
O processamento de documentos tem sido há muito tempo uma das aplicações mais práticas da IA — ainda assim, a maioria das soluções de OCR força uma troca desconfortável entre precisão e eficiência. Sistemas tradicionais como o Tesseract exigem pré-processamento extenso. APIs de nuvem cobram por página e adicionam latência. Mesmo modelos modernos de visão-linguagem lutam com a explosão de tokens que surge de imagens de documentos de alta resolução.
O DeepSeek-OCR 2 muda essa equação inteiramente. Baseando-se na abordagem de "Compressão Óptica de Contextos" da versão 1, a nova versão introduz o "Fluxo Causal Visual" — uma arquitetura que processa documentos da maneira como os humanos realmente os leem, compreendendo as relações visuais e o contexto, em vez de apenas reconhecer caracteres. O resultado é um modelo que alcança 97% de precisão enquanto comprime imagens para apenas 64 tokens, permitindo um throughput de mais de 200.000 páginas por dia em uma única GPU.
Este guia aborda tudo, desde a configuração básica até a implantação em produção — com código funcional que você pode copiar, colar e executar imediatamente.
O que é o DeepSeek-OCR 2?
DeepSeek-OCR 2 é um modelo de visão-linguagem de código aberto especificamente projetado para compreensão de documentos e extração de texto. Lançado pela DeepSeek AI em janeiro de 2026, ele se baseia no DeepSeek-OCR original com uma nova arquitetura de "Fluxo Causal Visual" que modela como os elementos visuais em documentos se relacionam causalmente entre si — entendendo que um cabeçalho de tabela determina como as células abaixo dele devem ser interpretadas, ou que a legenda de uma figura explica o gráfico acima dela.
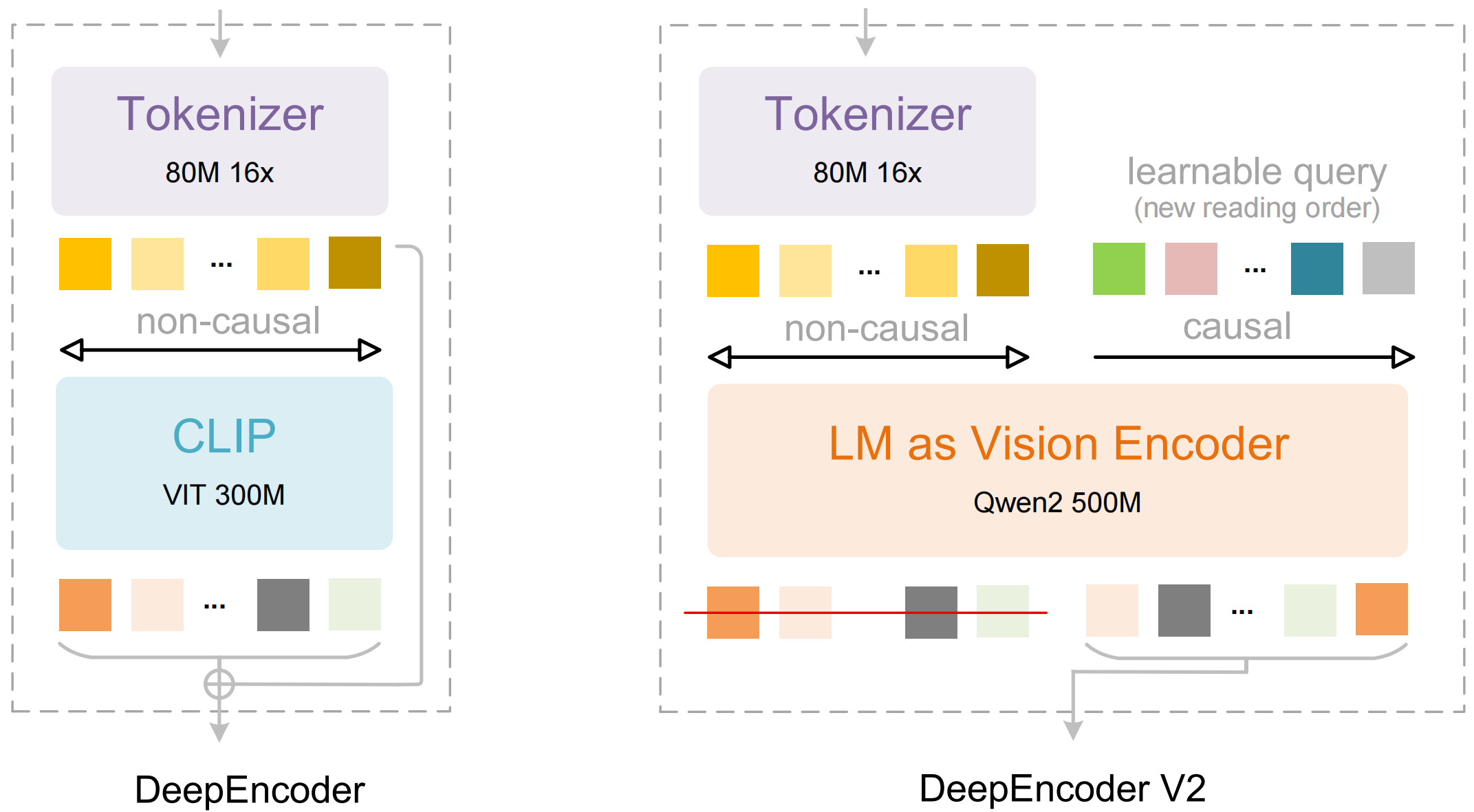
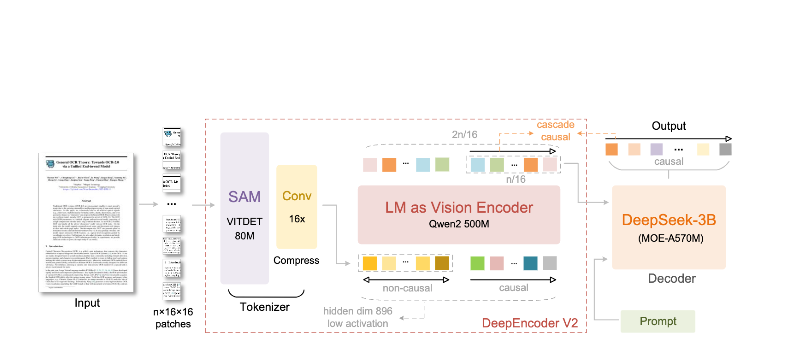
O modelo consiste em dois componentes principais:
- DeepEncoder: Um transformer de visão dupla que combina a extração de detalhes locais (baseado em SAM, 80M parâmetros) com a compreensão de layout global (baseado em CLIP, 300M parâmetros)
- DeepSeek3B-MoE Decoder: Um modelo de linguagem mixture-of-experts que gera saída estruturada (Markdown, LaTeX, JSON) a partir da representação visual compactada
O que torna o DeepSeek-OCR 2 diferente:
- Compressão extrema: Reduz uma imagem de 1024×1024 de 4.096 patches para apenas 256 tokens — uma redução de 16 vezes
- Saída estruturada: Gera Markdown limpo com tabelas, cabeçalhos e formatação adequados
- Suporte a múltiplos formatos: Lida com PDFs, documentos digitalizados, capturas de tela, notas manuscritas e muito mais
- Mais de 100 idiomas: Treinado em 30 milhões de páginas cobrindo aproximadamente 100 idiomas
- Pesos abertos: Licenciado sob MIT, disponível no Hugging Face
Principais Recursos e Arquitetura
Fluxo Causal Visual
O recurso principal da versão 2 é o "Fluxo Causal Visual" — uma nova abordagem para compreender documentos que vai além do OCR simples. Em vez de tratar uma página como uma grade plana de caracteres, o modelo aprende relações causais entre elementos visuais:
- Inferência da ordem de leitura: Determina automaticamente a sequência correta para layouts de várias colunas
- Compreensão da estrutura da tabela: Reconhece cabeçalhos, células mescladas e tabelas