากขึ้น และคุณอาจประสบกับการควบคุมชั่วคราวก่อนที่จะถึงการจัดสรรสูงสุดของคุณ
การระบุปัญหาข้อจำกัดด้านอัตรา
คุณอาจเข้าถึงขีดจำกัดด้านอัตราเมื่อแอปพลิเคชันของคุณได้รับรหัสสถานะ HTTP 429 Too Many Requests โดยทั่วไปการตอบสนองจะรวมส่วนหัวพร้อมข้อมูลเกี่ยวกับ:
- เมื่อคุณสามารถกลับมาทำคำขอได้
- สถิติการใช้งานปัจจุบันของคุณ
- ข้อมูลโควตาที่เหลือ
โซลูชันที่ 1: ใช้การจำกัดอัตราที่เหมาะสมในโค้ดของคุณ
แนวทางพื้นฐานที่สุดในการจัดการข้อจำกัดด้านอัตรา API คือการใช้การจำกัดอัตราฝั่งไคลเอนต์ ซึ่งจะช่วยป้องกันไม่ให้แอปพลิเคชันของคุณเกินปริมาณคำขอที่อนุญาต
การใช้อัลกอริทึม Token Bucket
Token bucket เป็นอัลกอริทึมยอดนิยมสำหรับการจำกัดอัตราที่ทำงานโดย:
- รักษา "ถัง" ที่เติมด้วยโทเค็นในอัตราคงที่
- ใช้โทเค็นสำหรับแต่ละคำขอ API
- บล็อกคำขอเมื่อไม่มีโทเค็น
นี่คือการใช้งาน Python:
import time
import threading
class TokenBucket:
def __init__(self, tokens_per_second, max_tokens):
self.tokens_per_second = tokens_per_second
self.max_tokens = max_tokens
self.tokens = max_tokens
self.last_refill = time.time()
self.lock = threading.Lock()
def _refill_tokens(self):
now = time.time()
elapsed = now - self.last_refill
new_tokens = elapsed * self.tokens_per_second
self.tokens = min(self.max_tokens, self.tokens + new_tokens)
self.last_refill = now
def get_token(self):
with self.lock:
self._refill_tokens()
if self.tokens >= 1:
self.tokens -= 1
return True
return False
def wait_for_token(self, timeout=None):
start_time = time.time()
while True:
if self.get_token():
return True
if timeout is not None and time.time() - start_time > timeout:
return False
time.sleep(0.1) # Sleep to avoid busy waiting
# Example usage with Claude API
import anthropic
# Create a rate limiter (5 requests per second, max burst of 10)
rate_limiter = TokenBucket(tokens_per_second=5, max_tokens=10)
client = anthropic.Anthropic(api_key="your_api_key")
def generate_with_claude(prompt):
# Wait for a token to become available
if not rate_limiter.wait_for_token(timeout=30):
raise Exception("Timed out waiting for rate limit token")
try:
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1000,
messages=[{"role": "user", "content": prompt}]
)
return response.content
except Exception as e:
if "429" in str(e):
print("Rate limit hit despite our rate limiting! Backing off...")
time.sleep(10) # Additional backoff
return generate_with_claude(prompt) # Retry
raise
การใช้งานนี้:
- สร้าง token bucket ที่เติมในอัตราคงที่
- รอให้โทเค็นพร้อมใช้งานก่อนทำการร้องขอ
- ใช้ backoff เพิ่มเติมหากยังพบข้อจำกัดด้านอัตรา
การจัดการการตอบสนอง 429 ด้วย Exponential Backoff
แม้จะมีการจำกัดอัตราเชิงรุก คุณอาจเข้าถึงขีดจำกัดเป็นครั้งคราว การใช้ exponential backoff ช่วยให้แอปพลิเคชันของคุณกู้คืนได้อย่างราบรื่น:
import time
import random
def call_claude_api_with_backoff(prompt, max_retries=5, base_delay=1):
retries = 0
while retries <= max_retries:
try:
# Wait for rate limiter token
rate_limiter.wait_for_token()
# Make the API call
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1000,
messages=[{"role": "user", "content": prompt}]
)
return response.content
except Exception as e:
if "429" in str(e) and retries < max_retries:
# Calculate delay with exponential backoff and jitter
delay = base_delay * (2 ** retries) + random.uniform(0, 0.5)
print(f"Rate limited. Retrying in {delay:.2f} seconds...")
time.sleep(delay)
retries += 1
else:
raise
raise Exception("Max retries exceeded")
ฟังก์ชันนี้:
- พยายามทำการเรียก API
- หากเกิดข้อผิดพลาด 429 จะรอเป็นระยะเวลาที่เพิ่มขึ้นแบบทวีคูณ
- เพิ่ม jitter แบบสุ่มเพื่อป้องกันการซิงโครไนซ์คำขอ
- ยอมแพ้หลังจากจำนวนการลองใหม่สูงสุด
โซลูชันที่ 2: ใช้ Request Queuing และการจัดลำดับความสำคัญ
สำหรับแอปพลิเคชันที่มีระดับความสำคัญของคำขอที่แตกต่างกัน การใช้คิวคำขอพร้อมการจัดการลำดับความสำคัญสามารถเพิ่มประสิทธิภาพการใช้งาน API ของคุณได้
การสร้างระบบคิวลำดับความสำคัญ
import heapq
import threading
import time
from dataclasses import dataclass, field
from typing import Any, Callable, Optional
@dataclass(order=True)
class PrioritizedRequest:
priority: int
execute_time: float = field(compare=False)
callback: Callable = field(compare=False)
args: tuple = field(default_factory=tuple, compare=False)
kwargs: dict = field(default_factory=dict, compare=False)
class ClaudeRequestQueue:
def __init__(self, requests_per_minute=60):
self.queue = []
self.lock = threading.Lock()
self.processing = False
self.requests_per_minute = requests_per_minute
self.interval = 60 / requests_per_minute
def add_request(self, callback, priority=0, delay=0, *args, **kwargs):
"""Add a request to the queue with the given priority."""
with self.lock:
execute_time = time.time() + delay
request = PrioritizedRequest(
priority=-priority, # Negate so higher values have higher priority
execute_time=execute_time,
callback=callback,
args=args,
kwargs=kwargs
)
heapq.heappush(self.queue, request)
if not self.processing:
self.processing = True
threading.Thread(target=self._process_queue, daemon=True).start()
def _process_queue(self):
"""Process requests from the queue, respecting rate limits."""
while True:
with self.lock:
if not self.queue:
self.processing = False
return
# Get the highest priority request that's ready to execute
request = self.queue[0]
now = time.time()
if request.execute_time > now:
# Wait until the request is ready
wait_time = request.execute_time - now
time.sleep(wait_time)
continue
# Remove the request from the queue
heapq.heappop(self.queue)
# Execute the request outside the lock
try:
request.callback(*request.args, **request.kwargs)
except Exception as e:
print(f"Error executing request: {e}")
# Wait for the rate limit interval
time.sleep(self.interval)
# Example usage
queue = ClaudeRequestQueue(requests_per_minute=60)
def process_result(result, callback):
print(f"Got result: {result[:50]}...")
if callback:
callback(result)
def make_claude_request(prompt, callback=None, priority=0):
def execute():
try:
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1000,
messages=[{"role": "user", "content": prompt}]
)
process_result(response.content, callback)
except Exception as e:
if "429" in str(e):
# Re-queue with a delay if rate limited
print("Rate limited, re-queuing...")
queue.add_request(
make_claude_request,
priority=priority-1, # Lower priority for retries
delay=10, # Wait 10 seconds before retrying
prompt=prompt,
callback=callback,
priority=priority
)
else:
print(f"Error: {e}")
queue.add_request(execute, priority=priority)
# Make some requests with different priorities
make_claude_request("High priority question", priority=10)
make_claude_request("Medium priority question", priority=5)
make_claude_request("Low priority question", priority=1)
การใช้งานนี้:
- สร้างคิวลำดับความสำคัญสำหรับคำขอ API
- ประมวลผลคำขอตามลำดับความสำคัญและเวลาดำเนินการตามกำหนดการ
- ควบคุมคำขอโดยอัตโนมัติเพื่อให้เป็นไปตามขีดจำกัดด้านอัตรา
- จัดการการลองใหม่โดยลดลำดับความสำคัญ
โซลูชันที่ 3: กระจายคำขอในหลายอินสแตนซ์
สำหรับแอปพลิเคชันที่มีปริมาณมาก การกระจายคำขอ Claude API ในหลายอินสแตนซ์สามารถช่วยให้คุณปรับขนาดเกินขีดจำกัดของบัญชีเดียวได้
การปรับสมดุลโหลดในหลาย API Key
import random
import threading
from datetime import datetime, timedelta
class APIKeyManager:
def __init__(self, api_keys, requests_per_day_per_key):
self.api_keys = {}
self.lock = threading.Lock()
# Initialize each API key's usage tracking
for key in api_keys:
self.api_keys[key] = {
'key': key,
'daily_limit': requests_per_day_per_key,
'used_today': 0,
'last_reset': datetime.now().date(),
'available': True
}
def _reset_daily_counters(self):
"""Reset daily counters if it's a new day."""
today = datetime.now().date()
for key_info in self.api_keys.values():
if key_info['last_reset'] < today:
key_info['used_today'] = 0
key_info['last_reset'] = today
key_info['available'] = True
def get_available_key(self):
"""Get an available API key that hasn't exceeded its daily limit."""
with self.lock:
self._reset_daily_counters()
available_keys = [
key_info for key_info in self.api_keys.values()
if key_info['available'] and key_info['used_today'] < key_info['daily_limit']
]
if not available_keys:
return None
# Choose a key with the fewest used requests today
selected_key = min(available_keys, key=lambda k: k['used_today'])
selected_key['used_today'] += 1
# If key has reached its limit, mark as unavailable
if selected_key['used_today'] >= selected_key['daily_limit']:
selected_key['available'] = False
return selected_key['key']
def mark_key_used(self, api_key):
"""Mark that a request was made with this key."""
with self.lock:
if api_key in self.api_keys:
self.api_keys[api_key]['used_today'] += 1
if self.api_keys[api_key]['used_today'] >= self.api_keys[api_key]['daily_limit']:
self.api_keys[api_key]['available'] = False
def mark_key_rate_limited(self, api_key, retry_after=60):
"""Mark a key as temporarily unavailable due to rate limiting."""
with self.lock:
if api_key in self.api_keys:
self.api_keys[api_key]['available'] = False
# Start a timer to mark the key available again after the retry period
def make_available_again():
with self.lock:
if api_key in self.api_keys:
self.api_keys[api_key]['available'] = True
timer = threading.Timer(retry_after, make_available_again)
timer.daemon = True
timer.start()
# Example usage
api_keys = [
"key1_abc123",
"key2_def456",
"key3_ghi789"
]
key_manager = APIKeyManager(api_keys, requests_per_day_per_key=100)
def call_claude_api_distributed(prompt):
api_key = key_manager.get_available_key()
if not api_key:
raise Exception("No available API keys - all have reached their daily limits")
client = anthropic.Anthropic(api_key=api_key)
try:
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1000,
messages=[{"role": "user", "content": prompt}]
)
return response.content
except Exception as e:
if "429" in str(e):
# Parse retry-after header if available, otherwise use default
retry_after = 60 # Default
key_manager.mark_key_rate_limited(api_key, retry_after)
# Recursively try again with a different key
return call_claude_api_distributed(prompt)
else:
raise
แนวทางนี้:
- จัดการ API key หลายรายการและติดตามการใช้งาน
- กระจายคำขอเพื่อให้อยู่ภายใต้ขีดจำกัดด้านอัตราต่อคีย์
- จัดการการตอบสนองข้อจำกัดด้านอัตราโดยการลบคีย์ที่ได้รับผลกระทบออกจากวงจรชั่วคราว
- รีเซ็ตตัวนับการใช้งานโดยอัตโนมัติทุกวัน
แนวทางปฏิบัติที่ดีที่สุดสำหรับการจัดการข้อจำกัดด้านอัตราของ Claude API
นอกเหนือจากโซลูชันสามข้อข้างต้นแล้ว นี่คือแนวทางปฏิบัติที่ดีที่สุดเพิ่มเติม:
ตรวจสอบการใช้งานของคุณอย่างแข็งขัน
- ใช้แดชบอร์ดเพื่อติดตามการใช้งาน API ของคุณ
- ตั้งค่าการแจ้งเตือนเมื่อคุณเข้าใกล้ขีดจำกัดด้านอัตรา
- ตรวจสอบรูปแบบการใช้งานเป็นประจำเพื่อระบุโอกาสในการเพิ่มประสิทธิภาพ
ใช้การลดระดับอย่างสง่างาม
- ออกแบบแอปพลิเคชันของคุณเพื่อตอบสนองทางเลือกเมื่อถูกจำกัดอัตรา
- พิจารณาแคชการตอบสนองก่อนหน้าสำหรับแบบสอบถามที่คล้ายกัน
- ให้ข้อเสนอแนะที่โปร่งใสแก่ผู้ใช้เมื่อประสบกับข้อจำกัดด้านอัตรา
ปรับแต่งพร้อมท์ของคุณ
- ลดการเรียก API ที่ไม่จำเป็นโดยการสร้างพร้อมท์ที่มีประสิทธิภาพมากขึ้น
- รวมแบบสอบถามที่เกี่ยวข้องเป็นคำขอเดียวเมื่อเป็นไปได้
- ประมวลผลอินพุตล่วงหน้าเพื่อขจัดความจำเป็นในการขอคำชี้แจง
สื่อสารกับ Anthropic
- สำหรับแอปพลิเคชันการผลิต ให้พิจารณาอัปเกรดเป็นแผนระดับสูงกว่า
- ติดต่อ Anthropic เกี่ยวกับขีดจำกัดด้านอัตราที่กำหนดเองสำหรับกรณีการใช้งานเฉพาะของคุณ
- รับทราบข้อมูลเกี่ยวกับการอัปเดตแพลตฟอร์มและการเปลี่ยนแปลงนโยบายการจำกัดอัตรา
บทสรุป
ข้อจำกัดด้านอัตราเป็นส่วนหนึ่งที่หลีกเลี่ยงไม่ได้ของการทำงานกับ API ที่ทรงพลังเช่น Claude ด้วยการใช้โซลูชันที่สรุปไว้ในบทความนี้—โค้ดการจำกัดอัตราที่เหมาะสม คิวคำขอ และการจัดการคำขอแบบกระจาย—คุณสามารถสร้างแอปพลิเคชันที่แข็งแกร่งซึ่งจัดการกับข้อจำกัดเหล่านี้ได้อย่างสง่างาม
โปรดจำไว้ว่าข้อจำกัดด้านอัตรามีอยู่เพื่อให้แน่ใจว่ามีการเข้าถึงที่เป็นธรรมและความเสถียรของระบบสำหรับผู้ใช้ทุกคน การทำงานภายในข้อจำกัดเหล่านี้ไม่เพียงแต่ช่วยปรับปรุงความน่าเชื่อถือของแอปพลิเคชันของคุณเท่านั้น แต่ยังมีส่วนช่วยให้ระบบนิเวศโดยรวมมีสุขภาพที่ดีอีกด้วย
ด้วยการวางแผนและการใช้กลยุทธ์เหล่านี้อย่างรอบคอบ คุณสามารถเพิ่มการใช้ความสามารถด้าน AI ที่ทรงพลังของ Claude ให้สูงสุดในขณะที่รักษาประสบการณ์ที่ราบรื่นสำหรับผู้ใช้ของคุณ แม้ว่าแอปพลิเคชันของคุณจะปรับขนาดก็ตาม


