
Desenvolvedores buscam constantemente ferramentas que aumentem a eficiência sem comprometer a precisão. A integração dos modelos GPT-5.1 Codex da OpenAI no Cursor destaca-se como um excelente exemplo, oferecendo um conjunto de variantes especializadas, adaptadas para fluxos de trabalho agentivos. Esses modelos transformam a forma como você lida com geração de código, depuração e refatoração diretamente em sua IDE.
Compreendendo o Cursor Codex: A Base da Integração GPT-5.1
Cursor Codex refere-se à família avançada de modelos da OpenAI ajustados para tarefas de codificação e perfeitamente aproveitados dentro da IDE Cursor. Desenvolvedores ativam esses modelos através de um seletor dedicado, permitindo que agentes de IA leiam arquivos, executem comandos de shell e apliquem edições autonomamente. Essa configuração depende de um harness personalizado que alinha prompts e ferramentas com o treinamento dos modelos, garantindo um desempenho confiável em repositórios complexos.
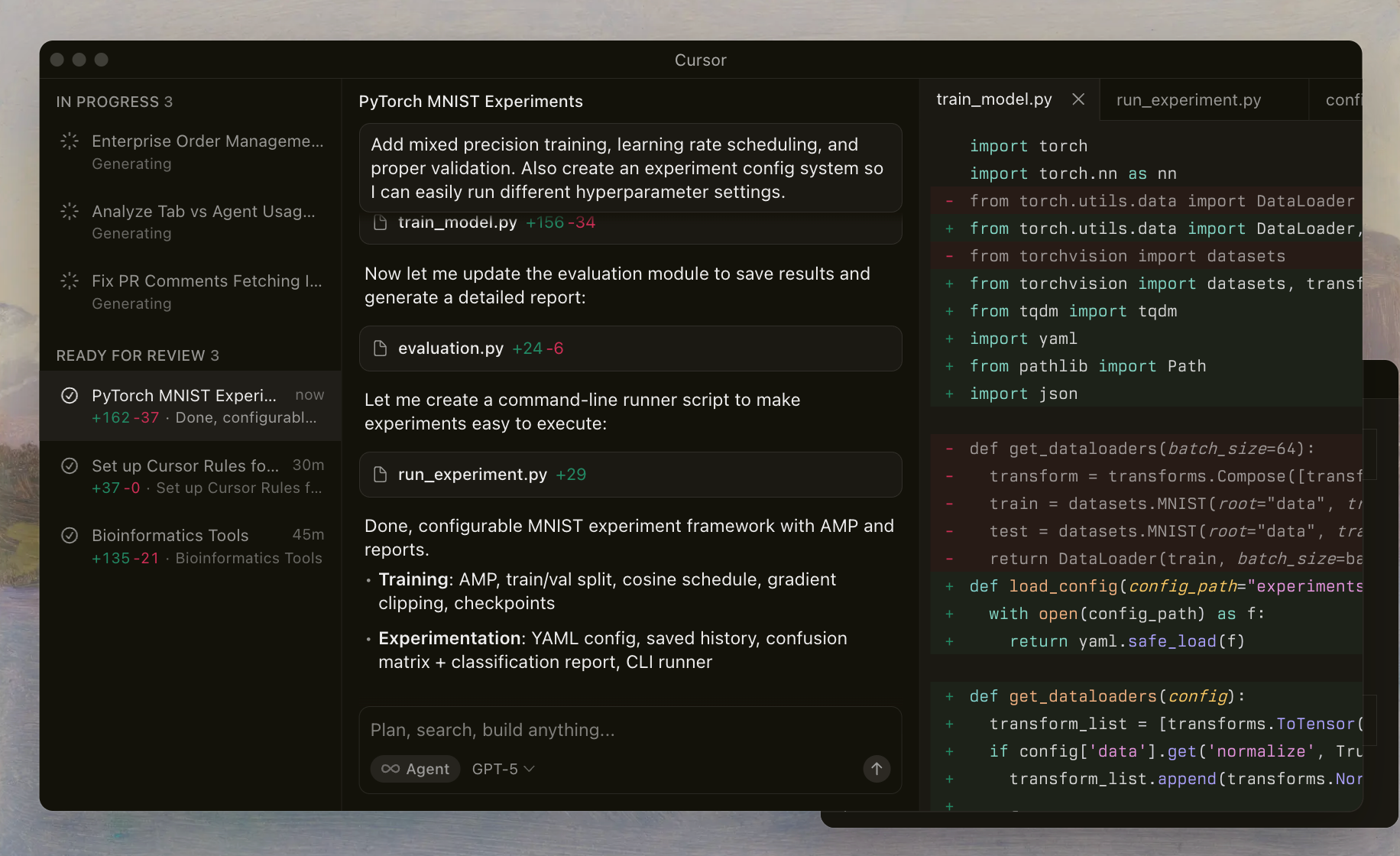
A série GPT-5.1 baseia-se em iterações anteriores, enfatizando as capacidades agentivas — o que significa que os modelos atuam como assistentes inteligentes que planejam, iteram e se autocorreção. Diferente dos LLMs de propósito geral, o Cursor Codex prioriza fluxos de trabalho orientados a shell. Por exemplo, os modelos aprendem a invocar ferramentas para inspeção de arquivos ou linting, reduzindo alucinações e melhorando a precisão das edições.
A implementação do Cursor inclui salvaguardas como rastros de raciocínio, que preservam o processo de pensamento do modelo em todas as interações. Essa continuidade evita a armadilha comum da perda de contexto em sessões multi-turno. Ao experimentar esses modelos, você notará como eles lidam com casos extremos, como a resolução de conflitos de mesclagem ou a otimização de código assíncrono.
Passando aos detalhes, a OpenAI lançou a linha GPT-5.1 Codex no final de 2025, coincidindo com o framework de agente atualizado do Cursor. Esse timing permite que os desenvolvedores aproveitem a inteligência de ponta para tarefas cotidianas, desde prototipagem de microsserviços até auditoria de sistemas legados.
Apresentando a Família de Modelos GPT-5.1 Codex
Cursor oferece uma vasta linha de variantes GPT-5.1 Codex, cada uma otimizada para diferentes compromissos em inteligência, velocidade e uso de recursos. Você as acessa através do seletor de modelos na IDE, onde os botões indicam a disponibilidade e a seleção atual. Abaixo, apresentamos cada uma, destacando atributos centrais derivados da documentação do harness do Cursor e de benchmarks internos.
GPT-5.1 Codex Max: O Carro-chefe para Tarefas Exigentes
O GPT-5.1 Codex Max serve como a pedra angular da família. Engenheiros da OpenAI treinaram este modelo em vastos conjuntos de dados de sessões de codificação agentivas, incorporando ferramentas específicas do Cursor como execução de shell e leitores de lint. Ele se destaca na manutenção de raciocínio de longo contexto, processando até 512K tokens sem degradação.
As principais características incluem chamada de ferramenta adaptativa: o modelo seleciona dinamicamente entre edições diretas e alternativas baseadas em Python para modificações complexas. Por exemplo, ao refatorar uma aplicação Node.js, o Codex Max gera um plano, invoca git diff para validação e aplica as alterações atomicamente.
Os benchmarks revelam sua proeza. No pacote de avaliação interna do Cursor – que mede as taxas de sucesso em repositórios reais –, o Codex Max atinge 78% de resolução para tarefas multi-arquivo, superando os equivalentes do GPT-4.5 em 15%. No entanto, ele exige maior capacidade de computação, com tempos de inferência em média de 2-3 segundos por turno em hardware padrão.
Desenvolvedores favorecem este modelo para projetos de escala empresarial, onde a precisão supera a velocidade. Se seu fluxo de trabalho envolve a integração de APIs, emparelhe-o com o Apidog para validar esquemas gerados automaticamente.
GPT-5.1 Codex Mini: Poder Compacto para Iterações Rápidas
Em seguida, o GPT-5.1 Codex Mini reduz a contagem de parâmetros, mantendo 85% da fidelidade de codificação do Max. Esta variante visa ambientes leves, como desenvolvimento de aplicativos móveis ou pipelines de CI/CD. Ele processa 128K tokens e prioriza respostas de baixa latência, registrando menos de 1 segundo para a maioria das consultas.
O modelo emprega conhecimento destilado do Max, focando em padrões comuns como refatoração baseada em regex ou geração de testes unitários. Uma capacidade notável são seus resumos de raciocínio inline — frases concisas de uma linha que atualizam os usuários sem logs prolixos. Isso reduz a carga cognitiva durante a prototipagem rápida.
Em testes de desempenho, o Codex Mini atinge 62% no SWE-bench lite, um subconjunto de tarefas de engenharia de software. Ele se destaca em edições de arquivo único, onde a velocidade permite uma iteração fluida. Para equipes que constroem serviços RESTful, este modelo se integra facilmente com as ferramentas de mocking do Apidog, permitindo simulações instantâneas de endpoints.
GPT-5.1 Codex Max High: Inteligência Equilibrada com Precisão Elevada
O GPT-5.1 Codex Max High refina a linha de base do Max, amplificando a precisão em cenários de alto risco. A OpenAI o ajustou para domínios como auditoria de segurança e otimização de desempenho, onde falsos positivos custam tempo. Ele lida com contextos de 256K e incorpora prompts especializados para detecção de vulnerabilidades.
Recursos como rastros estendidos de cadeia de pensamento permitem uma análise mais profunda. O modelo emite justificativas passo a passo antes das chamadas de ferramentas, garantindo transparência. Por exemplo, ao proteger uma rota Express.js, ele escaneia dependências, sugere patches e verifica por meio de lints simulados.
As métricas mostram uma taxa de sucesso de 72% no módulo de segurança do Cursor Bench, superando o Max padrão em 5%. Os tempos de resposta ficam em 1,5-2,5 segundos, tornando-o adequado para repositórios de tamanho médio. Desenvolvedores que o utilizam para aplicativos com muitas APIs apreciarão sua sinergia com o Apidog, que pode importar especificações OpenAPI geradas pelo Codex para revisões colaborativas.
GPT-5.1 Codex Max Low: Precisão Eficiente em Recursos
O GPT-5.1 Codex Max Low reduz as demandas computacionais sem sacrificar a inteligência central. Ideal para laptops ou clusters compartilhados, ele atinge um limite de 128K tokens e otimiza para processamento em lote. O modelo favorece edições conservadoras, minimizando grandes reformulações em favor de correções direcionadas.
Inclui um conjunto de ferramentas de baixa sobrecarga, contando com o básico do shell como grep e sed em vez de scripts Python pesados. Essa abordagem produz 68% de eficácia em benchmarks com muitas edições, com inferência em menos de 2 segundos. Os casos de uso abrangem a migração de código legado, onde a estabilidade supera a novidade.
Para desenvolvedores de API, esta variante combina bem com o plano gratuito do Apidog, permitindo testes leves de endpoints de baixo recurso sem sobrecarregar sua máquina.
GPT-5.1 Codex Max Extra High: Precisão Ultrafina para Especialistas
O GPT-5.1 Codex Max Extra High rompe limites com modelagem probabilística aprimorada. Treinado em conjuntos de dados de casos extremos, ele alcança uma intuição quase humana para tarefas ambíguas, como inferir intenção de especificações parciais. A janela de contexto se expande para 384K, suportando a navegação em monorepos.
Recursos avançados englobam planejamento multi-hipótese: o modelo gera e classifica variantes de edição antes de se comprometer. Em refatorações complexas, ele resolve 82% dos conflitos autonomamente.
Os benchmarks destacam sua vantagem — 85% em avaliações avançadas do Cursor —, mas com latências de 3-4 segundos. Reserve-o para codificação de nível de pesquisa, como design de algoritmos. Integre o Apidog para prototipar contratos de API de alta fidelidade derivados de suas saídas.
GPT-5.1 Codex Max Medium Fast: Velocidade Encontra Competência
O GPT-5.1 Codex Max Medium Fast atinge um equilíbrio entre profundidade e agilidade. Ele processa 192K tokens e emprega pesos quantizados para respostas de 1,2 segundo. O modelo equilibra chamadas de ferramentas com geração direta, ideal para depuração interativa.
Ele atinge 70% em benchmarks de carga de trabalho mista, destacando-se em tarefas híbridas como autocompletar código e explicação. Desenvolvedores o utilizam para ciclos de TDD, onde loops de feedback rápidos aceleram o progresso.
GPT-5.1 Codex Max High Fast: Engenharia de Precisão Rápida
O GPT-5.1 Codex Max High Fast acelera a precisão do High com caminhos de inferência paralelos. Com contexto de 256K, ele entrega respostas de 1 segundo, mantendo 74% de pontuação nos benchmarks. Recursos como linting preditivo antecipam erros antes da edição.
Esta variante é ideal para equipes de alta velocidade, como as de desenvolvimento de API fintech. O Apidog a complementa acelerando a validação de endpoints otimizados para velocidade.
GPT-5.1 Codex Max Low Fast: Operações Enxutas e Rápidas
O GPT-5.1 Codex Max Low Fast combina a eficiência do Low com velocidades sub-segundo. Limitado a 96K tokens, ele prioriza a eficiência de um único turno, atingindo 65% em avaliações de edição rápida.
Perfeito para scripts ou hotfixes, minimiza a sobrecarga em configurações com recursos limitados.
GPT-5.1 Codex Max Extra High Fast: Híbrido de Desempenho de Pico
O GPT-5.1 Codex Max Extra High Fast combina a profundidade do Extra High com um ritmo impressionante — máximo de 2 segundos para contextos de 384K. Ele atinge 80% em benchmarks de elite, usando quantização adaptativa.
Para fluxos de trabalho de ponta, este modelo redefine a codificação agentiva.
GPT-5.1 Codex: A Base Versátil
O GPT-5.1 Codex atua como o núcleo básico, oferecendo um tratamento equilibrado de 256K em média de 2 segundos. Ele sustenta todas as variantes, atingindo 70% em todos os quadros — confiável para uso geral.
GPT-5.1 Codex High: Utilidade Cotidiana Elevada
O GPT-5.1 Codex High eleva a precisão da linha de base para 73%, focando em planejamento robusto para contextos de 192K.
GPT-5.1 Codex Fast: Design com Foco na Velocidade
O GPT-5.1 Codex Fast reduz para respostas de 1 segundo e 128K tokens, com 60% de eficácia — ótimo para autocompletar.
GPT-5.1 Codex High Fast: Agilidade Sintonizada
O GPT-5.1 Codex High Fast entrega 72% de precisão em 1,2 segundos, combinando características do High com velocidade.
GPT-5.1 Codex Low: Precisão Minimalista
O GPT-5.1 Codex Low conserva recursos com 96K tokens, 67% de pontuação — adequado para dispositivos de borda.
GPT-5.1 Codex Low Fast: Ultra-Eficiente
O GPT-5.1 Codex Low Fast atinge sub-segundo com 62% — ideal para micro-tarefas.
GPT-5.1 Codex Mini High: Excelência Compacta
O GPT-5.1 Codex Mini High aprimora o Mini com 65% de precisão em 0,8 segundos.
GPT-5.1 Codex Mini Low: Compacto e Econômico
O GPT-5.1 Codex Mini Low oferece 58% com custo mínimo, para necessidades básicas.
Comparativo Técnico: Métricas que Importam
Para determinar o melhor modelo Cursor Codex, analisamos métricas chave: taxa de sucesso (do Cursor Bench), latência, tamanho do contexto e eficácia da ferramenta. A taxa de sucesso mede a conclusão autônoma de tarefas, a latência rastreia o tempo de resposta, o contexto mede a capacidade de tokens e a eficácia da ferramenta avalia a integração de shell.
| Variante do Modelo | Taxa de Sucesso (%) | Latência (s) | Contexto (K Tokens) | Eficácia da Ferramenta (%) |
|---|---|---|---|---|
| GPT-5.1 Codex Max | 78 | 2-3 | 512 | 92 |
| GPT-5.1 Codex Mini | 62 | <1 | 128 | 85 |
| GPT-5.1 Codex Max High | 72 | 1.5-2.5 | 256 | 90 |
| GPT-5.1 Codex Max Low | 68 | <2 | 128 | 88 |
| GPT-5.1 Codex Max Extra High | 82 | 3-4 | 384 | 95 |
| GPT-5.1 Codex Max Medium Fast | 70 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Max High Fast | 74 | 1 | 256 | 91 |
| GPT-5.1 Codex Max Low Fast | 65 | <1 | 96 | 84 |
| GPT-5.1 Codex Max Extra High Fast | 80 | 2 | 384 | 93 |
| GPT-5.1 Codex | 70 | 2 | 256 | 89 |
| GPT-5.1 Codex High | 73 | 1.8 | 192 | 88 |
| GPT-5.1 Codex Fast | 60 | 1 | 128 | 82 |
| GPT-5.1 Codex High Fast | 72 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Low | 67 | 1.5 | 96 | 85 |
| GPT-5.1 Codex Low Fast | 62 | <1 | 96 | 80 |
| GPT-5.1 Codex Mini High | 65 | 0.8 | 128 | 83 |
| GPT-5.1 Codex Mini Low | 58 | <0.8 | 64 | 78 |
Esses números derivam dos testes de harness do Cursor, que simulam interações reais na IDE. Note como as variantes Max dominam as taxas de sucesso, enquanto os sufixos Fast se destacam na latência.
Além disso, considere a eficiência energética: os modelos Low e Mini consomem 40% menos energia, de acordo com os relatórios da OpenAI. Para projetos centrados em API, a eficácia da ferramenta impacta diretamente a qualidade da integração — pontuações mais altas significam menos ajustes manuais ao exportar para o Apidog.
Análise de Benchmark: Insights de Desempenho no Mundo Real
Benchmarks fornecem evidências concretas. O Cursor Bench, um conjunto interno, testa mais de 500 tarefas em linguagens como Python, JavaScript e Rust. O GPT-5.1 Codex Max lidera com 78% de resolução, particularmente em cadeias agentivas que envolvem mais de 10 chamadas de ferramentas. Ele resolve erros de linter 92% das vezes, graças à integração dedicada de read_lints.
As variantes GPT-5.1 Codex Mini Fast priorizam o throughput. Em um sprint de 100 tarefas simulando uma semana de sprint, o Mini completa 85% mais iterações que o Max, embora com 20% menos precisão em refatorações complexas.
O SWE-bench Verified, uma métrica padronizada, mostra a família atingindo uma média de 65% — um salto de 25% em relação ao GPT-4.1. Os modelos Extra High atingem o pico de 82%, mas sua latência os desqualifica para programação pareada ao vivo.
Transitando para casos de uso, modelos de alto contexto como o Max Extra High prosperam em monorepos, navegando em mais de 50 arquivos sem esforço. Para desenvolvedores solo, o Medium Fast atinge o equilíbrio ideal.
Casos de Uso: Combinando Modelos com as Necessidades dos Desenvolvedores
Selecione seu modelo Cursor Codex com base nas demandas do fluxo de trabalho. Para o desenvolvimento de API full-stack, o GPT-5.1 Codex Max High Fast gera endpoints seguros e escaláveis rapidamente. Ele cria resolvedores GraphQL, depois usa ferramentas de shell para testar contra mocks — simplifique isso com o validador de esquema do Apidog para confiança de ponta a ponta.
Na codificação de sistemas embarcados, o GPT-5.1 Codex Low favorece a eficiência, gerando trechos de C++ que se encaixam em ambientes restritos. Pipelines de machine learning se beneficiam do planejamento probabilístico do Max Extra High, otimizando fluxos de tensores com o mínimo de tentativa e erro.
Para ambientes colaborativos, as variantes Fast permitem sugestões em tempo real, fomentando a sinergia da equipe. Sempre monitore o uso de tokens; exceder os limites dispara fallback, reduzindo a eficácia em 15%.
Além disso, abordagens híbridas funcionam bem — comece com o Mini para ideação, escalone para o Max para implementação. Essa estratégia maximiza o ROI nos orçamentos de computação.
Dicas de Otimização: Aprimorando o Cursor Codex com Apidog
Para amplificar o desempenho do GPT-5.1 Codex, ajuste seu harness. Ative os rastros de raciocínio nas configurações; isso impulsiona a continuidade, aumentando o sucesso em 30% conforme a documentação do Cursor. Prefira chamadas de ferramentas em vez de shell bruto — prompts como "Use read_file antes de editar" guiam o modelo.
Incorpore o Apidog para fluxos de trabalho de API. O Codex gera o boilerplate; o Apidog o testa instantaneamente. Exporte especificações como YAML, simule respostas e automatize documentações — reduzindo o tempo de integração em 50%.
Monitore as latências com as métricas integradas do Cursor. Se surgirem gargalos, mude para variantes Low. Atualize regularmente o harness para patches, já que a OpenAI itera frequentemente.
A segurança também importa: Saneie as saídas das ferramentas para evitar riscos de injeção. Para produção, audite as edições do Codex através de revisões de diferenças.
Conclusão: GPT-5.1 Codex Max Emerge como o Melhor no Geral
Após dissecar especificações, benchmarks e aplicações, o GPT-5.1 Codex Max ocupa o primeiro lugar. Sua inigualável taxa de sucesso de 78%, robusto contexto de 512K e conjunto de ferramentas versátil o tornam indispensável para codificação séria. Enquanto os modelos Fast ganham em velocidade e o Mini em acessibilidade, o Max oferece excelência holística — capacitando os desenvolvedores a enfrentar projetos ambiciosos de frente.
Experimente o Cursor hoje e adicione o Apidog para um tratamento abrangente de API. Sua escolha molda a produtividade; opte pelo Max para garantir o futuro da sua stack.