
Qwen, a iniciativa de modelo de fundação aberta da Alibaba, consistentemente expande os limites da inteligência artificial através de iterações e lançamentos rápidos. Desenvolvedores e pesquisadores aguardam ansiosamente cada atualização, pois os modelos Qwen frequentemente estabelecem novos padrões de desempenho e versatilidade. Recentemente, a Qwen lançou três modelos inovadores: Qwen-Image-Edit-2509, Qwen3-TTS-Flash e Qwen3-Omni. Esses lançamentos aprimoram as capacidades em edição de imagem, síntese de texto para fala e processamento omnimodal, respectivamente.
Além disso, esses modelos chegam em um momento crucial no desenvolvimento da IA, onde a integração multimodal se torna essencial para aplicações práticas. O Qwen-Image-Edit-2509 atende à demanda por manipulações visuais precisas, enquanto o Qwen3-TTS-Flash aborda problemas de latência na geração de voz. Enquanto isso, o Qwen3-Omni unifica diversas entradas em uma estrutura coesa. Juntos, eles demonstram o compromisso da Qwen com uma IA acessível e de alto desempenho. No entanto, entender seus fundamentos técnicos requer um exame mais aprofundado. Este artigo disseciona cada modelo, destacando recursos, arquiteturas, benchmarks e impactos potenciais.
Qwen-Image-Edit-2509: Elevando a Precisão na Edição de Imagens
O Qwen-Image-Edit-2509 representa um avanço significativo na manipulação de imagens impulsionada por IA. Engenheiros da Qwen reconstruíram este modelo para atender a criadores, designers e desenvolvedores que exigem controle granular sobre o conteúdo visual. Ao contrário das iterações anteriores, esta versão suporta edição de múltiplas imagens, permitindo que os usuários combinem elementos como uma pessoa com um produto ou uma cena sem esforço. Consequentemente, ele elimina artefatos comuns, como misturas incompatíveis, produzindo saídas coerentes.

O modelo se destaca na consistência de imagem única. Ele preserva identidades faciais em diferentes poses, estilos e filtros, o que se mostra inestimável para aplicações em publicidade e personalização. Para imagens de produtos, o Qwen-Image-Edit-2509 mantém a integridade do objeto, garantindo que as edições não distorçam atributos chave. Além disso, ele lida com elementos de texto de forma abrangente, permitindo modificações de conteúdo, fontes, cores e até texturas. Essa versatilidade decorre de mecanismos ControlNet integrados, que incorporam mapas de profundidade, detecção de bordas e pontos-chave para orientação precisa.
Tecnicamente, o Qwen-Image-Edit-2509 se baseia na arquitetura fundamental do Qwen-Image, mas incorpora técnicas de treinamento avançadas. Os desenvolvedores o treinaram usando métodos de concatenação de imagens para facilitar entradas de múltiplas imagens. Por exemplo, combinar "pessoa + pessoa" ou "pessoa + cena" aproveita fluxos de dados concatenados, aprimorando a capacidade do modelo de fundir visuais díspares. Além disso, a arquitetura integra processos baseados em difusão, onde o ruído é progressivamente removido para gerar imagens refinadas. Essa abordagem, comum em variantes de difusão estável, permite a geração condicional com base em prompts do usuário.
Em termos de benchmarks, o Qwen-Image-Edit-2509 demonstra desempenho superior em métricas de consistência. Avaliações internas mostram que ele supera os concorrentes na preservação facial, com pontuações de similaridade excedendo 95% em diversas edições. Os benchmarks de consistência de produtos revelam distorção mínima, tornando-o ideal para e-commerce. No entanto, dados quantitativos de fontes externas permanecem limitados devido ao seu lançamento recente. Não obstante, demonstrações de usuários em plataformas como o Hugging Face destacam sua vantagem sobre modelos como o Stable Diffusion XL na mesclagem de múltiplos elementos.
As aplicações para o Qwen-Image-Edit-2509 são abundantes. Profissionais de marketing o utilizam para criar anúncios personalizados, editando o posicionamento de produtos de forma contínua. Designers o empregam para prototipagem rápida, alterando cenas sem retoques manuais. Além disso, em jogos, ele facilita a geração dinâmica de ativos. Um exemplo ilustrativo envolve a transformação da roupa de uma pessoa: uma imagem de entrada de uma mulher em traje casual, combinada com uma referência de vestido preto, produz uma saída onde o vestido se encaixa naturalmente, preservando a postura e a iluminação. Essa capacidade, como demonstrado em demos visuais, ressalta sua utilidade prática.


Passando para a implementação, os desenvolvedores acessam o Qwen-Image-Edit-2509 via repositórios do GitHub e espaços do Hugging Face. A instalação geralmente envolve clonar o repositório e configurar dependências como o PyTorch. Um script de uso básico pode ser assim:
import torch
from qwen_image_edit import QwenImageEdit
model = QwenImageEdit.from_pretrained("Qwen/Qwen-Image-Edit-2509")
input_image = load_image("person.jpg")
reference_image = load_image("dress.jpg")
output = model.edit_multi(input_image, reference_image, prompt="Apply the black dress to the person")
output.save("edited.jpg")
Esse código permite iterações rápidas. No entanto, os usuários devem considerar os requisitos computacionais, pois a inferência exige aceleração por GPU para velocidade ótima.
Apesar de seus pontos fortes, o Qwen-Image-Edit-2509 enfrenta desafios. Edições de alta resolução podem consumir memória significativa, e prompts complexos ocasionalmente levam a inconsistências. No entanto, as contribuições contínuas da comunidade através de canais de código aberto mitigam esses problemas. No geral, este modelo redefine a edição de imagens, combinando precisão com acessibilidade.
Qwen3-TTS-Flash: Acelerando a Síntese de Texto para Fala
O Qwen3-TTS-Flash surge como uma potência na tecnologia de texto para fala (TTS), priorizando velocidade e naturalidade. Engenheiros da Qwen o projetaram para entregar vozes semelhantes às humanas com latência mínima, abordando gargalos em aplicações em tempo real. Especificamente, ele atinge uma latência de primeiro pacote de apenas 97ms em ambientes de thread único, permitindo interações fluidas em chatbots e assistentes virtuais.
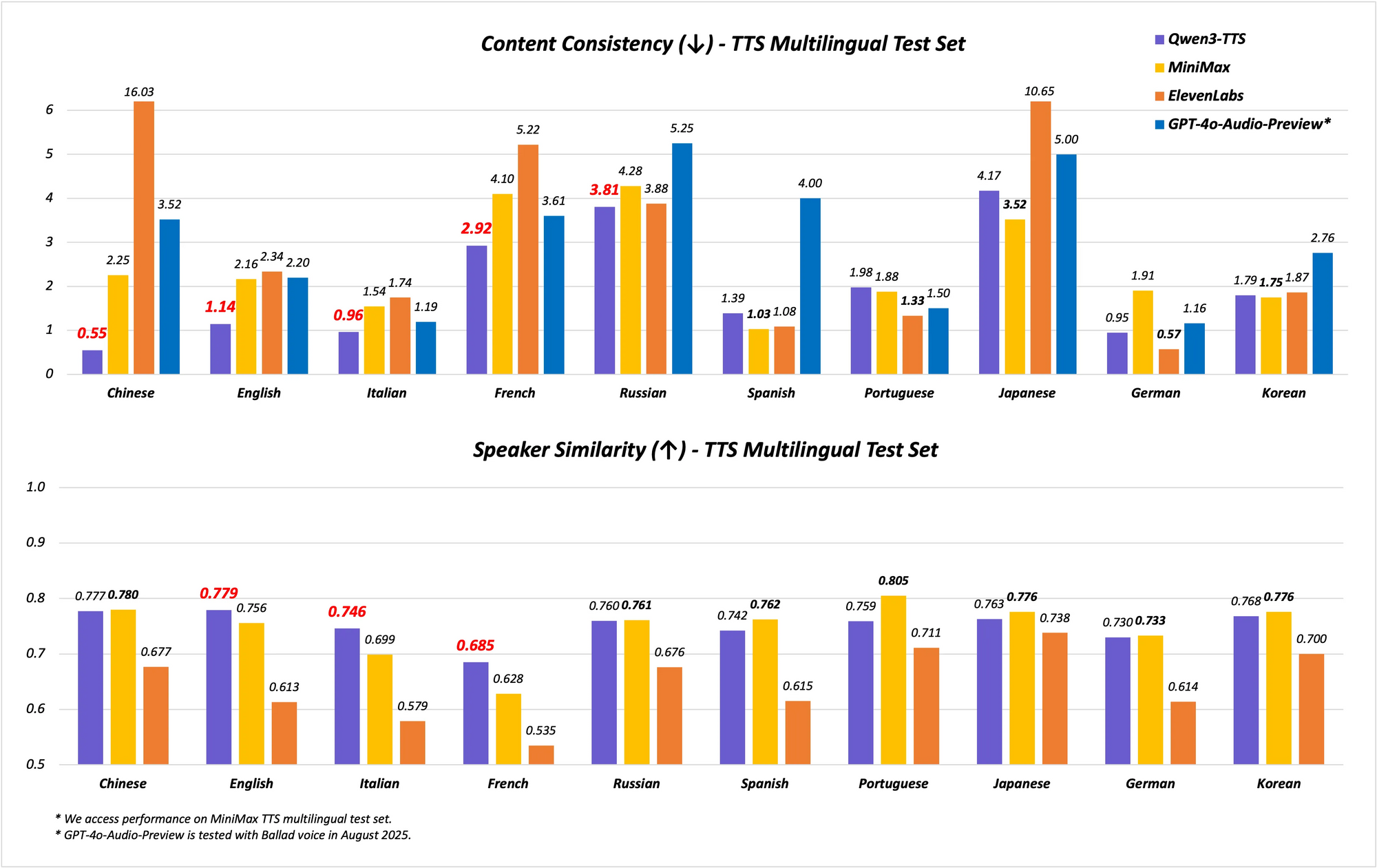
O modelo suporta capacidades multilíngues e multidialetais, cobrindo 10 idiomas com 17 vozes expressivas. Ele se destaca na estabilidade em chinês e inglês, alcançando desempenho de ponta (SOTA) em benchmarks como o conjunto de testes Seed-TTS-Eval. Aqui, ele supera modelos como SeedTTS, MiniMax e GPT-4o-Audio-Preview em métricas de estabilidade. Além disso, em avaliações multilíngues no conjunto de testes MiniMax TTS, o Qwen3-TTS-Flash registra a menor Taxa de Erro de Palavras (WER) para chinês, inglês, italiano e francês.
O suporte a dialetos diferencia o Qwen3-TTS-Flash. Ele lida com nove dialetos chineses, incluindo Cantonês, Hokkien, Sichuanês, Pequim, Nanquim, Tianjin e Shaanxi. Esse recurso permite uma fala culturalmente matizada, essencial em mercados diversos. Além disso, o modelo adapta tons automaticamente, utilizando dados de treinamento em larga escala para corresponder ao sentimento da entrada. O tratamento robusto de texto aumenta ainda mais a confiabilidade, pois ele extrai informações chave de formatos complexos como datas, números e acrônimos.
Arquitetonicamente, o Qwen3-TTS-Flash emprega uma estrutura encoder-decoder baseada em transformador, otimizada para inferência de baixa latência. Ele usa representações de múltiplos codebooks para uma modelagem de voz mais rica, melhorando a expressividade. O treinamento envolveu vastos conjuntos de dados abrangendo 119 idiomas para texto e 19 para compreensão de fala, embora a saída se concentre em 10 idiomas. Essa configuração permite a geração interlinguística, onde entradas em um idioma produzem saídas em outro de forma contínua.

Os benchmarks ilustram sua destreza. Em testes de estabilidade, o Qwen3-TTS-Flash pontua mais alto em similaridade de timbre e naturalidade em comparação com ElevenLabs e GPT-4o. Por exemplo:
| Benchmark | Qwen3-TTS-Flash | MiniMax | GPT-4o-Audio-Preview |
|---|---|---|---|
| Estabilidade em Chinês | SOTA | Inferior | Inferior |
| WER em Inglês | Mais Baixo | Superior | Superior |
| Similaridade de Timbre Multilíngue | SOTA | Inferior | Inferior |
Esses resultados derivam de avaliações rigorosas, posicionando-o como líder em TTS.
Em demonstrações, o Qwen3-TTS-Flash gera fala expressiva, como descrever um "latte de mel e lavanda" com entusiasmo ou lidar com diálogos em dialetos. Transcrições de vídeo revelam sua capacidade de processar entradas de idiomas mistos, como "Estou muito feliz hoje. Conheço aquela garota da China", entregues em vozes com sotaque. As aplicações incluem sistemas de resposta de voz interativa (IVR), NPCs de jogos e criação de conteúdo, onde a baixa latência dobra a eficiência.
A implementação requer acesso ao modelo via APIs ou demos do Hugging Face. Uma invocação Python de exemplo:
from qwen_tts import QwenTTSFlash
model = QwenTTSFlash.from_pretrained("Qwen/Qwen3-TTS-Flash")
audio = model.synthesize(text="Hello, world!", voice="expressive_english", dialect="sichuanese")
audio.save("output.wav")
Essa simplicidade acelera o desenvolvimento. No entanto, a precisão do dialeto pode variar com entradas raras, necessitando de ajuste fino.
O Qwen3-TTS-Flash transforma o TTS ao equilibrar velocidade, qualidade e diversidade, tornando-o indispensável para sistemas de IA modernos.
Apresentando Qwen3-Omni: A Potência Multimodal Unificada
A introdução do Qwen3-Omni marca um marco na IA multimodal, pois a Qwen integra texto, imagem, áudio e vídeo em um único modelo de ponta a ponta. Essa unificação nativa evita trade-offs de modalidade, permitindo um raciocínio intermodal mais profundo. O modelo processa 119 idiomas para texto, 19 para entrada de fala e 10 para saída de fala, com uma notável latência de 211ms para respostas.
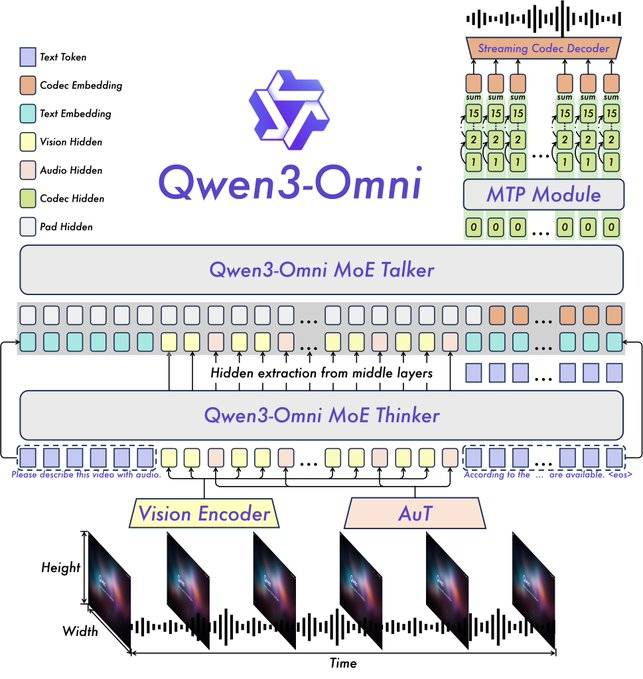
Os principais recursos incluem desempenho SOTA em 22 dos 36 benchmarks de áudio e áudio-visual, prompts de sistema personalizáveis, chamada de ferramenta integrada e um modelo de legendagem de código aberto com baixas taxas de alucinação. A Qwen disponibilizou variantes de código aberto como Qwen3-Omni-30B-A3B-Instruct para seguir instruções e Qwen3-Omni-30B-A3B-Thinking para raciocínio aprimorado.
A arquitetura se baseia na estrutura Thinker-Talker do Qwen2.5-Omni, com atualizações como a substituição do codificador de áudio Whisper por um Audio Transformer (AuT) para melhor representação. O tratamento de fala com múltiplos codebooks enriquece a saída de voz, enquanto o contexto estendido suporta mais de 30 minutos de áudio. Isso permite um raciocínio de modalidade completa, onde entradas de vídeo informam respostas de áudio.
Os benchmarks confirmam seu domínio. Ele alcança SOTA geral em 32 benchmarks, destacando-se na compreensão e geração de áudio. Por exemplo, em tarefas audiovisuais, ele supera modelos como o GPT-4o em latência e precisão. Uma tabela de comparação:
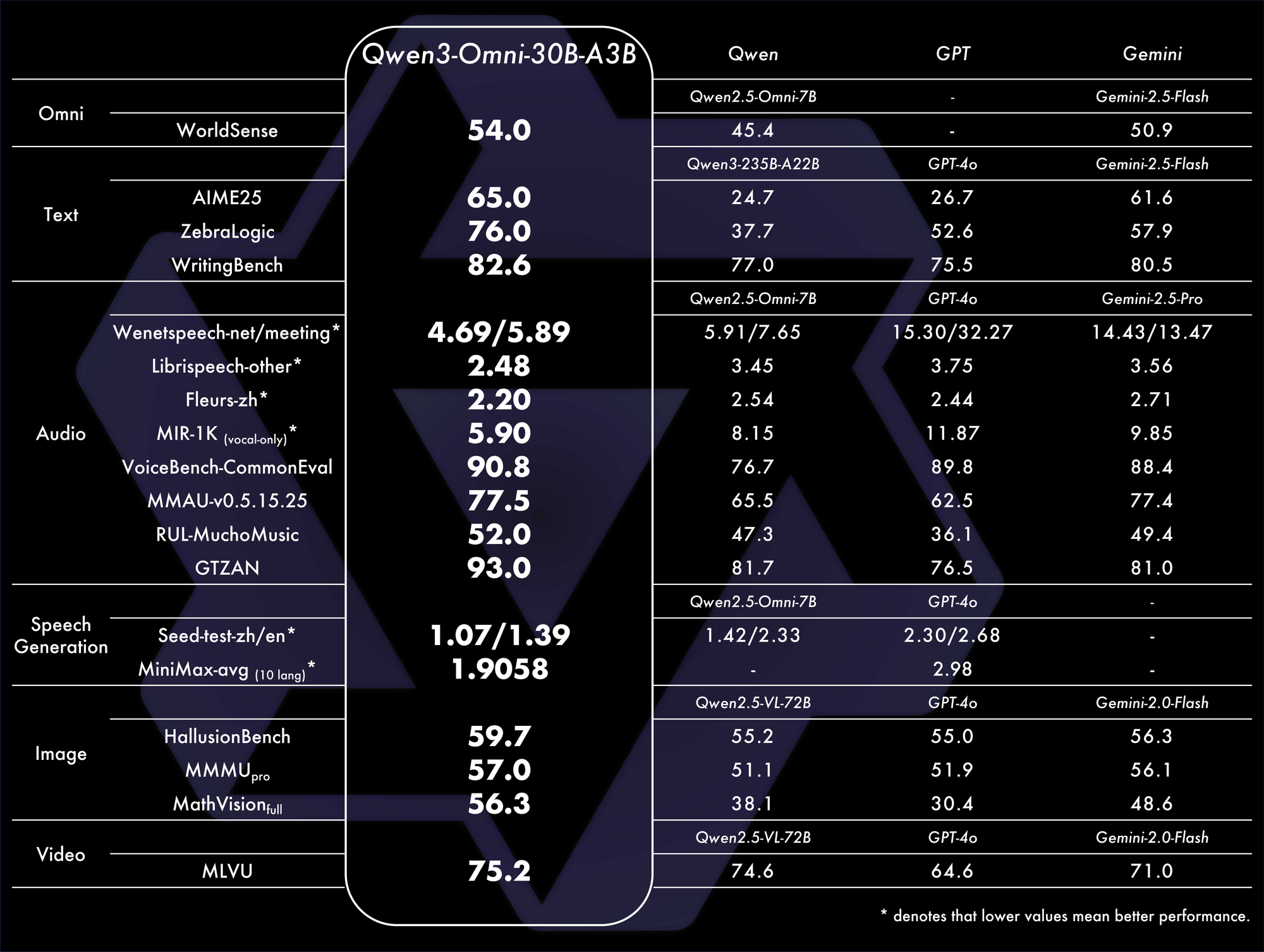
Essas métricas destacam sua eficiência em cenários do mundo real.
As aplicações abrangem chat de voz, análise de vídeo e agentes multimodais. Por exemplo, ele analisa um clipe de vídeo e gera resumos falados, ideal para ferramentas de acessibilidade. Demos no Qwen Chat mostram interações de voz e vídeo, onde os usuários consultam imagens ou áudios verbalmente.
No GitHub, o README o descreve como capaz de gerar fala em tempo real a partir de diversas entradas. A configuração envolve:
from qwen_omni import Qwen3Omni
model = Qwen3Omni.from_pretrained("Qwen/Qwen3-Omni-30B-A3B-Instruct")
response = model.process(inputs={"text": "Describe this", "image": "img.jpg", "audio": "clip.wav"})
print(response.text)
response.audio.save("reply.wav")
Essa abordagem modular facilita a personalização. Os desafios incluem altas demandas computacionais para o processamento de vídeo, mas otimizações como a quantização ajudam.
Apresentando o Qwen3-Omni consolida modalidades, promovendo ecossistemas de IA inovadores.
Sinergias Entre os Novos Modelos da Qwen e Implicações Futuras
Qwen-Image-Edit-2509, Qwen3-TTS-Flash e Qwen3-Omni complementam-se, permitindo fluxos de trabalho de ponta a ponta. Por exemplo, edite uma imagem com Qwen-Image-Edit-2509, descreva-a via Qwen3-Omni e vocalize a saída com Qwen3-TTS-Flash. Essa integração amplifica a utilidade na criação de conteúdo e automação.
Além disso, sua natureza de código aberto convida a aprimoramentos da comunidade. Desenvolvedores usando o Apidog podem testar APIs de forma eficiente, garantindo integrações robustas.
No entanto, surgem considerações éticas, como o uso indevido em deepfakes. A Qwen mitiga isso através de salvaguardas.
Em conclusão, os lançamentos da Qwen redefinem os cenários da IA. Ao avançar as fronteiras técnicas, eles capacitam os usuários a alcançar mais. À medida que a adoção cresce, esses modelos impulsionarão a próxima onda de inovação.