코드 한 줄 바꾸지 않고도 AI 공급자를 전환할 수 있다면 어떨까요? Venice API는 바로 그런 기능을 제공합니다. 데이터 보존 없는 OpenAI 호환 엔드포인트, 무수정 모델 옵션, 그리고 사용자가 제어하는 프라이버시 우선 아키텍처를 갖추고 있습니다.
대부분의 AI API는 공급업체별 SDK 사용을 강요하고, 모델 훈련을 위해 데이터를 보존하며, 기본 기능에 대해 프리미엄 요금을 부과합니다. 공급업체를 전환할 때마다 애플리케이션을 다시 작성해야 합니다. 사용자의 프롬프트가 경쟁 모델을 훈련시키는 데 사용되며, 비용은 예측 불가능하게 증가합니다.
Venice API는 이러한 문제점들을 해결합니다. OpenAI의 API 구조를 정확히 반영하여, 기본 URL만 변경하면 기존 코드가 즉시 작동합니다. 사용자의 데이터는 비공개로 유지됩니다. 암호화폐 스테이킹 및 사용한 만큼 지불하는 USD 크레딧을 포함한 여러 결제 모델 중에서 선택할 수 있습니다.
개발팀이 최대 생산성으로 함께 작업할 수 있는 통합된 올인원 플랫폼을 원하십니까?
Apidog는 모든 요구사항을 충족하며, Postman을 훨씬 더 저렴한 가격으로 대체합니다!
Venice API 키 생성하기
1. venice.ai/settings/api로 이동하세요.
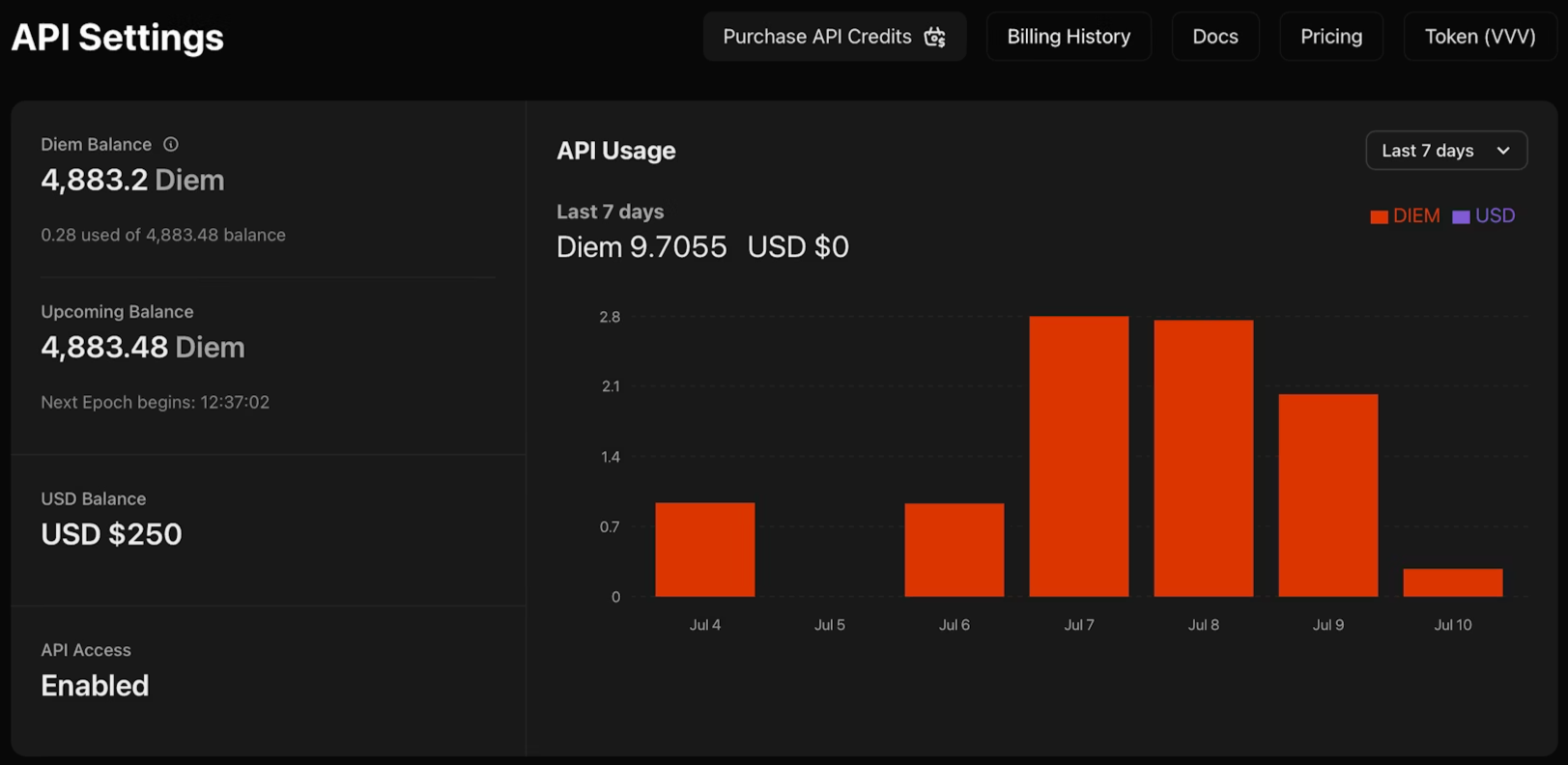
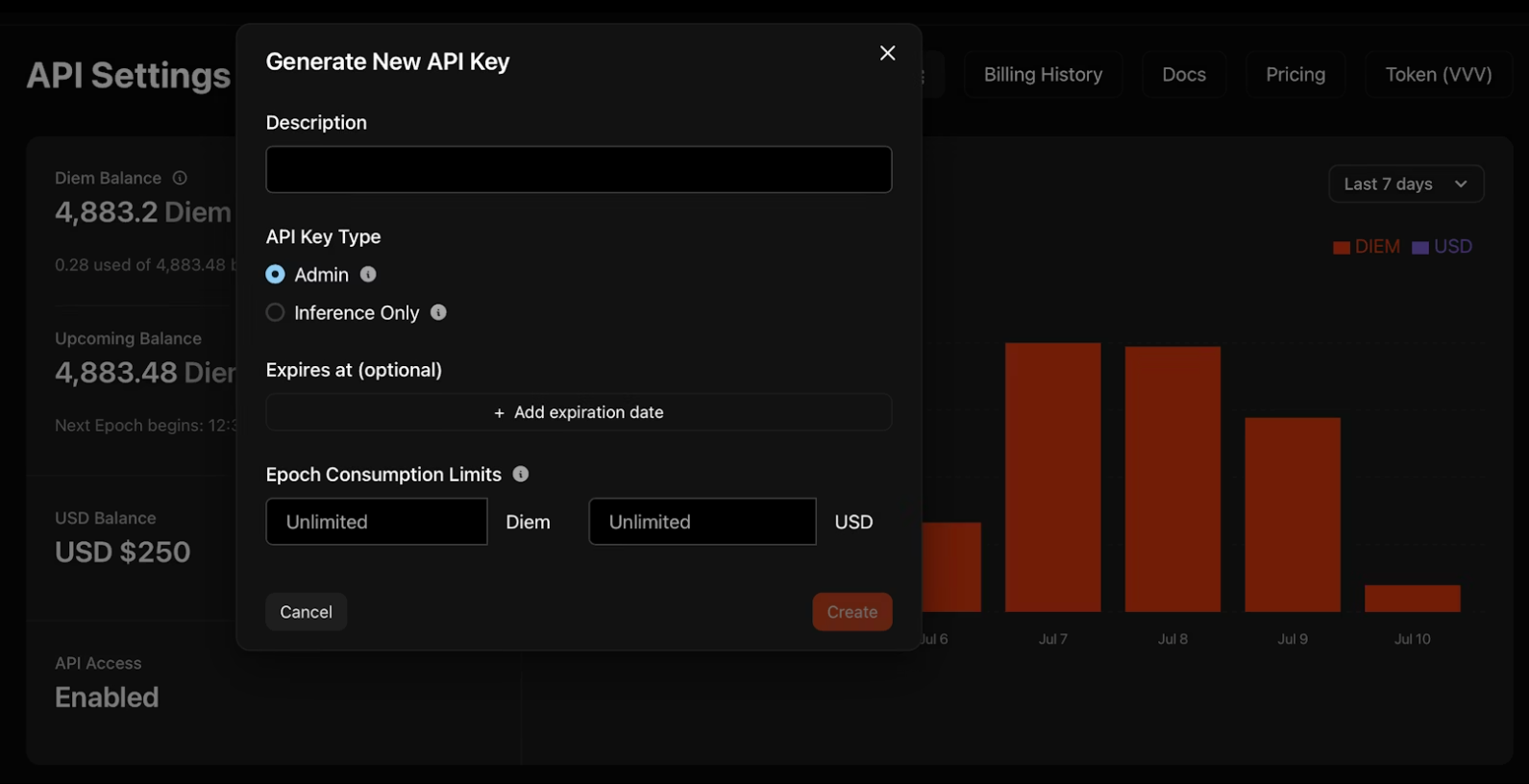
2. "새 API 키 생성"을 클릭하고 자격 증명을 구성하세요:
- 설명: 구분을 위해 키 이름을 지정하세요
- 유형: 관리자 키는 다른 키를 프로그래밍 방식으로 관리합니다; 추론 전용 키는 모델만 실행합니다
- 만료: 키가 자동으로 비활성화되는 선택적 날짜
- 소비 제한: 지출을 제어하기 위한 일일 디엠 또는 USD 한도
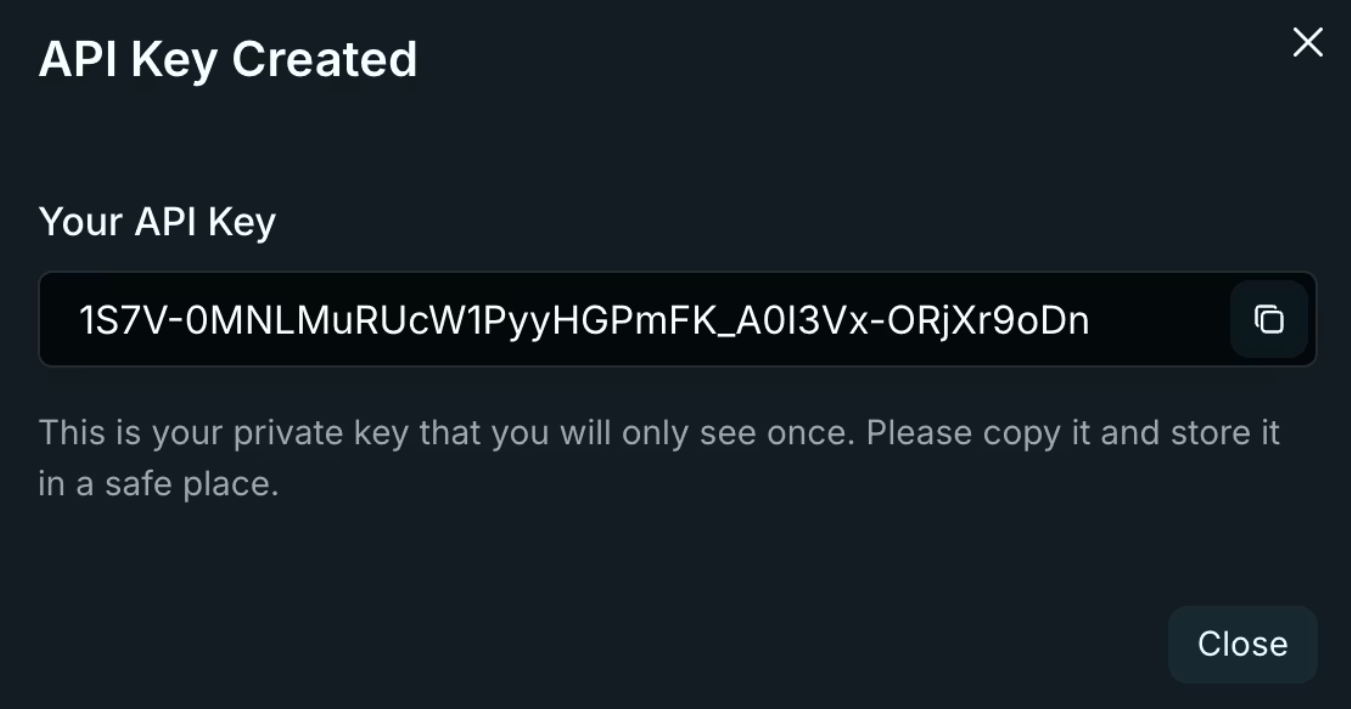
3. 키를 즉시 복사하세요. Venice는 키를 한 번만 표시합니다! 환경 변수에 저장하고 코드 저장소에는 절대 저장하지 마세요.
export VENICE_API_KEY="your-key-here"
키 보안 고려 사항
관리자 키는 Venice 계정에 광범위한 접근 권한을 제공합니다. 루트 자격 증명처럼 취급하여 키 순환 스크립트 및 팀 관리에 사용하고, 애플리케이션 코드에는 절대 사용하지 마세요. 추론 전용 키는 모델 실행으로 작업을 제한하여 유출 시 노출을 줄입니다. 대시보드의 활동 로그를 사용하여 만료된 자격 증명을 식별하고 분기별로 키를 순환시키세요.
Venice API의 인증 및 기본 구성
Venice는 표준 Bearer 토큰 인증을 사용합니다. 모든 요청에는 두 가지 헤더가 필요합니다:
Authorization: Bearer $VENICE_API_KEY
Content-Type: application/json
기본 URL은 OpenAI의 패턴을 정확히 따릅니다:
import openai
import os
client = openai.OpenAI(
api_key=os.getenv("VENICE_API_KEY"),
base_url="https://api.venice.ai/api/v1"
)
이 단일 구성 변경으로 기존의 모든 OpenAI SDK 호출이 Venice의 인프라를 통해 라우팅됩니다. 메서드 변경도, 매개변수 재작성도 필요 없습니다. 코드가 즉시 작동합니다.
SDK 호환성
Venice는 Python, TypeScript, Go, PHP, C#, Java 및 Swift를 포함한 OpenAI의 공식 SDK와 호환성을 유지합니다. OpenAI 사양을 기반으로 구축된 타사 라이브러리도 수정 없이 작동합니다. 기본 URL과 API 키만 변경하여 기존 코드베이스를 Venice에 대해 테스트해 보세요. 표준 채팅 완료, 스트리밍 또는 함수 호출을 사용하는 경우 마이그레이션은 몇 분 밖에 걸리지 않습니다.
OpenAI에서 마이그레이션하기
마이그레이션에는 세 가지 변경 사항이 필요합니다: 기본 URL, API 키 및 모델 이름. https://api.openai.com/v1을 https://api.venice.ai/api/v1으로 교체하세요. OpenAI API 키를 Venice 키로 바꾸세요. 모델 식별자를 gpt-4 또는 gpt-3.5-turbo에서 qwen3-4b와 같은 Venice 동등 모델로 변경하세요. 프로덕션 배포 전에 철저히 테스트하세요. 스트리밍 응답이 올바르게 처리되는지 확인하세요. 함수 호출 스키마가 유효한지 확인하세요. 이미지 생성 매개변수가 요구 사항과 일치하는지 확인하세요. Venice의 호환성 레이어는 대부분의 엣지 케이스를 처리하지만, 오류 메시지 형식 및 속도 제한 헤더에는 미묘한 차이가 존재합니다.
전문가 팁: Apidog로 모든 API 엔드포인트를 철저히 테스트하세요.
핵심 Venice API 엔드포인트 및 기능
Venice는 텍스트, 이미지, 오디오 및 비디오 생성을 다루는 9개의 고유한 엔드포인트를 제공합니다:
텍스트 생성
/api/v1/chat/completions- 스트리밍을 지원하는 대화형 AI/api/v1/embeddings/generate- RAG 애플리케이션을 위한 벡터 임베딩
이미지 처리
/api/v1/image/generate- 텍스트-이미지 생성/api/v1/image/upscale- 해상도 향상/api/v1/image/edit- AI 기반 인페인팅 및 수정
오디오
/api/v1/audio/speech- 텍스트 음성 변환/api/v1/audio/transcriptions- 음성 텍스트 변환
비디오 및 캐릭터
/api/v1/video/queue- 텍스트/비디오-비디오 생성/api/v1/characters/list- AI 페르소나 관리
각 엔드포인트는 적용 가능한 경우 OpenAI 호환 요청/응답 형식을 유지합니다. 기존 파싱 로직을 재사용할 수 있습니다.
엔드포인트 선택 전략
사용 사례 복잡성에 따라 엔드포인트를 매칭하세요. 채팅 완료는 대부분의 텍스트 생성 요구 사항을 처리합니다. 시맨틱 검색 또는 RAG 파이프라인을 위해 임베딩을 추가하세요. 크리에이티브 워크플로 또는 콘텐츠 조정에는 이미지 엔드포인트를 사용하세요. 오디오 엔드포인트는 접근성 기능 또는 음성 인터페이스를 활성화합니다. 하나의 엔드포인트로 시작하여 통합을 검증한 다음 다중 모드 워크플로로 확장하세요.
스트리밍 응답 작업
스트리밍은 채팅 애플리케이션의 체감 지연 시간을 줄여줍니다. Venice는 OpenAI의 구현과 동일한 Server-Sent Events (SSE)를 사용합니다. 완전한 응답을 기다리는 대신 도착하는 부분적인 콘텐츠를 처리하세요. [DONE] 메시지를 확인하여 스트림 종료를 처리하세요. 중단된 스트림을 위한 재연결 로직을 구현하세요—클라이언트 측에 대화 기록을 저장하고 실패한 요청을 재시도하세요. 스트림 청크의 토큰 사용량을 모니터링하여 실시간으로 비용을 추적하세요.
Venice API 전용 매개변수
OpenAI의 표준 매개변수 외에도 Venice는 venice_parameters 객체를 통해 기능 제어를 추가합니다:
{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Latest AI developments?"}],
"venice_parameters": {
"enable_web_search": "on",
"enable_web_citations": true,
"strip_thinking_response": false
}
}
웹 검색 통합
enable_web_search를 auto, on, 또는 off로 설정하세요. auto는 모델이 현재 정보가 응답을 개선하는 시점을 결정하도록 합니다. 최근 이벤트나 빠르게 변화하는 기술에 대한 실시간 쿼리에는 on으로 강제 설정하세요. enable_web_citations와 함께 사용하여 출처 URL을 반환하세요—연구 도구 및 사실 확인에 필수적입니다.
추론 제어
DeepSeek R1과 같은 추론 모델은 기본적으로 단계별 사고 과정을 보여줍니다. strip_thinking_response를 true로 설정하여 최종 답변만 반환하면 토큰 소비를 줄일 수 있습니다. 간단한 쿼리의 경우 disable_thinking을 사용하여 추론을 완전히 우회하세요.
대체 구문
간결한 요청을 위해 모델 접미사를 통해 매개변수를 전달하세요:
model="qwen3-4b:enable_web_search=on&enable_web_citations=true"
매개변수 계층 구조
Venice 전용 매개변수는 기본값을 재정의하지만 명시적 설정을 존중합니다. 루트 객체에 temperature: 0.5를 지정하고 venice_parameters에 enable_web_search: on을 지정하면 둘 다 동시에 적용됩니다. 프로덕션 배포 전에 매개변수 조합을 개별적으로 테스트하세요—일부 매개변수는 특정 모델과 예측할 수 없게 상호작용할 수 있습니다.
Venice API 사용 시 실제 구현 예시
기본 채팅 완료
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Explain zero-knowledge proofs"}],
"stream": true
}'
스트리밍은 OpenAI와 동일하게 작동합니다—도착하는 SSE 청크를 처리하세요.
함수 호출
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Weather in Tokyo?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather for location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
}]
}'
Venice 모델은 OpenAI 구현과 같이 병렬 함수 호출 및 스키마 적용을 지원합니다.
이미지 생성
curl --request POST \
--url https://api.venice.ai/api/v1/image/generate \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "venice-sd35",
"prompt": "Cyberpunk cityscape at night, neon reflections",
"aspect_ratio": "16:9",
"resolution": "2K",
"hide_watermark": true
}'
사용 가능한 종횡비는 1:1, 4:3, 16:9, 21:9입니다. 해상도 옵션은 1K 및 2K입니다.
이미지 업스케일링
curl --request POST \
--url https://api.venice.ai/api/v1/image/upscale \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "upscale-sd35",
"image": "base64encodedimage..."
}'
비전 분석
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-vl-235b-a22b",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "What architecture style is this?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}]
}'
이미지를 base64 데이터 URI 또는 HTTPS URL로 전달하세요. 비전 모델은 비교 작업을 위해 메시지당 여러 이미지를 허용합니다.
오디오 합성
curl --request POST \
--url https://api.venice.ai/api/v1/audio/speech \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "tts-kokoro",
"input": "Welcome to Venice API",
"voice": "af_sky",
"response_format": "mp3"
}'
음성 옵션은 접두사를 사용합니다: af_ (미국 여성), am_ (미국 남성) 및 다른 악센트에 대한 유사한 패턴.
오류 처리 패턴
Venice는 표준 HTTP 상태 코드를 반환합니다. 401은 인증 실패를 나타냅니다—API 키와 헤더를 확인하세요. 429는 속도 제한을 나타냅니다; 1초부터 시작하는 지수 백오프를 구현하세요. 500 오류는 일시적인 인프라 문제를 나타냅니다; 5초 후에 재시도하세요. 특정 메시지에 대한 오류 응답을 파싱하세요—Venice는 응답 본문에 상세한 실패 원인을 포함합니다.
Venice API의 프라이버시 및 데이터 아키텍처
Venice의 데이터 무보존 정책은 단순한 법적 약속이 아닌 기술 아키텍처를 통해 작동합니다. 사용자의 브라우저는 IndexedDB를 사용하여 대화 기록을 로컬에 저장합니다. Venice 서버는 현재 요청만 보는 GPU에서 프롬프트를 처리합니다—대화 기록, 사용자 ID 메타데이터, API 키 정보는 보지 않습니다.
응답을 생성한 후 서버는 프롬프트와 출력을 즉시 폐기합니다. 디스크나 로그에 어떤 것도 보존되지 않습니다. 사용자의 데이터는 모델 훈련에 사용되지 않습니다. 이는 오용 감지 및 모델 개선을 위해 데이터를 보존하는 중앙 집중식 서비스와 근본적으로 다릅니다.
추가적인 프라이버시를 위해 Venice는 대부분의 모델을 타사 공급업체에 의존하지 않고 자체 프라이빗 인프라에서 호스팅합니다. 무수정 옵션은 Venice가 제어하는 하드웨어에서 실행되어 외부 필터링이나 로깅이 없음을 보장합니다.
데이터 흐름 검증
네트워크 트래픽을 모니터링하여 Venice의 프라이버시 주장을 감사하세요. API 요청은 TLS 암호화를 통해 api.venice.ai로 직접 전송됩니다. 문서에는 타사 분석 스크립트가 로드되지 않습니다. 응답 헤더는 캐싱 지시를 표시하지 않습니다—서버 측 데이터 무보존을 확인합니다. 민감한 애플리케이션의 경우, 모델이 내용을 이해하는 것을 방해할 수 있지만, 프롬프트를 보내기 전에 클라이언트 측 암호화를 구현하세요.
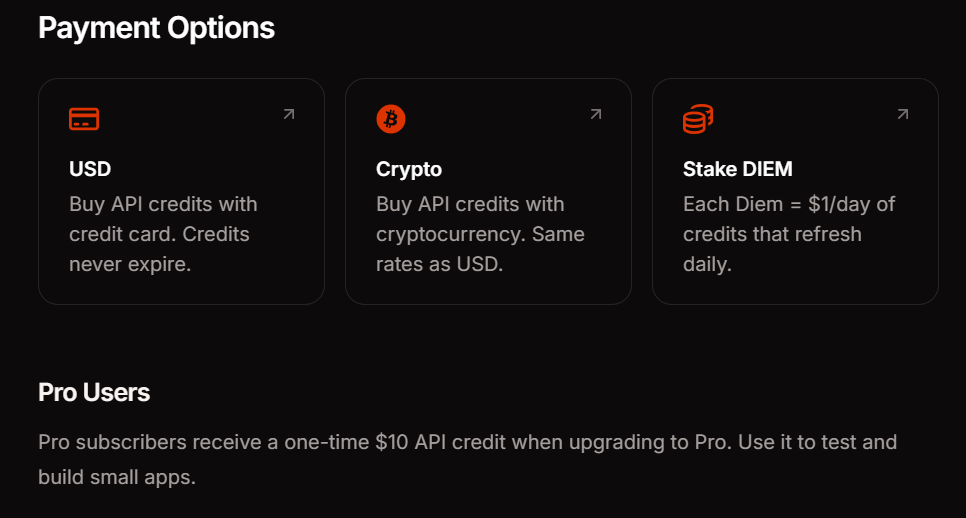
Venice API의 가격 및 결제 옵션
Venice는 사용 패턴에 맞는 세 가지 결제 방법을 제공합니다. Pro 구독은 월 $18이며, API 크레딧 $10과 소비자 기능에 대한 무제한 프롬프트를 포함합니다. DIEM 스테이킹은 VVV 토큰 구매를 필요로 하며, 이는 영구적인 일일 컴퓨팅 할당량을 제공하여 예측 가능한 트래픽이 있는 대용량 애플리케이션에 이상적입니다. USD 종량제(pay-as-you-go)는 달러로 계정에 자금을 충전하고 필요에 따라 크레딧을 소비할 수 있게 해주어 실험 및 가변적인 워크로드에 완벽합니다.
현재 베타 기간 동안 API 접근은 무료입니다. 이를 통해 결제 방법을 확정하기 전에 통합 패턴을 검증하고 비용을 추정할 수 있습니다. 사용량 대시보드를 모니터링하여 엔드포인트 및 모델 전반의 토큰 소비량을 추적하세요.
모델 선택 가이드라인
기능 요구 사항 및 지연 시간 제약 조건에 따라 모델을 선택하세요. 프로토타이핑 및 간단한 쿼리에는 qwen3-4b로 시작하세요—빠르게 응답하고 대부분의 텍스트 생성 작업을 적절하게 처리합니다. 고급 추론, 코드 생성 또는 복잡한 지시 따르기가 필요할 때는 llama-3.3-70b 또는 deepseek-ai-DeepSeek-R1과 같은 더 큰 모델로 업그레이드하세요. 비전 작업에는 qwen3-vl-235b-a22b와 같은 다중 모드 모델이 필요합니다. 오디오 생성에는 특수 음성 모델이 사용됩니다. /api/v1/models 엔드포인트를 프로그래밍 방식으로 쿼리하여 실시간 가용성을 확인하세요—Venice는 수요 및 인프라 용량에 따라 모델을 순환합니다.
결론
Venice API는 AI 통합의 마찰을 제거합니다. 잠금 없이 OpenAI 호환성, 복잡한 구성 없이 프라이버시, 예상치 못한 청구서 없이 유연한 가격 책정을 얻을 수 있습니다. 드롭인 교체 방식은 애플리케이션 코드를 다시 작성할 필요 없이 현재 공급자와 함께 Venice를 평가할 수 있음을 의미합니다.
Venice 엔드포인트를 테스트하거나, 인증 흐름을 디버깅하거나, 여러 공급업체 구성을 관리하는 등 API 통합을 구축할 때 Apidog를 사용하여 워크플로를 간소화하세요. Apidog는 시각적 API 테스트, 문서 생성 및 팀 협업을 처리하여 기능 출시에 집중할 수 있도록 돕습니다.