
นักพัฒนาแสวงหาเครื่องมือที่ช่วยเพิ่มประสิทธิภาพอย่างต่อเนื่องโดยไม่ลดทอนความแม่นยำ การรวมโมเดล GPT-5.1 Codex ของ OpenAI เข้ากับ Cursor ถือเป็นตัวอย่างที่โดดเด่น โดยนำเสนอชุดรูปแบบพิเศษที่ปรับแต่งสำหรับเวิร์กโฟลว์แบบเอเจนต์ โมเดลเหล่านี้จะเปลี่ยนวิธีที่คุณจัดการการสร้างโค้ด การแก้ไขข้อผิดพลาด และการปรับปรุงโค้ดได้โดยตรงภายใน IDE ของคุณ
ทำความเข้าใจ Cursor Codex: รากฐานของการรวม GPT-5.1
Cursor Codex หมายถึง ตระกูลโมเดลขั้นสูงของ OpenAI ที่ได้รับการปรับแต่งมาอย่างดีสำหรับงานเขียนโค้ดและถูกนำมาใช้ประโยชน์ได้อย่างราบรื่นภายใน Cursor IDE นักพัฒนาเปิดใช้งานโมเดลเหล่านี้ผ่านตัวเลือกเฉพาะ ทำให้เอเจนต์ AI สามารถอ่านไฟล์ รันคำสั่งเชลล์ และทำการแก้ไขได้ด้วยตนเอง การตั้งค่านี้อาศัยชุดเครื่องมือแบบกำหนดเองที่ปรับพรอมต์และเครื่องมือให้เข้ากับการฝึกอบรมของโมเดล เพื่อให้มั่นใจถึงประสิทธิภาพที่เชื่อถือได้ในพื้นที่เก็บข้อมูลที่ซับซ้อน
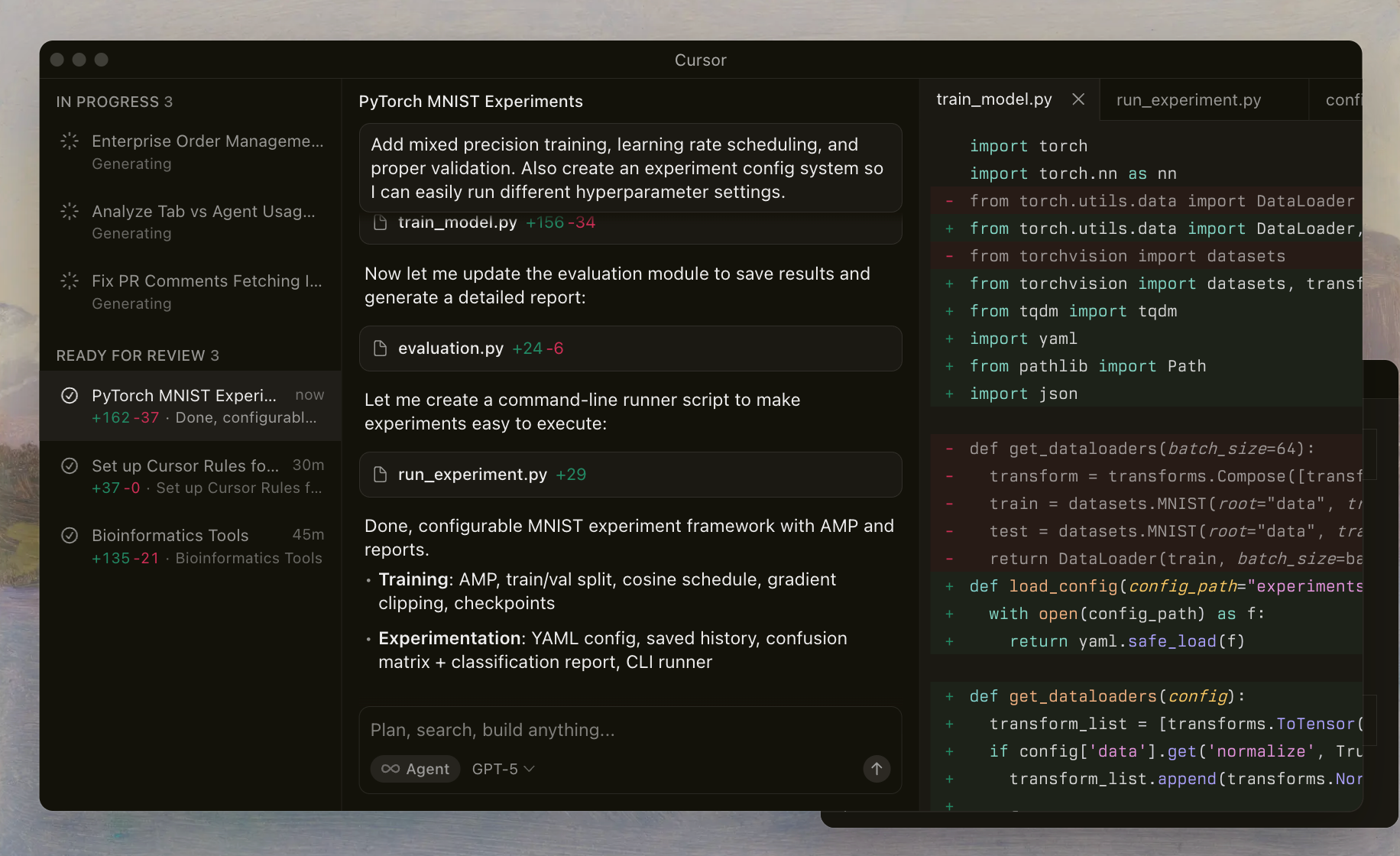
ซีรีส์ GPT-5.1 สร้างขึ้นจากรุ่นก่อนหน้าโดยเน้นความสามารถแบบเอเจนต์ ซึ่งหมายความว่าโมเดลจะทำหน้าที่เหมือนผู้ช่วยอัจฉริยะที่วางแผน ทำซ้ำ และแก้ไขตัวเองได้ แตกต่างจาก LLM ทั่วไป Cursor Codex ให้ความสำคัญกับเวิร์กโฟลว์ที่เน้นเชลล์เป็นหลัก ตัวอย่างเช่น โมเดลเรียนรู้ที่จะเรียกใช้เครื่องมือสำหรับการตรวจสอบไฟล์หรือการตรวจสอบโค้ด (linting) ซึ่งช่วยลดข้อผิดพลาดและปรับปรุงความแม่นยำในการแก้ไข
การใช้งานของ Cursor มีการป้องกัน เช่น การติดตามกระบวนการคิด (reasoning traces) ซึ่งช่วยรักษาแนวคิดของโมเดลตลอดการโต้ตอบ ความต่อเนื่องนี้ช่วยป้องกันปัญหาทั่วไปของการสูญเสียบริบทในการสนทนาหลายรอบ ในขณะที่คุณทดลองใช้โมเดลเหล่านี้ คุณจะสังเกตเห็นว่าโมเดลจัดการกับกรณีพิเศษอย่างไร เช่น การแก้ไขข้อขัดแย้งในการรวมโค้ด (merge conflicts) หรือการเพิ่มประสิทธิภาพโค้ดแบบอะซิงโครนัส
เมื่อพูดถึงรายละเอียด OpenAI ได้เปิดตัวกลุ่มผลิตภัณฑ์ GPT-5.1 Codex ในช่วงปลายปี 2025 ซึ่งตรงกับการปรับปรุงเฟรมเวิร์กเอเจนต์ของ Cursor ระยะเวลาที่เหมาะสมนี้ช่วยให้นักพัฒนาสามารถใช้ประโยชน์จากความฉลาดระดับแนวหน้าสำหรับงานประจำวัน ตั้งแต่การสร้างต้นแบบไมโครเซอร์วิสไปจนถึงการตรวจสอบระบบเก่า
ขอแนะนำตระกูลโมเดล GPT-5.1 Codex
Cursor นำเสนอตัวเลือกที่หลากหลายของ GPT-5.1 Codex แต่ละรุ่นได้รับการปรับแต่งมาอย่างดีเพื่อให้ได้ความสมดุลที่แตกต่างกันในด้านความฉลาด ความเร็ว และการใช้ทรัพยากร คุณสามารถเข้าถึงได้ผ่านตัวเลือกโมเดลใน IDE ซึ่งสลับสับเปลี่ยนเพื่อระบุความพร้อมใช้งานและการเลือกปัจจุบัน ด้านล่างนี้ เราจะแนะนำแต่ละรุ่น โดยเน้นคุณลักษณะหลักที่ได้มาจากเอกสารประกอบของ Cursor และเกณฑ์มาตรฐานภายใน
GPT-5.1 Codex Max: เรือธงสำหรับงานที่ต้องการประสิทธิภาพสูง
GPT-5.1 Codex Max เป็นรากฐานสำคัญของตระกูลนี้ วิศวกรของ OpenAI ได้ฝึกฝนโมเดลนี้ด้วยชุดข้อมูลจำนวนมากของการเขียนโค้ดแบบเอเจนต์ โดยรวมเครื่องมือเฉพาะของ Cursor เช่น การรันเชลล์และเครื่องอ่าน Lint เข้าไว้ด้วยกัน โมเดลนี้โดดเด่นในการรักษาการให้เหตุผลในบริบทที่ยาวนาน ประมวลผลโทเค็นได้สูงสุด 512K โดยไม่ลดทอนประสิทธิภาพ
คุณสมบัติที่สำคัญรวมถึงการเรียกใช้เครื่องมือแบบปรับเปลี่ยนได้: โมเดลจะเลือกแบบไดนามิกระหว่างการแก้ไขโดยตรงและทางเลือกสำรองที่ใช้ Python สำหรับการปรับเปลี่ยนที่ซับซ้อน ตัวอย่างเช่น เมื่อปรับปรุงแอปพลิเคชัน Node.js, Codex Max จะสร้างแผน เรียกใช้ git diff เพื่อตรวจสอบ และนำการเปลี่ยนแปลงไปใช้แบบอะตอมมิก
เกณฑ์มาตรฐานแสดงให้เห็นถึงความสามารถของมัน ในชุดประเมินภายในของ Cursor ซึ่งวัดอัตราความสำเร็จในพื้นที่เก็บข้อมูลจริง Codex Max สามารถแก้ไขงานหลายไฟล์ได้ถึง 78% ซึ่งสูงกว่า GPT-4.5 ถึง 15% อย่างไรก็ตาม มันต้องการการประมวลผลที่สูงกว่า โดยมีเวลาในการอนุมานเฉลี่ย 2-3 วินาทีต่อรอบบนฮาร์ดแวร์มาตรฐาน
นักพัฒนาชื่นชอบโมเดลนี้สำหรับโปรเจกต์ขนาดองค์กร ซึ่งความแม่นยำมีความสำคัญมากกว่าความเร็ว หากเวิร์กโฟลว์ของคุณเกี่ยวข้องกับการรวม API ให้จับคู่กับ Apidog เพื่อตรวจสอบสคีมาที่สร้างขึ้นโดยอัตโนมัติ
GPT-5.1 Codex Mini: พลังกระทัดรัดสำหรับการทำซ้ำอย่างรวดเร็ว
ถัดมา GPT-5.1 Codex Mini ลดจำนวนพารามิเตอร์ลง ในขณะที่ยังคงรักษาความแม่นยำในการเขียนโค้ดของ Max ไว้ได้ถึง 85% รุ่นนี้เหมาะสำหรับสภาพแวดล้อมที่มีน้ำหนักเบา เช่น การพัฒนาแอปพลิเคชันมือถือหรือ CI/CD pipelines มันประมวลผลโทเค็นได้ 128K และให้ความสำคัญกับการตอบสนองที่มีความล่าช้าต่ำ โดยใช้เวลาไม่ถึง 1 วินาทีสำหรับคำขอส่วนใหญ่
โมเดลนี้ใช้ความรู้ที่กลั่นกรองมาจาก Max โดยเน้นไปที่รูปแบบทั่วไป เช่น การปรับโครงสร้างโค้ดโดยใช้ regex หรือการสร้างชุดทดสอบ (unit test) ความสามารถที่โดดเด่นคือสรุปเหตุผลแบบอินไลน์ ซึ่งเป็นข้อความสั้นๆ กระชับที่อัปเดตผู้ใช้โดยไม่มีบันทึกที่ยืดยาว สิ่งนี้ช่วยลดภาระทางความคิดในระหว่างการสร้างต้นแบบอย่างรวดเร็ว
ในการทดสอบประสิทธิภาพ Codex Mini ทำคะแนนได้ 62% ใน SWE-bench lite ซึ่งเป็นชุดย่อยของงานวิศวกรรมซอฟต์แวร์ มันโดดเด่นในการแก้ไขไฟล์เดียว ซึ่งความเร็วช่วยให้สามารถทำซ้ำได้อย่างราบรื่น สำหรับทีมที่สร้างบริการ RESTful โมเดลนี้ทำงานร่วมกับเครื่องมือจำลองของ Apidog ได้อย่างง่ายดาย ทำให้สามารถจำลองปลายทางได้ทันที
GPT-5.1 Codex Max High: ความฉลาดที่สมดุลพร้อมความแม่นยำที่เหนือกว่า
GPT-5.1 Codex Max High ปรับปรุงพื้นฐานของ Max โดยเพิ่มความแม่นยำในสถานการณ์ที่มีความเสี่ยงสูง OpenAI ปรับแต่งโมเดลนี้สำหรับโดเมนต่างๆ เช่น การตรวจสอบความปลอดภัยและการเพิ่มประสิทธิภาพ ซึ่งข้อผิดพลาดที่ระบุผิด (false positives) ทำให้เสียเวลา มันจัดการกับบริบทได้ 256K และรวมเอาพรอมต์เฉพาะสำหรับการตรวจจับช่องโหว่
คุณสมบัติต่างๆ เช่น การติดตามกระบวนการคิดแบบขยาย (extended chain-of-thought traces) ช่วยให้สามารถวิเคราะห์ได้ลึกซึ้งยิ่งขึ้น โมเดลจะแสดงเหตุผลทีละขั้นตอนก่อนการเรียกใช้เครื่องมือ เพื่อให้มั่นใจถึงความโปร่งใส ตัวอย่างเช่น เมื่อรักษาความปลอดภัยเส้นทาง Express.js โมเดลจะสแกนการพึ่งพา เสนอแพตช์ และตรวจสอบผ่านการจำลองการตรวจสอบโค้ด (lints)
ตัวชี้วัดแสดงอัตราความสำเร็จ 72% ในโมดูลความปลอดภัยของ Cursor Bench ซึ่งสูงกว่า Max มาตรฐาน 5% เวลาตอบสนองอยู่ที่ 1.5-2.5 วินาที ทำให้เหมาะสำหรับพื้นที่เก็บข้อมูลขนาดกลาง นักพัฒนาที่ใช้สิ่งนี้สำหรับแอปพลิเคชันที่เน้น API จะชื่นชอบการทำงานร่วมกันกับ Apidog ซึ่งสามารถนำเข้าข้อกำหนด OpenAPI ที่สร้างโดย Codex สำหรับการตรวจสอบร่วมกันได้
GPT-5.1 Codex Max Low: ความแม่นยำที่มีประสิทธิภาพในการใช้ทรัพยากร
GPT-5.1 Codex Max Low ลดความต้องการในการประมวลผลลงโดยไม่ลดทอนความฉลาดหลัก เหมาะสำหรับแล็ปท็อปหรือคลัสเตอร์ที่ใช้ร่วมกัน โดยจำกัดที่ 128K โทเค็นและเพิ่มประสิทธิภาพสำหรับการประมวลผลแบบแบตช์ โมเดลนี้ชอบการแก้ไขที่อนุรักษ์นิยม ลดการปรับปรุงครั้งใหญ่เพื่อเน้นการแก้ไขเฉพาะจุด
มันมีชุดเครื่องมือที่ใช้ทรัพยากรน้อย โดยอาศัยคำสั่งพื้นฐานของเชลล์ เช่น grep และ sed แทนสคริปต์ Python ที่ซับซ้อน วิธีการนี้ให้ประสิทธิภาพ 68% ในเกณฑ์มาตรฐานที่เน้นการแก้ไข โดยมีการอนุมานภายใน 2 วินาที กรณีการใช้งานครอบคลุมการย้ายโค้ดเก่า ซึ่งความเสถียรสำคัญกว่าความแปลกใหม่
สำหรับนักพัฒนา API รุ่นนี้เข้ากันได้ดีกับ Apidog's free tier ซึ่งช่วยให้สามารถทดสอบปลายทางที่ใช้ทรัพยากรน้อยได้อย่างเบา ๆ โดยไม่เป็นภาระกับเครื่องของคุณ
GPT-5.1 Codex Max Extra High: ความแม่นยำสูงพิเศษสำหรับผู้เชี่ยวชาญ
GPT-5.1 Codex Max Extra High ก้าวข้ามขีดจำกัดด้วยการสร้างแบบจำลองความน่าจะเป็นที่ได้รับการปรับปรุงให้ดีขึ้น ได้รับการฝึกฝนด้วยชุดข้อมูลกรณีพิเศษ ทำให้มีความเข้าใจใกล้เคียงมนุษย์สำหรับงานที่ไม่ชัดเจน เช่น การอนุมานความตั้งใจจากข้อมูลจำเพาะบางส่วน หน้าต่างบริบทขยายเป็น 384K รองรับการนำทางใน monorepo
คุณสมบัติขั้นสูงประกอบด้วยการวางแผนแบบหลายสมมติฐาน: โมเดลจะสร้างและจัดอันดับตัวเลือกการแก้ไขก่อนที่จะยืนยัน ในการปรับโครงสร้างโค้ดที่ซับซ้อน สามารถแก้ไขความขัดแย้งได้ด้วยตัวเองถึง 82%
เกณฑ์มาตรฐานเน้นย้ำถึงจุดเด่นของมัน โดยทำคะแนนได้ 85% ในการประเมินขั้นสูงของ Cursor แต่มีความล่าช้า 3-4 วินาที เก็บสิ่งนี้ไว้สำหรับการเขียนโค้ดระดับงานวิจัย เช่น การออกแบบอัลกอริทึม ผสานรวม Apidog เพื่อสร้างต้นแบบสัญญา API ที่มีความแม่นยำสูงพิเศษที่ได้จากผลลัพธ์ของมัน
GPT-5.1 Codex Max Medium Fast: ความเร็วพบกับความสามารถ
GPT-5.1 Codex Max Medium Fast สร้างความสมดุลระหว่างความลึกและการจัดส่ง มันประมวลผลโทเค็นได้ 192K และใช้ quantized weights สำหรับการตอบสนอง 1.2 วินาที โมเดลนี้สร้างสมดุลระหว่างการเรียกใช้เครื่องมือกับการสร้างโดยตรง ซึ่งเหมาะสำหรับการดีบักแบบโต้ตอบ
มันทำคะแนนได้ 70% ในเกณฑ์มาตรฐานงานผสมผสาน โดดเด่นในงานแบบไฮบริด เช่น การเติมโค้ดอัตโนมัติพร้อมคำอธิบาย นักพัฒนาใช้ประโยชน์จากมันสำหรับวงจร TDD ซึ่งการตอบรับที่รวดเร็วช่วยเร่งความก้าวหน้า
GPT-5.1 Codex Max High Fast: วิศวกรรมความแม่นยำที่รวดเร็ว
GPT-5.1 Codex Max High Fast เร่งความแม่นยำของรุ่น High ด้วยเส้นทางการอนุมานแบบขนาน ที่บริบท 256K มันให้การทำงาน 1 วินาทีต่อรอบ ในขณะที่ยังคงรักษาคะแนนเกณฑ์มาตรฐาน 74% คุณสมบัติต่างๆ เช่น predictive linting คาดการณ์ข้อผิดพลาดก่อนการแก้ไข
รุ่นนี้เหมาะสำหรับทีมที่มีความเร็วสูง เช่น ทีมพัฒนา API สำหรับฟินเทค Apidog เสริมด้วยการเร่งการตรวจสอบปลายทางที่ปรับให้เหมาะสมกับความเร็ว
GPT-5.1 Codex Max Low Fast: การทำงานที่กระชับและรวดเร็ว
GPT-5.1 Codex Max Low Fast ผสมผสานประสิทธิภาพของรุ่น Low เข้ากับความเร็วระดับ sub-second จำกัดที่ 96K โทเค็น มันให้ความสำคัญกับประสิทธิภาพในการทำงานรอบเดียว โดยทำคะแนนได้ 65% ในการประเมินการแก้ไขด่วน
เหมาะสำหรับการเขียนสคริปต์หรือการแก้ไขด่วน ช่วยลดโอเวอร์เฮดในการตั้งค่าที่มีทรัพยากรจำกัด
GPT-5.1 Codex Max Extra High Fast: ประสิทธิภาพสูงสุดแบบไฮบริด
GPT-5.1 Codex Max Extra High Fast ผสมผสานความลึกของ Extra High เข้ากับความเร็วที่รวดเร็ว โดยสูงสุด 2 วินาทีสำหรับบริบท 384K มันทำคะแนนได้ 80% ในเกณฑ์มาตรฐานระดับสูง โดยใช้ adaptive quantization
สำหรับเวิร์กโฟลว์ที่ล้ำสมัย โมเดลนี้กำหนดนิยามใหม่ของการเขียนโค้ดแบบเอเจนต์
GPT-5.1 Codex: พื้นฐานที่หลากหลาย
GPT-5.1 Codex ทำหน้าที่เป็นแกนหลักที่เรียบง่าย นำเสนอการจัดการ 256K ที่สมดุล โดยเฉลี่ย 2 วินาที มันเป็นรากฐานของทุกรุ่น โดยทำคะแนนได้ 70% ทั่วไป ซึ่งเชื่อถือได้สำหรับการใช้งานทั่วไป
GPT-5.1 Codex High: ประโยชน์ใช้สอยประจำวันที่เหนือกว่า
GPT-5.1 Codex High เพิ่มความแม่นยำพื้นฐานเป็น 73% โดยเน้นการวางแผนที่แข็งแกร่งสำหรับบริบท 192K
GPT-5.1 Codex Fast: การออกแบบที่เน้นความเร็วก่อน
GPT-5.1 Codex Fast ลดเวลาตอบสนองเหลือ 1 วินาทีและใช้โทเค็น 128K ที่ประสิทธิภาพ 60% เหมาะสำหรับการเติมโค้ดอัตโนมัติ
GPT-5.1 Codex High Fast: ความคล่องตัวที่ปรับแต่งมาอย่างดี
GPT-5.1 Codex High Fast มอบความแม่นยำ 72% ใน 1.2 วินาที ผสมผสานคุณสมบัติของรุ่น High เข้ากับความเร็ว
GPT-5.1 Codex Low: ความแม่นยำแบบมินิมอล
GPT-5.1 Codex Low ประหยัดทรัพยากรที่ 96K โทเค็น ทำคะแนนได้ 67% เหมาะสำหรับอุปกรณ์ปลายทาง
GPT-5.1 Codex Low Fast: ประสิทธิภาพสูงเป็นพิเศษ
GPT-5.1 Codex Low Fast ทำงานได้ภายใน sub-second ด้วยคะแนน 62% เหมาะสำหรับงานขนาดเล็ก
GPT-5.1 Codex Mini High: ความเป็นเลิศในขนาดกะทัดรัด
GPT-5.1 Codex Mini High ปรับปรุงรุ่น Mini ด้วยความแม่นยำ 65% ใน 0.8 วินาที
GPT-5.1 Codex Mini Low: ขนาดกะทัดรัดราคาประหยัด
GPT-5.1 Codex Mini Low ให้ประสิทธิภาพ 58% ด้วยต้นทุนที่น้อยที่สุด สำหรับความต้องการพื้นฐาน
การเปรียบเทียบทางเทคนิค: ตัวชี้วัดที่สำคัญ
เพื่อพิจารณาโมเดล Cursor Codex ที่ดีที่สุด เราจะวิเคราะห์ตัวชี้วัดสำคัญ: อัตราความสำเร็จ (จาก Cursor Bench) ความหน่วง ขนาดบริบท และประสิทธิภาพของเครื่องมือ อัตราความสำเร็จวัดการทำงานอัตโนมัติของงาน ความหน่วงติดตามเวลาตอบสนอง บริบทวัดความจุของโทเค็น และประสิทธิภาพของเครื่องมือประเมินการรวมเชลล์
| รุ่นโมเดล | อัตราความสำเร็จ (%) | ความหน่วง (วินาที) | บริบท (K โทเค็น) | ประสิทธิภาพของเครื่องมือ (%) |
|---|---|---|---|---|
| GPT-5.1 Codex Max | 78 | 2-3 | 512 | 92 |
| GPT-5.1 Codex Mini | 62 | <1 | 128 | 85 |
| GPT-5.1 Codex Max High | 72 | 1.5-2.5 | 256 | 90 |
| GPT-5.1 Codex Max Low | 68 | <2 | 128 | 88 |
| GPT-5.1 Codex Max Extra High | 82 | 3-4 | 384 | 95 |
| GPT-5.1 Codex Max Medium Fast | 70 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Max High Fast | 74 | 1 | 256 | 91 |
| GPT-5.1 Codex Max Low Fast | 65 | <1 | 96 | 84 |
| GPT-5.1 Codex Max Extra High Fast | 80 | 2 | 384 | 93 |
| GPT-5.1 Codex | 70 | 2 | 256 | 89 |
| GPT-5.1 Codex High | 73 | 1.8 | 192 | 88 |
| GPT-5.1 Codex Fast | 60 | 1 | 128 | 82 |
| GPT-5.1 Codex High Fast | 72 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Low | 67 | 1.5 | 96 | 85 |
| GPT-5.1 Codex Low Fast | 62 | <1 | 96 | 80 |
| GPT-5.1 Codex Mini High | 65 | 0.8 | 128 | 83 |
| GPT-5.1 Codex Mini Low | 58 | <0.8 | 64 | 78 |
ตัวเลขเหล่านี้มาจากชุดทดสอบของ Cursor ซึ่งจำลองการโต้ตอบกับ IDE จริง สังเกตว่ารุ่น Max มีอัตราความสำเร็จที่โดดเด่น ในขณะที่รุ่นที่ลงท้ายด้วย Fast มีความโดดเด่นในด้านความหน่วง
นอกจากนี้ ให้พิจารณาประสิทธิภาพด้านพลังงาน: โมเดล Low และ Mini ใช้พลังงานน้อยลง 40% ตามรายงานของ OpenAI สำหรับโปรเจกต์ที่เน้น API ประสิทธิภาพของเครื่องมือส่งผลโดยตรงต่อคุณภาพของการผสานรวม คะแนนที่สูงขึ้นหมายถึงการปรับแต่งด้วยมือน้อยลงเมื่อส่งออกไปยัง Apidog
รายละเอียดเกณฑ์มาตรฐาน: ข้อมูลเชิงลึกประสิทธิภาพในโลกจริง
เกณฑ์มาตรฐานให้หลักฐานที่จับต้องได้ Cursor Bench ซึ่งเป็นชุดเครื่องมือภายใน ทดสอบงานกว่า 500 รายการในภาษาต่างๆ เช่น Python, JavaScript และ Rust GPT-5.1 Codex Max เป็นผู้นำด้วยการแก้ไข 78% โดยเฉพาะในห่วงโซ่ของเอเจนต์ที่เกี่ยวข้องกับการเรียกใช้เครื่องมือมากกว่า 10 ครั้ง มันแก้ไขข้อผิดพลาดของ Linter ได้ 92% ของเวลาทั้งหมด ด้วยการรวม read_lints โดยเฉพาะ
รุ่น GPT-5.1 Codex Mini Fast ให้ความสำคัญกับปริมาณงาน ในการวิ่งเร็ว 100 งานที่จำลองสัปดาห์ Sprint, Mini ทำซ้ำได้มากกว่า Max ถึง 85% แม้ว่าจะมีความแม่นยำลดลง 20% สำหรับการปรับโครงสร้างโค้ดที่ละเอียดอ่อน
SWE-bench Verified ซึ่งเป็นตัวชี้วัดมาตรฐาน แสดงให้เห็นว่าตระกูลนี้มีค่าเฉลี่ย 65% ซึ่งเพิ่มขึ้น 25% จาก GPT-4.1 โมเดล Extra High ทำคะแนนสูงสุดที่ 82% แต่ความหน่วงของมันทำให้ไม่เหมาะสำหรับการเขียนโค้ดคู่แบบสด
เมื่อเปลี่ยนไปสู่กรณีการใช้งาน โมเดลที่มีบริบทสูงอย่าง Max Extra High จะทำงานได้ดีใน monorepos โดยสามารถนำทางไฟล์มากกว่า 50 ไฟล์ได้อย่างง่ายดาย สำหรับนักพัฒนาเดี่ยว Medium Fast สร้างความสมดุลที่เหมาะสมที่สุด
กรณีการใช้งาน: การจับคู่โมเดลกับความต้องการของนักพัฒนา
เลือกรุ่น Cursor Codex ของคุณตามความต้องการของเวิร์กโฟลว์ สำหรับการพัฒนา API แบบ Full-Stack, GPT-5.1 Codex Max High Fast จะสร้างปลายทางที่ปลอดภัยและปรับขนาดได้รวดเร็ว มันสร้าง GraphQL resolvers จากนั้นใช้เครื่องมือเชลล์เพื่อทดสอบกับ mocks – เพิ่มประสิทธิภาพด้วยตัวตรวจสอบสคีมาของ Apidog เพื่อความมั่นใจแบบ end-to-end
ในการเขียนโค้ดระบบฝังตัว (embedded systems) GPT-5.1 Codex Low เน้นประสิทธิภาพ โดยสร้างส่วนของโค้ด C++ ที่เหมาะสมกับสภาพแวดล้อมที่มีข้อจำกัด พายป์ไลน์การเรียนรู้ของเครื่องได้ประโยชน์จากการวางแผนแบบความน่าจะเป็นของ Max Extra High ซึ่งช่วยเพิ่มประสิทธิภาพของ tensor flows โดยมีการลองผิดลองถูกน้อยที่สุด
สำหรับการตั้งค่าการทำงานร่วมกัน รุ่น Fast ช่วยให้สามารถให้คำแนะนำแบบเรียลไทม์ ส่งเสริมการทำงานร่วมกันเป็นทีม ตรวจสอบการใช้โทเค็นเสมอ การเกินขีดจำกัดจะทำให้เกิดการสำรองข้อมูล ลดประสิทธิภาพลง 15%
ยิ่งไปกว่านั้น แนวทางแบบไฮบริดก็ใช้งานได้ดี — เริ่มต้นด้วย Mini สำหรับการระดมสมอง จากนั้นปรับไปใช้ Max สำหรับการนำไปใช้งาน กลยุทธ์นี้ช่วยเพิ่มผลตอบแทนจากการลงทุนในงบประมาณการประมวลผลให้สูงสุด
เคล็ดลับการเพิ่มประสิทธิภาพ: การยกระดับ Cursor Codex ด้วย Apidog
เพื่อเพิ่มประสิทธิภาพของ GPT-5.1 Codex ให้ปรับแต่งชุดเครื่องมือของคุณ เปิดใช้งานการติดตามกระบวนการคิด (reasoning traces) ในการตั้งค่า ซึ่งจะช่วยเพิ่มความต่อเนื่อง ทำให้ความสำเร็จเพิ่มขึ้น 30% ตามเอกสาร Cursor ควรเลือกการเรียกใช้เครื่องมือมากกว่าคำสั่งเชลล์ดิบ — พรอมต์เช่น "Use read_file before editing" จะช่วยแนะนำโมเดล
รวม Apidog เข้ากับเวิร์กโฟลว์ API Codex สร้างโค้ดเริ่มต้น Apidog ทดสอบทันที ส่งออกสเปคเป็น YAML จำลองการตอบกลับ และสร้างเอกสารอัตโนมัติ – ลดเวลาในการรวมระบบลง 50%
ตรวจสอบความหน่วงด้วยตัวชี้วัดในตัวของ Cursor หากเกิดคอขวด ให้เปลี่ยนไปใช้รุ่น Low อัปเดตชุดเครื่องมือเป็นประจำเพื่อรับแพตช์ เนื่องจาก OpenAI ทำการปรับปรุงบ่อยครั้ง
ความปลอดภัยก็สำคัญเช่นกัน: ทำความสะอาดเอาต์พุตของเครื่องมือเพื่อป้องกันความเสี่ยงจากการฉีดโค้ด สำหรับการใช้งานจริง ให้ตรวจสอบการแก้ไขของ Codex ผ่านการตรวจสอบความแตกต่าง (diff reviews)
บทสรุป: GPT-5.1 Codex Max กลายเป็นตัวเลือกที่ดีที่สุดโดยรวม
หลังจากวิเคราะห์ข้อมูลจำเพาะ เกณฑ์มาตรฐาน และแอปพลิเคชันต่างๆ แล้ว GPT-5.1 Codex Max ก็ขึ้นมาครองอันดับหนึ่ง อัตราความสำเร็จที่ไม่มีใครเทียบได้ถึง 78% บริบทที่แข็งแกร่ง 512K และชุดเครื่องมือที่หลากหลาย ทำให้เป็นสิ่งที่ขาดไม่ได้สำหรับการเขียนโค้ดที่จริงจัง ในขณะที่โมเดล Fast ชนะในด้านความเร็วและ Mini ชนะในด้านการเข้าถึง Max ก็มอบความเป็นเลิศแบบองค์รวม — ช่วยให้นักพัฒนาสามารถจัดการกับโปรเจกต์ที่ทะเยอทะยานได้อย่างเต็มที่
ทดลองใช้ Cursor วันนี้ และผสาน Apidog เพื่อการจัดการ API ที่ครอบคลุม ทางเลือกของคุณกำหนดประสิทธิภาพการทำงาน เลือก Max เพื่อให้ Stack ของคุณพร้อมสำหรับอนาคต