
Desenvolvedores que criam aplicações inteligentes frequentemente enfrentam o desafio de integrar modelos de ponta como o GPT-5.2 em seus fluxos de trabalho. Lançado pela OpenAI como a mais recente fronteira em capacidades de IA, o GPT-5.2 impulsiona os limites na geração de código, percepção de imagens e raciocínio multi-etapa. Você o integra não apenas para experimentar, mas para implantar soluções robustas e escaláveis que lidam com tarefas profissionais complexas. No entanto, a profundidade da API — desde a seleção de variantes até o ajuste de parâmetros — exige uma abordagem estruturada. É aí que ferramentas como o Apidog entram, simplificando o design, teste e documentação da API para que você se concentre na inovação em vez de tarefas repetitivas.
Entendendo o GPT-5.2: Capacidades Essenciais e Por Que Ele Importa para Desenvolvedores
Você escolhe o GPT-5.2 porque ele supera seus predecessores em precisão e eficiência. A OpenAI o posiciona como um conjunto otimizado para trabalho de conhecimento, onde ele alcança resultados de ponta em vários benchmarks. Por exemplo, ele atinge 80,0% no SWE-Bench Verified para tarefas de codificação, o que significa que você gera soluções de software mais precisas com menos iterações. Além disso, suas capacidades de visão reduzem pela metade as taxas de erro no raciocínio de gráficos, permitindo aplicações como ferramentas automatizadas de visualização de dados.
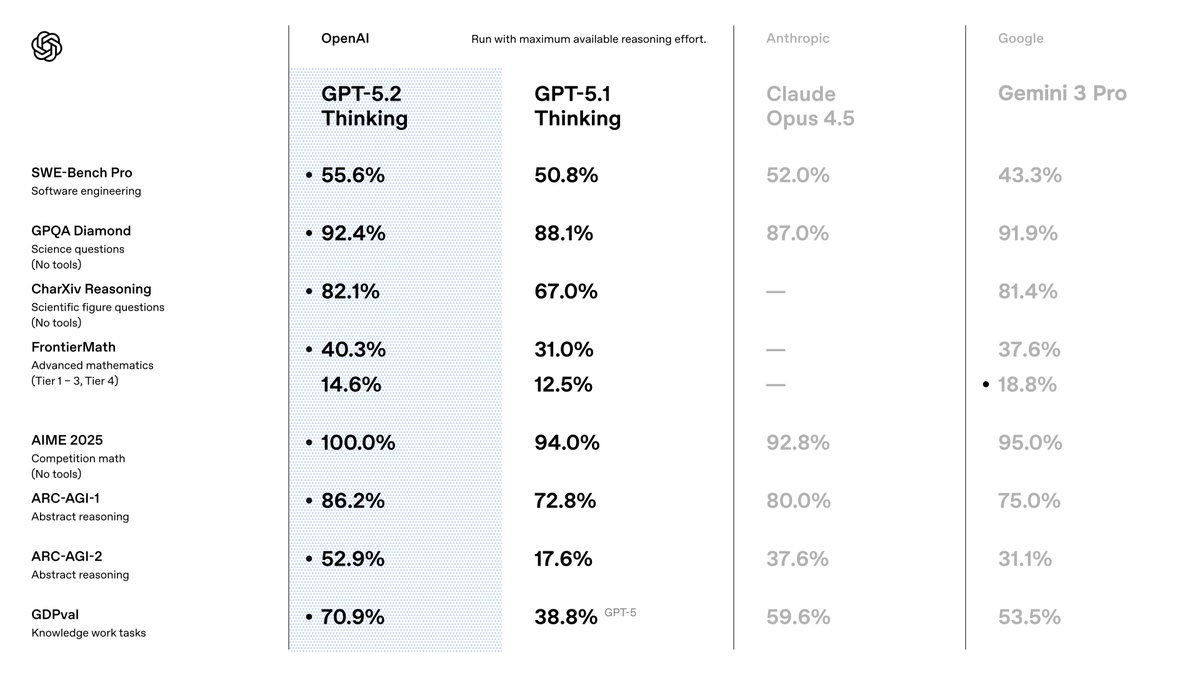
Ao fazer a transição do GPT-5.1, você nota melhorias na factualidade — 30% menos alucinações em consultas habilitadas por pesquisa — e no tratamento de contextos longos, com precisão quase perfeita de até 256k tokens. Esses recursos importam porque reduzem a necessidade de pós-processamento em seus pipelines. Você também se beneficia da chamada de ferramentas aprimorada, atingindo 98,7% em benchmarks de múltiplas rodadas, o que otimiza sistemas de agentes.
Para usuários da API, o GPT-5.2 se integra perfeitamente aos ecossistemas existentes da OpenAI. Você o acessa através da API de Chat Completions ou Responses, suportando parâmetros como temperatura para controle de criatividade. No entanto, o sucesso depende da escolha da variante certa. Vamos explorá-las a seguir.
Explorando as Variantes do GPT-5.2: Adapte o Desempenho às Suas Necessidades
O GPT-5.2 oferece variantes que equilibram velocidade, profundidade e custo, permitindo que você ajuste o comportamento do modelo às demandas da tarefa. Diferentemente de modelos monolíticos, essas opções — Instant, Thinking e Pro — proporcionam flexibilidade. Você as ativa através de identificadores de modelo específicos em suas requisições de API.
Comece com o GPT-5.2 Instant (gpt-5.2-chat-latest). Esta variante prioriza baixa latência para interações cotidianas, como busca rápida de informações ou escrita técnica. Desenvolvedores a preferem para chatbots ou assistentes em tempo real, onde tempos de resposta abaixo de 200ms se mostram essenciais. Ela lida com traduções e tutoriais com precisão aprimorada, tornando-a ideal para aplicativos voltados para o consumidor.
Em seguida, considere o GPT-5.2 Thinking (gpt-5.2). Você o utiliza para análises mais aprofundadas, como sumarização de documentos longos ou planejamento lógico. Seu motor de raciocínio se destaca em matemática e tomada de decisões, resolvendo 40,3% dos problemas do FrontierMath. Use o parâmetro reasoning aqui — definido como 'high' ou 'xhigh' — para amplificar a qualidade da saída em consultas complexas. Por exemplo, em ferramentas de gerenciamento de projetos, ele orquestra fluxos de trabalho de várias etapas com erros mínimos.
Finalmente, o GPT-5.2 Pro (gpt-5.2-pro) visa um desempenho de elite em domínios desafiadores. Ele ostenta 93,2% no GPQA Diamond para perguntas científicas e se destaca na programação com menos falhas em casos extremos. Você o reserva para protótipos de P&D ou ambientes de alto risco, como modelagem financeira, onde a precisão supera a velocidade.
A imagem que você compartilhou destaca os seletores para estas opções, incluindo os modos "Max", "Mini", "High", "Low" e "Fast". Estes se alinham com os esforços de raciocínio: 'none' para respostas instantâneas, 'low' para tarefas básicas, até 'xhigh' para análise exaustiva. Você os alterna via parâmetros da API, garantindo que o modelo se adapte dinamicamente. Por exemplo, mude para "Max High Fast" para sessões de codificação equilibradas que priorizam a velocidade sem sacrificar a profundidade.
Ao selecionar variantes de forma cuidadosa, você otimiza o uso de recursos. Agora, você configura o acesso para fazer essas chamadas.
Configurando Seu Acesso à API GPT-5.2: Autenticação e Preparação do Ambiente
Você inicia a integração garantindo as credenciais da API. A OpenAI exige uma chave de API, que você gera no painel da plataforma. Navegue até platform.openai.com, crie uma conta se necessário e emita uma chave em "API Keys".
Em seguida, instale o SDK Python da OpenAI. Execute pip install openai no seu terminal. Esta biblioteca lida com requisições HTTP, retentativas e streaming de forma nativa. Para usuários de Node.js, npm install openai oferece funcionalidade semelhante. Você o importa da seguinte forma:
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
Teste a conectividade com uma simples conclusão:
response = client.chat.completions.create(
model="gpt-5.2-chat-latest",
messages=[{"role": "user", "content": "Explain quantum entanglement briefly."}]
)
print(response.choices[0].message.content)
Esta chamada verifica a configuração. Se surgirem erros, verifique os limites de taxa (padrão de 3.500 RPM para o Nível 1) ou a validade da chave. Você também configura a URL base para endpoints personalizados, como /compact para contextos estendidos: client = OpenAI(base_url="https://api.openai.com/v1", api_key=...).
Com o básico configurado, você explora a criação de requisições.
Criando Requisições Eficazes para a API GPT-5.2: Parâmetros e Melhores Práticas
Você constrói requisições usando o endpoint de Chat Completions (/v1/chat/completions). O payload inclui model, messages e parâmetros opcionais como temperature (0-2 para determinismo) e max_tokens (até 4096 de saída).
Para especificidades do GPT-5.2, incorpore reasoning_effort para controlar a profundidade:
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Write a Python function for Fibonacci sequence."}],
reasoning_effort="high", # Aligns with "Max High" toggle
temperature=0.7,
max_tokens=500
)
Isso gera código com raciocínio passo a passo, reduzindo bugs. Você encadeia mensagens para conversas, preservando o contexto entre as interações. Para tarefas de visão, carregue imagens via content com o tipo "image_url":
messages = [
{"role": "user", "content": [
{"type": "text", "text": "Describe this chart's trends."},
{"type": "image_url", "image_url": {"url": "https://example.com/chart.png"}}
]}
]
As melhores práticas incluem o agrupamento de requisições para economia de custos e o uso de streaming (stream=True) para UIs em tempo real. Monitore o uso de tokens com usage nas respostas para refinar os prompts. Além disso, habilite ferramentas para chamada de funções — defina esquemas para APIs externas, e o GPT-5.2 as executa autonomamente.
Para testar isso de forma eficiente, integre o Apidog. Ele simula endpoints da OpenAI, permitindo que você teste variantes sem atingir as cotas reais.
Integrando o GPT-5.2 com Apidog: Simplifique Testes e Documentação
O Apidog transforma a forma como você gerencia os fluxos de trabalho da API GPT-5.2. Como uma plataforma tudo-em-um, ele suporta importações de especificações OpenAPI, construção de requisições e testes automatizados. Você importa o esquema da OpenAI para o Apidog e então projeta coleções para chamadas GPT-5.2.
Comece criando um novo projeto no Apidog. Adicione uma requisição HTTP para https://api.openai.com/v1/chat/completions, defina os cabeçalhos (Authorization: Bearer SUA_CHAVE, Content-Type: application/json) e cole um corpo de exemplo. Alterne variáveis para modelos como "gpt-5.2-pro" para comparar saídas lado a lado.
A força do Apidog reside em seu servidor de mocking. Você gera respostas falsas imitando a estrutura JSON do GPT-5.2, ideal para desenvolvimento offline. Por exemplo, simule uma resposta "Max Extra High" com rastreamentos de raciocínio detalhados. Execute testes com asserções sobre contagem de tokens ou taxas de alucinação.

Além disso, documente sua API com o editor integrado do Apidog. Gere documentação interativa que seus colegas podem usar para explorar os endpoints. Exporte para Postman ou HAR para portabilidade. Em produção, o Apidog monitora as chamadas, alertando sobre anomalias como alta latência em modos "Low Fast".
Ao integrar o Apidog ao seu processo, você acelera a iteração. Baixe-o gratuitamente e importe sua primeira requisição GPT-5.2 — experimente a diferença em minutos.
Preços da API GPT-5.2: Equilibre Custo e Capacidade Estrategicamente
Você não pode ignorar os preços ao escalar aplicações GPT-5.2. A OpenAI estrutura os custos por milhão de tokens, com níveis que refletem o volume de uso. Para o GPT-5.2 Instant (gpt-5.2-chat-latest), espere $1.75 por 1M de tokens de entrada e $14 por 1M de tokens de saída. Entradas em cache caem para $0.175 — uma economia de 90% — incentivando contextos repetidos.
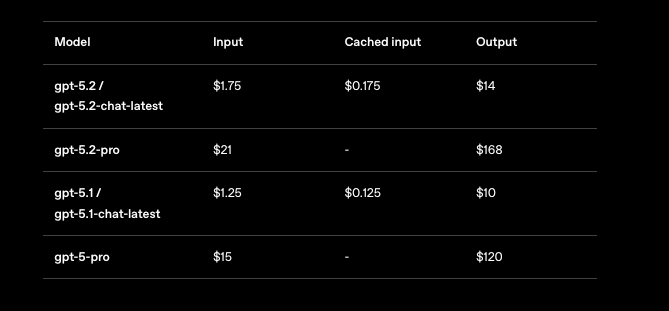
O GPT-5.2 Thinking (gpt-5.2) reflete essas taxas, tornando-o econômico para tarefas equilibradas. No entanto, o GPT-5.2 Pro (gpt-5.2-pro) exige mais: $21 por 1M de entrada e $168 por 1M de saída. Este prêmio reflete sua precisão superior em consultas de nível profissional, mas você deve avaliar o ROI cuidadosamente.
No geral, o GPT-5.2 se mostra eficiente em tokens, muitas vezes reduzindo o gasto total em comparação com o GPT-5.1 para saídas de qualidade. Você acompanha através do analisador de uso do painel. Para empresas, negocie níveis personalizados. Ferramentas como o Apidog ajudam a prever custos registrando fluxos de tokens simulados.
Compreendendo esses valores, você prossegue para exemplos práticos.
Exemplos Práticos: Geração de Código e Tarefas de Visão com GPT-5.2
Você aplica o GPT-5.2 em cenários tangíveis. Considere a geração de código: Solicite um componente React com gerenciamento de estado.
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Build a React todo list with useReducer."}],
reasoning_effort="medium"
)
A saída gera código limpo e comentado — 80% alinhado com o benchmark. Você refina iterando: Continue com "Otimizar para desempenho".
Para visão, analise capturas de tela. Faça o upload de um mockup de UI e consulte: "Sugira melhorias de acessibilidade." O GPT-5.2 identifica problemas como contraste de cores, aproveitando sua taxa de erro reduzida pela metade.
Em agentes multi-ferramentas, defina funções para consultas a bancos de dados. O GPT-5.2 orquestra as chamadas, reduzindo a latência em mega-agentes com mais de 20 ferramentas.
Esses exemplos demonstram versatilidade. No entanto, erros ocorrem — lide com eles com retentativas e fallbacks.
Lidando com Erros e Casos Extremos em Chamadas da API GPT-5.2
Você pode encontrar limites de taxa ou parâmetros inválidos. Envolva as chamadas em try-except:
try:
response = client.chat.completions.create(...)
except openai.RateLimitError:
time.sleep(60) # Backoff
response = client.chat.completions.create(...)
Para alucinações, verifique cruzadamente com ferramentas de busca. Em contextos longos, use /compact para compactar históricos. Monitore por viés em aplicativos sensíveis, aplicando filtros.
O Apidog ajuda aqui: Crie scripts de teste para cenários de erro, garantindo resiliência.
Otimizações Avançadas: Escalando o GPT-5.2 para Produção
Você escala ajustando prompts e usando a API de Assistentes para threads persistentes. Implemente cache para entradas repetidas. Para aplicativos globais, roteie via servidores de borda.
Integre com frameworks como LangChain: Encadeie o GPT-5.2 com armazenamentos de vetores para sistemas RAG.
Finalmente, mantenha-se atualizado — a OpenAI itera rapidamente.
Conclusão: Domine a API GPT-5.2 e Construa o Futuro
Agora você possui as ferramentas para usar o GPT-5.2 de forma eficaz. Desde a seleção de variantes até os testes aprimorados pelo Apidog, aplique essas etapas para elevar seus projetos. Os preços permanecem acessíveis para uso consciente, desbloqueando capacidades antes reservadas a laboratórios.
Experimente hoje: Prototipe um agente GPT-5.2 e meça os ganhos. Compartilhe suas criações nos comentários — quais desafios você enfrenta? Para aprofundar, explore a documentação da OpenAI. Construa com ousadia.