MoltBot, anteriormente conhecido como ClawdBot, se destaca como um agente auto-hospedado que se integra diretamente com plataformas de mensagens como Telegram, WhatsApp, Discord e Slack. Ele executa tarefas reais em sua máquina, mantendo a privacidade e baixa latência.
Conectar o Kimi K2.5 ao MoltBot cria um assistente versátil e econômico. Os usuários obtêm forte desempenho para tarefas gerais, trabalho criativo e comportamentos agenticos por uma fração do custo de modelos como Claude 3.5 Sonnet ou GPT-4o. Para configurações focadas na privacidade, a implantação local usando pesos GGUF quantizados elimina a transmissão externa de dados.
Este guia explica detalhadamente os métodos via API e local. Inclui exemplos de configuração, etapas de verificação e soluções para problemas frequentes.
Por que Parear o MoltBot com o Kimi K2.5?
MoltBot serve como a camada de execução, enquanto o LLM fornece inteligência. Kimi K2.5 oferece vantagens distintas neste papel.
O modelo oferece alta capacidade através de seu design MoE, ativando especialistas relevantes de forma eficiente. Ele lida com entradas multimodais nativamente, permitindo que o MoltBot processe capturas de tela, designs de UI ou vídeos curtos para tarefas como geração de código a partir de visuais.
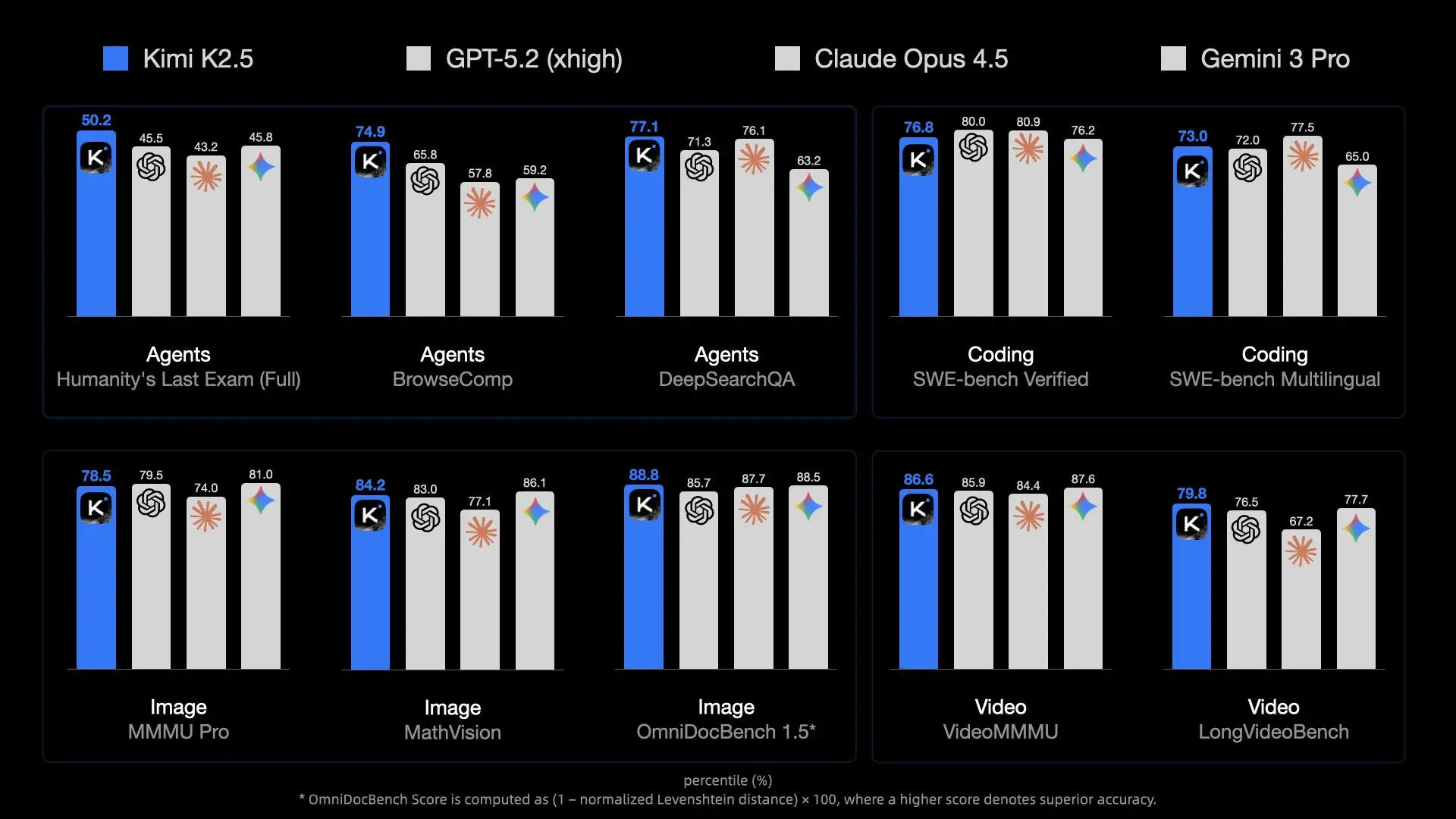
O comprimento do contexto atinge 256K tokens na maioria das implantações, permitindo a retenção de extensas bases de código de projetos, documentação ou históricos de conversas — essencial para assistentes persistentes.
Os custos da API permanecem baixos em comparação com alternativas ocidentais. Usuários pesados economizam substancialmente ao longo do tempo. Para custo zero e controle máximo, a inferência local funciona em hardware de consumo com quantização.
Kimi K2.5 demonstra fortes capacidades agenticas, incluindo enxames autodirigidos de até 100 sub-agentes para execução paralela de ferramentas. Quando roteados através do sistema de habilidades do MoltBot, esses recursos automatizam fluxos de trabalho complexos diretamente a partir de mensagens de chat.
A flexibilidade do MoltBot suporta qualquer endpoint compatível com OpenAI. A troca de provedores requer apenas atualizações de configuração, para que os usuários experimentem facilmente.
Pré-requisitos
Prepare estes elementos antes da configuração.
Instale o MoltBot completamente. Execute o script de instalação se ainda não o fez:
curl -fsSL https://molt.bot/install.sh | bash
O projeto foi renomeado de ClawdBot para MoltBot em 27 de janeiro de 2026, após um pedido de marca registrada da Anthropic. Instalações mais antigas podem manter o diretório ~/.clawdbot, mas as versões recentes usam comandos moltbot e ~/.moltbot ou caminhos semelhantes. Verifique a documentação em molt.bot ou no repositório GitHub (github.com/moltbot/moltbot) para sua configuração exata.
Obtenha acesso ao Kimi K2.5:
- Rota da API: Crie uma conta em platform.moonshot.ai, gere uma chave de API e observe quaisquer limites de orçamento do projeto.
- Rota local: Baixe pesos quantizados (por exemplo, de Hugging Face moonshotai/Kimi-K2.5 ou repositórios da comunidade como unsloth/Kimi-K2.5-GGUF). Instale o llama.cpp e inicie um servidor.
Instale o Apidog para testes. Ele lida com cabeçalhos de autenticação, corpos JSON e streaming de resposta de forma eficaz.
Certifique-se de que o Node.js esteja em execução para o MoltBot. Familiaridade básica com o terminal ajuda na edição de arquivos JSON.
Método 1: Conectando via API Moonshot (Recomendado para a Maioria dos Usuários)
Esta abordagem requer hardware mínimo e fornece contexto completo de 256K mais suporte multimodal.
Passo 1: Validar a Conexão da API Usando o Apidog
Inicie o Apidog e crie uma nova solicitação POST.
Defina a URL para:
https://api.moonshot.ai/v1/chat/completions
Adicione o cabeçalho:
Authorization: Bearer sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
(Substitua pela sua chave real.)
Use este corpo para um teste básico:
{
"model": "kimi-k2.5",
"messages": [
{
"role": "user",
"content": "Confirm you are Kimi K2.5 and describe your capabilities briefly."
}
],
"temperature": 0.7,
"max_tokens": 256
}
Envie a solicitação. Uma resposta 200 bem-sucedida com saída coerente confirma que a chave funciona. Observe quaisquer erros de limite de taxa ou orçamento aqui.
Passo 2: Localizar e Editar o Arquivo de Configuração
MoltBot armazena configurações em um arquivo JSON, geralmente:
~/.moltbot/moltbot.json- Ou legado:
~/.clawdbot/moltbot.json/~/.clawdbot/agents/default/config.json
Abra-o com um editor.
Adicione ou modifique a seção de provedores:
{
"agent": {
"model": {
"primary": "moonshot/kimi-k2.5"
}
},
"models": {
"providers": {
"moonshot": {
"baseUrl": "https://api.moonshot.ai/v1",
"apiKey": "sk-your-moonshot-api-key-here",
"api": "openai-completions",
"models": [
{
"id": "kimi-k2.5",
"name": "Kimi K2.5 (API)",
"contextWindow": 262144,
"maxTokens": 8192
}
]
}
}
}
}
Nota de segurança: Evite codificar chaves diretamente em produção. Defina uma variável de ambiente (por exemplo, export MOONSHOT_API_KEY=sk-...) e faça referência a ela se o MoltBot suportar expansão.
Passo 3: Aplicar Alterações e Reiniciar
Salve o arquivo e reinicie:
moltbot restart
Ou pare e inicie o gateway/serviço conforme necessário.
Método 2: Conectando via Implantação Local do Kimi K2.5
A execução local prioriza a privacidade e elimina custos recorrentes, embora exija VRAM/RAM substancial.
Passo 1: Iniciar o Servidor de Inferência Local
Use o llama.cpp para compatibilidade.
Compile o llama.cpp com suporte a GPU, se disponível:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make LLAMA_CUDA=1 # ou flags apropriadas
Baixe uma variante GGUF quantizada (por exemplo, UD-TQ1_0 para equilíbrio):
Use huggingface-cli ou download direto.
Inicie o servidor compatível com OpenAI:
./llama-server \
-m /path/to/Kimi-K2.5-UD-TQ1_0.gguf \
--port 8080 \
--ctx-size 32768 \ # Ajuste até o limite do hardware; 256K exige recursos extremos
--n-gpu-layers 99 \
--host 0.0.0.0
Verifique navegando em http://localhost:8080/v1/models.
Passo 2: Atualizar a Configuração do MoltBot para o Endpoint Local
Edite o arquivo JSON:
{
"agent": {
"model": {
"primary": "local-kimi/kimi-k2.5"
}
},
"models": {
"providers": {
"local-kimi": {
"baseUrl": "http://127.0.0.1:8080/v1",
"apiKey": "sk-no-key-required",
"api": "openai-completions",
"models": [
{
"id": "kimi-k2.5-local",
"name": "Kimi K2.5 Local",
"contextWindow": 32768, // Deve corresponder a --ctx-size
"maxTokens": 4096
}
]
}
}
}
}
Nota sobre Docker: Se o MoltBot estiver em contêiner, substitua 127.0.0.1 por host.docker.internal.
Passo 3: Reiniciar e Monitorar o Uso de Recursos
Reinicie o MoltBot e observe os monitores do sistema. A inferência local consome muita memória; descarregue camadas ou reduza o contexto, se necessário.
Testando e Verificando
Confirme se a integração funciona.
Envie uma mensagem para sua instância do MoltBot (via aplicativo conectado):
"Por quem você é alimentado agora?"
Kimi K2.5 geralmente responde identificando Moonshot AI.
Verifique os logs:
moltbot logs
Procure por solicitações roteadas para api.moonshot.ai ou localhost:8080.
Teste o modo multimodal se estiver usando a API: Carregue uma imagem via chat e peça uma descrição ou geração de código a partir dela.
Solução de Problemas Comuns
Falha na verificação do provedor → Teste novamente o baseUrl + chave exatos no Apidog. Proxies de rede ou firewalls geralmente interferem.
Erros de estouro de contexto → Alinhe `contextWindow` no JSON com `--ctx-size` do servidor. MoltBot trunca ou resume quando os limites são atingidos; valores incompatíveis causam falhas.
Respostas lentas localmente → Reduza as `gpu-layers`, use quantização menor ou ative `flash attention` no llama.cpp.
Formatação inesperada/alucinações → Experimente a temperatura (0.6–1.0) ou adicione prompts de sistema personalizados na configuração do agente MoltBot para ajuste específico do Kimi.
Esgotamento do orçamento da API → Monitore o uso em platform.moonshot.ai e defina limites diários.
Conclusão
Integrar o Kimi K2.5 com o MoltBot oferece um agente de IA pessoal de alto desempenho, econômico e, opcionalmente, totalmente privado. O método via API oferece conveniência e capacidades máximas, enquanto a configuração local garante total soberania dos dados.
Experimente ambas as abordagens. Use o Apidog para isolar problemas rapidamente. Enquanto a Moonshot continua atualizando os modelos Kimi e o MoltBot evolui, esta combinação posiciona os usuários na vanguarda da IA agentica acessível.
Comece a configurar agora — seu assistente aprimorado espera.