Desenvolvedores buscam constantemente modelos de linguagem eficientes e de alto desempenho para construir aplicações inteligentes. A API MiniMax M2.1 se destaca como uma opção robusta, particularmente para fluxos de trabalho agenticos e tarefas de codificação complexas.
botão
Você começa entendendo o modelo em si. Em seguida, explora os métodos de acesso. Finalmente, implementa integrações práticas.
O que é MiniMax M2.1 e por que usar sua API?
MiniMax M2.1 representa o mais recente avanço da MiniMax AI, lançado como um modelo de código aberto otimizado para capacidades agenticas. Desenvolvedores o utilizam para criar aplicações autônomas que lidam com desenvolvimento de software multilíngue, planejamento multi-etapas e uso de ferramentas com robustez excepcional.
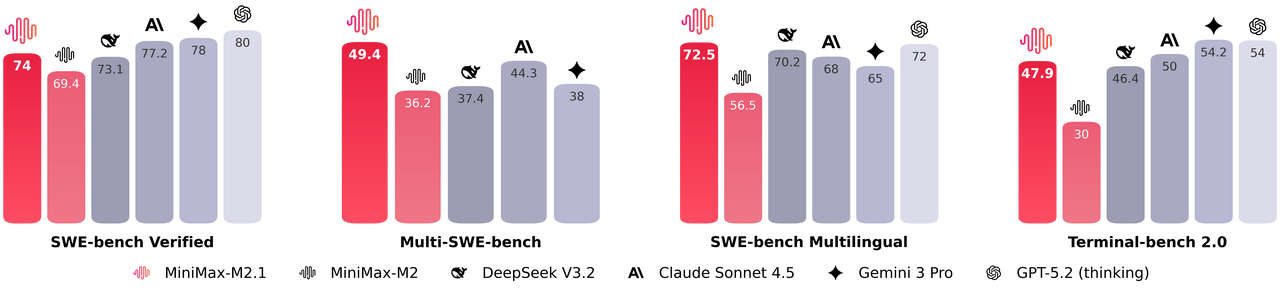
Além disso, o MiniMax M2.1 ativa um conjunto compacto de parâmetros durante a inferência, entregando desempenho quase de ponta enquanto mantém baixa latência. Ele se destaca em benchmarks como SWE-bench Verified e VIBE, frequentemente igualando ou superando modelos proprietários em estabilidade de codificação e seguimento de instruções. Adicionalmente, o modelo suporta demonstrações avançadas, incluindo a geração de animações 3D interativas, aplicativos móveis nativos e painéis de dados em tempo real.
Você escolhe o MiniMax M2.1 quando precisa de transparência e controlabilidade. Além disso, seus pesos de código aberto permitem a implantação local via Hugging Face, mas a API hospedada oferece acesso imediato sem gerenciamento de infraestrutura.
MiniMax M2.1 vs GLM-4.7: Qual Modelo Atende às Suas Necessidades?
Desenvolvedores frequentemente comparam o MiniMax M2.1 ao GLM-4.7, outro concorrente líder de peso aberto da Z.ai. Ambos os modelos visam codificação e raciocínio, mas diferem em arquitetura, eficiência e custo.
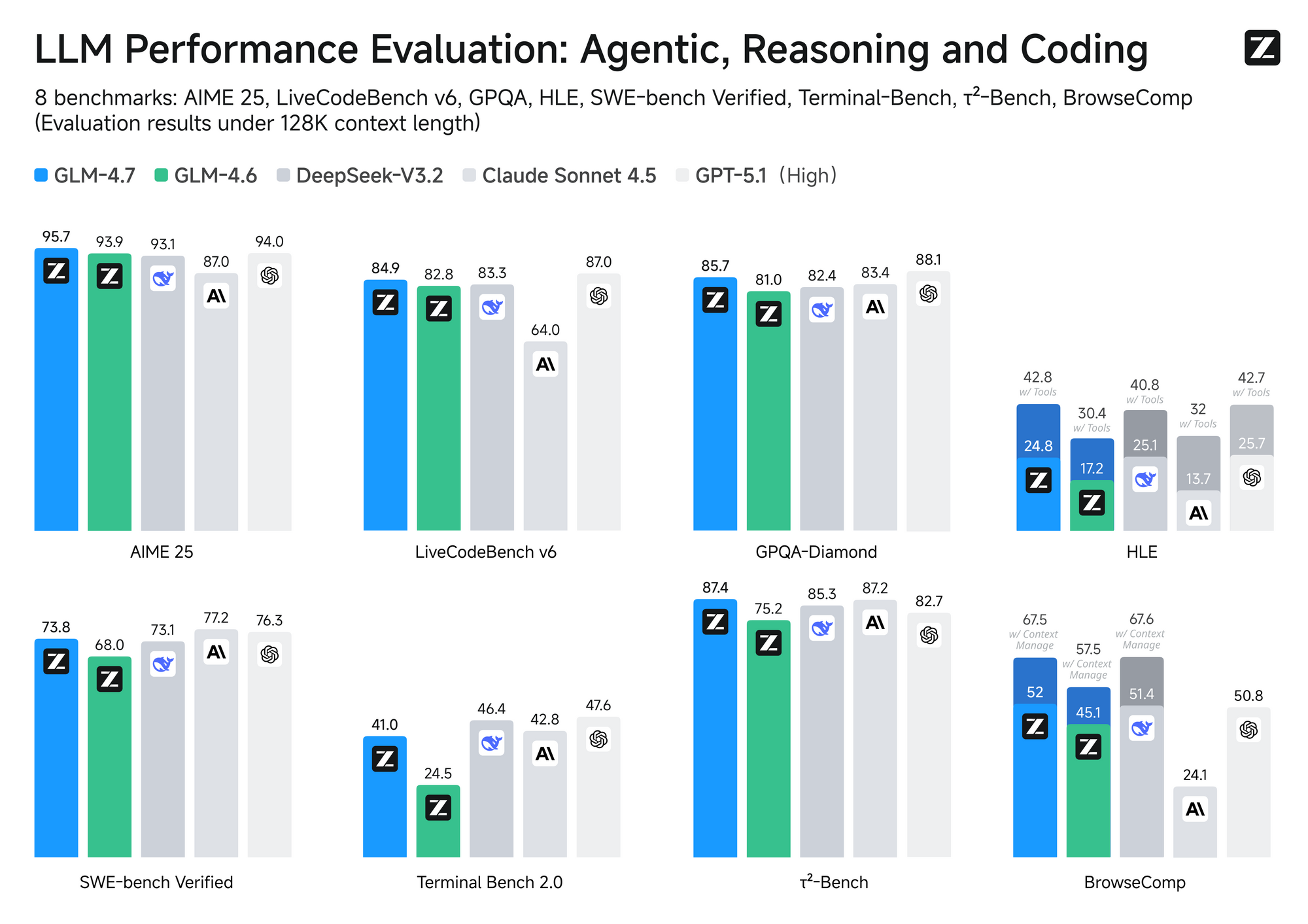
O MiniMax M2.1 emprega um design de Mistura de Especialistas (MoE) com ativação seletiva — tipicamente cerca de 10B de parâmetros ativos de um pool maior. Esta abordagem garante inferência rápida e custos operacionais mais baixos. Em contraste, o GLM-4.7 utiliza um MoE completo com 358B de parâmetros, suportando uma enorme janela de contexto de 200K tokens e recursos nativos como controle de pensamento em nível de turno.
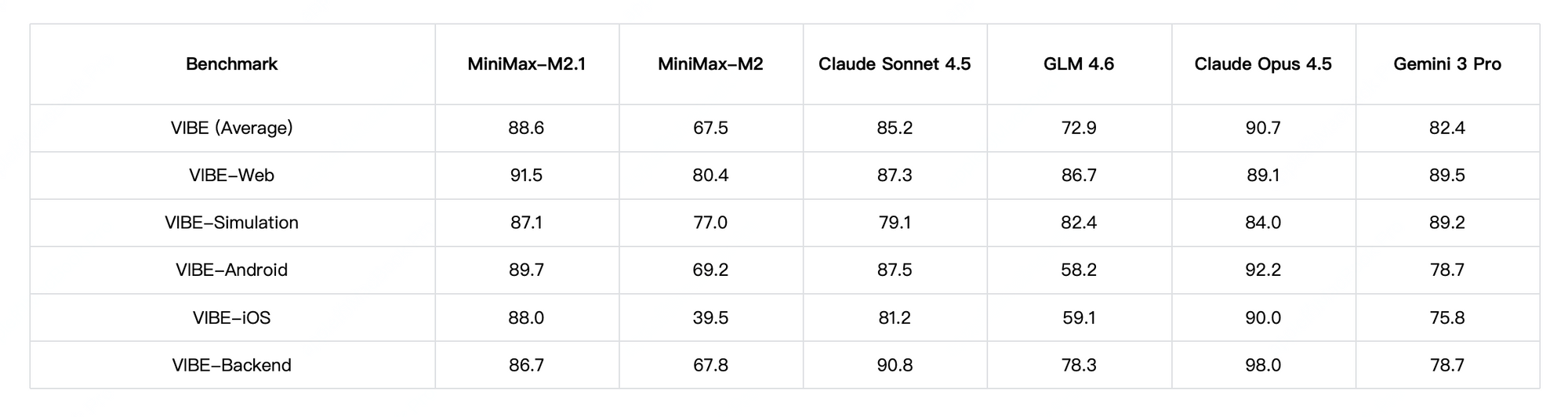
Em termos de desempenho, o MiniMax M2.1 brilha em tarefas agenticas e planejamento de longo prazo, alcançando altas pontuações no VIBE (média de 88,6) e demonstrando estabilidade superior no uso de ferramentas. Testes da comunidade mostram que ele supera as versões anteriores do GLM em codificação criativa e autonomia multi-ferramenta. No entanto, o GLM-4.7 se destaca em benchmarks de raciocínio puro e saídas estruturadas, com fortes resultados no SWE-bench (73,8%).
O preço desempenha um papel fundamental. Modelos MiniMax, incluindo predecessores como o M2, geralmente cobram cerca de US$ 0,30–US$ 0,315 por milhão de tokens de entrada e US$ 1,20–US$ 1,26 por milhão de tokens de saída na plataforma oficial. O GLM-4.7, disponível via Z.ai ou provedores como OpenRouter, começa em aproximadamente US$ 0,44–US$ 0,60 de entrada e US$ 1,74–US$ 2,20 de saída por milhão de tokens — frequentemente mais alto, embora as assinaturas reduzam as taxas efetivas.
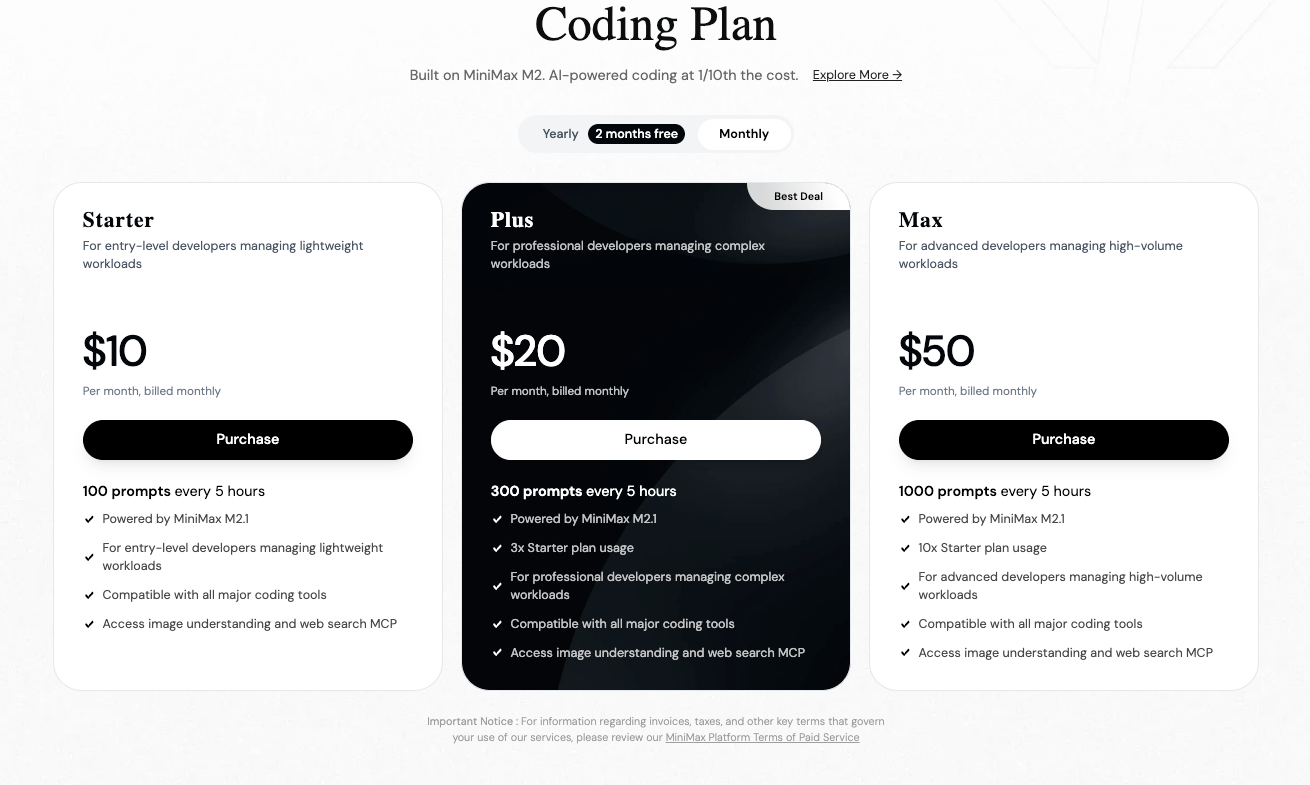
Consequentemente, você seleciona o MiniMax M2.1 para aplicações agenticas de alta velocidade e custo-eficientes. Alternativamente, você opta pelo GLM-4.7 quando o contexto estendido ou modos de pensamento precisos se mostram essenciais.
Como você se registra na Plataforma API MiniMax?
Você inicia o acesso criando uma conta na Plataforma Aberta MiniMax. Cadastre-se usando seu e-mail ou método preferencial.
Após a verificação, você faz login e prossegue para o painel. Aqui, você gerencia chaves de API e faturamento. A plataforma suporta endpoints globais e específicos da região, então você escolhe com base na sua localização para uma latência ideal.
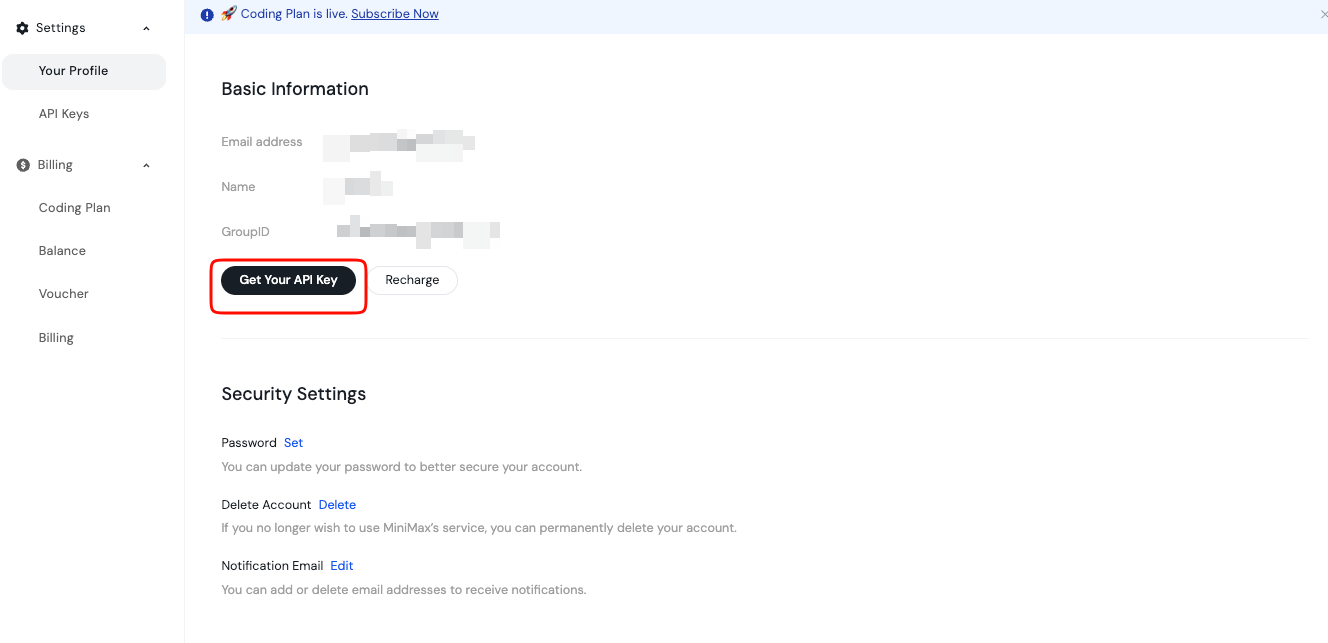
Além disso, revise as seções de documentação desde cedo. Elas cobrem a disponibilidade do modelo, limites de taxa e melhores práticas. Armazene esta chave com segurança, talvez em uma variável de ambiente ou gerenciador de segredos. Nunca a exponha em código do lado do cliente.
Adicionalmente, recarregue seu saldo, se necessário, através da página de Faturamento. A MiniMax opera em um modelo de pagamento conforme o uso, garantindo que você controle os custos com precisão.
Qual é o Endpoint e a Estrutura da Requisição da API MiniMax M2.1?
A API MiniMax oferece compatibilidade com formatos populares, incluindo estilos OpenAI e Anthropic. Para geração de texto com M2.1, você mira no endpoint de chat completions.
Tipicamente, a URL base aparece como https://api.minimax.io ou uma variante regional. Você especifica o nome do modelo, como "MiniMax-M2.1", em seu payload de requisição.
Uma requisição POST padrão inclui cabeçalhos para autorização e tipo de conteúdo. Você define Authorization: Bearer YOUR_API_KEY e Content-Type: application/json.
O corpo segue um formato de array de mensagens, semelhante a outros LLMs. Você inclui os papéis de sistema, usuário e assistente conforme necessário.
Além disso, você ajusta parâmetros como temperatura, max_tokens, top_p e tool choices para refinar as saídas.
Como você envia sua primeira requisição para a API MiniMax M2.1?
Você testa a API rapidamente usando curl para verificação.
Aqui está um exemplo básico:
curl https://api.minimax.io/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "MiniMax-M2.1",
"messages": [
{"role": "system", "content": "Você é um assistente de codificação útil."},
{"role": "user", "content": "Escreva uma função Python para calcular números de Fibonacci."}
],
"temperature": 0.7,
"max_tokens": 512
}'
Este comando retorna uma resposta JSON com a conclusão gerada. Você inspeciona o array de choices para a resposta do assistente.
Adicionalmente, você habilita o streaming para saídas em tempo real adicionando "stream": true.
Como você pode usar Python para interagir com a API MiniMax M2.1?
Desenvolvedores Python preferem bibliotecas pela simplicidade. Embora o MiniMax forneça compatibilidade, você usa o SDK oficial do OpenAI com uma URL base personalizada.
Primeiro, instale o pacote:
pip install openai
Então, configure o cliente:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.minimax.io/v1" # Ajuste se necessário
)
response = client.chat.completions.create(
model="MiniMax-M2.1",
messages=[
{"role": "system", "content": "Você é um desenvolvedor especialista."},
{"role": "user", "content": "Explique fluxos de trabalho agenticos."}
],
temperature=0.8
)
print(response.choices[0].message.content)
Este código lida com requisições eficientemente. Você o estende com tratamento de erros e retentativas para uso em produção.
Por que usar o Apidog para testar e gerenciar chamadas da API MiniMax M2.1?
Testar APIs manualmente se torna tedioso à medida que os projetos crescem. O Apidog simplifica significativamente esse processo.
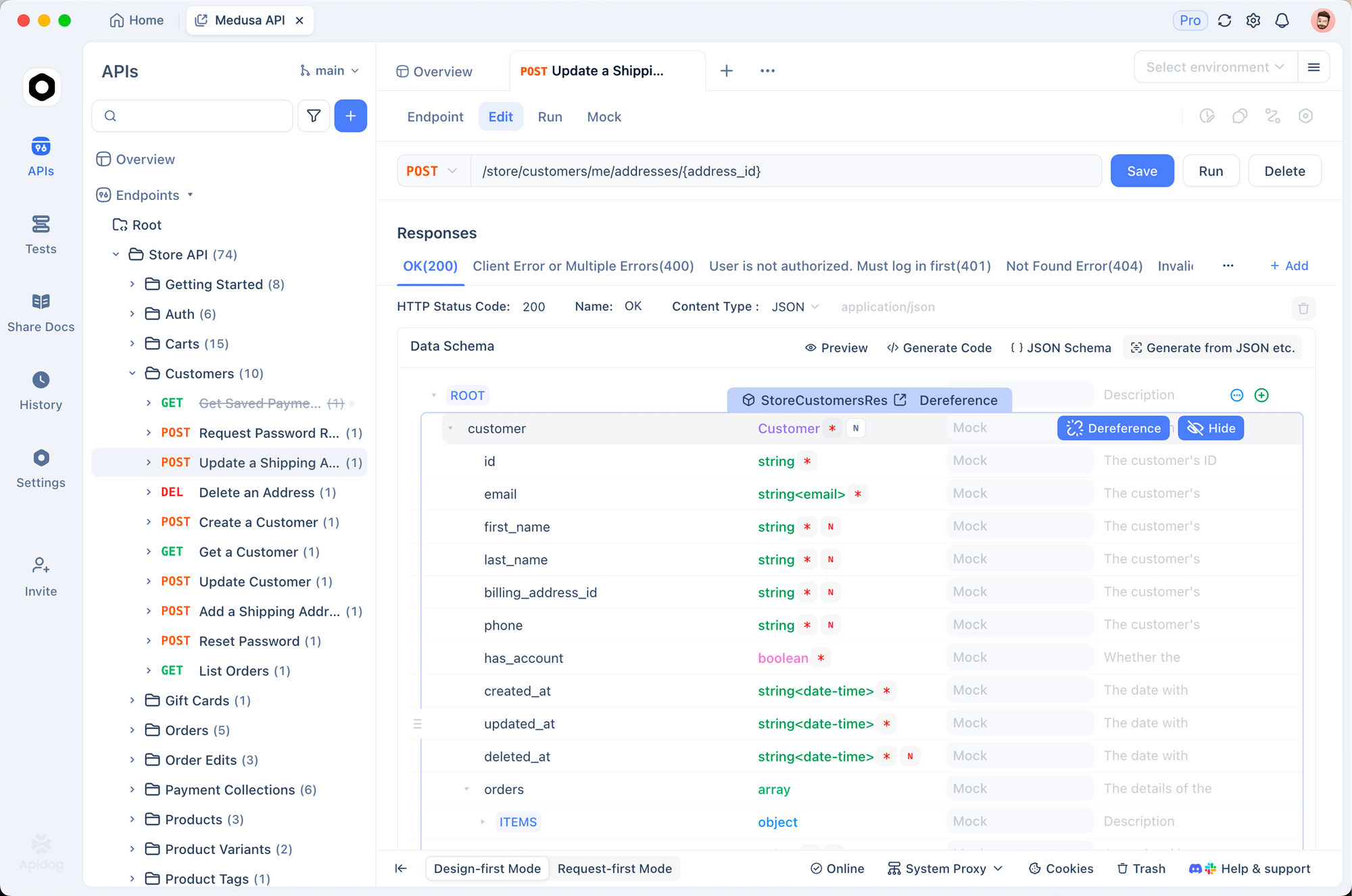
Você importa a documentação do MiniMax ou cria coleções manualmente no Apidog. Em seguida, você define variáveis de ambiente para sua chave de API.
O Apidog suporta o envio de requisições, visualização de respostas formatadas e mocking de endpoints. Além disso, ele gera código cliente em múltiplas linguagens automaticamente.
Por exemplo, você depura o uso de tokens ou respostas de streaming visualmente. Isso economiza horas em comparação com comandos curl brutos.
Adicionalmente, o Apidog se integra com pipelines de CI/CD, garantindo um comportamento consistente da API.
Como você lida com chamadas de ferramentas e recursos avançados no MiniMax M2.1?
O MiniMax M2.1 suporta chamadas de ferramentas nativas, cruciais para aplicações agenticas. Você define as ferramentas no payload da requisição.
O modelo decide quando invocá-las, retornando chamadas estruturadas. Sua aplicação executa as ferramentas e anexa os resultados como mensagens do assistente.
Este loop permite raciocínio multi-etapas. Além disso, você aproveita o pensamento intercalado para rastreamentos de raciocínio transparentes.
Quais são as melhores práticas para limites de taxa e tratamento de erros?
O MiniMax impõe limites de taxa para manter a qualidade do serviço. Você monitora cabeçalhos como x-ratelimit-remaining nas respostas.
Implemente backoff exponencial para retentativas em erros 429. Adicionalmente, você captura falhas de autenticação (401) e requisições inválidas (400).
O registro de requisições e respostas auxilia na depuração. Você acompanha o uso através do painel para evitar surpresas.
Conclusão: Comece a Construir com MiniMax M2.1 Hoje
Você agora possui o conhecimento para acessar e utilizar a API MiniMax M2.1 de forma eficaz. Registre-se na plataforma, gere sua chave e envie requisições — seja via curl, Python ou Apidog.
Este modelo permite que você construa agentes sofisticados e ferramentas de codificação a custos competitivos. Experimente livremente, compare com alternativas como GLM-4.7 e escale seus projetos.
O Apidog aprimora ainda mais seu fluxo de trabalho, fornecendo poderosas ferramentas de teste. Baixe-o gratuitamente e acelere seu desenvolvimento.
botão