
Desenvolvedores que criam aplicativos inteligentes exigem cada vez mais modelos que lidem com diversos tipos de dados sem comprometer a velocidade ou a precisão. O GLM-4.6V aborda essa necessidade diretamente. A Z.ai lança esta série como um modelo de linguagem grande multimodal de código aberto, mesclando texto, imagens, vídeos e arquivos em interações contínuas. A API permite integrar essas capacidades diretamente em seus projetos, seja para análise de documentos ou para agentes de busca visual.
Ao examinarmos a arquitetura, os métodos de acesso e o preço do GLM-4.6V, você verá como ele supera seus concorrentes em benchmarks. Além disso, dicas de integração com ferramentas como o Apidog ajudarão você a implantar mais rapidamente. Vamos começar com o design central do modelo.
Compreendendo o GLM-4.6V: Arquitetura e Capacidades Principais
A Z.ai projeta o GLM-4.6V para processar entradas multimodais nativamente, gerando respostas de texto estruturadas. Esta série de modelos inclui duas variantes: o carro-chefe GLM-4.6V (106B parâmetros) para tarefas de alto desempenho e o GLM-4.6V-Flash (9B parâmetros) para implantações locais eficientes. Ambos suportam uma janela de contexto de 128K tokens, permitindo a análise de documentos extensos — até 150 páginas — ou vídeos de uma hora em uma única passada.

Em sua essência, o GLM-4.6V incorpora um codificador visual alinhado com protocolos de contexto longo. Este alinhamento garante que o modelo retenha detalhes finos em todas as entradas. Por exemplo, ele lida com sequências intercaladas de texto-imagem, fundamentando respostas a elementos visuais específicos, como coordenadas de objetos em fotos. A chamada de função nativa o diferencia; desenvolvedores invocam ferramentas diretamente com parâmetros de imagem, e o modelo interpreta os ciclos de feedback visual.
Além disso, o aprendizado por reforço aprimora a invocação de ferramentas. O modelo aprende a encadear ações, como consultar uma ferramenta de busca com uma captura de tela e raciocinar sobre os resultados. Isso resulta em fluxos de trabalho de ponta a ponta, desde a percepção até a tomada de decisão. Consequentemente, os aplicativos ganham autonomia sem pós-processamento frágil.

Na prática, esses recursos se traduzem em um tratamento robusto de dados do mundo real. O modelo se destaca na criação de rich text, gerando saídas de imagem-texto intercaladas para relatórios ou infográficos. Ele também suporta o Protocolo de Contexto de Modelo Estendido (MCP), permitindo entradas multimodais baseadas em URL para processamento escalável.
Benchmarks e Desempenho: Medindo o GLM-4.6V Contra Seus Concorrentes
Dados quantitativos validam a vantagem do GLM-4.6V. No MMBench, ele atinge 82,5% em QA multimodal, superando o LLaVA-1.6 em 4 pontos. O MathVista revela 68% de precisão em equações visuais, graças aos codificadores alinhados.
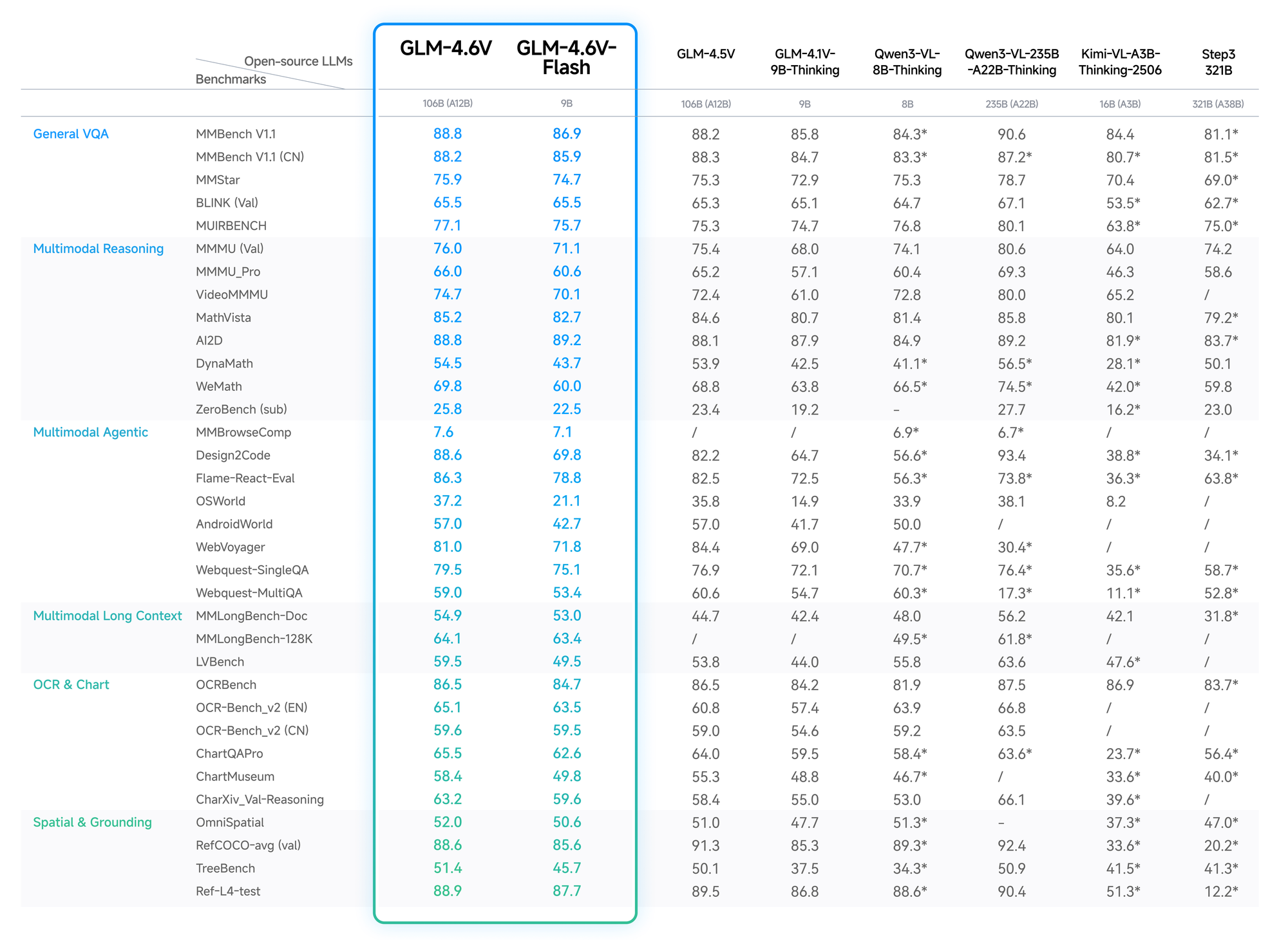
Os testes do OCRBench resultam em 91% para extração de texto de imagens distorcidas, superando o GPT-4V nas classificações de código aberto. Avaliações de contexto longo, como o Video-MME, atingem 75% para clipes de uma hora, retendo detalhes entre os quadros.
A variante Flash troca uma leve perda de precisão (queda de 2-3%) por acelerações de 5x, ideal para aplicativos em tempo real. O blog da Z.ai detalha isso, com configurações reproduzíveis no Hugging Face.
Assim, os desenvolvedores escolhem o GLM-4.6V para um desempenho confiável e com bom custo-benefício.
Principais Recursos da Série de Modelos GLM-4.6V
O GLM-4.6V oferece recursos avançados que elevam a IA multimodal. Primeiramente, suas modalidades de entrada cobrem texto, imagens, vídeos e arquivos, com saídas focadas na geração precisa de texto. Desenvolvedores apreciam a flexibilidade: faça upload de um PDF financeiro, e o modelo extrairá tabelas, analisará tendências e sugerirá visualizações.
O uso de ferramentas nativas representa um avanço. Ao contrário dos modelos tradicionais que exigem orquestração externa, o GLM-4.6V incorpora a chamada de função. Você define ferramentas em requisições — digamos, um cortador para imagens — e o modelo passa dados visuais como parâmetros. Ele então compreende os resultados, iterando se necessário. Isso fecha o ciclo para tarefas como busca visual na web: reconhecer a intenção a partir de uma imagem de consulta, planejar a recuperação, fundir os resultados e gerar insights fundamentados.
Além disso, o contexto de 128K possibilita análises de formato longo. Processe 200 slides de uma apresentação; o modelo resume os temas principais enquanto marca eventos de vídeo com carimbo de data/hora, como gols em uma partida de futebol. Para o desenvolvimento frontend, ele replica UIs a partir de capturas de tela, gerando código HTML/CSS/JS com precisão de pixel. Edições em linguagem natural se seguem, refinando protótipos interativamente.
A variante Flash otimiza para latência. Com 9B parâmetros, ela roda em hardware de consumidor via motores de inferência vLLM ou SGLang. Pesos disponíveis no Hugging Face permitem o ajuste fino, embora a coleção se concentre em modelos base sem estatísticas extensivas ainda. No geral, esses recursos posicionam o GLM-4.6V como uma espinha dorsal versátil para agentes em inteligência de negócios ou ferramentas criativas.
Como Acessar a API GLM-4.6V: Configuração Passo a Passo
Acessar a API GLM-4.6V é simples, graças à sua interface compatível com OpenAI. Comece inscrevendo-se no portal de desenvolvedores da Z.ai (z.ai). Gere uma chave de API no painel da sua conta — este token Bearer autentica todas as requisições.
O endpoint base está localizado em https://api.z.ai/api/paas/v4/chat/completions. Use o método POST com payloads JSON. Os cabeçalhos de autenticação incluem Authorization: Bearer <sua-chave-api> e Content-Type: application/json. O array de mensagens estrutura conversas, suportando conteúdo multimodal.
Por exemplo, envie um URL de imagem junto com prompts de texto. O payload especifica "model": "glm-4.6v" ou "glm-4.6v-flash". Ative as etapas de pensamento com "thinking": {"type": "enabled"} para rastreamentos de raciocínio transparentes. O modo de streaming adiciona "stream": true para respostas em tempo real via eventos enviados pelo servidor.
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.jpg"}
},
{"type": "text", "text": "Descreva os elementos-chave nesta imagem e sugira melhorias."}
]
}
],
"thinking": {"type": "enabled"}
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
print(response.json())
Este código busca uma descrição com justificativa. Para vídeos ou arquivos, estenda o array de conteúdo de forma similar — URLs ou codificações base64 funcionam. Limites de taxa se aplicam com base no seu plano; monitore via painel.
O Apidog aprimora este processo. Importe a especificação OpenAPI da documentação da Z.ai para o Apidog, e então simule requisições visualmente. Teste chamadas de função sem código, validando payloads antes da produção. Como resultado, você itera mais rápido, detectando erros precocemente.
O acesso local complementa o uso da nuvem. Baixe os pesos da coleção GLM-4.6V do Hugging Face e sirva-os via frameworks compatíveis. Esta configuração é adequada para aplicativos sensíveis à privacidade, embora exija recursos de GPU para o modelo de 106B.
Análise de Preços: Escalabilidade Custo-Efetiva com GLM-4.6V
A Z.ai estrutura os preços do GLM-4.6V para equilibrar acessibilidade e desempenho. O modelo carro-chefe cobra US$ 0,6 por milhão de tokens de entrada e US$ 0,9 por milhão de tokens de saída. Este modelo em camadas considera a complexidade multimodal — imagens e vídeos consomem tokens com base na resolução e duração.
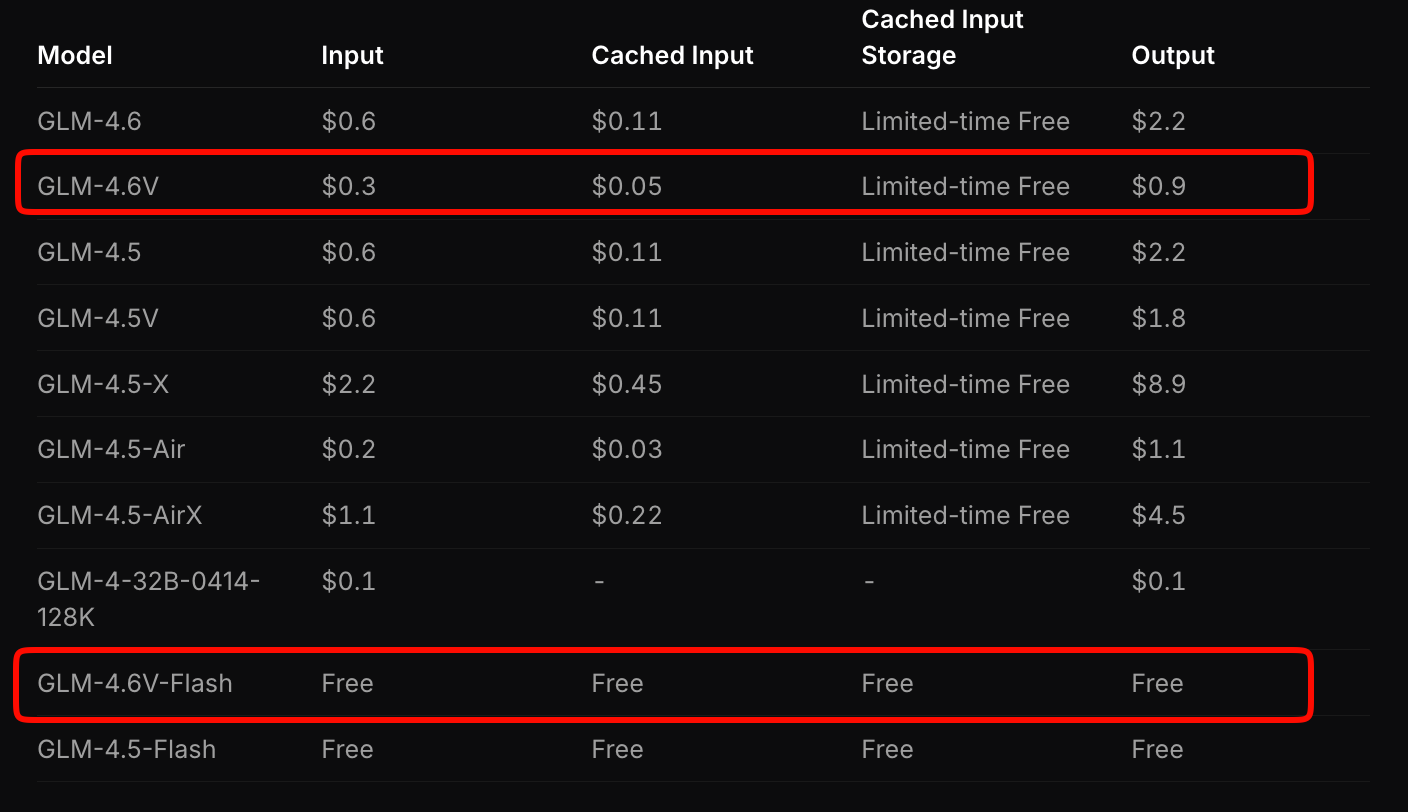
Em contraste, o GLM-4.6V-Flash oferece acesso gratuito, ideal para prototipagem ou implantações em edge. Nenhuma taxa de token se aplica, embora os custos de inferência estejam vinculados ao seu hardware. Uma promoção por tempo limitado triplica as cotas de uso a um sétimo do custo para camadas pagas, tornando a experimentação acessível.
Compare isso com os concorrentes: o GLM-4.6V supera APIs multimodais semelhantes em 20-30% enquanto oferece benchmarks superiores. Para aplicativos de alto volume, calcule os custos por meio da ferramenta de estimativa da Z.ai. Insira uma carga de trabalho de exemplo — digamos, 100 análises diárias de documentos — e ele projeta as despesas mensais.
Além disso, pesos de código aberto mitigam custos de longo prazo. Ajuste fino em seus dados para reduzir a dependência de chamadas na nuvem. No geral, essa precificação permite que startups escalem sem restrições orçamentárias.
Integrando a API GLM-4.6V com o Apidog: Otimização Prática do Fluxo de Trabalho
O Apidog transforma a integração do GLM-4.6V de um trabalho manual árduo para uma colaboração eficiente. Como cliente de API e ferramenta de design, ele importa a especificação da Z.ai, gerando automaticamente modelos de requisição. Você arrasta e solta payloads multimodais, visualiza respostas e exporta para snippets de código em Python, Node.js ou cURL.
Comece criando um novo projeto no Apidog. Cole o URL do endpoint e autentique com sua chave. Para uma tarefa de fundamentação visual, construa uma requisição: adicione um tipo image_url, insira o prompt de coordenadas e clique em enviar. O Apidog visualiza as saídas, destacando as etapas de pensamento.
A colaboração se destaca aqui. Compartilhe coleções com equipes; controle de versão de endpoints à medida que você adiciona ferramentas. Variáveis de ambiente protegem as chaves entre os ambientes de desenvolvimento, staging e produção. Consequentemente, os ciclos de implantação são encurtados — teste uma cadeia de agentes completa em minutos.
Estenda para o monitoramento: O Apidog registra latências e erros, identificando gargalos em fluxos multimodais. Emparelhe-o com o GLM-4.6V-Flash para testes locais gratuitos e depois dimensione para a nuvem. Desenvolvedores relatam prototipagem 40% mais rápida com tais ferramentas.
Casos de Uso no Mundo Real: Aplicando o GLM-4.6V em Produção
O GLM-4.6V se destaca em indústrias com grande volume de documentos. Analistas financeiros carregam relatórios; o modelo analisa gráficos, calcula proporções e gera resumos executivos com elementos visuais incorporados. Uma empresa reduziu o tempo de análise de horas para minutos, aproveitando o contexto de 128K para declarações anuais.
No e-commerce, agentes de busca visual são ativados. Clientes fazem upload de fotos de produtos; o GLM-4.6V planeja consultas, recupera correspondências e raciocina sobre atributos como variantes de cor. Isso aumenta a conversão em 15%, de acordo com os primeiros adotantes.

Equipes de frontend aceleram a prototipagem. Insira uma captura de tela; receba código editável. Itere com prompts como "Adicionar uma barra de navegação responsiva". A fidelidade em nível de pixel do modelo minimiza as revisões, reduzindo pela metade o tempo de design para implantação.

Plataformas de vídeo se beneficiam do raciocínio temporal. Resuma palestras com carimbos de data/hora ou detecte eventos em feeds de vigilância. O uso nativo de ferramentas se integra a bancos de dados, sinalizando anomalias automaticamente.
Estes casos demonstram a versatilidade do GLM-4.6V. No entanto, o sucesso depende da engenharia de prompts — crie instruções claras para maximizar a precisão.
Desafios e Melhores Práticas para o Uso da API GLM-4.6V
Apesar das vantagens, modelos multimodais enfrentam obstáculos. Entradas de alta resolução inflacionam a contagem de tokens, aumentando os custos — comprima imagens para 512x512 pixels primeiro. O estouro de contexto arrisca alucinações; divida vídeos longos em segmentos.
As melhores práticas mitigam esses problemas. Use o modo de pensamento para depuração; ele expõe etapas intermediárias. Valide as saídas das ferramentas com asserções em seu código. Para usuários do Apidog, configure testes automatizados em endpoints para impor esquemas.
Monitore as cotas de perto — o Flash gratuito evita surpresas, mas as camadas pagas precisam de planejamento orçamentário. Finalmente, ajuste fino em dados de domínio via pesos abertos para aumentar a especificidade.
Conclusão: Eleve Seus Projetos com GLM-4.6V Hoje
O GLM-4.6V redefine a IA multimodal através de ferramentas nativas, vasto contexto e acessibilidade aberta. Sua API, com preços competitivos de US$ 0,6/M de entrada para o modelo completo e gratuita para o Flash, integra-se perfeitamente com plataformas como o Apidog. De agentes de documentos a geradores de UI, ele impulsiona a inovação.
Implemente essas percepções agora: pegue sua chave de API, teste no Apidog e comece a construir. O futuro da IA favorece aqueles que aproveitam tais capacidades precocemente. Qual aplicação você transformará a seguir?