A inteligência artificial continua a evoluir rapidamente, e os desenvolvedores agora exigem ferramentas que ofereçam capacidades avançadas de raciocínio. A NVIDIA atende a essa necessidade com a família de modelos NVIDIA Llama Nemotron. Esses modelos se destacam em tarefas que requerem raciocínio complexo, oferecem eficiência computacional e vêm com uma licença aberta para uso empresarial. Os desenvolvedores podem acessar esses modelos por meio da API NVIDIA Llama Nemotron, fornecida pelos microserviços NIM da NVIDIA, facilitando a integração em aplicações.
Entendendo os Modelos NVIDIA Llama Nemotron
Antes de mergulhar na API, vamos examinar os modelos NVIDIA Llama Nemotron. Esta família inclui três variantes: Nano, Super e Ultra. Cada uma delas atende a necessidades específicas de implantação, equilibrando desempenho e demanda de recursos.
- Nano (8B parâmetros): Engenheiros otimizam este modelo para dispositivos de borda e PCs. Ele oferece alta precisão com poder computacional mínimo, tornando-se ideal para aplicações leves.
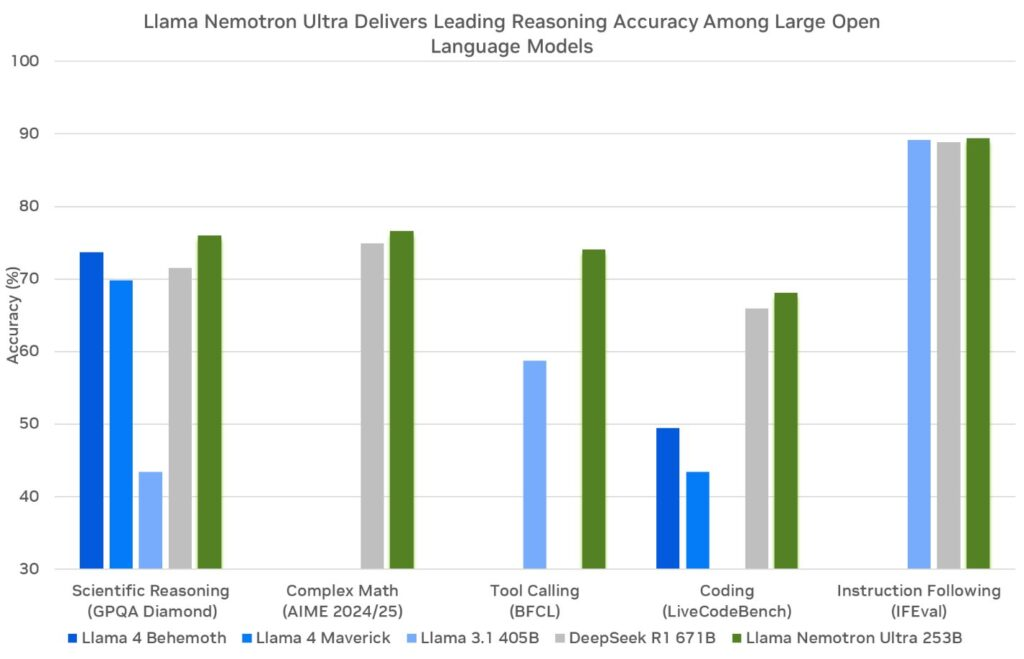
- Super (49B parâmetros): Desenvolvedores projetam este modelo para configurações de GPU única. Ele equilibra a taxa de transferência e a precisão, sendo adequado para tarefas moderadamente complexas.
- Ultra (253B parâmetros): Especialistas criam este modelo para servidores de data center com múltiplas GPUs. Ele fornece precisão de alto nível para as aplicações de agente de IA mais exigentes.
A NVIDIA desenvolve esses modelos com base no framework Llama da Meta, aprimorando-os com técnicas de pós-treinamento como destilação e aprendizado por reforço. Consequentemente, eles se destacam em tarefas de raciocínio, como análise científica, matemática avançada, codificação e seguimento de instruções. Cada modelo suporta um comprimento de contexto de 128.000 tokens, permitindo que processem documentos longos ou mantenham o contexto em interações prolongadas.
Um recurso destacado é a capacidade de ativar ou desativar o raciocínio por meio do prompt do sistema. Os desenvolvedores ativam o raciocínio para consultas complexas, como solução de problemas, e o desativam para tarefas simples, como a recuperação de informações estáticas. Essa flexibilidade otimiza o uso de recursos, uma vantagem crítica em aplicações do mundo real.
Configurando a API NVIDIA Llama Nemotron
Para aproveitar a API NVIDIA Llama Nemotron, você deve primeiro configurá-la. A NVIDIA entrega esta API por meio de seus microserviços NIM, que suportam implantação em ambientes de nuvem, locais ou de borda. Siga estas etapas para começar:
Participe do Programa de Desenvolvedores da NVIDIA: Registre-se para acessar recursos, documentação e ferramentas. Essa etapa desbloqueia o ecossistema que você precisa.
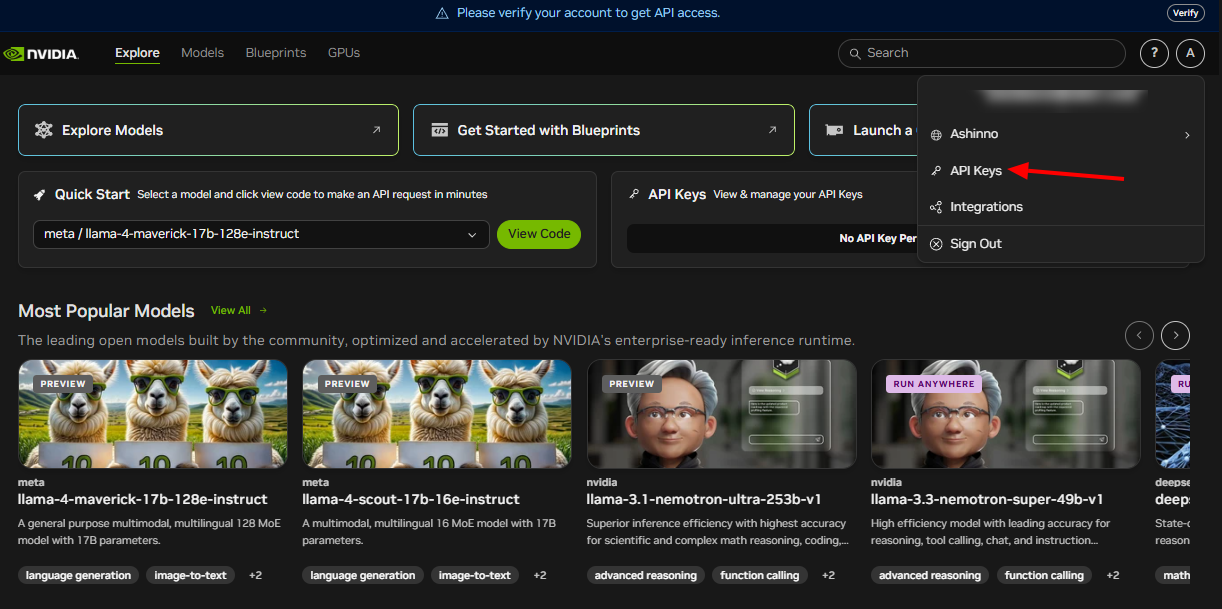
Obtenha Credenciais da API: A NVIDIA fornece chaves API. Use estas para autenticar suas solicitações de forma segura.
Instale as Bibliotecas Necessárias: Para desenvolvedores Python, instale a biblioteca requests para gerenciar chamadas HTTP. Execute este comando no seu terminal:
pip install requests
Com essas etapas concluídas, você prepara seu ambiente para interagir com a API NVIDIA Llama Nemotron. Em seguida, vamos explorar como fazer solicitações.
Fazendo Solicitações à API
A API NVIDIA Llama Nemotron adere aos padrões RESTful, simplificando a integração em seus projetos. Você envia solicitações POST para o endpoint da API, incorporando parâmetros no corpo da solicitação. Vamos simplificar isso com um exemplo prático.
Aqui está como você consulta a API usando Python:
import requests
import json
# Defina o endpoint da API e a autenticação
endpoint = "https://your-nim-endpoint.com/api/v1/generate"
headers = {
"Authorization": "Bearer SUA_CHAVE_API",
"Content-Type": "application/json"
}
# Crie a carga útil da solicitação
payload = {
"model": "llama-nemotron-super",
"prompt": "Quantas letras 'R' existem na palavra 'morango'?",
"max_tokens": 100,
"temperature": 0.7,
"reasoning": "on"
}
# Envie a solicitação
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# Processar a resposta
if response.status_code == 200:
result = response.json()
print(result["text"])
else:
print(f"Erro: {response.status_code} - {response.text}")
Parâmetros Chave Explicados
model: Especifica a variante do modelo—Nano, Super ou Ultra. Selecione com base na sua implantação.prompt: Fornece o texto de entrada para o modelo processar.max_tokens: Limita o comprimento da resposta em tokens. Ajuste isso para controlar o tamanho da saída.temperature: Varia de 0 a 1. Valores mais baixos (por exemplo, 0.5) geram saídas previsíveis, enquanto valores mais altos (por exemplo, 0.9) aumentam a criatividade.reasoning: Alterna as capacidades de raciocínio. Defina como "on" para tarefas complexas e "off" para tarefas simples.
Por exemplo, ativar o raciocínio se adapta a tarefas como resolver problemas matemáticos, enquanto desativá-lo funciona para buscas básicas. Você também pode adicionar parâmetros como top_p para controle de diversidade ou stop_sequences para interromper a geração em tokens específicos, como "\n\n".
Aqui está um exemplo estendido:
payload = {
"model": "llama-nemotron-super",
"prompt": "Explique recursão em programação.",
"max_tokens": 200,
"temperature": 0.6,
"top_p": 0.9,
"reasoning": "on",
"stop_sequences": ["\n\n"]
}
Essa solicitação gera uma explicação detalhada sobre recursão, parando em uma quebra de linha dupla. Ferramentas como Apidog ajudam você a testar e aprimorar essas solicitações de forma eficiente.
Manipulando Respostas da API
Após enviar uma solicitação, a API NVIDIA Llama Nemotron retorna uma resposta JSON. Isso inclui o texto gerado e metadados. Aqui está um exemplo de resposta:
{
"text": "Existem três letras 'R' na palavra 'morango'.",
"tokens_generated": 10,
"time_taken": 0.5
}
text: Contém a saída do modelo.tokens_generated: Indica o número de tokens produzidos.time_taken: Mede o tempo de geração em segundos.
Verifique sempre o código de status. Um código 200 sinaliza sucesso, permitindo que você analise o JSON. Erros retornam códigos como 400 ou 500, com detalhes no corpo da resposta para depuração. Implemente o tratamento de erro, como tentativas de repetição ou alternativas, para garantir robustez em produção.
Por exemplo, estenda o código anterior:
if response.status_code == 200:
result = response.json()
print(f"Resposta: {result['text']}")
print(f"Tokens usados: {result['tokens_generated']}")
else:
print(f"Falha: {response.text}")
# Adicione a lógica de repetição aqui, se necessário
Essa abordagem mantém seu aplicativo confiável em condições variadas.
Melhores Práticas e Casos de Uso
Para maximizar o potencial da API NVIDIA Llama Nemotron, adote estas melhores práticas:
- Otimize o Uso de Recursos: Ative o raciocínio apenas para tarefas complexas. Isso reduz significativamente os custos computacionais.
- Monitore o Desempenho: Acompanhe
time_takenpara garantir respostas tempestivas, especialmente para aplicações em tempo real. - Ajuste os Parâmetros: Experimente com
temperatureemax_tokenspara equilibrar criatividade e precisão. - Proteja as Credenciais: Armazene as chaves API em variáveis de ambiente ou cofres seguros, nunca no código.
- Solicitações em Lote: Processar múltiplos prompts em uma única chamada para aumentar a eficiência.
Casos de Uso Práticos
A versatilidade da API suporta diversas aplicações:
- Suporte ao Cliente: Desenvolva chatbots que resolvem consultas complexas com raciocínio, como problemas de hardware.
- Educação: Construa tutores que explicam conceitos, como cálculo, com lógica passo a passo.
- Pesquisa: Ajude cientistas a analisar dados ou formular hipóteses.
- Desenvolvimento de Software: Gere código ou depure scripts com base em entradas em linguagem natural.
Para um exemplo de codificação:
payload = {
"model": "llama-nemotron-super",
"prompt": "Escreva uma função em Python para calcular um fatorial.",
"max_tokens": 200,
"temperature": 0.5,
"reasoning": "on"
}
O modelo pode retornar:
def factorial(n):
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)
Isso demonstra sua capacidade de raciociniar através de lógica recursiva. O Apidog pode ajudar a testar chamadas de API, garantindo precisão.
Conclusão
A API NVIDIA Llama Nemotron capacita os desenvolvedores a criarem agentes de IA avançados com robustas capacidades de raciocínio. Seu recurso de raciocínio alternado otimiza o desempenho, enquanto sua escalabilidade entre os modelos Nano, Super e Ultra atende a diversas necessidades. Seja você construindo chatbots, ferramentas educacionais ou assistentes de codificação, esta API oferece flexibilidade e poder.
Além disso, integrá-la com ferramentas como o Apidog melhora seu fluxo de trabalho. Teste endpoints, valide respostas e itere rapidamente para focar na inovação. À medida que a IA avança, dominar a API NVIDIA Llama Nemotron o posiciona na vanguarda deste campo transformador.