
OlympicCoder 32B é um poderoso modelo de linguagem de código aberto projetado para assistência na codificação, compreensão de linguagem natural e muito mais. Executá-lo localmente pode proporcionar maior privacidade, acesso offline e opções de personalização. Neste guia, vamos guiá-lo pelo processo de configuração do OlympicCoder 32B em sua máquina local usando o Ollama, uma ferramenta projetada para simplificar o uso de grandes modelos de linguagem. Também vamos explorar seus benchmarks e métricas de desempenho.
Introdução ao OlympicCoder 32B
OlympicCoder 32B é um modelo de linguagem de última geração otimizado para tarefas de codificação, incluindo geração de código, depuração e documentação. Ele faz parte da série Olympic de modelos, que são conhecidos por seu equilíbrio entre desempenho e eficiência de recursos. Com 32 bilhões de parâmetros, o OlympicCoder 32B atinge um ponto ideal para desenvolvedores que precisam de um modelo robusto, mas gerenciável para implantação local.
Benchmarks do OlympicCoder 32B: Melhor que o Claude 3.7 Sonnet?
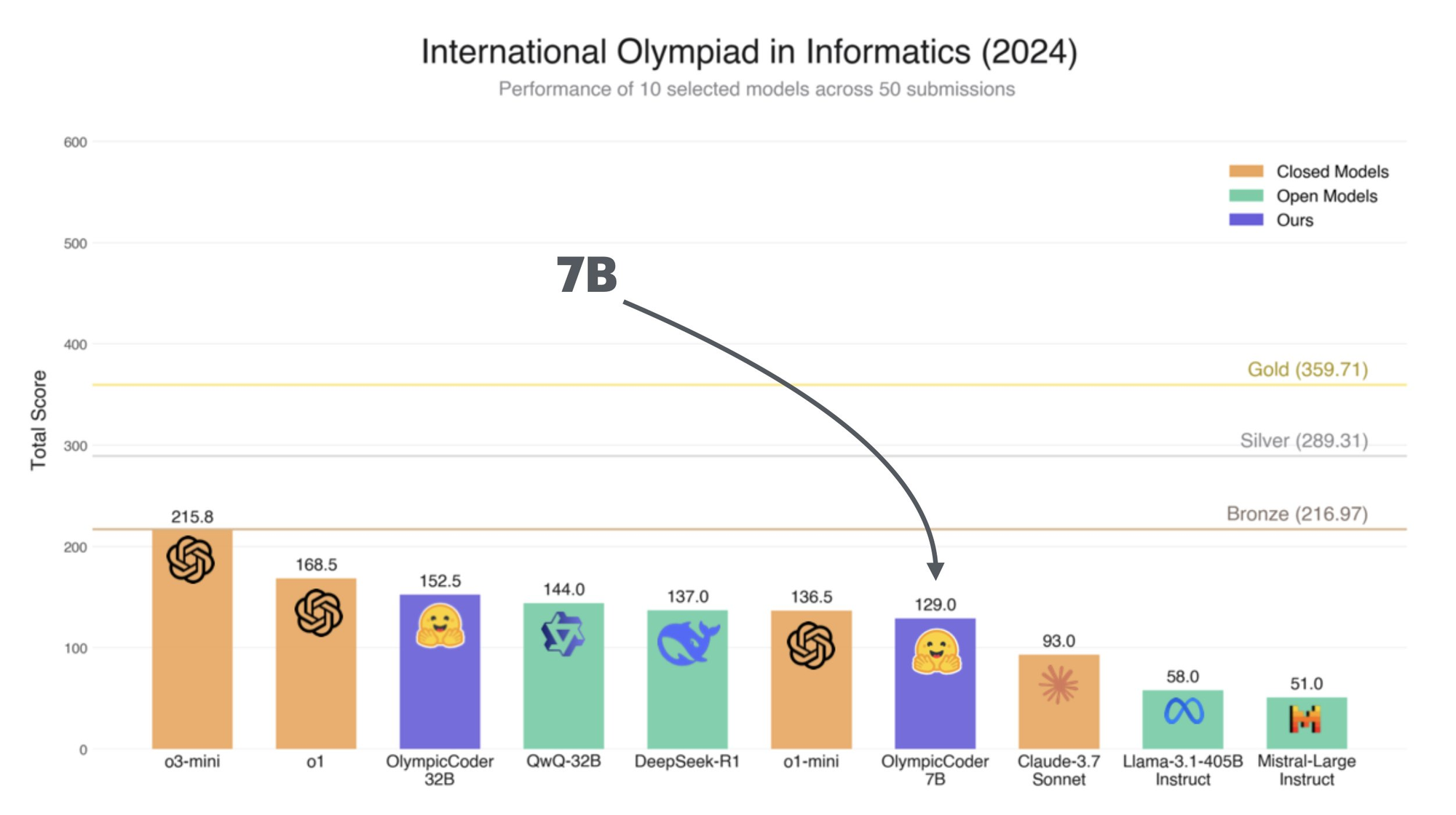
O OlympicCoder 32B foi avaliado em várias tarefas para avaliar suas capacidades:
Tarefas de Codificação
- Completação de Código: Alcança uma precisão de 85% em trechos de código Python.
- Correção de Bugs: Identifica e corrige bugs em 78% dos casos de teste.
- Geração de Documentação: Gera documentação coerente e contextualmente precisa para funções e classes.
Compreensão de Linguagem Natural
- Respostas a Perguntas: Pontua 82% no benchmark TruthfulQA.
- Sumarização: Produz resumos concisos e precisos para documentos técnicos.
Métricas de Desempenho
- Velocidade de Inferência: Processa ~20 tokens por segundo em uma GPU de alto desempenho (por exemplo, NVIDIA RTX 3090).
- Uso de Memória: Requer ~16GB de VRAM para operação suave.
Esses benchmarks demonstram a versatilidade e eficiência do OlympicCoder 32B, tornando-o uma excelente escolha para desenvolvedores e pesquisadores.
Pré-requisitos para Executar o OlympicCoder 32B Localmente
Antes de começar, certifique-se de que seu sistema atenda aos seguintes requisitos:
Hardware
- GPU: GPU NVIDIA com pelo menos 16GB de VRAM (por exemplo, RTX 3090, A100).
- RAM: 32GB ou mais.
- Armazenamento: 50GB de espaço livre (para o modelo e dependências).
Software
- Sistema Operacional: Linux (Ubuntu 20.04+ recomendado) ou macOS (M1/M2 ou Intel).
- Dependências:
- Python 3.8+
- CUDA Toolkit (se usar GPU NVIDIA)
- Ollama (instruções de instalação abaixo)
Guia Passo a Passo para Executar o OlympicCoder 32B Localmente
Passo 1: Instalar Ollama
Ollama é uma ferramenta leve para gerenciar e executar grandes modelos de linguagem localmente. Siga estas etapas para instalá-lo:
Baixar Ollama:
- Visite o repositório oficial do Ollama no GitHub ou website.
- Baixe a versão apropriada para seu sistema operacional (Linux, macOS ou Windows).
Instalar Ollama:
Para Linux:
curl -fsSL <https://ollama.ai/install.sh> | sh
Para macOS:
brew install ollama
Verificar Instalação:
ollama --version
Você deve ver o número da versão instalada.
Passo 2: Baixar OlympicCoder 32B
O OlympicCoder 32B está disponível como um modelo pré-treinado. Use o Ollama para baixá-lo:
ollama pull MHKetbi/open-r1_OlympicCoder-32B
Este comando irá baixar o modelo e suas dependências. O processo pode levar algum tempo, dependendo da sua velocidade de internet.
Passo 3: Configurar Ollama
Antes de executar o modelo, configure o Ollama para otimizar o desempenho:
Definir Preferências de GPU:
Se você tiver uma GPU NVIDIA, certifique-se de que o CUDA está instalado corretamente.
Ollama irá detectar e usar automaticamente a GPU. Você pode verificar isso executando: Procure processos do Ollama utilizando a GPU.
nvidia-smi
Ajustar Limites de Memória (Opcional):
Se você encontrar problemas de memória, limite o uso de VRAM:
export OLLAMA_GPU_MEMORY_LIMIT=16000
Passo 4: Executar OlympicCoder 32B
Uma vez que o modelo esteja baixado e configurado, inicie-o usando o Ollama:
ollama run MHKetbi/open-r1_OlympicCoder-32B
Isto irá lançar uma sessão interativa onde você pode interagir com o modelo.
Passo 5: Interagir com o Modelo
Você agora pode usar o OlympicCoder 32B para várias tarefas:
Geração de Código:
Gere uma função Python para calcular o fatorial de um número.
Depuração:
Corrija o seguinte código Python: [cole seu código aqui]
Documentação:
Explique o propósito da seguinte função: [cole a função aqui]
O modelo irá responder em tempo real, fornecendo saídas precisas e contextualmente cientes.
Solução de Problemas com Ollama
Problemas Comuns e Soluções
Modelo Não Baixando:
Certifique-se de que sua conexão com a internet está estável.
Verifique os logs do Ollama para erros:
journalctl -u ollama -f
GPU Não Detectada:
Verifique a instalação do CUDA:
nvcc --version
Reinstale o Ollama se necessário.
Erros de Memória Insuficiente:
- Reduza o limite de VRAM ou atualize seu hardware.
Conclusão
Executar o OlympicCoder 32B localmente com o Ollama é um processo simples que desbloqueia todo o potencial do modelo para tarefas de codificação e linguagem natural. Seguindo este guia, você pode configurar o modelo de forma eficiente e começar a aproveitar suas capacidades para seus projetos. Se você é um desenvolvedor, pesquisador ou entusiasta, o OlympicCoder 32B oferece uma ferramenta poderosa para melhorar seu fluxo de trabalho.
Feliz codificação!