
Engenheiros e desenvolvedores buscam constantemente modelos eficientes que entreguem alto desempenho sem demandas excessivas de recursos. O GLM-4.7-Flash surge como uma opção atraente neste cenário. Este modelo Mixture-of-Experts (MoE) 30B-A3B, desenvolvido pela Zhipu AI (Z.ai), se destaca pelo seu equilíbrio entre força e eficiência. Ele se sobressai em benchmarks de codificação, tarefas de raciocínio e integração de ferramentas, tornando-o adequado para cenários de implantação local.
Executar o GLM-4.7-Flash localmente capacita os usuários a manter a privacidade dos dados, reduzir a latência e personalizar integrações. Ferramentas como Ollama, LM Studio e Hugging Face simplificam esse processo.
button
À medida que você avança neste guia, obterá insights práticos sobre instalação e uso. Primeiro, considere os requisitos fundamentais do sistema.
O Que É o GLM-4.7-Flash e Por Que Usá-lo Localmente?
O GLM-4.7-Flash representa um avanço nos modelos de linguagem de código aberto. Construído sobre a arquitetura glm4_moe_lite, ele utiliza tipos de tensor BF16 e F32 sob uma licença MIT. O artigo do modelo, "GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models," detalha seu treinamento para uso de ferramentas e raciocínio, baseado em arXiv:2508.06471.
As principais características incluem suporte para inglês e chinês, geração de texto e tarefas conversacionais. Ele lida com entradas multimodais como texto, mas se concentra em saídas apenas de texto. As limitações surgem de sua escala — embora eficiente, pode não corresponder a modelos maiores em domínios de nicho sem ajuste fino. Os detalhes dos dados de treinamento permanecem não divulgados, mas as avaliações confirmam sua vantagem em cenários de codificação e agentic.
Os usuários optam por execuções locais para evitar custos de API. A Z.ai oferece um nível gratuito para o GLM-4.7-Flash através de sua plataforma, mas a implantação local elimina a dependência de serviços externos. Essa abordagem é adequada para desenvolvedores que criam aplicativos personalizados, pesquisadores testando hipóteses ou empresas que priorizam a segurança. Por exemplo, você controla os níveis de quantização para se adequar às restrições de hardware, garantindo o desempenho ideal.
Requisitos do Sistema para Executar o GLM-4.7-Flash Localmente
O hardware desempenha um papel crucial na inferência do modelo. O GLM-4.7-Flash exige pelo menos 16 GB de memória do sistema para operações básicas, conforme especificado nas diretrizes do LM Studio. No entanto, a aceleração da GPU aumenta significativamente a velocidade.
Para variantes do Ollama:
- q4_K_M: 19 GB de VRAM
- q8_0: 32 GB de VRAM
- bf16: 60 GB de VRAM
Hugging Face recomenda torch.bfloat16 para eficiência, exigindo GPUs NVIDIA compatíveis (arquiteturas Ampere ou posteriores). A inferência apenas com CPU funciona, mas desacelera consideravelmente para grandes contextos.
Os pré-requisitos de software incluem Python 3.8+, pip e Git. Frameworks como Transformers necessitam de instalações adicionais. Certifique-se de que seu sistema operacional suporte CUDA para uso da GPU — Ubuntu 20.04 ou Windows com WSL2 tem bom desempenho.
Se os recursos forem insuficientes, a quantização reduz a pegada de memória. Ferramentas como llama.cpp ou Unsloth oferecem versões de 4 ou 2 bits, reduzindo os requisitos para 15-20 GB de VRAM. Essa flexibilidade permite a implantação em hardware de consumo como o RTX 4090.
Com os requisitos atendidos, explore os métodos de instalação. Comece com o Ollama pela sua simplicidade.
Como Instalar e Usar o GLM-4.7-Flash com Ollama
O Ollama oferece uma plataforma acessível para executar grandes modelos localmente. Ele gerencia automaticamente a quantização e o serviço de API.
Primeiro, instale o Ollama. Baixe o executável para o seu sistema operacional e execute-o.

Verifique a instalação com ollama --version, garantindo a versão 0.14.3 ou posterior, pois o GLM-4.7-Flash a exige.

Em seguida, baixe o modelo: execute ollama pull glm-4.7-flash.

Escolha variantes como glm-4.7-flash:q4_K_M para menor uso de memória. O comando baixa aproximadamente 19 GB para a versão q4.
Execute o modelo interativamente: digite ollama run glm-4.7-flash. Insira prompts como "Gerar código Python para uma sequência de Fibonacci." O modelo responde com saídas racionais, aproveitando seus pontos fortes em codificação.
Para acesso programático, use a API. Envie uma requisição curl:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
Isso retorna JSON com a resposta. Em Python, integre com a biblioteca ollama:
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
JavaScript segue de forma semelhante com o pacote npm ollama.
Personalize as configurações editando o Modelfile. Defina a temperatura para 0.7 para saídas determinísticas em tarefas de codificação. O modo mais recente do Ollama busca postagens recentes, se necessário, mas o foco aqui é a inferência local.
Este método é adequado para configurações rápidas. No entanto, para uma interface gráfica, recorra ao LM Studio.
Configurando o GLM-4.7-Flash no LM Studio
O LM Studio oferece uma GUI amigável para gerenciamento de modelos. Baixe-o e instale-o.
Procure por "zai-org/glm-4.7-flash" no hub de modelos. Selecione uma versão quantizada — MLX-4bit, 6bit ou 8bit — dos repositórios Hugging Face vinculados. O download é concluído no aplicativo.
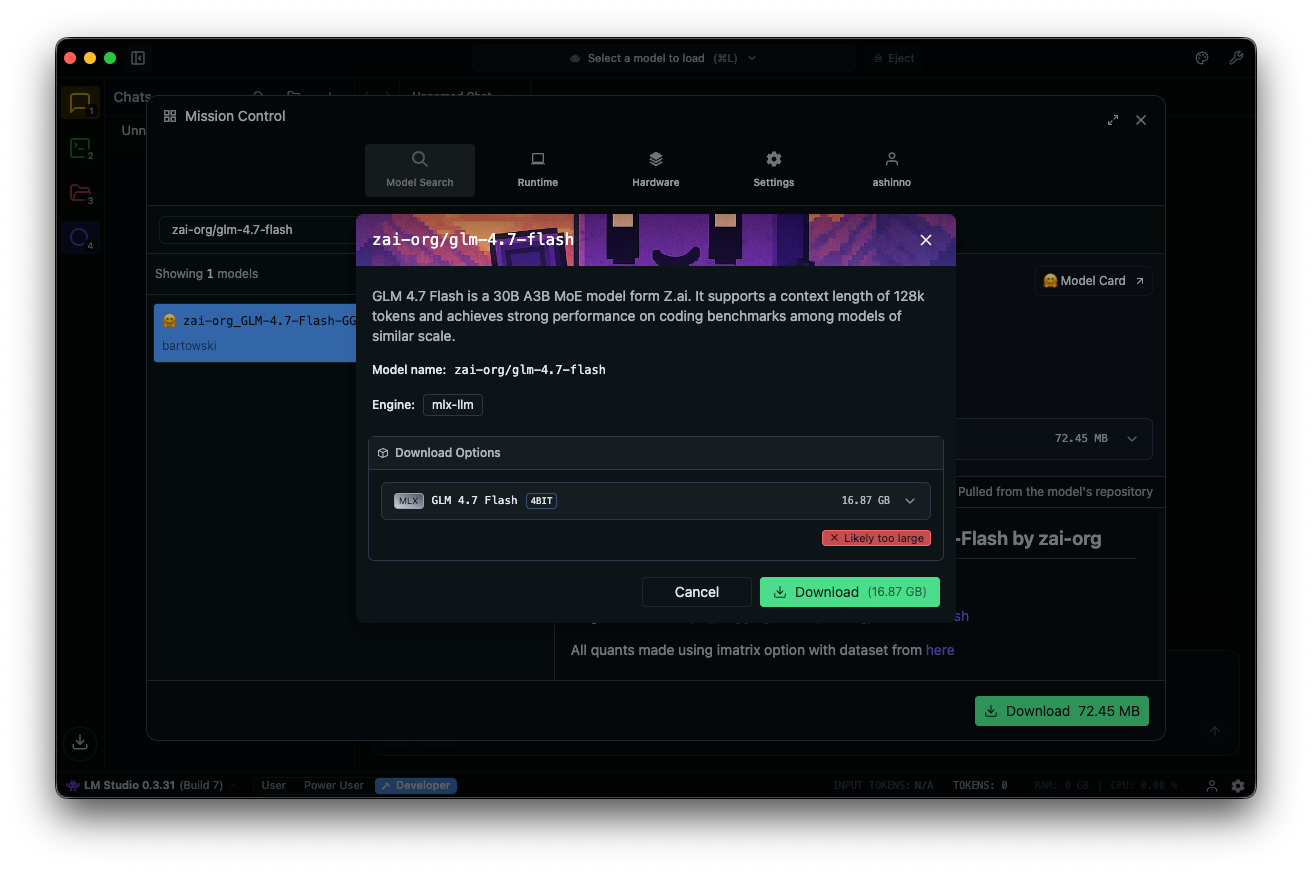
Carregue o modelo: navegue até a interface de chat, selecione GLM-4.7-Flash e ajuste os parâmetros. Habilite o pensamento (padrão: true) para raciocínio passo a passo. Defina a temperatura como 1, top_k como 50, top_p como 0.95 e desative a penalidade de repetição.
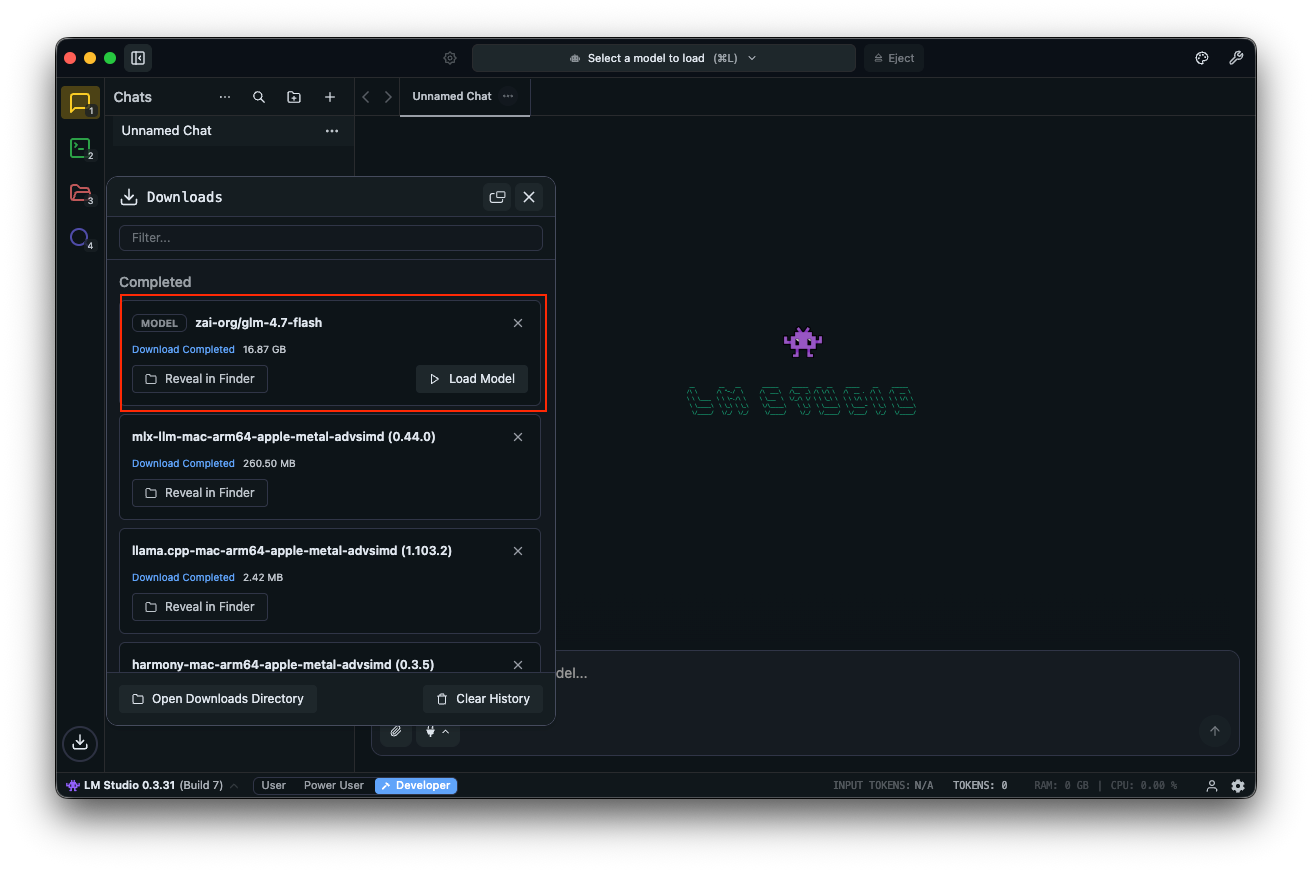
Teste com prompts: "Projete uma API REST para autenticação de usuário." O LM Studio exibe as saídas com velocidades de token, auxiliando na otimização de desempenho.
Campos personalizados como clear_thinking (padrão: false) gerenciam o histórico. Para modelos MoE, monitore os especialistas ativos — A3B significa três ativos por passagem de avanço, otimizando a eficiência.
O LM Studio suporta deeplinks para acesso direto ao modelo. Se surgirem problemas, verifique a memória do sistema — 16 GB no mínimo previnem travamentos.
Esta ferramenta se destaca para experimentação. Para scripts avançados, integre com o Hugging Face.
Usando o GLM-4.7-Flash com Hugging Face Transformers
A Hugging Face fornece bibliotecas robustas para controle granular. Instale o Transformers a partir do branch principal:
pip install git+https://github.com/huggingface/transformers.git
Carregue o modelo:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
Prepare as entradas:
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
Gerar:
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
Esta configuração suporta quantização via bitsandbytes para menor VRAM. Adicione load_in_4bit=True no carregamento do modelo.
Para servir, use vLLM ou SGLang. Instale vLLM:
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
Execute um servidor:
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
Acesse via endpoints compatíveis com OpenAI. O SGLang requer instalação a partir do código fonte e segue etapas semelhantes.
Esses frameworks permitem implantações de nível de produção. Agora, considere o teste de API com Apidog.
Integrando Apidog para Teste de API com GLM-4.7-Flash Local
Depois de servir o GLM-4.7-Flash via Ollama ou vLLM, teste os endpoints de forma eficiente. O Apidog, uma plataforma de API completa, facilita isso.
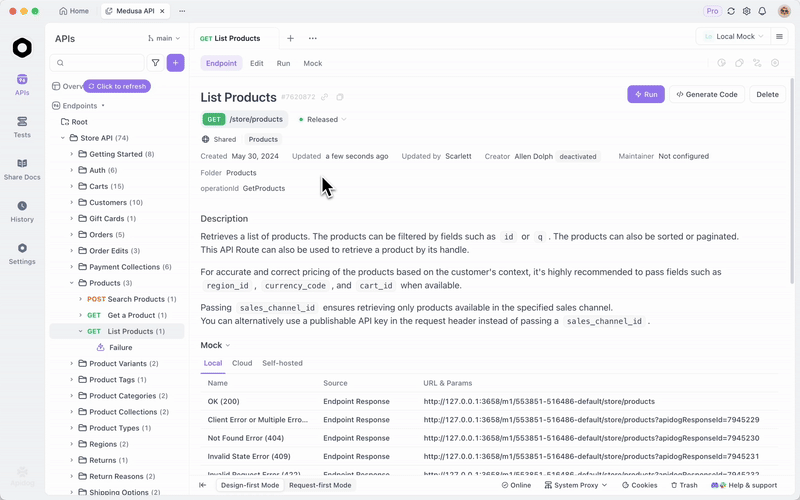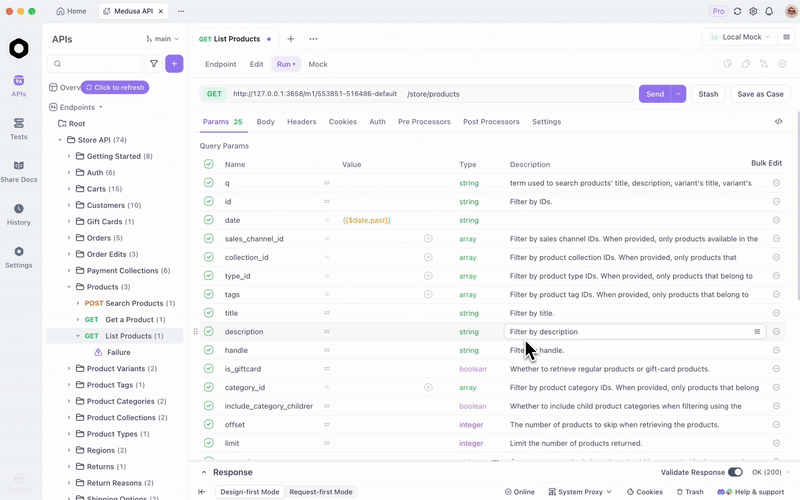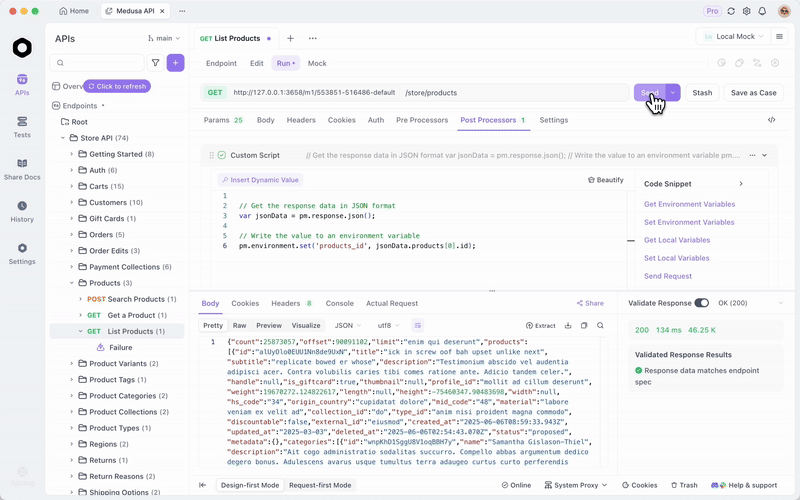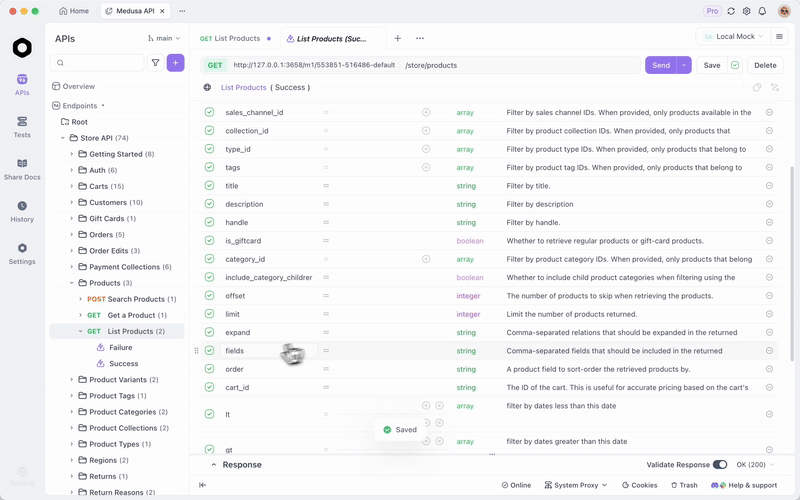
Baixe o Apidog gratuitamente. Ele suporta recursos de IA configurando seu modelo local como um provedor — use chaves de API, se aplicável, ou endpoints diretos.
button
O MCP Server do Apidog se integra com IDEs como o Cursor, usando especificações de API para geração de código. Isso se conecta às capacidades de codificação do GLM-4.7-Flash — teste diretamente as saídas agentic.
Por exemplo, consulte seu servidor local e valide as respostas. Isso garante confiabilidade nas aplicações.
Construindo sobre o básico, avance para a otimização.
Dicas Avançadas para Otimizar o Desempenho do GLM-4.7-Flash
Ajuste os parâmetros para as tarefas. Defina a temperatura para 0.7 para codificação, 1.0 para escrita criativa. Use top_p 0.95 para equilibrar a diversidade.
Quantize ainda mais com formatos GGUF via llama.cpp. Compile llama.cpp com CUDA e depois converta:
./llama-gguf-split --model GLM-4.7-Flash.gguf
Execute com --jinja para suporte a templates.
Lide com contextos longos: Divida as entradas se excederem 128K. Habilite o pensamento para consultas complexas.
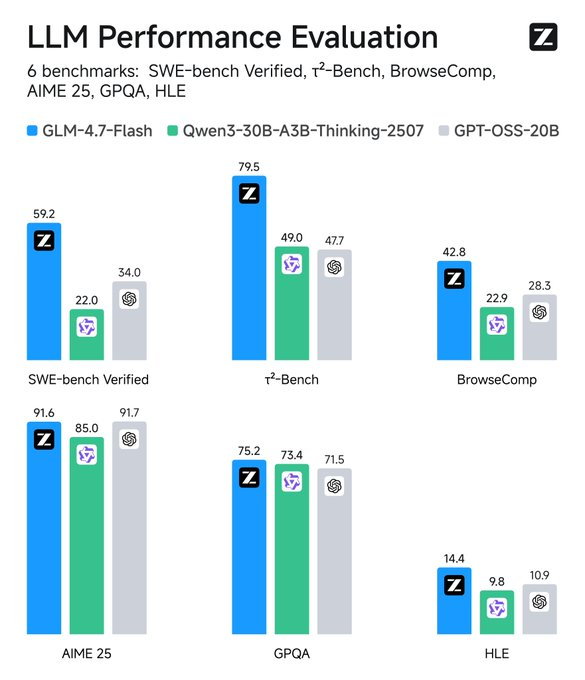
Monitore métricas: Ferramentas como o TensorBoard rastreiam a latência. Compare com as linhas de base — o GLM-4.7-Flash supera seus pares no SWE-bench por 37.2 pontos.
Integre ferramentas: Adicione chamadas de função nos prompts para comportamento agentic.
Segurança: Execute em ambientes isolados para prevenir vazamentos de dados.
Essas estratégias maximizam a utilidade. Pense nas aplicações a seguir.
Solucionando Problemas Comuns
Encontrou erros de falta de memória? Reduza o tamanho do lote ou quantize para um nível inferior.
Inferência lenta? Atualize a GPU ou use frameworks mais rápidos como vLLM.
Problemas de compatibilidade? Atualize o Transformers para o branch principal.
Se o Ollama falhar, verifique a disponibilidade da porta 11434.
O LM Studio trava? Verifique a integridade do modelo.
Aborde isso proativamente.
Conclusão: Capacite Seu Fluxo de Trabalho com o GLM-4.7-Flash
Executar o GLM-4.7-Flash localmente desbloqueia poderosas capacidades de IA. Da facilidade do Ollama à flexibilidade do Hugging Face, as opções são muitas. Incorpore o Apidog para um gerenciamento de API contínuo — baixe-o gratuitamente para elevar sua configuração.
À medida que a tecnologia evolui, modelos como este unem desempenho e acessibilidade. Implemente estas etapas e você alcançará implantações de IA eficientes e privadas. Pequenos ajustes nos parâmetros ou ferramentas produzem melhorias significativas, transformando tarefas rotineiras em processos otimizados.
button