
Introdução ao Framework API Evals da OpenAI
A API Evals da OpenAI, introduzida em 9 de abril de 2025, representa um avanço significativo na avaliação sistemática de Modelos de Linguagem de Grande Escala (LLMs). Embora as capacidades de avaliação já estivessem disponíveis através do painel da OpenAI há algum tempo, a API Evals agora permite que os desenvolvedores definam testes programaticamente, automatizem execuções de avaliação e iterem rapidamente em prompts e implementações de modelos dentro de seus próprios fluxos de trabalho. Essa interface poderosa suporta a avaliação metódica das saídas do modelo, facilitando a tomada de decisões baseadas em evidências ao selecionar modelos ou aprimorar estratégias de engenharia de prompts.
Este tutorial fornece um guia técnico abrangente para implementar e aproveitar a API Evals da OpenAI. Vamos explorar a arquitetura subjacente, os padrões de implementação e técnicas avançadas para criar pipelines de avaliação robustos que possam medir objetivamente o desempenho de suas aplicações LLM.
API Evals da OpenAI: Como Funciona?
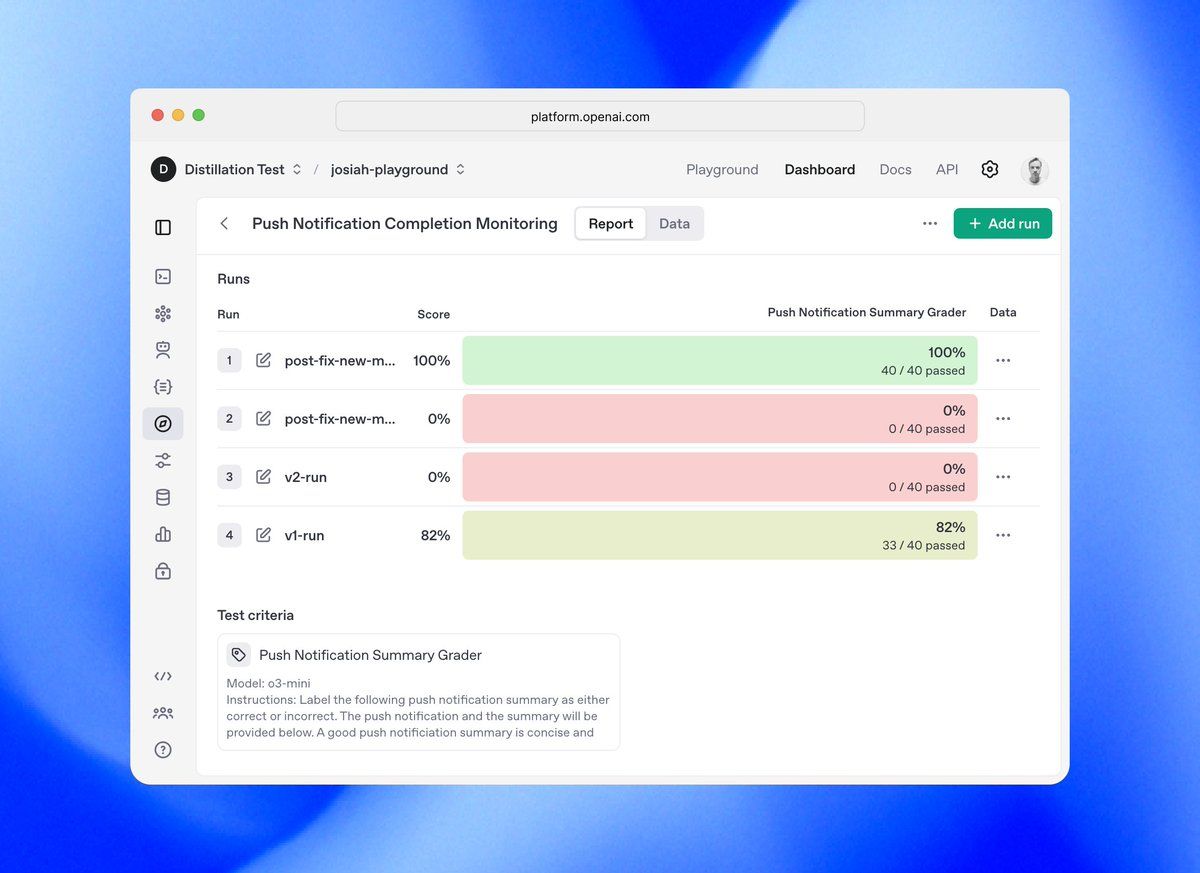
A API Evals da OpenAI segue uma estrutura hierárquica construída em torno de duas abstrações principais:
- Configuração de Avaliação - O contêiner para especificações de avaliação que inclui:
- Definição do esquema da fonte de dados
- Configuração dos critérios de teste
- Metadados para organização e recuperação
2. Execuções de Avaliação - Execuções individuais de avaliação que incluem:
- Referência a uma configuração de avaliação pai
- Exemplos de dados específicos para avaliação
- Respostas de modelos e resultados de avaliação
Essa separação de preocupações permite reutilização em múltiplos cenários de teste, mantendo a consistência nos padrões de avaliação.
O Modelo de Objetos da API Evals
Os objetos principais dentro da API Evals seguem esta relação:
- data_source_config (definição do esquema)
- testing_criteria (métodos de avaliação)
- metadata (descrição, tags, etc.)
- Execução 1 (contra dados específicos)
- Execução 2 (implementação alternativa)
- ...
- Execução N (comparação de versões)
Configurando Seu Ambiente para a API Evals da OpenAI
Ao implementar a API Evals da OpenAI, sua escolha de ferramentas de teste e desenvolvimento pode impactar significativamente sua produtividade e a qualidade dos resultados.

Apidog se destaca como a principal plataforma de API que supera soluções tradicionais como o Postman em vários aspectos, tornando-se a companheira ideal para trabalhar com a tecnicamente complexa API Evals.
Antes de implementar avaliações, você precisará configurar corretamente seu ambiente de desenvolvimento:
import openai
import os
import pydantic
import json
from typing import Dict, List, Any, Optional
# Configure o acesso à API com as permissões apropriadas
os.environ["OPENAI_API_KEY"] = os.environ.get("OPENAI_API_KEY", "sua-chave-api")
# Para ambientes de produção, considere usar um método mais seguro
# como variáveis de ambiente carregadas de um arquivo .env
A biblioteca cliente Python da OpenAI fornece a interface para interagir com a API Evals. Certifique-se de estar usando a versão mais recente que inclui suporte para a API Evals:
pip install --upgrade openai>=1.20.0 # Versão que inclui suporte para a API Evals
Criando Sua Primeira Avaliação com a API Evals da OpenAI
Vamos implementar um fluxo de trabalho completo de avaliação usando a API Evals da OpenAI. Criaremos um sistema de avaliação para uma tarefa de sumarização de texto, demonstrando todo o processo desde o design da avaliação até a análise dos resultados.
Definindo Modelos de Dados para a API Evals da OpenAI
Primeiro, precisamos definir a estrutura dos nossos dados de teste usando modelos Pydantic:
class ArticleSummaryData(pydantic.BaseModel):
"""Estrutura de dados para avaliação de sumarização de artigos."""
article: str
reference_summary: Optional[str] = None # Referência opcional para comparação
class Config:
frozen = True # Garante a imutabilidade para avaliação consistente
Esse modelo define o esquema para nossos dados de avaliação, que será usado pela API Evals para validar entradas e fornecer variáveis de modelo para nossos critérios de teste.
Implementando a Função Alvo para Testes da API Evals
Em seguida, implementaremos a função que gera as saídas que queremos avaliar:
def generate_article_summary(article_text: str) -> Dict[str, Any]:
"""
Gere um resumo conciso de um artigo usando os modelos da OpenAI.
Args:
article_text: O conteúdo do artigo a ser resumido
Returns:
Objeto de resposta da conclusão com o resumo
"""
summarization_prompt = """
Resuma o seguinte artigo de maneira concisa e informativa.
Capture os pontos chave enquanto mantém a precisão e o contexto.
Mantenha o resumo em 1-2 parágrafos.
Artigo:
{{article}}
"""
response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": summarization_prompt.replace("{{article}}", article_text)},
],
temperature=0.3, # Temperatura mais baixa para resumos mais consistentes
max_tokens=300
)
return response.model_dump() # Converte para um dicionário serializável
Configurando Fonte de Dados para a API Evals da OpenAI
A API Evals requer uma configuração de fonte de dados definida que especifica o esquema dos seus dados de avaliação:
data_source_config = {
"type": "custom",
"item_schema": ArticleSummaryData.model_json_schema(),
"include_sample_schema": True, # Inclui o esquema de saída do modelo automaticamente
}
print("Esquema da Fonte de Dados:")
print(json.dumps(data_source_config, indent=2))
Essa configuração informa à API Evals quais campos esperar em seus dados de avaliação e como processá-los.
Implementando Os Critérios de Teste com a API Evals da OpenAI
Agora definiremos como a API Evals deve avaliar as saídas do modelo. Vamos criar uma avaliação abrangente com múltiplos critérios:
# 1. Avaliação de precisão usando julgamento baseado em modelo
accuracy_grader = {
"name": "Avaliação de Precisão do Resumo",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
Você é um avaliador especialista avaliando a precisão dos resumos de artigos.
Avalie se o resumo representa com precisão os principais pontos do artigo original.
Classifique o resumo como um dos:
- "preciso": Contém todas as informações chave, sem erros factuais
- "parcialmente_preciso": Contém a maioria das informações chave, erros ou omissões menores
- "impreciso": Erros significativos, faltando informações críticas ou representação incorreta
Forneça uma explicação detalhada para sua avaliação.
"""
},
{
"role": "user",
"content": """
Artigo Original:
{{item.article}}
Resumo a Avaliar:
{{sample.choices[0].message.content}}
Avaliação:
"""
}
],
"passing_labels": ["preciso", "parcialmente_preciso"],
"labels": ["preciso", "parcialmente_preciso", "impreciso"],
}
# 2. Avaliação de concisão
conciseness_grader = {
"name": "Avaliação de Concisão do Resumo",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
Você é um avaliador especialista avaliando a concisão dos resumos de artigos.
Avalie se o resumo expressa informações de forma eficiente, sem detalhes desnecessários.
Classifique o resumo como um dos:
- "conciso": Comprimento perfeito, sem informações desnecessárias
- "aceitável": Ligeiramente prolixo, mas geralmente apropriado
- "prolixo": Excessivamente longo ou contendo detalhes desnecessários
Forneça uma explicação detalhada para sua avaliação.
"""
},
{
"role": "user",
"content": """
Resumo a Avaliar:
{{sample.choices[0].message.content}}
Avaliação:
"""
}
],
"passing_labels": ["conciso", "aceitável"],
"labels": ["conciso", "aceitável", "prolixo"],
}
# 3. Se resumos de referência estão disponíveis, adicione uma comparação de referência
reference_comparison_grader = {
"name": "Avaliação de Comparação de Referência",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
Compare o resumo gerado com o resumo de referência.
Avalie quão bem o resumo gerado captura as mesmas informações chave que a referência.
Classifique a comparação como um dos:
- "excelente": Equivalente ou melhor que a referência
- "bom": Captura a maioria das informações importantes da referência
- "inadequado": Faltando informações significativas presentes na referência
Forneça uma explicação detalhada para sua avaliação.
"""
},
{
"role": "user",
"content": """
Resumo de Referência:
{{item.reference_summary}}
Resumo Gerado:
{{sample.choices[0].message.content}}
Avaliação:
"""
}
],
"passing_labels": ["excelente", "bom"],
"labels": ["excelente", "bom", "inadequado"],
"condition": "item.reference_summary != null" # Apenas aplica quando a referência existe
}
Criando a Configuração de Avaliação com a API Evals da OpenAI
Com nosso esquema de dados e critérios de teste definidos, agora podemos criar a configuração de avaliação:
eval_create_result = openai.evals.create(
name="Avaliação da Qualidade da Sumarização de Artigos",
metadata={
"description": "Avaliação abrangente da qualidade da sumarização de artigos em múltiplas dimensões",
"version": "1.0",
"created_by": "Sua Organização",
"tags": ["sumarização", "qualidade-de-conteúdo", "precisão"]
},
data_source_config=data_source_config,
testing_criteria=[
accuracy_grader,
conciseness_grader,
reference_comparison_grader
],
)
eval_id = eval_create_result.id
print(f"Avaliação criada com ID: {eval_id}")
print(f"Visualizar no painel: {eval_create_result.dashboard_url}")
Executando Execuções de Avaliação com a API Evals da OpenAI
Preparando Dados de Avaliação
Agora vamos preparar dados de teste para nossa avaliação:
test_articles = [
{
"article": """
A Agência Espacial Europeia (ESA) anunciou hoje o lançamento bem-sucedido de seu novo satélite de observação da Terra, Sentinel-6.
Este satélite monitorará os níveis do mar com precisão sem precedentes, fornecendo dados cruciais sobre os impactos das mudanças climáticas.
O Sentinel-6 apresenta tecnologia avançada de altimetria por radar capaz de medir mudanças no nível do mar com precisão de milímetros.
Cientistas esperam que esses dados melhorem significativamente os modelos climáticos e as estratégias de planejamento costeiro.
O satélite, lançado da Base Aérea de Vandenberg na Califórnia, faz parte do programa Copernicus, uma colaboração
entre a ESA, NASA, NOAA e outros parceiros internacionais.
""",
"reference_summary": """
A ESA lançou com sucesso o satélite de observação da Terra Sentinel-6, projetado para monitorar os níveis do mar
com precisão de milímetros usando altimetria por radar avançada. Esta missão, parte do programa internacional Copernicus,
fornecerá dados cruciais para a pesquisa sobre mudanças climáticas e planejamento costeiro.
"""
},
# Artigos de teste adicionais seriam adicionados aqui
]
# Processar nossos dados de teste para avaliação
run_data = []
for item in test_articles:
# Gere o resumo usando nossa função
article_data = ArticleSummaryData(**item)
result = generate_article_summary(article_data.article)
# Prepare a entrada de dados da execução
run_data.append({
"item": article_data.model_dump(),
"sample": result
})
Criando e Executando uma Execução de Avaliação
Com nossos dados preparados, podemos criar uma execução de avaliação:
eval_run_result = openai.evals.runs.create(
eval_id=eval_id,
name="execucao-baseline-sumarizacao",
metadata={
"model": "gpt-4o",
"temperature": 0.3,
"max_tokens": 300
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": run_data,
}
},
)
print(f"Execução de Avaliação criada: {eval_run_result.id}")
print(f"Visualizar resultados detalhados: {eval_run_result.report_url}")
Recuperando e Analisando Resultados de Avaliação da API Evals
Uma vez que uma execução de avaliação é concluída, você pode recuperar resultados detalhados:
def analyze_run_results(run_id: str) -> Dict[str, Any]:
"""
Recupere e analise os resultados de uma execução de avaliação.
Args:
run_id: O ID da execução de avaliação
Returns:
Dicionário contendo os resultados analisados
"""
# Recupere os detalhes da execução
run_details = openai.evals.runs.retrieve(run_id)
# Extraia os resultados
results = {}
# Calcule a taxa de aprovação geral
if run_details.results and "pass_rate" in run_details.results:
results["overall_pass_rate"] = run_details.results["pass_rate"]
# Extraia métricas específicas de critério
if run_details.criteria_results:
results["criteria_performance"] = {}
for criterion, data in run_details.criteria_results.items():
results["criteria_performance"][criterion] = {
"pass_rate": data.get("pass_rate", 0),
"sample_count": data.get("total_count", 0)
}
# Extraia falhas para análise posterior
if run_details.raw_results:
results["failure_analysis"] = [
{
"item": item.get("item", {}),
"result": item.get("result", {}),
"criteria_results": item.get("criteria_results", {})
}
for item in run_details.raw_results
if not item.get("passed", True)
]
return results
# Analise nossa execução
results_analysis = analyze_run_results(eval_run_result.id)
print(json.dumps(results_analysis, indent=2))
Técnicas Avançadas da API Evals da OpenAI
Implementando Testes A/B com a API Evals
A API Evals se destaca em comparar diferentes implementações. Aqui está como configurar um teste A/B entre duas configurações de modelo:
def generate_summary_alternative_model(article_text: str) -> Dict[str, Any]:
"""Implementação alternativa usando uma configuração de modelo diferente."""
response = openai.chat.completions.create(
model="gpt-4o-mini", # Usando um modelo diferente
messages=[
{"role": "system", "content": "Resuma este artigo de forma concisa."},
{"role": "user", "content": article_text},
],
temperature=0.7, # Temperatura mais alta para comparação
max_tokens=250
)
return response.model_dump()
# Processar nossos dados de teste com o modelo alternativo
alternative_run_data = []
for item in test_articles:
article_data = ArticleSummaryData(**item)
result = generate_summary_alternative_model(article_data.article)
alternative_run_data.append({
"item": article_data.model_dump(),
"sample": result
})
# Crie a execução de avaliação alternativa
alternative_eval_run = openai.evals.runs.create(
eval_id=eval_id,
name="execucao-modelo-alternativo",
metadata={
"model": "gpt-4o-mini",
"temperature": 0.7,
"max_tokens": 250
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": alternative_run_data,
}
},
)
# Compare os resultados programaticamente
def compare_evaluation_runs(run_id_1: str, run_id_2: str) -> Dict[str, Any]:
"""
Compare resultados de duas execuções de avaliação.
Args:
run_id_1: ID da primeira execução de avaliação
run_id_2: ID da segunda execução de avaliação
Returns:
Dicionário contendo a análise comparativa
"""
run_1_results = analyze_run_results(run_id_1)
run_2_results = analyze_run_results(run_id_2)
comparison = {
"overall_comparison": {
"run_1_pass_rate": run_1_results.get("overall_pass_rate", 0),
"run_2_pass_rate": run_2_results.get("overall_pass_rate", 0),
"difference": run_1_results.get("overall_pass_rate", 0) - run_2_results.get("overall_pass_rate", 0)
},
"criteria_comparison": {}
}
# Compare cada critério
all_criteria = set(run_1_results.get("criteria_performance", {}).keys()) | set(run_2_results.get("criteria_performance", {}).keys())
for criterion in all_criteria:
run_1_criterion = run_1_results.get("criteria_performance", {}).get(criterion, {})
run_2_criterion = run_2_results.get("criteria_performance", {}).get(criterion, {})
comparison["criteria_comparison"][criterion] = {
"run_1_pass_rate": run_1_criterion.get("pass_rate", 0),
"run_2_pass_rate": run_2_criterion.get("pass_rate", 0),
"difference": run_1_criterion.get("pass_rate", 0) - run_2_criterion.get("pass_rate", 0)
}
return comparison
# Compare nossas duas execuções
comparison_results = compare_evaluation_runs(eval_run_result.id, alternative_eval_run.id)
print(json.dumps(comparison_results, indent=2))
Detectando Regressões com a API Evals da OpenAI
Uma das aplicações mais valiosas da API Evals é a detecção de regressões ao atualizar prompts:
def create_regression_detection_pipeline(eval_id: str, baseline_run_id: str) -> None:
"""
Crie um pipeline de detecção de regressão que compara um novo prompt
contra uma execução de baseline.
Args:
eval_id: O ID da configuração de avaliação
baseline_run_id: O ID da execução de baseline para comparar
"""
def test_prompt_for_regression(new_prompt: str, threshold: float = 0.95) -> Dict[str, Any]:
"""
Testa se um novo prompt causa regressão em comparação com a baseline.
Args:
new_prompt: O novo prompt a ser testado
threshold: Relação de desempenho mínima aceitável (novo/baseline)
Returns:
Dicionário contendo a análise de regressão
"""
# Defina a função usando o novo prompt
def generate_summary_new_prompt(article_text: str) -> Dict[str, Any]:
response = openai.chat.completions.create(
model="gpt-4o", # Mesmo modelo da baseline
messages=[
{"role": "system", "content": new_prompt},
{"role": "user", "content": article_text},
],
temperature=0.3,
max_tokens=300
)
return response.model_dump()
# Processar dados de teste com o novo prompt
new_prompt_run_data = []
for item in test_articles:
article_data = ArticleSummaryData(**item)
result = generate_summary_new_prompt(article_data.article)
new_prompt_run_data.append({
"item": article_data.model_dump(),
"sample": result
})
# Crie uma execução de avaliação para o novo prompt
new_prompt_run = openai.evals.runs.create(
eval_id=eval_id,
name=f"teste-regressao-{int(time.time())}",
metadata={
"prompt": new_prompt,
"test_type": "regressao"
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": new_prompt_run_data,
}
},
)
# Aguarde a conclusão (em produção, você pode querer implementar o gerenciamento assíncrono)
# Esta é uma implementação simplificada
time.sleep(10) # Aguarde a avaliação ser concluída
# Compare com a baseline
comparison = compare_evaluation_runs(baseline_run_id, new_prompt_run.id)
# Determine se há uma regressão
baseline_pass_rate = comparison["overall_comparison"]["run_1_pass_rate"]
new_pass_rate = comparison["overall_comparison"]["run_2_pass_rate"]
regression_detected = (new_pass_rate / baseline_pass_rate if baseline_pass_rate > 0 else 0) < threshold
return {
"regression_detected": regression_detected,
"baseline_pass_rate": baseline_pass_rate,
"new_pass_rate": new_pass_rate,
"performance_ratio": new_pass_rate / baseline_pass_rate if baseline_pass_rate > 0 else 0,
"threshold": threshold,
"detailed_comparison": comparison,
"report_url": new_prompt_run.report_url
}
return test_prompt_for_regression
# Crie um pipeline de detecção de regressão
regression_detector = create_regression_detection_pipeline(eval_id, eval_run_result.id)
# Teste um prompt potencialmente problemático
problematic_prompt = """
Resuma este artigo em detalhes excessivos, garantindo que cada ponto menor seja incluído.
O resumo deve ser abrangente e não deixar nada de fora.
"""
regression_analysis = regression_detector(problematic_prompt)
print(json.dumps(regression_analysis, indent=2))
Trabalhando com Métricas Personalizadas na API Evals da OpenAI
Para necessidades de avaliação especializadas, você pode implementar métricas personalizadas:
# Exemplo de uma avaliação de pontuação numérica personalizada
numeric_score_grader = {
"name": "Pontuação de Qualidade do Resumo",
"type": "score_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
Você é um avaliador especialista avaliando a qualidade dos resumos de artigos.
Avalie a qualidade geral do resumo em uma escala de 1,0 a 10,0, onde:
- 1,0-3,9: Qualidade ruim, problemas significativos
- 4,0-6,9: Qualidade aceitável com espaço para melhoria
- 7,0-8,9: Boa qualidade, atende às expectativas
- 9,0-10,0: Qualidade excelente, excede as expectativas
Forneça uma pontuação numérica específica e uma justificativa detalhada.
"""
},
{
"role": "user",
"content": """
Artigo Original:
{{item.article}}
Resumo a Avaliar:
{{sample.choices[0].message.content}}
Pontuação (1,0-10,0):
"""
}
],
"passing_threshold": 7.0, # Pontuação mínima para aprovação
"min_score": 1.0,
"max_score": 10.0
}
# Adicione isso aos seus critérios de teste ao criar uma avaliação
Integrando a API Evals da OpenAI nos Fluxos de Trabalho de Desenvolvimento
Integração CI/CD com a API Evals
Integrar a API Evals em seu pipeline CI/CD garante qualidade consistente:
def ci_cd_evaluation_workflow(
prompt_file_path: str,
baseline_eval_id: str,
baseline_run_id: str,
threshold: float = 0.95
) -> bool:
"""
Integração CI/CD para avaliar prompts de modelo antes da implantação.
Args:
prompt_file_path: Caminho para o arquivo de prompt sendo atualizado
baseline_eval_id: ID da configuração de avaliação de baseline
baseline_run_id: ID da execução de baseline para comparar
threshold: Relação mínima aceitável de desempenho
Returns:
Booleano indicando se o novo prompt passou na avaliação
"""
# Carregue o novo prompt do controle de versão
with open(prompt_file_path, 'r') as f:
new_prompt = f.read()
# Crie um detector de regressão usando o baseline
regression_detector = create_regression_detection_pipeline(baseline_eval_id, baseline_run_id)
# Teste o novo prompt
regression_analysis = regression_detector(new_prompt)
# Determine se o prompt é seguro para implantar
is_approved = not regression_analysis["regression_detected"]
# Registre os resultados da avaliação
print(f"Resultados da Avaliação para {prompt_file_path}")
print(f"Taxa de Aprovação da Baseline: {regression_analysis['baseline_pass_rate']:.2f}")
print(f"Taxa de Aprovação do Novo Prompt: {regression_analysis['new_pass_rate']:.2f}")
print(f"Relação de Desempenho: {regression_analysis['performance_ratio']:.2f}")
print(f"Decisão de Implantação: {'APROVADO' if is_approved else 'REJEITADO'}")
print(f"Relatório Detalhado: {regression_analysis['report_url']}")
return is_approved
Monitoramento Agendado com a API Evals da OpenAI
Avaliações regulares ajudam a detectar desvios ou degradação do modelo:
def schedule_periodic_evaluation(
eval_id: str,
baseline_run_id: str,
interval_hours: int = 24
) -> None:
"""
Agende avaliações periódicas para monitorar mudanças de desempenho.
Args:
eval_id: ID da configuração de avaliação
baseline_run_id: ID da execução de baseline para comparar
interval_hours: Frequência das avaliações em horas
"""
# Em um sistema de produção, você usaria um agendador de tarefas como Airflow,
# Celery ou soluções nativas da nuvem. Este é um exemplo simplificado.
def perform_periodic_evaluation():
while True:
try:
# Execute a configuração de produção atual contra a avaliação
print(f"Executando avaliação agendada em {datetime.now()}")
# Implemente sua lógica de avaliação aqui, semelhante ao teste de regressão
# Durma até a próxima execução agendada
time.sleep(interval_hours * 60 * 60)
except Exception as e:
print(f"Erro na avaliação agendada: {e}")
# Implemente manuseio de erros e alertas
# Em uma implementação real, você gerenciaria esta thread adequadamente
# ou usaria um sistema de agendamento dedicado
import threading
evaluation_thread = threading.Thread(target=perform_periodic_evaluation)
evaluation_thread.daemon = True
evaluation_thread.start()
Padrões de Uso Avançados da API Evals da OpenAI
Pipelines de Avaliação em Múltiplas Etapas
Para aplicações complexas, implemente pipelines de avaliação em múltiplas etapas:
def create_multi_stage_evaluation_pipeline(
article_data: List[Dict[str, str]]
) -> Dict[str, Any]:
"""
Crie um pipeline de avaliação em múltiplas etapas para geração de conteúdo.
Args:
article_data: Lista de artigos para avaliação
Returns:
Dicionário contendo os resultados da avaliação de cada etapa
"""
# Etapa 1: Avaliação de geração de conteúdo
generation_eval_id = create_content_generation_eval()
generation_run_id = run_content_generation_eval(generation_eval_id, article_data)
# Etapa 2: Avaliação de precisão factual
accuracy_eval_id = create_factual_accuracy_eval()
accuracy_run_id = run_factual_accuracy_eval(accuracy_eval_id, article_data)
# Etapa 3: Avaliação de tom e estilo
tone_eval_id = create_tone_style_eval()
tone_run_id = run_tone_style_eval(tone_eval_id, article_data)
# Agregue resultados de todas as etapas
results = {
"generation": analyze_run_results(generation_run_id),
"accuracy": analyze_run_results(accuracy_run_id),
"tone": analyze_run_results(tone_run_id)
}
# Calcule a pontuação composta
composite_score = (
results["generation"].get("overall_pass_rate", 0) * 0.4 +
results["accuracy"].get("overall_pass_rate", 0) * 0.4 +
results["tone"].get("overall_pass_rate", 0) * 0.2
)
results["composite_score"] = composite_score
return results
Conclusão: Dominando a API Evals da OpenAI
A API Evals da OpenAI representa um avanço significativo na avaliação sistemática de LLM, fornecendo aos desenvolvedores ferramentas poderosas para avaliar objetivamente o desempenho do modelo e tomar decisões baseadas em dados.
À medida que os LLMs se tornam cada vez mais integrados em aplicações críticas, a importância da avaliação sistemática cresce de forma correspondente. A API Evals da OpenAI fornece a infraestrutura necessária para implementar essas práticas de avaliação em escala, garantindo que seus sistemas de IA permaneçam robustos, confiáveis e alinhados com suas expectativas ao longo do tempo.
Mas por que parar por aqui? Integrar o Apidog ao seu fluxo de trabalho da API Evals da OpenAI oferece vantagens significativas:
- Teste Simplificado: Os modelos de solicitação e as capacidades de teste automatizado do Apidog reduzem o tempo de desenvolvimento para implementar pipelines de avaliação
- Documentação Aprimorada: A geração automática de documentação da API garante que seus critérios de avaliação e implementações estejam bem documentados
- Colaboração em Equipe: Espaços de trabalho compartilhados facilitam padrões de avaliação consistentes entre as equipes de desenvolvimento
- Integração CI/CD: Capacidades de linha de comando permitem integração com pipelines CI/CD existentes para testes automatizados
- Análise Visual: Ferramentas de visualização integradas ajudam a interpretar rapidamente resultados de avaliação complexos
